[Distributed Systems] 분산처리에서 해결해야 할 challenges(issues)
Distributed Systems
이 블로그는 단국대학교 김승훈 교수님 수업을 토대로 작성되었습니다.
저작권 문제가 될 수 있는 강의자료는 되도록 지우고 작성하였습니다.
분산시스템에서 해결해야 할 challenges(Issues)
issue 1. Heterogeneity (이질성)
문제점 1) Networks
-다양한 종류의 인터넷 사용(wifi, bluetooth). 하지만 우리가 그런 것을 생각하지 말고 사양해야 함
⇒ 이것을 가능하게 하는 게 인터넷 프로토콜
-IP 프로토콜이 갖는 장점 : 계층 3에 위치하는 IP 프로토콜이 역할 해주면 그 위에는 4층 부터 7층 까지는 그 아래가 어떤 network가 왔는지 같은 것을 신경 쓸 필요 없음
문제점 2) Computer hardware
-정수는 보통 최소 2byte, 4byte 식으로 되어있기 때문에 byte가 메모리에 저장되는 순서를 말하는 big endian이나 little endian이 있게 됨. 이런 저장된 순서가 컴퓨터 CPU 구조에 따라 다르기 때문에 network을 통해서 보낼 때 문제가 될 수 있음
문제점 3) Operating systems
-OS가 다르면 system call이나 API가 다르게 됨
문제점 4) Programming languages
-리눅스 환경에서 C로 구현했다고 하면 client는 windows 환경에서 JAVA로 구현이 됐다면, JAVA와 C 간의 통신이 일어나게 됨. 프로그램 언어끼리 통신이 일어나는 것 X
(프로그램도 결국 machine language로 바꿔야 하고 JAVA도 machine 코드로 바뀌어야 하기 때문에 어떤 language로 구현되었다는 것이 중요하지 않다)
문제점 5) implementations by different developers
-개발자에 따라 다르게 됨. network을 주고 받는 communication의 프로토콜이 다르게 되는데 그때 주고받는 방식이 다르고 그 데이터에 대한 표현 방법이 다르게 됨
해결방법 1) middleware
-아래 계층은 다 다른데 위에는 uniform한 interface를 요구하게 됨. 다른 것들을 고려하기 힘들기 때문에 heterogeneity를 감춰야 함. 감추고 우리가 원하는 추상화(abstraction)을 이루어서 uniform한 추상화적인 프로그래밍 interface를 제공하게 하는 것 ⇒ middle ware
-대표적인 middleware :
-Common Object Request Broker (CORBA)
-Java Remote Method Invocation (RMI)
해결방법 2) mobile code
-코드 자체를 한 컴퓨터에서 다른 컴퓨터로 이동 시켜서 실행
-Java applet, JavaScript
issue 2. Openess
-시스템을 다양한 방식으로 확장성(extended, 덧붙임), 재구현(reimplemented)할 수 있는지 여부를 결정하는 특성
장점: 확장성
특성
→ 예) 마이크로소프트사에서 plug and play 개념→ Interface만 정해시 공표를 하고나면 거기에 해당하는 소프트웨어 회사나 하드웨어 회사들이 이런 Interface에 근거를 해서 뭔가를 개발하면 Windows운영체제에서 그대로 돌아간다는 개념
issue 3. Security
1) confidentiality
→ 비인가된 사용자(권한이 없는 사용자)들이 사용하는 것을 막자
-protection against disclosure to unauthorized individuals
-ID 같은 걸 통해서 사용자의 identity 체크
2) integrity
→ 그 내용에 손상이 가지 말아야 함: 내용 변조의 문제
-누가 들어와서 그 내용을 고친다던가 망가뜨리는 것 (alteration or corruption)
-encryption technique: 저장하거나 통신을 하게 될 때는 그 데이터를 그대로 사용하면 안됨⇒ 그래서 encryption이 꼭 따라 나오게 됨
3) availability
→ 가용성
-protection against interference with the means to access the resources
-Denial of service(DoS) attacks:wish to disrupt a service for some reason
→ DoS 공격한다고 해서 자신에게 이득 X. 그러나 그 서비스를 제공하는 측에서는 타격, availability가 떨어지게 됨
firewall
→ intranet. 한 조직에서 사용하는 network ⇒ 장벽을 세우고 데이터가 들락날락 할 때만 control하면 됨 ⇒ 전제: firewall 바깥에서 (intranet 밖에서 불순한 의도를 갖고있는 것을 막겠다는 것)
security of mobile code
→ 모바일 코드에 대한 문제
-바이러스에 감염되기 쉬운 email에 첨부되어 있는 어떠한 바이러스성 프로그램을 실행하다 보면 바이러스에 감염되는 대표적(electronic mail attachment)
issue 4. Scalability
-A system is described as scalable if it will remain effective when there is a significant increase in the number of resources and the number of users.
→ HW, SW 수를 늘리는 이유: client 수들이 늘어나니까 거기에 맞춰서
-이렇게 늘어났을 때도 여전히 효과적으로 동작할 수 있으면 이 시스템은 scalability 있다
-서버들을 증가 시키더라도 더 이상 performance가 늘어나지 않을 때, scalability 없다
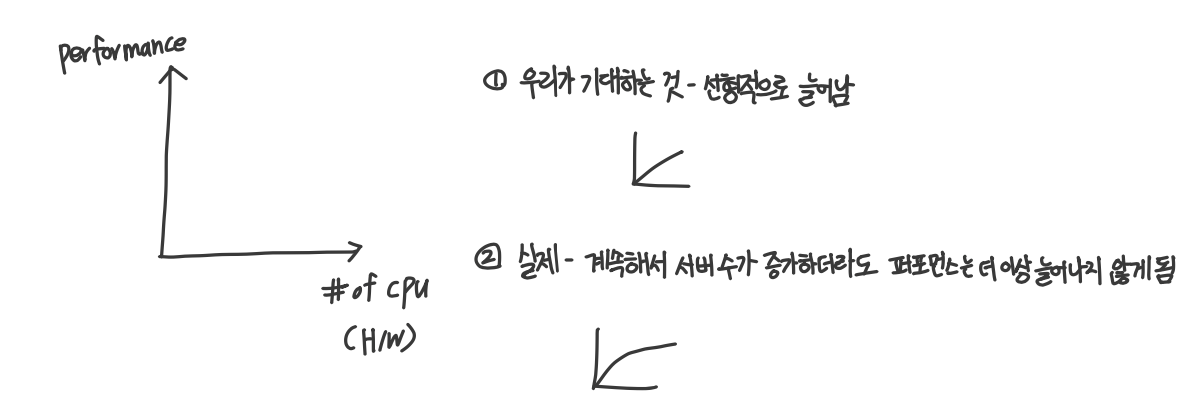
목표: scalable한 분산시스템을 설계하는 것
-
Controlling the cost of physical resources
→ 시스템이 늘어나면 cost가 늘어남
-
Controlling the performance loss
→ linear한 건 효율이 떨어짐
-
Preventing software resources running out
→ 시스템이 얼마나 대형화 될지 개발하는 입자에서 미리알 수 없음
-
Avoiding performance bottlenecks – load balancing
→ 알고리즘도 분산 알고리즘이 되어야 함 (학교에서 배운 알고리즘은 한 컴퓨터에서 돌아가는 알고리즘 전제, MM에 데이터가 있다는 전제)
issue 5. Failure handling
-faults 발생 시
-incorrect한 results를 생성하거나
-실행하다가 stop해주면 제일 좋음
-partial : 분산 시스템에서 failure의 문제-일부는 실행하다가 일부는 실행하지 않고..
-고장 난다고 해도 다른 component들은 여전히 돌아감. 고장이 나면 실행을 안하고 고장 나는게 제일 좋음
결함대처 1) Detecting failures
:고장 발견
-손상된 데이터(corrupted data)를 감지하기 위한 checksums; 인터넷에서 원격 충돌 서버와 같은 다른 오류를 감지하기 어려움
결함대처 2) Masking failures
:고장 감춤 (hidden or made less severe)
-Messages can be retransmitted → 재전송
-File data can be written to a pair of disks → 중복해서 저장
결함대처 3) Tolerating failures
:고장 나더라도 어느정도 허용하면서 돌아가는
결함대처 4) Recovery from failurres
-HW와 data를 다루는 부분이 고장났을 때 데이터가 원래대로 돌아갈 수 있게끔 rolled back 필요
-오류가 발생하면 계산이 불완전하고 업데이트 되는 영구 데이터가 일관된 상태가 아닐 수 있음(inconsistent 상태에 있으면 안됨)
결함대처 5) Redundancy
- Tolerate failures by the use of redundant components
-multiple routes in network – multiple disjoint paths
→ 네트워크도 redundant 해야 함-다양한 paths. disjoint해야 의미 있음
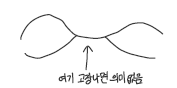
-The design of effective techniques for keeping replicas of rapidly changing data up-to-date without excessive loss of performance is a challenge
availability
→ 전체 시간을 1로 봤을 때, 그 중에 몇 %를 사용할 수 있는가 (100%가 정상)
-사용하고자 할 때에 사용 시간에 대한 비율(100%가 목표)
-분산시스템은 높은 수준의 availability를 제공
issue 6. Concurrency v
- 여러 client들이 동시에 처리되도록 허용 -여러 client가 동시에 shared resource에 access를 시도하여 일관성 없는 결과를 생성(producing inconsistent result) -Race condition
- object가 concurrent environment에서 안전하려면, 데이터가 일관되게(consistent) 유지되는 방식으로 작업이 동기화(synchronized) 되어야 함
-**semaphores** 같은 기술로 달성
→ *OS 배울 때
공유되는 데이터에 발생하는 문제
-공유되는 데이터에 마지막으로 접근을 해서 거기다 write를했다. update했다에 따라 결과가 달라지는현상 ⇒ synchronization 문제
-공유되는 데이터를 프로세서들이 마구 접근해서 쓰게하면 안됨 ⇒ 항상 consistent하게, synchronized된 방법으로 쓸 수 있게끔 관리, 감독 해야 함. 그 테크닉 중에 대표적인게 semaphore
-분산시스템의 많은 테크닉들은 하나의 OS에서 다뤘던 내용을 분산 시스템으로 확장한 것이 대부분
-하나의 Machine 내에서 배웠던것 ⇒ OS내용
-확장. 한 Machine 이 아닌 여러 Machine 에서 다룰 때도 똑같이 semaphore라는 개념을 이용해서 해결 가능 ⇒ distributed semaphore
issue 7. Transparency v
-독립된 여러개 컴포넌트(collection of independent components)가 모였다는 것을 인식하면 안됨(그러면 분산 시스템 아님)
-'전체가 하나다(perceived as a whole). heterogeneity가 없다'는 식으로 느껴지는 것 ⇒ transparency
8가지 형태의 transparency
1) Access transparency
→ 접근할 때 local한지 remote해놓은건지 우리가 신경쓰지 말아야 함.
근처에 local 한건지 remote 한건지 access 할 때 transparent 하다면 access transparency가 있다- -enables local and remote resources to be accessed using identical operations, e.g, Distributed File Systems
2) Location transparency
→ IP 주소가 뭔지, 어느 건물에 있는지 이런 식의 physical한 그러한 주소. 이런 것에 대한 이해 없이 접근하면 location transparency가 있다 (예: URL, 한 서버 밑에 있는 file을 다른 쪽에 서버에 이동을 할 때 URl 사용 불가능)
- -enables resources to be accessed without knowledge of their physical or network location (for example, which building or IP address)
-URLs are location-transparent, but not mobility-transparent
1&2 ⇒ network transparency
3) Concurrency transparency
→ 나 혼자 사용하는 건지 여럿이서 동시에 사용하는 건지에 대해 느끼지 않고 써야 함
- -enables several processes to operate concurrently using shared resources without interference between them
4) Replication transparency
→ copy가 정확히 몇개가 있고 어디에 있는지에 대해서 모르고 사용했을 때
- enables multiple instances of resources to be used to increase reliability and performance without knowledge of the replicas by users or application programmers
5) Failure transparency
→ 고장이나도 우리가 모르고 사용할 때
- -enables the concealment of faults, allowing users and application programs to complete their tasks despite the failure of hardware or software components
6) Mobility transparency
→ resources, clients가 이동할 때도 여전히 끊어지지 않고
- -allows the movement of resources and clients within a system without affecting the operation of users or programs
7) Performance transparency
→ 재배치 등을 못느껴야 함
- -allows the system to be reconfigured to improve performance as loads vary
8) Scaling transparency
→ scale을 확장하기 위해 뭔가 고쳐야할 때 자연스럽게
- -allows the system and applications to expand in scale without change to the system structure or the application algorithms
issue 8. Quality of Service(QoS) v
-applications에 대한 서비스 요구 사항을 충족하는 시스템 기능
-그 achieve는 적절한 시간에 필요한 computing 및 network resources의 availability에 달려 있음
-시스템이 애플리케이션이 각 작업을 제 시간에 완료할 수 있도록 하기에 충분한 보장된 컴퓨팅 및 통신 리소스를 제공해야하는 요구사항
-QoS를 필요하는 application은 각 중요 resource를 reserved해야 함 ⇒ 원격진료, 원격수술
-Guaranteed service vs best-effort service
→ 항상 원하는 서비스를 보장해주는 서비스 vs network 상태에 따라 다르지만 최선을 다하는
