
7.1 앙상블 학습
목표 : 여러 분류기를 하나의 메타 분류기로 연결 -> 개별 분류기보다 더 좋은 일반화 성능을 달성하는 것
☑️방법☑️
1) 과반수 투표 : 분류기의 과반수가 예측한 클래스 레이블을 선택하는 단순한 방법
2) 다수결 투표 : 가장 많은 투표(최빈값)를 받은 클래스 레이블을 선택
3) 랜덤 포레스트 : 서로 다른 결정 트리를 연결
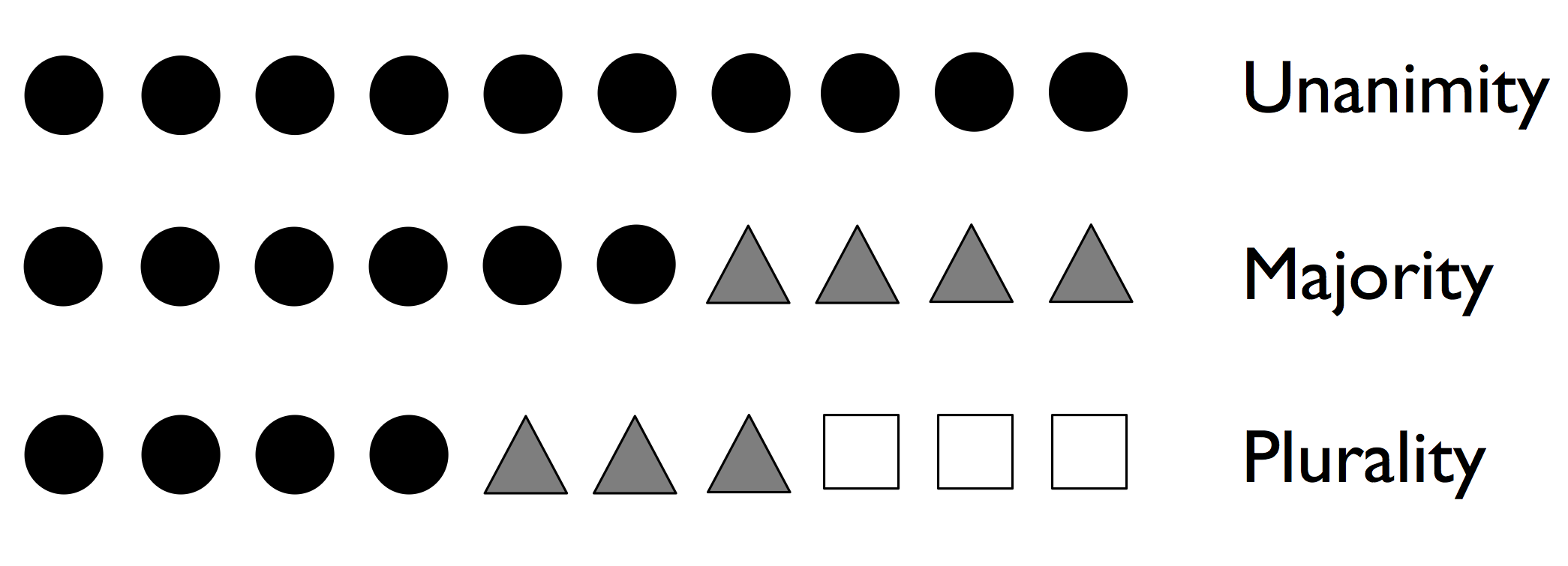
📍과반수 투표📍
1) 훈련 데이터셋을 사용하여 m개의 다른 분류기(예 : 결정 트리, 서포트 벡터 머신, 로지스틱 회귀 분류기)를 훈련시킴 또는, 같은 분류 알고리즘을 사용하고 훈련 데이터셋의 부분 집합을 달리하여 학습
2) 개별 분류기의 예측 레이블을 모두 모아 가장 맣은 표를 받은 레이블 y를 선택
📍앙상블 방법이 개별 분류기보다 성능이 뛰어난 이유📍
ex) 에러율이 0.25인 분류기 11개로 구성된 앙상블의 에러율은 0.034로 훨씬 낮게 됨
이상적인 앙상블 분류기와 다양한 범위의 분류기를 가진 경우 비교
☑️파이썬으로 확률 질량 함수 구현☑️
from scipy.special import comb
import math
def ensemble_error(n_classifier, error):
k_start = int(math.ceil(n_classifier / 2.))
probs = [comb(n_classifier, k) * error**k * (1-error)**(n_classifier - k)
for k in range(k_start, n_classifier + 1)]
return sum(probs)
print(ensemble_error(n_classifier=11, error=0.25))
☑️분류기 에러가 0.0에서 1.0까지 걸쳐 있을 때 앙상블의 에러율을 계산, 앙상블과 개별 분류기 에러 사이의 관계를 선 그래프로 시각화☑️
import numpy as np
error_range = np.arange(0.0, 1.01, 0.01)
ens_errors = [ensemble_error(n_classifier=11, error=error)
for error in error_range]
import matplotlib.pyplot as plt
plt.plot(error_range,
ens_errors,
label='Ensemble error',
linewidth=2)
plt.plot(error_range,
error_range,
linestyle='--',
label='Base error',
linewidth=2)
plt.xlabel('Base error')
plt.ylabel('Base/Ensemble error')
plt.legend(loc='upper left')
plt.grid(alpha=0.5)
plt.show()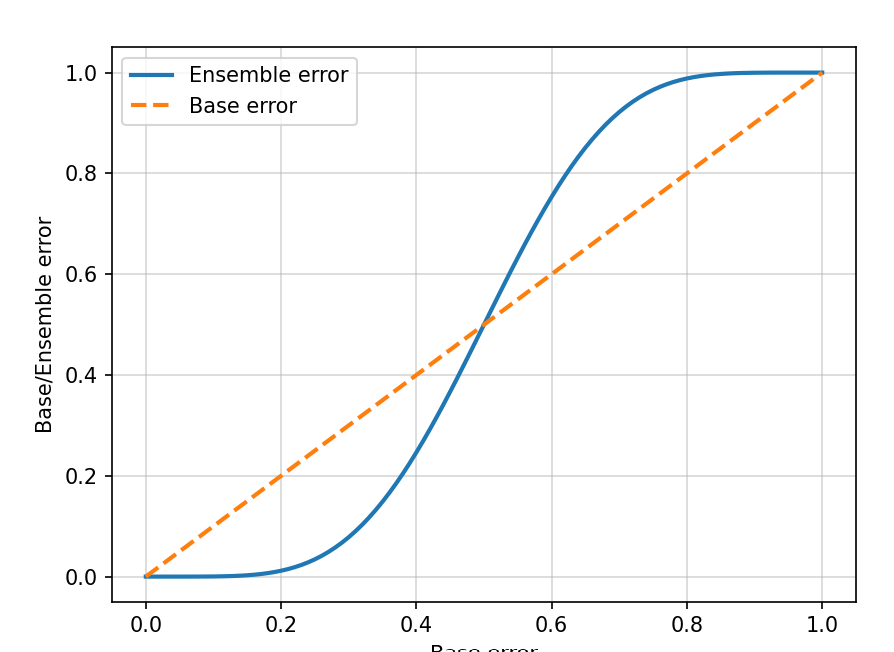
➡️ 앙상블의 에러 확률은 개별 분류기보다 항상 좋음
7.2 다수결 투표를 사용한 분류 앙상블
7.2.1 간단한 다수결 투표 분류기 구현
📍목표📍
-> 특정 데이터셋에서 개별 분류기의 약점을 보완하는 강력한 메타 분류기를 구축
☑️가중치가 적용된 다수결 투표를 파이썬 코드로 구현☑️
- argmax & bicount 함수 : 가중치가 적용된 다수결 투표 구현 가능하게
import numpy as np
np.argmax(np.bincount([0, 0, 1],
weights=[0.2, 0.2, 0.6]))☑️클래스 확률 기반으로 가중치가 적용된 다수결 투표 구현☑️
- average 함수 : weights 매개변수가 주어지면 weights 배열의 비율을 더할 원소에 곱해 가중 평균을 구함
ex = np.array([[0.9, 0.1],
[0.8, 0.2],
[0.4, 0.6]])
p = np.average(ex,
axis=0,
weights=[0.2, 0.2, 0.6])
np.argmax(p) # 0☑️MajorityVoteClassifer 파이썬 클래스 구현☑️
- get_params 메서드 : 분류기의 매개변수를 반환
- set_params 메서드 : 분류기의 매개변수를 설정
- score 메서드 : 예측 정확도를 계산
from sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.preprocessing import LabelEncoder
from sklearn.base import clone
from sklearn.pipeline import _name_estimators
import numpy as np
import operator
class MajorityVoteClassifier(BaseEstimator,
ClassifierMixin):
"""다수결 투표 앙상블 분류기
매개변수
----------
classifiers : 배열 타입, 크기 = [n_classifiers]
앙상블에 사용할 분류기
vote : str, {'classlabel', 'probability'}
기본값: 'classlabel'
'classlabel'이면 예측은 다수인 클래스 레이블의 인덱스가 됩니다
'probability'면 확률 합이 가장 큰 인덱스로
클래스 레이블을 예측합니다(보정된 분류기에 추천합니다)
weights : 배열 타입, 크기 = [n_classifiers]
선택 사항, 기본값: None
'int' 또는 'float' 값의 리스트가 주어지면 분류기가 이 중요도로 가중치됩니다
'weights=None'이면 동일하게 취급합니다
"""
def __init__(self, classifiers, vote='classlabel', weights=None):
self.classifiers = classifiers
self.named_classifiers = {key: value for key, value
in _name_estimators(classifiers)}
self.vote = vote
self.weights = weights
def fit(self, X, y):
"""분류기를 학습합니다
매개변수
----------
X : {배열 타입, 희소 행렬},
크기 = [n_samples, n_features]
훈련 샘플 행렬
y : 배열 타입, 크기 = [n_samples]
타깃 클래스 레이블 벡터
반환값
-------
self : 객체
"""
if self.vote not in ('probability', 'classlabel'):
raise ValueError("vote는 'probability' 또는 'classlabel'이어야 합니다"
"; (vote=%r)이 입력되었습니다."
% self.vote)
if self.weights and len(self.weights) != len(self.classifiers):
raise ValueError('분류기와 가중치 개수는 같아야 합니다'
'; 가중치 %d 개, 분류기 %d 개'
% (len(self.weights), len(self.classifiers)))
# self.predict 메서드에서 np.argmax를 호출할 때
# 클래스 레이블이 0부터 시작되어야 하므로 LabelEncoder를 사용합니다
self.lablenc_ = LabelEncoder()
self.lablenc_.fit(y)
self.classes_ = self.lablenc_.classes_
self.classifiers_ = []
for clf in self.classifiers:
fitted_clf = clone(clf).fit(X, self.lablenc_.transform(y))
self.classifiers_.append(fitted_clf)
return self☑️predict 메서드 만들기☑️
- predict_proba 메서드 : 평균 확률을 반환
- _name_estimators 함수 : 앙상블에 있는 각 분류기의 매개변수에 접근하기 위함
def predict(self, X):
"""X에 대한 클래스 레이블을 예측합니다
매개변수
----------
X : {배열 타입, 희소 행렬},
크기 = [n_samples, n_features]
샘플 데이터 행렬
반환값
----------
maj_vote : 배열 타입, 크기 = [n_samples]
예측된 클래스 레이블
"""
if self.vote == 'probability':
maj_vote = np.argmax(self.predict_proba(X), axis=1)
else: # 'classlabel' 투표
# clf.predict 메서드를 사용하여 결과를 모읍니다
predictions = np.asarray([clf.predict(X)
for clf in self.classifiers_]).T
maj_vote = np.apply_along_axis(
lambda x:
np.argmax(np.bincount(x,
weights=self.weights)),
axis=1,
arr=predictions)
maj_vote = self.lablenc_.inverse_transform(maj_vote)
return maj_vote
def predict_proba(self, X):
"""X에 대한 클래스 확률을 예측합니다
매개변수
----------
X : {배열 타입, 희소 행렬},
크기 = [n_samples, n_features]
n_samples는 샘플의 개수고 n_features는 특성의 개수인
샘플 데이터 행렬
반환값
----------
avg_proba : 배열 타입,
크기 = [n_samples, n_classes]
샘플마다 가중치가 적용된 클래스의 평균 확률
"""
probas = np.asarray([clf.predict_proba(X)
for clf in self.classifiers_])
avg_proba = np.average(probas, axis=0, weights=self.weights)
return avg_proba
def get_params(self, deep=True):
"""GridSearch를 위해 분류기의 매개변수 이름을 반환합니다"""
if not deep:
return super(MajorityVoteClassifier, self).get_params(deep=False)
else:
out = self.named_classifiers.copy()
for name, step in self.named_classifiers.items():
for key, value in step.get_params(deep=True).items():
out['%s__%s' % (name, key)] = value
return out7.2.2 다수결 투표 방식을 사용하여 예측 만들기
☑️테스트를 위한 데이터셋 준비☑️
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X, y = iris.data[50:, [1, 2]], iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)☑️붓꽃 데이터 샘플을 50:50으로 훈련 데이터와 테스트 데이터로 나누기☑️
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.5,
random_state=1,
stratify=y)☑️10-겹 교차 검증으로 성능 평가 후, 서로 다른 세 개의 분류기를 훈련☑️
- 로지스틱 회귀 분류기
- 결정 트리 분류기
- k-최근접 이웃 분류기
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
clf1 = LogisticRegression(penalty='l2',
C=0.001,
random_state=1)
clf2 = DecisionTreeClassifier(max_depth=1,
criterion='entropy',
random_state=0)
clf3 = KNeighborsClassifier(n_neighbors=1,
p=2,
metric='minkowski')
pipe1 = Pipeline([['sc', StandardScaler()],
['clf', clf1]])
pipe3 = Pipeline([['sc', StandardScaler()],
['clf', clf3]])
clf_labels = ['Logistic regression', 'Decision tree', 'KNN']
print('10-겹 교차 검증:\n')
for clf, label in zip([pipe1, clf2, pipe3], clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))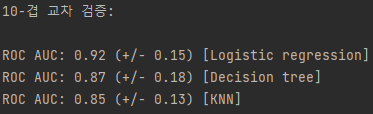
☑️다수결 투표 앙상블을 위해 MajorityVoteClassifier 클래스로 각 분류기를 하나로 연결☑️
mv_clf = MajorityVoteClassifier(classifiers=[pipe1, clf2, pipe3])
clf_labels += ['Majority voting']
all_clf = [pipe1, clf2, pipe3, mv_clf]
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))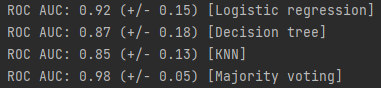
➡️ MajorityVoteClassifier의 성능이 개별 분류기보다 뛰어남
7.2.3 앙상블 분류기의 평가와 튜닝
테스트 데이터셋의 목적 : 편향되지 않은 분류기의 일반화 성능을 추정하기 위함(테스트 데이터셋은 모델 선택에 사용하지 않음)
☑️테스트 데이터셋에 대한 RCO 곡선 그리기☑️
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
colors = ['black', 'orange', 'blue', 'green']
linestyles = [':', '--', '-.', '-']
for clf, label, clr, ls \
in zip(all_clf,
clf_labels, colors, linestyles):
# 양성 클래스의 레이블이 1이라고 가정합니다
y_pred = clf.fit(X_train,
y_train).predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_true=y_test,
y_score=y_pred)
roc_auc = auc(x=fpr, y=tpr)
plt.plot(fpr, tpr,
color=clr,
linestyle=ls,
label='%s (auc = %0.2f)' % (label, roc_auc))
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1],
linestyle='--',
color='gray',
linewidth=2)
plt.xlim([-0.1, 1.1])
plt.ylim([-0.1, 1.1])
plt.grid(alpha=0.5)
plt.xlabel('False positive rate (FPR)')
plt.ylabel('True positive rate (TPR)')
plt.show()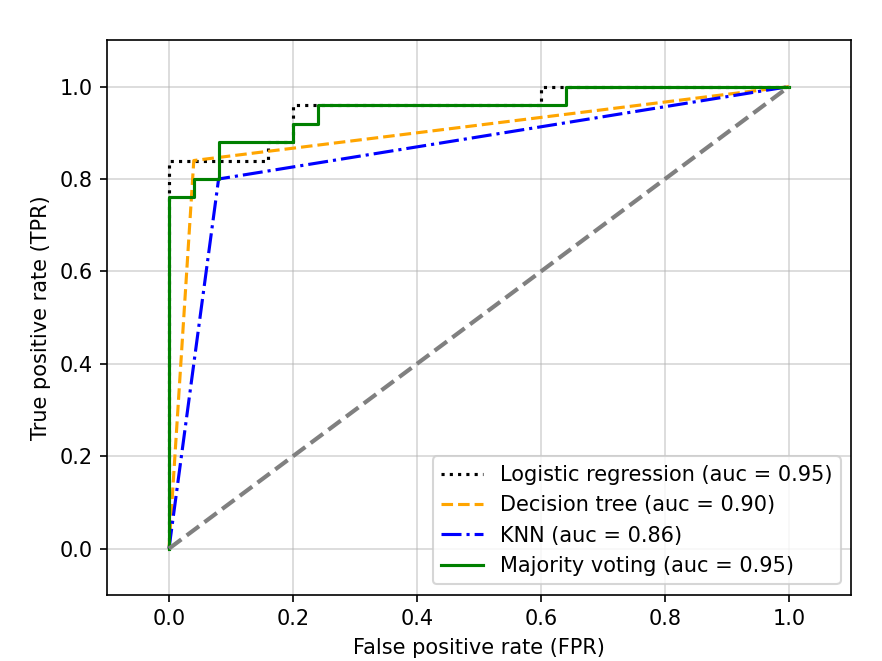
➡️ 앙상블 분류기는 테스트 데이터셋에서도 좋은 성능을 냄(ROC AUC=0.95)
☑️앙상블의 결정 경계 확인☑️
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
from itertools import product
all_clf = [pipe1, clf2, pipe3, mv_clf]
x_min = X_train_std[:, 0].min() - 1
x_max = X_train_std[:, 0].max() + 1
y_min = X_train_std[:, 1].min() - 1
y_max = X_train_std[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=2, ncols=2,
sharex='col',
sharey='row',
figsize=(7, 5))
for idx, clf, tt in zip(product([0, 1], [0, 1]),
all_clf, clf_labels):
clf.fit(X_train_std, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.3)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train == 0, 0],
X_train_std[y_train == 0, 1],
c='blue',
marker='^',
s=50)
axarr[idx[0], idx[1]].scatter(X_train_std[y_train == 1, 0],
X_train_std[y_train == 1, 1],
c='green',
marker='o',
s=50)
axarr[idx[0], idx[1]].set_title(tt)
plt.text(-3.5, -5.,
s='Sepal width [standardized]',
ha='center', va='center', fontsize=12)
plt.text(-12.5, 4.5,
s='Petal length [standardized]',
ha='center', va='center',
fontsize=12, rotation=90)
plt.show()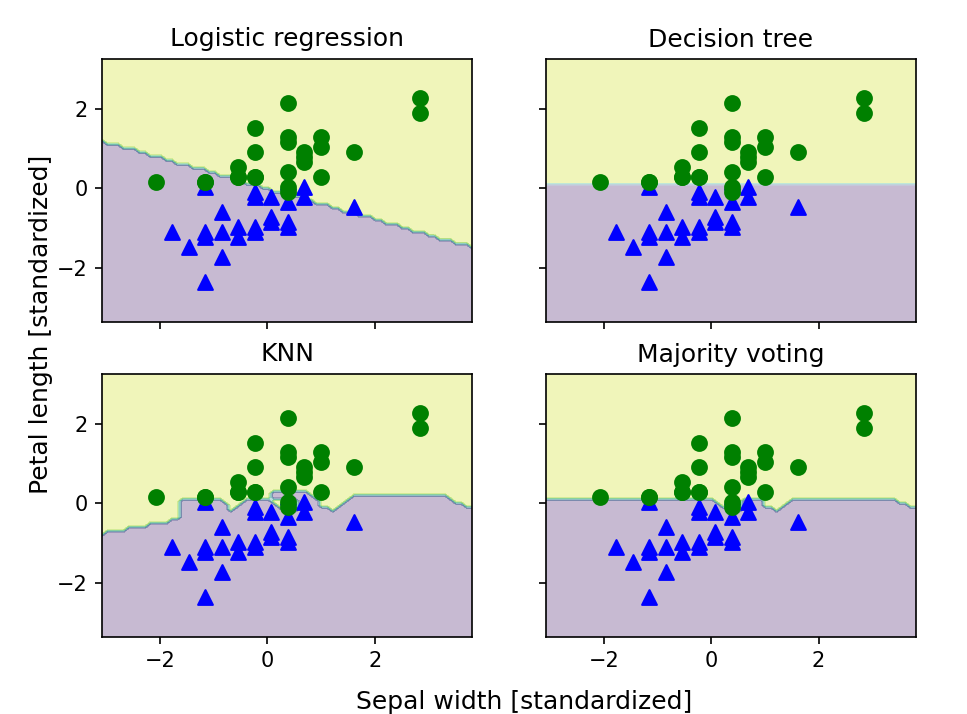
➡️앙상블 분류기의 결정 경계는 개별 분류기의 결정 경계를 혼합한 것처럼 보임
☑️GridSearchCV 객체 안에 있는 매개변수 접근☑️
mv_clf.get_params()☑️그리드 서치로 로지스틱 회귀 분류기의 규제 매개변수 C와 결정 트리의 깊이를 튜닝☑️
from sklearn.model_selection import GridSearchCV
params = {'decisiontreeclassifier__max_depth': [1, 2],
'pipeline-1__clf__C': [0.001, 0.1, 100.0]}
grid = GridSearchCV(estimator=mv_clf,
param_grid=params,
cv=10,
scoring='roc_auc')
grid.fit(X_train, y_train)☑️그리드 서치 실행이 완료되면 평균 ROC AUC 점수 출력☑️
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_['mean_test_score'][r],
grid.cv_results_['std_test_score'][r] / 2.0,
grid.cv_results_['params'][r]))
print('최적의 매개변수: %s' % grid.best_params_)
print('정확도: %.2f' % grid.best_score_)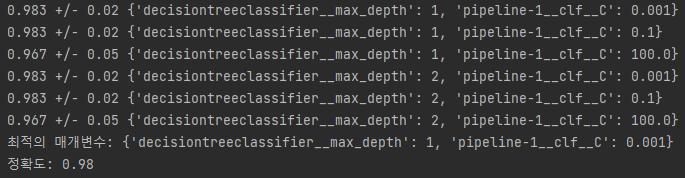
➡️규제 매개변수가 가장 낮을 때(C=0.001) 최상의 교차 검증 결과를 얻음
➡️트리 깊이는 성능에 영향을 주지 않음
7.3 배깅: 부트스트랩 샘플링을 통한 분류 앙상블
배깅 : 앙상블에 있는 개별 분류기를 동일한 훈련 데이터셋으로 학습하는 것이 아니라, 원본 훈련 데이터셋에서 부트스트랩 샘플(중복을 허용한 랜덤 샘플)을 뽑아서 사용
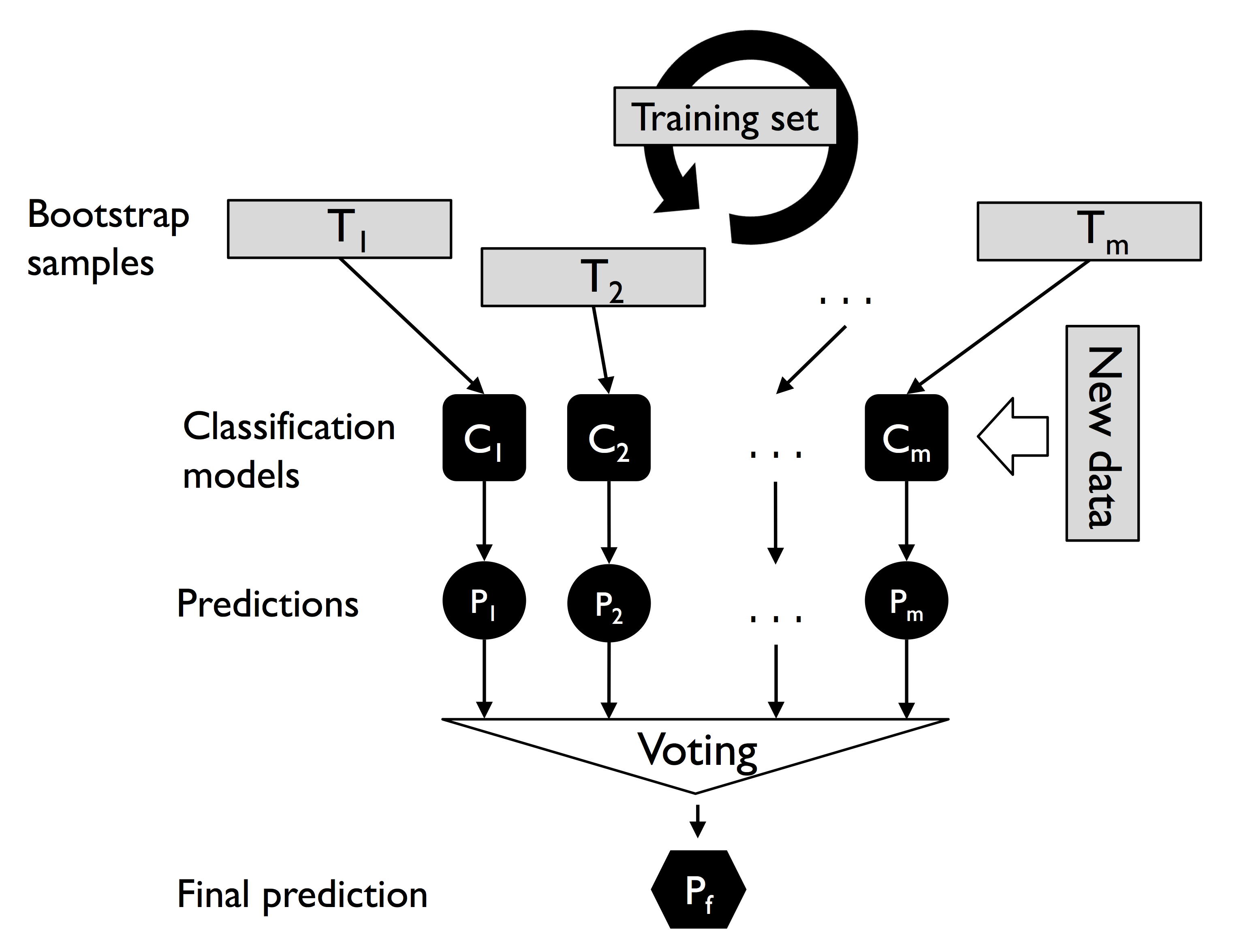
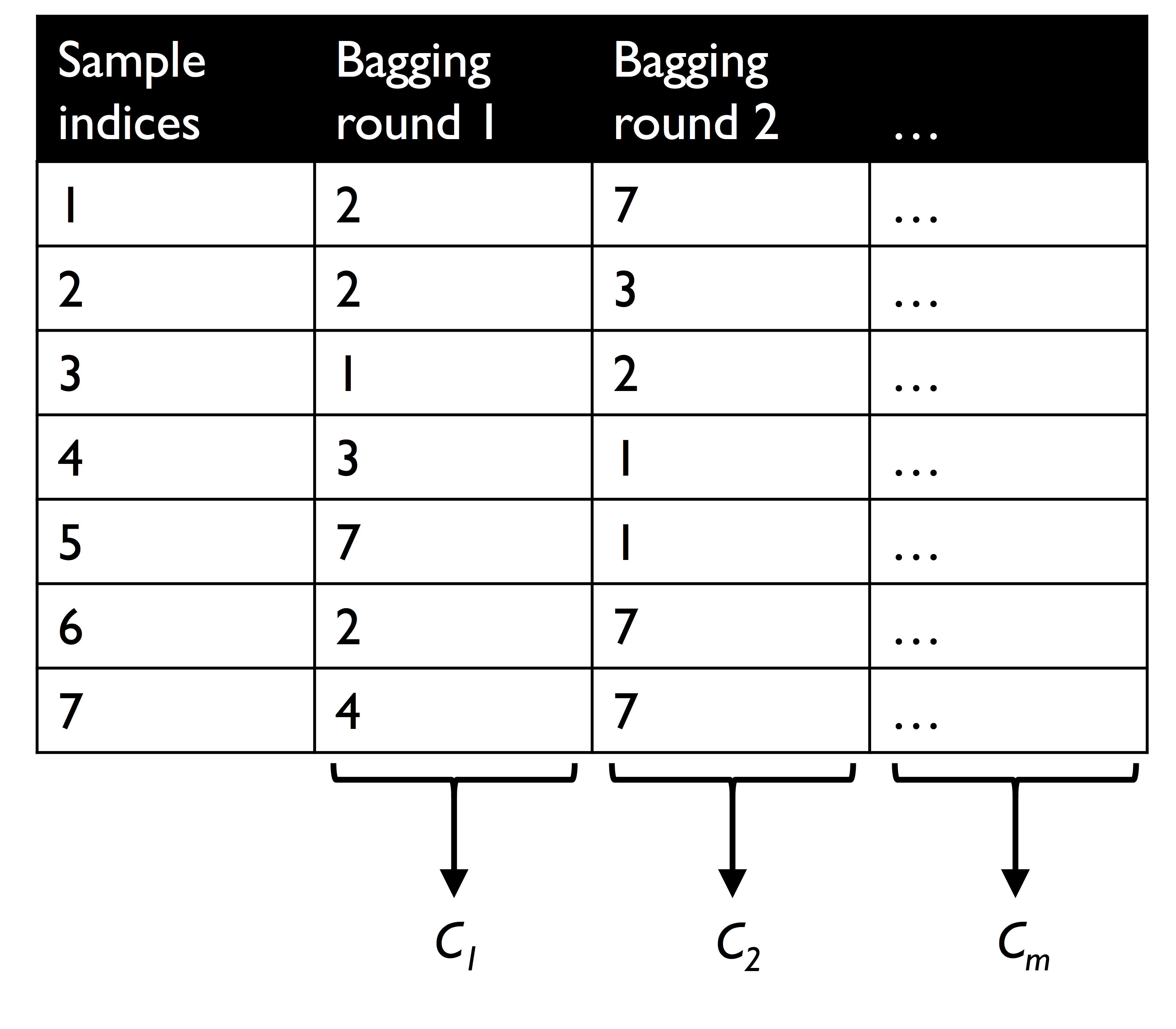
7.3.1 배깅 알고리즘의 작동 방식
1) 1에서 7까지 인덱스가 부여된 일곱 개의 훈련 샘플이 있음
2) 배깅 단계 마다 중복을 허용하여 랜덤하게 샘플링됨
3) 각각의 부트스트랩 샘플을 사용하여 분류기를 학습함 (분류기는 일반적으로 가지치기하지 않는 결정트리를 사용)
4) 개별 분류기가 부트스트랩 샘플에 학습되고 나면 다수결 투표를 사용하여 예측을 모음
7.3.2 배깅으로 Wine 데이터셋의 샘플 분류
☑️Wine 데이터셋 가져오기☑️
import pandas as pd
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/wine/wine.data',
header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
# 클래스 1 제외
df_wine = df_wine[df_wine['Class label'] != 1]
y = df_wine['Class label'].values
X = df_wine[['Alcohol', 'OD280/OD315 of diluted wines']].values☑️클래스 레이블을 이진 형태로 인코딩하고 80%는 훈련 데이터셋으로, 20%는 테스트 데이터셋으로 분리☑️
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.2,
random_state=1,
stratify=y)☑️500개의 결정 트리로 구성된 BagginClassifier 앙상블 만들기☑️
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=None,
random_state=1)
bag = BaggingClassifier(base_estimator=tree,
n_estimators=500,
max_samples=1.0,
max_features=1.0,
bootstrap=True,
bootstrap_features=False,
n_jobs=1,
random_state=1)☑️배깅 분류기와 가지치기가 없는 단일 결정 트리에서 훈련 데이터셋과 테스트 데이터셋의 예측 정확도를 계산하여 성능 비교☑️
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('결정 트리의 훈련 정확도/테스트 정확도 %.3f/%.3f'
% (tree_train, tree_test))
bag = bag.fit(X_train, y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train, y_train_pred)
bag_test = accuracy_score(y_test, y_test_pred)
print('배깅의 훈련 정확도/테스트 정확도 %.3f/%.3f'
% (bag_train, bag_test))
➡️ 훈련 정확도가 훈련 데이터셋에서 비슷하지만 테스트 데이터셋의 정확도로 미루어 보아 배깅 분류기가 일반화 성능이 더 나음
➡️ 결정 트리 테스트 정확도는 모델의 분산이 높은 과대적합을 나타냄
☑️결정 트리와 배깅 분류기의 결정 경계 비교☑️
import numpy as np
import matplotlib.pyplot as plt
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,
sharex='col',
sharey='row',
figsize=(8, 3))
for idx, clf, tt in zip([0, 1],
[tree, bag],
['Decision tree', 'Bagging']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train == 0, 0],
X_train[y_train == 0, 1],
c='blue', marker='^')
axarr[idx].scatter(X_train[y_train == 1, 0],
X_train[y_train == 1, 1],
c='green', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,
s='OD280/OD315 of diluted wines',
ha='center',
va='center',
fontsize=12,
transform=axarr[1].transAxes)
plt.show()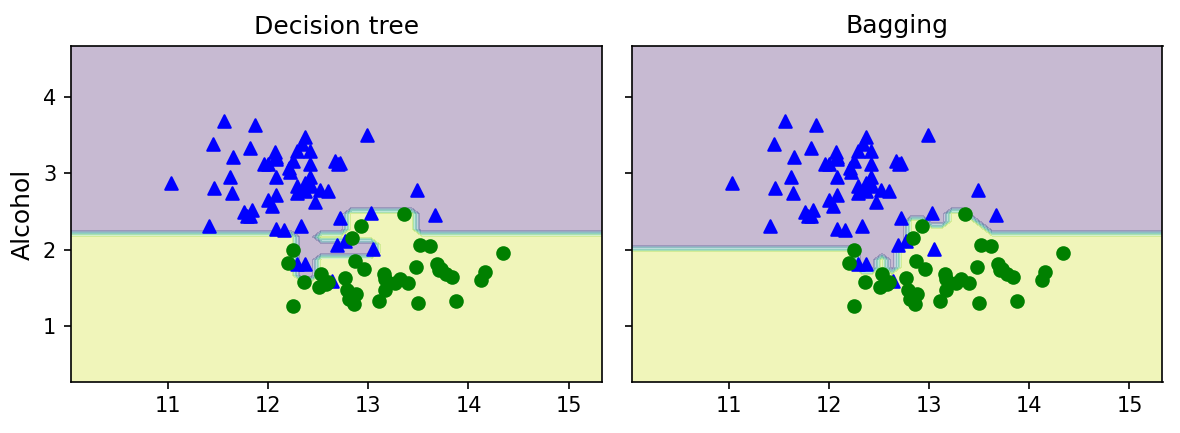
➡️ 결정 트리의 선형 결정 경계가 배깅 앙상블에서 더 부드러워짐
📍배깅 장점📍
- 실전에서 고차원 데이터셋을 사용하는 복잡한 분류 문제에서 단일 결정 트리가 쉽게 과대적합되는 문제 해결
📍배깅 단점📍
- 모델이 너무 단순해서 모델의 편향을 낮추고 데이터의 경향을 잘 잡아내지는 못함
7.4 약한 학습기를 이용한 에이다부스트
부스팅의 핵심 아이디어 : 잘못 분류된 훈련 샘플을 그다음 약한 학습기가 학습하여 앙상블 성능을 향상시킴
7.4.1 부스팅 작동 원리
📍원본 부스팅 과정📍
1) 훈련 데이터셋 D에서 중복을 허용하지 않고 랜덤한 부분 집합 d1을 뽑아 약한 학습기 C1을 훈련
2) 훈련 데이터셋에서 중복을 허용하지 않고 랜덤한 훈련 부분 집합 d2를 뽑고 이전에 잘못 분류된 샘플의 50%를 더해서 약한 학습기 C2를 훈련
3) 훈련 데이터셋 D에서 C1과 C2에서 잘못 분류한 훈련 샘플 d3을 찾아 세 번째 약한 학습기인 C3을 훈련
4) 약한 학습기 C1, C2, C3를 다수결 투표로 연결
📍장점📍
-> 배깅 모델에 비해 분산은 물론 편향도 감소시킬 수 있음
-> but, 실제로는 훈련 데이터에 과대적합되는 경향 있음(분산이 높음)
📍에이다 부스트 과정📍
1) 가중치 벡터 w를 동일한 가중치로 설정
2) m번 부스팅 반복의 j번째에서 다음을 수행
- 가중치가 부여된 약한 학습기를 훈련함
- 클래스 레이블을 예측함
- 가중치가 적용된 에러율 을 계산
- 학습기 가중치를 계산
- 가중치를 업데이트함
- 합이 1이 되도록 가주치를 정규화함
3) 최종 예측을 계산
7.4.2 사이킷런에서 에이다부스트 사용
☑️깊이가 1인 결정 트리 500개로 구성된 AdaBoostClassifier를 훈련시키기☑️
from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=1,
random_state=1)
ada = AdaBoostClassifier(base_estimator=tree,
n_estimators=500,
learning_rate=0.1,
random_state=1)
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('결정 트리의 훈련 정확도/테스트 정확도 %.3f/%.3f'
% (tree_train, tree_test))
ada = ada.fit(X_train, y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train, y_train_pred)
ada_test = accuracy_score(y_test, y_test_pred)
print('에이다부스트의 훈련 정확도/테스트 정확도 %.3f/%.3f'
% (ada_train, ada_test))
➡️깊이가 1인 결정 트리는 훈련 데이터에 과소적합됨
➡️에이다부스트 모델은 훈련 데이터셋의 모든 클래스 레이블을 정확하게 예측하고 결정트리에 비해 테스트 데이터셋 성능도 좀 더 높음
☑️결정 영역 확인☑️
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(1, 2, sharex='col', sharey='row', figsize=(8, 3))
for idx, clf, tt in zip([0, 1],
[tree, ada],
['Decision tree', 'AdaBoost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train == 0, 0],
X_train[y_train == 0, 1],
c='blue', marker='^')
axarr[idx].scatter(X_train[y_train == 1, 0],
X_train[y_train == 1, 1],
c='green', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,
s='OD280/OD315 of diluted wines',
ha='center',
va='center',
fontsize=12,
transform=axarr[1].transAxes)
plt.show()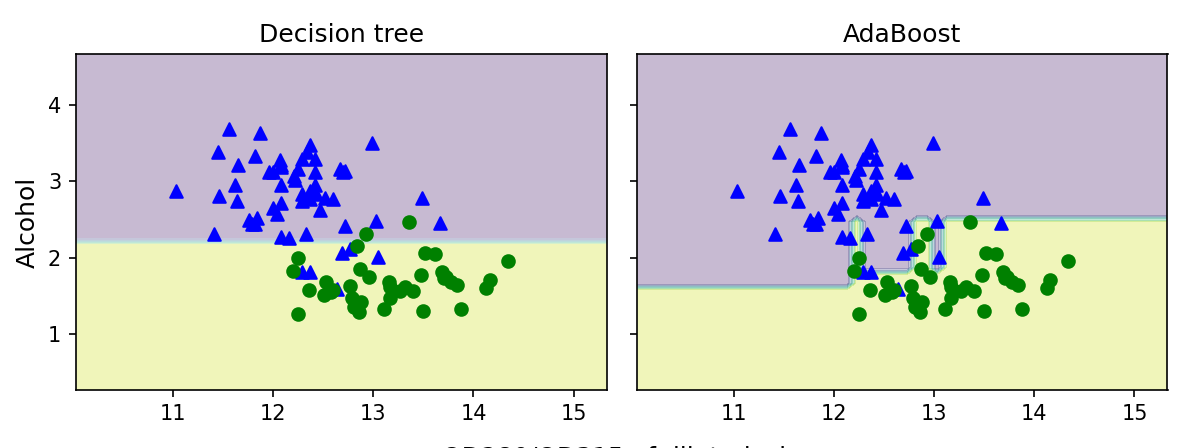
➡️에이다부스트 모델이 결정 트리의 결정 경계보다 더 복잡함
➡️에이다부스트 모델이 배깅 분류기와 매우 비슷하게 특성 공간을 분할
