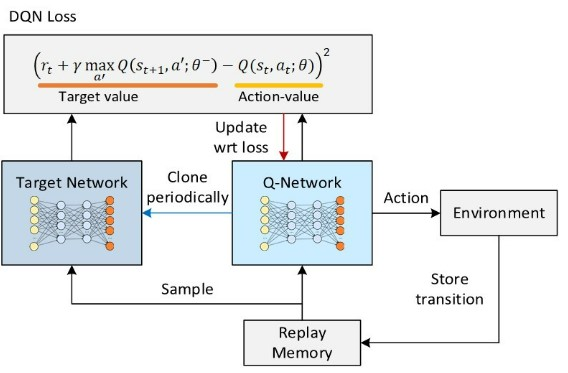
DQN에서 학습 안정화와 성능 향상을 위해 사용하는 두 가지
- 익스피리언스 리플레이
- 타깃 네트워크
익스피리언스 리플레이
- 에피소드는 여러 개의 상태 전이로 이루어져 있다.
- 상태 전이: “상태 St에서 액선 At를 했더니 보상 Rt를 받고 다음 상태 St+1에 도착”
- 하나의 상태 전이는 곧 하나의 데이터
- 리플레이 버퍼:
- 버퍼에 가장 최근의 데이터 n개를 저장해 놓음
- 학습 할 때 이 버퍼에서 임의로 데이터를 뽑아서 사용 (데이터 재사용)
- 32개씩 뽑아서 미니 배치를 만들어서 학습하는 방식
- 미니 배치 안의 서로 다른 게임에서 발생한 다양한 데이터들이 섞이는데, 각각 데이터 사이 상관성이 작아짐
- ⇒ 효율성 향상
타깃 네트워크
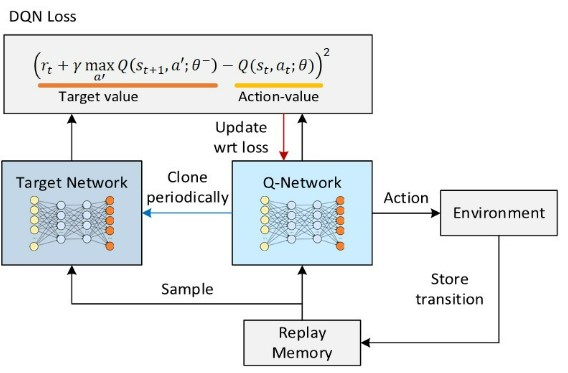
- 손실 함수: 정답과 추측 사이의 차이 ⇒ 이 차이를 줄이는 방향으로 파라미터 업데이트
- 벨만 방정식에 들어가는 값인 파라미터가 업데이트 될 때마다 값이 계속 변해서 안정적인 학습에 해가 됨
- 그래서 두 개의 네트워크를 준비하여
- 한 네트워크는 파라미터를 고정, 다른 네트워크는 계속 업데이트 (이 때 계산은 고정된 파라미터로 계산)
- 일정 주기마다 고정된 파라미터 업데이트
(고정된 파라미터의 네트워크 = 타깃 네트워크)
- (정답 - 추측)
- 정답 : 파라미터에 의존적인 식 ⇒ 불안정한 학습
- 타깃 네트워크를 통해 정답식의 파라미터를 고정 ⇒ 안정적인 학습!

코딩코