
마르코프 결정 프로세스
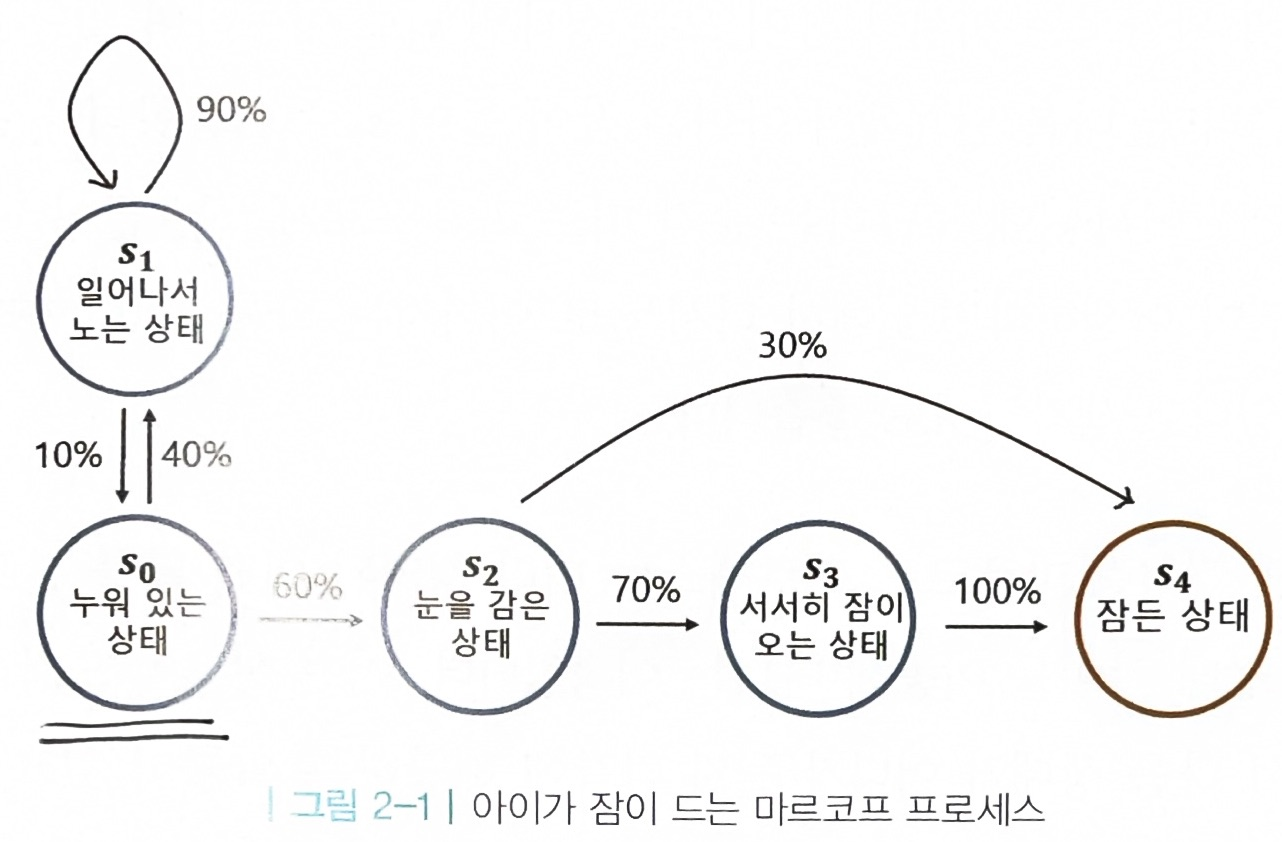
1. 마르코프 프로세스: 미래는 현재에 의해서만 결정됨
- 상태
- 상태 전이: 현재 상태에서 다음 상태로 넘어
- 종료 상태: 마르코프 프로세스의 끝
- 전이 확률: 상태 s에서 다음 상태 s’에 도착할 확률
- 전이 확률 행렬: 전이 확률을 행렬로 표현
- 전이 확률 행렬: 전이 확률을 행렬로 표현

2.마르코프 리워드 프로세스(MRP): 보상의 개념 추가
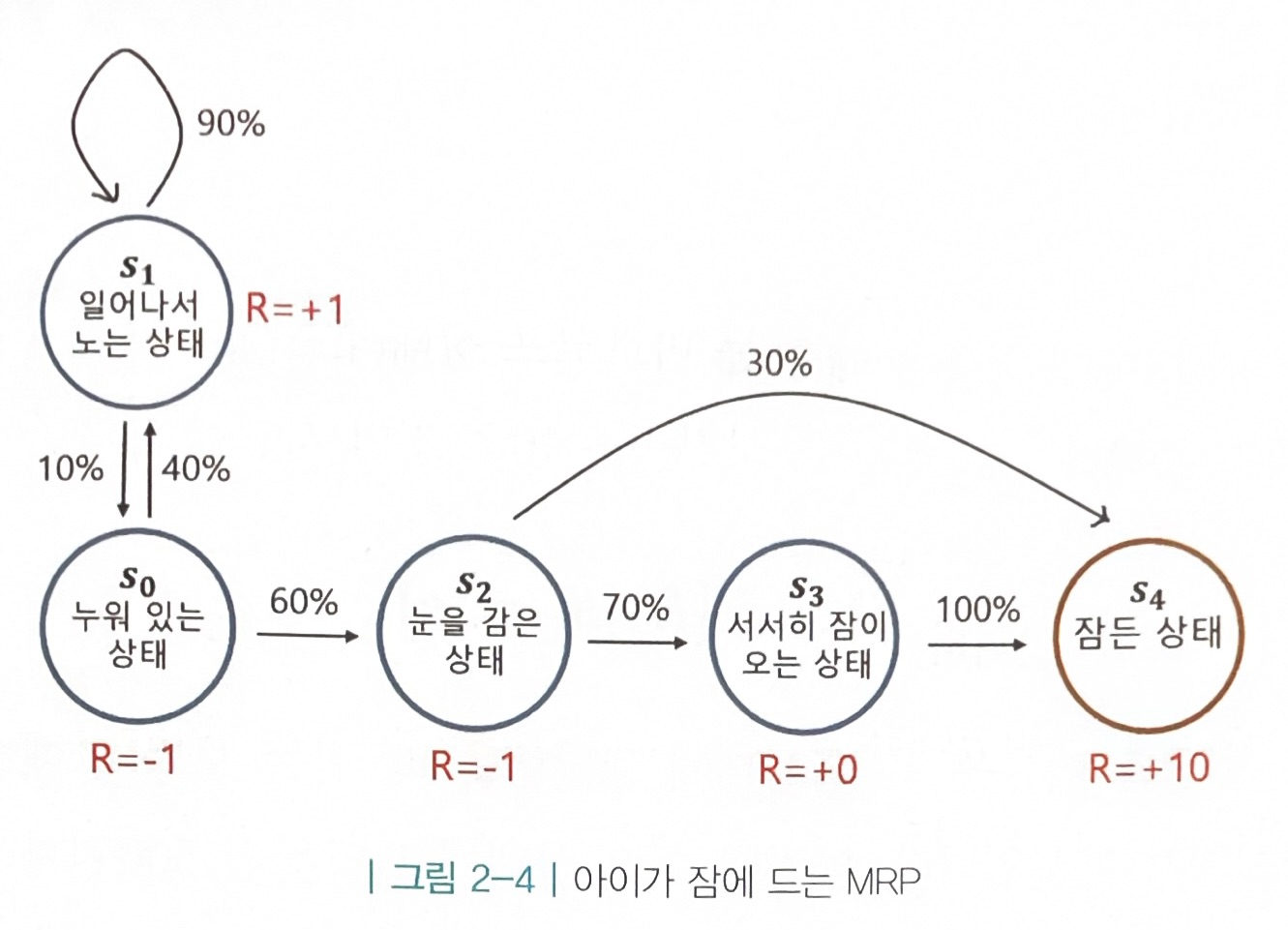
- 보상 함수 R : 어떤 상태 S에 도착했을 때 받게 되는 보상 R
- 감쇠 인자 γ: 당장 얻는 가치에 비해 미래에 얻는 가치를 떨어뜨림
- 리턴 Gt : t 시점부터 미래에 받을 감쇠된 보상의 합
⇒강화 학습은 보상이 아니라 리턴을 최대화하도록 학습하는 것
3.마르코프 결정 프로세스
- MDP = MRP + 에이전트
- 액션 집합 A 추가
- MDP는 환경에 의해 같은 상태에서 같은 액션을 해도 확률적으로 다음 상태가 달라질 수 있다.
- 전이 확률 행렬: 현재 상태가 s이고, 에이전트가 액션 a를 선택했을때 다음 상태가 s’이 될 확률
(액션을 포함한 전이 확률 행렬 그리는 법)$$ P_{ss'}^a $$
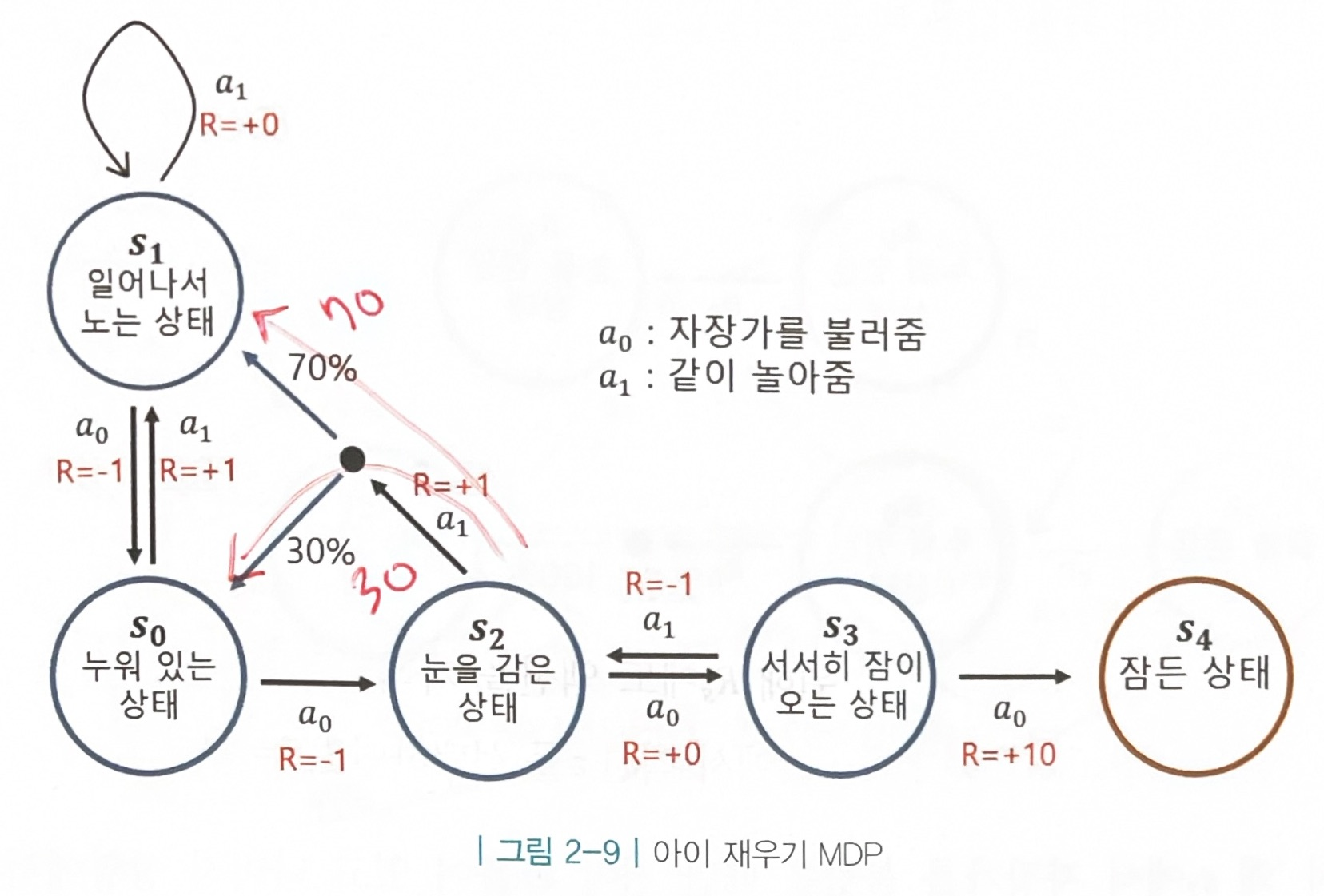
- 정책: 각 상태 s에 따라 어떤 액션 a를 선택해야 보상의 합을 최대로 할 수 있는가
- 정책 함수: 각 상태 s에서 어떤 액션 a를 선택할지 정해주는 함수.
- 상태 s에서 액션 a를 선택할 확률
- 각 확률의 합은 1
- 정책 함수는 에이전트 안에 존재
- 더 큰 보상을 얻기 위해 계속해서 정책을 교정해 나가는 것이 강화 학습 ⇒최적 정책(모든 정책중 가장 기대 리턴이 큰 정책)을 찾아 나가는 것
상태 가치 함수: 어떤 상태 s를 평가해주는 함수
- 상태의 가치를 나타내는 함수 v(s)
-
가치 함수를 정의하기 전, 먼저 정책 함수 π가 정의되어야 함.
-
정책 함수 π가 주어졌다고 가정했을 때:
-
정책 π일 때 상태 s로부터 시작하여 얻는 리턴의 기댓값
-
가치 함수는 정책 함수 π에 의존적
-
액션 가치 함수: 어떤 상태 s에서 액션 a를 평가해주는 함수
- 상태s에서의 액션 a의 가치를 나타내는 함수 q(s,a)
-
상태에 따라 액션의 결과가 달라져서 상태 s를 포함
-
정책 함수 π가 주어졌다고 가정했을 때:
-
s에서 a를 선택하고, 그 이후에는 정책 π를 따라 움직일 때 얻는 리턴의 기댓값
-
“일단 액션 선택” 후 정책 함수 따라 이동
-
최적 가치 함수(v*):
- v: 최적 정책(π)을 따를 때의 가치 함수

코딩코