Interporlation Search
보간탐색
이진 탐색은 정렬된 대상을 기반하여 중앙에 위치한 데이터를 탐색한 후, 이를 기준으로 탐색 기준을 반으로 줄여나가면서 탐색을 진행함.
이러한 방식은, 달라지는 탐색 대상에 관계없이 항상 중앙에 위치한 데이터를 기준으로 탐색을 시작한다.
이러한 방식에서 발생할 수 있는 비효율을 줄이기 위한 보완책으로 보간탐색이 등장하였다.
단순한 예로, 유저 이름을 탐색하는 경우에 대해 살펴보자.
데이터베이스엔 문자열에 따라 정렬되어 저장되어 있고, "고길동"이라는 사용자를 검색하는 경우
- 이진 탐색인 경우
데이터들의 중앙에 위치한 인덱스부터 탐색 시작 -> ㄱㄴㄷㄹㅁㅂ ㅅ ㅇㅈㅊㅋㅌㅍㅎ 에서 탐색 시작- 보간 탐색인 경우
탐색 대상 "고길동"을 반영하여 ㄱ에서 부터 탐색 시작
"12" 탐색 하는 경우
이진 탐색 vs 보간 탐색의 시작점 비교

이러한 특성을 이용하여 일반적인 이진탐색 방법보다 조금 더 나은 성능을 기대할 수 있다.
탐색 기준 선정 방식
중복이 없는(키) 정렬된 데이터에 대한 탐색이라는 점을 고려하여, 탐색할 대상이 대략 어디위치에 있는 지 파악하는 식이 존재한다.
[1, 2, 3, ... , 10] 인 배열에서 3을 탐색하는 경우, 우리는 직관적으로 배열 앞부분에 위치한다는 것을 알지 않는가
보간 탐색에서는 데이터의 값과 그 데이터가 저장된 위치의 인덱스의 값이 비례하다는 아이디어를 근거로 탐색한다
이러한 아이디어를 비례식으로 표현해보면 다음과 같다.
"x" 라는 데이터를 찾는 경우, 해당 데이터의 인덱스 값 S
: 탐색 대상의 시작 인덱스
: 탐색 대상의 마지막 인덱스
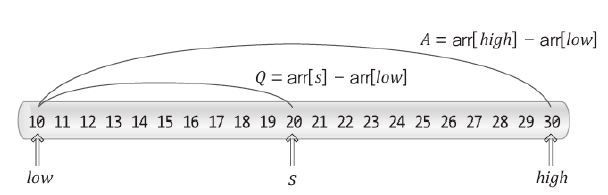
만약 12를 찾는다면,
=> S는 2임을 알 수 있다.
구현
#include <stdio.h>
int ISearch(int ar[], int first, int last, int target) {
int mid;
//탈출 조건
if(ar[first] > target || ar[last] < target) {
return -1;
}
//보간 탐색의 비례관계 계산 식
mid = ((double) (target - ar[first]) / (ar[last] - ar[first]) * (last - first)) + first;
if(target == ar[mid]) {
return mid;
} else if(target < ar[mid]) {
return ISearch(ar, first, mid - 1, target);
} else {
return ISearch(ar, mid + 1, last, target);
}
}
int main() {
int arr[] = {1, 3, 5, 7, 9};
int idx;
//7 찾기
idx = ISearch(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1, 7);
if(idx == -1)
printf("탐색 실패\n");
else
printf("탐색 저장 인덱스 : %d\n", idx);
//10 찾기
idx = ISearch(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1, 10);
if(idx == -1)
printf("탐색 실패\n");
else
printf("탐색 저장 인덱스 : %d\n", idx);
return 0;
}- 시작 기준이 다를 뿐, 일반적인 이진탐색과 작동 방식이 유사하다
-> 탐색 범위를 좁혀가며 찾아가는 방식 (재귀) - 탈출 조건
- 값을 찾으면 탈출
- 값이 존재하지 않으면, target이 탐색 범위를 벗어나게 됨

앞으로 넘어지기