
이제부터 본격적으로 직접적으로 데이터와 관련된 내용을 배운다.
완전 처음이니까 한번할때 제대로 복습하면서 내 것으로 만들어야지
1. miniconda 설치
- 구글에 miniconda 입력 후 conda홈페이지 들어가기
- window를 사용 한다면 운영체제에 맞는 window용 다운
1.1 Anaconda Prompt(miniconda) 실행
- miniconda 정상 작동 확인
conda env list : 만든 가상 환경의 목록 출력
conda --version : miniconda의 버전 출력
- conda 버전 최신으로 업데이트
conda update conda
- env(가상환경) 생성
conda create -n ds_study(가상환경 이름) python=3.8(사용 할 파이썬 버전)
- env 활성화
conda activate ds_study 또는 source activate ds_study
- env 활성화 확인
(base)에서 (ds_study)로 변환

- env 비활성화
conda deactivate
- env 삭제
conda env remove -n name(삭제할 가상환경 이름)
2. jupyter Notebook 및 패키지 설치
- conda prompt에서 실행
- 이용할 가상환경에서 설치
- 가상환경 활성화 해야한다.
conda activate ds_study
- conda install jupyter(다운받을 패키지명)

- jupyter notebook실행
jupyter notebook
- 주피터노트북 크롬창이 뜨면 성공(기본 앱 : 크롬)
- 오른쪽 상단 New카테고리에 Python3클릭 후 파이썬 출력 되면 성공.(print('hello world))
- 주피터 노트북 환경에서는 Shift+enter가 실행 단축키
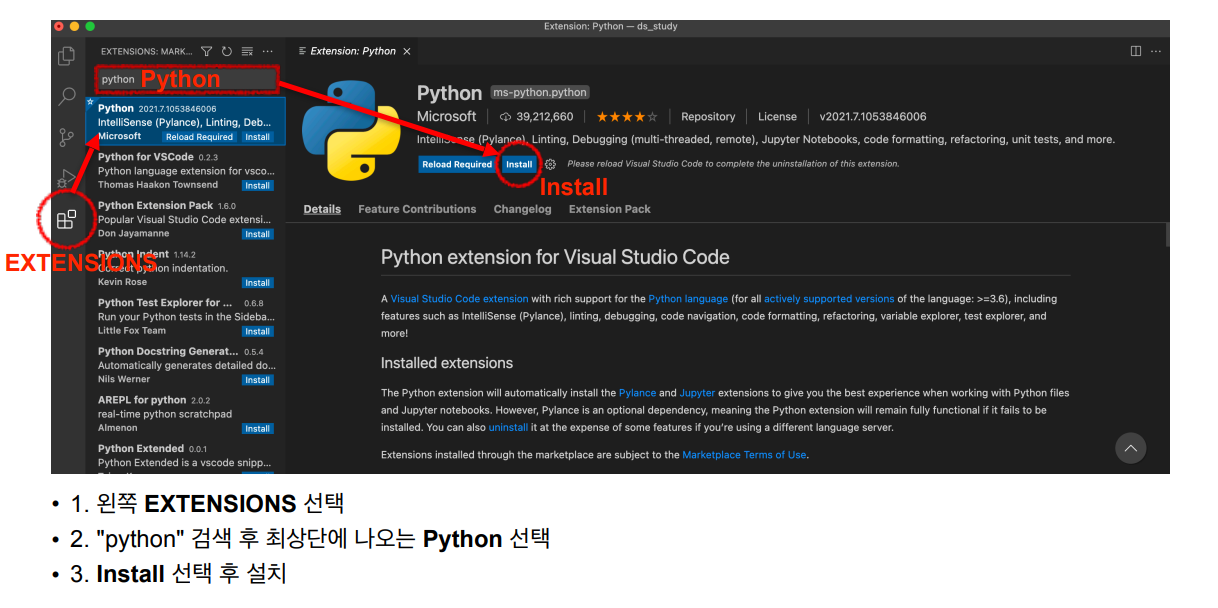
3. VScode 설치
- 구글창에 vscode다운로드 검색 후 홈페이지 클릭
- 자신이 사용하는 운영체제 맞는것 다운
3.1 vscode 파이썬 환경설정
- vscode에서 사용될 파일 경로지정해서 폴더생성
- 예를들어 C에 문서 폴더에 ds_study(vscode에서 사용하는 데이터 저장할 폴더)라는 폴더 생성
- vscode 실행방법 (conda prompt에서 진행)
code- vscode가 실행되면 성공
- .ipynb는 주피터 확장명, .py는 파이썬 확장명

- ds_study 활성화
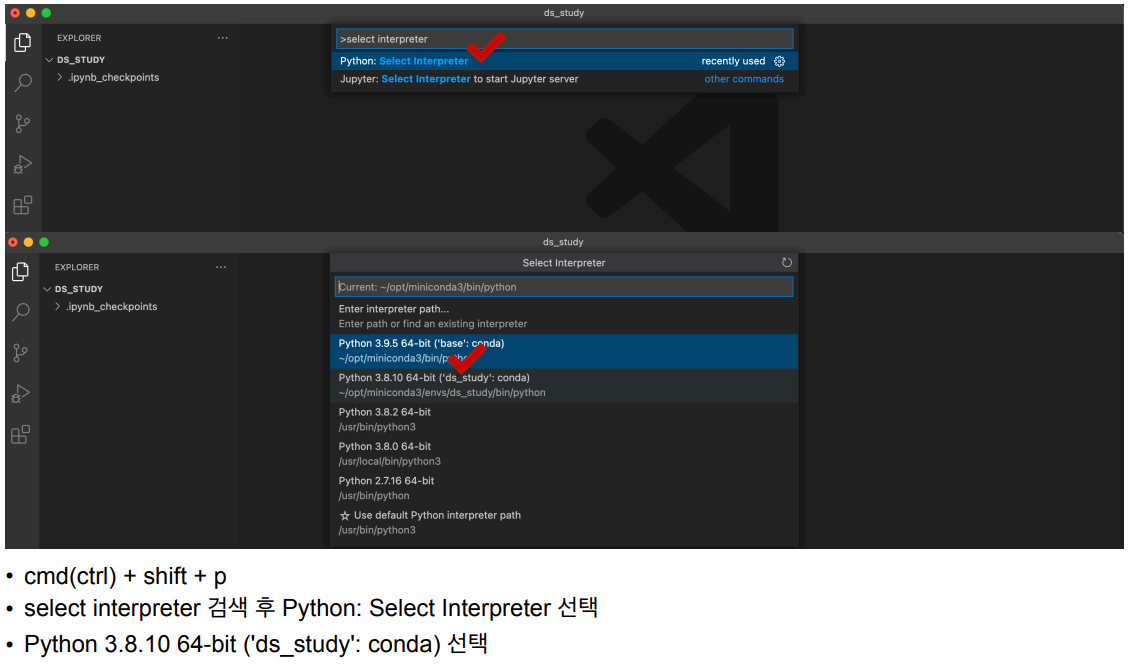
4. jupyter notebook 시작
- conda prompt에서 사용 가상환경 활성화
conda activate ds_study- 데이터가 저장되어 있는 폴더에서 jupyter notebook을 실행해야 함으로 데이터 저장 폴더 경로로 들어가기 (cd 명령어 사용)
cd OneDrive
cd 문서
cd ds_study
jupyter notebook- 위에서 말한 데이터는 .CSV이거나 액셀 파일이다.
01. Analysis Seoul CCTV
1. 데이터 읽기(pandas 사용)
- pandas모듈 가져오기
import pandas as pd
- cvs파일 불러오기
CCTV_Seoul = pd.read_csv("데이터 경로 /데이터 명.csv", encoding='utf-8')
encoding='utf-8은 csv파일을 읽어오면서 한글이 깨질 수 있기 떄문에 사용
- 위에서 5번쨰 까지 데이터 출력
CCTV_Seoul.head()
- 컬럼 명 변경
CCTV_Seoul.rename( columns={CCTV_Seoul.columns[0]: "구별"},inplace=True )inplace = True는 본문에도 적용한다는 것
1) Pandas 기초
- python에서 R만큼 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용가능한 액셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 액셀이라 표현
- Serise
- pandas의 데이터형을 구성하는 기본이 Serise이다.
- index와 value로 이루어져 있다.
- 한가지 데이터 타입만 가질 수 있다.
시작
- pandas모듈과 numpy모듈 가져오기
import pandas as pd
import numpy as np
-Serise이용한 데이터 만들기 : Series([], dtype: float64)
pd.Series([1,2,3,4])0 1 1 2 2 3 3 4 dtype: int64
- 데이터 타입을 float로 받기(numpy모듈 사용)
pd.Serise([1,2,3,4], dtype=np.float64)0 1.0 1 2.0 2 3.0 3 4.0 dtype: float64
- 데이터 타입을 str로 받기
pd.Series([1,2,3,4], dtype=str)0 1 1 2 2 3 3 4 dtype: objectobject는 pandas에서 사용하는 문자열 데이터
- numpy 이용해서 만들 수도 있다.
pd.Series(np.array([1,2,3]))0 1 1 2 2 3 dtype: int32
- key, value 이용해서 만들기
pd.Series({'key':'value'})key value dtype: object
날짜데이터
- 20230628기준으로 6일 날짜
dates = pd.date_range("20230628",periods=6)
DataFrame
- pd.Serise() : index, value
- pd.DataFrame : index, value, column
- 표준정규분포에서 샘플링한 난수 생성
6행4열로 된 난수 생성
data = np.random.randn(6,4)
- 데이터프레임 생성
df = pd.DataFrame(data, index=dates, columns=['A','B','C','D'])
데이터, index, column 순으로 행,열의 수는 맞춰야 한다.
DataFrame 정보탐색
df.head() : 위 5행 정보
df.tail() : 아래 5행 정보 , 가장 아래 행의 이름으로 행의 개수 파악도 할 수 있다.
- colum 목록 보기
df.columns
- index목록 보기
df.index
- value들 보기
df.values
- 데이터 프레임의 기본 정보 확인
df.info()
- 데이터프레임의 기술통계 정보 확인 (평균, 최저, 1/4, 1/2, 3/4)
df.describe()
데이터 정렬
- sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬한다.
- df.sort_values(by='B', ascending = True)
B컬럼을 기준으로 오름차순정렬 (오름차순이 기본값이라 ascending=true는 생략 가능)
- df.sort_values(by="b", ascending=True, inplace=True)
B컬럼 기준으로 오름차순 정렬한 후 본문 저장
- df["A"]
A컬럼 값 출력
- df.A
컬럼이 알파벳이라면 그냥 알파벳만 써도 컬럼이 불러진다.
- df[["A","B"]]
두개 이상 컬럼 선택, []안에 가져올 컬럼 넣어줘야 한다.
offset index
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함
["20230628":"20230630] : 인덱스 20230628에서 20230630까지
loc : location
- index이름으로 특정 행과 열을 선택
- df.loc[:.["A","B"]]
A,B칼럼의 모든 인덱스 뽑기
- df.loc["20230628":"20230630",["A","B"]]
A,B칼럼의 20230628부터 20230630인덱스 값 뽑기
iloc : inter locatioin
- 컴퓨터가 인식하는 인덱스 값으로 선택
- df.iloc[3]
인덱스 3행의 값 뽑기a -0.092953 b -0.183957 c 0.912878 d 0.458107 Name: 2023-07-01 00:00:00, dtype: float64
- df.iloc[3,2]
인덱스3행 인덱스2열 값 뽑기
- df.iloc[3:5,0:2]
인덱스3에서4까지의 행, 인덱스0에서1까지의 열의 값 뽑기
- df.iloc[[1,2,4],[0,2]]
인덱스 1,2,4번 행, 인덱스 0,2번열 값 뽑기
- df["A"]>0
2023-06-28 True 2023-06-29 False 2023-06-30 True 2023-07-01 False 2023-07-02 True 2023-07-03 FalseA컬럼에서 0보다 큰 숫자(양수)만 선택(bool형으로 출력)
- df[df["A"]>0]
데이터 프레임 형태로 뽑기
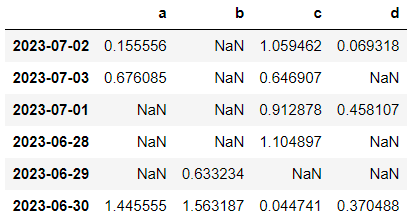
- df[df > 0]
포함되지 않는 값들은 NaN으로 표현
NaN : Not a Number
컬럼추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
- df["E"] = ["one","two","three","four","five","six"]
E컬럼 만들기
isin()
- 특정 요소가 있는지 확인
- df["E"].isin(["two","five","three"])
bool형으로 출력
- df[df["E"].isin(["two","five","three"])]
데이터프레임 형식으로 출력
특정컬럼 삭제
- del
- drop
- del df["E"]
df
E컬럼 삭제하고 df출력해서 확인
- df.drop(['D'], axis=1) #axis = 0 가로(디폴트값), axis = 1 세로
D컬럼 세로값들 삭제 : 결국 D컬럼 삭제
- df.drop(["20230630"])
20230630의 가로값 삭제 : 20230630행 삭제
apply()
- 여러 기능들을 적용한다.
- df["A"].apply("sum")
A칼럼에 값들의 합
- df['A'].apply('mean')
A칼럼의 평균
- df['A'].apply('min'),df['A'].apply('max')
A칼럼의 최솟값, 최댓값
- df[['A','B']].apply("sum")
각각 A,B 칼럼의 합
- numpy이용해서도 가능
df["A"].apply(np.sum)
df["A"].apply(np.mean)
df["A"].apply(np.std) #표준편차
- 함수를 만들어서 사용가능
def plusminus(num): return "plus" if num > 0 else "minus"#함수 생성df['A'].apply(plusminus) #함수 호출
- lambda로 함수 생성 후 호출
df['A'].apply(lambda num: "plus" if num > 0 else "minus")

취업공부