알파고와 MCTS
알파고: 학습 + 실시간 플래닝
- 학습: 알파고가 이세돌을 만나기 전에 이루어지는 과정
- 실시간 플래닝: 이세돌과의 대국 도중에 실시간으로 어디에 바둑알을 놓을지 고민하는 과정
- MCTS(Monte Carlo Tree Search): 실시간 플래닝 알고리즘
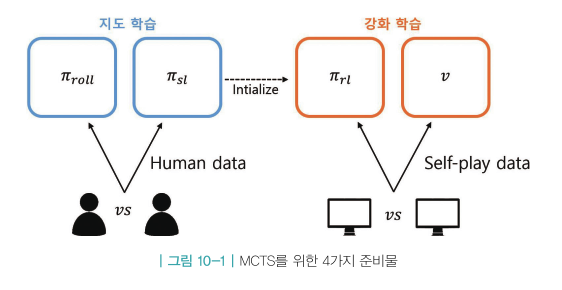
학습 단계
- MCTS에서 쓰일 재료들을 만드는 과정
- 사람의 기보를 이용해 지도 학습한 정책
- 롤아웃 정책
- 스스로 대국하며 강화학습한 정책
- 밸류 네트워크
지도 학습(무거움)
- 6단 이상의 기사가 플레이한 데이터를 사용
- 바둑판의 상태 정보 s가 인풋으로 들어오면 총19x19=361개의 바둑 칸들 중 현재 둘 수 있는 곳에 대해 실제로 돌을 내려놓을 확률 리턴
- 13층의 컨볼루션 레이어
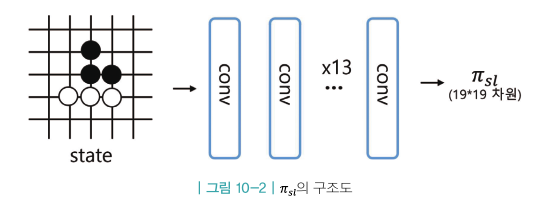
- 학습 결과: 57%의 정답률
- 사람 5단 정도의 실력
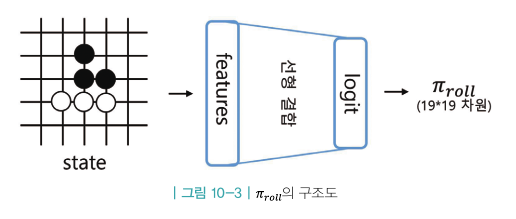
롤아웃 정책(가벼움)
- 위 지도 학습 정책의 가벼운 버전
- 마찬가지로 사람의 기보 데이터 이용해 지도 학습으로 만들어짐
- 대신 뉴럴넷이 훨씬 작고 가벼운 네트워크
- 13층의 컨볼루션 레이어가 아니라 사람 지식을 이용하여 만든 수많은 feature에 대한 선형결합 레이어 하나만 존재
- ⇒ 속도가 빠름 / 성능 부족
- ⇒ 정확도 24.2%
강화학습 정책
- 지도 학습과 완벽히 똑같이 생긴 뉴럴 네트워크
- 지도 학습의 파라미터를 이용해 초기화
- 초기에는 완전히 같은 네트워크이나 강화학습 정책은 self-play를 통해 계속해서 강화됨
- REINFORCE 알고리즘 사용
- ⇒80%의 승률 달성
밸류 네트워크
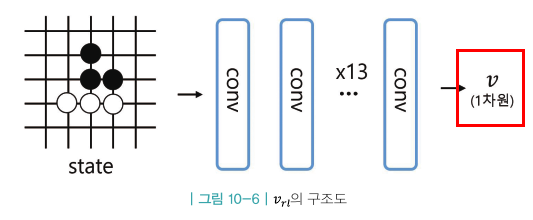
- 각 상태의 밸류를 리턴(1차원)
- V(S) :주어진 상태 s부터 시작해서 강화학습 정책을 이용하여 플레이했을때 이길지 여부를 예측하는 함수
- 손실함수 : MSE

코딩코