
이 시리즈의 목표는 중고등학생 수준으로 각종 논문을 읽어보고 이해하는 것에 있습니다. 이를 통하여 점진적으로 전문 용어와 개념에 익숙해지고자 합니다. 따라서 자세한 부분에서 틀린 부분이 있거나 전문적이지 않을 수 있습니다. 필요한 부분은 따로 더 집중적으로 다룰 예정입니다. 또한 영어-한국어의 번역이 매끄럽지 않을 수 있습니다. 영어적 표현에 익숙해지는 과정으로 보기를 바랍니다. 논문의 완전한 번역보다는 이해를 위한 발최 의역을 기본으로 합니다.
본론(Main)
알아야 할 간단한 정의
- 밀도 함수 이론(Density Functional Theory (DFT)): 원자, 분자, 고체의 전자 구조를 연구하기 위해 물리학 및 화학에서 사용되는 양자역학적 모델링 방법
- 그래프 신경망 (graph neural networks (GNNs)): 그래프 구조를 가진 데이터를 학습하는 신경망
내용
기존의 실험적인 방법으로 만들어진 데이터: Inorganic Crystal Structure Database (ICSD)[site]
밀도 함수 이론 (DFT)를 기반으로 한 접근법: Open Quantum Materials Database (OQMD) [site], AFLOWLIB [site], NOMAD[site]
데이터를 기반으로 한 방법은 좋은 성과를 거두었지만, 경쟁상(competing phases)에서 안정화된 볼록홀(convex hull)에서의 안정성을 예측하는 것에는 효과적이지 않았다.
graph networks for materials exploration (GNoME)에서 사용한 두가지 큰 방법
- 대칭 인식 부분 치환 (symmetry-aware partial substitutions (SAPS))과 무작위 구조 검색
- 그래프 신경망 (graph neural networks (GNNs))
다른 머신 러닝처럼 데이터의 양에 따라 예측성능이 거듭제곱 법칙처럼 향상됨을 관찰하였다.
모델 최종성능
- 까지 에너지를 예측
- 안정 예측 정밀도 개선
- 구조(structure)와 구성(composition)을 함께 사용하면 80% 이상
- 구성만 사용하면 100번의 시도당 33% 개선
- 기존 방법과 비교하면 1% 개선
- 발전된 일반화로, 훈련에 포함되지 않았음에도, 5개 이상의 요소들로 이루어진 구조를 예측
GNoME로 생성된 데이터세트는 다른 곳에서 활용이 가능하다.
생성 및 필터링 개요 (Overview of generation and filtration)
알아야 할 간단한 정의
- 증강(argment): 기존에 있는 정보에 새로운 정보를 추가하거나 기존의 정보를 변형하여 조금 더 우리가 원하는 형태로 바꾸는 것
- 테스트 시간 증강(test-time augmentation): 테스트 시간에 여러 데이터 증강을 사용, 여러 추론 결과를 결합(앙상블)한다.
- 동소체(polymorphs): 같은 원소로 이루어져 있지만, 모양과 성질이 다른 물질
- 상 (phases): 물질의 상태라고 생각하면 된다. 고체, 액체, 기체 등등이 있으며, 각종 환경(압력, 온도)에 따라 다양한 상이 존재한다.
- 앙상블(ensemble): 기계 학습(ML)에서는 다양한 모델을 사용 후 그 결과값들을 활용하는 경우를 말한다.
- 분해 에너지(decomposition energy): 물질을 구성 요소들(주로 원자들)까지 분해하는데 필요한 에너지. 간단하게, 물질을 만드는데 필요한 에너지라고 생각하면 된다.
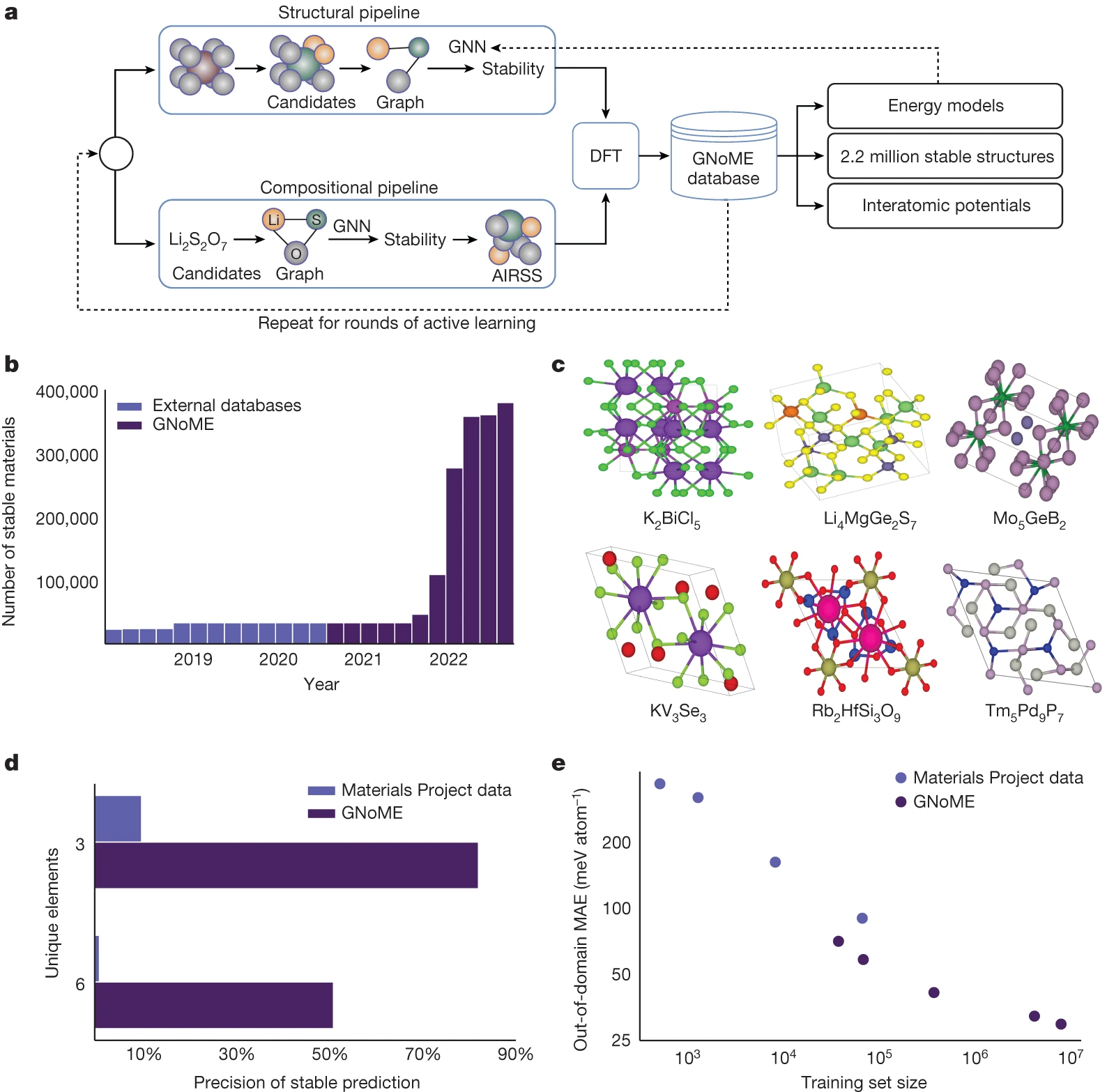
a. 기본적인 구조와 흐름
b. 발견된 안정적인 물질 수와 이전과의 비교
c. 736개의 실험적으로 검증된 안정적인 구조 중 6개
d. 훈련에는 최대 4개의 고유 요소가 포함되어 있지만, 모델은 6개의 고유 요소가 있는 물질을 발견하였다.
e. 무작위 구조 검색에서 전문 분야(domain)외의 임력에 대해 테스트를 했을때 어느정도 일반화된 성능을 보여주었습니다.
후보를 생성하고 필터링하기 위한 두가지 방법
- 사용 가능한 결정의 변형을 통한 생성
- 발견에 우선 순위를 부여한 이온 치환 확률을 조정하여 치환 세트를 증강(argment)
- 대칭 인식 부분 치환 (SAPS)를 사용하여 불완전한 치환을 효율적으로 작업
- 이를 통해 개의 후보를 생성함
- 후보를 부피 기반 테스트 시간 증강 (volume-based test-time augmentation)과 깊은 모델간 협업(앙상블)을 통해 불확실성을 정량화하고 이를 이용하여 필터링한다.
- 구조들을 무리지고(clustering-클러스터링) 동소체(polymorphs)을 순위매겨 DFT로 평가합니다.(나중에 방법에서 자세하게 봄)
- 구조적 정보 없이 구성 모델이 안정성을 예측함
- 입력은 환원 화학식 (reduced chemical formulas)을 사용
- 산화 상태 균형은 너무 엄격
- 완화된 제약조건과 GNoME를 사용하여 100개의 무작위 구조를 초기화함.
- ab initio random structure searching (AIRSS)를 사용하여 평가함.
두 방법 모두 에너지 예측을 한다. 임계값(threshold)은 경쟁 위상(competing phases)에 대한 상대적인 안정성(분해 에너지 decomposition energy)를 기준으로 선택한다.
Vienna Ab initio Simulation Package (VASP)의 DFT를 사용하여 평가를 한다. 발견된 안정적인 소재의 수와 예측된 안정적인 소재의 정밀도를 모두 특정한다.
