
📄 목차
- 자연어 처리 환경 구성
- 자연어 엔진 테스트
- WordCloud
- 이상한 나라의 앨리스
- 스타워즈
- 대한민국 육아휴직 법안
- 나이브 베이즈 분류
- 감성분석 - 영어
- 감성분석 - 한글
- 문장의 유사도 측정
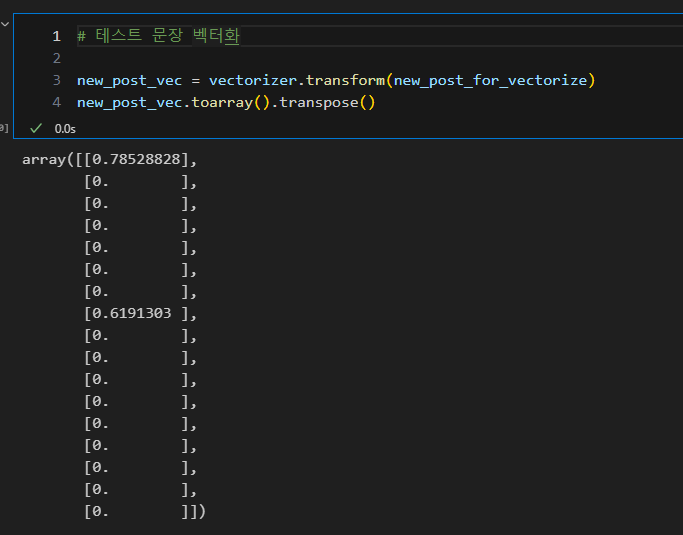
- count vectorize
- tfidf vectorize
- 네이버 API를 통해 유사질문 찾기
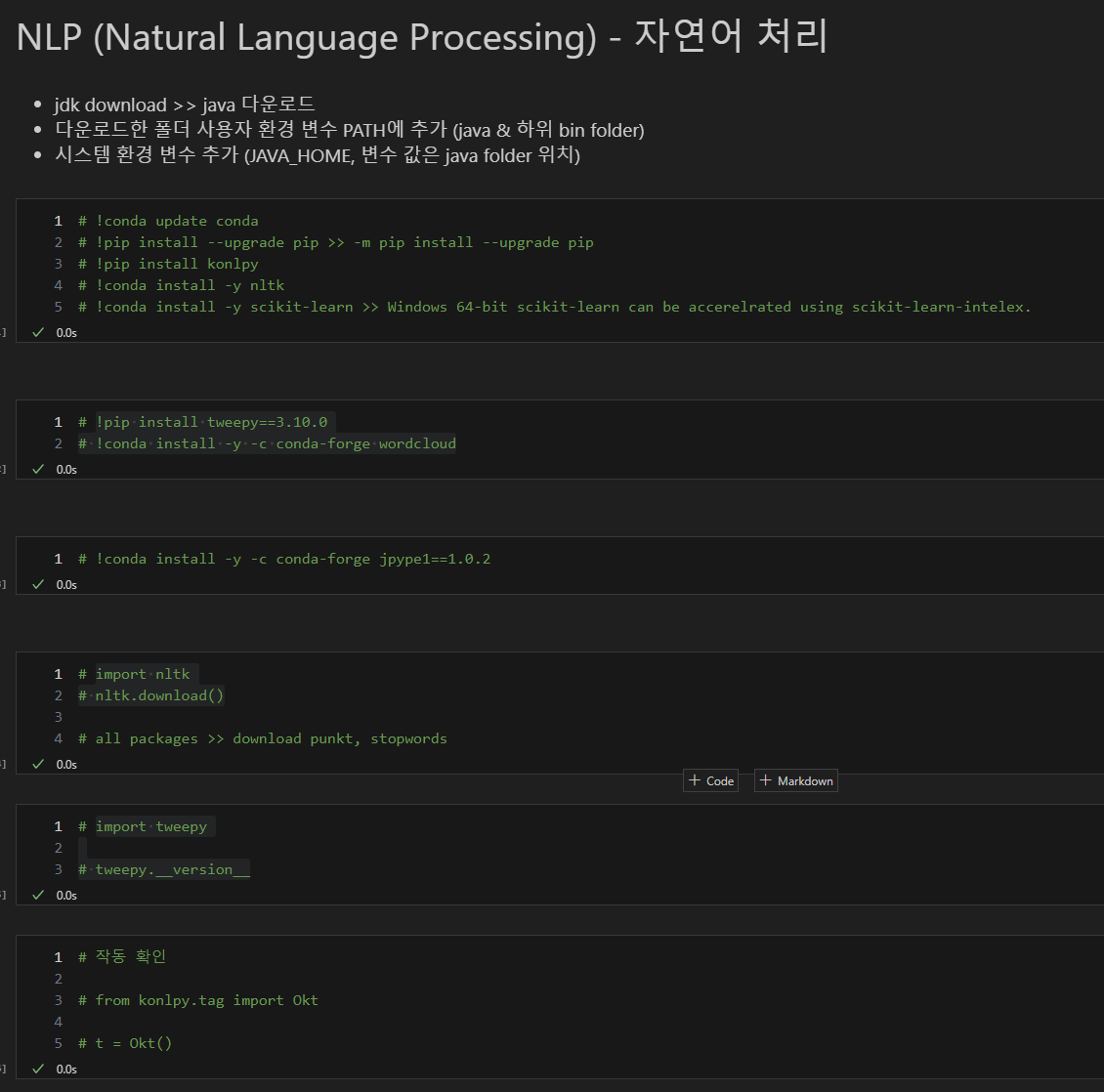
1. 자연어 처리 환경 구성
- JAVA download
- Java 폴더 / bin 폴더 위치 사용자 환경변수 PATH에 추가
- 시스템 환경 변수 추가
- 이름: JAVA_HOME
- 변수 값: Java 폴더 위치
- Package 다운로드
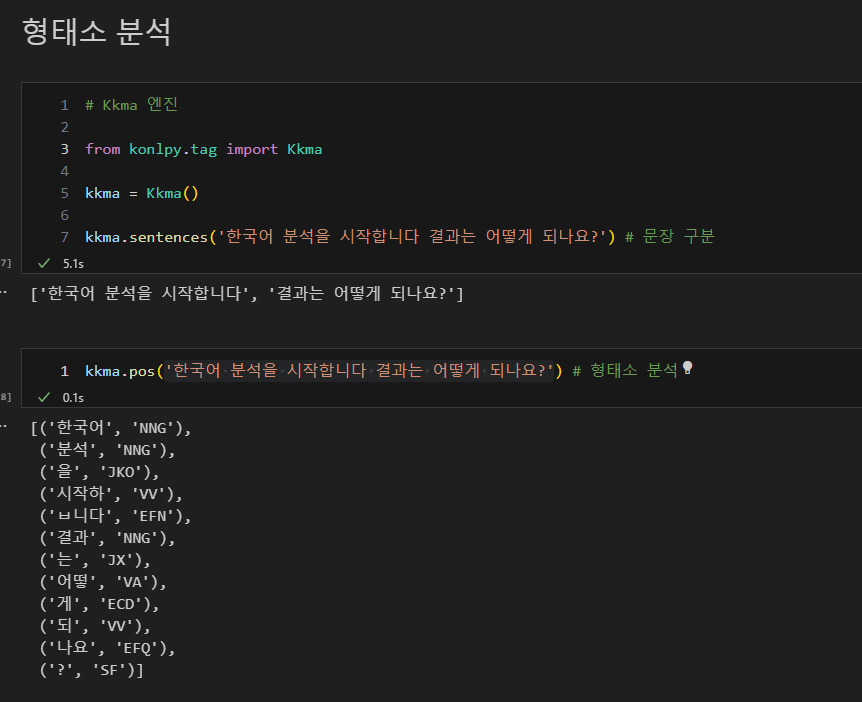
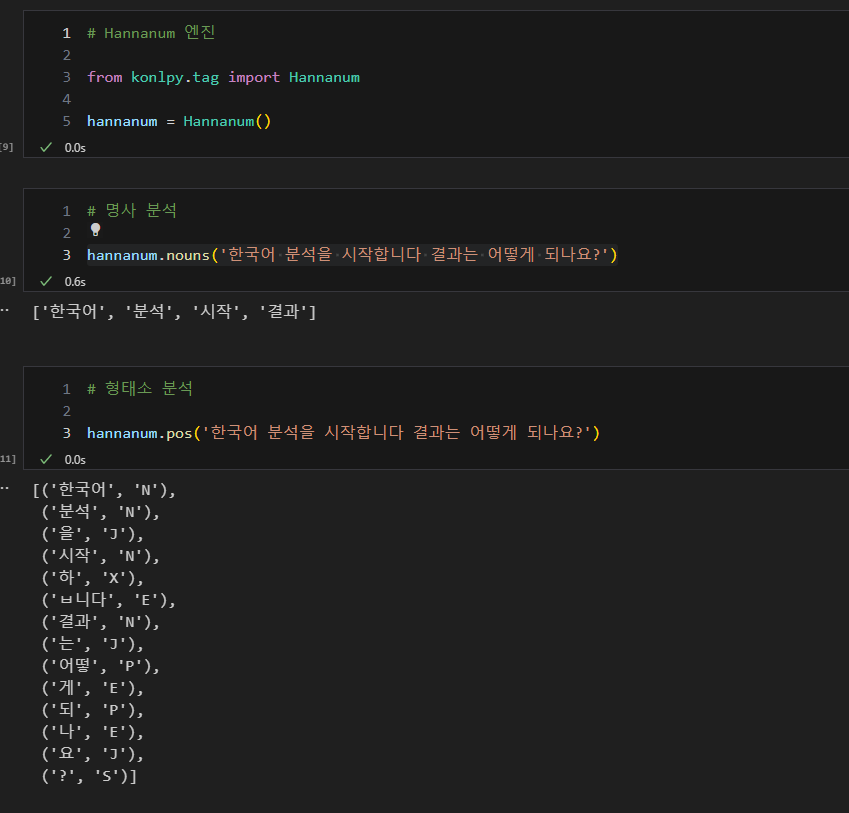
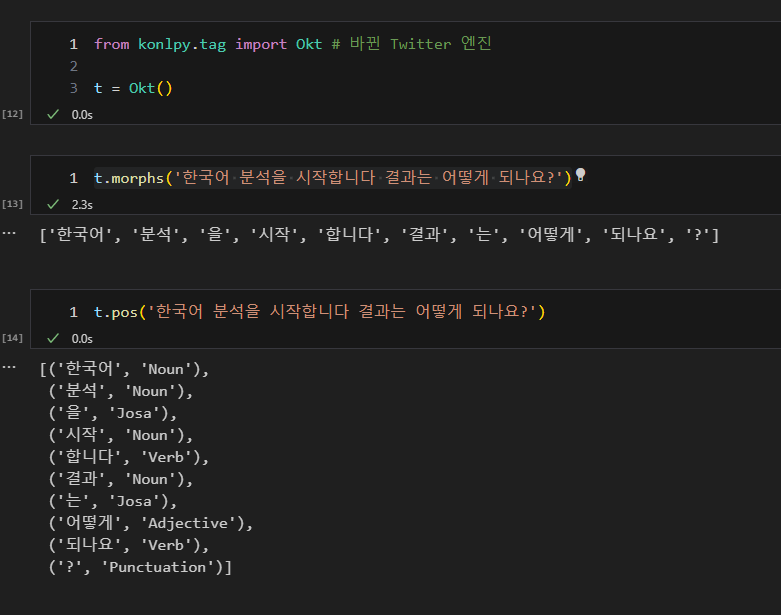
2. 자연어 처리 엔진 테스트
- 3가지 엔진 테스트 (Kkma, Hannanum, Okt)
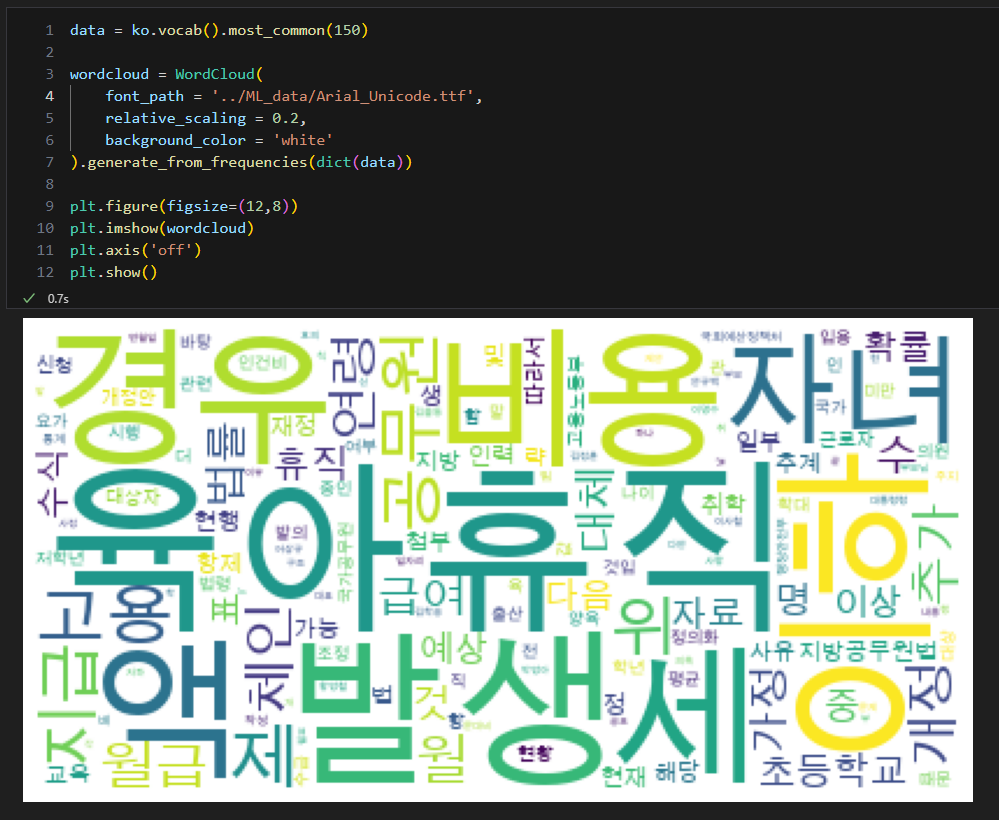
3. WordCloud
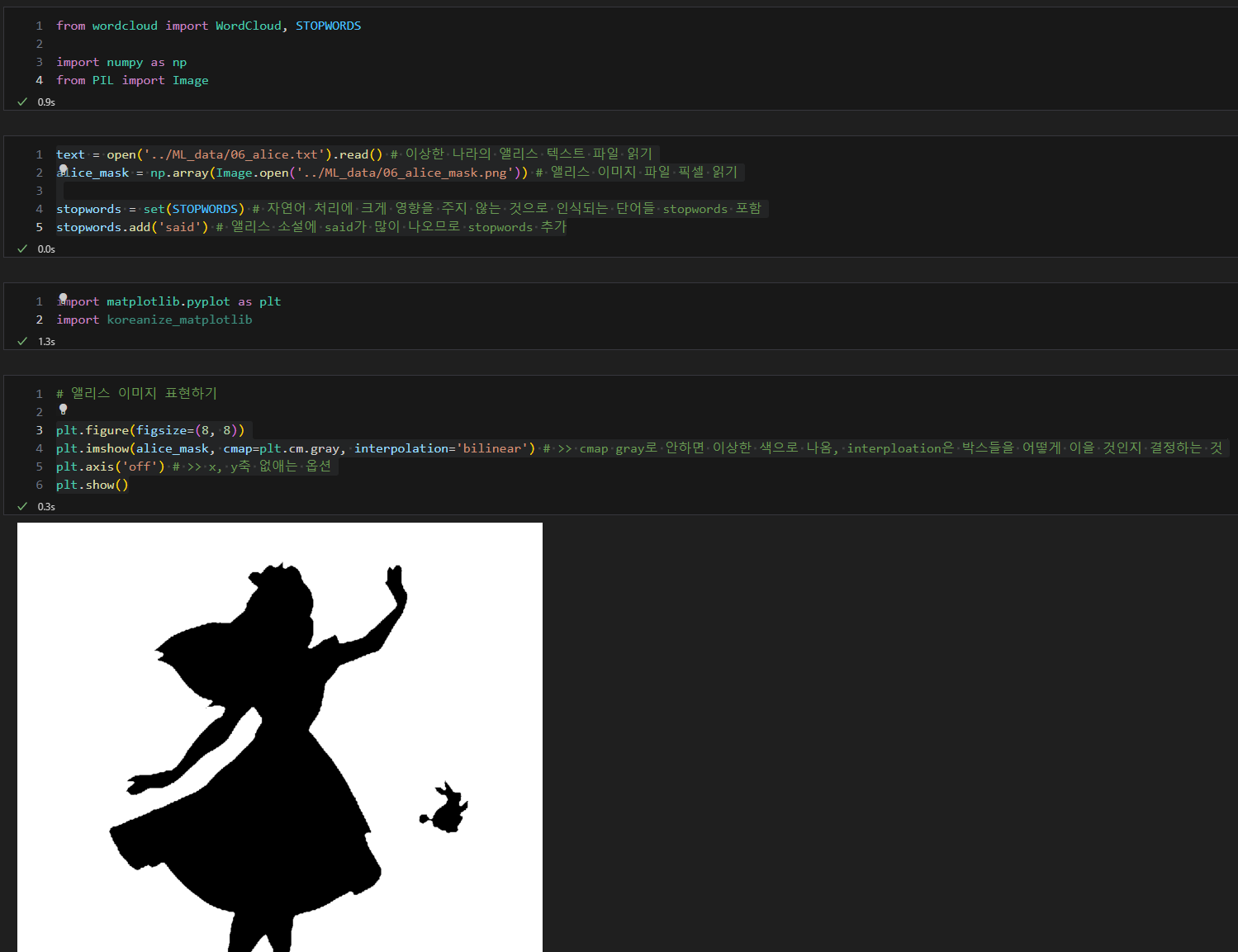
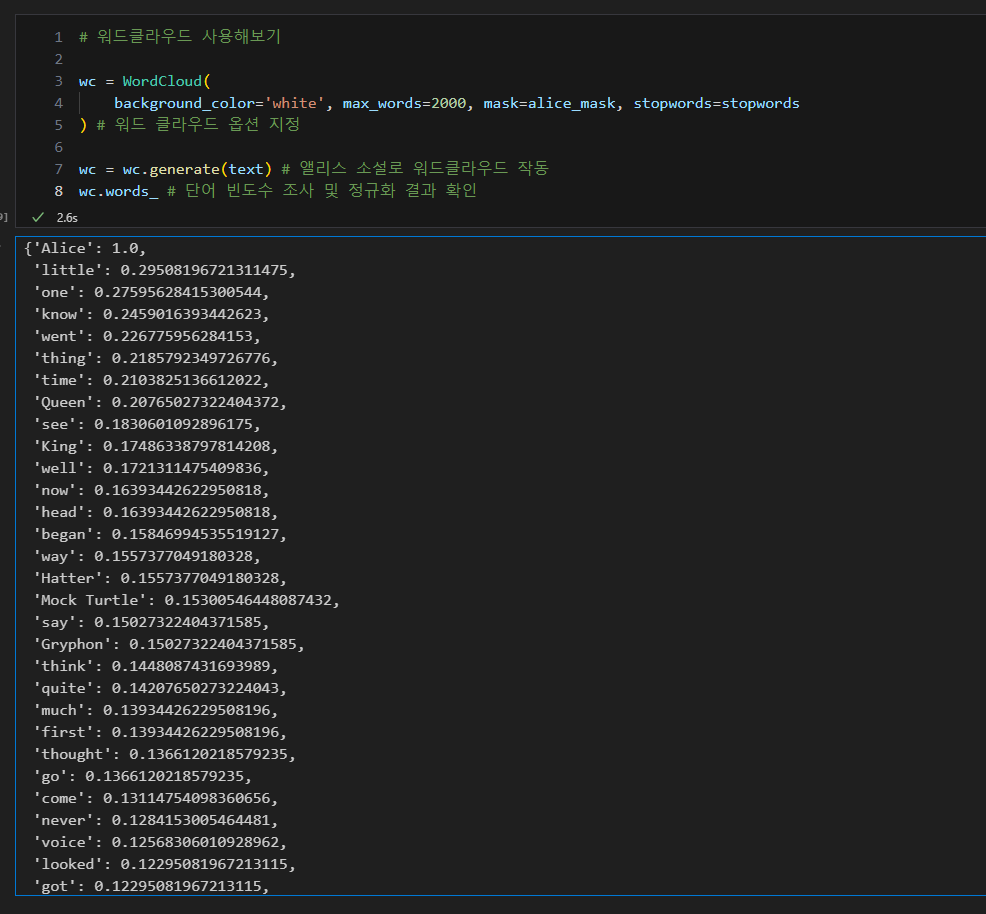
이상한 나라의 앨리스 (소설과 이미지)

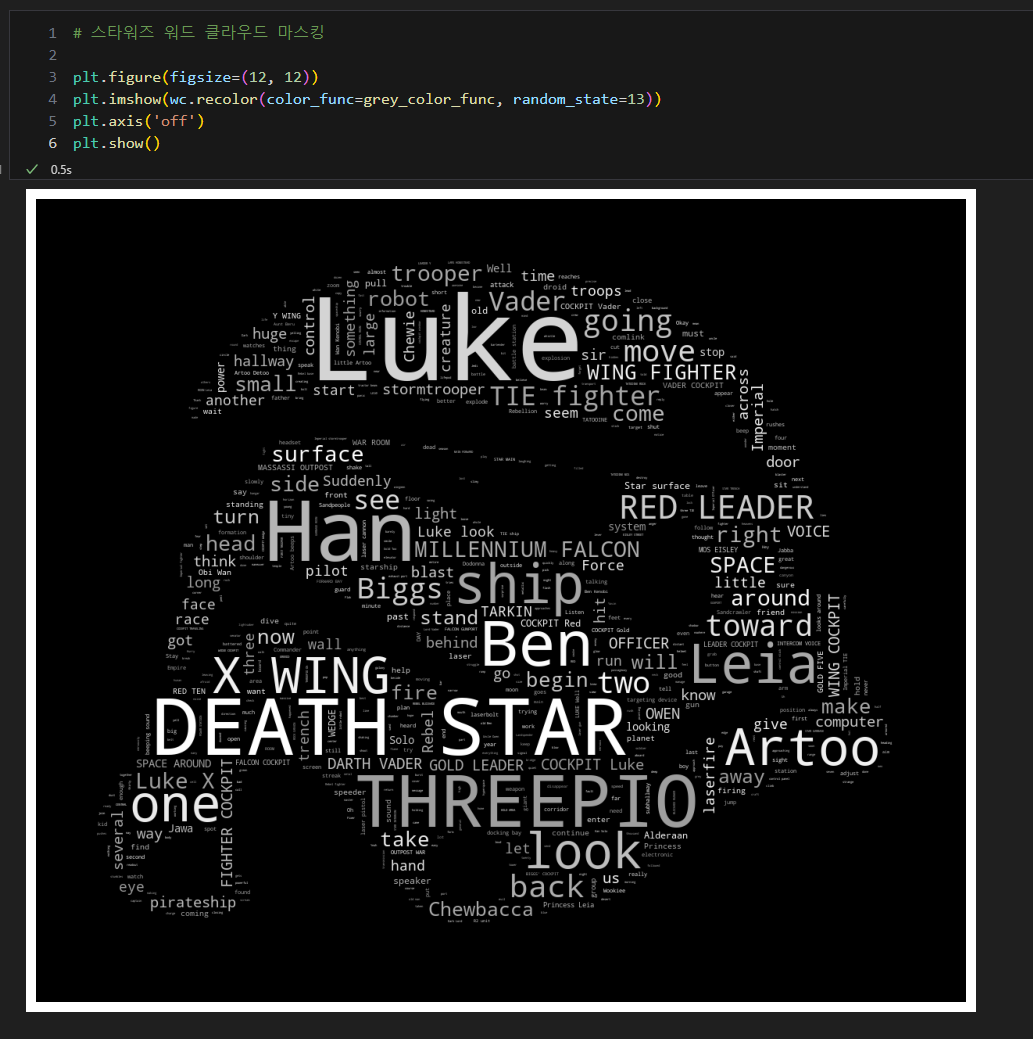
스타워즈 (대본과 이미지)
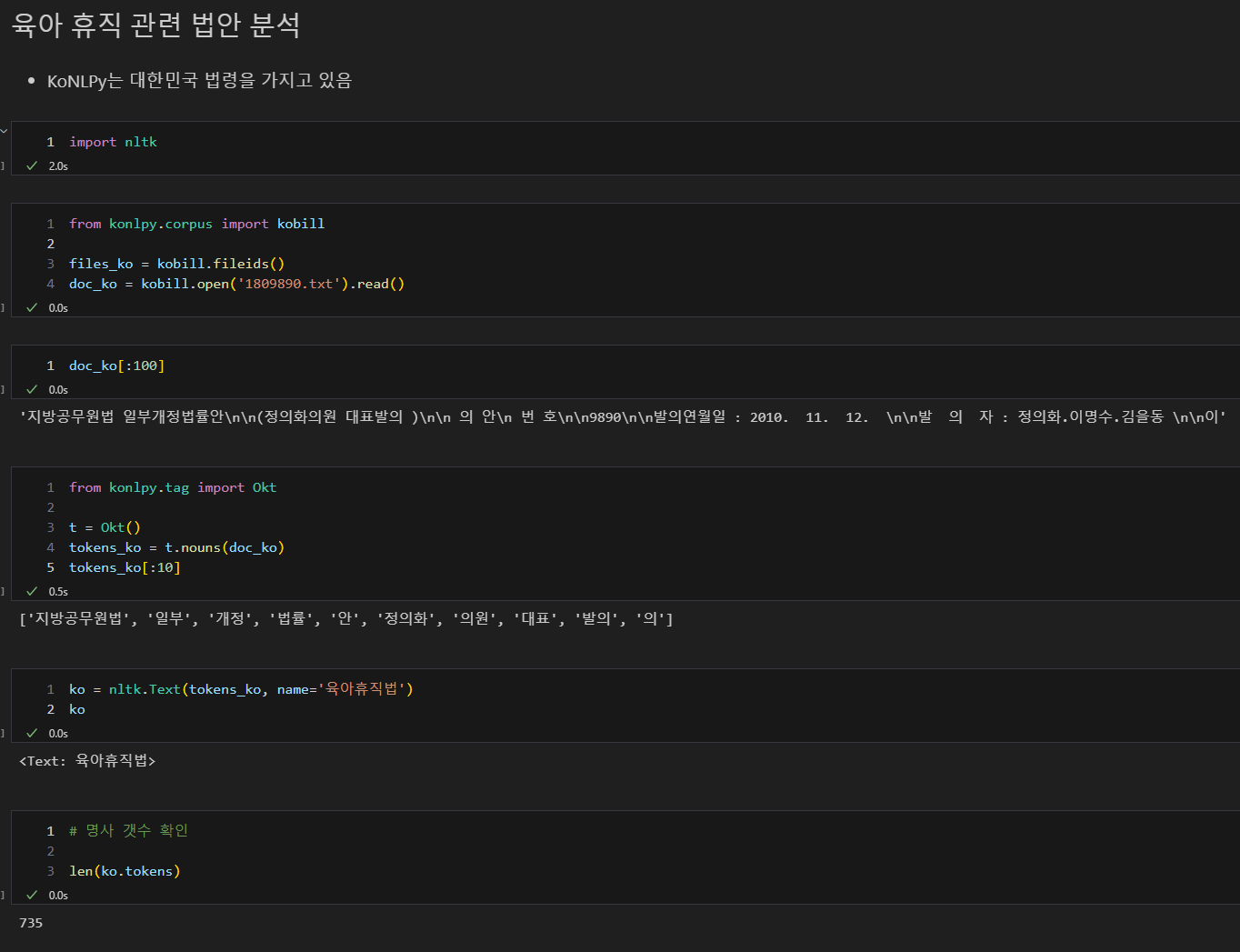
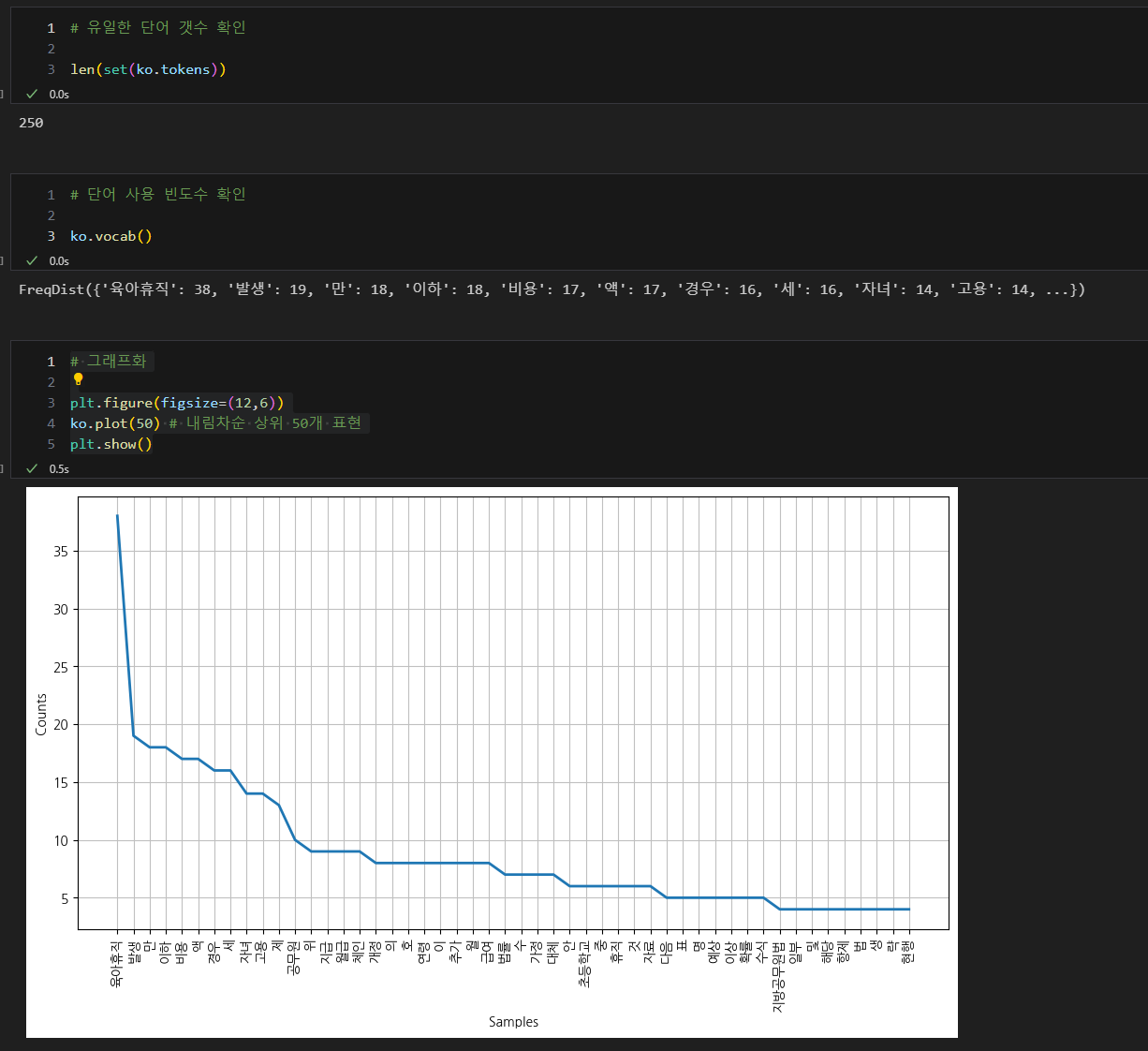
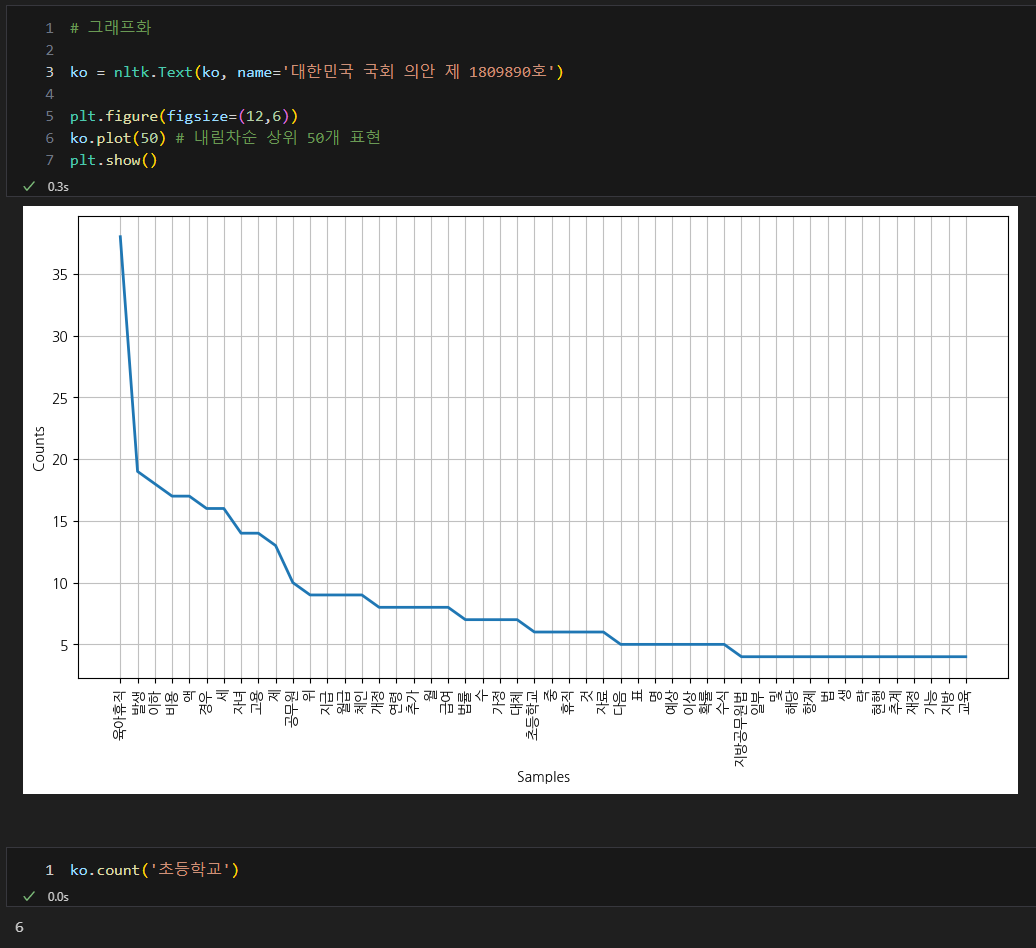
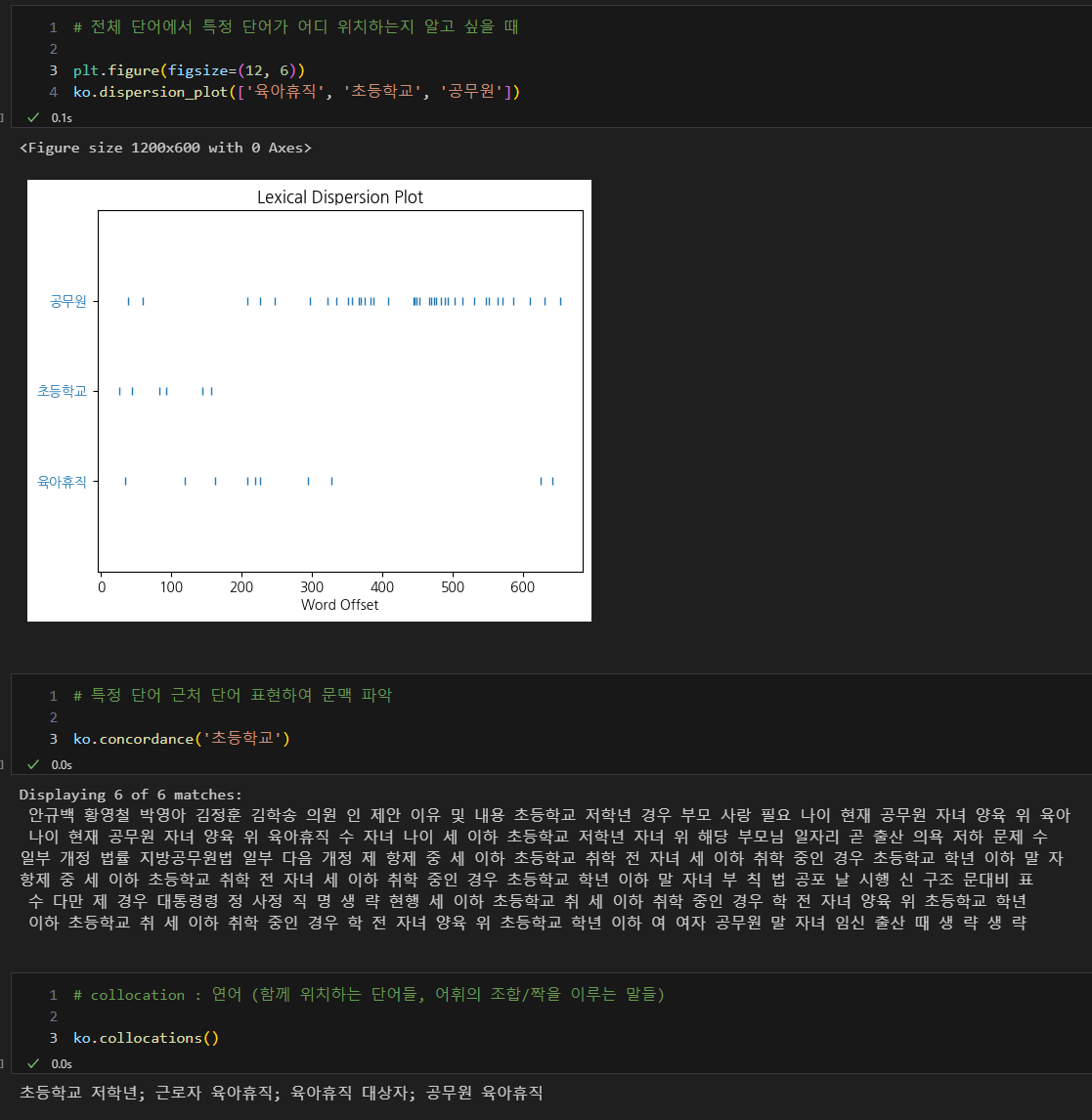
대한민국 육아휴직 법안
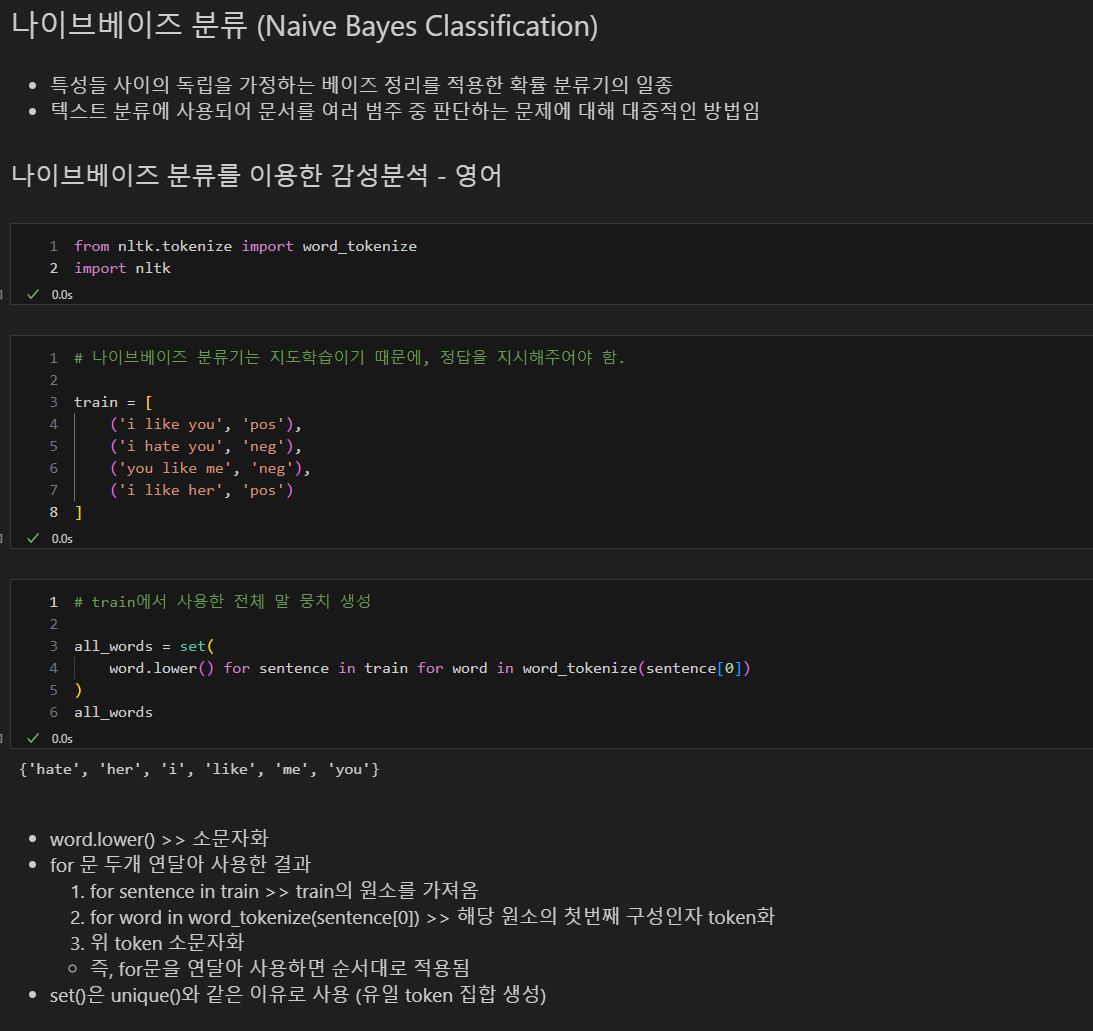
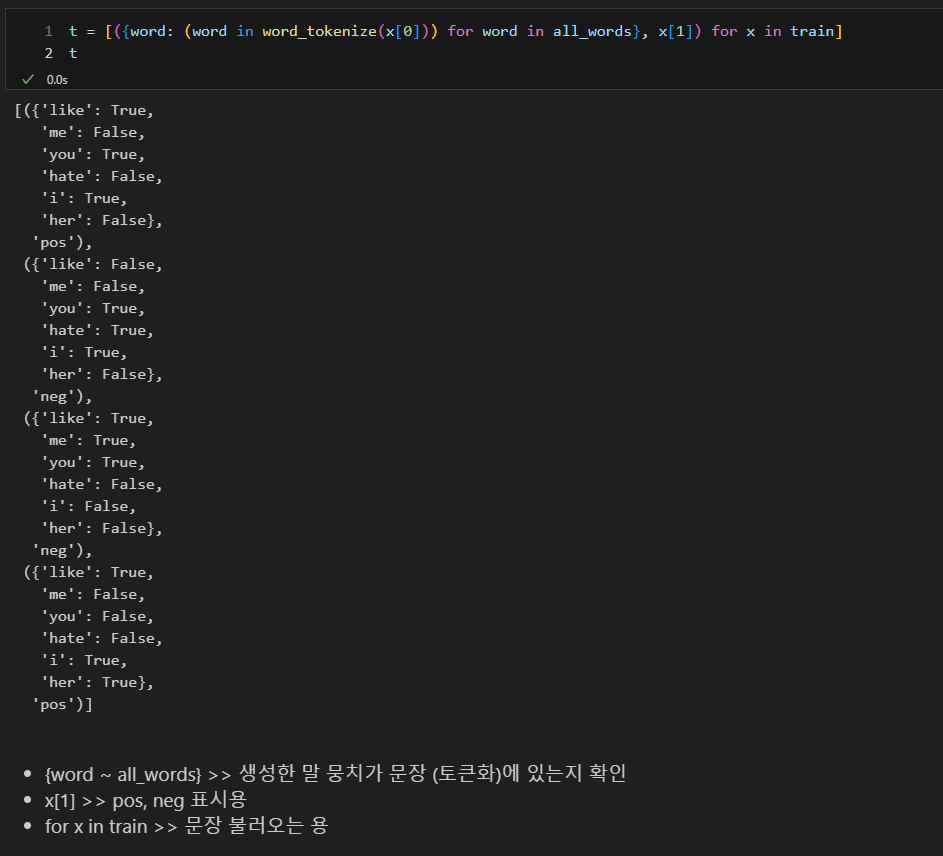
4. 나이브베이즈 분류 (Naive Bayes Classification)
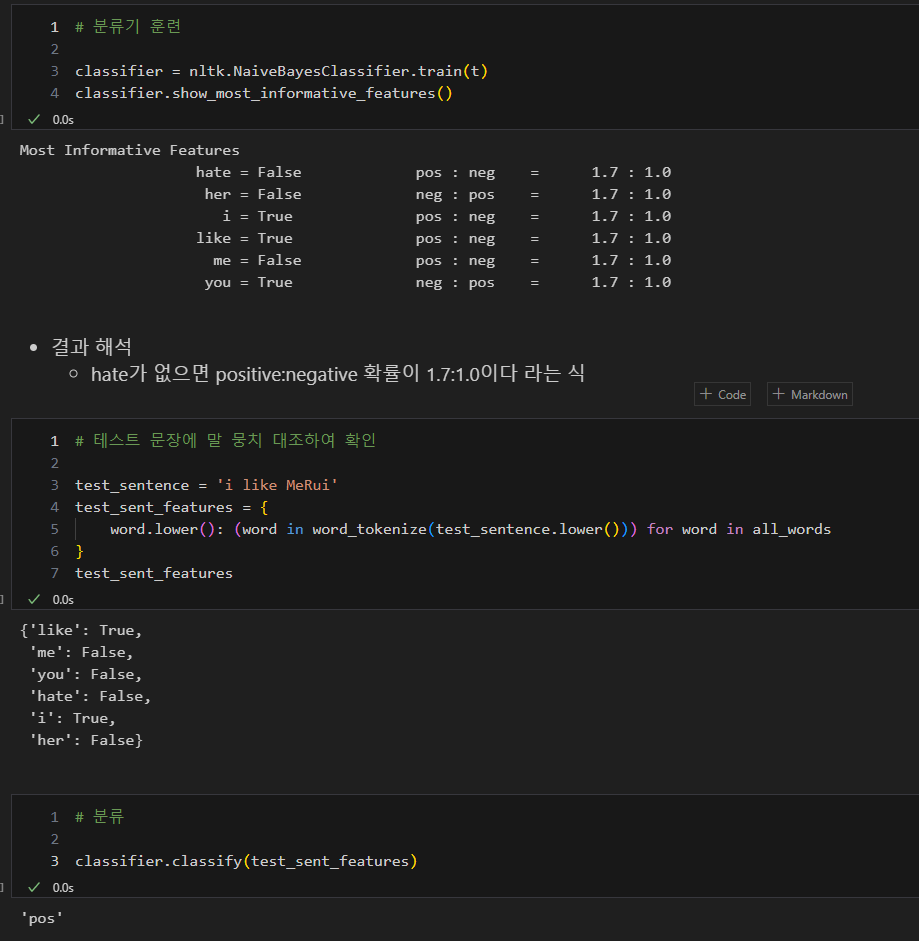
감성분석 - 영어
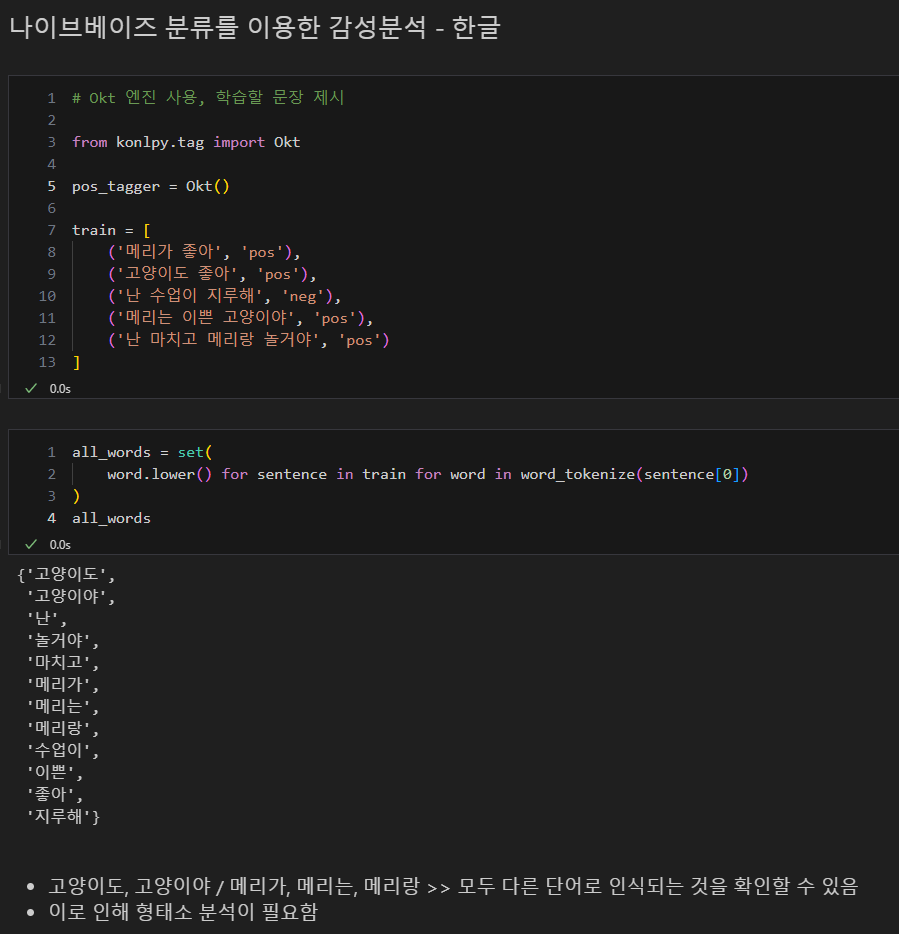
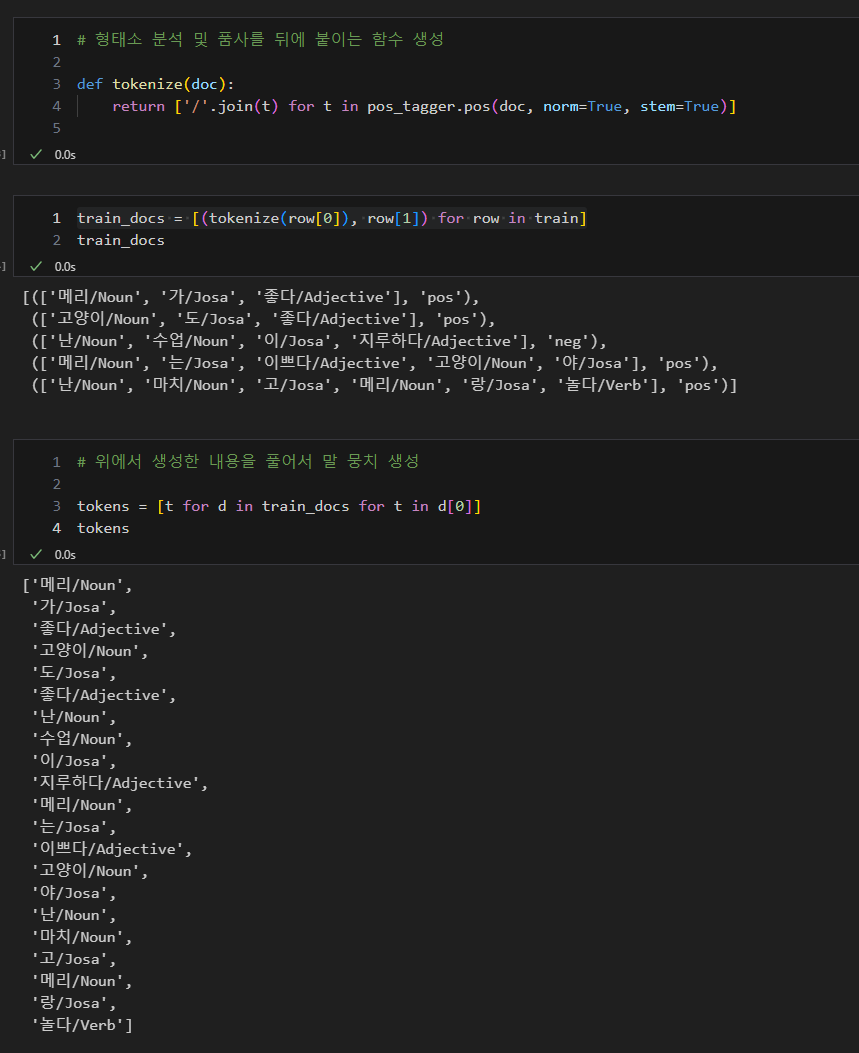
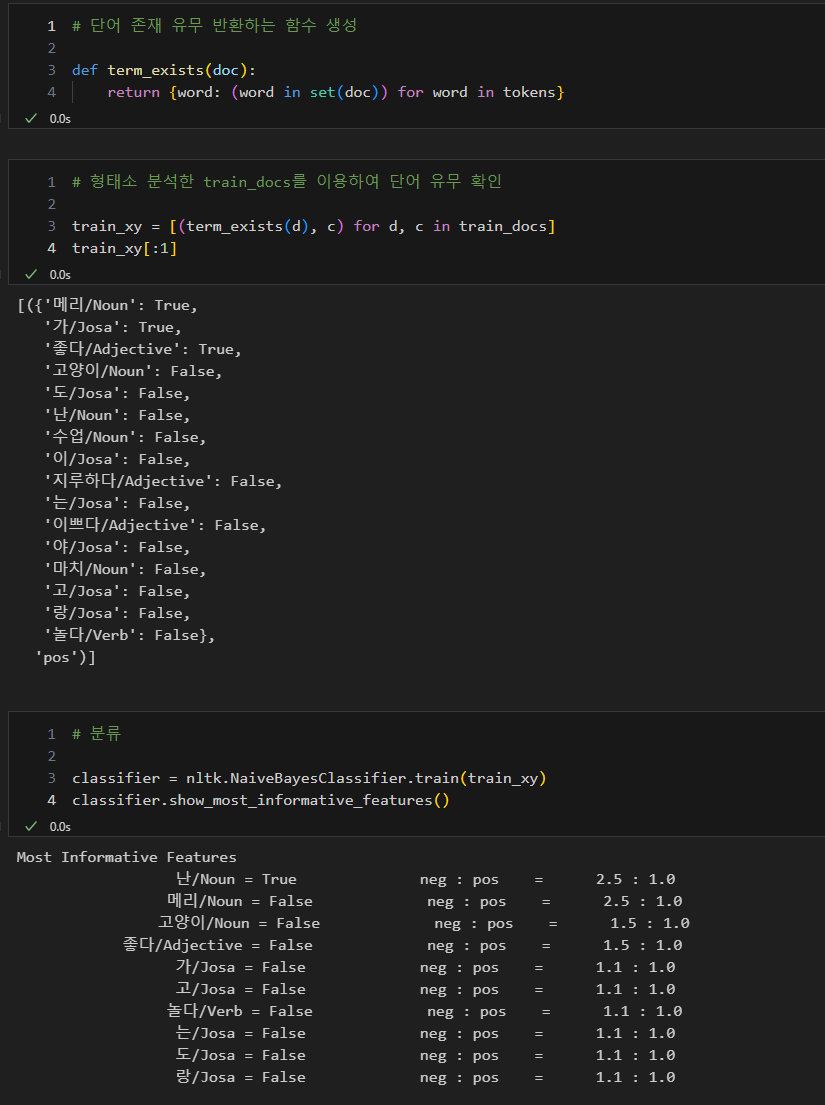
감성분석 - 한글
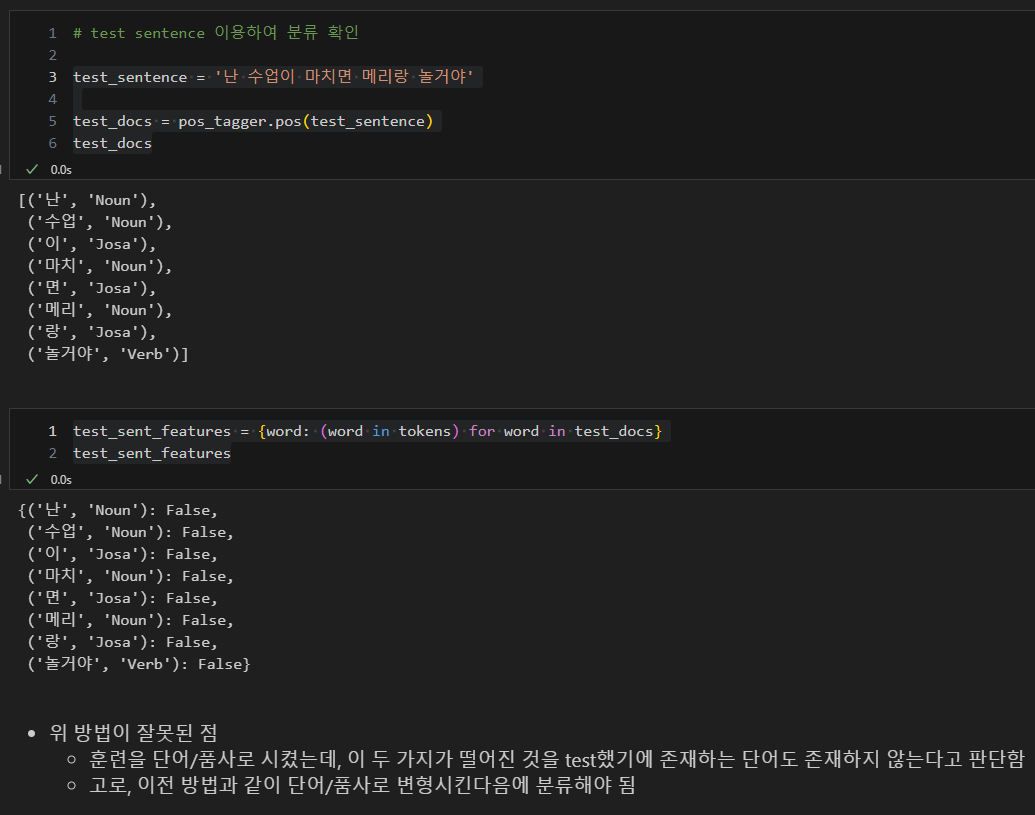
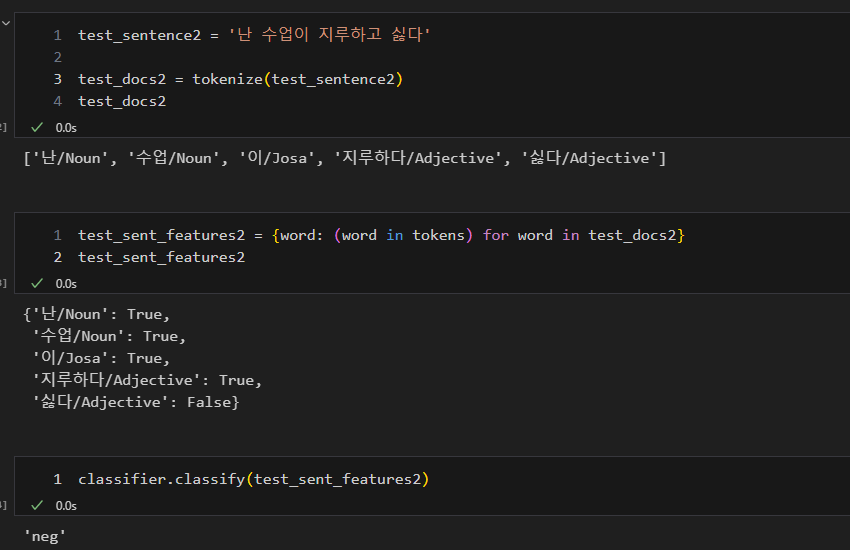
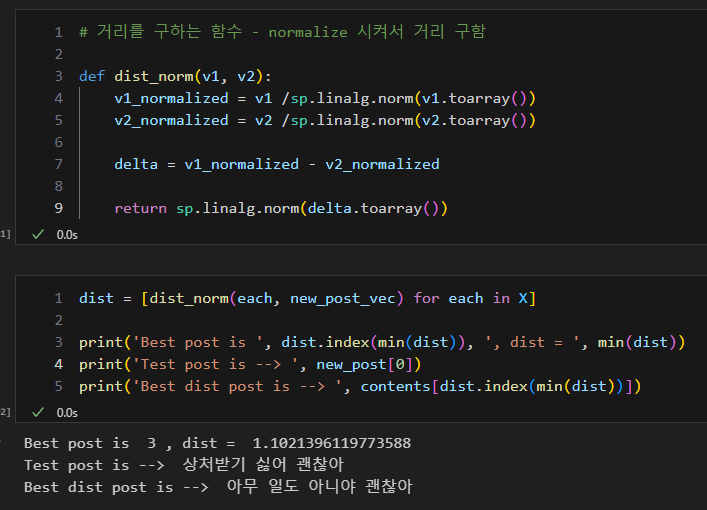
5. 문장 유사도 측정
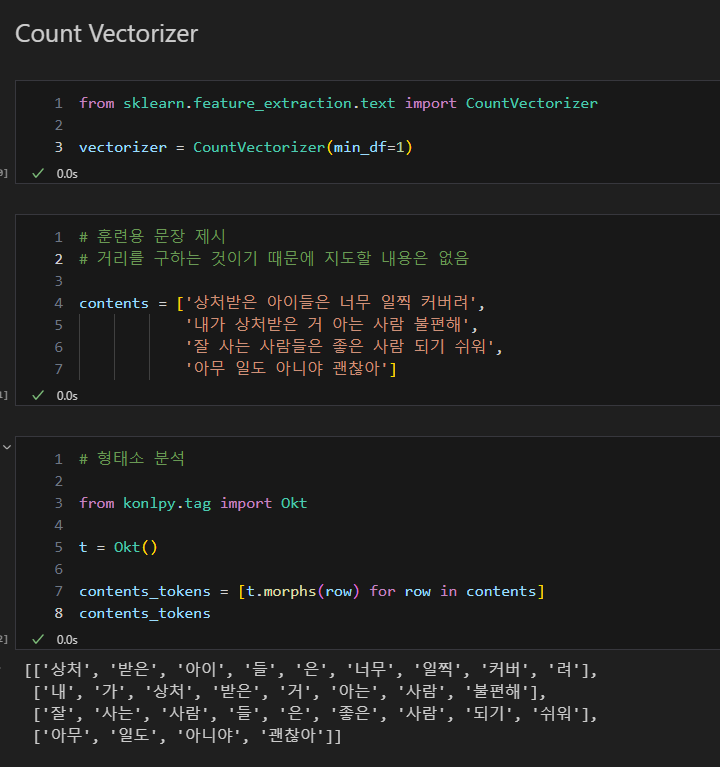
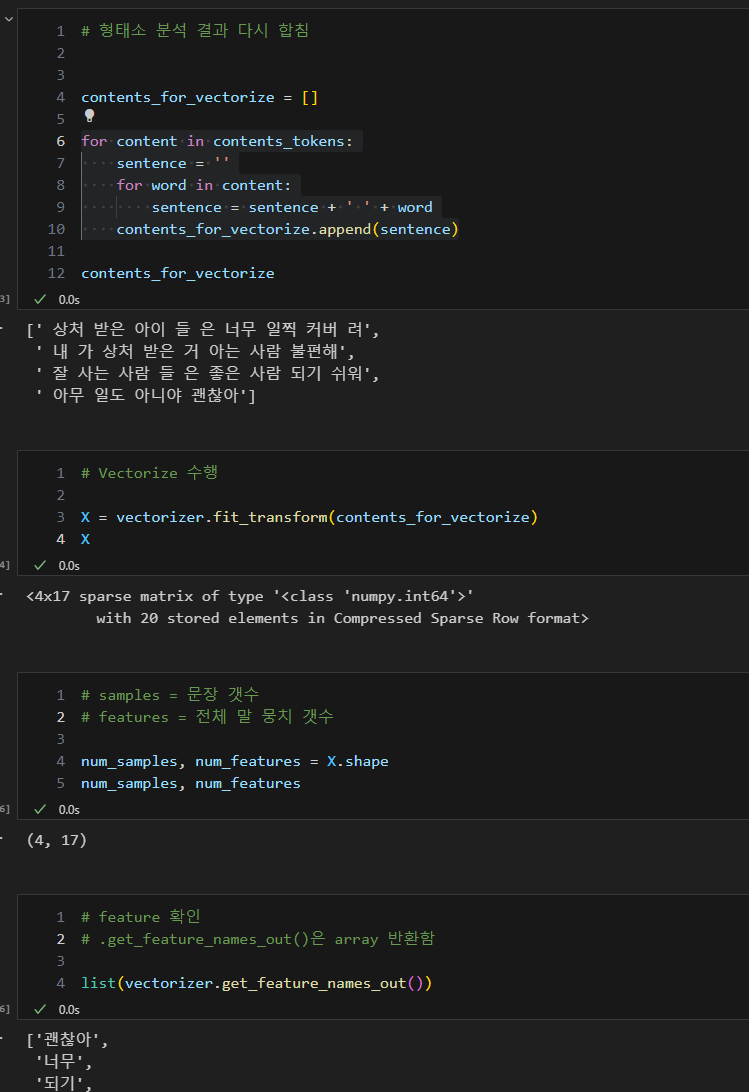
Count Vectorize
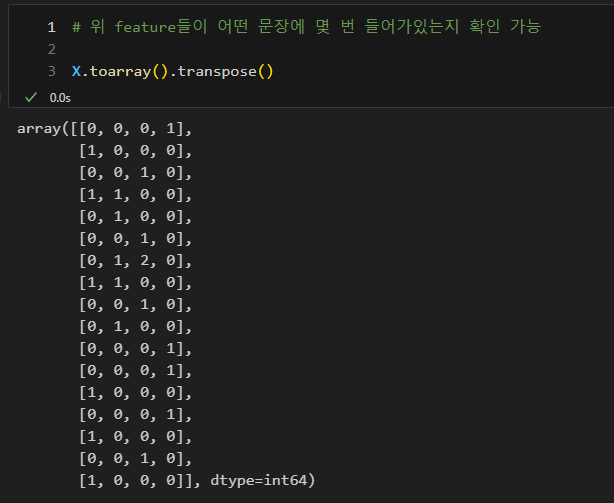
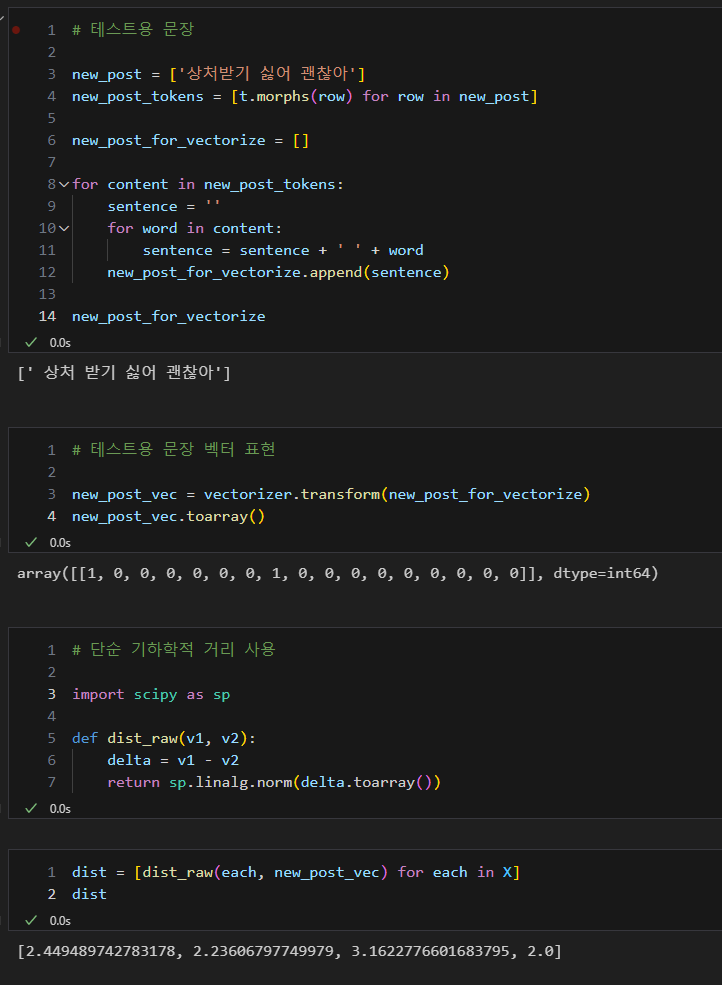
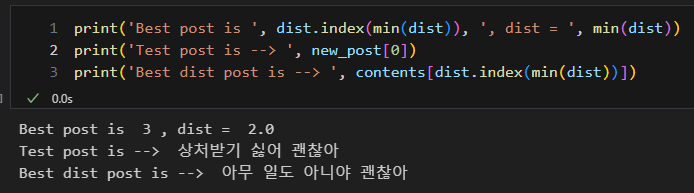
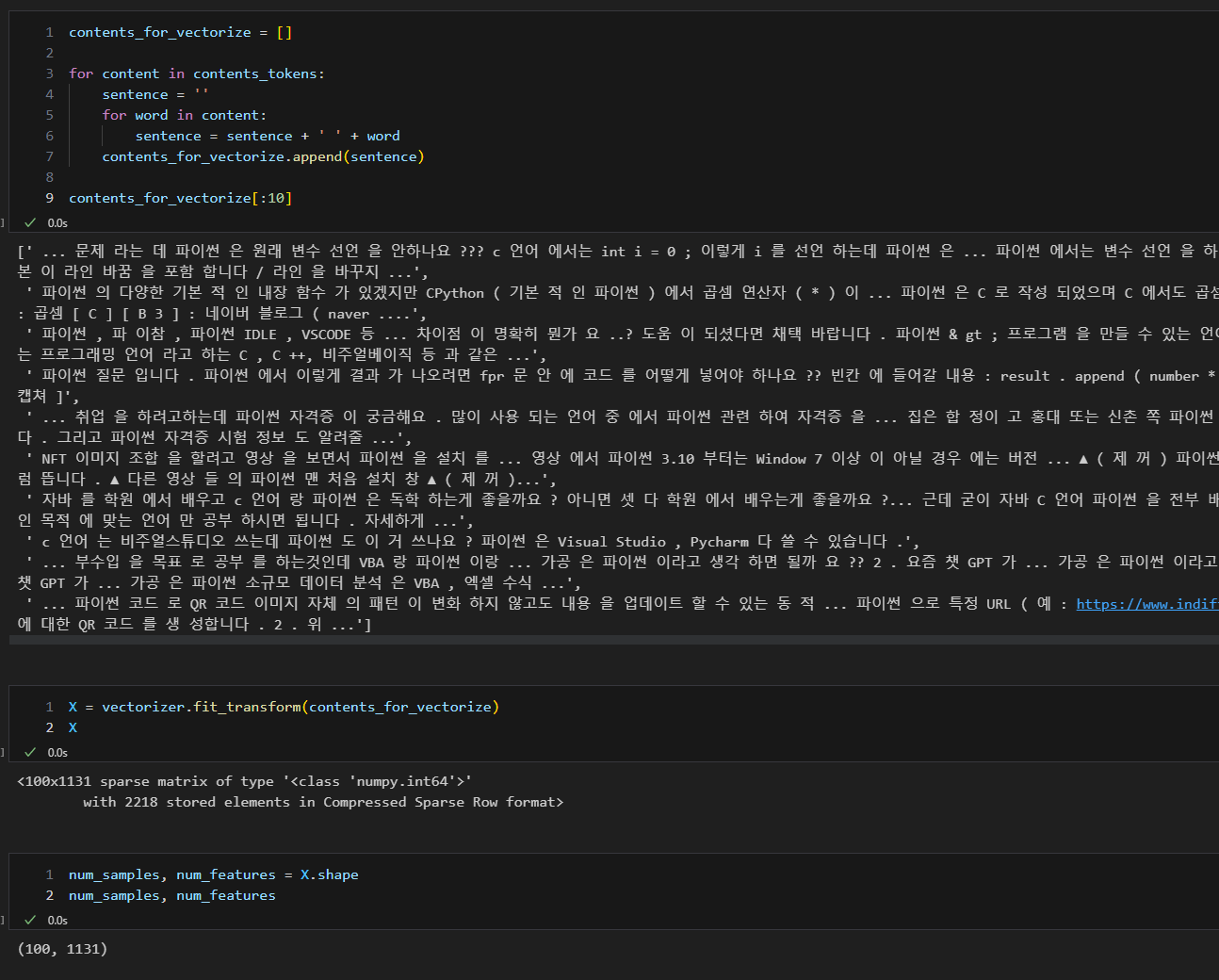
- 문장을 점과 같이 일종의 벡터로 표현하여 두 문장 사이의 거리를 구해 유사성 파악
tfidf Vectorize
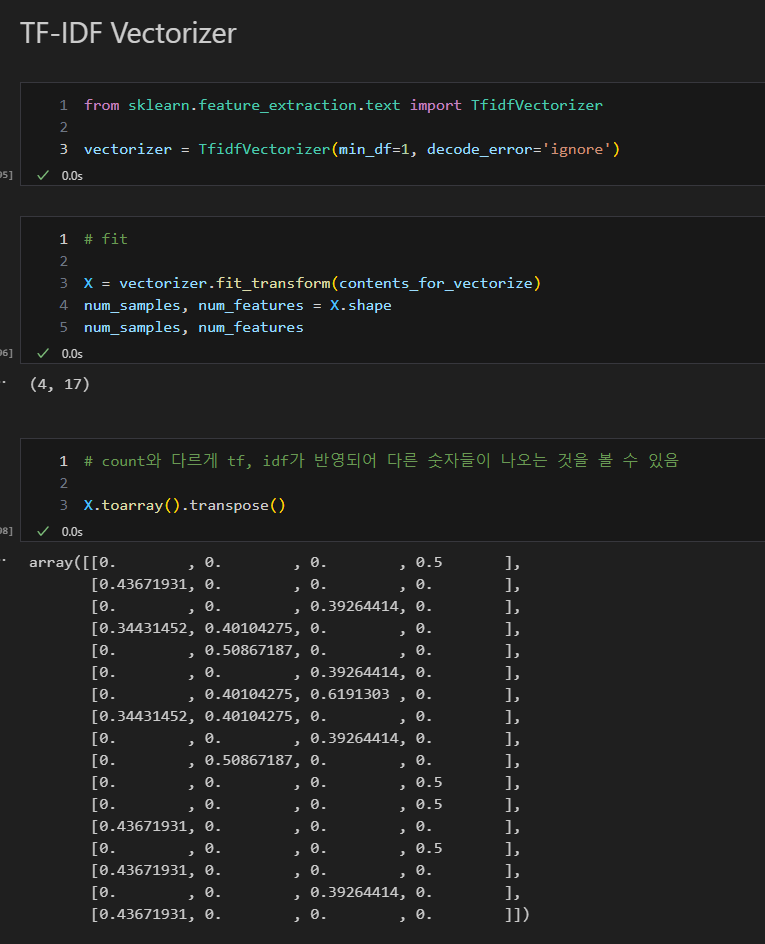
- TF-IDF (Term Frequency - Inverse Document Frequency):
정보 검색과 텍스트 마이닝에서 이용하는 가중치, 여러 문서로 이루어진 문서 군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치.- TF: 말 그대로 단어 빈도, 특정 단어가 '문서'내에 얼마나 자주 등장하는지 나타내는 값
- 그러나 '문서군'내에서 자주 사용되는 경우 흔하게 등장하는 것을 의미
- DF: 문서 빈도, '문서군'에서 얼마나 흔하게 등장하는지를 의미
- 이 값의 역수를 이용한 IDF 사용
- TF-IDF는 TF와 IDF를 곱한 값임.
(TF <-> 중요도 비례 / DF <-> 중요도 반비례)
- TF: 말 그대로 단어 빈도, 특정 단어가 '문서'내에 얼마나 자주 등장하는지 나타내는 값
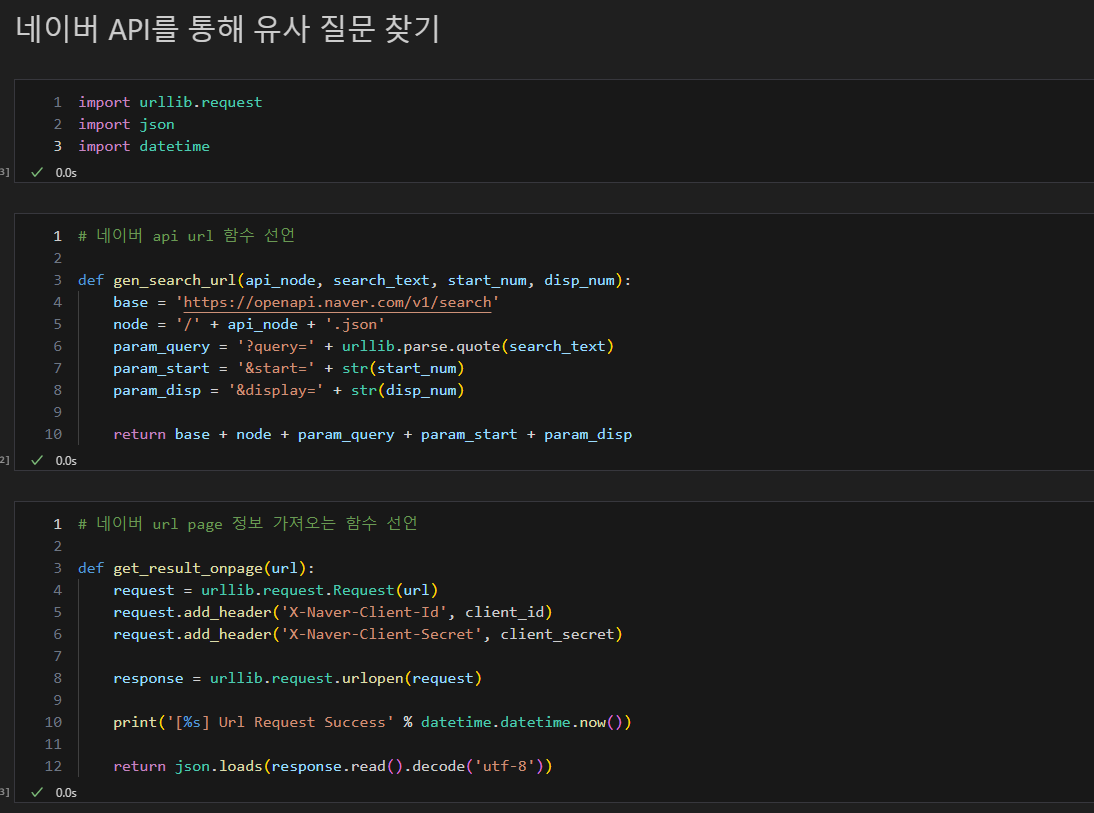
네이버 API를 통해 유사질문 찾기
- 흐름
- API에 따라 필요한 함수 선언
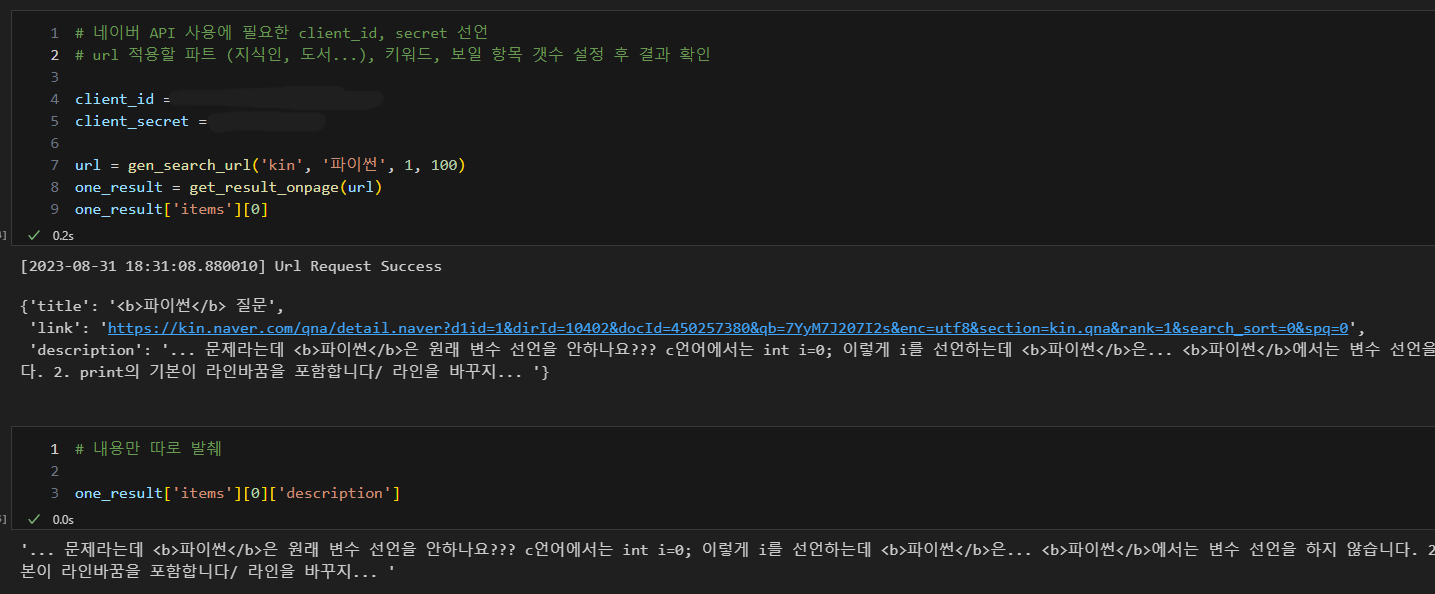
- 추가로 필요한 client Id 등 선언하고 활용
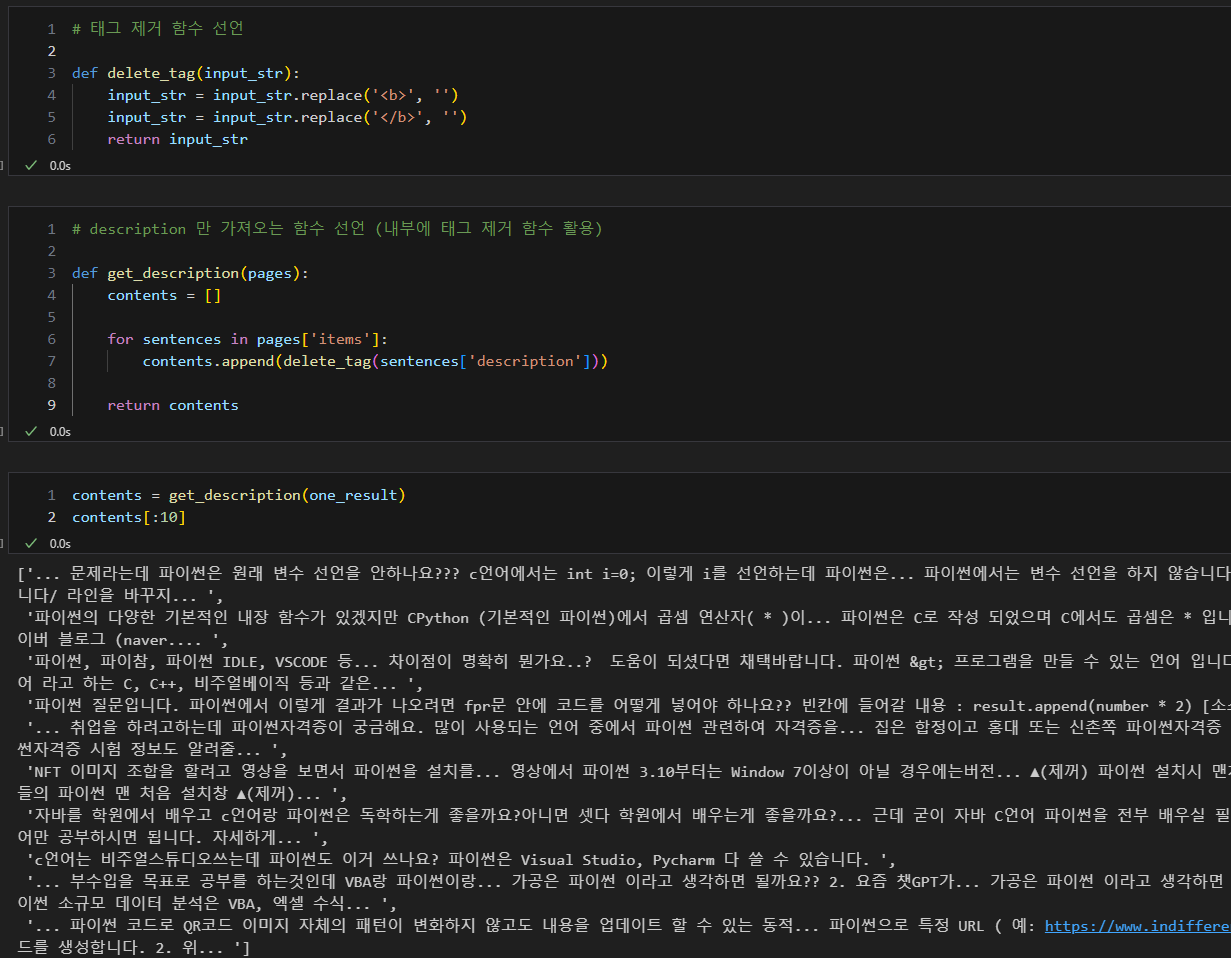
- 어떤 내용 어떻게 발췌할 것인지 코드 확인 및 함수 선언 (description만 가져올 것인지..)
- 태그 제거, 어떤 내용 가져올 것인지 정하기
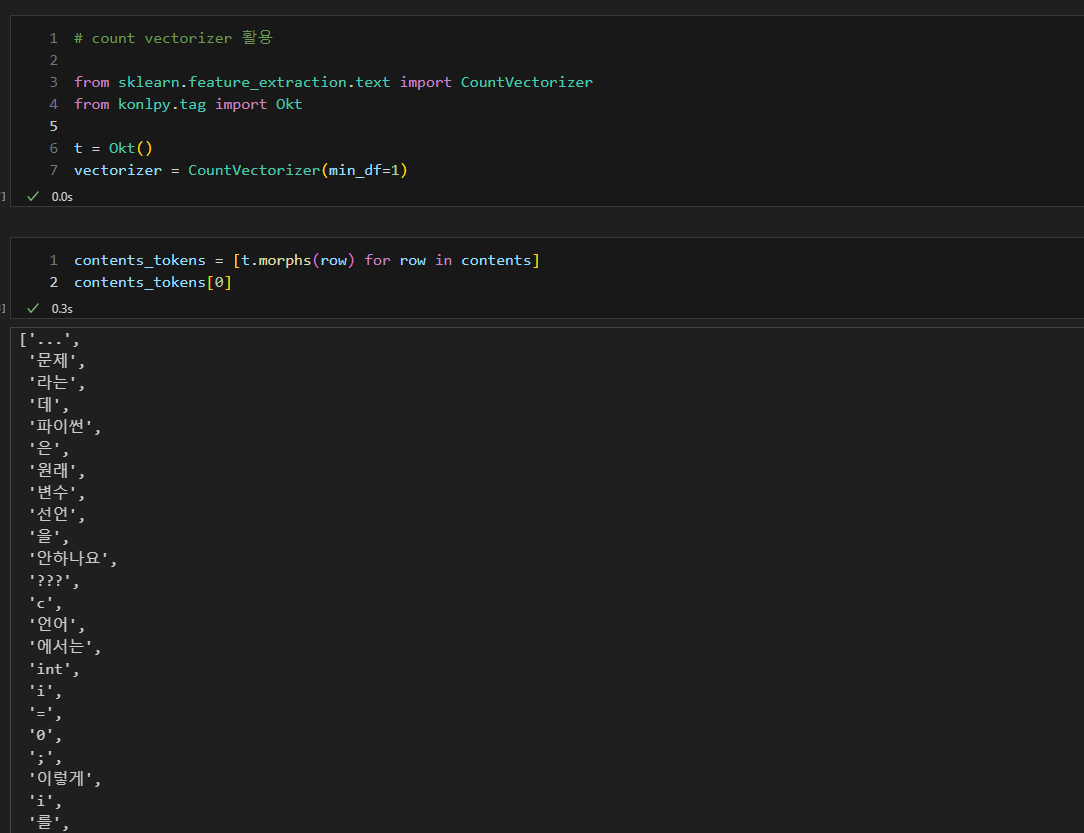
- 형태소 분석 후 원하는 vectorizer 사용하여 학습
- 토큰화, 문장 재조합, 학습 (벡터화)
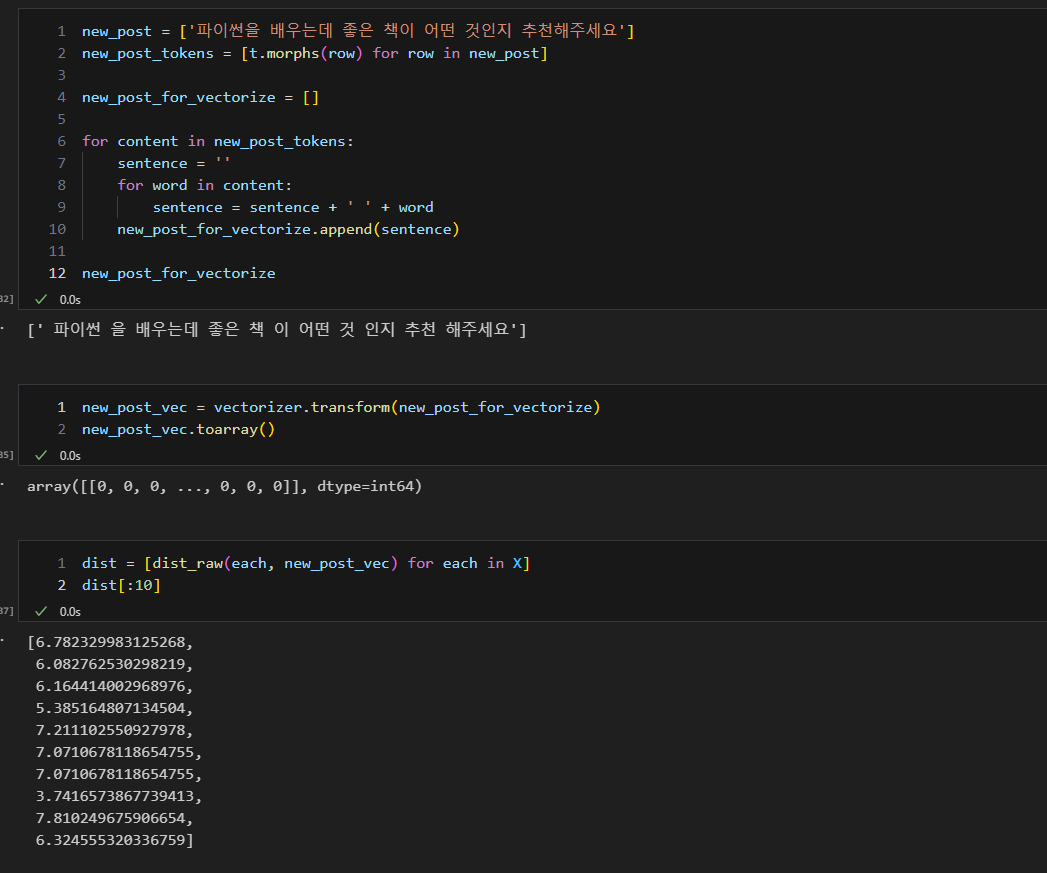
- 하고자 하는 질문을 new_post로 이용하여 비교
- 토큰화, 문장 재조합, 벡터화 (3. vectorizer 이용)
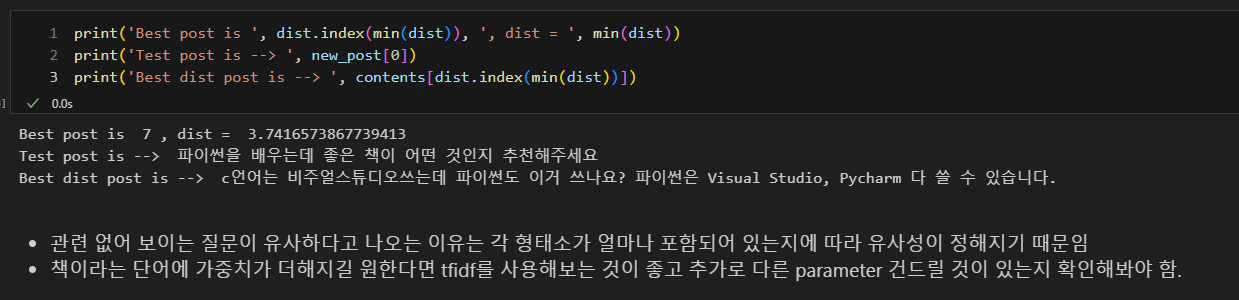
- 벡터 거리 비교하여 가장 비슷한 질문 발췌
- 거리 비교, 가장 짧은 거리 확인, 해당 인덱스 확인, 인덱스 이용하여 문장 참조
- API에 따라 필요한 함수 선언

새싹 데이터 분석가 https://github.com/KulangK