
1. 결정 나무의 분류 (Decision Tree Classifier) with Pipe line
1-1. 파이프 라인으로 결정 나무 만들기
from category_encoders import OneHotEncoder from sklearn.impute import SimpleImputer from sklearn.tree import DecisionTreeClassifier from sklearn.pipeline import make_pipeline from sklearn.metrics import f1_score from warnings import filterwarnings filterwarnings('ignore') # pipeline 만들기 pipe = make_pipeline(OneHotEncoder(use_cat_names=True), SimpleImputer(strategy='mean'), DecisionTreeClassifier(criterion='gini', max_depth=10, random_state=2)) # 예측 pipe.fit(X_train, y_train) val_pred = pipe.predict(X_val) # f1 score print(f'검증세트의 f1_score : {f1_score(y_val, val_pred):.2f}') # score print(f'검증세트의 score : {pipe.score(X_val, y_val):.2f}') # # out: # 검증세트의 f1_score : 0.56 # 검증세트의 score : 0.82
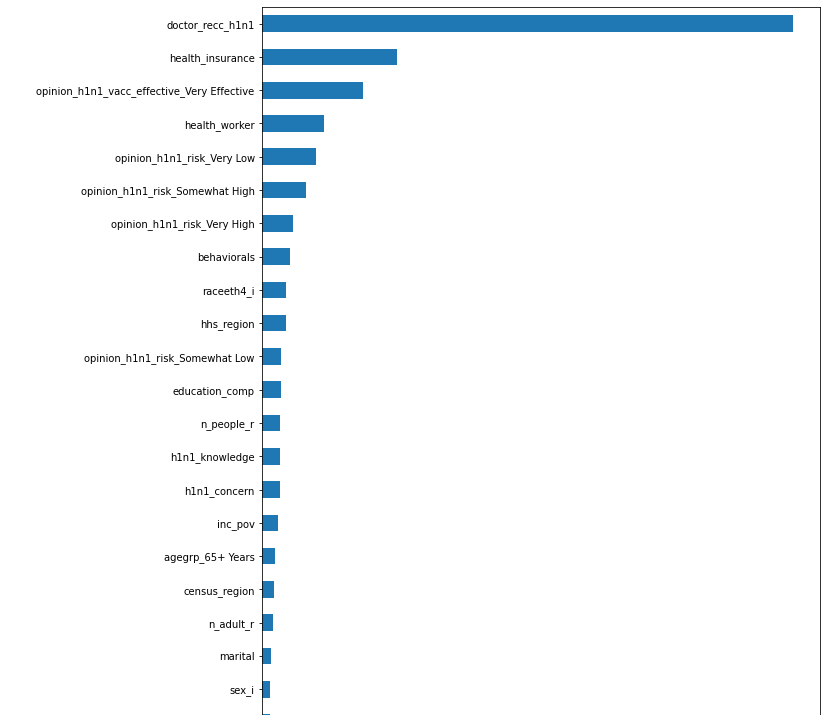
1-2. step 접근하여 feature importance 시각화
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline # pipe의 결정나무트리 가져오기 model_dt = pipe[2] # or pipe.named_steps['decisiontreeclassifier'] importance = model_dt.feature_importances_ # pipe의 원핫인코더 가져오기 enc = pipe[0] # or pipe.names_steps['onehotencoder'] encoded_cols = enc.transform(X_train).columns importances = pd.Series(importance, encoded_cols) plt.figure(figsize=(10, 30)) importances.sort_values().plot.barh();
2. Graphviz
import graphviz from sklearn.tree import export_graphviz model_dt = pipe.named_steps['decisiontreeclassifier'] enc = pipe.named_steps['onehotencoder'] encoded_columns = enc.transform(X_val).columns export_graphviz(model_dt , max_depth=3 , feature_names=encoded_columns , class_names=['no', 'yes'] , filled=True , proportion=True , out_file="tree.dot") with open("tree.dot") as f: dot_graph = f.read() display(graphviz.Source(dot_graph))
✅ Graphviz png 파일로 출력하기
dot = graphviz.Source(dot_graph) dot.format = 'png' dot.render(filename='tree.png')
3. SimpleImputer로 결측치 대체
from sklearn.impute import SimpleImputer imputer = SimpleImputer() # imputer를 통해 결측치 채워진 데이터 다시 데이터 프레임 만들기 X = imputer.fit_transform(X_train) X = pd.DataFrame(X) X.columns = X_train.columnsimputer의 매개변수
missing_value
default=np.nan
int, float, str 중 결측치로 지정할 값 입력strategy
mean : 각 컬럼의 평균값으로 대체 (수치형 데이터만 가능)
median : 각 컬럼의 중앙값으로 대체 (수치형 데이터만 가능)
most_frequent : 각 컬럼의 최빈값으로 대체 (수치, 문자형 데이터 모두 가능)
constant = fill_value 매개변수를 통해 대체할 값 지정하여 대체
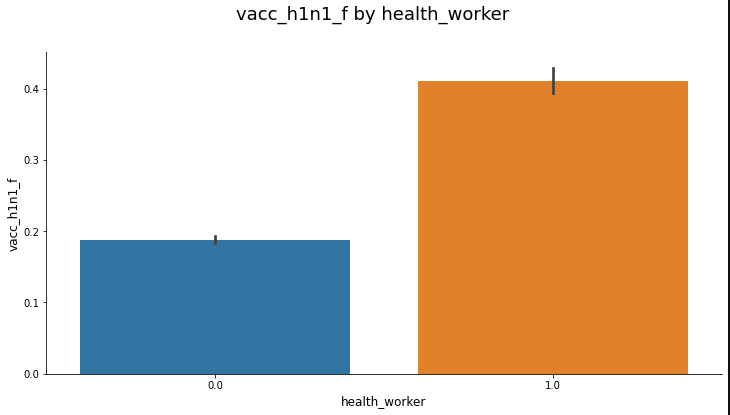
4. ETC (Cat plot 매개변수 설정)
a = sns.catplot(x='health_worker', y='vacc_h1n1_f', data=train, kind='bar', height=5, aspect=2) # height, ascpect로 사이즈 조정 # plt.figure(figsize=(x,y))를 통해서 되지 않음 a.fig.suptitle('vacc_h1n1_f by health_worker', fontsize=18, y=1.1) a.set_xlabels(fontsize=12) a.set_ylabels(fontsize=12) plt.show()

조금씩 천천히