
1. OrdinalEncoder
데이터는 아래와 같은 두가지 범주형 변주만 가져와서 쓰겠다.
df = X_train[['state', 'census_msa']]
encoder = OrdinalEncoder()
X = encoder.fit_transform(df)
X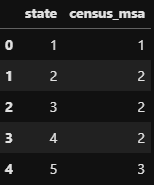
OrdinalEncoder는 범주형 변수를 순서형변수로 바꿔준다.
선형회귀와 같은 모델에서는 데이터를 OrdinalEncoder를 사용하게 되면 순서형 데이터는 Rank와 같은 의미를 띄기 때문에 특성을 다른 의미로 해석하게 된다. 하지만 Tree모델에서는 노드에서 True, False와 같은 이산형 결과를 내기 때문에 OnehotEncoder을 사용하는 것보다 특성의 설명력이 더 높아질 수 있다.
왜냐하면 많은 범주를 가지는 데이터의 경우 OneHotEncoder을 사용하게 되면 특성이 범주의 갯수만큼 분할된 이산형데이터를 갖기 때문에 트리에서 본래 특성의 중요도가 그만큼 나눠지게 된다. 하지만 OrdinalEncoder는 특성열을 순서형척도로 만들고 특성의 갯수를 증가시키지 않기 때문에 하나의 특성 안에서 설명이 가능하다.
2.TargetEncoder
위와 같은 데이터셋을 사용한다.
encoder = TargetEncoder()
X = encoder.fit_transform(df, target)
X = pd.concat([X, target],axis=1, ignore_index=True)
X.columns=['state', 'census_msa', 'target']
X.head(10)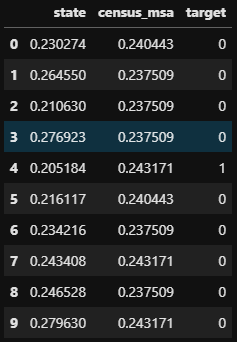
TargetEncoder
- 범주형 타겟의 경우
특정 범주 형 값이 주어진 대상의 사후 확률과 모든 훈련 데이터에 대한 대상의 사전 확률의 혼합 - 연속형 타겟의 경우
특정 범주 값이 주어진 목표의 예상 값과 모든 학습 데이터에 대한 목표의 예상 값의 혼합

조금씩 천천히