핵심 Method 요약
Input/Output
- Input: 텍스트 쿼리 + 멀티모달 비디오 콘텐츠 (비디오 프레임, 음성 전사, 화면상 텍스트, 메타데이터)
- Output: 관련성 점수 기반 검색 결과
- Transformation: 멀티모달 콘텐츠 → 통합 인코딩 → Late-interaction 유사도 계산 → 관련성 스코어
알고리즘 구조
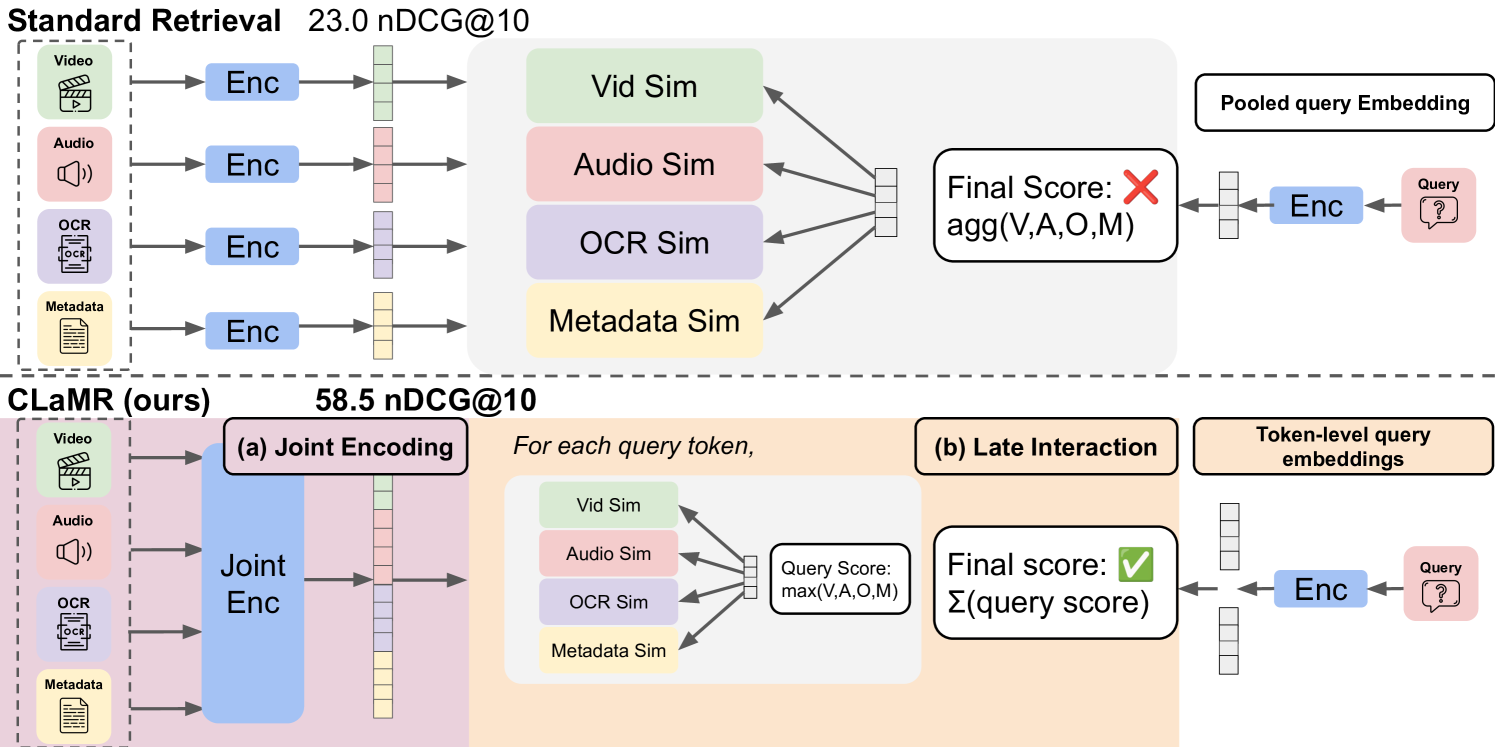
- Joint Multimodal Encoding: Vision-Language Model을 통한 모든 모달리티 통합 인코딩
- Late-Interaction Mechanism: 토큰 레벨에서 세밀한 유사도 계산
- Modality-Aware Training: 모달리티별 동적 선택을 위한 대조 학습
핵심 수식
- Contextualized Late-Interaction
- Modality-Wise Late-Interaction:
- InfoNCE Loss:
Key Point: 통합 인코딩과 토큰 레벨 상호작용을 통한 동적 모달리티 선택
1. 연구 배경 및 동기
기존 멀티모달 검색의 한계
기존의 멀티모달 비디오 검색 시스템들은 여러 근본적인 문제점을 가지고 있다.
독립적 모달리티 처리의 문제점
- 각 모달리티(비디오, 음성, OCR, 메타데이터)를 별도로 인코딩
- 단순한 점수 집계 방식(평균, 최댓값, RRF 등) 사용
- 관련 없는 모달리티의 노이즈가 전체 성능을 저하시킴
컨텍스트화 부족
- 모달리티 간의 상호작용과 맥락 정보 손실
- 쿼리에 따른 동적 모달리티 선택 능력 부재
- Cross-modal 의존성을 효과적으로 모델링하지 못함
훈련 데이터의 한계
- 모달리티별 특화 쿼리의 부족
- 동적 모달리티 선택을 학습할 수 있는 대규모 데이터셋의 부재
연구의 핵심 질문
"멀티모달 비디오 콘텐츠에서 쿼리에 따라 가장 관련성이 높은 모달리티를 동적으로 선택하여 검색 성능을 향상시킬 수 있는가?"
→ Contextualized Late-Interaction과 모달리티 인식 훈련을 통해 해결하자!
2. Method
전체 아키텍처 개요
Stage 1: Contextualized Joint Encoding
- 모든 모달리티를 하나의 Vision-Language Model로 통합 인코딩
- 모달리티 간 상호작용과 컨텍스트 정보 보존
- 각 토큰과 패치에 대한 contextualized representation 생성
Stage 2: Modality-Aware Late-Interaction
- 토큰 레벨에서 세밀한 유사도 계산
- 쿼리별로 가장 관련성 높은 모달리티 동적 선택
- 모달리티별 점수 계산 후 최대값 선택
Contextualized Multimodal Encoder
Vision-Language Model 활용
- Qwen-VL-2.5-3B를 백본으로 사용
- 모든 입력 모달리티를 하나의 시퀀스로 연결
- Visual inputs → Textual inputs 순서로 배치
- 128차원 projection layer를 통한 임베딩 공간 통합
Omni-Model 확장
- Qwen-Omni-3B를 이용한 실험
- 텍스트 변환 없이 원시 오디오 직접 처리
- 더 자연스러운 음성 신호 활용 가능
Late-Interaction 메커니즘
기존 방식과의 차이점
- 기존: Pooled embedding 간의 cosine similarity 계산
- CLAMR: 모든 쿼리 토큰과 문서 토큰 간 토큰 레벨 매칭
Contextualized Late-Interaction
- 모든 모달리티를 concatenate한 후 late-interaction 수행
- 전체적인 맥락 정보 활용
Modality-Wise Late-Interaction
- 각 모달리티별로 separate late-interaction 계산
- 가장 높은 점수를 가진 모달리티 선택
훈련 목표: Modality-Aware Contrastive Learning
InfoNCE Loss 기반
- 표준 대조 학습으로 올바른 문서 검색 학습
- Positive pair는 가까이, negative pair는 멀리 배치
모달리티 인식 훈련의 필요성
- 단순한 contextualized late-interaction은 모달리티 선택 학습에 어려움
- 동시에 문서 구분과 모달리티 구분을 학습해야 하는 복잡성
- Modality-wise approach로 단계적 학습 가능
3. MULTIVENT 2.0++: 합성 훈련 데이터
기존 데이터의 한계
MULTIVENT 2.0의 문제점
- 101K 비디오 중 대부분이 쿼리 없음
- 단 1,504개의 annotated 쿼리만 존재
- 모달리티별 특화 쿼리 부족
- 동적 모달리티 선택 학습에 부적합
합성 쿼리 생성 전략
모달리티별 쿼리 생성 파이프라인
- 각 비디오에서 ASR, OCR, 메타데이터 추출
- 인간이 작성한 10개 예시를 in-context learning으로 활용
- Gemma-3-27b-it 모델로 모달리티별 쿼리 생성
- 각 쿼리가 특정 모달리티에서만 답변 가능하도록 설계
생성된 데이터 규모
- 총 371,644개의 query-document pairs
- 91K 비디오에 대한 모달리티별 쿼리
- 훈련용 367,644개, 검증용 4,000개 분할
품질 보장 방법
- 다국어 콘텐츠에 대한 강력한 처리 능력
- 자연스럽고 관용적인 영어 쿼리 생성
- 모달리티 간 일부 중복 허용으로 실제적인 검색 환경 모사
4. 실험 설계 및 결과 분석
데이터셋
MULTIVENT 2.0++
- 훈련: 367,644개 합성 query-document pairs
- 테스트: 1,504개 human-annotated pairs (원본 MULTIVENT 2.0)
- 다양한 언어와 이벤트 중심 비디오 콘텐츠
MSR-VTT
- 표준 text-video retrieval 벤치마크
- 10K 예시를 9K (훈련) + 1K (평가)로 분할
- 기존 연구와의 비교 가능성 확보
평가 지표 및 Baseline
평가 메트릭
- Recall@k: top-k 결과에 관련 항목 포함 여부
- nDCG@10: 관련성과 순위를 동시에 고려한 종합 평가
Single-Modality Baselines
- Multilingual CLIP (mCLIP) 각 모달리티별 적용
- ImageBind, LanguageBind (비전 모달리티만)
Multi-Modality Baselines
- ImageBind, LanguageBind (평균 집계)
- GPT-4.1 기반 Router 방식
- Qwen-VL-2.5 pooled representation (동일 백본 비교군)
실험 결과
MULTIVENT 2.0++에서의 성능
| Method | Modality | R@1 | R@5 | R@10 | nDCG@10 |
|---|---|---|---|---|---|
| Single-Modality (Best) | |||||
| LanguageBind | Vision | 14.2 | 39.5 | 47.9 | 30.2 |
| Multi-Modality (Best) | |||||
| LanguageBind (avg.) | All | 6.8 | 19.8 | 23.7 | 15.1 |
| Ours | |||||
| CLAMR (VLM) | All | 26.7 | 85.1 | 88.0 | 58.5 |
MSR-VTT에서의 성능
| Method | R@1 | R@5 | R@10 | nDCG@10 |
|---|---|---|---|---|
| LanguageBind (Vision) | 40.2 | 64.3 | 74.8 | 56.5 |
| LanguageBind (avg.) | 23.0 | 38.3 | 45.2 | 33.2 |
| CLAMR (VLM) | 46.1 | 71.3 | 79.8 | 62.4 |
핵심 성과 요약
- MULTIVENT 2.0++: 최고 single-modality 대비 25.7% nDCG@10 향상
- MSR-VTT: LanguageBind 대비 5.9% R@1 향상
- 모든 평가 지표에서 일관된 최우수 성능 달성
5. Ablation Studies
컴포넌트별 기여도 분석
| Method | R@1 | R@5 | R@10 | nDCG@10 |
|---|---|---|---|---|
| CLAMR (Full) | 26.66 | 85.11 | 88.03 | 58.47 |
| w/o Contextualization | 18.95 | 64.30 | 68.02 | 44.53 |
| w/ LI_context | 23.93 | 80.92 | 86.04 | 56.26 |
Contextualization의 중요성
- 통합 인코딩 제거 시 R@10 20% 감소
- 모달리티 간 상호작용이 성능에 결정적 영향
Late-Interaction 방식 비교
- Modality-wise approach가 contextualized보다 2.21 nDCG@10 향상
- 모달리티별 학습이 더 효과적임을 입증
모달리티별 성능 분석
단일 모달리티 훈련 vs. 멀티모달 추론
| Training | Inference | R@1 | nDCG@10 | 개선폭 |
|---|---|---|---|---|
| Vision Only | Vision Only | 16.22 | 40.71 | - |
| Vision Only | All | 23.93 | 53.62 | +12.91 |
| Full Model | All | 26.66 | 58.47 | +17.76 |
주요 발견사항
- 추론 시 모든 모달리티 활용이 단일 모달리티보다 현저히 우수
- 멀티모달 훈련이 단일 모달리티 훈련보다 일관되게 우수
- 메타데이터가 가장 정보가 풍부한 단일 모달리티로 판명
6. 쿼리별 모달리티 선택 분석
모달리티 정확도 평가
| Method | Video | ASR | OCR | Metadata | Average |
|---|---|---|---|---|---|
| Router | 22.4 | 30.9 | 20.0 | 56.9 | 30.9 |
| mCLIP (max) | 0.0 | 54.3 | 69.1 | 39.2 | 39.5 |
| CLAMR | 58.2 | 80.0 | 84.3 | 86.0 | 76.4 |
모달리티별 특성 분석
- OCR과 메타데이터에서 특히 높은 정확도 (84.3%, 86.0%)
- 비디오 모달리티에서도 기존 방법 대비 크게 향상
- 전체적으로 router 대비 2배 이상의 성능 향상
7. Long Video QA 적용
실험 설정
데이터셋
- Video-MME: 30-60분 장시간 비디오 QA
- LongVideoBench: 900-3600초 구간 개발 세트
방법론
- RAG 파이프라인: 검색 → 관련 프레임 선택 → VLM 답변 생성
- 100개 프레임 예산으로 성능 비교
- Qwen2.5-VL-7B-Inst를 answerer로 사용
결과
| Method | LongVideoBench | Video-MME (w/o subs) | Video-MME (w/ subs) |
|---|---|---|---|
| Uniform Sample | 52.30 | 53.90 | 57.80 |
| LanguageBind (V+A) | 56.38 | 54.40 | 57.80 |
| CLAMR (V+A) | 57.09 | 55.90 | 61.30 |
| No Sample (768 frames) | 55.67 | 53.10 | 62.30 |
핵심 성과
- 모든 설정에서 기존 검색 방법 대비 일관된 향상
- 전체 프레임 입력보다 선별적 검색이 더 효과적
- Subtitle 활용 시 특히 큰 성능 향상 (3.5% 개선)
8. 한계점
Architecture 측면의 한계
단일 백본 의존성
- Qwen-VL 계열 모델에만 의존한 실험
- 다른 Vision-Language Model과의 호환성 검증 부족
- 모델 크기 확장성에 대한 분석 부재
토큰 길이 제한
- 각 모달리티별 최대 토큰 수 제한 (256-750)
- 긴 비디오나 복잡한 콘텐츠에서의 정보 손실 가능
- Omni-model에서 특히 배치 크기 제약
계산 복잡성
- Late-interaction의 O( ) 복잡도
- 대규모 검색에서의 효율성 문제 미해결
- 실시간 추론에 대한 성능 분석 부족
실험 설계의 제약
데이터셋 다양성 부족
- 주로 MULTIVENT 2.0++ 중심의 평가
- 도메인별 특화 성능 검증 부족 (의료, 금융, 교육 등)
- 실제 산업 환경의 noisy, irregular 데이터 미고려
합성 데이터의 한계
- LLM 생성 쿼리의 품질과 다양성 제한
- Human annotation 부족으로 인한 평가의 불완전성
- 실제 사용자 쿼리 패턴과의 괴리 가능성
평가 메트릭의 한계
- Retrieval 성능에만 집중, 실제 task 성능과의 연관성 부족
- Computational cost 대비 성능 분석 부재
- 불확실성 정량화 및 calibration 평가 누락
일반화 가능성 문제
언어 및 문화적 편향
- 영어 쿼리 중심의 평가
- 다국어 콘텐츠에서의 실제 성능 검증 부족
- Cross-cultural relevance 고려 부족
도메인 적응성
- 이벤트 중심 비디오에 특화된 훈련
- 다른 비디오 유형(튜토리얼, 엔터테인먼트, 뉴스 등)에서의 성능 미검증
- Zero-shot domain transfer 능력 평가 부재
9. 개선 방향 및 Future Work
Architecture 개선
더 효율적인 Late-Interaction
- Sparse attention mechanism 도입으로 계산 복잡도 감소
- Hierarchical late-interaction으로 다단계 매칭
- Approximate nearest neighbor search 활용
다중 백본 지원
- 다양한 Vision-Language Model과의 호환성 확보
- Model-agnostic late-interaction framework 개발
- 백본별 최적화된 projection layer 설계
확장성 개선
- Streaming video에 대한 incremental indexing
- Distributed late-interaction for large-scale retrieval
- Memory-efficient representation learning
훈련 데이터 및 방법론 강화
더 정교한 합성 데이터 생성
- Multi-step query generation with verification
- Human-in-the-loop quality control
- Cross-modal consistency check
Advanced Training Objectives
- Curriculum learning for modality selection
- Multi-task learning with auxiliary objectives
- Reinforcement learning for optimal modality routing
Domain Adaptation
- 도메인별 특화 모델 개발
- Few-shot adaptation techniques
- Transfer learning across video domains
평가 및 분석 강화
종합적 평가 프레임워크
- End-to-end task performance evaluation
- Computational efficiency vs. accuracy trade-off analysis
- User study for real-world relevance assessment
해석가능성 향상
- Attention visualization for modality selection
- Query-modality alignment explanation
- Failure case analysis and debugging tools
Robustness 테스팅
- Adversarial query testing
- Noisy modality handling
- Out-of-distribution generalization
10. 가능한 질문들
"정말로 Late-Interaction이 멀티모달 검색에 효과적인가?"
- 토큰 레벨 매칭의 계산 오버헤드가 성능 향상을 정당화하는가?
- 더 간단한 attention mechanism과 비교했을 때의 장단점은?
- Large-scale deployment에서의 실용성은?
"Contextualized Encoding의 실제 기여도는?"
- 단순 concatenation과 진정한 multi-modal fusion의 차이점은?
- Cross-modal attention이 실제로 학습되고 있는가?
- 모달리티별 representation quality는 보존되는가?
"합성 데이터 생성 전략이 충분히 robust한가?"
- LLM bias가 검색 모델에 전파될 위험은 없는가?
- Human-generated query와의 분포 차이는?
- 실제 사용자 정보 요구를 얼마나 잘 반영하는가?
"실제 산업 환경에 적용 가능한가?"
- Streaming video indexing에서의 성능은?
- Privacy-sensitive 환경에서의 적용 방안은?
- 다양한 품질의 비디오 콘텐츠에서의 robustness는?
"모달리티 선택이 정말 'intelligent'한가?"
- 단순 heuristic과 비교했을 때의 실질적 이득은?
- 모달리티 간 conflict 상황에서의 처리 방식은?
- User preference 학습이 가능한가?
종합 평가
CLAMR은 "멀티모달 검색에 late-interaction을 적용한 최초의 연구"로서 중요한 기여를 했다. 특히 contextualized encoding과 modality-aware training의 결합을 통해 기존 방법들의 한계를 극복하고 의미 있는 성능 향상을 달성했다.
강점
기술적 혁신성
- Late-interaction의 멀티모달 확장이라는 새로운 연구 방향 제시
- Contextualized encoding을 통한 모달리티 간 상호작용 모델링
- 동적 모달리티 선택을 위한 효과적인 훈련 전략 개발
실용적 가치
- 기존 백본 활용으로 구현의 용이성 확보
- 다양한 도메인과 태스크에 적용 가능한 범용적 프레임워크
- Long video QA에서의 downstream utility 입증
실험적 엄밀성
- 포괄적인 baseline 비교와 ablation study 수행
- 통계적 유의성 검증과 다양한 평가 지표 활용
- 실제적인 합성 데이터 생성 방법론 제시
개선 필요 사항
확장성과 효율성
- Late-interaction의 계산 복잡도 문제 해결 필요
- 대규모 검색 환경에서의 실용성 검증 요구
- 실시간 응답이 필요한 응용에서의 최적화 필요
일반화 능력
- 더 다양한 도메인과 언어에서의 성능 검증 필요
- 실제 사용자 쿼리 패턴에 대한 robustness 평가 요구
- Zero-shot generalization 능력 분석 필요
해석가능성
- 모달리티 선택 과정에 대한 설명 가능성 부족
- 실패 케이스 분석과 디버깅 도구 필요
- 사용자 신뢰도 향상을 위한 투명성 확보 필요
