핵심 Method 요약
Input/Output
- Input: Current utterance speech + Historical conversation database
- Output: Retrieved best historical context + Enhanced ASR transcription
- Transformation: Speech → Multi-modal retrieval → Context selection → LLM-based ASR
알고리즘 구조
- Multi-modal Retrieval: DTW-based speech similarity + embedding-based text similarity
- Multi-modal Selection: Near-ideal ranking method for optimal context selection
- LLM-based ASR: Qwen2.5-7B with LoRA adaptation + retrieved context augmentation
핵심 수식
- 2차원 Euclidean Distance:
- Relative Closeness:
- Near-ideal Ranking: Euclidean distance to ideal vs negative ideal points
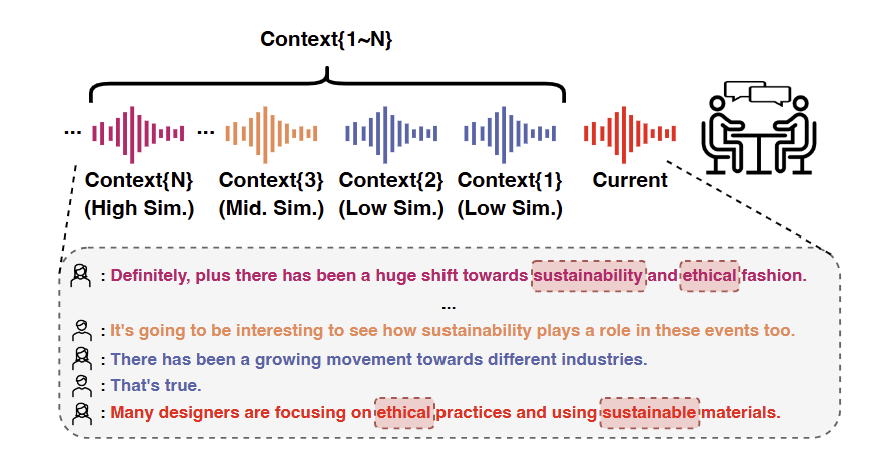
Key Point: 고정된 preceding context 대신 동적으로 가장 관련성 높은 historical context를 검색하여 선택
1. 연구 배경 및 동기
기존 Conversational LLM-ASR의 한계
고정 Context 방식의 문제점
- 기존 방법들은 고정된 수의 preceding utterances나 전체 대화 히스토리를 사용한다
- Preceding few utterances에는 filler, semantically insignificant content가 많아 노이즈가 된다
- 가장 관련성 높은 context가 항상 바로 앞 utterance에 있지 않을 수 있다
전체 히스토리 사용의 문제점
- 전체 대화 히스토리를 사용하면 정보 과부하와 계산 비용 증가를 초래한다
- Redundant information이 현재 utterance의 ASR 성능을 저해한다
- Real-time 처리에 부적합하다
기존 RAG의 한계
- 전통적인 RAG는 text generation에 최적화되어 있어 ASR과는 목적이 다르다
- ASR은 speech-to-text mapping이 목표인 반면, RAG는 new content generation이 목표이다
- 대량의 retrieved content가 인식할 speech를 drowning out시킬 수 있다
연구의 핵심 질문
"어떻게 현재 utterance와 가장 관련성 높은 historical context를 동적으로 검색하고 선택하여 conversational LLM-ASR 성능을 향상시킬 수 있는가?"
→ Multi-modal Retrieval-and-Selection 방법론으로 해결하자!
2. Method
전체 아키텍처 개요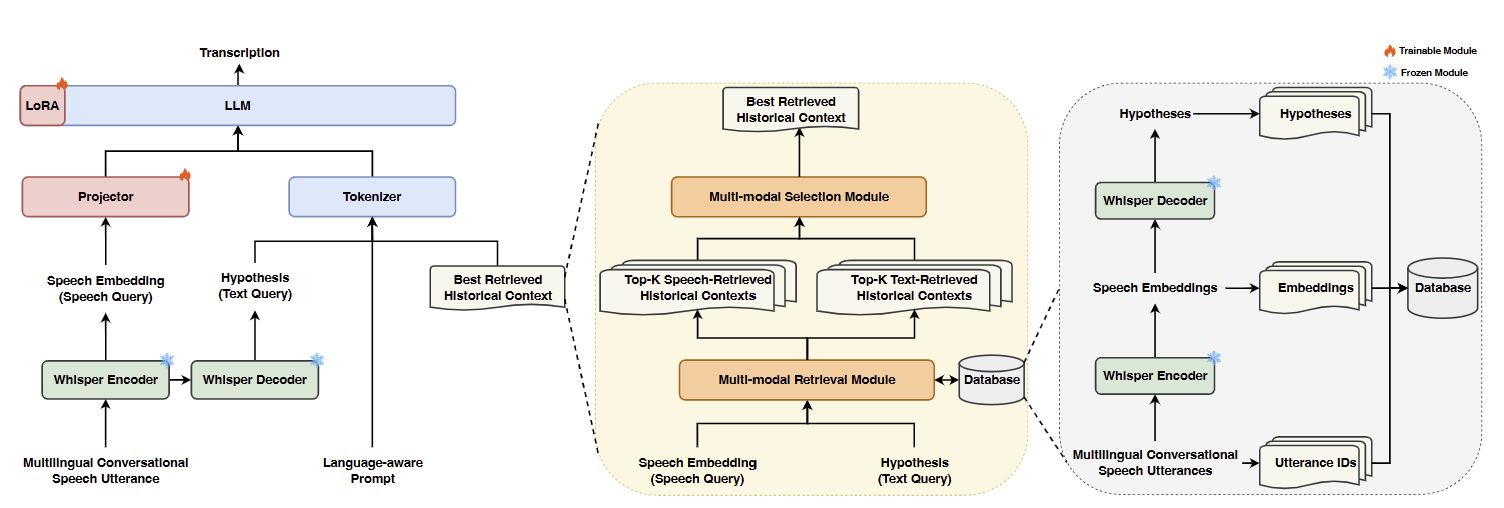
MARS는 3단계 파이프라인으로 구성된다:
- Database Construction: Whisper를 이용해 각 utterance의 (ID, speech embedding, hypothesis) triplet 저장
- Multi-modal Retrieval: Speech와 text 쿼리를 이용해 Top-K candidates 검색
- Multi-modal Selection: Near-ideal ranking으로 best historical context 선택
Multi-modal Retrieval 메커니즘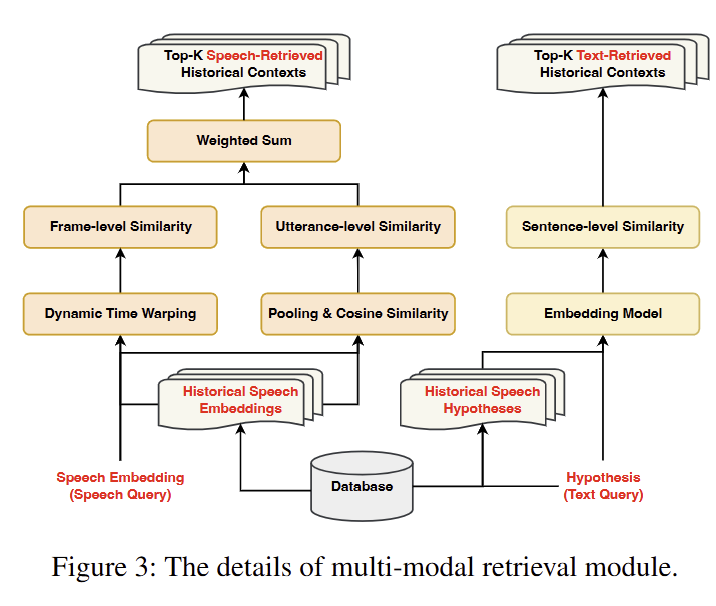
Speech Modality Retrieval
- Frame-level Similarity: FastDTW를 사용하여 speech embedding 간 acoustic similarity 계산
- Utterance-level Similarity: Pooled embedding의 cosine similarity 계산
- Combined Similarity: Frame-level과 utterance-level을 0.5:0.5로 weighted sum
Text Modality Retrieval
- Sentence-level Similarity: Qwen3-Embedding-0.6B를 사용해 hypothesis 간 semantic similarity 계산
- Top-K Selection: 각 modality별로 가장 높은 similarity를 가진 K개 context 선택
Multi-modal Selection: Near-Ideal Ranking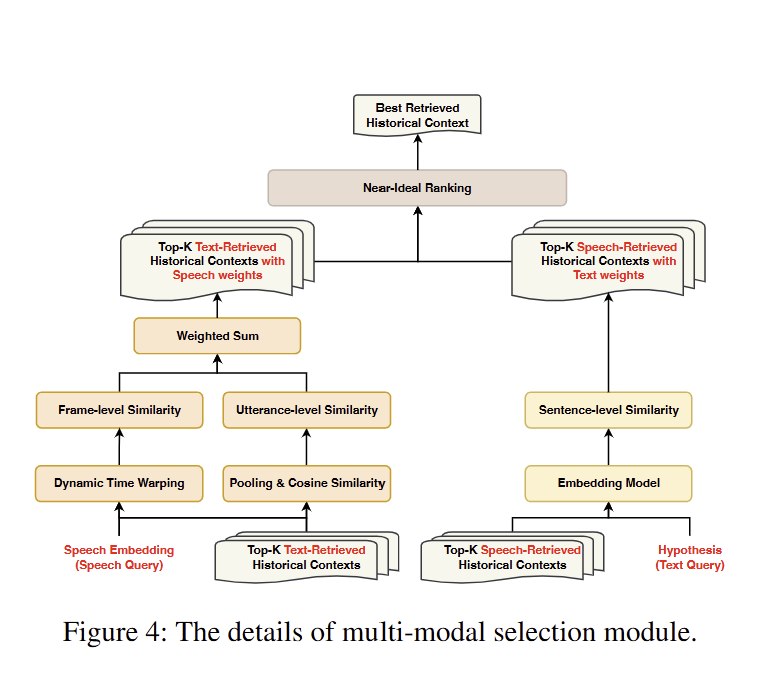
핵심 아이디어
- Speech와 text similarity는 서로 다른 차원과 스케일을 가져 직접 합산할 수 없다
- Ideal point(both similarities maximized)와 negative ideal point(both minimized)를 정의
- 각 candidate의 relative closeness를 계산하여 최적 context 선택
알고리즘 단계
-
Normalization:
-
Ideal Points:
, -
Distance Calculation: Euclidean distance to ideal and negative ideal points
-
Relative Closeness:
Adaptive Contextual Decoding
Training Strategy
- 50% 확률로 best retrieved context를 randomly mask하여 over-reliance 방지
- 모델의 generalization capability 향상
Decoding Options
- Direct Decoding: Context 없이 독립적 디코딩
- MARS Decoding: Best retrieved context와 함께 디코딩
- Two-pass Decoding: 1차 direct decoding → 새 database 구축 → 2차 MARS decoding
3. 실험 설계 및 결과 분석
데이터셋
MLC-SLM Dataset (Interspeech 2025 Challenge)
- 11개 언어: English, French, German, Italian, Portuguese, Spanish, Japanese, Korean, Russian, Thai, Vietnamese
- 총 1,500시간: English 500시간 + 다른 언어별 100시간
- 특징: Natural conversation, 2-speaker dialogue, quiet indoor recording
평가 Metric 및 Baseline
평가 지표
- WER: Word Error Rate (단어 기반 언어)
- CER: Character Error Rate (문자 기반 언어: Japanese, Korean, Thai)
- MER: Mixed Error Rate (전체 언어 평균)
Baseline 모델들
- Vanilla Whisper-large-v3
- Fine-tuned Whisper-large-v3
- Qwen2-Audio
- TEA-ASLP: 179K 시간 데이터로 훈련된 SOTA 모델 (challenge 1위)
실험 결과
Main Results (Table 1)
| Model | Training Data | Dev MER | Test MER | 성능 개선 |
|---|---|---|---|---|
| TEA-ASLP | 179K hours | 10.62% | 9.60% | SOTA baseline |
| MARS | 1.5K hours | 8.97% | 8.35% | +13.0% 개선 |
핵심 성과
- 데이터 효율성: 119배 적은 데이터로 SOTA 성능 달성
- 일관된 성능: 15개 언어 중 대부분에서 최고 성능
- 실용성: 계산 효율적이면서도 의미있는 성능 향상
Context Type 비교 (Table 2)
| Context Type | Dev MER | 분석 |
|---|---|---|
| None | 14.87% | Baseline |
| Context{1~2} | 13.56% | 고정 context |
| GT: Context{1~2} | 13.16% | Ground-truth context |
| MARS Best Retrieved | 8.97% | 동적 최적 context |
Ablation Study 결과 (Table 3)
| Component | Dev MER | Test MER | 기여도 |
|---|---|---|---|
| Base LLM-ASR | 12.75% | 11.04% | - |
| + Speech Retrieval | 10.24% | 9.41% | +14.7% |
| + Text Retrieval | 10.33% | 9.23% | +16.4% |
| + Multi-modal Selection | 9.77% | 8.96% | +18.8% |
| + Two-pass Decoding | 8.97% | 8.35% | +24.4% |
4. 한계점
Architecture에서의 한계
DTW 계산 복잡성
- DTW는 O(n×m) 시간 복잡도를 가져 대규모 database에서 비효율적이다
- FastDTW로 완화했지만 여전히 real-time 처리에는 제약이 있다
- Memory usage도 상당할 수 있다
Retrieval Quality의 불확실성
- Top-K 선택이 항상 optimal candidates를 보장하지 않는다
- K값 설정이 경험적이고 도메인별 튜닝이 필요하다
- Speech와 text modality 간 trade-off 관계가 복잡하다
Context Length 제한
- LLM의 context window 제한으로 very long conversations 처리가 어렵다
- Historical context의 temporal decay 고려가 부족하다
실험 설계의 제약
단일 데이터셋 평가
- MLC-SLM dataset만으로는 일반화 성능 검증에 한계가 있다
- 다양한 도메인(의료, 금융, 법률 등) 특화 평가가 부족하다
- Noisy, far-field recording 환경에서의 검증이 없다
Computational Cost 분석 부족
- Retrieval overhead vs. performance gain에 대한 정량적 분석이 없다
- Energy consumption, latency 측면의 평가가 부족하다
- Production deployment 관점의 scalability 검증이 미흡하다
Baseline 비교의 한계
- Recent foundation model 기반 ASR systems와의 비교 부족
- Multi-modal context utilization methods와의 세밀한 비교 없음
- Oracle context 실험이 제한적이다
5. 개선 방향 및 Future Work
Retrieval 메커니즘 고도화
Efficient Similarity Search
- Neural embedding 기반 approximate nearest neighbor search 도입
- Locality Sensitive Hashing (LSH)을 활용한 fast retrieval 구현
- Hierarchical clustering으로 search space 축소
Adaptive Retrieval Strategy
- Context relevance에 따른 dynamic K값 조정
- Conversation topic shift detection을 통한 retrieval scope 최적화
- Multi-granularity retrieval (word-level, phrase-level, utterance-level)
Context Selection 정교화
Advanced Ranking Methods
- Learning-based ranking model 도입으로 near-ideal ranking 개선
- Multi-objective optimization for speech/text balance
- Temporal decay factor를 고려한 recency-weighted selection
Context Quality Assessment
- Retrieved context의 quality score 예측 모델 구축
- Confidence-aware selection mechanism
- Dynamic context length adjustment based on complexity
도메인 및 태스크 확장
Multi-Domain Adaptation
- Domain-specific knowledge base 구축 방법론
- Cross-domain transfer learning for retrieval models
- Specialized embedding spaces for different domains
Extended Task Coverage
- Real-time streaming ASR에 MARS 적용
- Multi-speaker conversation handling
- Code-switching 및 multilingual mixed conversation 지원
실용성 및 효율성 강화
Production Optimization
- Model compression techniques for deployment
- Caching strategies for frequently accessed contexts
- Distributed retrieval system architecture
Interpretability Enhancement
- Retrieved context의 contribution 분석 도구
- Failure case analysis 및 debugging mechanism
- User-friendly explanation interface
6. 가능한 질문들
"정말로 Multi-modal Retrieval이 필요한가?"
- Table 4에서 speech-only나 text-only retrieval도 상당한 성능 향상을 보였는데, multi-modal의 추가 이득이 computational cost를 정당화하는가?
- Single modality로도 충분한 경우는 언제이고, multi-modal이 반드시 필요한 scenario는 무엇인가?
"Near-ideal Ranking의 이론적 근거는 충분한가?"
- Euclidean distance 기반 ranking이 speech와 text similarity의 복잡한 관계를 적절히 모델링하는가?
- 다른 multi-criteria decision making 방법들(TOPSIS, AHP 등)과 비교했을 때의 장단점은?
- Ideal point의 정의가 모든 상황에서 optimal한가?
"1.5K vs 179K 시간 데이터 비교가 공정한가?"
- TEA-ASLP는 large-scale pre-training의 이점을 활용한 반면, MARS는 retrieval augmentation을 사용했다
- 동일한 데이터 조건에서의 비교 결과는 어떨까?
- Pre-training data의 질적 차이는 고려되었는가?
"Real-time 환경에서의 실용성은?"
- DTW computation과 database search latency가 실제 conversation flow에 미치는 영향은?
- Streaming ASR에 적용했을 때의 성능 변화는?
- Edge device에서의 deployment 가능성은?
"다양한 대화 패턴에서의 강건성은?"
- Topic shift가 빈번한 대화에서도 효과적인가?
- 화자 변경, background noise, overlapping speech 상황에서의 성능은?
- Very long conversation (1시간+)에서의 scalability는?
종합 평가
MARS는 "conversational ASR을 위한 동적 context selection"이라는 새로운 패러다임을 제시한 중요한 연구다. 특히 대규모 데이터 없이도 intelligent retrieval을 통해 SOTA 성능을 달성한 것은 실용적 가치가 매우 크다.
강점
- 데이터 효율성: 119배 적은 데이터로 최고 성능 달성
- 방법론적 혁신: Multi-modal retrieval + near-ideal ranking의 체계적 결합
- 실용적 접근: 기존 LLM 구조를 크게 변경하지 않고도 성능 향상
- 일반화 가능성: 다양한 언어와 도메인에서 일관된 성능
개선 필요 사항
- 계산 효율성: DTW 기반 retrieval의 scalability 문제 해결 필요
- 이론적 완성도: Near-ideal ranking의 수학적 근거 강화 필요
- 평가 범위 확대: 다양한 실제 환경과 도메인에서의 검증 필요
- Long-term 안정성: 매우 긴 대화에서의 성능 유지 방안 필요
