
1. K-means clustering
https://www.kaggle.com/uciml/breast-cancer-wisconsin-data
캐글의 Breast Cancer 데이터 셋으로 진행하였다.# 1. 데이터 label 값 추출 label = df.loc[:,['diagnosis']].rename(columns={'diagnosis':'label'}) # 2. label값과 클러스터링에 영향이 없는 컬럼 삭제 df.drop(['id', 'diagnosis', 'Unnamed: 32'], axis=1, inplace=True) # 3. 표준화 진행 scaler = StandardScaler() scaled_df = scaler.fit_transform(df) # 4. K_means 클러스터링 진행 kmeans = KMeans(n_clusters=2, random_state=31) kmeans.fit(scaled_df) # 5. 클러스터링이 진행된 label값 저장 label2 = pd.DataFrame(kmeans.labels_, columns=['clustered_label']) # 6. 클러스터링 된 label 값 기존 label 값과 동일하게 변경 label2 = label2.replace(0,'M') label2 = label2.replace(1,'B') label2.value_counts() # out: # clustered_label # M 380 # B 189 # dtype: int64 # 7. 정확도 측정 acc = (labels_df['label'] == labels_df['clustered_label']).sum() / len(labels_df) print("acc : {}".format(round(acc, 3)) # out: # acc : 0.905
2. Clustering이 진행된 label값 시각화 비교
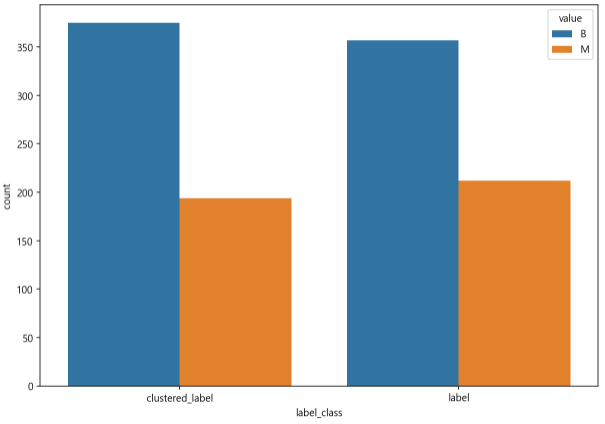
# 1. 수치 그래프 보기 위해 label값 결합 labels_df = pd.concat([label, label2], axis=1) # out: # label clustered_label # 0 M M # 1 M M # 2 M M # 2. 그래프화 하기 위한 1차 stack stacked = labels_df.stack().reset_index().rename(columns={0:'value'}) stacked.head(3) # out: # level_0 level_1 value # 0 0 label M # 1 0 clustered_label M # 2 1 label M # 3. 기존 인덱스열 지우기 stacked.drop('level_0', axis=1, inplace=True) stacked.head(3) # out: # level_1 value # 0 label M # 1 clustered_label M # 2 label M # 4. label 수치카운트를 위한 교차표 crosstab_df = pd.crosstab(stacked.level_1, stacked.value) crosstab_df # out: # value B M # level_1 # clustered_label 375 194 # label 357 212 # 5. 교차표 2차 stack stacked_2 = crosstab_df.stack().reset_index().rename(columns={'level_1' : 'label_class', 0 : 'count'}) stacked_2.head(3) # out: # label_class value count # 0 clustered_label B 375 # 1 clustered_label M 194 # 2 label B 357 # 6. bar plot으로 시각화 fig = plt.figure(figsize=(10, 7)) sns.barplot(x=stacked_2["label_class"], y=stacked_2['count'], hue=stacked_2['value']);out :

조금씩 천천히