Paper Review
1.[ICML 2025] ITFormer: 'Adapter' 하나로 LLM을 시계열 전문가 만드는 법
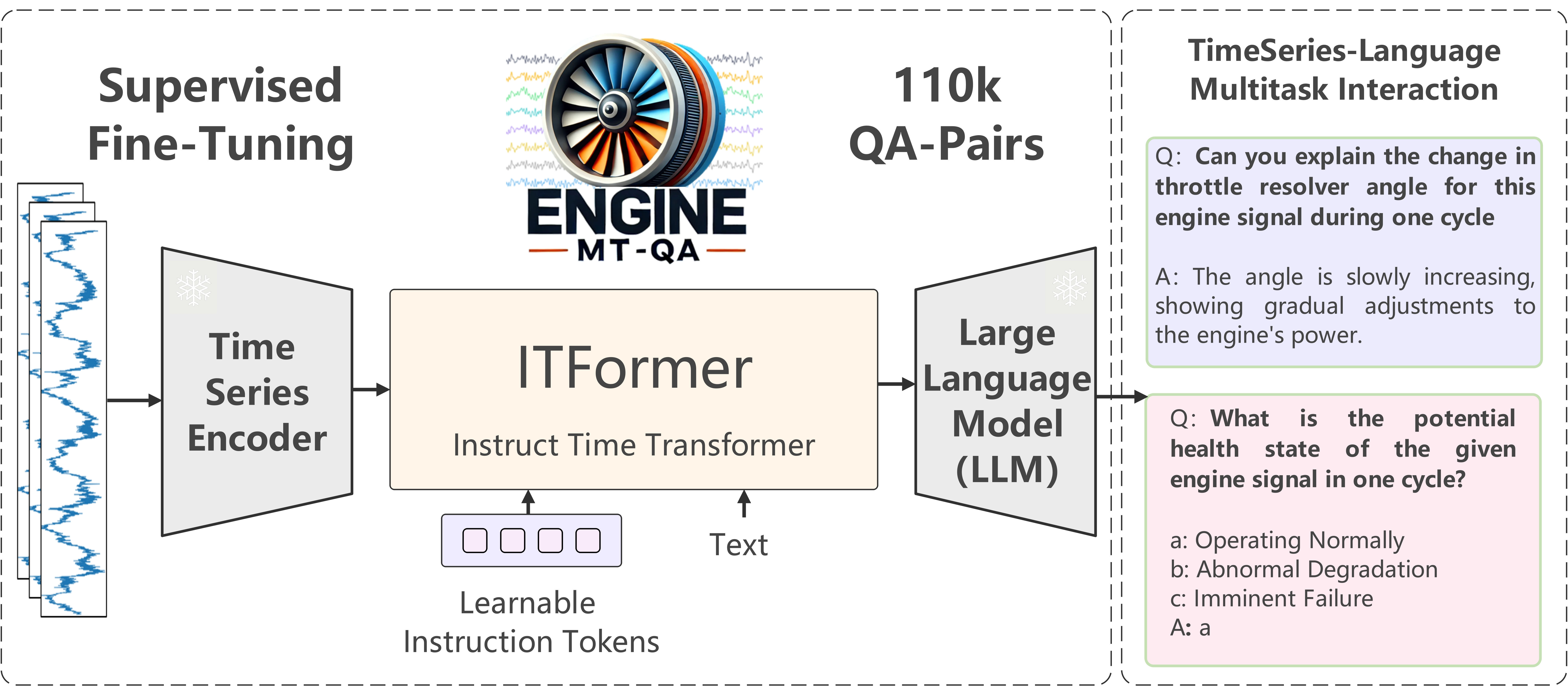
인공지능 분야에서 시계열 분석과 거대 언어 모델(LLM)은 각자의 영역에서 괄목할 만한 발전을 이루어왔습니다. 하지만 숫자 데이터의 패턴을 읽는 능력과 인간의 언어를 이해하는 능력은 오랫동안 별개의 길을 걸어왔습니다. 이 두 강력한 AI를 어떻게 하면 하나로 합쳐 시너
2.[ICML 2025] Time-VLM: 멀티모달리티는 어떻게 시계열 예측의 한계를 극복하는가?
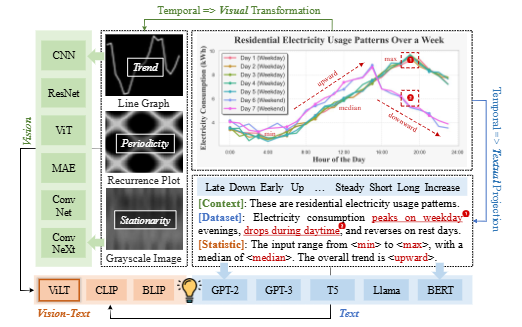
시계열 데이터는 금융, 기후, 에너지 등 다양한 분야에서 예측의 근간이 되지만, ARIMA와 같은 전통적인 모델은 복잡한 비선형 패턴을 포착하는 데 어려움이 있습니다. RNN이나 트랜스포머 기반의 딥러닝 모델들이 이러한 한계를 개선했지만, 이들 역시 여러 도메인에 걸쳐
3.[NeurIPS 2024] Time-MMD: 멀티모달 시계열 예측의 새로운 벤치마크

본 논문은 시계열 분석(Time Series Analysis, TSA)의 현주소와 그 한계를 명확히 짚고, 멀티모달(multimodal) 접근을 통해 이를 극복하고자 하는 시도이다. 특히 기존의 시계열 예측 모델들이 수치 기반 단일 모달(unimodal) 입력에 의존해
4.[ICASSP 2025] SpeechRAG
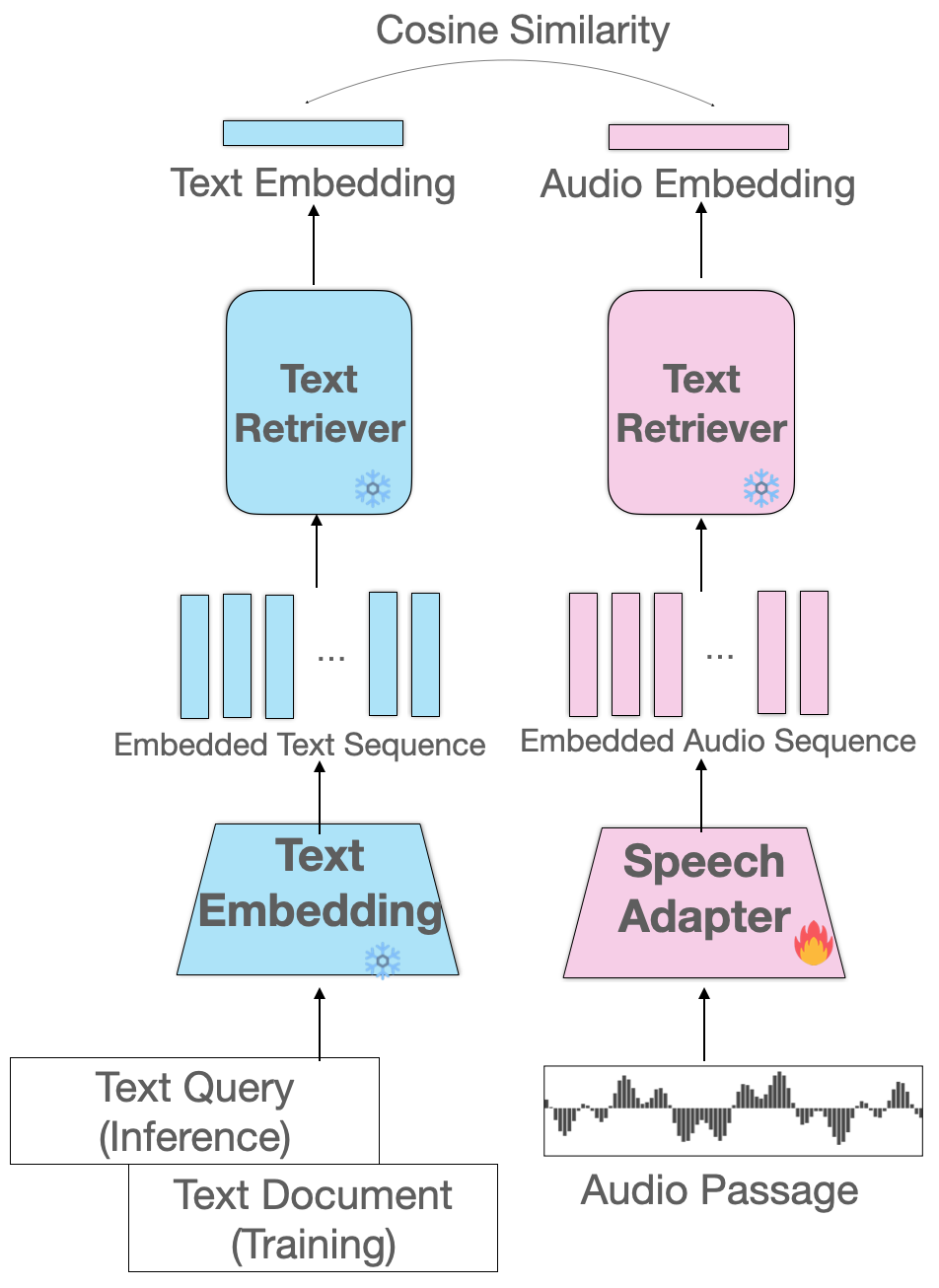
기존 Spoken QA의 한계기존 음성 기반 질의응답 시스템은 cascaded pipeline을 따른다Audio → ASR → Text Retrieval → Text Generation이 접근법의 근본적 문제점들이 존재한다.ASR 오류 전파 (Error Propagat
5.VisionThink: GRPO and Dynamic Resolution
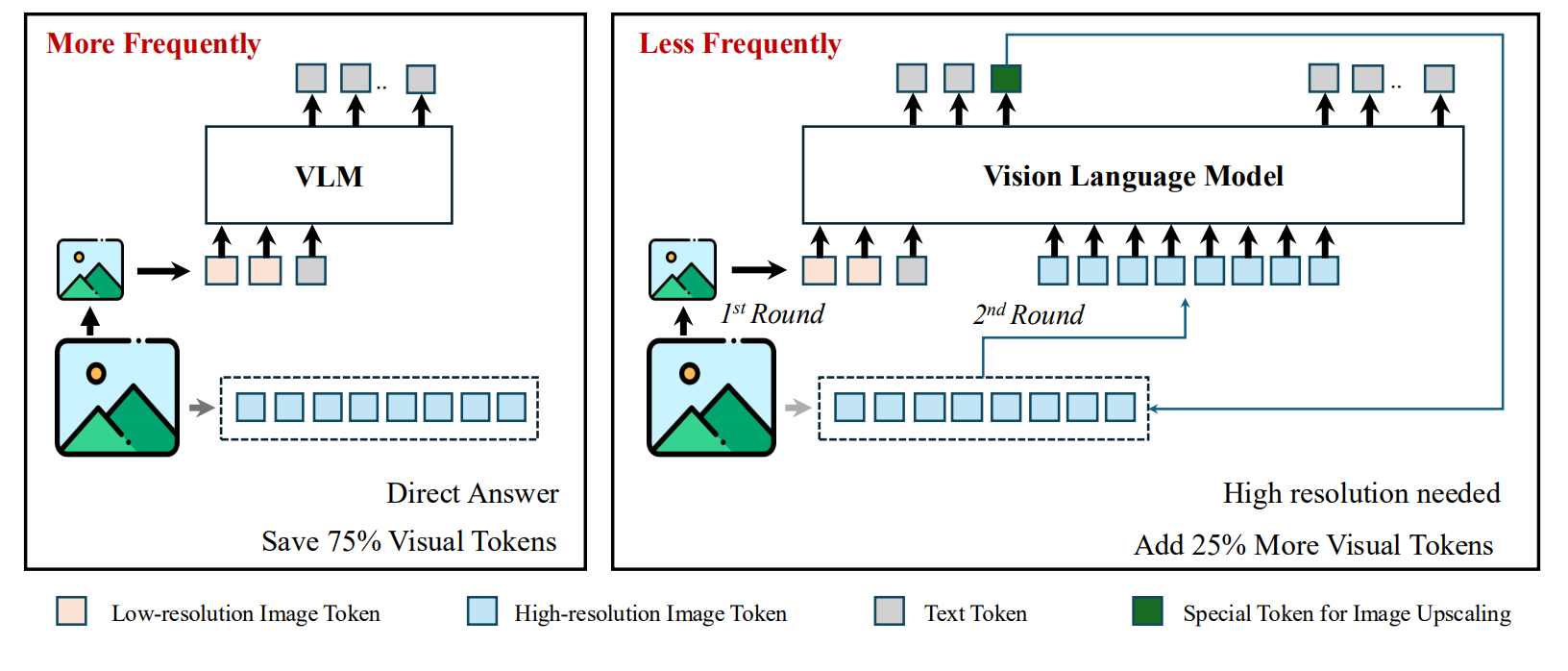
Input: Text query + Low-resolution image (initially 1/4 resolution)Output: Text answer + Optional high-resolution image requestTransformation: Low-res
6.[ACL Workshop 2025] VoxRAG

Input: Speech query + Podcast audio passagesOutput: Retrieved relevant audio segments + Generated text answersTransformation: Speech → CLAP embedding
7.[ACL 2025] WavRAG
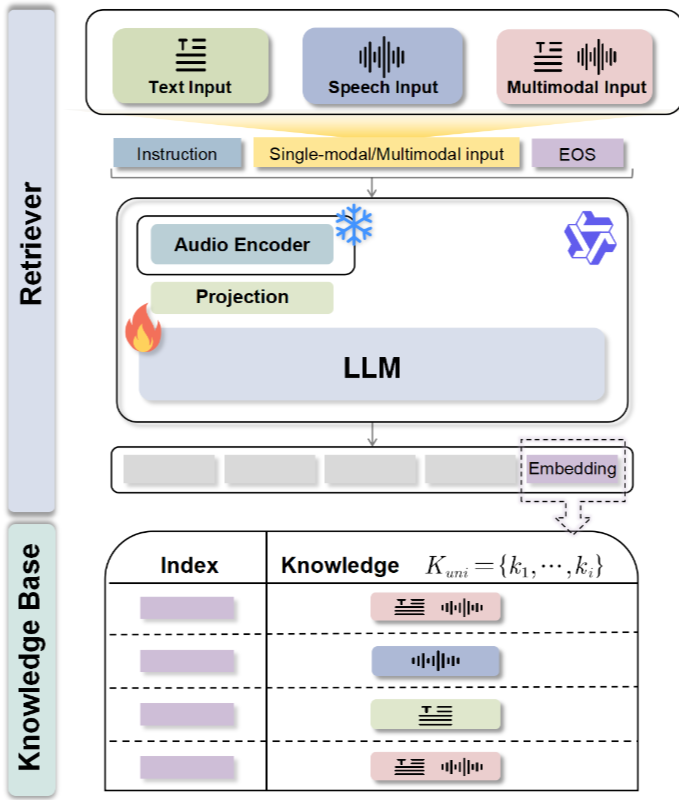
→ 음성을 직접 처리할 수 있는 새로운 RAG(Retrieval-Augmented Generation) 프레임워크. 기존 RAG 시스템이 텍스트만 처리했다면, WavRAG는 음성과 텍스트를 모두 처리할 수 있는 최초의 end-to-end 시스템이다.WavRetrieve
8.[ICASSP 2025] TimeRAG Paper Review
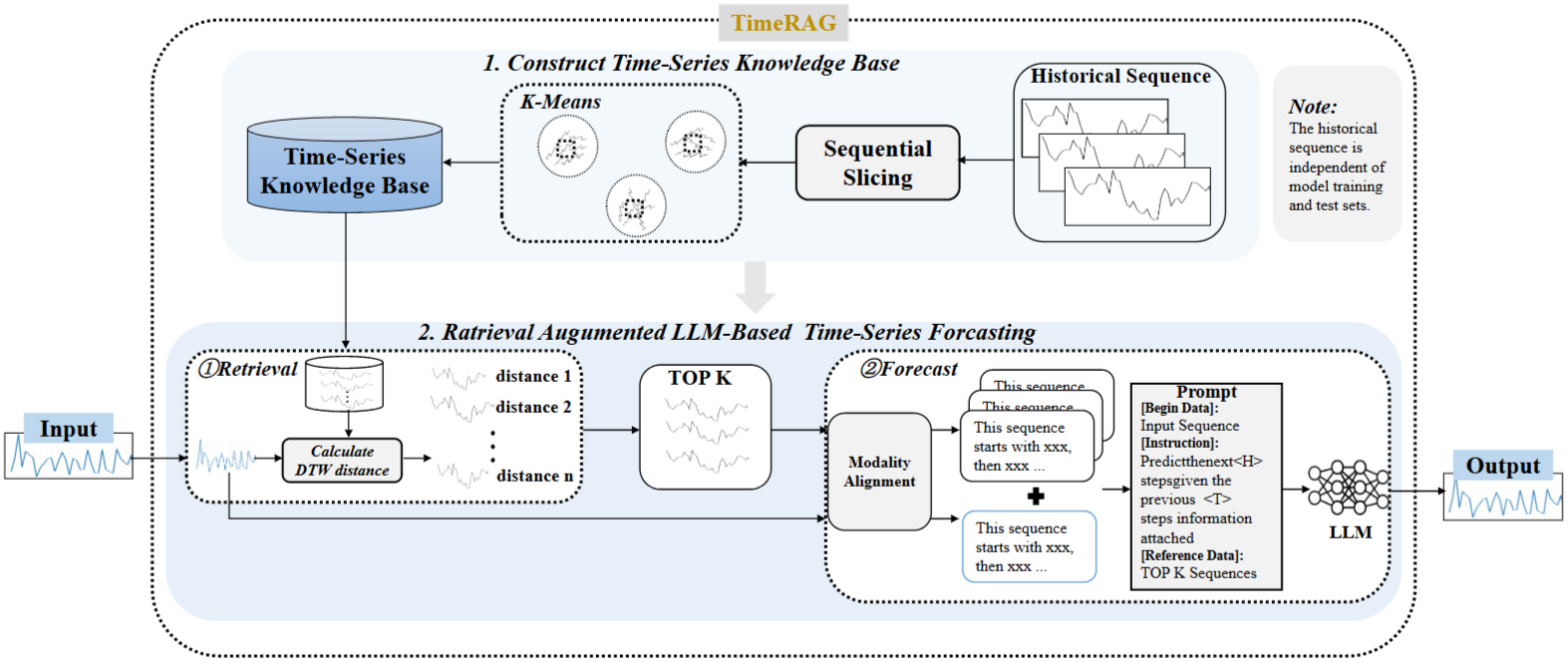
Input: Time series query sequence + Historical time series sequencesOutput: Retrieved similar time series sequences + Enhanced forecasting predictions
9.[2025] MARS Paper Review
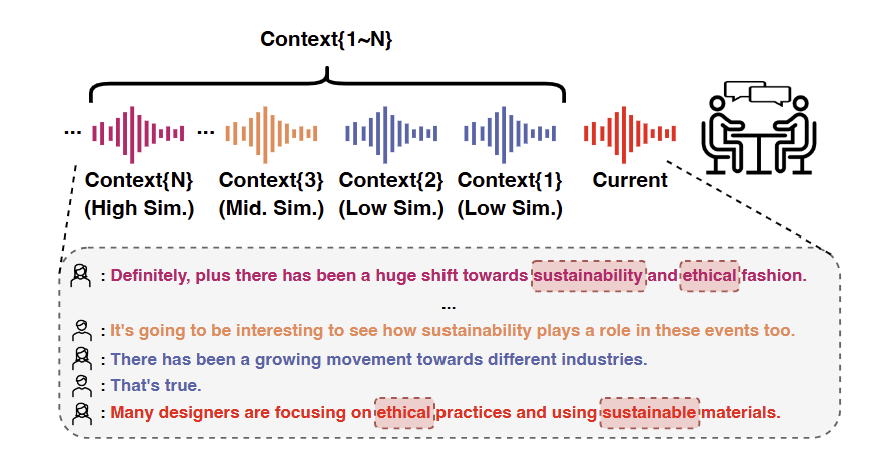
Input: Current utterance speech + Historical conversation databaseOutput: Retrieved best historical context + Enhanced ASR transcriptionTransformation
10.[2025] CLAMR Paper Review
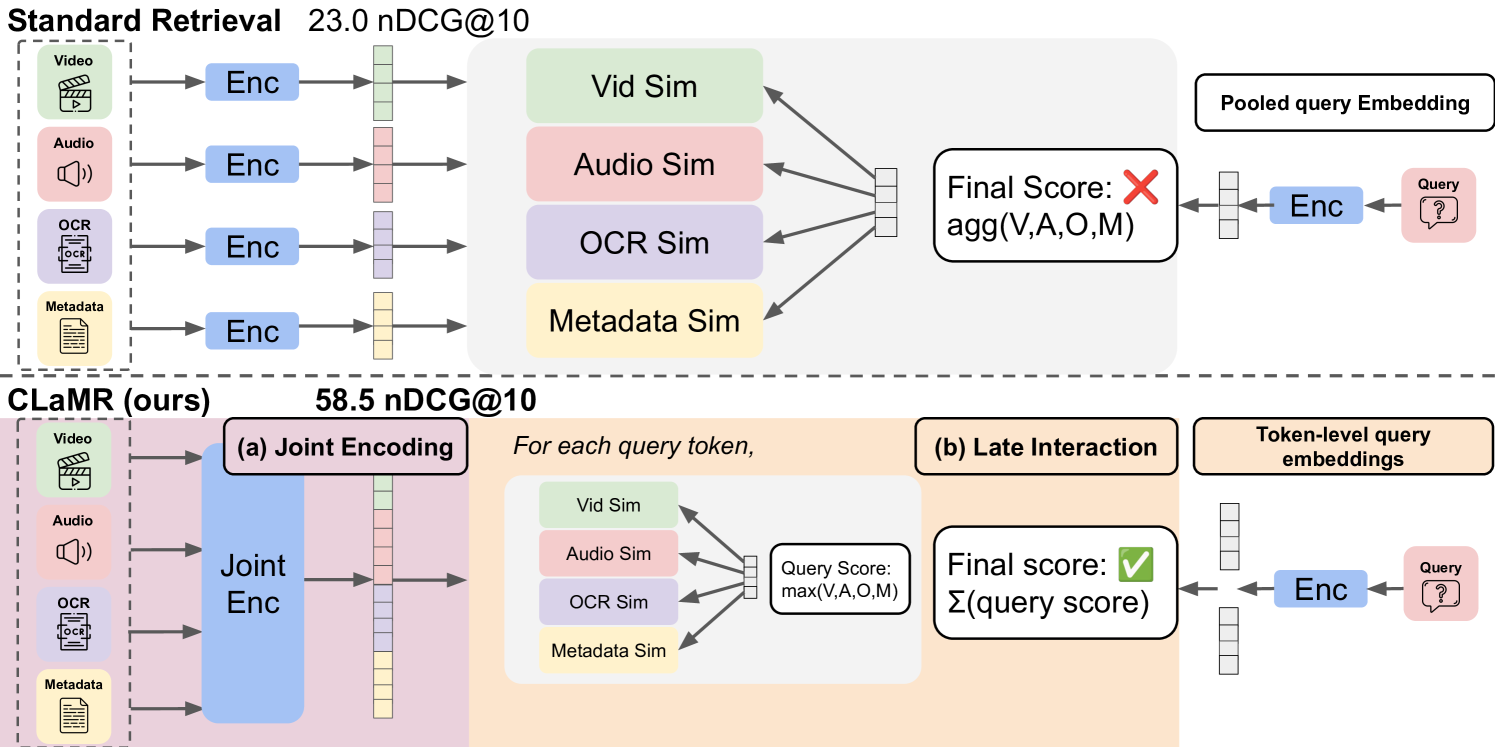
CLAMR codePaperInput: 텍스트 쿼리 + 멀티모달 비디오 콘텐츠 (비디오 프레임, 음성 전사, 화면상 텍스트, 메타데이터)Output: 관련성 점수 기반 검색 결과Transformation: 멀티모달 콘텐츠 → 통합 인코딩 → Late-interactio
11.Uncertainty Quantification in Retrieval Augmented Question Answering: 논문 리뷰
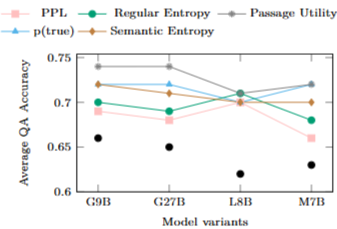
Input: Question + Retrieved passagesOutput: Passage utility scores → Answer uncertainty estimationTransformation: Individual passage utility predictio
12.FRANQ: Faithfulness-Aware Uncertainty Quantification 논문 리뷰
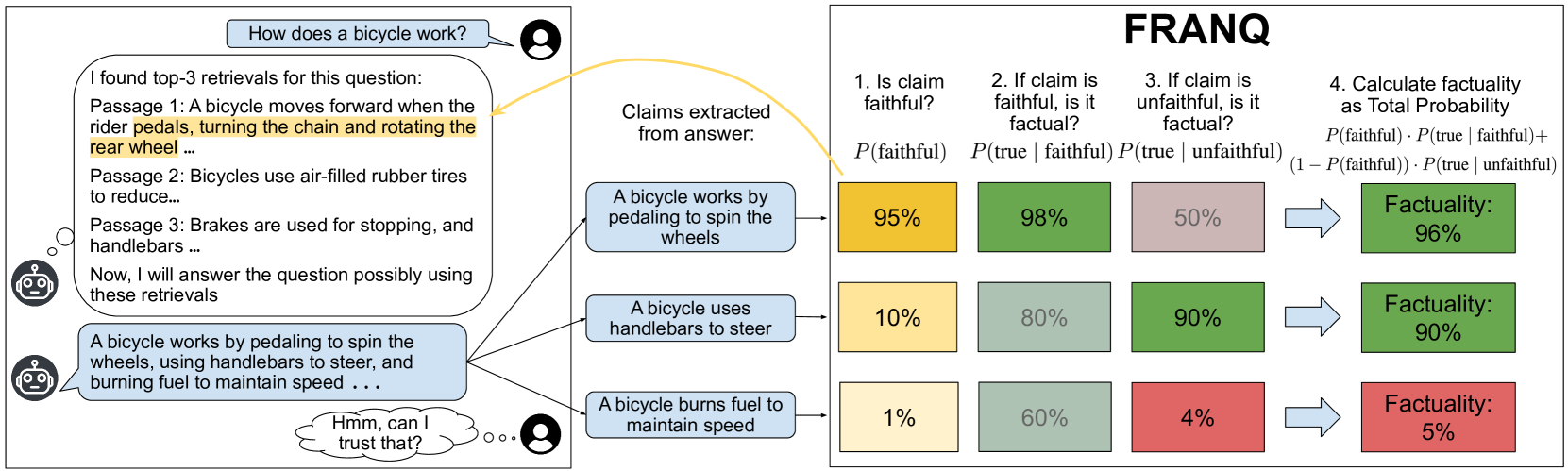
Input: RAG generated response (질문 + 검색된 문서 + 생성된 답변)Output: Claim-level factuality probability (각 atomic claim의 사실성 확률)Transformation: Faithfulness as
13.LLMTIME: Large Language Models Are Zero-Shot Time Series Forecasters 논문 리뷰
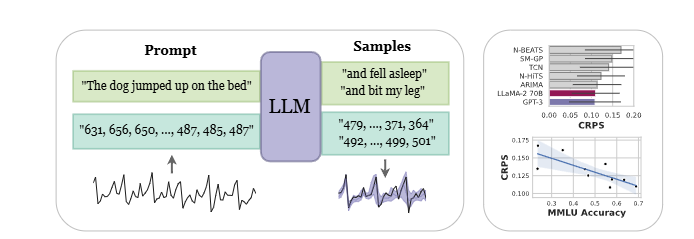
Input: 시계열 데이터를 문자열로 변환 (예: "1 2, 1 2 3, 1 2 3 0, 1 2 3 0 0")Output: 다음 시퀀스 예측 (sampling 기반)Transformation: 숫자 → 텍스트 → LLM next-token prediction → 확률적