
8.1 텍스트 처리용 IMDb 영화 리뷰 데이터 준비
감정 분석(의견 분석) - 자연어 처리(NLP)의 하위 분야
📍IMDB 영화 리뷰 데이터셋📍
- 긍정 또는 부정으로 레이블되어 있는 영화 리뷰 5만 개로 구성
- 긍정 : IMDb에서 별 여섯 개 이상을 받은 영화
- 부정 : IMDb에서 별 다섯 개 아래로 받은 영화
8.1.1 영화 리뷰 데이터셋 구하기
import os
import sys
import tarfile
import time
import urllib.request
source = 'http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
target = 'aclImdb_v1.tar.gz'
def reporthook(count, block_size, total_size):
global start_time
if count == 0:
start_time = time.time()
return
duration = time.time() - start_time
progress_size = int(count * block_size)
speed = progress_size / (1024.**2 * duration)
percent = count * block_size * 100. / total_size
sys.stdout.write("\r%d%% | %d MB | %.2f MB/s | %d sec elapsed" %
(percent, progress_size / (1024.**2), speed, duration))
sys.stdout.flush()
if not os.path.isdir('aclImdb') and not os.path.isfile('aclImdb_v1.tar.gz'):
urllib.request.urlretrieve(source, target, reporthook)
if not os.path.isdir('aclImdb'):
with tarfile.open(target, 'r:gz') as tar:
tar.extractall()8.1.2 영화 리뷰 데이터셋을 더 간편한 형태로 전처리
☑️영화 리뷰를 읽어 하나의 판다스 DataFrame 객체로 만들기☑️
import pyprind
import pandas as pd
import os
# `basepath`를 압축 해제된 영화 리뷰 데이터셋이 있는
# 디렉토리로 바꾸세요
basepath = 'aclImdb'
labels = {'pos': 1, 'neg': 0}
pbar = pyprind.ProgBar(50000)
df = pd.DataFrame()
for s in ('test', 'train'):
for l in ('pos', 'neg'):
path = os.path.join(basepath, s, l)
for file in sorted(os.listdir(path)):
with open(os.path.join(path, file),
'r', encoding='utf-8') as infile:
txt = infile.read()
df = df.append([[txt, labels[l]]],
ignore_index=True)
pbar.update()
df.columns = ['review', 'sentiment']☑️데이터프레임 섞고 CSV 파일로 저장☑️
import numpy as np
np.random.seed(0)
df = df.reindex(np.random.permutation(df.index))
df.to_csv('movie_data.csv', index=False, encoding='utf-8')☑️CSV 파일 읽어 처음 세 개의 샘플 출력☑️
import pandas as pd
df = pd.read_csv('movie_data.csv', encoding='utf-8')
df.head(3)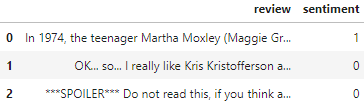
8.2 BoW 모델 소개
BoW : 텍스트를 수치 특성 벡터로 표현
📍아이디어📍
1) 전체 문서에 대해 고유한 토큰, 예를 들어 단어로 이루어진 어휘 사전을 만듦
2) 특정 문서에 각 단어가 얼마나 자주 등장하는지 헤아려 문서의 특성 벡터를 만듦
8.2.1 단어를 특성 벡터로 변환
☑️CountVectorizer 클래스로 BoW 모델 만들기☑️
- fit_transform 메서드 : BoW 모델의 어휘 사전을 구축하고 문장을 희소한 특성 벡터로 변환
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
docs = np.array([
'The sun is shining',
'The weather is sweet',
'The sun is shining, the weather is sweet, and one and one is two'])
bag = count.fit_transform(docs)` python☑️만들어진 특성 벡터를 출력☑️
print(bag.toarray())
8.2.2 tf-idf를 사용하여 단어 적합성 평가
tf-idf : 특성 벡터에서 자주 등장하는 단어의 가중치를 낮추는 기법
☑️단어 빈도를 입력받아 tf-idf로 변환☑️
from sklearn.feature_extraction.text import TfidfTransformer
tfidf = TfidfTransformer(use_idf=True,
norm='l2',
smooth_idf=True)
np.set_printoptions(precision=2)
print(tfidf.fit_transform(count.fit_transform(docs))
.toarray())
➡️단어 빈도가 가장 컸던 'is'의 tf-idf 비교적 작아짐(0.45)
8.2.3 텍스트 데이터 정제
☑️텍스트 데이터에서 마크업과 구두점 기호 제거☑️
import re
def preprocessor(text):
text = re.sub('<[^>]*>', '', text)
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)',
text)
text = (re.sub('[\W]+', ' ', text.lower()) +
' '.join(emoticons).replace('-', ''))
return text☑️데이터프레임에 있는 모든 영화 리뷰에 preprocessor 함수를 적용☑️
df['review'] = df['review'].apply(preprocessor)8.2.4 문서를 토큰으로 나누기
☑️단어의 기본 형태인 어간으로 바꾸는 포터 어간 추출 알고리즘 사용☑️
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
def tokenizer_porter(text):
return [porter.stem(word) for word in text.split()]
tokenizer_porter('runners like running and thus they run')
➡️단어 'running'이 어간 'run'으로 바뀜
☑️불용어 제거☑️
from nltk.corpus import stopwords
stop = stopwords.words('english')
[w for w in tokenizer_porter('a runner likes running and runs a lot')[-10:]
if w not in stop]
8.3 문서 분류를 위한 로지스틱 회귀 모델 훈련
☑️정제된 텍스트 문서가 저장된 DataFrame을 2만 5000개는 훈련 데이터셋으로 나머지 2만 5000개는 테스트 데이터셋으로 나누기☑️
X_train = df.loc[:25000, 'review'].values
y_train = df.loc[:25000, 'sentiment'].values
X_test = df.loc[25000:, 'review'].values
y_test = df.loc[25000:, 'sentiment'].values☑️5-겹 계층별 교차 검증을 사용하여 모델에 대한 최적의 매개변수 조합 찾기☑️
- TfidfVectorizer : CountVectorizer와 TfidTransformer 두 기능을 하나로 합친 것
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import GridSearchCV
tfidf = TfidfVectorizer(strip_accents=None,
lowercase=False,
preprocessor=None)
param_grid = [{'vect__ngram_range': [(1, 1)],
'vect__stop_words': [stop, None],
'vect__tokenizer': [tokenizer, tokenizer_porter],
'clf__penalty': ['l1', 'l2'],
'clf__C': [1.0, 10.0, 100.0]},
{'vect__ngram_range': [(1, 1)],
'vect__stop_words': [stop, None],
'vect__tokenizer': [tokenizer, tokenizer_porter],
'vect__use_idf':[False],
'vect__norm':[None],
'clf__penalty': ['l1', 'l2'],
'clf__C': [1.0, 10.0, 100.0]},
]
lr_tfidf = Pipeline([('vect', tfidf),
('clf', LogisticRegression(random_state=0, solver='liblinear'))])
gs_lr_tfidf = GridSearchCV(lr_tfidf, param_grid,
scoring='accuracy',
cv=5,
n_jobs=-1)
gs_lr_tfidf.fit(X_train, y_train)☑️최적의 매개변수 조합 출력☑️
print('최적의 매개변수 조합: %s ' % gs_lr_tfidf.best_params_)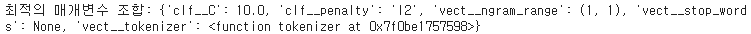
➡️포터 어간 추출을 하지 않는 tokenizer 함수와 tf-idf를 사용하고 불용어 제거는 사용하지 않는 경우 최상의 그리드 서치 결과를 얻음
➡️이대 로지스틱 회귀 분류기는 L2 규제를 사용, 규제 강도 C의 값은 10.0
☑️그리드 서치로 찾은 최상의 모델을 사용하여 훈련 데이터셋에 대한 검증 정확도와 테스트 정확도 출력☑️
print('CV 정확도: %.3f' % gs_lr_tfidf.best_score_)
clf = gs_lr_tfidf.best_estimator_
print('테스트 정확도: %.3f' % clf.score(X_test, y_test))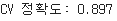
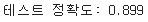
➡️머신 러닝 모델이 영화 리뷰가 긍정인지 부정인지 89.9% 정확도로 예측하리라 기대 가능
8.4 대용량 데이터 처리: 온라인 알고리즘과 외부 메모리 학습
외부 메모리 학습 기법 : 데이터셋을 작은 배치로 나누어 분류기를 점진적으로 학습시킴
☑️텍스트 데이터를 정제하고 불용어를 제외한 후 단어 토큰으로 분리하는 tokenizer 함수 만들기☑️
import numpy as np
import re
from nltk.corpus import stopwords
# `stop` 객체를 앞에서 정의했지만 이전 코드를 실행하지 않고
# 편의상 여기에서부터 코드를 실행하기 위해 다시 만듭니다.
stop = stopwords.words('english')
def tokenizer(text):
text = re.sub('<[^>]*>', '', text)
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text.lower())
text = re.sub('[\W]+', ' ', text.lower()) +\
' '.join(emoticons).replace('-', '')
tokenized = [w for w in text.split() if w not in stop]
return tokenized☑️한 번에 문서 하나씩 읽어서 반환하는 stream_docs 제너레이터 함수 정의☑️
def stream_docs(path):
with open(path, 'r', encoding='utf-8') as csv:
next(csv) # 헤더 넘기기
for line in csv:
text, label = line[:-3], int(line[-2])
yield text, label☑️movie_data.csv 파일에서 첫 번째 문서 읽어보기☑️
next(stream_docs(path='movie_data.csv'))
➡️리뷰 텍스트와 이에 상응하는 클래스 레이블이 하나의 튜플로 반환
☑️문서를 읽어 size 매개변수에서 지정한 만큼 문서를 반환하는 get_minibatch 함수 정의☑️
def get_minibatch(doc_stream, size):
docs, y = [], []
try:
for _ in range(size):
text, label = next(doc_stream)
docs.append(text)
y.append(label)
except StopIteration:
return None, None
return docs, y☑️HashingVectorizer 클래스와 로지스틱 회귀 모델 초기화☑️
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.linear_model import SGDClassifier
vect = HashingVectorizer(decode_error='ignore',
n_features=2**21,
preprocessor=None,
tokenizer=tokenizer)
from distutils.version import LooseVersion as Version
from sklearn import __version__ as sklearn_version
clf = SGDClassifier(loss='log', random_state=1)
doc_stream = stream_docs(path='movie_data.csv')☑️외부 메모리 학습 시작 (점진적인 학습)☑️
import pyprind
pbar = pyprind.ProgBar(45)
classes = np.array([0, 1])
for _ in range(45):
X_train, y_train = get_minibatch(doc_stream, size=1000)
if not X_train:
break
X_train = vect.transform(X_train)
clf.partial_fit(X_train, y_train, classes=classes)
pbar.update()☑️마지막 5000개의 문서를 사용하여 모델 성능 평가☑️
X_test, y_test = get_minibatch(doc_stream, size=5000)
X_test = vect.transform(X_test)
print('정확도: %.3f' % clf.score(X_test, y_test))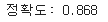
➡️그리드 서치로 하이퍼파라미터 튜닝을하여 달성한 정확도보다 조금 낮음
➡️but, 메모리 효율적이고 모델 훈련이 1분도 채 걸리지 않음
☑️나머지 5000개의 문서를 사용하여 모델을 업데이트☑️
clf = clf.partial_fit(X_test, y_test)8.5 잠재 디리클레 할당을 사용한 토픽 모델링
토픽 모델링 : 레이블이 없는 텍스트 문서에 토픽을 할당하는 광범위한 분야
ex) 대량의 뉴스 기사 데이터셋을 분류하는 일 (스포츠, 금융, 세계 뉴스, 정치, 지역 뉴스)
- 잠재 디렉터리 할당(LDA) : 인기 있는 토픽 모델링 기법
8.5.1 LDA를 사용한 텍스트 문서 분해
LDA : 여러 문서에 걸쳐 자주 등장하는 단어의 그룹을 찾는 확률적 생성 모델
- 입력은 BoW 모델 -> 두 개의 행렬로 분해
- 행렬 : 문서-토픽 행렬, 단어-토픽 행렬
- 단점 : 미리 토픽 개수를 정해야 함(LDA의 하이퍼파라미터로 수동으로 지정해야 함)
8.5.2 사이킷런의 LDA
☑️movie_data.csv 로컬 파일을 판다스의 DataFrame으로 읽어들임☑️
import pandas as pd
df = pd.read_csv('movie_data.csv', encoding='utf-8')☑️CountVectorizer 클래스를 사용하여 LDA 입력으로 넣을 BoW 행렬 만들기☑️
- stop_words='english'로 지정하여 영어 불용어 제거 가능
- max_df=.1 : 단어의 최대 문서 빈도를 10%로 지정하여 여러 문서에 걸쳐 너무 자주 등장하는 단어를 제외 (하이퍼 파라미터)
- max_features=5000 : 가장 자주 등장하는 단어 5000개로 단어 수를 제한 -> 데이터셋의 차원을 제한하여 LDA의 추론 성능을 향상시킴 (하이퍼 파라미터)
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english',
max_df=.1,
max_features=5000)
X = count.fit_transform(df['review'].values)☑️문서에서 열 개의 토픽을 추정하도록 LatentDirichletAllocation 추정기를 BoW 행렬에 학습하기☑️
- learning_method='batch' : lda 추정기가 한 번 반복할 때 가능한 모든 훈련 데이터(BoW 행렬)를 사용하여 학습됨 -> 'online' 설정보다 느리지만 더 정확한 결과를 만듦
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components=10,
random_state=123,
learning_method='batch')
X_topics = lda.fit_transform(X)☑️결과 분석 : 열 개의 토픽에서 가장 중요한 단어 다섯 개씩 출력하기☑️
n_top_words = 5
feature_names = count.get_feature_names()
for topic_idx, topic in enumerate(lda.components_):
print("Topic %d:" % (topic_idx + 1))
print(" ".join([feature_names[i]
for i in topic.argsort()\
[:-n_top_words - 1:-1]]))
➡️각 토픽에서 가장 중요한 단어 다섯 개를 기반으로 LDA가 다음 토픽을 구별했다고 추측 가능
➡️대체적으로 형편없는 영화(실제 토픽 카테고리가 되지 못함), 가족 영화, 전쟁 영화, 예술 영화, 범죄 영화, 공포 영화, 코미디 영화, TV 쇼와 관련된 영화, 소설을 원작으로 한 영화, 액션 영화
☑️카테고리가 잘 선택되었는지 확인하기 위해 공포 영화 카테고리에서 세 개의 영화 리뷰를 출력☑️
horror = X_topics[:, 5].argsort()[::-1]
for iter_idx, movie_idx in enumerate(horror[:3]):
print('\n공포 영화 #%d:' % (iter_idx + 1))
print(df['review'][movie_idx][:300], '...')
➡️정확히 어떤 영화에 속한 리뷰인지는 모르지만 공포 영화의 리뷰임을 알 수 있음
➡️but, 영화 #2는 1번 카테고리인 '대체적으로 형편없는 영화'에 속한다고 볼 수도 있음
