[참고]
Sigmoid와 Softmax의 차이점
[정보이론] 정보량과 엔트로피의 의미
Logistic Regression - 간단한 설명
강의를 듣다가 확실히 짚고 넘어가야 할 것 같아서 정리하는 sigmoid vs softmax!
📌 Sigmoid
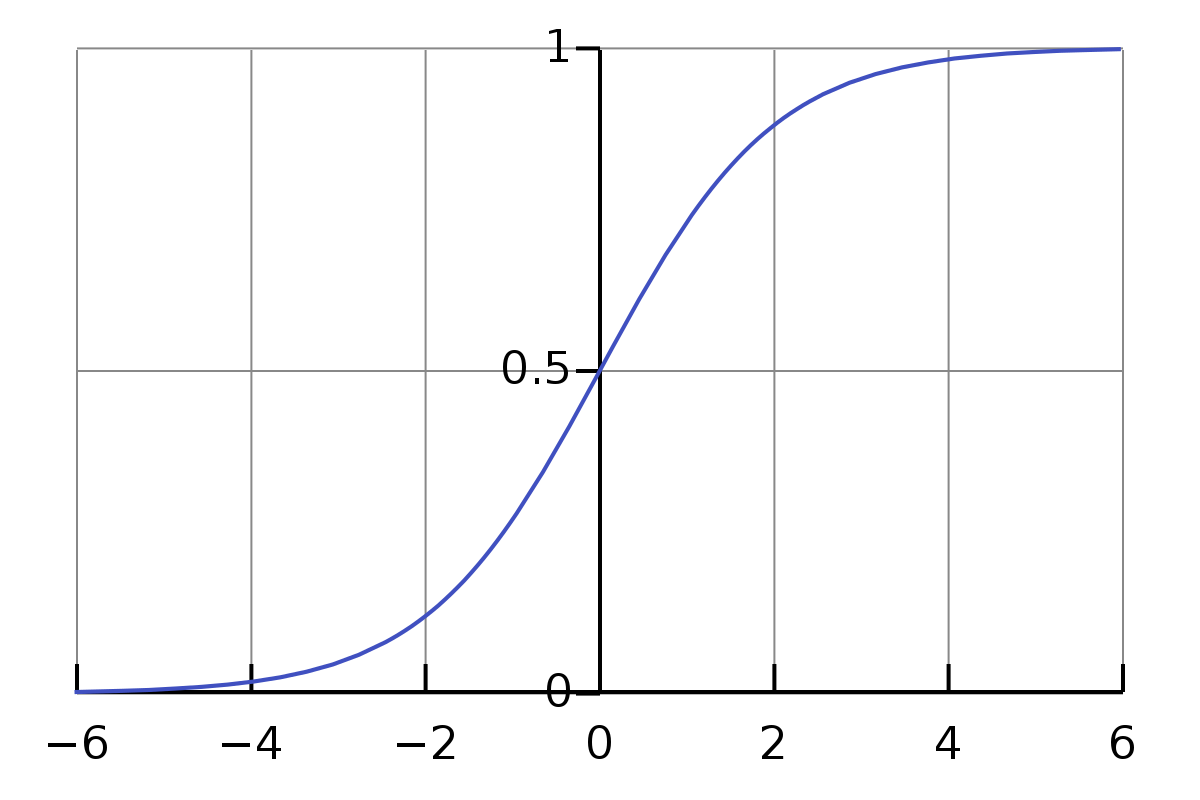
시그모이드는 0에서 1사이의 값을 출력해주는 함수
단, sigmoid 함수의 output, 즉 Prediction 값과 예측하고자 하는 Target 값은 모두 (0,1)에 속하므로,
- MSE(Mean Squared Error)로 계산한다면 prediction과 target의 차이가 최대 1이다.
- 따라서 Gradient도 최대 2가 되어서, 학습이 잘 이뤄지지 않을 수 있다.
따라서, output vector의 합이 1이 되는, 확률 값이 되도록 하는 것이 바람직하다~ 하여 등정한 softmax.
📌 Softmax
softmax는 K개의 클래스 구분 결과를 확률처럼 해석하도록 해준다.
지수함수 를 이용하되, 시그마를 이용해 확률을 구하는 것이 포인트다. '확률'이기 때문에 당연히 출력 값이 0에서 1사이가 되고, 모든 확률의 합이 1이 된다!
그리고 softmax에 적용하는 Loss를 Softmax loss, 혹은 Cross Entropy라고 부른다. 여기서 Cross Entropy에 더불어 Entropy, logits 개념까지 확실히 짚고 가보자...
Entropy: Entropy는 불확실성을 의미한다.
어느 확률이 한쪽으로 치우치지 않고 분산되어 있을 때, 어떤 사건이 일어날 지에 대해서 알 수 없다. 여기서 도대체 얼마나 알 수 없는가를 표현하는 것이 바로 Entropy다.
그리고 내가 참고한 블로그에서는 Entropy를 '정보량'이란 개념에 대입해 설명하고 있었다.
정보이론에서 정보량이란, '놀람의 정도'를 의미한다.
따라서 식상한 정보일수록 정보량이 적고, 새로운 정보일수록 정보량이 크다고 표현한다.
정보량을 수학적으로 구하자면, 다음과 같다.
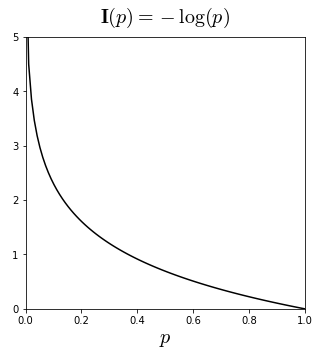
여기서 는 가 발생할 확률이고, 로그 밑 a는 어떤 정보를 측정하느냐에 따라 달라지며 컴퓨터에서는 2를 붙여(섀넌 엔트로피) 출력된 엔트로피를 바탕으로 몇 bit가 필요한지를 알 수 있게하고, 확률에 대해서는 e(나츠 엔트로피)를 붙인다.
그래프를 보면 확률이 0에 가까워질수록 정보량은 무한대로 커지고, 확률이 1에 가까울수록 정보량은 0에 가까워진다. 즉, 발생할 확률이 적은 사건은 큰 정보량을, 확률이 큰 사건은 작은 정보량을 갖다는 것을 알 수 있다.
이 정보량의 기댓값(가중치 평균)을 구한 것이 바로 Entropy다. 엔트로피를 구하는 식을 보자.
는 어떤 사건 i가 발생활 확률이고, 여기에 역수를 취한 는 정보량들이다! 즉, 어떤 사건이 발생할 확률이 클수록 정보량은 감소하기 때문에 역수를 취해주는 것이다.
log를 사용하는 이유에 대해서도 블로그에서 설명해줬는데.. 위에 링크를 걸어둔 블로그를 참조하자.^^..
다시 Entropy의 개념과 비교해보자면,
- Entropy가 낮을수록 = 확실할수록 = 정보량은 감소한다.
- Entropy가 높을수록 = 불확실할수록 = 정보량은 증가한다.
Cross Entropy: Cross Entropy는 분류 모델의 Loss function으로 사용된다!
그렇다면 Entropy에서 Cross Entropy로 넘어가자. Cross Entropy는, 우리가 로 구했던 어떤 사건 i의 정보량 대신에 모델이 구한 확률을 쓴다는 것이다. 그리고 에는 실제 target 값ㅇㄹ 넣는다. 여기에 넣을 확률을 구할 때, 클래스가 3개 이상인 multi-class인 경우 softmax를 이용한다. 위에서 봤던 softmax 함수식을 다시 보자.
이렇게 softmax로 각각의 클래스에 대한 모델의 확률을 구하고, 이 식을 이용해 Cross Entropy(Entropy의 기댓값)를 계산한다. Cross Entropy Loss의 식은 다음과 같다.
c = classese
그러나 여기서 에 들어가는, Groundtruth 값은 one-hot encoding vector로 주어진다. 따라서 예측 하고자 하는 c번째 class를 제외하고는 어짜피 0이랑 곱해지기 때문에, 식을 다음과 같이 간소화할 수 있다.
참 간단해졌다...
이렇게 구한 Cross Entropy를, Classification 모델에서 손실함수로 사용한다. (Regression 모델에서 손실함수가 MSE였던것처럼!) 이렇게 Cross Entropy를 사용함으로써 '모델에서의 정보량이 실제 정보량과 얼마나 비슷한가?'를 측정한다.
Binary Cross Entropy: for Logistic Regression(Binary Classification)
[Logistic Regression에서 MSE가 아니라 BCE를 사용하는 이유]
잠시 Logistic Regression에 대해 짚고 넘어가자면, Logistic Regression은 회귀가 아니라 사실 Classification 문제다. 단, sigmoid를 Activation Function으로 사용해 0과 1사이의 확률 값으로 나타낸다.
이러한 Logistic Regression에선 MSE가 아니라 BCE를 사용하게 되는데, 위에 참고 문서에 따르면 그 이유는 바로 MSE가 convex하지 않기 때문에, Local Minimum에 빠질 위험이 크기 때문이다.
BCE의 식은 다음과 같다.
Binary Case이기 때문에, 가 1(positive) 또는 0(negatvie)이 되고, 그에 따라 엔트로피값을 구할 수 있게 된다.
📌 정리 : Cross Entropy의 목적
정리하자면, Cross Entropy는 어떤 두 확률분포 차이의 기준이다. CE가 크다는 것은, 두 확률분포 차이가 많이 난다는 것이고, 작다는 것은 두 확률분포의 차이가 작다는 것이다.
여기서 두 확률분포 = 정답지(Groundtruth)와 모델이 예측한 확률이라고 이해했다.
정답지가 0과 1로 이루어진 one-hot vector이므로 이걸 베르누이 확률분포로 이해할 수 있고, Cross Entropy를 계산함으로써, 베르누이 확률분포의 일종인 one-hot encoding 정답지와 가장 비슷한 확률분포를 출력하는 Classification 모델을 만들기 위함이다.
