이미지 출처: LG AIMERS 강의자료
Activation Function들의 종류를 정리해보자.
📌 1. Sigmoid

sigmoid function의 문제점
-
Saturation(포화 상태): input이 엄청 작거나, 큰 값일 때 gradient가 0에 수렴한다.
-> Gradient Vanishing Problem을 야기
: sigmoid 함수의 미분값의 범위가 0~1/4여서 backpropagation을 수행할때마다 gradient가 점점 0으로 수렴하게 되어 학습이 느려진다. -
Not zero-centered: sigmoid 함수의 모양을 보면,

이렇게 함수값들이 positive한 값들에 모여있는 것을 볼 수 있다. 이것의 문제점이 무엇인지 알아보자.
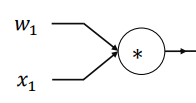
만약 을 계산해 activation function을 통과시켜 loss를 구하는 일반적인 NN 계산에서 의 gradient를 구하기 위한 backpropagation을 한다면, 이 되고, 여기서 는 과 같아진다. (를 에 대해 편미분하면 이기 때문)
따라서, 의 gradient는 에 의해 결정된다! 그런데 이 값은 어느 노드나 backprop 할 때 똑같이 적용되는 값이기 때문에, 이나, 나 모든 w에 대해서 똑같이 적용되고, gradient w들이 모두 항상 같은 방향으로 움직인다.
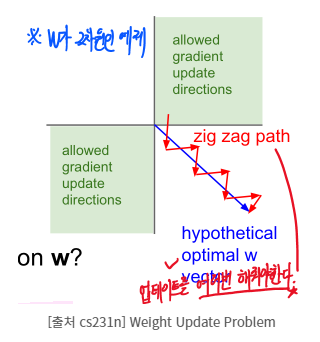
위 사진과 같이 파란색 선의 최적의 해를 찾으려면, 빨간색 선의 zig-zag 경로밖에 갈수가 없다. 이는 굉장히 비효율적...!
따라서 아예 input x들의 분포가 양수/음수 고르게 나타나도록 zero-mean data를 선호하는 것이다. 그런데 위에서 봤듯이 sigmoid는 not zero-centered라는 문제가 있다!
📌 2. Tanh
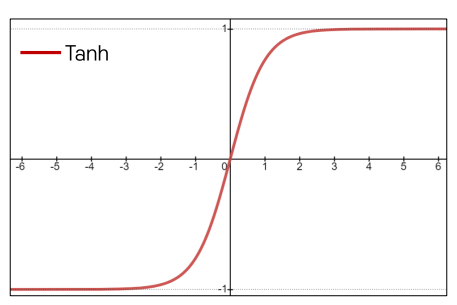
tanh는 zero-centered 문제를 해결해줄 수 있다.
tanh의 문제점
- 그러나 여전히 gradient saturation 문제가 있다...!
📌 3. ReLU(Rectified Linear Unit)

그래서 등장한 ReLU! Saturation 문제가 일단 해결되고, 계산이 매우 빠르다고 한다!
ReLU의 문제점
- Not zero-centered
- Gradient가 x가 음수 일 때는 완전히 0이다.
