"Attention is All You Need" - 트랜스포머 구조의 이해
원래 글의 순서대로라면 NLP Tutorial에서 Transformer 챕터를 진행할 예정이나, 이 부분에 대해선 사전에 "Attention is All You Need" 논문을 읽고 시작하는게 좋을 것 같다는 생각이 들었다. 이미 너무나도 유명해서, 많은 사람들이 읽었으리라 생각하지만, 복습 차원에서 한번 더 보도록 하자.

사전 세 줄 요약
- 순환 신경망 및 합성곱 기반이 아닌 오직 Attention 매커니즘으롬나 구성된 트랜스포머 모델 제안
- RNN에서 길어지는 시퀀스로 인해 발생하는 장거리 의존성(Long-term dependency) 문제를 Self-Attetion 매커니즘으로 극복
- 여러 개의 어텐션을 병렬로 수행하는 Multi-Head Attention 구조 도입을 통해 다양한 과넞ㅁ 혹은 위치에서 정보를 통합적으로 파악
Background
이 논문을 이해하려면 왜 트랜스포머(Transformer)가 등장해야 했는지 그 배경을 간단히 알아보고 논문으로 넘어가자.
- 시퀀스(Sequence) : 순서가 중요한 데이터, 즉 문장 및 단어들
- RNN/LSTM은 '순차적'이다.
- RNN은 시퀀스를 처리할 때 기본적으로 한 단어씩 순서대로 넣는다. 순차적이기에 느리고 병렬화가 어렵다. RNN은 기본적으로 현재 시점 의 Hidden state를 알아내지 위해선 이전 상태가 필요하다. 즉, 긴 시퀀스일수록 병렬로 돌릴 수 없고 계산 비용은 기하급수적으로 커진다.
- '장거리 의존성' 학습이 어렵다.
- 시퀀스에서 멀리 떨어진 위치끼리 연결되기 위해선 많은 단계가 필요하고 결국 신호는 약해진다.
- CNN도 완벽한 해법은 아니었음.
-
합성곱은 한 번에 병렬 계산을 수행할 수 있지만, 두 위치를 잘 매칭하려면 결국 깊은 여러 층을 거쳐야했고 계산량이 커졌음.
What is Attention ?
특정 단어(토큰)을 해석할 때, 문장 안의 다른 모든 단어들을 '참조'하는 매커니즘으로 보면 된다. 예를 들어,
"I went to the bank to deposit money."
여기서 bank는 단어 뜻만 보자면 강둑이 될 수도, 은행이 될 수도 있다. 사람은 이 bank가 financial bank인지 주변 단어들을 보고 연결하여 이해한다.
그럼 여기서 좀 더 자세히, 사람이 이 과정을 어떻게 수행했는지 생각해보자.
- (Question) bank가 무신 의미인지 알기 위해 추가적인 단어(혹은 문장이 필요하다)
- (Key) deposit은 예금하다라는 단어이다.
- (Key) money는 돈이라는 단어이다.
- (Key) (여기엔 없지만 엄청 뒤에 있다고 생각하자.) river는 강이라는 뜻의 단어이다
그리고 우리는 평소에 bank-deposit-money 관계를 인생을 살아오면서 수없이 마주했다. 즉 우리는 자체적으로 bank와 deposit, money가 연관성이 높다는 것을 알 수 있다.
반면 river bank 가 deposit, money와 관계가 있는걸 많이 보았는가?
이 과정이 사실은 Attention 알고리즘 그 자체이다.
다시 돌아가서 수식과 함께 살펴보자. Attention 알고리즘의 목표는 다음과 같다.
"현재의 토큰(Query, Q)이 문맥 전체에서 중요한 토큰들 (Key, K)을 골라 정보를 가중합으로 모아오기"
Query (Q) : "이거랑 연관되는 키들을 뭐야?"
Key (K) : "난 이런 의미를 갖는 토큰이야."
Value (V) : "실제는 이러한 정보를 가지는 토큰이야"
를 가지고 Scaled Dot-Product Attetion 수식을 따라
여기서 은 찾고 싶은 단서와 제공하는 단서의 내적으로, 두 단어가 같은 방향을 공유하면 큰 값이 도출된다. 즉 유사도가 높다는 뜻이다.
그리고 , 의 차원 가 크면 내적 값이 커지면서 softmax가 포화되므로, 기술기 소실의 위험성이 있어 크기 유지를 위해 차원의 제곱근을 항상 나누어준다.
마지막으로 그 확률을 Value에 곱해 가중합을 결정한다. 이를 통해, 특정 토큰이나 단어를 이해함에 있어 중요한 단어와 중요하지 않은 단어를 구분하고 집중할 수 있게된다.
나는 본질이 SLAM & Perception Engineer기에, SLAM에 비유하자면,
Q = 로봇이 찾고 있는 랜드마크의 특징
K = 맵 안에 저장된 랜드마크의 특징
QK = 지금 관측이 특정 랜드마크와 얼마나 잘 맞는가
Softmax = 여러 랜드마크 중 가장 가능성이 높은 것을 선택하게 유도
V = 랜드마크의 실제 좌표나 속성
이렇게 정리할 수 있겠다.
이제 논문으로 들어가보자.
Introduction
“Recurrent neural networks, long short-term memory and gated recurrent neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation.”
“This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.”
“In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.”위에서 설명한대로, RNN 계열의 시퀀스 모델링/번역은 토큰 순서를 가지는 본질적 순차성 때문에 병렬화가 어렵고 문장의 길이가 길수록 전체 맥락을 유지하거나 찾기 어렵다는 단점이 있었다. 기존에도 Attention 모델이 있었지만, RNN과 함께 쓰였고 그 자체로만 사용은 쉽지 않았었다.
따라서 이 논문은, Transformer라는 순환이 아닌 오직 Attention 만으로 입-출력 간의 전역 의존성을 캐치한 모델을 제안하였고, 짧은 학습 시간만에 번역 SOTA(State of the art)에 도달하였음을 보였다.
Model Architecture

Transformer 구조는 전체적으로 인코더-디코더 구조를 따르며, 양쪽 모두 (Multi-Head) Self-Attention -> Position-wse FFN(FeedForward Network) 블록을 쌓은 형태를 보인다 (스택으로 사용한다고 명시되어 있다).
*FeedForward Network : 각 토큰 벡터의 MLP을 독립적으로 적용하는 것 각 토큰 표현을 가공하여 표현력을 높이는 역할
인코더에는 Multi-Head Self Attention과 Position-wse FFN 두 서브 레이어로 구성되며 서브레이어 뒤에 Residual + LayerNorm을 두고 있다. 출력 차원은 기본적으로 512로 명시되어 있다.
디코더에는 동일한 두 서브레이어에 대해 Encoder-Decoder Attention (Cross Attention)이 추가되어 있고, 미래 토큰을 보지 못하도록 마스크된 Self-Attention을 사용해 Auto-regressive 특성을 보장한다.
*Auto-regressive : 시퀀스에서는 앞에 있는 것들만 보고 다음을 예측해야함. 그 특성을 유지
Attention
Scaled Dot-Product Attention
위의 서론에서 이 내용을 이미 언급했다. 다시 요약하자면, 특정 토큰이 다른 토큰과 얼마나 관련 있는가 점수를 계산하는 과정을 다루고 있다.
Multi-Head Attention
"Multi-head attention consists of several attention layers running in parallel."
"Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions."어텐션 하나보다, 여러 개의 '작은 어텐션(Head)'을 병렬로 작동한 뒤 결과를 합치는 것이 더 효율적이다. 이렇게 하면 서로 다른 표현 하위 공간(Subspaces)에서, 서로 다른 위치 정보를 동시에 파악할 수 있다. 이를 통해, 단일 헤드로 평균만 내면 잃어버릴 디테일을 보완할 수 있게된다 (해상도 손실 방지). 또한, 헤드 차원을 나눠서 쓰므로, 헤드 수를 늘려도 총 FLOPs는 단일 대형 헤드와 유사하게 되어 계산 효율성이 유지된다.
이를 위해, 입력 , , 들을 헤드 수 만큼 서로 다른 가중치로 하위 공간으로 분배한다. 이러면 각 헤드 에 대해
헤드별 는 이렇게 될 것이고 여기서 , , 이고
이제 다시 각 헤드에 대해 Scaled Dot-Product Attention을 적용한다.
이후 연결(concat) 후 출력을 사영하여 모델 차원으로 돌려보낸다.
Application of Attention in out Model
전체 트랜스포머 구조에서 Attention이 어디서 어떻게 쓰이는지를 살펴보자.
Input Embedding + Positional Encoding
│
├── Self-Attention (Multi-Head)
│
└── Feed-Forward Network
Output Embedding + Positional Encoding
│
├── Masked Self-Attention (Multi-Head) ← 미래 정보 차단
├── Encoder–Decoder Attention (Multi-Head) ← 인코더 출력 참조
└── Feed-Forward Network
논문에서는 Attention을 세 가지 방식으로 적용하였다.
- Encoder-Decoder Attention
- 디코더 블록의 두 번째 sub-layer에서 사용.
- Query는 디코더의 이전 레이어 출력에서 오고, Key/Value는 인코더 출력에서 종합
- 디코더가 입력 시퀀스 전체를 바라보며 출력 단어를 생성할 때 입력과 Align
- Encoder Self-Attention
- 인코더 블록의 첫 번째 sub-layer에 위치
- 인코더의 각 위치(토큰)가, 인코더 입력 시퀀스의 모든 토큰을 바라봄.
- 입력 문장 안에서 장거리 의존성 포착 가능 및 모든 토큰이 서로를 병렬로 봄.
- Decoder Self-Attention (Masked)
-
디코더 블록 첫 번째 sub-layer
-
미래 단어를 못 보게 마스킹
-
Softmax 입력에서 미래 위치를 처리, 디코더가 현재와 과거가지만 보고 다음 단어를 예측하게 만듬. (Auto-regressive)
기존의 RNN 기반에 Attention을 섞은 방법은, 주로 인코더-디코더 사이에만 추가되는 방식을 채택했었고, 이는 Alignment를 잘하는 것에는 효과가 있었으나, 인코더 내부 및 디코더 내부는 여전히 순차적 계산이 적용되어 있었음.
Position-wise Feed-Forward Networks (FFN)
각 인코더와 디코더 블록에선 Self-Attention 다음 항상 FFN을 배치하였다. 이 FFN은 모든 위치에 대해 독립적으로, 그리고 같은 방식으로 적용되는 작은 신경망으로, 시퀀스 길이와 관계없이 각 단어 벡터를 별개로 변환하는 역할을 한다.
두 개의 선형 변환과 ReLU 활성화 함수로 이루어져있음을 확인할 수 있다.
이 구조는 요약하자면 특징(Feature, 임베딩 결과)을 강화하는 역할을 한다. 수식을 따라가 보면
1) 확장 : 를 로 더 넓은 공간(2048차원)으로 펼친다. 이 단계에서 모델을 다양한 기초 패턴 축들로 를 분해한다.
2) 게이팅 : 가 음수 성분을 날리며 양수를 통과시킴으로써, 중간 특징을 달리하는 마스킹 기능을 한다.
3) 압축 : 선택 혹은 증폭된 중간 특징들을 로 다시 512차원으로 재투영한다.
즉 잠재 특징을 다양히 생성하고 쓸 특징만 선택 혹은 증폭한 후 다시 골라진 특징만 출력 표현에 반영한다.
여기서 ReLU는 좌표별로 가 양수일 때만 그 채널을 통과시켜 가 된다. 결과 는 활성화된 채널 집합에 따라 서로 다른 선형 사상이 적용된 것과 동일하하다. 이는 곧 입력이 바뀌면 활성 채널이 달라지고 입력별로 최적화된 가중치 조합이 선택되는 셈으로, 특정 의미/문법/도메인 신호를 각각에 맞게 증폭해 준다.
결론적으로, Attention이 토큰들 사이 관계를 섞어 "문맥화된" 표현을 만든다면, FFN은 각 토큰 표현 내부를 비선형적으로 재가공 해주는 역할을 한다.
Embeddings and Softmax
본 논문에선 다른 시퀀스 변환 모델과 마찬가지로, 학습된 임베딩을 이용하여 입력 토큰과 출력 토큰을 차원 의 벡터로 변환한다. 또한 일반적인 학습된 선형 변환과 소프트맥스 함수를 사용하여 디코더 출력을 예측된 다음 토큰 확률로 변환한다. Transformer 모델에선, 두 임베딩 레이어와 이전 소프트맥스 선형 변환 간에 동일한 가중치 행렬을 공유하며 임베딩 레이어에선 이런 가중치에 을 곱한다.
Positional Encoding
Self-Attetion의 구조로 인해, Self-Attention은 RNN과 달리 시퀀스의 순서를 계속 가지고 있을 수 없다. 따라서, 순서 정보를 별도로 알아내야 한다.
이를 위해 트랜스포머 구조엔 Positional Encoding (PE)가 추가되었다.
각 위치(pos)에 대해, 같은 차원()의 벡터를 만들어, 입력 임베딩에 더한다. 즉 최종 입력은 단어 임베딩과 포지션 임베딩이 더하여 입력을 구성한다.
수식은 위와 같이, 짝수 차원엔 sin을 홀수 차원엔 cos을 이용하여 서로 다른 주파수로 위치를 부호화할 수 있게 하였다. 이 덕분에, 모델은 상대적 위치 관계를 선형적으로 계산할 수 있게 되었다.
-
참고, sin/cos의 조합만으로도 엄청난 크기의 시퀀스도 위치를 표현할 수 있음.
Why Self-Attention

Section 4에선 Self-Attention을 다른 구조와 비교하며 강점을 소개한다. 위 표의 내용을 따라가보자.
-
경로 길이 (Path Length)
문제 : 모델이 두 위치 사이 의존성을 학습하려면, 그 위치를 연결하는 경로 길이가 짧을수록 좋다.RNN은 만큼, CNN은 , Self-Attention은 의 길이를 가지며 장거리 의존성을 학습하기에 Self-Attention이 제일 효율적임을 알 수 있다.
-
계산 복잡도 (Computational Complexity per Layer)
Self-Attention :
RNN :
CNN :n이 매우 크면 CNN이 유리할 수 있으나, 웬만한 경우 Self-Attention의 계산량이 충분히 감당 가능한 수준
-
병렬화
RNN : 시퀀스 특성상 순차 계산이 필수이므로 병렬화 사실상 불가
CNN & Self-Attention : 시퀀스 전체를 병렬로 계산가능, 그러나 Self-Attention 구조가 병렬성에서 CNN보다 단순하고 효율적임.Training & Result
학습은 WMT'14 En-DE (450만 문장쌍)과 En-Fr (3600만) 데이터셋을 기반하며, 토큰화는 BPE 방법을 사용하였다. Optimzer는 Adam을 본 논문에선 채택하였다.
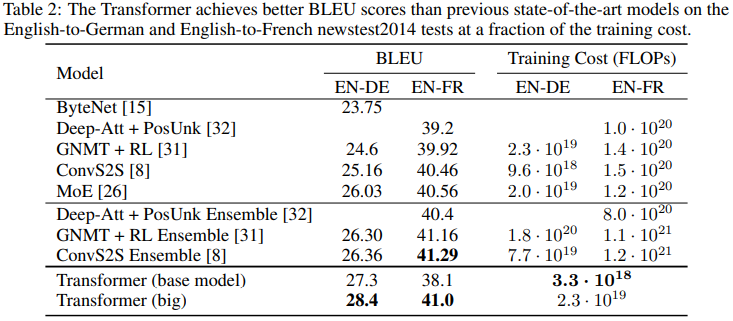
결과 표2는 WNT'14 En-De 번역에 있어 기존의 방법들보다 큰 폭으로 성능이 향상하였음을 보이며
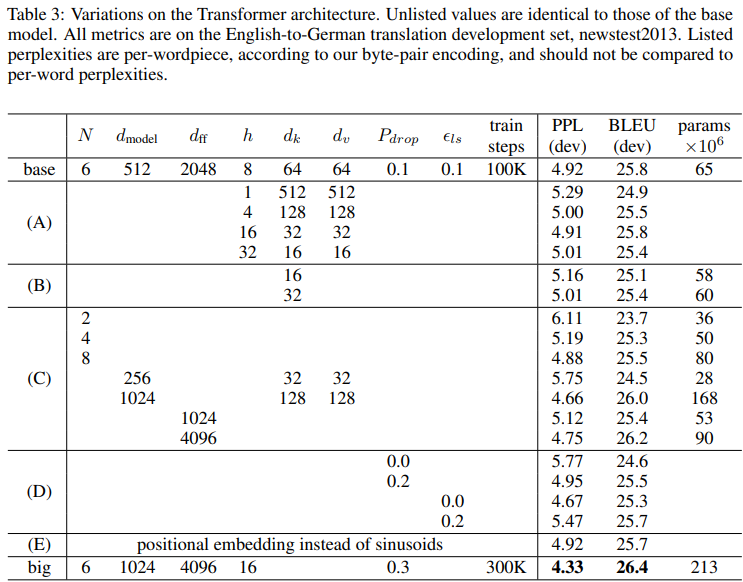
표 3은 하이퍼파라미터 변경에 따른 품질(BLEU), 난이도 (PPL), 파라미터 수에 어떤 영향을 미치는지 정리한 표로, 요약하자면 아래와 같다.
1) 헤드 수 & 헤드 차원 변화 : 싱글 헤드는 소폭 낮은 BLEU 스코어를 보이며 너무 많은 헤드도 품질이 존재함. 적정선이 존재
2) 키 차원 () 축소 : 줄일수록 품질이 감소함을 확인
3) 모델 깊이 변화 : 깊이와 폭이 크고 깊어질수록 대체로 좋으나 비용이 증가함.
4) 드롭아웃&라벨 스무딩 : 드롭아웃이 과적합 방지에 확실한 도움이 되며 라벨은 PPL은 약화, BLEU는 개선됨을 확인
5) Positional encoding : 학습에 큰 영향을 주지 않음
단 표에서 흥미로운 점은 멀티헤드의 적정 수가 h=8 전후가 제일 적정선이고 정규화 기법의 역할에서 두 정규화 방법 모두 BLEU 개선에 실질적인 기여를 함을 확인함.
Conclusion
본 논문은 순환 신경망이나 합성곱 신경망이 아닌 오직 Attention 기반의 Transformer 모델을 제안하였고, 이 아키텍쳐는 더욱 병렬화가 쉬운 구조 및 더 적은 시간에 학습이되며 기존 SOTA보다 더 좋은 번역 성능을 보였음. 논문에선 기계번역뿐만 아니라 다양한 시퀀스 처리 문제에 활용될 것으로 예견하고 있다.
+) 논문에서는 간단히 언급했지만, 사실 Transformer 구조는 언어를 넘어서 이미지, 음성, 심지어 로봇의 센서 시퀀스까지 일반화되고 있고, 이 논문은 현재 우리가 AI라고 부르는 것들의 대부분의 토대가 된 논문이다. 늦었지만, 얕게라도 이렇게 리뷰하며 읽어보는 것이 도움이 될 것이라 확신한다.
