핵심 Method 요약
Input/Output
- Input: Text query + Low-resolution image (initially 1/4 resolution)
- Output: Text answer + Optional high-resolution image request
- Transformation: Low-res image → VLM decision → High-res request (if needed) → Final answer
알고리즘 구조
- Image Processing: Dynamic resolution switching (1/4 → full resolution)
- Decision Making: Reinforcement Learning with GRPO (Group Relative Policy Optimization)
- Evaluation: LLM-as-Judge strategy for reward assignment
- Generation: Multi-turn conversation with special tokens for image upscaling
핵심 수식
보상 함수: R_overall = R_accuracy + R_format - P_control
→ 강화학습을 통해 VLM이 스스로 고해상도 이미지 필요 여부를 동적으로 결정
1. 연구 배경 및 동기
기존 VLM의 한계
현재 비전-언어 모델들은 성능 향상을 위해 지속적으로 증가하는 시각 토큰을 사용하고 있다.
LLaVA 1.5: 2048×1024 이미지 → 576개 시각 토큰 Qwen2.5-VL: 동일 이미지 → 2,678개 시각 토큰 (4.6배 증가)
근본적 문제점들
비효율적인 자원 사용
- 모든 태스크에 동일한 고해상도 처리를 적용
- 대부분의 일반적인 VQA 작업에서는 1/4 해상도로도 충분한 성능 달성
- 계산 비용이 시각 토큰 수에 비례하여 급격히 증가
태스크별 요구사항 무시
- OCR이 필요한 복잡한 태스크: 고해상도 필수
- 일반적인 VQA 태스크: 저해상도로도 충분
- 기존 방법들은 이러한 차이를 고려하지 않고 획일적 처리
고정된 압축 비율의 한계
- 기존 Efficient VLM들(FastV, SparseVLM)은 고정된 임계값 사용
- OCR 관련 벤치마크에서 성능 저하 발생
- 샘플별 복잡도 차이를 반영하지 못함
연구의 핵심 질문
"VLM이 스스로 판단하여 언제 고해상도 이미지가 필요한지 동적으로 결정할 수 있다면?"
→ VisionThink로 해결하자!
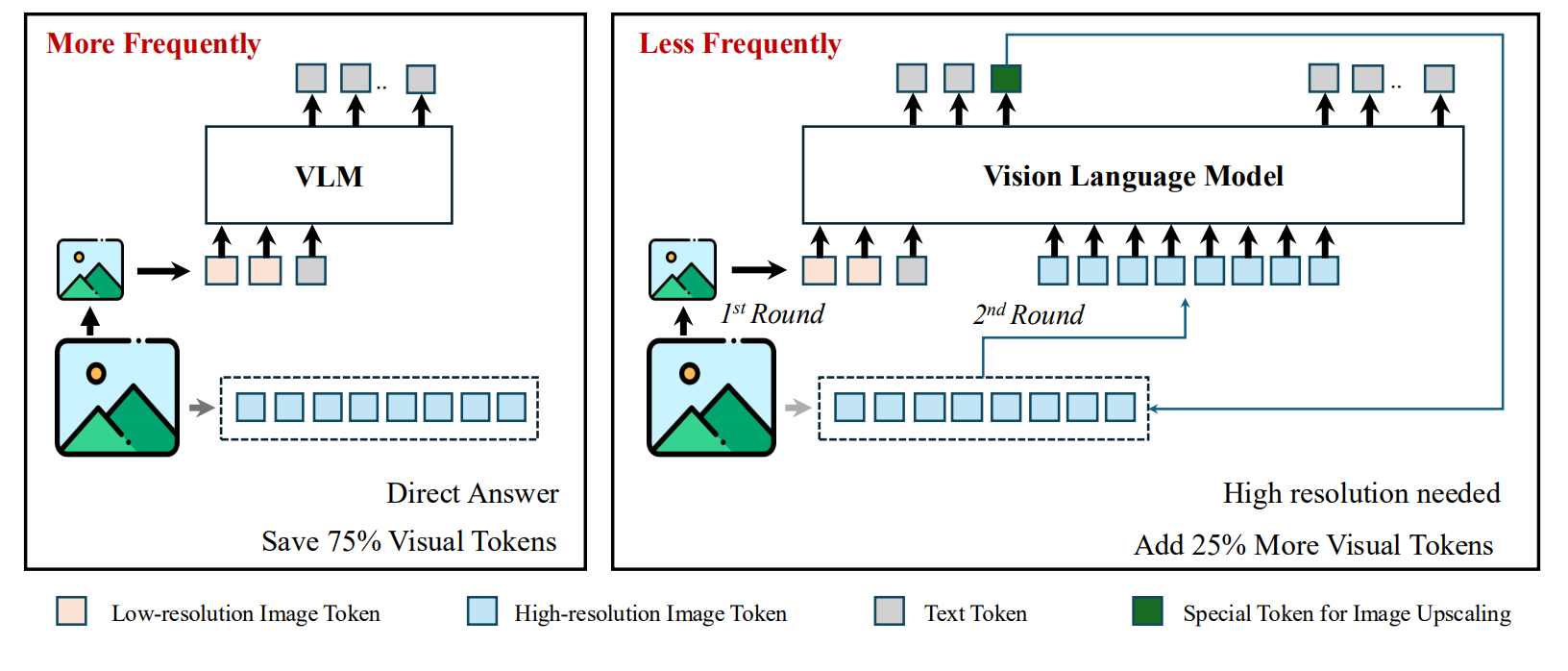
2. Method
전체 아키텍처 개요
Stage 1: Low-Resolution Processing
VLM이 먼저 1/4 해상도 이미지로 질문에 답변을 시도한다. 정보가 충분하면 바로 답변을 생성한다.
Stage 2: Adaptive High-Resolution Request
저해상도 정보가 불충분하다고 판단되면, 특별한 토큰을 출력하여 원본 고해상도 이미지를 요청한다.
Stage 3: Enhanced Answer Generation
고해상도 이미지를 바탕으로 더 정확한 최종 답변을 생성한다.
강화학습 기반 의사결정
Multi-Turn GRPO 확장
기존 GRPO 알고리즘을 Multi-turn 상황에 맞게 확장
# Multi turn GRPO 목적 함수
J_GRPO(θ) = E[
1/G * Σ(1/Σ I(o_i,t)) * Σ I(o_i,t) *
min(p_i,t * Â_i,t, clip(p_i,t, 1-ε, 1+ε) * Â_i,t)
- β * D_KL[π_θ||π_ref]
]LLM-as-Judge 전략
- 문제: 일반 VQA는 정답이 모호하거나 다양할 수 있어 보상 설계가 어려움
- 해결: 외부 LLM(GPT-4o)을 판사로 사용하여 의미적 일치성 평가
- 장점: 텍스트만으로 평가하여 시각적 편향 제거, 이산적 보상(0 또는 1)으로 오판 최소화
균형잡힌 보상 함수 설계
3-Component 보상 시스템
R_overall = R_accuracy + R_format - P_control
Accuracy Reward: LLM-as-Judge가 평가한 답변 정확성 (0 또는 1)
Format Reward: 출력 형식 준수 여부 (최대 0.5점)
<think></think>태그 내 추론 과정<answer></answer>태그 내 최종 답변- JSON 형식의 tool call (고해상도 요청 시)
Penalty Control: 극단적 행동 방지를 위한 적응적 페널티
P_control = 0.1 * [
1_direct * I(r < θ) + # 직접 답변에 페널티 (r < 0.2일 때)
1_high * I(r ≥ θ) # 고해상도 요청에 페널티 (r ≥ 0.2일 때)
]여기서 r = C_direct / (C_direct + C_high)
데이터 준비 전략
자동 데이터 분류
기반 모델(Qwen2.5-VL)을 사용하여 20K 샘플을 자동 분류
- 각 샘플에 대해 8번의 rollout 수행 (temperature=1)
- 고해상도와 저해상도 모두에서 정답률 비교
- 10K 고해상도 필요 샘플 + 10K 저해상도 충분 샘플로 균형잡힌 데이터셋 구성
3. 실험 설계 및 결과 분석
데이터셋
평가 벤치마크 분류
- Strong OCR-Related: ChartQA, OCRBench, MathVista (고해상도 필수)
- Weak OCR-Related: MME, DocVQA, RealWorldQA (저해상도 충분)
기반 모델: Qwen2.5-VL-7B-Instruct
평가 Metric 및 Baseline
성능 평가
- 각 벤치마크별 정확도
- 고해상도 이미지 요청 비율
- 추론 시간 비교
효율성 평가
- 시각 토큰 사용량 (약 51.3% 보유)
- vLLM 프레임워크를 사용한 실제 추론 시간
실험 결과
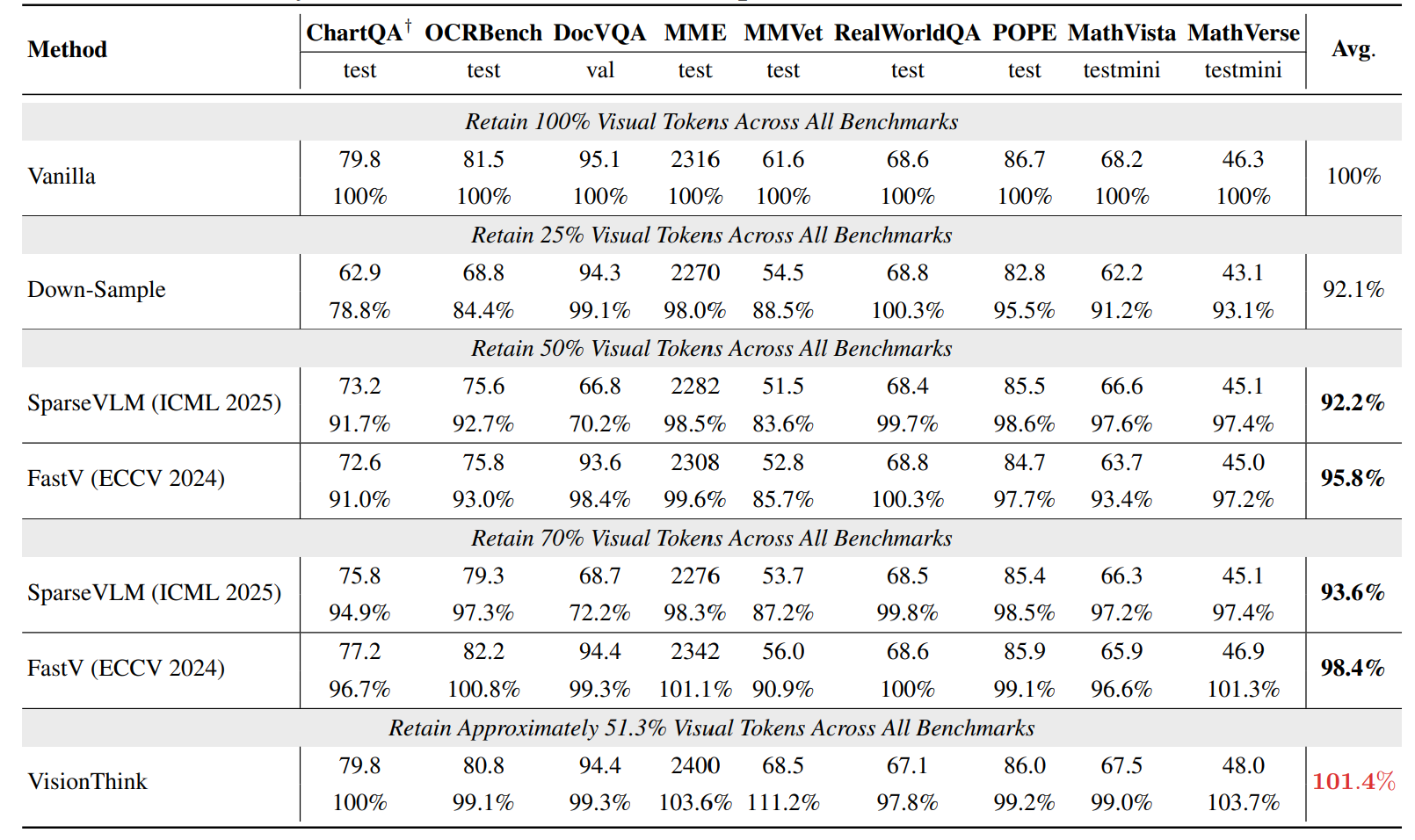
의사결정 능력
| 벤치마크 | 고해상도 요청 비율 |
|---|---|
| ChartQA (Strong OCR) | 79% |
| OCRBench (Strong OCR) | 62% |
| MME (Weak OCR) | 31% |
| DocVQA (Weak OCR) | 7% |
KEY INSIGHTS
- 지능적 판단: OCR이 필요한 태스크에서 높은 고해상도 요청률
- 효율적 처리: 일반 태스크에서 대부분 저해상도로 처리
- 태스크 적응성: 문제 복잡도에 따른 자원 할당 최적화
성능 및 효율성 비교
기존 Efficient VLM 대비
| Method | ChartQA | OCRBench | Average Performance | Token 사용량 |
|---|---|---|---|---|
| FastV | 72.6% | 75.8% | 95.8% | 50% |
| SparseVLM | 73.2% | 75.6% | 92.2% | 50% |
| VisionThink | 79.8% | 80.8% | 102% | 51.3% |
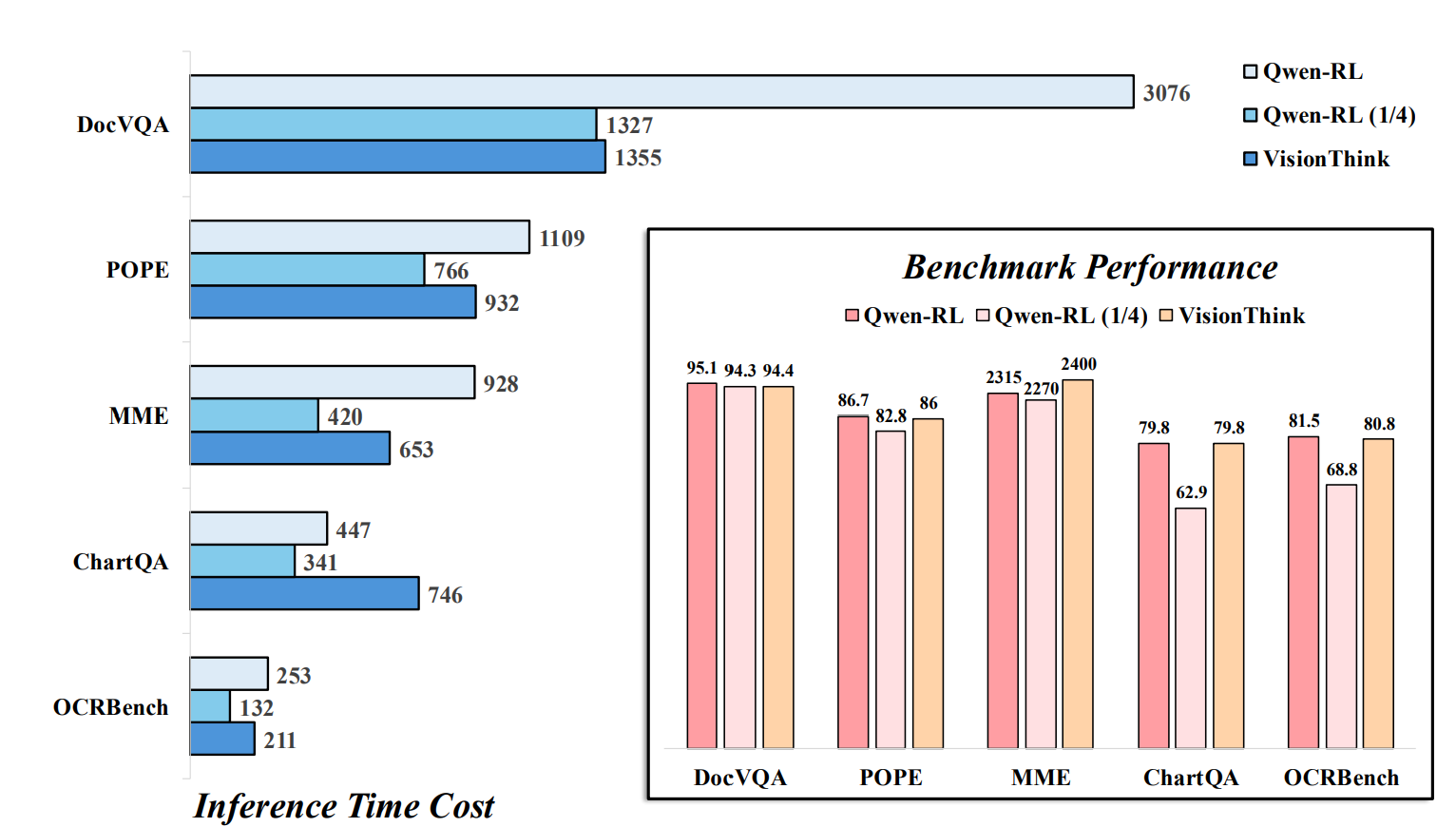
추론 속도 비교
| 벤치마크 | 속도 변화 |
|---|---|
| DocVQA | 기존 대비 2배 이상 빠름 |
| MME / POPE | 약 1/3 시간 단축 |
| ChartQA | 고해상도 요청 증가 → 시간 증가 |
LLM-as-Judge 확장 실험
130K 데이터셋 결과
| Metric | Baseline | VisionThink | Improvement |
|---|---|---|---|
| MathVista | 68.2 | 71.2 | +4.4% |
| MMVet | 61.6 | 69.5 | +12.8% |
4. 한계점
Architecture에서의 한계
해상도 제약
- 고정된 2배 업스케일링(1/4 → full)에 제한
- 다양한 해상도 단계의 유연한 조절 불가
- 이진적 의사결정(요청/미요청)의 단순함
도구 한계
- 이미지 크롭핑, 줌인 등 다양한 시각 도구 미지원
- 2턴 이상의 복잡한 Multi-turn 상호작용 탐색x
실험 설계의 제약
데이터 편향
- 기반 모델 성능을 기준으로 한 데이터 분류의 순환적 편향
- 20K 훈련 데이터의 상대적 소규모
평가 한계
- 단일 모델(Qwen2.5-VL) 기반 검증
- 다른 VLM 아키텍처에서의 일반화 성능 미검증
Cold-Start 부재의 한계
- 기존 RL 방식과 달리 cold-start 없이 바로 RL 적용
- 초기 프롬프트 설계에 과도하게 의존
실제 배포 관점
지연 시간 이슈
- 고해상도 요청 시 2단계 처리로 인한 지연 시간 증가
- 실시간 응용에서의 사용자 경험 저하 가능성
훈련 복잡성
- 강화학습 파이프라인의 높은 구현 복잡도
- 보상 함수 튜닝의 민감성과 불안정성
5. 개선 방향 및 Future Work
유연한 해상도 시스템
Multi-Scale Resolution
`# 다단계 해상도 요청 시스템
resolution_levels = [0.25, 0.5, 0.75, 1.0]
action_space = ["direct_answer", "request_higher", "request_crop", "request_zoom"]`Dynamic Cropping Integration
- 전체 고해상도 대신 관심 영역만 크롭핑
- 더욱 효율적인 세부 정보 접근
강화학습 고도화
Multi-Objective Optimization
*# 다목적 최적화 보상 함수*
R_total = α*R_accuracy + β*R_efficiency + γ*R_user_satisfaction - δ*P_latencyHierarchical Decision Making
- 거친 단계: 고해상도 필요 여부
- 세밀한 단계: 어떤 시각 도구 사용할지
Cross-Modal Reasoning 강화
Tool-Augmented VLM
- 이미지 편집, 객체 감지, 텍스트 추출 등 다양한 시각 도구 통합
- 각 도구의 비용-효과 분석을 통한 최적 선택
Multi-Turn Complex Reasoning
- 5턴 이상의 복잡한 시각적 추론 지원
- 중간 결과를 활용한 점진적 문제 해결
6. 가능한 질문들
"정말 모든 VLM에 적용 가능한가?"
현재는 Qwen2.5-VL에서만 검증됨. 다른 VLM 아키텍처에서의 일반화는 추가 연구 필요하며, 각 모델의 토큰 처리 방식에 따라 효과가 달라질 수 있음.
"2단계 처리의 지연 시간이 실용적인가?"
OCR 태스크에서는 정확도 향상이 지연 시간을 상쇄하지만, 실시간 응용에서는 한계. 병렬 처리나 캐싱 전략으로 개선 가능.
"강화학습 없이는 불가능한가?"
SFT 비교 실험에서 RL이 더 스마트한 의사결정을 보임. SFT는 과도한 고해상도 요청 경향을 보여 효율성 저하.
"실제 사용자 만족도는 어떤가?"
논문에서는 자동 평가에 집중. 실제 사용자 연구를 통한 UX 평가가 필요하며, 지연 시간과 정확도 간 트레이드오프에 대한 사용자 선호도 조사 필요.
"다른 효율적 VLM 기법과 결합 가능한가?"
VisionThink는 샘플 레벨 압축 결정 프레임워크로, 기존 토큰 레벨 압축 기법(FastV, SparseVLM)과 호환 가능. 상호 보완적 효과 기대.
VisionThink와 기존 Efficient VLM의 차이점
1. 압축 결정 방식의 차이
기존 방법들
→ 모든 샘플에 고정된 압축 비율을 적용한다. FastV와 SparseVLM은 어텐션 스코어를 기반으로 사전 정의된 임계값에 따라 토큰을 제거한다.
VisionThink
→ 각 샘플의 복잡도와 요구사항에 따라 동적으로 압축 여부를 결정한다. 모델이 스스로 판단하여 필요시에만 고해상도를 요청하는 적응적 접근법을 취한다.
2. 처리 시점의 차이
기존 방법들
→ 입력 후 압축 방식으로, 먼저 전체 이미지를 처리한 후 중복 토큰을 제거한다. 이미 계산된 정보를 버리는 방식이다.
VisionThink
→ 입력 전 압축 방식으로, 처음부터 압축된 저해상도 이미지를 입력하고, 필요시에만 원본을 요청한다. 불필요한 계산을 원천적으로 방지한다.
3. OCR 태스크에서의 성능 차이
기존 방법들
→ 고정된 압축으로 인해 OCR 관련 벤치마크에서 상당한 성능 저하를 겪는다. ChartQA에서 FastV는 91.0%, SparseVLM은 91.7%의 성능만 달성한다.
VisionThink
→ OCR이 필요한 경우 고해상도를 요청하여 성능 손실을 최소화한다. ChartQA에서 100% 성능을 유지하며, 전체적으로 102%의 평균 성능을 달성한다.
결론
VisionThink는 "적응적 해상도 선택"이라는 혁신적 아이디어를 강화학습으로 구현하여 VLM의 효율성과 성능 사이의 딜레마를 해결했다. 특히 LLM-as-Judge 전략을 통해 일반 VQA 태스크에 강화학습을 성공적으로 적용한 점이 주목할 만하다.
하지만 2단계 처리의 지연 시간, 해상도 선택의 단순함, 훈련 복잡성 등의 한계는 여전히 해결해야 할 과제다. 이러한 한계점들은 오히려 향후 연구의 명확한 개선 방향을 제시한다는 점에서 의미가 있다.
→ VLM이 인간처럼 상황에 맞게 필요한 정보의 해상도를 동적으로 조절할 수 있는 지능적 시스템의 가능성을 보여주었다.
