대학교에 입학하고 마냥 열정만 넘치던 새내기 때
'AI 전공만 왕창 들어야지!'
라고 생각했던 나는 2학년 여름방학이 지날때까지 AI 수업을 하나도 듣지 못했다ㅜ
기초필수, 교양, 리더십 등등 들어야 될 과목이 얼마나 많던지...정신이 하나도 없었다..
그러던 도중 2학년 가을학기에 눈에 확 들어온 과목이 있었는데 바로
윤영규 교수님의 CoE202 인공지능 입문 <빅데이터 분석 및 기계학습>..!
제목처럼 입문자들을 위한 강의로, 쉽고 다양한 인공지능 이론들을 소개해주시고 Google Colab을 이용해서 학생들이 직접 실습까지 해보며 그야말로 인공지능의 매력에 푹 빠지게 해준 명강의였다!!
그중에서도 제일 재미있었던 건 기말 프로젝트!
그당시에 내가 가장 좋아했던 인공지능 기법이었던 CNN(Convolutional Neural Network)을 직접 코딩할 수 있어서 인상 깊었던 시간이었다.
그래서 이번 글에서는 CoE202 기말 프로젝트였던 Kaggle Competition에서 내가 프로그래밍한 코드에 대해 다루려고 한다.
🎨 과제 소개
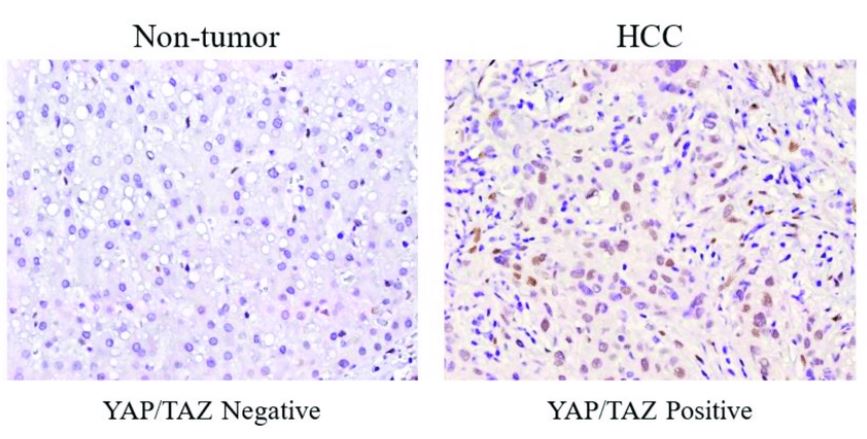
(사진 출처 : 클릭)
과제에 대해 간단히 소개하자면, 정상 조직세포와 암 조직세포의 사진을 보고 둘을 분류해내는 CNN 모델을 만드는 것이 목적이다.
Training 데이터셋은 4096개의 조직세포 사진, Test 데이터셋은 512개의 조직세포 사진들로 이루어져 있다.
이번 과제도 마찬가지로 Google Colab을 사용해 코딩해야됐는데, Google Colab은 GPU 자원이 한정되어 있기 때문에 효율적으로 코딩해야 하는 것도 코딩에 있어 중요했다!
🎈 코드 발전 과정
🥚Basic model
(그림 첨부)
Train accuracy : 0.4
Valid accuracy : 0.3
프로젝트를 시작하기에 앞서 앞으로 작업할 모델의 성능이 얼마나 향상되는지 알기 위해 주어진 Basic model을 먼저 훈련시켜 보았는데, 역시나 정확도는 그리 높지 않았다.
😎Data augmentation 구현
transforms.RandomGrayscale(p=0.1),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None),
Train accuracy : 0.5
Valid accuracy : 0.4
본격적으로 프로젝트를 시작하고 초반에는 CNN의 구조를 변형시키는 것에 익숙하지 않았기 때문에 Basic model을 그대로 둔 채 여러 외적인 요인들을 변형시켜 보며 모델의 성능을 높이고자 했다.
정상 세포와 암 세포의 이미지 구별에 있어 세포들의 패턴이 가장 중요하다고 생각했고, 이미지의 색깔 뿐만 아니라 패턴만 보고도 학습을 진행하고 싶어서 랜덤으로 이미지들을 Grayscale 시켜보았다.
또한 이미지들을 여러 방향으로 뒤집고 회전시켜보면 주요 특징이 손상되지 않고 의미 있는 변형이 가해질 것 같아서 Pytorch.transforms에서 이러한 기능을 담은 함수들을 적용해보았다.
테스트 해보았더니, 정확도가 약간 올라가긴 했지만 아직은 갈 길이 멀어 보였다ㅎㅎ
🕒LR scheduler 구현
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, 'min')Train accuracy : 0.79
Valid accuracy : 0.67
수십 번의 epoch을 일정한 학습률로 훈련시키면 다음과 같은 딜레마가 생겼다.
학습률이 클 때 : 훈련 속도가 빠르지만 후반에 최적점을 넘어가는 경우 발생
학습률이 작을 때: 최적점을 찾기에는 좋지만 그러기까지 오랜 시간이 걸림
이 문제를 해결하기 위해, 처음에는 큰 학습률을 적용하고 점차 학습률을 줄이는 lr_scheduler.ReduceLROnPlateau 함수를 사용했다.
학습률의 변화를 출력해보았더니, 40번째 epoch까지 학습률이 0.001로 유지되다가 이후에 빠르게 감소하는 모습을 보였다.
학습 결과, 정확도가 생각보다 많이 올라가서 놀랐다..!
학습률은 단지 모델의 학습 시간만을 결정짓는 줄 알았는데, 모델의 성능에도 깊이 관여할 수 있다는 걸 깨달았던 것 같다.
🧶3x3 커널 사용 + 채널 증가
self.conv1 == nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 == nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.conv3 == nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1)
self.linear1 = nn.Linear(3*64*64, 64)
self.linear2 = nn.Linear(64, 2)Train accuracy : 0.7
Valid accuracy : 0.6
이것저것 코딩해보면서 Basic model에 조금은 친숙해졌으니 구조를 바꾸어보기로 했다.
강의 시간에 교수님이 일반적으로 3x3 커널을 사용하는 것이 좋을 때가 많다고 말씀하신 게 기억나서 모델의 5x5 커널을 모두 3x3으로 바꾸고, 채널 수를 16에서 64로 늘려서 좀 더 많은 패턴들을 학습할 수 있게 바꾸어 보았다.
그런데 이런, 오히려 정확도가 둘 다 줄어들었다...ㅜㅜ
⚽(Custom model) 3x3 커널 + 채널 증가
self.conv1 == nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.conv2 == nn.Conv2d(16, 16, kernel_size=3, stride=1, padding=1)
self.conv3 == nn.Conv2d(16, 3, kernel_size=3, stride=1, padding=1)
self.linear1 = nn.Linear(3*64*64, 64)
self.linear2 = nn.Linear(64, 2)Train accuracy : 0.78
Valid accuracy : 0.81
욕심이 너무 컸던 것 같아서 채널 수는 원래대로 바꾸고 Dropout 함수도 없애고 커널의 크기만 3x3으로 바꾼 채로 다시 학습시켜 보았다.
그랬더니 Train accuracy는 비슷하지만 Valid accuracy가 0.81이 나오면서 확실히 성능이 좋아졌다!
🧩(VGG-19) Pretrained
model = torchvision.models.vgg16(pretrained=True)Train accuracy : 0.5
Valid accuracy : 0.43
이때쯤 공지사항에 조교님의 공지가 하나 올라왔는데, 다른 Task를 위해 사용됐던 이미지 분류 모델을 이용해 Transfer-learning을 구현해도 된다고 하셨다.
그래서 유명한 모델들을 여럿 찾아보았고, 사전학습된 VGG-19를 학습시켜보았지만 오히려 더 낮은 성능을 보여주었다.
🛶(VGG-19) Non-pretrained
model = torchvision.models.vgg16(pretrained=False)Train accuracy : 0.65
Valid accuracy : 0.66
혹시 사전학습되지 않은 모델을 처음부터 암세포 데이터셋으로 학습시키면 성능이 더 좋지 않을까 싶어 pretrained 변수를 False로 설정하고 학습시켜보았디.
학습 결과, 성능이 향상되긴 했지만 여전히 Custom model에 비해서 좋지 않았다.
🎁(ResNet-101) Pretrained
model = torchvision.models.resnet101(pretrained=True)Train accuracy : 0.97
Valid accuracy : 0.97
VGG-19는 암세포 분류와는 맞지 않는 것 같다고 생각해서 다른 모델을 찾아보았다.
그러다 VGG-19와 기본적인 틀은 비슷하지만 Skip Connection이 적용된 ResNet-101에 대해 알게 되었고 이걸 이용해보기로 했다.
이때, ResNet-101은 224x224 크기의 인풋을 받기 때문에 transforms.Resize(224) 함수를 이용해서 인풋의 크기를 조절했다.
학습 결과, 정확도가 둘 다 눈에 띄게 향상되었다!
🧵(ResNet-101) Non-Pretrained
model = torchvision.models.resnet101(pretrained=False)Train accuracy : 0.94
Valid accuracy : 0.95
VGG-19처럼 사전학습되지 않은 모델을 처음부터 학습시키면 성능이 좋아질까 기대해서 실험해보았지만 ResNet-101은 오히려 성능이 약간 떨어지는 모습을 보여주었다.
🥽(ResNet-101) Pretrained + FC Layer 추가 + SGD optimizer
model = torchvision.models.resnet101(pretrained=True)
model = nn.Sequential(
model,
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1000, 2)
)Train accuracy : 1.0
Valid accuracy : 0.98
ResNet101은 1000개의 항목을 분류하는데, 이 프로젝트는 2개의 항목만을 분류하면 되기 때문에 너무 많은 노드가 낭비된다고 판단했다.
나머지 노드들도 이용하면 좋을 것 같다고 생각해서 모델 마지막에 1000x2 FC 층을 하나 추가했다.
이때, FC 층을 곧바로 추가하면 Linear 층 2개가 연결된 거라 사실상 변화가 없기 때문에 이 둘 사이에 ReLU 함수와 Dropout을 넣어서 비선형성을 추가해주었다.
또 Pytorch 공식 사이트에서 Transfer learning 튜토리얼을 보았는데, 해당 코드에서 SGD optimizer를 사용하는 걸 보고 나도 한번 이걸 써봐야겠다고 생각하게 되었다.
학습을 진행해보니 20번째 epoch만에 Train accuracy가 0.98, Valid accuracy가 0.96으로 높게 나왔고 60번째 epoch에 이르러 위에 적은 정확도가 나왔다.
60번째 epoch을 넘어가고 나서는 정확도가 줄어들면서 오버피팅이 발생했기 때문에 최대 epoch을 60으로 바꾸었어요.
Adam optimizer
Train accuracy : 0.95
Valid accuracy : 0.90
일반적으로 가장 많이 사용하는 optimizer인 Adam도 사용해보았는데, SGD보다 낮은 정확도를 보여주었기 때문에 SGD를 계속 쓰기로 했다.
Rotation + Batch size 20
Train accuracy는 1.0을 달성했지만 Valid accuracy는 아직 0.98의 벽을 넘지 못했기 때문에 고민을 많이 했다..
제일 먼저 시도해본 건 Data augmentation 코드의 Random rotation의 각도 범위를 기존의 보다 크게 바꾸는 거였다.
데이터에 더 큰 변화를 가하면 그만큼 다양한 이미지를 학습해서 Valid accuracy가 높아질 거라고 생각했다.
그런데 , , 를 모두 시도해보니 Valid accuracy는 거의 변화가 없고 오히려 Train accuracy가 작아지는 결과가 나왔다.
유일하게 45도로 설정했을 때 Valid Accuracy가 가장 크게 나왔다.
또 Batch size를 여러 크기(20, 32, 64)로 바꾸어 보기도 했는데, Batch size가 커질수록 Valid accuracy가 감소하는 경향을 보여주었기 때문에 이후 모든 학습을 20의 Batch size로 진행했다.
Batch Normalization
model = torchvision.models.resnet101(pretrained=True)
model = nn.Sequential(
nn.BatchNorm2d(num_features=3),
model,
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1000, 2)
)Valid accuracy를 늘리기 위해서 모델의 성능을 높이는 여러가지 방법을 찾아보다가 Batch Normalization에 대해 알게 되었고, 이 기술이 Valid accuracy를 늘리는 데에 기여할 수 있는 것인지 알아보았다.
Batch Normalization을 배포한 논문을 읽어보았는데 이 기술이 자체적으로 regularization 효과가 있고 Dropout을 제거해도 될 정도로 효과적이라는 것을 알게 되었다..!
( 참고한 논문 : Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift; Sergey Ioffe, Christian Szegedy )
이 기술이 성능을 더 높여줄 거라는 확신이 들었고 모델의 앞부분에 Batch normalization 함수를 추가했다.
학습을 진행해보니 36번의 epoch만에 valid accuracy가 0.99를 달성하며 기존의 최고점을 뛰어넘었고 48번의 epoch에 이르러서는 train accuracy와 valid accuracy 모두 1.00을 달성하는 쾌거를 이루었다!
주어진 데이터로 만족할 만한 결과가 나왔다고 판단해 Test 데이터셋을 분류해보았다.
첫번째 시도에서는 Public score가 0.99346이었고 두번째 시도에서 1.00을 달성했다.
Private score도 비슷할 것이라고 기대하며 만족했지만 며칠 뒤에 공개된 점수는 0.980501으로 예상을 벗어난 낮은 점수였다ㅜㅜ
🥁Grayscale
변화를 줄 수 있는 부분에 어떤 것이 있을까 고민해보았고, 처음으로 돌아가서 생각해보기로 했다.
Data augmentation을 할 때 랜덤으로 Grayscale을 해주었는데, 다시 생각해보니 흑백 사진에서 명도만으로 암세포를 찾는 것 보다는 분홍색, 보라색의 확실히 대조되는 색깔로 학습하는 게 훨씬 의미 있을 것 같아서 이 부분을 삭제했다.
이후 Test 데이터셋을 분류해보았더니 public score가 0.99346으로 기존의 1.0보다는 낮아졌지만 private score를 보니 0.997214로 높은 점수가 나왔다.
그래서 이 모델을 최종 모델로 확정 지었다ㅎㅎ
🥇 Kaggle Leaderboard
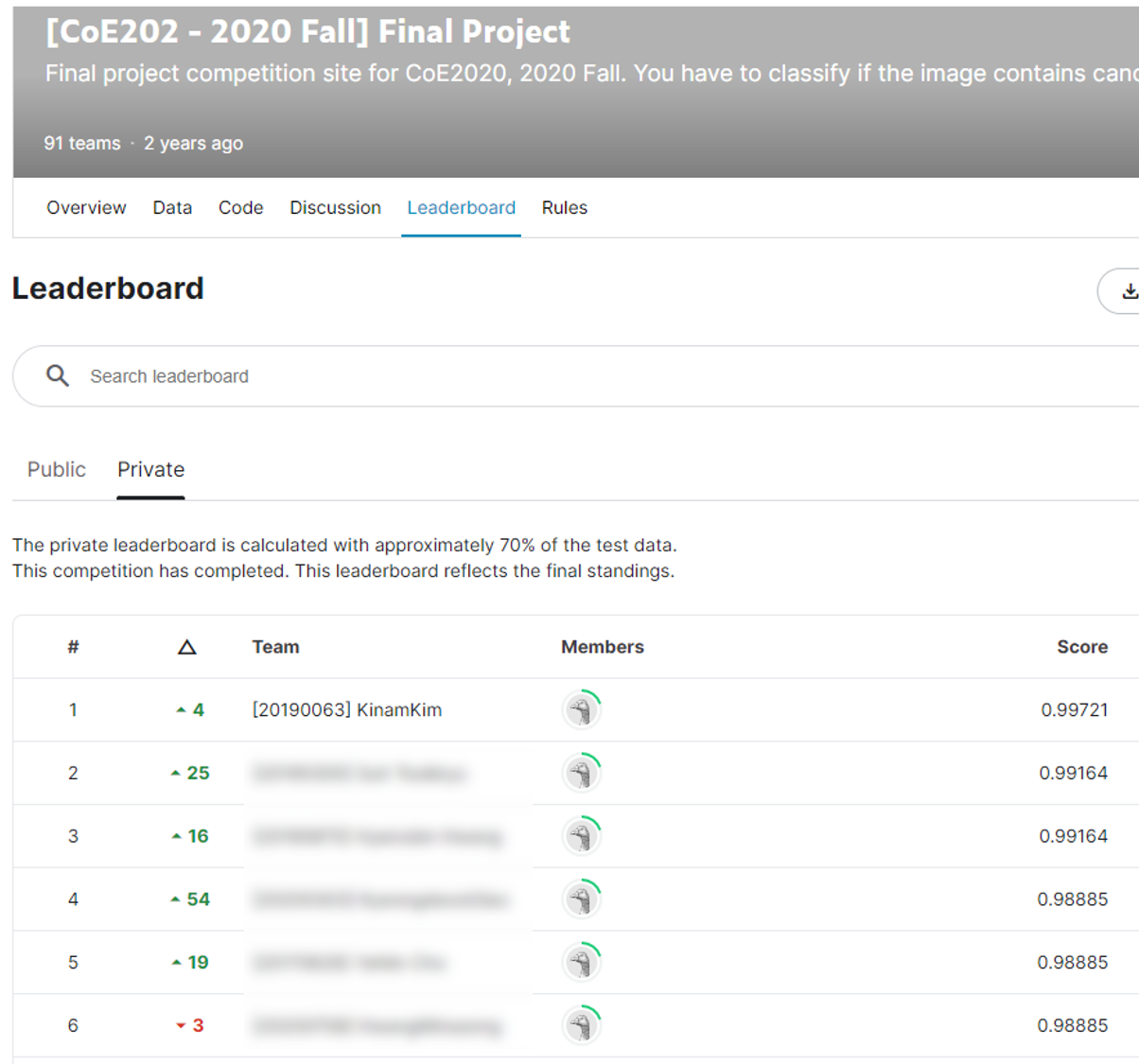
이렇게 재미있는 과제는 처음이었고, 한 달 동안 정말 몰입해서 열심히 코딩한 결과 Kaggle Competition에서 전체 91명 중에 1등도 할 수 있었다!!
