
Buffered Reader와 Scanner
Java를 처음 시작하면서 입력을 받을 땐 항상 Scanner를 사용했다.
만약 정수를 하나 입력받는 다고 하면 다음과 같이 작성할 수 있다.
Scanner sc = new Scanner(System.in);
int i = sc.nextInt(); Scanner 클래스가 제공하는 여러 메서드들을 통해 정수 입력, 줄 단위 입력, 문자열 입력 등등 원하는 동작을 수행할 수 있다.
의문점
사실, Scanner만 사용했다면 궁금해하지도 않았을 의문점이 있다.
Java로 알고리즘 문제를 풀 때, 평소처럼 Scanner를 통해 입력을 받으면 시간초과가 나는 Case를 자주 격어보았다. 메인 로직은 모두 동일하고, 입출력의 방식만 달랐을 뿐인데.. 졸지에 틀린 풀이가 되었다는 것이다.
이런 문제는 자주 발견되었고, 이를 해결하기 위해 BufferedReader, BufferedWriter를 사용해야하는 것을 어렵지 않게 찾아볼 수 있다.
알고리즘을 중점에 두고 공부를 하다보니 어떻게 다른지 공부해보진 않았다. 매번 모르고 단순 사용하는 것이 마음에 걸려 찾아보았다.
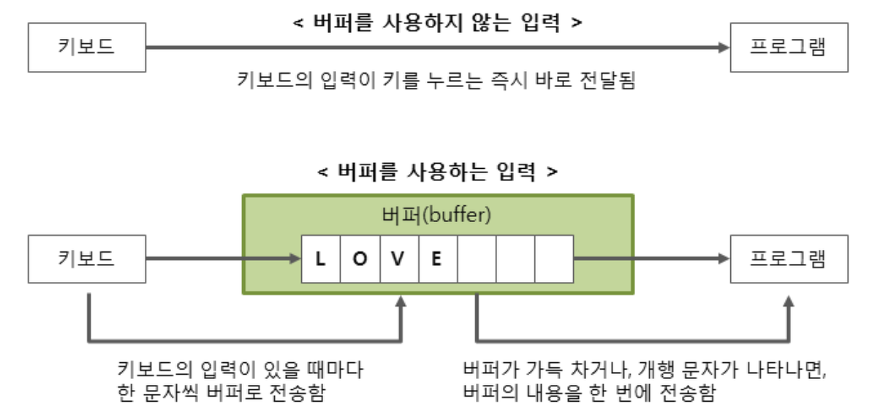
버퍼(Buffer)
우선 Buffer에 대해서 알고 넘어가야 할 것이다.
간단하게 말하자면... 어떤 데이터가 전송 될 때, 일시적으로 저장되는 메모리 영역이다.
In computer science, a data buffer (or just buffer) is a region of a memory used to temporarily store data while it is being moved from one place to another
버퍼를 지하철 플랫폼에 비교해볼 수 있다.
이동하고 싶은 많은 사람들이 가변적으로 들어와 플랫폼에 대기하고,
지하철은 이 사람들을 순식간에 태워 원하는 곳으로 한번에 이동한는 점이다.
중요한 건, 매번 사람들이 들어올때마다 이동하는 것이 아니라 어느정도 사람이 모이고, 지하철이 와야 이동이 가능하다는 점이다.
버퍼가 존재하면, 입출력을 OS가 직접 처리하며 발생되는 비효율적인 업무가 줄어든다
Without buffer I/O means each read or write request is handled directly by the underlying OS. This can make a program much less efficient, since each such request often triggers disk access, network activity, or some other operation that is relatively expensive.
https://stackoverflow.com/questions/22436289/when-to-use-buffer-and-what-for
이러한 버퍼를 써서 얻을 수 있는 장점은 2개정도 있는데,
- 문자를 묶어서 한 번에 전달하므로 전송시간이 적게 걸려 성능이 향상된다
- 사용자가 문자를 잘못 입력했을 경우 수정할 수 있다.
이런 특징이 있기에 입력 작업에서 버퍼를 사용하는 것이 대체적으로 유리하다는 것을 짐작할 수 있다.
BufferedReader
BufferedReader로 정수 하나를 입력받는 다고 하면,
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int userInputNumber = Integer.parseInt(br.readLine());와 같은 작업이 수행된다.
BufferedReader 말고 InputStreamReader라는 게 존재한다.
Stream
설명을 위해 간단하고 짚고 넘어가보자. 여기서 스트림은 파일을 읽거나 쓸 때, 데이터가 전송되는 통로라고 생각하면 좋을 것 같다.
Java에선 노드 스트림과 보조스트림이 있다고 이해해보자.
노드 스트림은 스트림의 주축을,
보조 스트림은 이 노드 스트림을 통해 들어오거나 나가는 데이터를 처리하는 것을 도와주는 보조의 역할을 하는 스트림이다.
짚고 넘어가야하는 건 BufferedReader는 보조 스트림이라는 점이다.
스트림은 데이터 타입 ( Char 또는 Byte ), 방향 ( Input 또는 Output )에 따라 결정된다. 그리고 FileReader, BufferedReader, InputStreamReader는 Char로 반환된다.
주로 사용하는
System.in은 시스템에서 설정된 입력 스트림을 따르겠다는 뜻. Stream, Redaer, File입력이 될 수 도 있다.
다시 BufferedReader
감싸지는 구조를 살펴보면
BufferedReader {
InputStreamReader {
InputStream 혹은 System.in
}
}
이런 구조이다.
정리하면, Byte타입으로 전송되는 데이터를 Char형으로 변환하고, 버퍼링을 적용하여 Char 데이터를 반환해주는 것이다.
Scanner와의 차이
Scanner가 느린 이유는, 입력을 읽는 과정에서 정규 표현식을 적용하고, 입력값 분할, 파싱 과정을 스스로 제공해주기 때문이다.
실제로, Scanner에서 제공하는 .nextInt(), .nextDouble() 메서드는 잘못 입력하면 입력 단계에서부터 예외가 발생한다.
BufferedReader는 모든 입력을 Char형으로, 버퍼를 사용하여 받는다.
하나의 글자에 대해 전달이 이루어지는 것이 아닌, 전체 입력(혹은 버퍼 단위)에 대해서만 전달되기 때문에 속도 부분에서 매우 유리할 수 밖에 없다.
그래서 속도는 빠르지만, 사용자가 사용하기 편하게 조작하려면 별도의 메서드를 호출해야한다.

Scanner와 BufferedReader의 수행시간 차이
출처 : https://algospot.com/forum/read/2496/
참고 글:
https://onlyfor-me-blog.tistory.com/368
https://docs.oracle.com/javase/7/docs/api/java/util/Scanner.html
