CNN(컨볼루션 신경망)
-
Convolution Layer
- 컨볼루션 레이어는 입력 이미지를 Kernel(Filter)을 이용하여 탐색하면서 이미지의 특징들을 추출하고, 추출한 특징들을 Feature Map으로 생성한다.
- Feature Map은 Kernel의 크기와 같다.
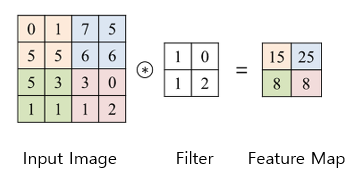
- CNN은 이런 컨볼루션 레이어를 여러 번 중첩해서 사용하는데, 이 경우 커널로 인하여 입력 이미지의 결과가 너무 작아지는 문제가 발생한다. 이를 방지하기 위해 Padding이라는 기법을 사용한다.
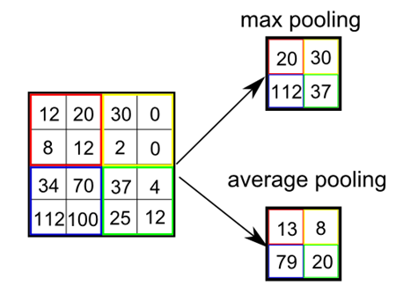
- Pooling Layer
- 풀링 레이어는 컨볼루션 레이어 다음에 주로 배치되는 레이어다.
- 풀링 레이어는 범위 내의 픽셀 중 대표값을 추출하는 방식으로 특징을 추출한다.
- Max Pooling, Average Pooing, Min Pooling 세 가지 방식으로 대표값을 추출할 수 있다.
- Fully Connected Layer
- Fully Connected Layer(FCL)은 이미지를 분류하는 인공신경망이다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.optimizers import SGD, Adam, Adagrad, RMSprop
#MNIST 데이터셋을 읽어와 신경망에 입력할 형태로 변환
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 28, 28, 1) #텐서 모양 변환
x_test = x_test.reshape(10000, 28, 28, 1)
x_train = x_train.astype(np.float32)/255.0 #ndarray로 변환
x_test = x_test.astype(np.float32)/255.0
y_train = tf.keras.utils.to_categorical(y_train, 10) #원핫 코드로 변환
y_test = tf.keras.utils.to_categorical(y_test, 10)
#Lenet-5 신경망 모델 설계
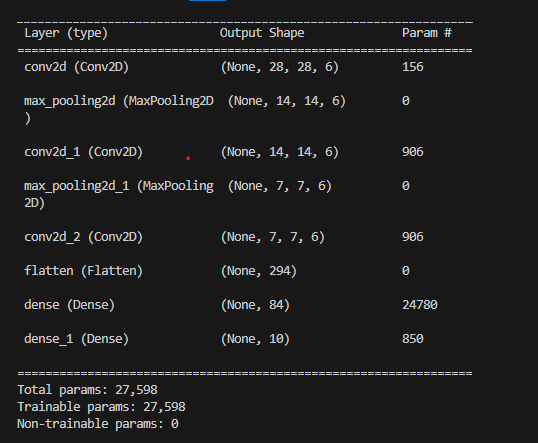
cnn = Sequential()
cnn.add(Conv2D(6,(5,5), padding='same', activation='relu', input_shape=(28, 28, 1)))
cnn.add(MaxPooling2D(pool_size=(2,2)))
cnn.add(Conv2D(6,(5,5), padding='same', activation='relu')) #Convolution
cnn.add(MaxPooling2D(pool_size=(2,2))) #pooling
cnn.add(Conv2D(6,(5,5), padding='same', activation='relu'))
cnn.add(Flatten())
cnn.add(Dense(84, activation='relu')) #Fully connected
cnn.add(Dense(10, activation='softmax')) #0~9까지의 숫자 10개 분류
#신경망 모델 학습
cnn.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
hist = cnn.fit(x_train, y_train, batch_size= 128, epochs= 30, validation_data=(x_test, y_test), verbose=2)
#신경망 모델 평가
res = cnn.evaluate(x_test, y_test, verbose=0)
print("정확률은", res[1]*100)
#정확률 그래프
plt.plot(hist.history['accuracy'],)
plt.plot(hist.history['val_accuracy'],)
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='best')
plt.grid()
plt.show()
#손실 함수 그래프
plt.plot(hist.history['loss'],)
plt.plot(hist.history['val_loss'],)
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='best')
plt.grid()
plt.show()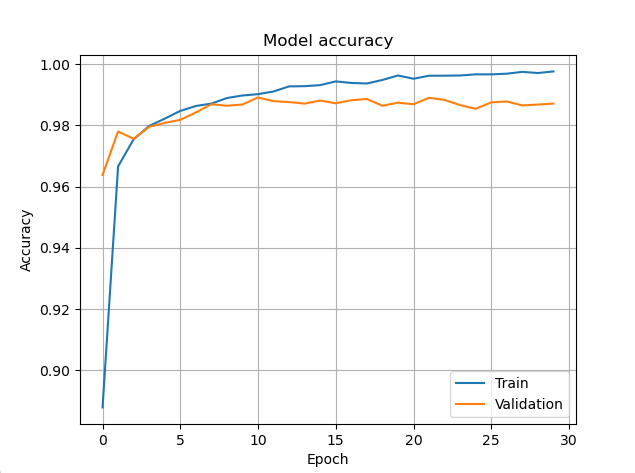
Epoch 15/30
469/469 - 8s - loss: 0.0201 - accuracy: 0.9931 - val_loss: 0.0370 - val_accuracy: 0.9881 - 8s/epoch - 17ms/step
Epoch 16/30
469/469 - 8s - loss: 0.0184 - accuracy: 0.9944 - val_loss: 0.0449 - val_accuracy: 0.9872 - 8s/epoch - 17ms/step
Epoch 17/30
469/469 - 8s - loss: 0.0177 - accuracy: 0.9938 - val_loss: 0.0410 - val_accuracy: 0.9882 - 8s/epoch - 17ms/step
Epoch 18/30
469/469 - 8s - loss: 0.0173 - accuracy: 0.9937 - val_loss: 0.0427 - val_accuracy: 0.9886 - 8s/epoch - 17ms/step
Epoch 19/30
…
Epoch 26/30
469/469 - 8s - loss: 0.0095 - accuracy: 0.9966 - val_loss: 0.0467 - val_accuracy: 0.9875 - 8s/epoch - 17ms/step
Epoch 27/30
469/469 - 8s - loss: 0.0090 - accuracy: 0.9969 - val_loss: 0.0515 - val_accuracy: 0.9878 - 8s/epoch - 17ms/step
Epoch 28/30
469/469 - 8s - loss: 0.0080 - accuracy: 0.9975 - val_loss: 0.0509 - val_accuracy: 0.9865 - 8s/epoch - 17ms/step
Epoch 29/30
469/469 - 8s - loss: 0.0087 - accuracy: 0.9971 - val_loss: 0.0563 - val_accuracy: 0.9868 - 8s/epoch - 17ms/step
Epoch 30/30
469/469 - 8s - loss: 0.0077 - accuracy: 0.9976 - val_loss: 0.0578 - val_accuracy: 0.9871 - 8s/epoch - 17ms/step
정확률은 98.71000051498413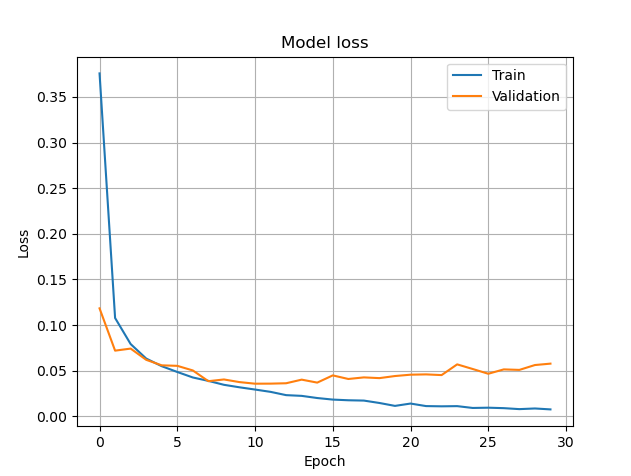

- 첫 번째 컨볼루션 연산:
- 입력 피쳐맵 크기: 28x28
- 필터 크기: 5x5
- 출력 피쳐맵 크기: 28x28 (padding='same'으로 인해 입력과 동일한 크기를 유지)
- 컨볼루션 결과에 ‘relu’함수 적용
- 첫 번째 MaxPooling2D 풀링 연산:
- 입력 피쳐맵 크기: 28x28
- 풀링 크기: 2x2
- 출력 피쳐맵 크기: 14x14 (크기가 반으로 줄어듦)
- 두 번째 컨볼루션 연산:
- 입력 피쳐맵 크기: 14x14
- 필터 크기: 5x5
- 출력 피쳐맵 크기: 14x14 (padding='same'으로 인해 입력과 동일한 크기를 유지)
- 컨볼루션 결과에 ‘relu’함수 적용
- 두 번째 MaxPooling2D 풀링 연산:
- 입력 피쳐맵 크기: 14x14
- 풀링 크기: 2x2
- 출력 피쳐맵 크기: 7x7 (크기가 반으로 줄어듦)
- 세 번째 컨볼루션 연산:
- 입력 피쳐맵 크기: 7x7
- 필터 크기: 5x5
- 출력 피쳐맵 크기: 7x7 (padding='same'으로 인해 입력과 동일한 크기를 유지)
- 컨볼루션 결과에 ‘relu’함수 적용
models
- Sequential: 맨 왼쪽에 텐서를 입력하고 순차적으로 층이 흐르다가 오른쪽 끝에 있는 층에서 출력 텐서를 내보낸다.
- functional API: 텐서가 흐르다가 중간에서 여러 개로 갈라져 출력층이 여러 개이다.
ex)시계열 데이터
딥러닝의 규제: 과적합 방지
- 데이터 증대
- 주어진 데이터를 적절하게 변형해 인위적으로 증대
- 드롭아웃
- 과잉 적합을 해소하기 위해 일정 비율의 가중치를 학습에 참여하지 못 하게 덜어냄
- ex) Dropout(0.25) ⇒ 전체 가중치의 25%를 학습하지 않음.
- 가중치 감소
- 학습 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 패널티를 부과하여 오버피팅을 억제하는 방법
- Weight Decay를 통해서 Weight의 학습 반경을 변경시킨다.
# Weight Decay를 전체적으로 반영한 예시 코드 from tensorflow.keras.constraints import MaxNorm from tensorflow.keras import regularizers # 모델 구성을 확인합니다. model = Sequential([ Flatten(input_shape=(28, 28)), Dense(64, input_dim=64, kernel_regularizer=regularizers.l2(0.01), # L2 norm regularization activity_regularizer=regularizers.l1(0.01)), # L1 norm regularization Dense(10, activation='softmax') ])

코딩코