핵심 Method 요약
Input/Output
- Input: RAG generated response (질문 + 검색된 문서 + 생성된 답변)
- Output: Claim-level factuality probability (각 atomic claim의 사실성 확률)
- Transformation: Faithfulness assessment → Conditional UQ → Weighted factuality estimation
알고리즘 구조
- Faithfulness Evaluator: AlignScore (RoBERTa 기반 semantic similarity)
- Faithful Condition UQ: MaxNLI (long-form) / Semantic Entropy (short-form)
- Unfaithful Condition UQ: Parametric Knowledge (long-form) / Sum of Eigenvalues (short-form)
- Calibration: Isotonic regression for condition-specific calibration
핵심 수식
1. 연구 배경 및 동기
RAG 환경에서의 Hallucination 정의 문제
기존 연구들은 RAG에서 hallucination을 faithfulness 관점에서만 접근했다. 즉, 검색된 문서에 직접 support되지 않는 모든 내용을 hallucination으로 분류했다. 하지만 이는 다음과 같은 문제를 야기한다:
잘못된 Hallucination 분류 사례:
질문: "파리의 수도는?"
검색된 문서: "파리는 프랑스의 아름다운 도시이다"
모델 답변: "파리는 프랑스의 수도이다"
기존 접근: Hallucination (문서에 명시되지 않음)
실제 상황: 사실적으로 정확한 답변
Factuality vs Faithfulness 구분의 필요성
- Faithfulness: 생성된 내용이 검색된 문서에 의해 entail되는지 여부
- Factuality: 생성된 내용이 객관적으로 사실인지 여부
저자들은 RAG 시스템에서 factuality가 더 중요한 평가 기준이라고 주장한다. 모델이 자신의 parametric knowledge에서 올바른 정보를 생성했다면, 이를 hallucination으로 분류해서는 안 된다는 것이다.
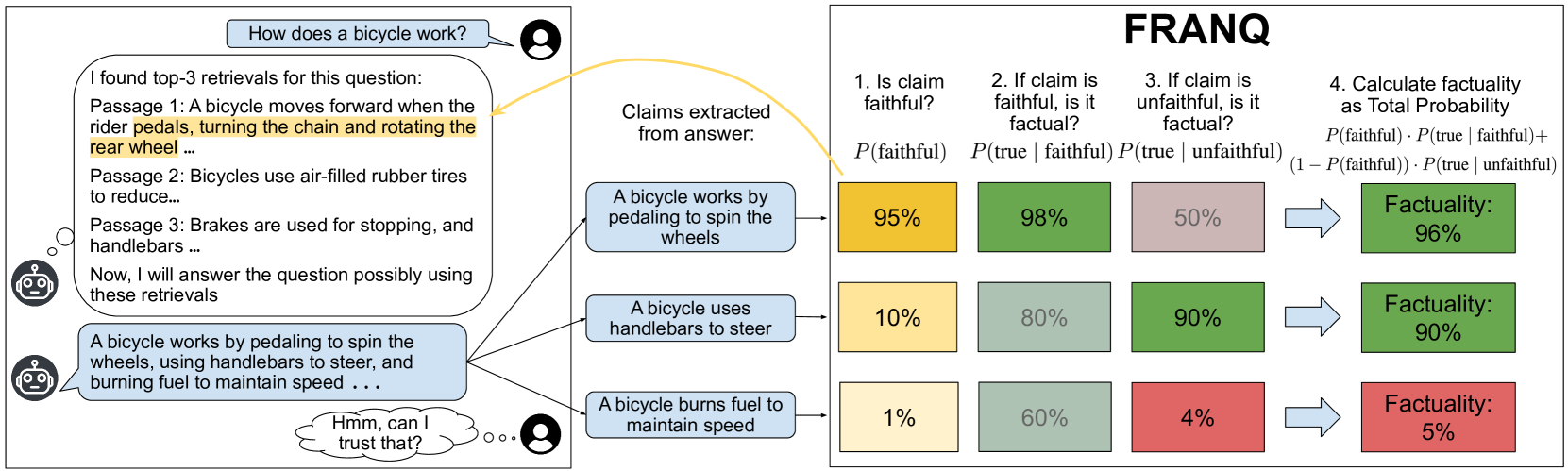
2. Method
전체 FRANQ 프레임워크
FRANQ의 핵심 아이디어는 조건부 불확실성 정량화이다:
- 1단계: Claim이 검색된 문서에 faithful한지 평가
- 2단계: Faithful/Unfaithful 조건에 따라 서로 다른 UQ 방법 적용
- 3단계: 가중평균으로 최종 factuality 확률 계산
2.1 세 가지 핵심 컴포넌트
Faithfulness Assessment (P(faithful)):
- AlignScore 사용: RoBERTa 기반 semantic similarity metric
- Long-form: claim vs concatenated retrieved documents
- Short-form: (question + answer) vs each retrieved document
Faithful Condition UQ (P(true | faithful)):
- Long-form: MaxNLI - NLI 모델로 최대 entailment confidence 계산
- Short-form: Semantic Entropy - 의미적 다양성 기반 불확실성
Unfaithful Condition UQ (P(true | unfaithful)):
- Long-form: Parametric Knowledge - 검색 문서 없이 모델 자체 확률
- Short-form: Sum of Eigenvalues - graph-based uncertainty metric
2.2 Condition-Specific Calibration
단순히 다른 UQ 방법들을 결합하는 것이 아니라, 조건별 보정을 수행한다:
훈련 데이터를 faithful/unfaithful로 분할
→ 각 조건에서 별도로 isotonic regression 적용
→ 조건에 맞는 보정 함수 학습이는 faithful claim과 unfaithful claim이 서로 다른 uncertainty 분포를 가질 수 있다는 통찰에 기반한다.
3. 실험 설계 및 결과 분석
3.1 데이터셋 구성
Long-form QA:
- 76개 질문 (RAGTruth 44개 + GPT-4 생성 32개)
- 1,782 claims (Llama-3B), 1,548 claims (Falcon-3B)
- Hybrid annotation: GPT-4o 자동 + 까다로운 케이스 수동 검증
Short-form QA:
- TriviaQA, SimpleQA, Natural Questions, PopQA
- 각 데이터셋에서 200개 훈련, 1,000개 테스트
3.2 주요 실험 결과
Long-form QA 성능 (전체 비교):
| Method | Llama-3B | Falcon-3B | ||||
|---|---|---|---|---|---|---|
| ROC-AUC | PR-AUC | PRR | ROC-AUC | PR-AUC | PRR | |
| Max Claim Probability | 0.497 | 0.058 | -0.029 | 0.678 | 0.126 | 0.258 |
| P(True) | 0.573 | 0.117 | 0.207 | 0.591 | 0.077 | 0.170 |
| Perplexity | 0.477 | 0.056 | -0.081 | 0.636 | 0.090 | 0.165 |
| Mean Token Entropy | 0.562 | 0.109 | 0.115 | 0.646 | 0.130 | 0.219 |
| MaxNLI | 0.642 | 0.109 | 0.151 | 0.669 | 0.101 | 0.287 |
| AlignScore | 0.616 | 0.075 | 0.108 | 0.652 | 0.104 | 0.233 |
| XGBoost (all features) | 0.611 | 0.124 | 0.206 | 0.616 | 0.088 | 0.198 |
| FRANQ no calibration | 0.646 | 0.100 | 0.181 | 0.692 | 0.135 | 0.362 |
| FRANQ calibrated | 0.653 | 0.103 | 0.256 | 0.602 | 0.074 | 0.090 |
| FRANQ condition-calibrated | 0.641 | 0.140 | 0.223 | 0.693 | 0.173 | 0.354 |
Short-form QA 상세 성능 (4개 데이터셋 평균):
| Method | Llama-3B Mean Rank | Llama-3B Mean Value | Falcon-3B Mean Rank | Falcon-3B Mean Value |
|---|---|---|---|---|
| ROC | PR | PRR | ROC | |
| Semantic Entropy | 4.00 | 5.25 | 4.75 | 0.792 |
| Degree Matrix | 6.25 | 3.75 | 5.75 | 0.789 |
| Sum of Eigenvalues | 5.25 | 4.25 | 5.50 | 0.791 |
| p(True) | 20.25 | 20.00 | 20.00 | 0.477 |
| XGBoost (all features) | 9.50 | 8.50 | 7.25 | 0.766 |
| FRANQ calibrated | 2.75 | 4.00 | 2.75 | 0.797 |
| FRANQ condition-calibrated | 2.75 | 3.00 | 2.25 | 0.802 |
데이터셋별 구체적 성능 (Llama-3B):
| Dataset | Method | ROC-AUC | PR-AUC | PRR |
|---|---|---|---|---|
| Natural Questions | Degree Matrix | 0.751 | 0.557 | 0.421 |
| FRANQ condition-calibrated | 0.748 | 0.526 | 0.409 | |
| TriviaQA | FRANQ condition-calibrated | 0.821 | 0.618 | 0.576 |
| FRANQ calibrated | 0.821 | 0.623 | 0.580 | |
| PopQA | Semantic Entropy | 0.776 | 0.602 | 0.496 |
| FRANQ condition-calibrated | 0.763 | 0.605 | 0.477 | |
| SimpleQA | FRANQ condition-calibrated | 0.877 | 0.776 | 0.703 |
| Semantic Entropy | 0.863 | 0.766 | 0.684 |
3.4 구체적 예시 분석
Faithful-True 케이스:
질문: "How and when to harvest chestnuts?"
검색 문서: "Chestnuts don't ripen at the same time... generally ripen in a 10- to 30-day span in late August and September"
생성 Claim: "Chestnuts typically take around 10-30 days to ripen in late August and September"
FRANQ 분석:
1. P(faithful) = AlignScore = 0.98 (매우 높음)
2. MaxNLI = max(0.44, 0.34, 0.99) = 0.99 (강한 entailment)
3. Parametric Knowledge = 3.5×10^-15 (거의 0)
최종 점수:
- No calibration: 0.98 × 0.99 + 0.02 × 3.5×10^-15 = 0.97
- Condition-calibrated: 0.98 × f(0.99) + 0.02 × g(3.5×10^-15) = 0.93
결과: 높은 factuality 예측 (실제로 True)
Unfaithful-True 케이스:
질문: "How does RAM work and why is it important?"
검색 문서: RAM 물리적 구성에 대한 일반적 설명
생성 Claim: "RAM is a volatile memory technology"
FRANQ 분석:
1. P(faithful) = AlignScore = 0.05 (매우 낮음)
2. MaxNLI = max(0.01, 0.19, 0.06) = 0.19
3. Parametric Knowledge = 0.05 (모델 자체 지식)
최종 점수:
- No calibration: 0.05 × 0.19 + 0.95 × 0.05 = 0.06 (underestimate)
- Condition-calibrated: 0.05 × f(0.19) + 0.95 × g(0.05) = 0.95
결과: Calibration으로 정확한 factuality 복원
Unfaithful-False 케이스:
질문: "Which type of diabetes is worse type 1 or type 2?"
검색 문서: Type 2 diabetes 관련 정보
생성 Claim: "Type 1 diabetes is a condition where the body either resists the effects of insulin..."
FRANQ 분석:
1. P(faithful) = AlignScore = 0.04 (매우 낮음)
2. Parametric Knowledge = 3.8×10^-15 (거의 0)
최종 점수:
- No calibration: 0.04 × 0.72 + 0.96 × 3.8×10^-15 = 0.03
- Condition-calibrated: 0.04 × f(0.72) + 0.96 × g(3.8×10^-15) = 0.15
결과: 낮은 factuality 예측 (실제로 False)
3.5 Error Analysis 및 실패 케이스
XGBoost 의사결정 트리 분석:
FRANQ 특성으로 훈련된 XGBoost의 첫 번째 트리 구조:
Root: AlignScore > 0.72?
├─ True → MaxNLI > 0.39?
│ ├─ True → High factuality
│ └─ False → Medium factuality
└─ False → Parametric Knowledge > exp(-22.13)?
├─ True → Medium factuality
└─ False → Low factuality
이는 FRANQ의 의사결정 논리와 정확히 일치하여 방법론의 타당성을 입증한다.
Calibration Quality 분석 (ECE):
| Method | Long-form ECE | Short-form ECE |
|---|---|---|
| Max Claim Probability | 0.72 | 0.46 |
| P(True) | 0.94 | 0.71 |
| Perplexity | 0.18 | 0.17 |
| AlignScore | 0.40 | 0.13 |
| FRANQ calibrated | 0.02 | 0.07 |
| FRANQ condition-calibrated | 0.03 | 0.07 |
FRANQ의 두 calibrated 버전이 가장 잘 보정된 confidence estimates를 제공한다.
4. 한계점
4.1 아키텍처 관점의 한계
Retrieved Evidence의 완벽성 가정:
- FRANQ는 검색된 문서가 항상 사실적이라고 가정
- 실제로는 검색된 문서 자체가 편향되거나 오류를 포함할 수 있음
- Large-scale index에서 완전한 factual accuracy 보장의 어려움
구체적 문제 시나리오:
검색된 문서: "지구는 평평하다" (잘못된 정보)
모델 답변: "지구는 둥글다" (올바른 정보)
FRANQ 판단: Unfaithful → Parametric Knowledge 기반 평가
→ 올바른 답변이지만 낮은 신뢰도로 평가될 위험
Component Selection의 경험적 특성:
- Long-form과 short-form에서 서로 다른 UQ 방법 조합 사용
- 이러한 선택이 empirical performance에만 기반하여 이론적 근거 부족
- 새로운 도메인이나 태스크에서의 일반화 가능성 의문
Token Span Extraction의 취약성:
논문에서 atomic claim의 token span을 추출할 때:
- GPT-4o로 relevant words 매핑
- Inconsistent annotation으로 인한 claim 제외 발생
- "words appearing in a different order than in the text" 문제
4.2 실험 설계의 제약
제한적 데이터셋 규모:
Long-form QA:
- 총 76개 질문만 사용
- Llama-3B: 1,782 claims 중 500개만 훈련용
- Falcon-3B: 1,548 claims 중 500개만 훈련용
Manual validation 범위:
- Llama-3B: 100개 claims random sample + 359개 False/Unverifiable
- Falcon-3B: 76개 claims random sample + 240개 False/Unverifiable
GPT-4o 기반 Annotation의 편향성:
Inter-annotator agreement 분석 결과:
- Factuality: Accuracy 0.87, Cohen's Kappa 0.552
- Faithfulness: Accuracy 0.78, Cohen's Kappa 0.586
이는 moderate agreement로, annotation 품질에 개선 여지가 있음을 시사한다.
Domain-Specific 최적화의 한계:
- 각 데이터셋/모델별로 별도 훈련 필요
- Cross-domain generalization 성능 미검증
- Production 환경에서의 adaptation cost 높음
4.3 방법론적 한계
AlignScore의 한계:
논문 자체에서 확인된 문제:
- Binary threshold (>0.5) 사용 시 성능 저하 (-8.4% ROC-AUC)
- AlignScore calibration 시 오히려 성능 감소
- Raw AlignScore 값에 과도하게 의존
Parametric Knowledge의 불안정성:
- Token-level probability의 곱으로 계산: ∏p(yt|x, y<t)
- 긴 sequence에서 extremely small values (3.5×10^-15)
- Numerical instability 및 calibration 어려움
Training Data Dependency:
Condition-calibrated FRANQ의 optimal training size:
- Long-form: 300 samples에서 peak 후 감소
- Short-form: 120 samples에서 saturation
- 실제 production에서 이러한 데이터 확보의 어려움
5. 개선 방향 및 Future Work
5.1 Retrieval Quality 개선
Multi-Source Evidence Validation:
현재 FRANQ는 retrieved evidence의 factuality를 검증하지 않는다. 다음과 같은 개선이 필요하다:
개선된 아키텍처:
1. Source Credibility Scoring
- Domain expertise 평가
- Publication date 및 freshness
- Author/organization reliability
2. Cross-Reference Validation
- 여러 독립적 소스에서 일치성 확인
- Conflict detection 및 resolution
- Consensus-based confidence scoring
3. Real-time Fact-Checking Integration
- External fact-checking APIs 연동
- Knowledge graph validation
- Temporal consistency 검증
5.2 Theoretical Foundation 강화
Information-Theoretic Framework:
현재의 empirical component selection을 이론적으로 뒷받침할 필요가 있다:
Proposed Framework:
H(Y|X,R) = H_faithful(Y|X,R) × P(faithful) +
H_unfaithful(Y|X,R) × P(unfaithful)
Where:
- H_faithful: Uncertainty given faithful evidence
- H_unfaithful: Uncertainty given unfaithful evidence
- Optimal UQ method selection based on information content
Causal Reasoning Integration:
Faithfulness와 factuality 간의 causal relationship 모델링:
- Confounder identification (domain expertise, model bias)
- Counterfactual reasoning: "만약 이 evidence가 없었다면?"
- Causal effect estimation for uncertainty attribution
5.3 Scalability 및 Production 개선
Unified Architecture Design:
현재 task-specific training의 한계를 극복하기 위해:
Meta-Learning Approach:
1. Task-Agnostic Base Model
- Universal faithfulness encoder
- Domain-adaptive uncertainty predictor
- Few-shot calibration mechanism
2. Continuous Learning Pipeline
- Online feedback integration
- Gradual domain adaptation
- Catastrophic forgetting prevention
3. Hierarchical Uncertainty Modeling
- Passage-level → Claim-level → Answer-level
- Multi-granularity confidence estimation
Real-time Optimization:
Production 환경을 위한 computational efficiency 개선:
Optimization Strategies:
1. Knowledge Distillation
- Large teacher model → Small student model
- Component-wise distillation
- Performance preservation
2. Caching Strategy
- Frequent claim pattern caching
- Pre-computed faithfulness scores
- Dynamic cache management
3. Parallel Processing
- Component-parallel execution
- Batch processing optimization
- GPU acceleration
5.4 평가 및 검증 강화
Comprehensive Evaluation Framework:
현재 evaluation의 한계를 보완하기 위해:
Multi-Dimensional Assessment:
1. Robustness Testing
- Adversarial evidence injection
- Domain shift evaluation
- Temporal consistency check
2. Human-Centric Evaluation
- Expert annotation validation
- User trust measurement
- Decision impact analysis
3. Longitudinal Analysis
- Performance degradation over time
- Adaptation capability assessment
- Real-world deployment metrics
5.5 실용적 확장 방향
Domain-Specific Customization:
Healthcare Domain:
- Medical knowledge base integration
- Clinical guideline compliance
- Risk-aware uncertainty thresholds
Legal Domain:
- Case law reference validation
- Statutory compliance checking
- Precedent-based confidence scoring
Scientific Domain:
- Peer-review quality assessment
- Citation network analysis
- Reproducibility-based scoring
Human-AI Collaboration Enhancement:
Interactive Uncertainty Explanation:
1. Component Attribution
- "이 claim이 불확실한 이유: faithfulness 0.1, parametric knowledge 0.05"
- Visual uncertainty breakdown
- Evidence quality indicators
2. Confidence Interval Provision
- Range-based uncertainty estimates
- Sensitivity analysis results
- Worst-case scenario planning
3. Feedback Loop Integration
- User correction incorporation
- Expert validation system
- Continuous improvement mechanism
6. 가능한 질문들
"Faithfulness와 Factuality를 분리하는 것이 항상 바람직한가?"
→ 특정 도메인(의료, 법률)에서는 retrieved evidence에 대한 strict adherence가 더 중요할 수 있다. Domain-specific policy가 필요하다.
"Retrieved evidence 자체가 틀렸을 때는 어떻게 처리하는가?"
→ 현재 FRANQ는 이를 직접 다루지 않는다. Multi-source validation이나 source credibility scoring 등의 추가 레이어가 필요하다.
"Component selection이 arbitrary하지 않나?"
→ 저자들도 인정하는 한계점이다. 각 component의 선택이 empirical performance에만 기반하여 이론적 justification이 부족하다.
"Real production에서 condition-specific calibration이 실용적인가?"
→ 각 도메인별로 별도 calibration이 필요하므로 maintenance overhead가 상당할 수 있다. Trade-off 고려가 필요하다.
7. 추가 인사이트 및 함의
7.1 RAG Evaluation 패러다임의 전환
From Faithfulness-Only to Factuality-First:
- 기존: "검색 문서와 일치하는가?"
- 새로운 관점: "실제로 사실적으로 올바른가?"
- 이는 RAG 시스템의 평가 기준에 근본적 변화를 제시
7.2 Uncertainty Quantification의 조건부 접근
Conditional UQ의 새로운 가능성:
- 단순히 하나의 UQ 방법을 적용하는 것보다 상황에 따른 selective application
- 다른 NLP 태스크에도 적용 가능한 general framework
- Multi-modal 환경에서의 확장 가능성
7.3 Human-AI Collaboration 관점
Uncertainty as Communication Tool:
- 단순히 "불확실하다"가 아닌 "왜 불확실한가"에 대한 설명
- Faithful vs Unfaithful uncertainty의 구분으로 사용자에게 더 rich한 정보 제공
- Expert knowledge와 AI knowledge의 complementary relationship
8. 결론
FRANQ는 RAG 환경에서 faithfulness와 factuality를 분리하여 접근한 첫 번째 systematic framework라는 점에서 의미가 있다. Conditional uncertainty quantification이라는 새로운 패러다임을 제시하고, 실험적으로 기존 방법들보다 우수한 성능을 보였다.
하지만 retrieved evidence의 완벽성 가정과 component selection의 경험적 특성은 실제 deployment를 위해 해결해야 할 핵심 과제다. 특히 large-scale production 환경에서는 검색된 문서 자체의 품질 보장과 domain adaptation이 더욱 중요해진다.
향후 연구에서는 retrieval quality assessment와 theoretical foundation 강화에 집중해야 할 것으로 보이며, 실제 사용자 연구를 통한 practical effectiveness 검증도 필요하다. 이 논문이 제시한 faithfulness-factuality 분리 접근법은 RAG 시스템의 신뢰성 향상을 위한 중요한 디딤돌이 될 것으로 예상된다.
