2022년을 맞이하며 어느덧 학부 3학년이 되었고, 인공지능과 관련된 수업도 듣고 논문도 읽으며
어느정도 입문 단계는 넘었다고 생각이 들었다.
이제는 단순히 이론을 공부하는 것을 넘어서 직접 코딩을 해보며 실습을 해보고 싶었다.
'여름학기를 의미 있게 보내려면 어떤 걸 해야 할까' 고민을 많이 했고, 직접 연구실에 컨택해
한번 개별 연구를 진행해보고 싶다는 생각이 들었다.
여러 연구실을 둘러보다 김준모 교수님의 KAIST SiiT Lab을 알게 되었고,
Computer Vision을 심도 있게 다룬다는 점이 인상 깊어서 곧바로 교수님께 이메일을 보냈다.

정말 다행히도 교수님께서 내 지원서류를 좋게 봐주셨고, 연구실 Lab Head 사수님과 함께 개별연구를 진행하게 되었다.
사수님과 얘기를 나누어보며 어떤 주제를 연구할까 고민해보았고, 당시 NLP 분야의 Transformer
알고리즘으로 무려 CNN모델을 능가해 화제가 되었던 Vision Transformer에 대해 다루기로 결정했다.
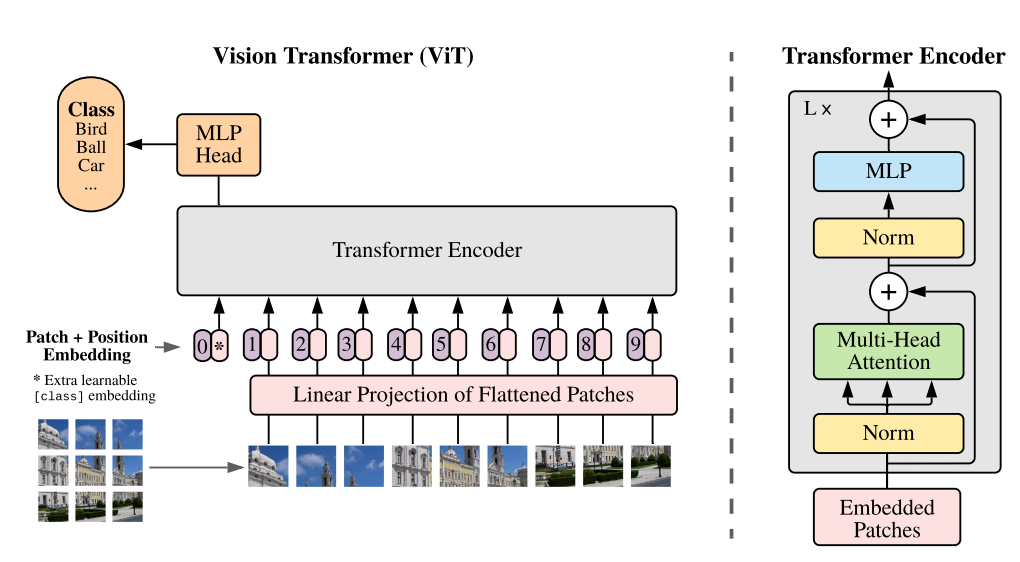
ViT 논문 요약에서도 언급했듯이, ViT는 Inductive Bias가 없기 때문에 CNN모델에 비해서 방대한
데이터셋을 사용해 학습해야 한다. 실제로 논문에서 이용한 데이터셋은 구글의 JBL-300M으로,
일반인이 이토록 방대한 데이터셋을 구할 수 없기 때문에 순수 ViT를 학습하기 쉽지 않다.
따라서 나는 다음과 같은 주제로 개별연구를 진행하기로 했다.
ViT의 구조를 효율적으로 개편해 적은 데이터셋으로도 학습시킬 수 있게 바꾸어보자!
🌏 Environment
개별 연구의 전체적인 환경 요소는 다음과 같다.
🚀 SSH
MobaXterm을 이용해 연구실 서버에 접속해 코딩을 진행했다.
🎨 Base Code
개별연구에 사용할 베이스 코드로는 jeonsworld/ViT-pytorch 를 이용했다.
🧵 Code Modification
ViT 코드에 CNN을 융합시키기 위해 다음과 같이 코드를 짰다.
🔹 우선, 기존에 class Attention(nn.Module) 만 있었던 코드에
class Convolution(nn.Module)을 추가한다.
class Convolution(nn.Module):
def __init__(self, config, vis):
...
def forward(self, hidden_states):
...🔹 다음으로, 임베딩된 패치들을 다시 원래의 위치로 복구하는 작업을 한다.
먼저 이미지와 상관 없는 CLS 토큰을 따로 빼두고, 나머지 패치들을 재배치시킨다.
# remove cls token [B, HxW+1, C] > [B, HxW, C]
conv_cls, conv_layer = torch.split(hidden_states, [1, hidden_states.shape[1]-1], dim=1)
# reshape from [B, HxW, C] to [B, H, W, C]
conv_layer = conv_layer.reshape(hidden_states.shape[0], PATCH_X, PATCH_Y, hidden_states.shape[2])🔹 Pytorch의 nn.Conv2d 함수를 사용하기 위해 텐서의 차원을 알맞게 바꾸어준다.
# change to CNN input dimension [B, C, H, W]
conv_layer = conv_layer.permute(0, 3, 1, 2).contiguous()
# CNN Forward
conv_layer = self.seq_conv2d(conv_layer)🔹 Conv layer들을 지나고 난 output 텐서를 다시 원래의 차원으로 돌려준다.
# restore original dimension [B, H, W, C]
conv_layer = conv_layer.permute(0, 2, 3, 1).contiguous()🔹 output 텐서를 원래의 shape로 되돌리고 CLS 토큰을 다시 결합해준다.
# restore initial shape without cls [B, HxW, C]
init_shape = (hidden_states.shape[0], self.n_out ** 2, hidden_states.shape[2])
total_conv_layer = total_conv_layer.reshape(init_shape)
# cat cls token [B, HxW, C] > [B, HxW+1, C]
cat_conv_layer = torch.cat((conv_cls, total_conv_layer), dim=1)💻 실험 내용
🎈 기본 ViT-B_16 모델
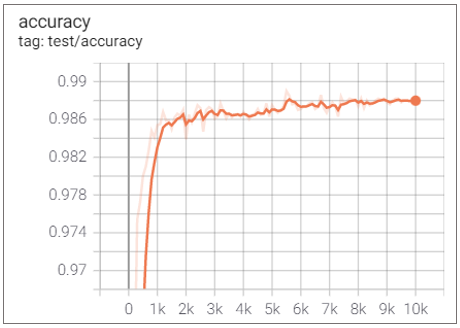
Elapsed Time : 1d 11h 59m 6s
Accuracy : 0.988
🧶ViT 6 layer + 4 Conv layer
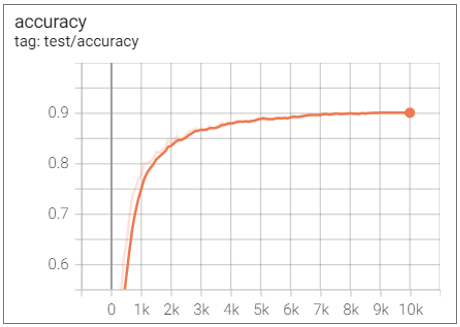
Elapsed Time : 1d 15h 33m 11s
Accuracy : 0.9011
적은 데이터셋으로 ViT를 학습시키기 위해서는 어느정도 Inductive Bias를 도입하는 것이 좋을 것 같았고,
ViT의 전체 12개의 layer 중 6번째 layer까지만 사용하고 이후 구조는 4개의 CNN으로 대체해 보았다.
성능은 매우 떨어지긴 했지만 학습이 안정화되어 그래프가 부드럽게 그려진 것을 확인할 수 있었다.
⚽ ViT 6 layer + 5 Conv layer
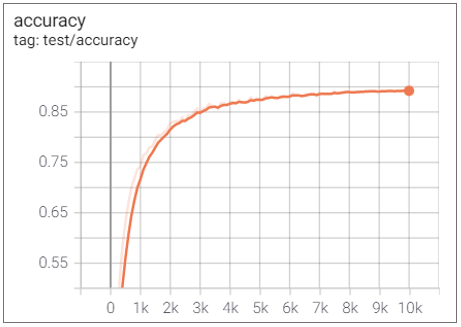
Elapsed Time : 1d 22h 54m 28s
Accuracy : 0.8921
Conv layer를 추가할수록 성능이 좋아질 것이라고 예상했지만 실험 결과는 그렇지 않았다.
⚾ ViT 6 layer + 5 Conv layer (kernel 2)
Elapsed Time : 2d 1h 11m 31s
Accuracy : 0.8608
패치의 크기가 2x2인 점을 고려해서 kernel 크기도 2x2로 맞추면 성능이 좋아지지 않을까 생각해
실험해보았지만, 오히려 더 낮은 성능을 보였다.
다시 생각해보니 2x2의 이미지 패치가 Conv layer에는 하나의 노드로 입력되기 때문에 kernel 크기와는
상관이 없다는 것을 깨닫게 되었고, 이후 실험에서는 kernel의 크기를 3으로 고정했다.
🥎 ViT 6 layer + 6 Conv layer
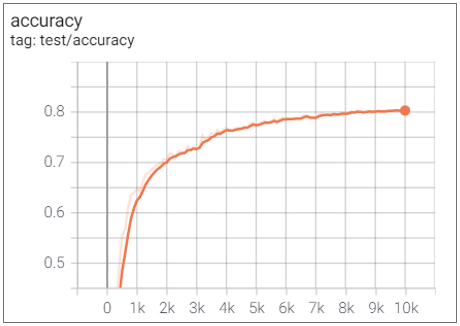
Elapsed Time : 1d 19h 12m 30s
Accuracy : 0.8031
앞서 Conv layer를 추가했을때 성능이 나빠진 모습을 이미 확인했지만 이번 실험을 통해 더욱 확신을 가질 수 있었다.
🎄 ViT 6 layer
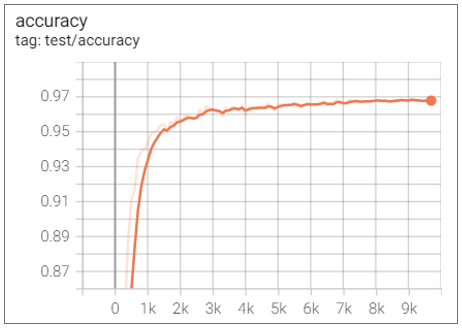
Elapsed Time : 21h 38m 4s
Accuracy : 0.9678
만약 Conv layer를 추가할수록 성능이 나빠진다면 아예 모든 CNN 층을 빼고 ViT 절반으로만 학습해보면
어떨까 하는 생각이 떠올라 실험해보았고, 충격적이게도 매우 좋은 성능을 보여주었다.
👓 ViT 6 layer + 6 FC layer
Elapsed Time : 13h 22m 7s
Accuracy : 0.9499
Conv layer가 ViT layer의 output과 너무 이질적인 것 같아 이번에는 Fully Connected layer 6개를 추가해 실험해보았다.
실험 결과, 역시 nn.Linear 는 Linear한 연산을 수행하다보니 성능은 Conv layer보다 훨씬 좋고, 학습도 안정화시켜 부드러운 그래프가 나왔다.
🛒 (Final) ViT 6 layer + 6 (FC+Conv) layer

Elapsed Time : 1d 4h 53m 46s
Accuracy : 0.97
FC layer의 이점을 확인했으니 이것을 어떻게 하면 Conv layer와 결합할 수 있을지 고민해보았는데,
그러던 중 ResNet의 Shortcut Connection에서 아이디어를 얻어 다음과 같이 코드를 짰다.
# permute from [B, HxW, C] to [B, C, HxW]
fc_layer = cnn_layer.permute(0, 2, 1).contiguous()
# Linear Forward
fc_layer = self.linear(fc_layer)
# reshape from [B, C, HxW] to [B, C, H, W]
fc_layer = fc_layer.reshape(fc_layer.shape[0], fc_layer.shape[1], PATCH_X, PATCH_Y)
# Connect FC layer to CNN layer
total_layer = conv_layer + fc_layer이렇게 FC layer와 Conv layer를 결합해 실험해보니 만족할 만큼 높은 성능이 나왔고, 학습도 많이 안정화되어 굉장히 부드러운 그래프가 도출되었다.
⛳ Conclusion
딥러닝 모델의 학습에는 엄청난 연산량이 필요하다.
특히 ViT와 같이 무거운 모델은 JBL-300M이나 ImageNet-21K와 같이 대규모 데이터셋을 사용해 학습해야 한다.
이러한 경우 고성능의 GPU가 필수인데, 인공지능을 공부하는 학생이나 일반인은 이러한 장비를 마련하기 어려운 것이 현실이다.
딥러닝의 발전을 위해서는 접근 경계를 낮추어 일반인도 어렵지 않게 접할 수 있도록 하는 것이 필요하며,
따라서 무조건 고성능 모델만을 연구하는 것 보다 성능이 살짝 낮더라도 비용이 적게 드는 효율적인 구조의
모델을 개발하는 것도 굉장히 중요하다고 생각한다.
이러한 점에서 이번 실험은 ViT의 구조를 단순화시키면서도 성능을 최대한 보존했다는 점에서 의의가 있다.
