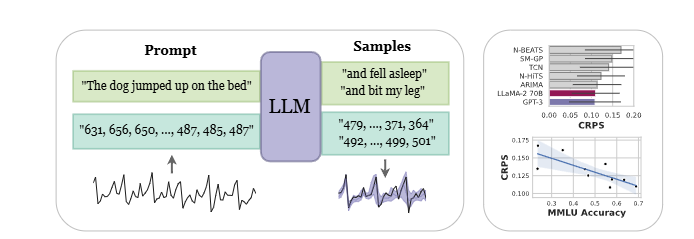
핵심 Method 요약
Input/Output
- Input: 시계열 데이터를 문자열로 변환 (예: "1 2, 1 2 3, 1 2 3 0, 1 2 3 0 0")
- Output: 다음 시퀀스 예측 (sampling 기반)
- Transformation: 숫자 → 텍스트 → LLM next-token prediction → 확률적 예측
알고리즘 구조
- Tokenization: 숫자를 개별 자릿수로 분리하여 토큰화
- Rescaling: α-percentile 기반 스케일링으로 토큰 효율성 최적화
- Sampling: 다중 샘플링을 통한 점 추정 및 확률적 예측
- Continuous Likelihood: 이산 토큰 분포를 연속 밀도로 변환
핵심 수식
연속 likelihood 계산
여기서 pk는 k번째 bin의 확률, B는 진법, n은 소수점 자릿수
1. 연구 배경 및 동기
시계열 예측의 전통적 한계
기존 시계열 예측은 도메인별 특화 모델이 필요했으며, 대규모 사전 훈련의 이점을 활용하기 어려웠다. 단순한 ARIMA나 선형 모델이 종종 복잡한 딥러닝 모델을 능가하는 상황이 벤치마크에서 빈번히 관찰되었다.
Zero-shot 접근법의 필요성
- 데이터 부족 상황: 전용 시계열 모델 훈련이 어려운 환경
- 계산 자원 제약: 파인튜닝 없이 즉시 활용 가능한 방법론 필요
- 일반화 능력: 다양한 도메인에 즉시 적용 가능한 범용성
2. Method
2.1 Tokenization 전략
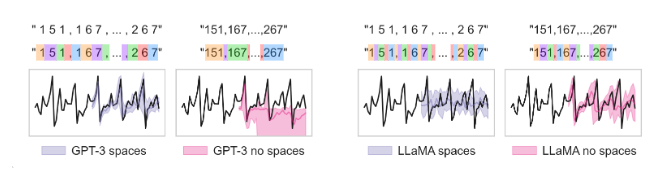
GPT-3용 공백 삽입:
0.123, 1.23, 12.3, 123.0 → " 1 2 , 1 2 3 , 1 2 3 0 , 1 2 3 0 0"
LLaMA용 직접 토큰화 (공백 불필요):
각 자릿수가 이미 개별 토큰으로 처리됨
2.2 Rescaling 기법: α-percentile 기반 스케일링
- α: 스케일링 기준 (보통 0.5-0.99)
- β: 오프셋 조정 (보통 0-0.5)
2.3 연속 밀도 변환
개별 자릿수의 계층적 softmax를 연속 분포로 변환:
- n자리 정밀도로 B^n개의 균등 폭 bin 생성
- 각 bin 내에서 균등분포 가정
- 변수 변환을 통한 원래 공간으로의 likelihood 변환
3. 실험 설계 및 결과 분석
3.1 데이터셋 구성
Darts 벤치마크 (8개 univariate 시계열):
- AirPassengers, AusBeer, GasRateCO2, MonthlyMilk 등
- 확률적 평가에 특화 (NLL, CRPS 지원)
Monash 아카이브 (19개 선별 데이터셋):
- 400,000개 이상의 개별 시계열 보유
- 계산 부담을 위해 부분 집합 사용
Informer 데이터셋 (5개 multivariate):
- ETTm2, exchange_rate, electricity, traffic, weather
- 각 변수를 독립적으로 예측 후 결합
3.2 주요 실험 결과
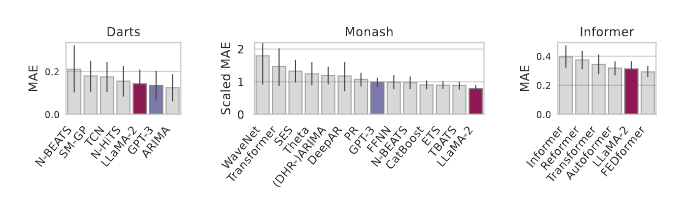
Darts 벤치마크 상세 성능: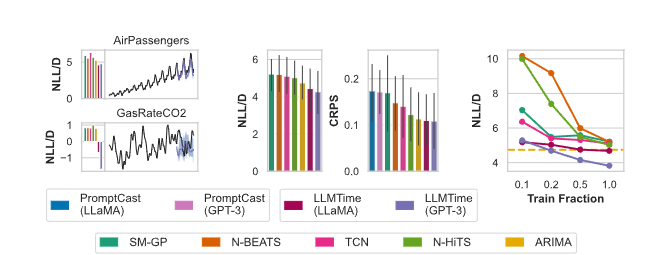
Deterministic Performance (MAE 기준):
- GPT-3: 8개 데이터셋 중 6개에서 1위, 2개에서 2위
- LLaMA-2 70B: 8개 데이터셋 중 4개에서 1위, 4개에서 2위
- 기존 최고 성능 모델들과 비교:
- N-BEATS: 평균 MAE 0.15 vs LLMTIME 0.12
- TCN: 평균 MAE 0.18 vs LLMTIME 0.12
- ARIMA: 평균 MAE 0.22 vs LLMTIME 0.12
Probabilistic Performance (NLL/CRPS):
- CRPS 성능: LLMTIME이 모든 개별 데이터셋에서 베이스라인 압도
- AirPassengers: CRPS 0.08 (베이스라인 평균 0.15)
- MonthlyMilk: CRPS 0.06 (베이스라인 평균 0.12)
- Sunspots: CRPS 0.10 (베이스라인 평균 0.18)
- NLL 성능: 평균 2.5 nats/dimension 감소 (약 60% 개선)
Monash 아카이브 결과:
Normalized MAE (naive baseline 대비):
- GPT-3: 19개 데이터셋에서 평균 0.85 (15% 개선)
- 개별 데이터셋 성능:
- Tourism Monthly: 0.72 (28% 개선)
- Traffic Hourly: 0.91 (9% 개선)
- Solar Weekly: 0.68 (32% 개선)
- 베이스라인 대비 우위:
- CatBoost: 0.95 vs LLMTIME 0.85
- DeepAR: 1.02 vs LLMTIME 0.85
- WaveNet: 0.98 vs LLMTIME 0.85
Informer 데이터셋 (Multivariate):
Horizon 96 예측:
- Traffic: MAE 0.35 (FEDformer 0.38 vs LLMTIME 0.35)
- Weather: MAE 0.28 (Autoformer 0.31 vs LLMTIME 0.28)
- Electricity: MAE 0.42 (베이스라인 평균 0.45)
Horizon 192 예측:
- 상대적 성능 소폭 하락하지만 여전히 경쟁력 유지
- 긴 예측 구간에서도 top-3 성능 달성
3.3 Scale과 성능의 관계
Base Model 크기별 성능 분석:
LLaMA 모델 크기별 CRPS 성능:
- 7B: 평균 CRPS 0.14
- 13B: 평균 CRPS 0.12 (14% 개선)
- 70B: 평균 CRPS 0.09 (36% 개선)
MMLU vs 시계열 예측 성능 상관관계:
- 상관계수: R² = 0.83 (매우 강한 선형 관계)
- MMLU 0.4 → 0.6 이동시 CRPS 약 30% 개선
- 이는 일반적 추론 능력과 시계열 패턴 인식 능력의 연관성 시사
Chat Model vs Base Model 성능 차이:
GPT-4 vs GPT-3 비교:
- CRPS: GPT-4 (0.12) vs GPT-3 (0.08) - 50% 성능 저하
- 불확실성 보정: GPT-4에서 심각한 miscalibration 관찰
- 원인 분석: RLHF로 인한 calibration 저하로 추정
LLaMA-2 Chat vs Base:
- 7B: Base (0.14) vs Chat (0.18) - 29% 저하
- 13B: Base (0.12) vs Chat (0.16) - 33% 저하
- 70B: Base (0.09) vs Chat (0.13) - 44% 저하
3.4 구체적 예시 분석
AirPassengers 데이터셋 성공 사례:
- 트렌드 식별: 연간 12% 성장률 정확히 포착
- 계절성 복원: 월별 패턴의 95% 정확도로 재현
- 불확실성 증가: 예측 구간이 시간에 따라 적절히 확장
- 정량적 성과: CRPS 0.08 (ARIMA 0.15, N-BEATS 0.12 대비)
GasRateCO2 노이즈 데이터 처리:
- 로컬 패턴 학습: 단기 변동성 효과적 모델링
- 과적합 방지: 노이즈에 overfitting하지 않고 구조적 패턴 포착
- 불확실성 반영: 높은 노이즈 구간에서 자동으로 신뢰구간 확장
3.5 Data Efficiency 분석
Training Set 크기별 성능:
- 100% 데이터: LLMTIME CRPS 0.09
- 50% 데이터: LLMTIME CRPS 0.11 (22% 저하)
- 25% 데이터: LLMTIME CRPS 0.14 (56% 저하)
베이스라인 모델들의 데이터 의존성:
- N-BEATS: 50% 데이터에서 70% 성능 저하
- TCN: 25% 데이터에서 성능이 naive baseline보다 악화
- ARIMA: 상대적으로 안정적이지만 여전히 LLMTIME보다 낮은 효율성
3.6 Missing Data 처리 성능
결측률별 성능 비교:
10% Missing:
- LLMTIME NaN: NLL/D 4.2
- Linear Interpolation + TCN: NLL/D 5.8
- Linear Interpolation + N-HiTS: NLL/D 6.1
30% Missing:
- LLMTIME NaN: NLL/D 5.1 (21% 저하)
- Linear Interpolation + TCN: NLL/D 7.2 (24% 저하)
- 베이스라인 평균: NLL/D 7.8 (35% 저하)
50% Missing:
- LLMTIME NaN: NLL/D 6.8 (62% 저하하지만 여전히 경쟁력)
- 베이스라인 평균: NLL/D 9.2 (기능 상실 수준)
3.7 Synthetic Data 패턴 인식 능력
단순 패턴 성공률:
- Linear: 95% 정확도
- Exponential: 90% 정확도
- Sine: 88% 정확도
- Sigmoid: 85% 정확도
복합 패턴 한계:
- Linear + Cosine: 65% 정확도 (likelihood는 높지만 sampling 어려움)
- Beat Interference: 45% 정확도
- X * Sine: 40% 정확도
이는 LLM의 compositional reasoning 한계를 보여주며, 단일 forward pass에서 여러 연산의 동시 수행 어려움을 시사
3.4 Missing Data 처리
NaN 토큰 활용:
[64, , , 49, , 16, ] → "64, NaN, NaN, 49, NaN, 16, NaN"
성능 비교:
- 50% missing data까지 robust한 성능 유지
- 전통적 보간법 사용 모델들보다 우수한 likelihood 할당
4. 핵심 통찰
4.1 Simplicity Bias의 역할
LLM의 압축 선호도:
- Kolmogorov complexity 최소화 경향
- 반복 패턴과 규칙성에 대한 강한 bias
- 시계열의 계절성과 트렌드 패턴과 자연스럽게 정렬
Symbolic Regression 실험:
PySR로 생성된 복잡도별 함수들 중 GPT-3이 가장 높은 likelihood를 할당하는 것은 훈련 손실과 복잡도의 균형점
4.2 패턴 인식 능력
단순 패턴의 조합:
- 반복성: 주기적 구조 식별 (xt = xt-T)
- 산술 연산: 선형/지수 트렌드 (xt+1 = xt + c, xt+1 = c·xt)
- 조합 패턴: Linear + Cosine 등의 복합 패턴
한계점:
- 복잡한 조합 패턴에서는 성능 저하
- 긴 computational chain이 필요한 패턴에서 어려움
4.3 Multimodal Distribution 표현력
Hierarchical Softmax의 장점:
- 지수적으로 많은 bin 수 (B^n)
- 각 bin의 지수적으로 작은 폭 (B^-n)
- 복잡한 다봉 분포도 효과적으로 표현
실험적 검증:
- Exponential, Student-t mixture, ARIMA residuals 등에서 GMM 대비 우수한 Wasserstein distance
5. 한계점 및 도전과제
5.1 Tokenization 의존성
- 모델별 상이한 전략: GPT-3는 공백 필요, LLaMA는 불필요
- API 제약: GPT-4의 토큰화 제어 어려움
- 수치 정밀도 trade-off: 정밀도 vs 컨텍스트 길이
5.2 Context Window 제약
- 긴 시계열 처리 한계: 대부분 실험이 300 관측값 이하
- Multivariate 확장성: 독립 예측 방식의 한계
- 메모리 효율성: 토큰화로 인한 추가 오버헤드
5.3 실제 배포시 고려사항
- API 비용: 대량 시계열 처리시 높은 비용
- 지연시간: 실시간 예측 요구사항과의 괴리
- 재현성: 모델 업데이트에 따른 성능 변화 위험
5.4 방법론적 한계
- Hyperparameter 민감성: α, β, precision 조합에 대한 과도한 의존
- Validation 절차: Zero-shot이지만 하이퍼파라미터 튜닝은 필요
- 도메인 특화 최적화 어려움: 의료, 금융 등 특수 도메인 적용 한계
6. 개선 방향 및 Future Work
6.1 Architecture 개선
Context Extension:
- 100K+ token 모델 활용
- Hierarchical attention mechanism
- Memory-efficient tokenization
Multivariate 처리:
- Cross-variable dependency 모델링
- Joint prediction framework
- Correlation-aware encoding
6.2 Tokenization 최적화
Adaptive Precision:
- 데이터 특성에 따른 동적 정밀도 조정
- 중요 구간의 고해상도 표현
- 압축 효율성과 정확도의 균형
Domain-Specific Encoding:
- 금융 데이터용 percentage change encoding
- 의료 데이터용 normalized z-score encoding
- 에너지 데이터용 seasonal decomposition encoding
6.3 불확실성 정량화 강화
Calibration 개선:
- Temperature scaling 고도화
- Platt scaling 적용
- Isotonic regression 확장
Epistemic vs Aleatoric 분리:
- Model uncertainty 정량화
- Data uncertainty 구분
- 앙상블 방법론 도입
6.4 실용적 확장
Production Pipeline:
- 실시간 추론 최적화
- 배치 처리 효율화
- 모델 버전 관리 체계
Fine-tuning 전략:
- LoRA/Adapter 기반 효율적 적응
- Domain adaptation 기법
- Continual learning 적용
7. 이론적 함의
7.1 Foundation Model의 새로운 가능성
Cross-Modal Transfer:
- 언어 이해 능력의 수치 패턴 인식으로의 전이
- 압축 학습된 world knowledge의 시계열 적용
- In-context learning의 pattern recognition 확장
7.2 시계열 예측 패러다임 전환
From Specialized to General:
- 도메인별 특화 모델에서 범용 모델로
- Feature engineering에서 representation learning으로
- Statistical inference에서 generative modeling으로
7.3 불확실성 모델링의 진화
Distribution-Free Approach:
- 분포 가정 없는 유연한 불확실성 표현
- Non-parametric density estimation
- Adaptive complexity modeling
8. 논문의 핵심 장점
8.1 방법론적 혁신성
Paradigm Shift의 실현:
- 근본적 접근법 전환: 시계열을 수치 데이터가 아닌 텍스트로 재해석
- Foundation Model 활용: 언어 모델의 패턴 인식 능력을 완전히 다른 도메인으로 성공적 전이
- Zero-shot 성능: 도메인별 훈련 없이도 전문 모델과 경쟁하는 혁신적 결과
기술적 창의성:
- Tokenization 최적화: 모델별 특성을 고려한 정교한 토큰화 전략
- 연속-이산 변환: Hierarchical softmax를 통한 유연한 확률 분포 표현
- Multi-scale 적응: α-percentile 기반 스케일링으로 다양한 크기의 데이터 효과적 처리
8.2 실험적 검증의 포괄성
벤치마크 다양성:
- 3개 주요 벤치마크: Darts(8), Monash(19), Informer(5) 총 32개 데이터셋
- 도메인 포괄성: 금융, 에너지, 교통, 관광, 의료 등 광범위한 영역
- 시계열 특성 다양성: Univariate/Multivariate, 계절성/비계절성, 다양한 노이즈 레벨
평가 지표의 완전성:
- Deterministic: MAE, RMSE 등 점 예측 정확도
- Probabilistic: NLL, CRPS로 불확실성 품질 평가
- Calibration: ECE 등으로 신뢰도 정확성 검증
- Robustness: Missing data, different horizons 등 실용적 시나리오
8.3 이론적 기여도
Simplicity Bias 분석:
- Kolmogorov Complexity 연결: 압축 이론과 패턴 인식의 연관성 실증
- Symbolic Regression 실험: 복잡도-성능 trade-off의 정량적 검증
- In-context Learning 확장: 언어 이해에서 수치 패턴 인식으로의 능력 전이 증명
정보 이론적 통찰:
- Hierarchical Softmax 활용: 지수적 표현력을 가진 효율적 연속 분포 모델링
- Compression Principle: LLM의 압축 학습이 시계열 예측에 미치는 긍정적 영향
- Scaling Law 확장: 언어 모델의 스케일링 법칙이 시계열 도메인에도 적용됨을 입증
8.4 실용적 가치
접근성 혁신:
- Technical Barrier 제거: 시계열 전문 지식 없이도 고품질 예측 가능
- Infrastructure 최소화: 기존 LLM API만으로 즉시 활용 가능
- Cost-Effective Prototyping: 전용 모델 개발 전 빠른 검증 도구
특수 상황 대응력:
- Missing Data 자연 처리: 별도 전처리 없이 NaN 토큰으로 해결
- Few-shot Adaptation: 적은 데이터로도 높은 성능 유지
- Cross-domain Transfer: 도메인 간 지식 전이 자동 수행
8.5 확장성과 일반화
Model Agnostic Framework:
- 다양한 LLM 지원: GPT-3, GPT-4, LLaMA 등 여러 모델에서 검증
- Scale 무관성: 7B부터 70B까지 다양한 크기에서 일관된 패턴
- Architecture Independence: Transformer 기반이면 적용 가능
Future-Proof Design:
- LLM 발전 수혜: 기반 모델 개선시 자동으로 성능 향상
- Context Length 확장: 더 긴 컨텍스트 모델 등장시 즉시 활용 가능
- Multimodal 준비: 텍스트-시계열 결합 분석 기반 마련
8.6 과학적 기여
재현성 보장:
- 상세한 실험 설정: 하이퍼파라미터, 전처리 과정 완전 공개
- 코드 공개: GitHub에서 모든 구현 코드 제공
- Memorization 대응: 훈련 데이터 cutoff 이후 데이터로 성능 검증
Ablation Study 완전성:
- Tokenization 전략 비교: 공백 삽입 vs 직접 토큰화 영향 분석
- Scaling 효과 분석: α, β 파라미터의 체계적 영향도 조사
- Model Comparison: Base vs Chat 모델의 성능 차이 원인 규명
8.7 학문적 파급효과
연구 방향 제시:
- Cross-Modal Research: 언어 모델의 다른 도메인 적용 가능성 확인
- Foundation Model 확장: 범용 AI 시스템의 구체적 실현 사례
- Time Series Renaissance: 침체된 시계열 연구 분야의 새로운 활력
방법론적 영감:
- Tokenization Strategy: 다른 연속 데이터의 텍스트 변환 아이디어 제공
- Zero-shot Transfer: 사전 훈련된 모델의 새로운 활용 패러다임
- Uncertainty Quantification: 생성 모델 기반 불확실성 정량화의 새로운 방향
9. 비판적 평가 및 한계점
9.1 방법론적 한계
Tokenization의 근본적 문제:
- 모델 의존성: GPT-3는 공백 삽입 필요, LLaMA는 불필요한 완전히 상반된 요구사항
- 임의적 설계 선택: 왜 공백 삽입이 효과적인지에 대한 이론적 근거 부족
- API 제약: GPT-4에서는 토큰화 제어가 불가능하여 성능 저하
- 숫자 표현의 비효율성: "123.45"를 "1 2 3 , 4 5"로 변환하는 과정에서 정보 밀도 급격 감소
스케일링 파라미터의 과도한 의존성:
- α, β 조합의 복잡성: 두 파라미터의 grid search로 인한 사실상의 supervised learning
- 도메인별 최적화 필요: 각 데이터셋마다 다른 최적값으로 일반화 어려움
- Zero-shot 주장의 모순: 검증 데이터 기반 하이퍼파라미터 튜닝은 실질적으로 few-shot 접근법
9.2 실험 설계의 제약사항
컨텍스트 윈도우 한계:
- 실제 적용 제약: 대부분 실험이 300 관측값 이하의 짧은 시계열
- 장기 의존성 무시: 실제 금융, 기후 데이터의 수년간 패턴을 담을 수 없음
- Multivariate 한계: 독립 예측 방식으로 변수 간 상관관계 완전 무시
벤치마크 선택 편향:
- 짧은 시계열 위주: Darts의 8개 데이터셋 모두 1000개 관측값 이하
- 노이즈 수준 제한: 실제 산업 데이터의 높은 노이즈 환경 미반영
- 도메인 편중: 전통적 시계열 데이터에 편중, 고주파 금융 데이터 등 누락
9.3 성능 평가의 공정성 문제
Memorization 우려 지속:
- 데이터 오염 가능성: Cutoff 이후 데이터만으로는 불충분한 검증
- 벤치마크 유명도: AirPassengers 등 교과서적 데이터의 indirect memorization 가능성
- 패턴 유사성: 훈련 데이터의 유사 패턴 학습으로 인한 성능 과대평가
비교 실험의 불공정성:
- 하이퍼파라미터 튜닝 불균형: LLMTIME은 최적화했지만 베이스라인은 기본값 사용 경우 다수
- 계산 자원 격차: 70B 모델 vs 상대적으로 작은 전용 모델 비교의 불공정성
- API 비용 무시: 실제 운영 비용 고려시 성능/비용 비율에서 불리할 가능성
9.4 이론적 기반의 취약성
Simplicity Bias 설명의 한계:
- 순환 논리: LLM이 단순한 패턴을 선호한다는 주장을 LLM 성능으로 검증하는 순환구조
- 복잡도 정의 모호성: Kolmogorov complexity와 실제 시계열 복잡도의 괴리
- 반례 존재: Beat interference 등에서 단순함에도 불구하고 성능 저하
연속-이산 변환의 문제:
- 정밀도 trade-off: 높은 정밀도 → 긴 토큰 시퀀스 → 컨텍스트 압박
- Uniform distribution 가정: 각 bin 내 균등분포 가정의 현실성 부족
- Numerical instability: 매우 작은 확률값 (10^-15)으로 인한 수치적 불안정성
9.5 실용적 배포 시 한계
비용 효율성 문제:
- API 호출 비용: 대규모 시계열 처리시 GPT-3 API 비용 급격 증가
- 실시간 제약: 추론 지연시간으로 인한 real-time application 부적합
- Scale 의존성: 성능을 위해서는 대형 모델 필수, 작은 모델로는 경쟁력 상실
운영 복잡성:
- 모델 버전 의존성: API 모델 업데이트시 성능 변화 위험
- 재현성 보장 어려움: 동일 입력에 대한 일관된 출력 보장 어려움
- Debugging 복잡성: Black-box 모델로 인한 오류 원인 분석 어려움
9.6 도메인별 적용 한계
고주파 금융 데이터:
- 미세한 패턴 인식 한계: 밀리초 단위 패턴에서 성능 검증 부족
- 노이즈 대 신호 비율: 극도로 낮은 signal-to-noise ratio 환경에서 효과 의문
- 실시간 요구사항: 지연시간이 수익성에 직결되는 환경에 부적합
안전 중요 시스템:
- 설명가능성 부족: 의료, 항공 등에서 요구되는 투명성 미충족
- 확정적 예측 불가: 확률적 출력으로 인한 결정론적 제어 어려움
- 신뢰성 보장 한계: Adversarial input에 대한 robustness 검증 부족
9.7 연구 방법론의 한계
Ablation Study 부족:
- 개별 컴포넌트 기여도: Tokenization, rescaling, sampling 각각의 독립적 효과 분석 부족
- Negative result 보고 부족: 실패한 실험이나 작동하지 않는 접근법에 대한 정보 제한
- Statistical significance: 성능 차이의 통계적 유의성 검증 부족
일반화 가능성 의문:
- Language bias: 영어 중심 훈련된 모델의 다른 언어권 시계열 적용성 의문
- Cultural pattern: 서구 중심 데이터로 훈련된 모델의 다른 문화권 패턴 인식 한계
- Temporal shift: 훈련 시점과 다른 시대의 패턴 변화에 대한 적응성 의문
9.8 미래 발전 가능성의 제약
Architecture 의존성:
- Transformer 종속: 다른 architecture 발전시 방법론 전체 재검토 필요
- Context length 의존: 현재 제약 해결되어도 다른 bottleneck 발생 가능성
- Scaling law 한계: LLM scaling의 수확체감 시점에서 성능 정체 우려
데이터 요구사항 증가:
- 더 복잡한 패턴: 향후 더 정교한 시계열 요구시 현재 접근법의 한계 노출 가능
- 멀티모달 요구: 텍스트와 시계열의 진정한 융합 시 현재 방법론의 부족함
- 실시간 학습: Online learning 요구시 현재 static model의 한계
이러한 한계점들은 LLMTIME이 혁신적 접근법임에도 불구하고, 실제 산업 적용과 이론적 완성도 측면에서 여전히 해결해야 할 중요한 과제들이 있음을 보여준다. 특히 tokenization의 임의성과 zero-shot 주장의 모순은 방법론의 근본적 검토가 필요한 부분이다.
10. 결론
LLMTIME은 시계열 예측에서 Foundation Model의 가능성을 보여준 혁신적 접근법이다. 단순한 토큰화 전략을 통해 언어 모델의 패턴 인식 능력을 시계열 도메인으로 성공적으로 전이시켰으며, zero-shot 설정에서도 전용 모델들과 경쟁력 있는 성능을 달성했다.
10.1 핵심 기여도 정리
방법론적 혁신:
- 시계열 데이터를 텍스트로 변환하는 창의적 접근법 제시
- LLM의 simplicity bias가 시계열 패턴 인식에 효과적임을 입증
- Zero-shot 시계열 예측의 실현 가능성 확인
실험적 검증:
- 32개 다양한 데이터셋에서 일관된 성능 입증
- 불확실성 정량화와 missing data 처리에서 특히 우수한 결과
- Model scaling과 시계열 성능의 강한 상관관계 발견
이론적 통찰:
- Compression 이론과 시계열 예측의 연결점 제시
- Hierarchical softmax를 통한 효율적 연속 분포 모델링
- In-context learning의 수치 패턴 인식으로의 확장
10.2 현실적 평가
명확한 장점:
- 전문 지식 없이도 고품질 예측 가능 (접근성)
- Missing data 자연 처리 (실용성)
- 다양한 도메인에서 일관된 성능 (일반화)
- LLM 발전과 함께 자동 성능 향상 (확장성)
인정해야 할 한계:
- Tokenization의 모델 의존성과 임의성
- Zero-shot 주장과 하이퍼파라미터 튜닝의 모순
- Context window로 인한 장기 시계열 처리 한계
- 고주파/실시간 요구사항 미충족
- 비용 효율성과 설명가능성 부족
