
1. Introduction
연구 배경
- 최근 이미지 Classification 분야에 Transformer를 적용하는 연구가 성공적으로 이루어지면서 CNN이 지배적이었던 분위기를 뒤흔들었다
- 하지만 아직 Image Transformer의 최적화에 대한 연구는 많이 이루어지지 않았다
- 이에 연구진은 이미지 분류를 위한 깊은 Transformer 네트워크를 구축하고 최적화하는 것을 연구하게 되었다
연구진은 더 깊은 구조로 학습해도 성능이 포화되지 않는 Image Transformer 모델을 만들었으며, 이 모델은 더 적은 계산량과 파라미터로 SOTA에 필적하거나 그 이상의 성능을 보여주었다.
2. Implementation
Residual architecture
: Identity function (인풋을 그대로 출력한다)
: Main building block (해당 layer에서 실질적인 연산을 수행한다)
이러한 구조는 더 나은 표현력을 보여주지는 않지만,
학습을 더욱 쉽게 해주어 모델의 성능을 높여준다.
Related Architecture
ViT & DeiT
- Residual branch의 시작 부분에서 먼저 layer normalization을 시행한다
- 모델의 깊이가 좋은 효과를 불러일으킨다는 근거가 없다
- ViT는 구조가 깊어질수록 오히려 더 낮은 성능을 보여주었다
- DeiT는 오직 12개의 layer block을 갖는 transformer만 고려한다
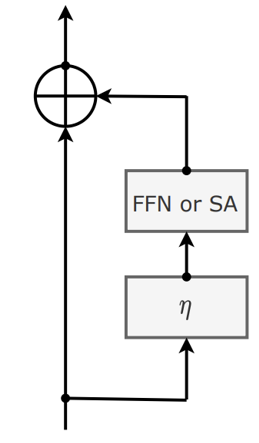
Fixup & ReZero & SkipInit
- Residual block의 출력 부분에서 학습 가능한 스칼라 를 곱한다
- Layer Normalization을 시행하지 않는다
- 스칼라 weighting 를 0 또는 1로 초기화한다
- 깊은 Transformer 네트워크를 이용할 때 수렴하지 않는 문제가 발생한다
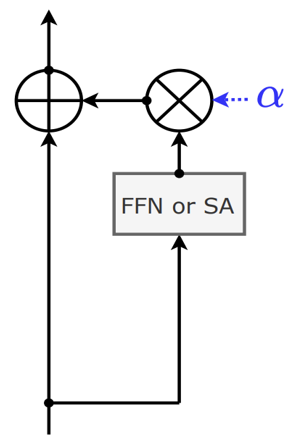
(보완) Fixup & ReZero & SkipInit
- Warm up과 Layer Normalization을 다시 추가해주어 학습을 안정화시켰다
- 깊은 Transformer 네트워크를 이용할 때 수렴하게 되었다
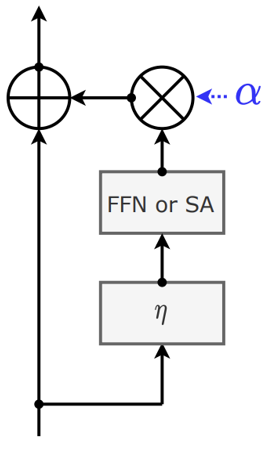
CaiT Architecture
- 하나의 스칼라 weighting 대신 per-channel weighting을 시행한다
- 각각의 weight 를 작은 값으로 초기화한다
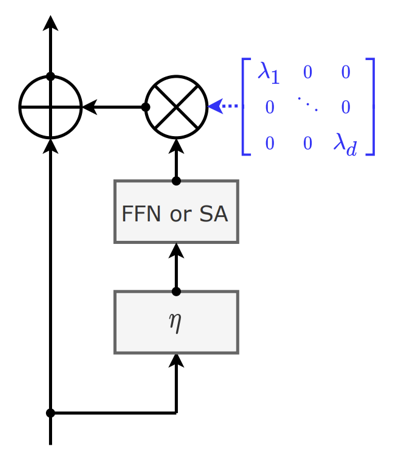
Layer Scale
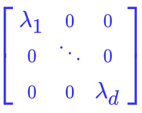
- 를 depth 18까지는 , depth 24까지는 , 이후에는 으로 작게 초기화한다
- ActNorm과 LayerNorm의 Scale parameter와 비슷하지만 다른 효과를 갖는다
- ActNorm은 배치가, LayerNorm은 인풋이 zero-mean과 unit-variance를 갖도록 Scale parameter를 초기화하는 것에 반해, Layer Scale은 데이터와 상관없이 작은 값으로 초기화한다
모델의 구조를 보면, Layer Scale의 파라미터들은 직전의 FFN나 Self-attention 블록에 통합될 수 있기 때문에 모델의 표현력을 높여주지는 않지만,
모델이 더 쉽게 수렴할 수 있도록 도와주어 간접적으로 성능을 높여주는 효과가 있다.
Later Class Token
Key Point
- CLS 토큰을 Transformer 처음이 아닌 중간 부분에 삽입한다
- Transformer의 처음 layer에서 Class 토큰과 패치 토큰들 간의 불일치를 제거하여 오로지 이미지 patch들 간의 self-attention을 수행할 수 있도록 한다
기존 Transformer 모델
- CLS 토큰을 이미지 패치들과 함께 처음에 삽입한다
- CLS 토큰의 weight들이 두가지 목적을 위해 사용된다
(이미지 패치들과의 attention / Classifier의 input)
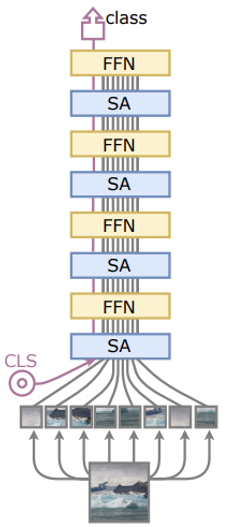
연구진은 CLS 토큰의 모든 weight들이 두가지 목적을 수행한다는 특성이 Transformer의 성능을 제한시켰을 것이라고 가정했다.
보완된 Transformer 모델
연구진은 이를 입증하기 위해 CLS 토큰을 모델 중간에 삽입해보았다.이로써 더 적은 CLS 토큰 weight들이 두가지 목적을 수행하게 되었고, 실제로 더욱 향상된 성능을 보여주었다.
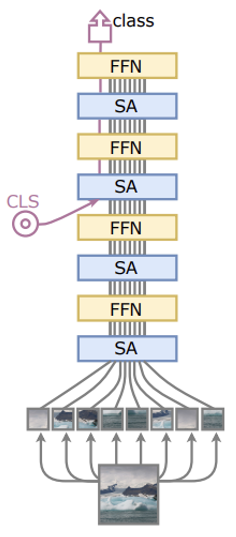
CaiT
- 위와 같은 아이디어에서 착안하여 CLS 토큰을 모델 중간에 삽입한다
- Self-attention 과정은 CLS 토큰이 없다는 것 이외에는 ViT와 동일하다
- Class-attention 과정은 Patch embedding을 CLS embedding에 컴파일하는 과정으로, 이 과정 동안에는 CLS embedding만 업데이트된다
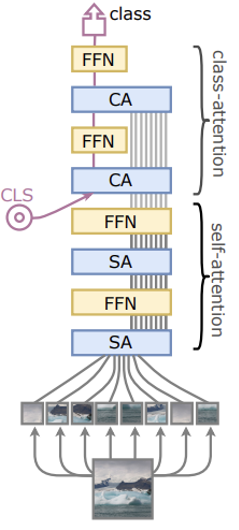
Multi-head Class Attention
에는 ,
각각의 에는 오직 임베딩에 대해서만 가 존재하며
비교 대상으로는 임베딩 뿐만 아니라 임베딩 스스로도 포함되어 있다.
이것과 관련해서 연구진이 수행한 실험이 있는데, 비교 대상으로 임베딩 없이 오직 임베딩들로만 설정하더라도 그다지 큰 성능 저하가 없었기 때문에 사용자의 선택에 맡긴다는 언급이 있었다.
우선, 와 각각의 값들 간의 점수를 구한다.
이후, 값과 곱한 것을 총합해 Scaling weight와 bias를 더해서 최종 output을 출력한다.
는 residual 구조이기 때문에 인풋으로 들어온 임베딩에 어텐션 결과값을 더한 뒤에 다음 layer로 전달한다.
Class Attention
- 이미지 patch embedding들로부터 유의미한 정보를 추출해 Class embedding으로 전달한다
- 첫번째 CA, FFN 블록이 학습에 큰 힘을 주고, 총 2개의 CA+FFN 블록으로 충분히 학습이 가능하다
- Self-attention에 비해 더 적은 Complexity를 갖기 때문에 연산 속도가 빠르다
- 연구진은 12개의 SA+FFN 블록과 2개의 CA+FFN 블록을 이용해 모델을 구축했다
Self-attention과 Class-attention의 시간복잡도 비교
Self-attention (Quadratic)
Class-attention (Linear)
3. Visualizations
아래는 호랑이, 폭포, 말에 대한 Class-attention map을 시각화한 그림이다.
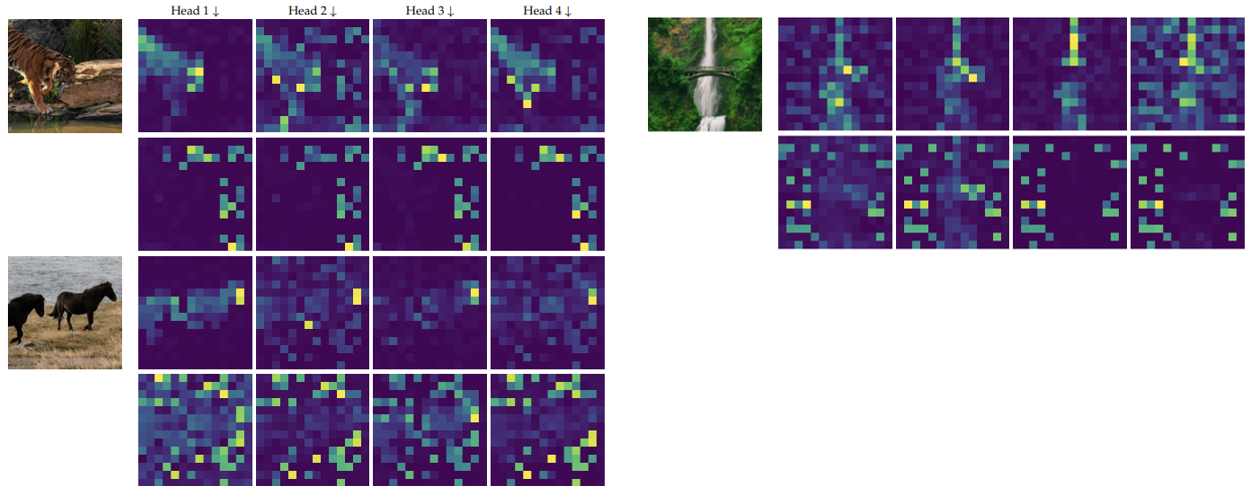
상단의 그림 4개는 첫번째 Class-attention map을,
하단의 그림 4개는 두번째 Class-attention map을 시각화한 것이다.
위 그림을 해석하면 다음과 같다.

먼저 첫번째 Class-attention map을 보면, 이미지 분류에 핵심이 되는 부분들에 집중하는 경향이 있다.
호랑이와 말은 동물의 형태, 특히 머리 부분에 집중하며 폭포는 물줄기에 집중한다.

두번째 Class-attention map을 보면, 물체 주변의 환경과 같은 Global한 특징들에 집중하는 경향이 있다.
다음으로, 아래 그림들은 각각의 이미지에 대한 첫 번째 Class-attention map의 강도를 illustrate한 것이며,
이미지 위쪽에는 Classifier가 10% 이상의 확률로 예측한 분류결과들이 적혀 있다.

이 중 라켓과 테니스공 이미지를 보면, Class-attention map이 두가지 이상의 물체에 동시에 집중할 수 있다는 것을 알 수 있다.
반면 마지막 그림을 보면 성당을 깃발로 잘못 분류한 것을 알 수 있는데, 이 경우는 ViT에서도 언급했듯이 이미지를 동일한 크기의 패치로 나눠야 하기 때문에 성당 위에 있는 뾰족한 첨탑과 아래쪽의 두꺼운 구조물을 함께 인식하지 못해 발생한 문제로 판단된다.
4. Conclusion
마지막으로 CaiT 논문의 의의에 대해 알아보자.
Image Transformer 성능 향상
- LayerScale 기법으로 깊은 Transformer 네트워크도 수렴할 수 있도록 유도했다
- Class-attention 기법으로 Class embedding의 학습 효율성을 높임으로써 Image Transformer의 성능을 향상시켰다
CNN보다 효율적인 Transformer
- 다양한 CNN 모델들과 비교 실험을 진행해보며 Transformer를 이용하면 더 빠른 연산 속도와 더 적은 파라미터 개수로 SOTA CNN모델에 필적하는 성능을 달성할 수 있음을 입증했다
- Best model로는 특정 ImageNet 데이터셋에서 기존의 SOTA CNN모델의 성능을 뛰어넘고 새로운 SOTA를 달성했다
