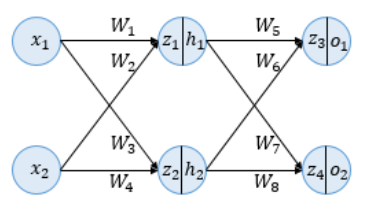
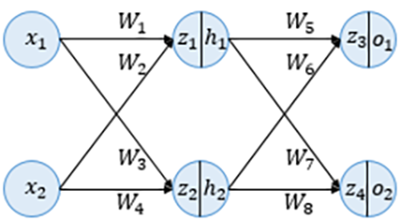
순전파 (Forward Propagation)
입력받은 데이터를 각 가중치와 곱하고 은닉층과 출력층의 활성화 함수를 통해 예측값을 출력한다.
이미지 출처 :
https://wikidocs.net/37406
활성화 함수는 시그모이드 함수로 정의함.
activation = 'sigmoid'
시그모이드 함수
sigmoid=S(x)=1+e−x1
첫번째로 입력층으로 입력된 데이터는 은닉층 방향으로 향하면서 가중치와 곱해져 시그모이드 함수의 입력값 z1, z2가 된다.
z1=W1x1+W2x2=0.3×0.1+0.25×0.2=0.08z2=W3x1+W4x2=0.4×0.1+0.35×0.2=0.11
가중합으로 계산된 z1, z2는 은닉층의 시그모이드 함수의 입력값이 되며 함수를 통해 출력되는 값이 은닉층의 최종 출력값 h1, h2가 된다.
h1=sigmoid(z1)=0.51998934h2=sigmoid(z2)=0.52747230
은닉층에서 출력된 h1, h2는 다시 출력층 방향으로 향하면서 가중치와 곱해지게 되고 출력층의 입력값 z3, z4가 된다.
z3z4=W5h1+W6h2=0.45×h1+0.4×h2=0.44498412=W7h1+W8h2=0.7×h1+0.6×h2=0.68047592
은닉층에서 출력층으로 향하면서 가중합으로 계산된 z3, z4는 출력층의 활성화 함수인 시그모이드의 입력값이 되고 함수를 통해 출력된 값은 최종 예측값이 된다.
o1o2=sigmoid(z3)=0.60944600=sigmoid(z4)=0.66384491
출력된 예측값에서 실제값과의 오차를 계산하기 위한 손실 함수(Loss function)로 평균 제곱 오차인 MSE 를 사용한다. 손실 함수를 통해서 우리는 예측값이 실제값과의 차이를 판단하여 모델 학습이 얼마나 잘 되었는지 판단할 수 있다. 식에서는 실제값은 target, 예측값은 output으로 표현된다. Eo1, Eo2 는 각각의 예측값과 실제값에 대한 오차이다.
Eo1=21(targeto1−outputo1)2=21(0.4−0.60944600)2=0.02193381Eo2=21(targeto2−outputo2)2=21(0.6−0.66384491)2=0.02193381
Eo1, Eo2인 각 오차의 합은 다음과 같다.
Etotal=Eo1+Eo2=0.02397190
위의 값을 토대로 역전파를 진행해보겠다.
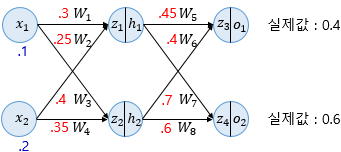
역전파 (Backpropagation)
역전파란 오차 역전파법 알고리즘이라고도 하며 동일 입력층에 대해 원하는 값이 출력되도록 각 계층의 가중치를 조정하는 방법이다. 예측값과 실제값의 차이인 오차를 계산하여 이것을 다시 역으로 전파하여 가중치를 조정한다.
이미지 출처 :
https://wikidocs.net/37406
역전파는 순전파의 반대방향으로 즉, 출력층에서 입력층까지 역으로 나아간다.
최종적으로 업데이트가 필요한 가중치는 W1, W2, W3, W4, W5, W6, W7, W8로 총 8개다.
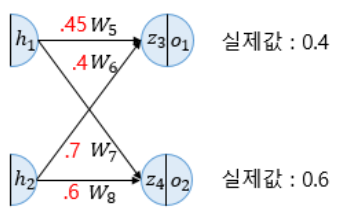
출력층부터 시작되기 때문에 먼저 업데이트 되는 가중치는 W4, W5, W6, W7, W8이다. 가중치를 업데이트 하기 위해서 경사 하강법을 사용한다.
가중치 W5를 업데이트 하기 위해서 W5에 대한 편미분을 계산해야 한다.
∂W5∂Etotal을 계산하기 위해서 연쇄법칙(chain rule)을 적용해서 풀 수 있다.
∂W5∂Etotal=∂o1∂Etotal×∂z3∂o1×∂W5∂z3
일단 첫번째로 Etotal은 순전파를 통해 출력된 전체 평균 오차 제곱합의 합이다. 식을 풀게 되면 다음과 같다.
Etotal=21(targeto1−outputo1)2+21(targeto2−outputo2)2
이 값을 o1에 대한 편미분을 하게 되면 다음과 같다.
∂o1∂Etotal=2×21(targeto1−outputo1)2−1×21(targeto22−2targeto2outputo2+outputo22)=(targeto1−outputo1)×(−1)+0=−(targeto1−outputo1)=−(0.4−0.60944600)=0.20944600
다음으로 z3의 편미분을 계산 한다.
편미분 하기 전에 o1의 식을 확인해면 다음과 같다.
o1=sigmoid(z3)
z3을 미분하려면 sigmoid 함수를 편미분 해야한다.
시그모이드 함수를 편미분 하게 되면 다음과 같다.
f(x)=1+e−x1=1+exex∂x∂f(x)=(1+ex)2ex⋅(1+ex)−ex⋅ex=(1+ex)2ex=f(x)(1−f(x))
시그모이드 함수의 편미분 식을 통해서 z3를 편미분한 식은 다음과 같다.
∂z3∂o1=o1×(1−o1)=0.60944600(1−0.60944600)=0.23802157
마지막으로 W5의 편미분을 하기 전 z3의 수식을 돌아보면 다음과 같다.
z3=W5h1+W6h2=0.45×h1+0.4×h2
위 식을 바탕으로 W5에 대해 편미분을 하게되면 W6는 상수취급되어 사라지고 W5가 0승이 되어 사라지기 떄문에 결과적으로 h1만 남게 된다.
식은 다음과 같다.
∂W5∂z3=h1=0.51998934
h1값은 알고 있기 때문에 바로 답을 구할 수 있었다.
모든 값을 구했기 때문에 결과적으로 ∂W5∂Etotal 값을 구할 수 있게 되었다.
∂W5∂Etotal=0.20944600×0.23802157×0.51998934=0.02592286
이제 경사하강법을 이용하여 가중치를 업데이트 하게 되는데 학습률(learning rate) α는 0.5로 설정하겠다.
W5+=W5−α∂W5∂Etotal=0.45−0.5×0.02592286=0.43703857
W5의 가중치가 다음과 같은 방법으로 업데이트 되는 것을 확인할 수 있다.
나머지의 W6, W7, W8 을 업데이트 하면 다음과 같다.
∂W6∂Etotal=∂o1∂Etotal×∂z3∂o1×∂W6∂z3→W6+=0.38685205∂W7∂Etotal=∂o2∂Etotal×∂z4∂o2×∂W7∂z4→W7+=0.69629578∂W8∂Etotal=∂o2∂Etotal×∂z4∂o2×∂W8∂z4→W8+=0.59624247
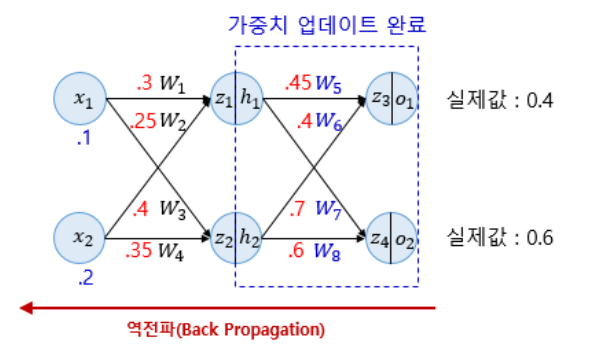
모두 업데이트가 되었다면 은닉층으로 넘어가서 W1, W2, W3, W4를 업데이트 해보겠다. 아래의 그림은 위에서 업데이트 된 가중치로 바뀐 것을 표현한 것이다.
이미지 출처 :
https://wikidocs.net/37406
먼저 W1을 업데이트 해보겠다. 위의 했던 과정과 동일하게 편미분을 진행한다.
∂W1∂Etotal=∂h1∂Etotal×∂z1∂h1×∂W1∂z1
우측항의 첫번째 식은 다음과 같다.
∂h1∂Etotal=∂h1∂Eo1+∂h1∂Eo2
위 식에서 우측 첫번째 식에 대해서 분해하여 계산하게 되면 다음과 같다.
∂h1∂Eo1=∂z3∂Eo1×∂h1∂z3=∂o1∂Eo1×∂z3∂o1×∂h1∂z3=−(targeto1−outputo1)×o1×(1−o1)×W5=0.20944600×0.23802157×0.45=0.2243370
위와 같은 원리로 ∂h1∂Eo2을 구하는 식은 다음과 같다.
∂h1∂Eo2=∂z4∂Eo2×∂h1∂z4=∂o2∂Eo2×∂z4∂o2×∂h1∂z4=0.00997311
이제 ∂h1∂Etotal를 구할수 있다.
∂h1∂Etotal=0.02243370+0.00997311=0.3240681
다음으로 ∂z1∂h1에 대해서의 편미분을 구하게 되면 위에서 보았던 sigmoid 함수의 편미분과 같다.
∂z1∂h1=h1×(1−h1)=0.51998934(1−0.51998934)=0.24960043
제일 우측항이었던 ∂W1∂z1 을 구하게 되면 아래의 식과 같다.
z1=W1x1+W2x2=0.3×0.1+0.25×0.2=0.08∂W1∂z1=x1=0.1
따라서 업데이트 하기 위한 ∂W1∂Etotal은 다음과 같은 식이 된다.
∂W1∂Etotal=0.03240681×0.24960043×0.1=0.00080888
이제 경사 하강법을 이용해 W1을 업데이트 한다.
W1+=W1−α∂W1∂Etotal=0.1−0.5×0.00080888=0.29959556
위와 같은 원리로 W2, W3, W4도 업데이트할 수 있다.
∂W2∂Etotal=∂h1∂Etotal×∂z1∂h1×∂W2∂z1→W2+=0.24919112∂W3∂Etotal=∂h2∂Etotal×∂z2∂h2×∂W3∂z2→W3+=0.39964496∂W4∂Etotal=∂h2∂Etotal×∂z2∂h2×∂W4∂z2→W4+=0.34928991
마지막으로 순전파를 업데이트된 가중치를 통해 진행하여 오차가 감소하였는지 확인해보겠다.
이미지 출처 :
https://wikidocs.net/37406
z1=W1x1+W2x2=0.29959556×0.1+0.24919112×0.2=0.07979778z2=W3x1+W4x2=0.39964496×0.1+0.34928991×0.2=0.10982248h1=sigmoid(z1)=0.51993887h2=sigmoid(z2)=0.52742806z3=W5h1+W6h2=0.43703857×h1+0.38685205×h2=0.43126996z4=W7h1+W8h2=0.67629578×h1+0.59624247×h2=0.67650625o1=sigmoid(z3)=0.60617688o2=sigmoid(z4)=0.66295848Eo1=21(targeto1−outputo1)2=0.02125445Eo2=21(targeto2−outputo2)2=0.00198189Etotal=Eo1+Eo2=0.02323634
기존의 전체 오차가 0.02397190이였으므로 역전파를 통해 오차가 0.00073556 감소한 것을 확인할 수 있다.
인공신경망의 학습은 순전파와 역전파를 반복하며 오차를 최소화하는 가중치를 찾는다.