[논문 요약] On the relationship between self-attention and convolutional layer (2)
0

4. Experiments
각 Head의 Attention 경향성 실험
실험 목적
- Relative position encoding이 적용된 attention layer는 Convolutional layer처럼 행동하도록 학습하는지 알아보자
실험 방법
- 3x3 kernel과 매치되도록 9개의 attention head를 학습에 이용한다
- 각 head의 중심을 정규 분포로 초기화한다
실험 1. 한 Layer에서 epoch에 따른 변화
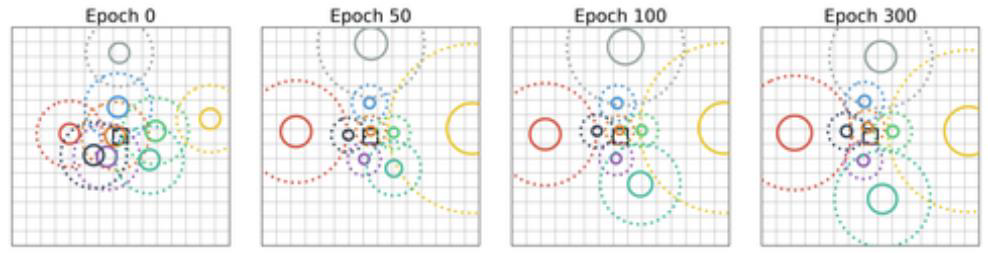
- 각 head가 학습을 진행할수록 점점 초기 위치를 벗어나 특정한 픽셀들에 attend하고 query 픽셀 주변에 Grid를 형성한다
실험 2. Layer의 깊이에 따른 차이
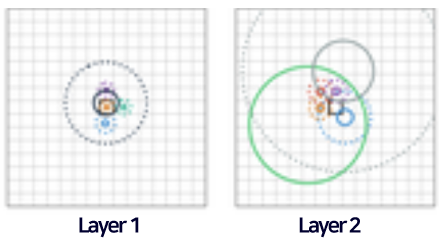
First few layers
- Local 패턴에 attend하는 경향이 있다
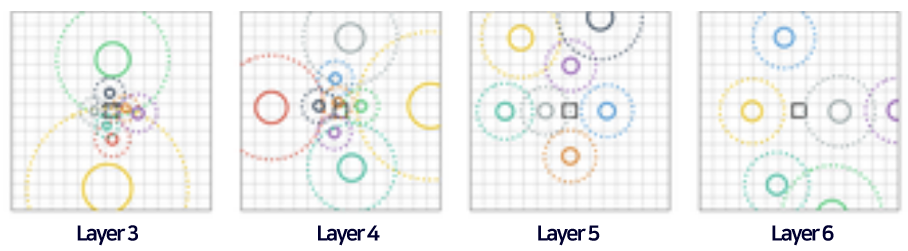
Deeper layers
- Query 픽셀로부터 멀리 떨어진 Larger pattern에도 attend하는 모습을 보여준다
Attention score 시각화
실험 목적
- 이 실제 실험 결과에서도 나타나는지를 관찰하고, 이를 통해 역시 실제로 적용될 수 있음을 입증한다
실험 방법
- (a) input data 없이 relative PE만으로 attention score를 계산하고 시각화한다
- (b) input data를 이용한 positional content-based attention 기반의 attention score를 계산하고 시각화한다 (이미지 100개에 대한 score의 평균)
- 위의 두 방법 (a), (b)를 분석해보며 과 관련된 점을 찾아본다
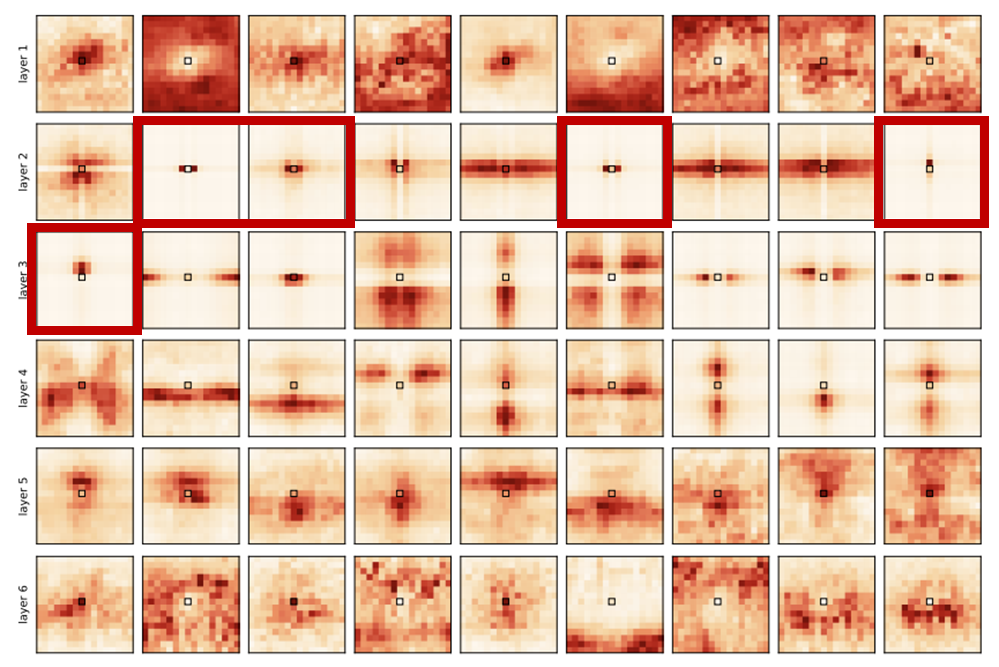
Attention score (a)의 시각화
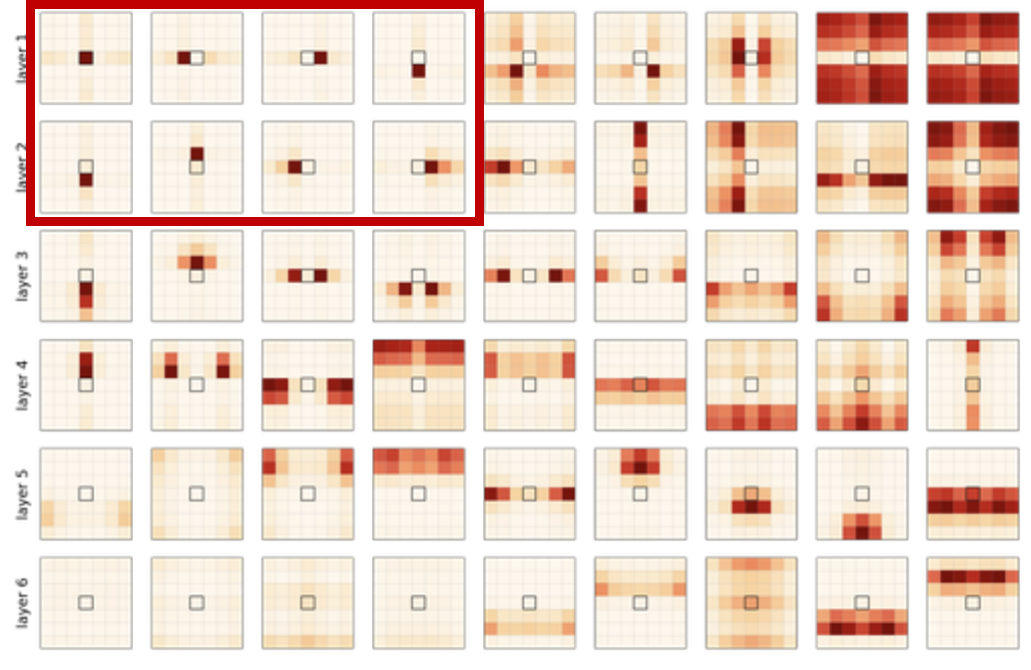
(a) 방식은 데이터를 이용하지 않기 때문에 아래 수식에서 마지막 항만 남는다.
위 그림에서 빨간색 박스 안의 결과들을 보면 하나의 토큰에만 attend하는 모습을 보여준다.
즉, 이 실제로 나타날 수 있음을 알 수 있다.
Attention score (b)의 시각화
(b) 방식은 데이터를 이용하므로 수식의 모든 항을 계산에 이용한다.
마찬가지로 빨간색 박스들을 보면 하나의 토큰에 집중적으로 attend하는 모습을 볼 수 있으며, 이는 이 실제로 나타날 수 있음을 입증한다.
Query 픽셀을 shift했을 때의 시각화
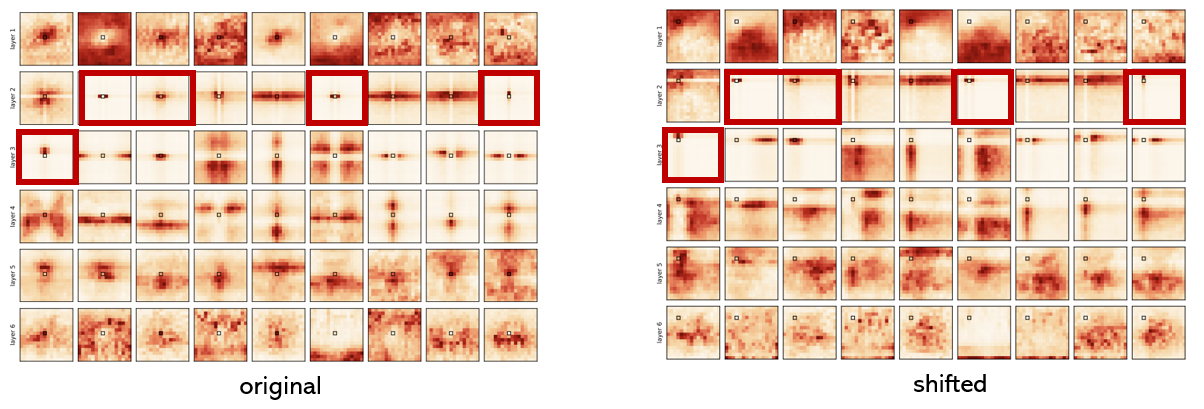
방법 (2)에서 보았던 빨간색 박스의 결과들은 Query 픽셀을 shift하더라도 동일하게 shift된 위치의 Key pixel에 attend하는 모습을 보여준다.
이는 마치 인풋 데이터와 상관 없이 일정하게 shift된 픽셀을 계산에 이용하는 CNN의 receptive field와 유사하다.
5. Conclusion
- 충분한 개수의 Head를 갖는 Self-attention layer는 적어도 Convolutional layer 만큼의 역할을 할 수 있다
- Fully-attention model은 Convolutional layer와 유사한 local behavior와 이미지의 global적인 attention을 결합하도록 학습한다 (Generalized CNN)
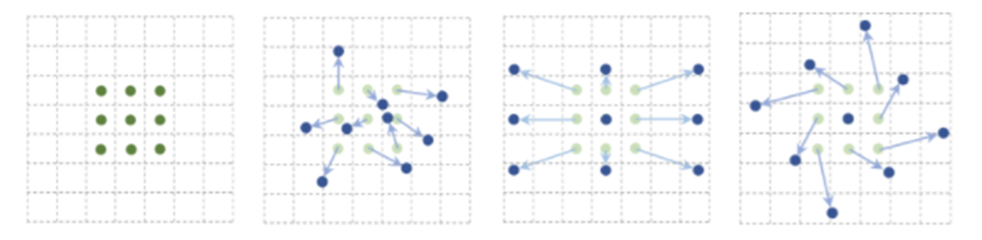
(ex : Deformable Convolution)
- 지금껏 CNN의 오랜 연구로 얻은 통찰들을 Transformer로 재해석하는 미래 연구를 기대해볼 수 있다
6. Reviews
해당 논문에 대한 Open review 사이트의 코멘트와 그에 대한 답글들을 정리해보았다.





AI 공부하는 대학생