핵심 Method 요약
Input/Output
- Input: Text query + Audio passages (speech)
- Output: Retrieved relevant audio passages + Generated answers
- Transformation: Speech → Text embedding space → Retrieval → Audio-conditioned generation
알고리즘 구조
- Speech Adapter: HuBERT + Average pooling + Projection layer
- Cross-modal Retriever: Frozen E5-Mistral-7B + Speech branch
- Audio-conditioned Generator: Speech Language Model (Qwen-Audio)
핵심 수식
- Main Loss:
L(es, et) = 1 - cos(es, et)(Cosine embedding loss) - Key Point: Knowledge distillation from text embedding to speech embedding
1. 연구 배경 및 동기
기존 Spoken QA의 한계
기존 음성 기반 질의응답 시스템은 cascaded pipeline을 따른다.
Audio → ASR → Text Retrieval → Text Generation
이 접근법의 근본적 문제점들이 존재한다.
- ASR 오류 전파 (Error Propagation)
ASR 단계에서 발생한 오류가 검색과 생성 단계로 누적되어 최종 성능을 크게 저하시킨다. 논문에서 제시한 실제 사례를 보면..?
- 원본 음성 내용: "Armenian classical music composer Aram Khatchaturian"
- ASR 전사 결과: "armenian classical music composer aram cocheterien"
- 최종 생성 답변: "Aram Cocheterien composed the Sabre Dance" (오답)
- Paralinguistic 정보 손실
ASR 과정에서 음성만이 가지는 여러 정보들이 완전히 소실된다
- 운율적 특징(Prosodic features): 억양, 강세, 리듬
- 화자 특성: 감정 상태, 개인적 특징
- 맥락적 단서: 말의 속도, 멈춤, 웃음 등
- Named Entity Recognition의 취약성
특히 고유명사 인식에서 ASR 성능이 급격히 떨어지는데, 이는 검색 정확도에 치명적이다. 고유명사는 종종 검색 쿼리의 핵심 키워드이기 때문이다.
연구의 핵심 질문
"ASR 단계를 완전히 우회하고 텍스트 쿼리로 음성 passage를 직접 검색할 수 있다면?"
→ SpeechRAG로 해결하자....!
2. Method
전체 아키텍처 개요
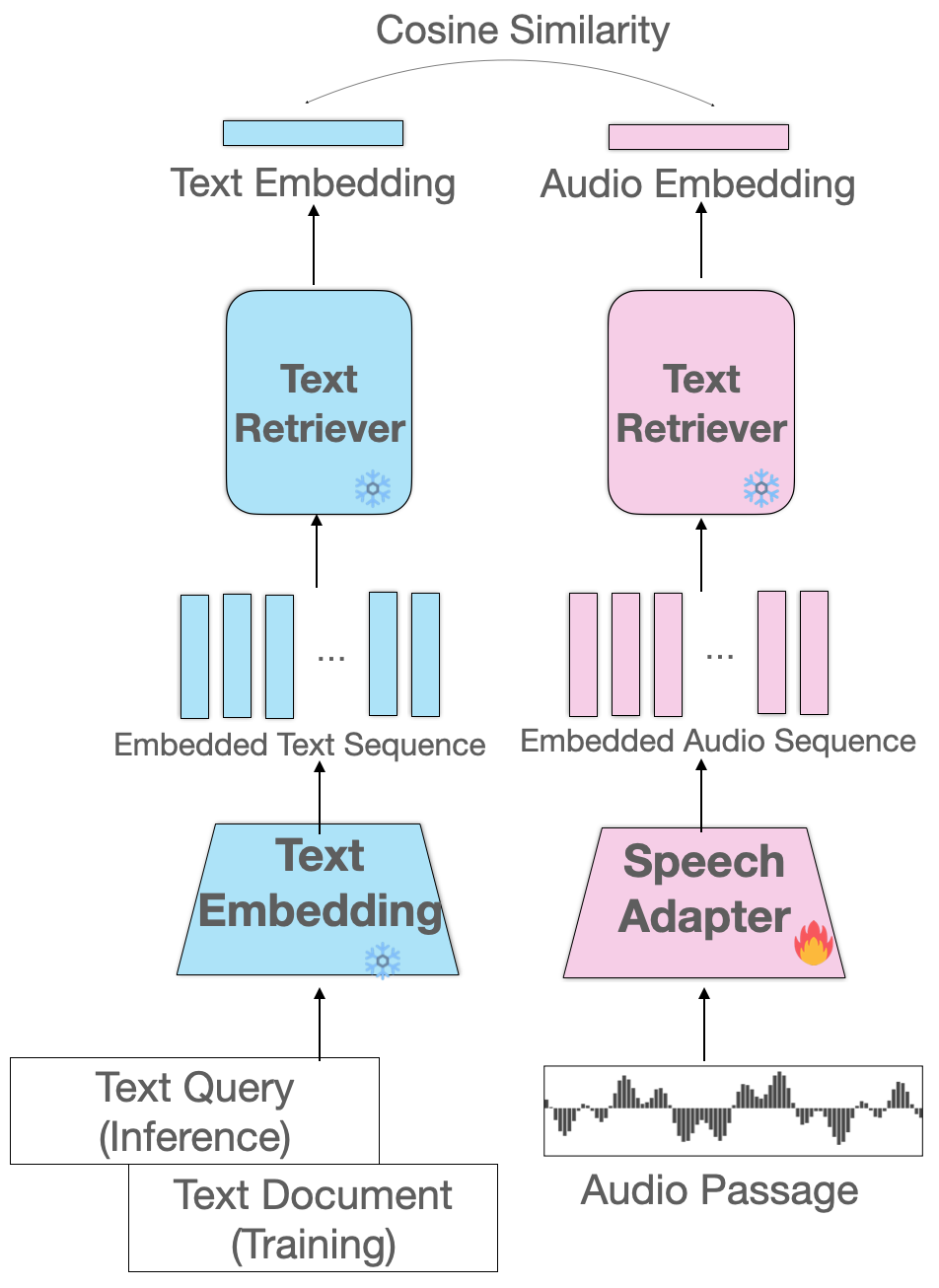
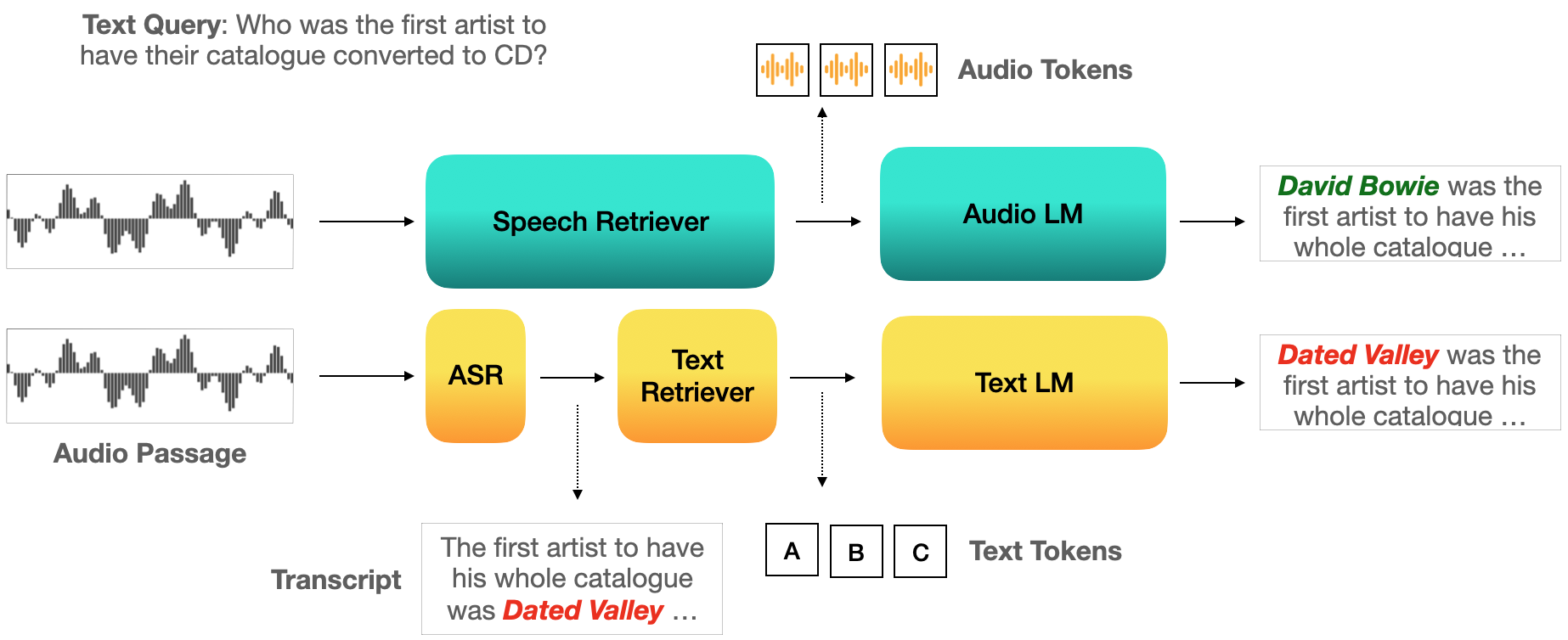
- Stage 1: Speech Retrieval 텍스트 쿼리를 입력받아 관련된 음성 패시지를 직접 검색한다. 핵심은 텍스트와 음성을 동일한 임베딩 공간에 매핑하는 것이다.
- Stage 2: Audio-Conditioned Generation 검색된 음성 패시지를 조건으로 하여 Speech Language Model(SLM)이 최종 답변을 생성한다.
Speech Adapter 설계
- Knowledge Distillation 접근법
- Teacher: 텍스트 검색 모델 (E5-Mistral-7B)
- Student: Speech Adapter (HuBERT + Projection layers)
- 목표: 음성을 텍스트와 동일한 의미 공간으로 매핑
- 구조적 특징
- HuBERT 기반 음성 인코더: 16kHz로 샘플링된 음성의 self-supervised 표현을 생성한다.
- 시간축 다운샘플링: HuBERT 출력을 4배 다운샘플링하여 최종 프레임 길이를 80ms로 설정한다.
- Average Pooling: 시간 차원에 대해 평균 풀링을 적용하여 고정 크기 임베딩을 생성한다.
- Projection Layer: 음성 표현을 LLM 임베딩 차원(768차원)으로 변환한다.
Cross-Modal Retrieval 메커니즘
-
임베딩 공간 정렬 전략
논문의 핵심은 frozen text retriever의 능력을 그대로 활용하면서 음성을 같은 공간으로 매핑하는 것이다. 이를 위해 텍스트 branch는 완전히 고정하고, 음성 branch만 학습한다. -
Training Loss: Cosine Embedding Distillation
: 음성 임베딩
: ground truth 전사의 텍스트 임베딩
- 왜 코사인 유사도..?
- 방향성 중심: 벡터의 크기보다 방향이 의미적 유사성을 더 잘 나타낸다.
- 정규화 효과: 임베딩 크기에 무관하게 순수 의미만 비교한다.
- 검색 일치성: 실제 검색에서도 코사인 유사도를 사용하므로 학습-추론 간 일관성을 보장한다.
Audio-Conditioned Generation
→ Speech Language Model 활용
검색된 음성 패시지들을 직접 조건으로 하여 Qwen-Audio-Chat 모델이 답변을 생성한다. 중요한 점은 추가 파인튜닝 없이 zero-shot으로 적용한다는 것이다.
3. 실험 설계 및 결과 분석
데이터셋
-
SpokenSQuAD
- 기반: SQuAD 데이터셋의 TTS 변환 버전
- 특성: Wikipedia 텍스트를 TTS로 변환, 평균 패시지 길이 약 60초
- 한계: 합성 음성으로 자연 발화의 다양성 부족
-
VoxPopuli
- 기반: 유럽 의회 연설 음성 코퍼스
- 특성: 자연 발화, 평균 발화 길이 약 10초
- QA 생성: Claude 3.5 Sonnet을 사용한 answer-aware 질문 생성
평가 Metric 및 Baseline
-
Retrieval 평가
Recall@K (K=5,10,100): Top-K에서 관련 패시지 발견 비율 -
Generation 평가
Exact Match: 생성 답변에 정답 포함 여부
LLM Correctness: 기계 기반 의미적 정확성 평가 -
Baseline
Fully-cascaded: ASR + 텍스트 검색 + 텍스트 LLM
Semi-cascaded: 음성 검색 + ASR 전사 + 텍스트 LLM
Ground Truth: WER 0% 가정한 이론적 상한
실험 결과
Retrieval 성능
| 데이터셋 | Passage WER | Recall@5 | Recall@10 | Recall@100 |
|---|---|---|---|---|
| SpokenSQuAD | GT Text Baseline 0% | 0.9707 | 0.9871 | 0.9985 |
| Low WER cascaded ∼20% | 0.9525 | 0.9745 | 0.9974 | |
| High WER cascaded ∼35% | 0.8768 | 0.9271 | 0.9926 | |
| Speech Retriever N/A | 0.9702 | 0.9869 | 0.9986 | |
| VoxPopuli | GT Text Baseline 0% | 0.9942 | 0.9971 | 1.0 |
| Low WER cascaded ∼17% | 0.9826 | 0.9855 | 0.9961 | |
| High WER cascaded ∼45% | 0.7106 | 0.7493 | 0.8858 | |
| Speech Retriever N/A | 0.9952 | 0.9981 | 0.9990 |
KEY POINT
- SpeechRAG가 GT 텍스트 수준의 성능을 달성한다.
- High WER 환경에서 cascaded 방식은 급격한 성능 저하를 보인다.
- VoxPopuli에서 SpeechRAG가 GT를 약간 상회하는 성능을 보인다.
노이즈 강건성
가우시안 노이즈를 다양한 SNR 수준에서 추가한 실험에서, SpeechRAG가 cascaded baseline보다 일관되게 더 강건한 성능을 보였다.
Generation 성능
- Exact Match (EM): 정답이 답변에 포함되면 1, 아니면 0
- LLM Correctness: 사소한 철자 오류 등도 포괄하여 기계 기반으로 정답 평가
SpokenSQuAD 예시
| Passage WER | Exact Match | LLM Correctness |
|---|---|---|
| GT Text Baseline 0% | 0.7514 | 0.8352 |
| Fully-cascaded Low WER ~20% | 0.5019 | 0.6987 |
| Fully-cascaded High WER ~35% | 0.2684 | 0.3701 |
| Semi-cascaded GT Text 0% | 0.7364 | 0.8013 |
| Semi-cascaded Low WER ~20% | 0.5057 | 0.7072 |
| Semi-cascaded High WER ~35% | 0.2787 | 0.3842 |
| SpeechRAG | 0.3522 | 0.4811 |
VoxPopuli 예시
| Passage WER | Exact Match | LLM Correctness |
|---|---|---|
| GT Text Baseline 0% | 0.9080 | 0.9003 |
| Fully-cascaded Low WER ~17% | 0.7473 | 0.7561 |
| Fully-cascaded High WER ~45% | 0.4511 | 0.3950 |
| Semi-cascaded GT Text 0% | 0.9158 | 0.9071 |
| Semi-cascaded Low WER ~17% | 0.7301 | 0.7561 |
| Semi-cascaded High WER ~45% | 0.4327 | 0.3766 |
| SpeechRAG | 0.8045 | 0.7173 |
KEY POINT
- High WER 환경에서 SpeechRAG가 크게 우수하다.
- Low WER 환경에서 아직까지는 전통적인 텍스트 기반 RAG 방식이 좋다.
- VoxPopuli에서 상대적으로 더 좋은 성능을 보인다.
4. 한계점
Architecture에서의 한계
-
Average Pooling의 정보 손실
시간 차원에 대한 단순 평균은 다음과 같은 치명적 정보 손실을 야기한다.
- 순서 정보 완전 손실: "rise then fall"과 "fall then rise"가 구분되지 않는다.
- 강조점 무시: 특정 단어의 강세나 억양 변화가 사라진다.
- Local Pattern 소실: 음성의 지역적 패턴들이 평균화되어 버린다. -
Cross-Modal Alignment의 단순함
코사인 유사도만으로는 복잡한 음성-텍스트 관계를 충분히 모델링하지 못한다.
- Magnitude 정보 손실: "slightly"와 "dramatically"의 차이를 구분하기 어렵다.
- 복잡한 관계 한계: 음성의 계층적 구조(음소→단어→문장→의미)를 포착하지 못한다.
실험 설계의 제약
- 데이터셋 한계
SpokenSQuAD: TTS 합성으로 자연 발화와 prosodic 특성이 다르다.
언어 제한: 영어 데이터셋만으로 다언어 일반화 능력이 미검증되었다.
- 평가의 한계
긴 오디오 처리: 논문에서 직접 언급한 대로, 평균 60초인 SpokenSQuAD에서 평균 10초인 VoxPopuli보다 성능이 떨어진다.
이외에도 계산 효율성이나 메모리 관리 측면에서 개선해야 될 부분이 있을 것으로 보인다.
5. 개선 방향 및 Future Work
Temporal Modeling 강화
- Attention-based Aggregation
Average pooling 대신 multi-head attention을 사용하여 중요한 시간 구간에 집중해보기 - Hierarchical Temporal Representation
다양한 시간 스케일에서의 패턴을 동시에 고려하는 계층적 구조
Cross-Modal Alignment 개선
- Multi-Objective Loss
코사인 유사도와 함께 유클리드 거리, contrastive loss 등을 결합해 관계 모델링 - Cross-Attention Mechanism
텍스트와 음성 간의 양방향 attention을 통한 정렬
도메인 및 언어 확장
- 한국어 특화 개선
한글 자소 단위 매칭, 한국어 발음/억양 특성 반영 등 - Multi-Domain Adaptation
전문 도메인별 특화된 어댑터 설계
신뢰성 및 해석가능성 강화
- Uncertainty Quantification
검색 결과의 신뢰도를 정량화 - Attention Visualization
어떤 음성 구간이 검색에 중요했는지 시각화하여 설명 가능성 높이기
6. 가능한 질문들
-
"정말 ASR을 완전히 대체할 수 있는가?"
ASR 기술도 지속적으로 발전하고 있으며(Whisper 등), 텍스트 형태의 중간 결과물이 디버깅과 해석에 더 유리할 수 있다. -
"Average Pooling이 정말 최선인가?"
시간 정보의 불필요한 손실로 이어질 수 있다.... -
"실제 산업 환경에서 적용 가능한가?"
실시간 처리, 대용량 DB 검색, 기존 시스템과의 통합 등 현실적 제약들이 많다. -
“모델의 출력에 편향성이 없는가?”
특정 화자군, 액센트, 도메인에 대한 편향이 발생할 수 있으며, 이에 대한 공정성 고려가 필요하다.
SpeechRAG는 "ASR 없는 직접 음성 검색"이라는 아이디어를 구현하여 연구 방향을 제시했다. 특히 ASR 오류가 빈번한 환경에서의 좋은 성능을 보였다.
그러나 과도한 아키텍처 단순화와 시간 정보 손실 등의 한계는 여전히 해결해야 할 부분이다. 이러한 한계점들은 오히려 향후 연구의 명확한 개선 방향을 제시한다는 점에서 의미가 있다.
