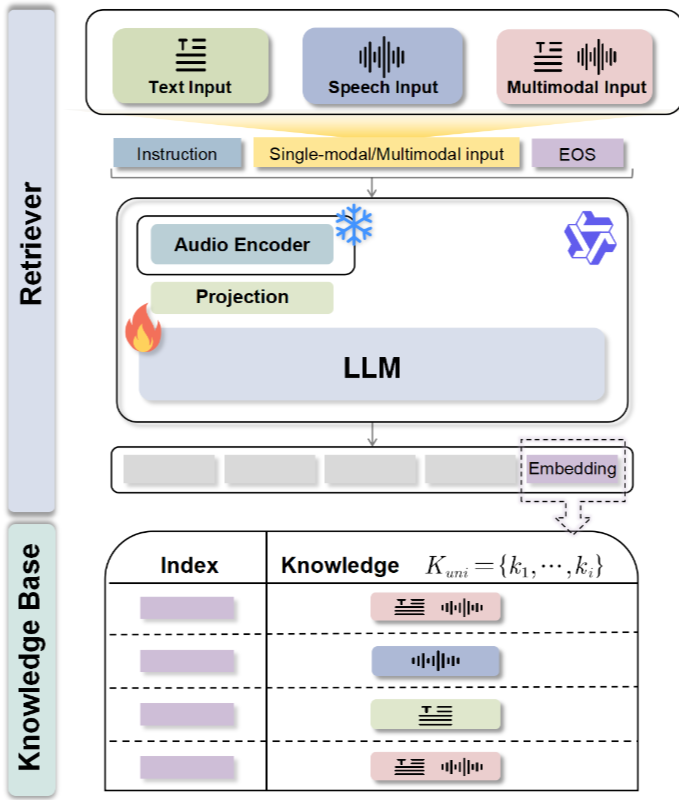
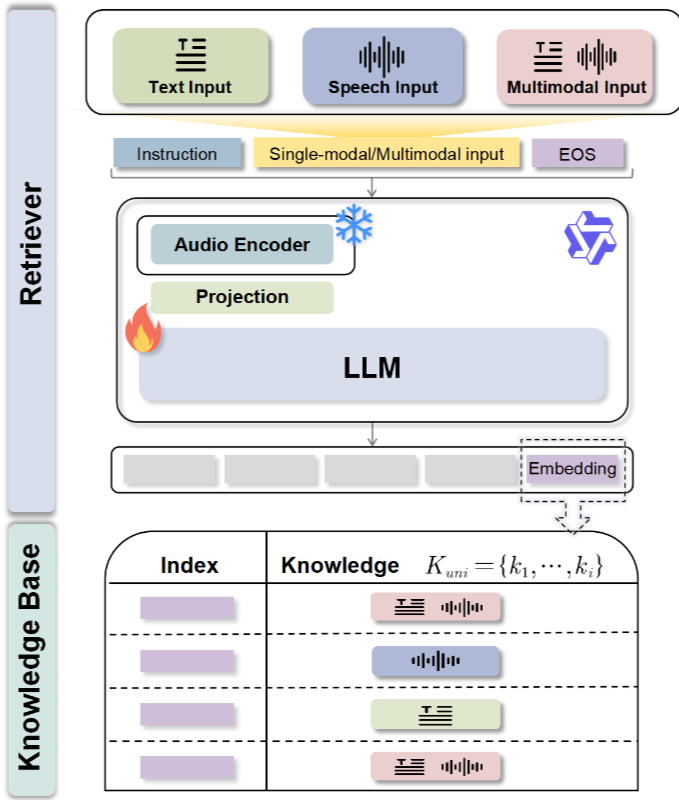
1. WavRAG란?
→ 음성을 직접 처리할 수 있는 새로운 RAG(Retrieval-Augmented Generation) 프레임워크.
기존 RAG 시스템이 텍스트만 처리했다면, WavRAG는 음성과 텍스트를 모두 처리할 수 있는 최초의 end-to-end 시스템이다.
핵심 기술적 특징
- WavRetriever (음성 검색기)
- Qwen2-Audio 모델을 기반으로 구축
- 음성(speech)과 비음성(non-speech) 오디오, 그리고 텍스트를 하나의 통합된 임베딩 공간에서 처리
- 대조 학습(Contrastive Learning) 기법으로 검색 성능 향상
- End-to-End 처리
- 기존: 음성 → ASR(음성인식) → 텍스트 → 처리 (단계별 오류 누적)
- WavRAG: 음성을 직접 처리 (오류 전파 방지, 연산 효율성 향상)
- Chain-of-Thought (CoT) 추론
- 단계적이고 해석 가능한 추론 과정
- 검색된 다중모달 지식 활용의 신뢰성과 제어성 향상
주요 기여사항
- 최초의 음성 대화용 RAG: 음성 대화 영역에 RAG를 end-to-end 방식으로 확장한 첫 번째 시스템
- 하이브리드 검색: 텍스트와 오디오를 동시에 검색할 수 있는 새로운 능력
- 뛰어난 성능
- 기존 텍스트 기반 RAG 모델과 비슷한 성능
- 10배 빠른 처리 속도
- 하이브리드 검색을 통한 새로운 기능 제공
2. 기존 텍스트 기반 RAG 프레임워크
- Retriever: 텍스트 임베딩 모델
- Generator: 텍스트 기반 대화 모델
- Knowledge Corpus: 텍스트 조각들만 포함된 외부 지식 저장소
이 프레임워크의 작동 과정은 검색과 생성의 두 단계로 나뉜다.
검색 (Retrieval)
텍스트 쿼리 가 주어지면, 리트리버는 다음 수식을 통해 검색 확률 분포 를 계산한다.
여기서 는 리트리버의 인코딩 함수, 은 유사도 측정 함수.
이 분포를 기반으로 가장 관련성 높은 상위 개의 텍스트 조각 집합 를 선택한다.
생성 (Generation)
생성기는 원본 쿼리 와 검색된 텍스트 조각 를 바탕으로 최종 답변 를 생성할 확률을 다음과 같이 계산한다.
여기서 는 생성기 가 주는 확률이며, 은 답변 의 토큰 수
# 지식 코퍼스 와 상호작용한다.
-
통합된 입출력: 기존의 텍스트 쿼리 와 코퍼스 를 확장하여, 오디오/텍스트/멀티모달로 구성 가능한 통합 쿼리
와 지식 코퍼스 를 사용한다.
-
향상된 생성: 생성 단계에서는 Chain-of-Thought (CoT) 추론을 도입하여, 검색된 외부 지식을 원본 입력과 체계적으로 통합해 최종 답변을 생성한다.
WavRetriever의 목표와 구조
목표
WavRetriever ( )의 핵심 목표는 쿼리(질문)와 지식 모두에 대해 효율적인 유사도 기반 검색을 가능하게 하는 임베딩 벡터를 생성하는 것이다.
- 기반 모델: WavRetriever는 강력한 범용 오디오 이해 능력을 가진 멀티모달 언어 모델(MLLM) Qwen2-Audio를 기반으로 만들어졌습니다.
- 학습 전략: Qwen2-Audio의 기존 오디오 처리 능력을 최대한 활용하기 위해, 사전 학습된 오디오 인코더는 동결(freeze)하고 프로젝션 레이어와 LLM 백본만 학습에 집중합니다.
대조 학습 (Contrastive Learning) 의 사용
단순히 MLLM을 특정 작업에 맞게 미세조정(fine-tuning)하는 것만으로는 최적의 검색 성능을 얻기 어렵다.
그 이유는, 기존 MLLM은 다중 모드 입력을 이해하도록 사전 학습되었지만, 유사도 검색에 최적화된 임베딩을 만들도록 설계되지 않았기 때문이다.
이를 해결하기 위해 연구팀은 contrastive learning전략을 사용한다.
- Positive 쌍 (query ↔ 관련 지식): 유사도 최대화
- Negative 쌍 (query ↔ 관련 없는 지식): 유사도 최소화
학습 방식 및 손실 함수
- 쿼리:
- 긍정적 지식 샘플:
- 부정적 지식 샘플들:
쿼리와 지식 샘플은 오디오, 텍스트, 또는 이 둘의 조합일 수 있다.
최종 임베딩 표현은 마지막 토큰의 최종 은닉 상태 (final hidden state) 에서 추출된다.
- InfoNCE 손실 함수
손실 함수는 InfoNCE 기반으로 정의된다.
- : 코사인 유사도
- : 온도(temperature) 파라미터
- : 리트리버 가 생성한 쿼리 임베딩
- : 긍정적 지식 샘플의 임베딩
- : 부정적 지식 샘플의 임베딩
인덱스 은 (positive sample)을 의미하며, 나머지 는 negative sample에 해당한다.
생성 단계의 문제점과 해결책
WavRAG의 생성기는 리트리버가 찾아낸 상위 개의 지식(오디오, 텍스트, 또는 멀티모달)과 원본 쿼리 를 입력으로 받는다.
하지만 이렇게 길고 복잡한 멀티모달 정보를 단순히 합쳐서 기존의 음성 대화 시스템에 제공하면, 성능 저하가 발생할 수 있다.
이를 해결하기 위해, WavRAG는 두 가지 핵심적인 기법을 도입한다.
-
사고의 연쇄 (Chain-of-Thought, CoT) 추론
-
자기 일관성 (Self-Consistency) 메커니즘
-
Chain-of-Thought(CoT) 추론
Zero-Shot-CoT는 특별한 학습 예제 없이도 LLM이 스스로 중간 추론 과정을 생성하도록 유도하는 프롬프팅 기법이다.
생성기 는 다음을 입력받는다.
- 멀티모달 쿼리
- 안내 프롬프트
- "한 단계씩 생각해 보자"와 같은 '프롬프트'
- 검색된 지식
이를 바탕으로 추론의 연쇄 를 생성한다.
검색된 지식 는 논리적이고 단계적인 추론 과정의 근거가 되어, 모델이 최종 답변에 도달하도록 돕는다.
- Self-Consistency 메커니즘 → 추론 과정의 신뢰도를 높이기 위해
-
여러 개의 다른 추론 경로를 LLM으로부터 샘플링
-
그중 가장 일관된 답변을 선택
이 방법은 단 하나의 추론 경로(어쩌면 최적이 아닐 수 있음)에 의존하는 위험을 줄여준다.
특히 본 연구에서는 Universal Self-Consistency (USC) 방법을 적용한다.
-
단순히 다수결로 답변을 정하지 않고,
-
샘플링된 모든 추론 경로와 그 결과를 하나로 통합
-
다시 LLM에게 가장 일관성 있는 응답을 선택하도록 요청
즉, LLM 자체의 이해 능력을 활용하여 최적의 답변을 결정하게 하는 효과적인 방법.
-
Training Datasets
모델 학습을 위해 총 150만 개의 샘플로 구성된 대규모 데이터셋을 구축했습니다. 이 데이터셋은 5가지의 다양한 검색 시나리오를 포함한다.
- Speech-to-Text (음성 → 텍스트)
존의 텍스트 검색 데이터셋(예: HotpotQA, Quora)을 기반으로, CosyVoice2라는 TTS(Text-to-Speech) 모델을 사용해 텍스트 질문을 음성 질문으로 합성하여 만들었다. 이때 다양한 목소리 톤과 잡음을 추가하여 데이터의 현실성을 높였다. - Speech-to-Speech (음성 → 음성) 및 Text-to-Speech (텍스트 → 음성)
이 시나리오들을 위해서는 기존에 공개된 데이터셋인 SLUE-SQA-5와 Spoken-SQuAD를 사용했다. - Text-to-Text (텍스트 → 텍스트)
ELI5, NQ, HotpotQA 등 기존의 다양한 텍스트 검색 데이터셋을 활용했다. - Audio+Text-to-Audio+Text (멀티모달)
이 복합적인 시나리오를 위해 AudioCaps, MusicCaps, VoxCeleb 등 여러 소스에서 새로운 데이터를 처리하여 구축했다. 여기서는 질문(queries)과 문서(documents)가 모두 일반 오디오와 텍스트의 쌍으로 이루어져 있다.
Evaluation Datasets
- HotpotQA
- Spoken-SQuAD
- SLUE-SQA-5
- 자체 제작한 혼합 모달리티 데이터셋
Baselines
Retrieval 베이스라인
- BGE
→ 텍스트 임베딩 모델.
음성 관련 작업에서는 음성을 텍스트로 변환하는 ASR 기반 파이프라인 내에서 사용되었다. - CLSR
음성-텍스트 검색 프레임워크.
음성-텍스트 및 텍스트-음성 검색 작업의 비교를 위해 사용되었다. - CLAP
자체 제작한 멀티모달 데이터셋의 성능 비교를 위해 사용되었다. - Qwen2Audio-enhanced Text Retrieval:
→ 자체 제작 데이터셋에 사용된 또 다른 비교 모델.
Qwen2Audio 모델을 사용해 오디오 클립에 대한 설명 텍스트를 생성한 뒤, 이를 원본 텍스트와 합쳐 BGE 모델로 처리하는 방식이다.
Generation베이스라인
- TextRAG
→ 표준적인 텍스트 기반 RAG 파이프라인.
검색에는 BGE 임베딩을, 음성 인식(ASR)에는 Whisper (medium) 모델을 사용한다.
4. 평가 지표 및 실험 설정
Retrieval 성능 평가
검색 성능은 네 가지 시나리오에서 평가되었다.
→ Speech-to-Text, Speech-to-Speech, Text-to-Speech, 그리고 Audio+Text to Audio+Text.
- Recall@k
검색된 상위 k개 결과 안에 정답이 포함되어 있는 비율입니다. 높을수록 좋다. (k=1, 5, 10에 대해 보고됨). - NDCG@10
검색 결과의 순위 품질을 측정하는 지표로, 정답이 더 높은 순위에 있을수록 점수가 높아진다. 높을수록 좋다. - Average Inference Time
쿼리 하나를 처리하는 데 걸리는 평균 시간. - WER (Word Error Rate)
음성 인식의 정확도를 측정하며, 낮을수록 좋다. (베이스라인 모델에서 사용된 Whisper ASR 모델에 대해 보고됨).
Generation 성능 평가
생성 성능은 세 가지 RAG 프레임워크를 비교하여 평가되었다.
→ TextRAG, WavRAG, 그리고 WavRAG-CoT (사고의 연쇄 적용). 이때 생성 모델로는 GPT-4o와 QwenAudio가 사용되었다.
- EM (Exact Match)
단답형 답변에 사용되며, 생성된 답변이 정답과 정확히 일치하면 1, 아니면 0을 주는 이진(binary) 지표이다. 높을수록 좋다. - FactScore
장문형 답변에 사용되며, 생성된 답변의 내용 중 검색된 근거에 의해 뒷받침되는 사실의 비율을 평가하여 사실적 정확도를 측정한다. 높을수록 좋다.
실험은 검색된 문서를 1개(top-1), 2개(top-2), 3개(top-3) 제공했을 때의 결과를 각각 보여준다. 또한, 이상적인 상황을 가정하여 정답 문서만 제공했을 때의 성능을 측정하는 "Oracle" 조건도 함께 평가되었다.
5. 주요 결과
Retrieval 성능
→ WavRAG의 가장 큰 장점은 ASR 없이 오디오 입력을 직접 처리한다는 점이다. 이를 통해 ASR의 계산 오버헤드와 잠재적인 변환 오류를 원천적으로 제거한다.
- 속도 향상: 그 결과, Whisper ASR을 사용하는 BGE 모델에 비해 추론 속도가 약 5배에서 14배 이상 빨라졌다.
- 성능 유지: 이렇게 속도가 빠르면서도, 검색 정확도는 기존 모델들과 비슷하거나 오히려 더 높았다.
- 압도적 성능: 특히 가장 어려운 Audio+Text-to-Audio+Text (멀티모달) 시나리오에서는 WavRAG가 모든 베이스라인 모델을 압도적으로 능가했다. 이는 WavRAG의 통합된 멀티모달 임베딩 공간이 오디오와 텍스트 간의 복잡한 관계를 효과적으로 포착했음을 보여준다.
Generation 성능
- 직접적인 오디오 입력의 효과 (WavRAG vs. TextRAG)
- 모든 데이터셋과 LLM에서, WavRAG는 기존의 TextRAG 방식보다 일관되게 더 좋은 성능을 보였다.
- 이는 정보 손실이 있을 수 있는 ASR 변환 텍스트 대신 원본 오디오를 생성기에 직접 제공하는 것의 이점을 명확히 보여준다.
- 예를 들어, GPT-4o를 사용한 HotpotQA 데이터셋 평가에서 WavRAG의 EM 점수는 0.4019로, TextRAG의 0.3124보다 +0.0895만큼 높았다.
- 사고의 연쇄(CoT)의 효과 (WavRAG-CoT)
- 사고의 연쇄(Chain-of-Thought, CoT) 추론을 추가하자 성능이 더욱 향상되었다. WavRAG-CoT는 기본 WavRAG보다 일관되게 더 높은 성능을 기록했다.
- 예를 들어, GPT-4o를 사용한 SLUE-SQA-5 데이터셋 평가에서 EM 점수가 0.3904에서 0.4520으로 증가했다.
- 흥미로운 점은, 검색된 문서의 수를 2개(Top-2)에서 3개(Top-3)로 늘렸을 때 오히려 성능이 감소하는 경향이 관찰되었다는 것이다. 이는 모델이 더 많고 다양한 정보를 종합하는 데 어려움을 겪는다는 것을 시사한다.
CoT를 적용한 WavRAG-CoT는 이 문제를 완화했는데, 이는 CoT의 구조화된 추론 방식이 복잡한 멀티모달 지식을 더 잘 관리하게 해주기 때문이다.
Analysis
- 대조 학습 프레임워크에 대한 Ablation Study
-
비교 대상: 대조 학습으로 미세조정된 WavRAG 리트리버와, 미세조정하기 전의 원본 Qwen2-Audio 모델을 비교했다. 원본 모델은 멀티모달 이해 능력은 뛰어나지만 검색에 특화된 최적화는 되어있지 않다.
-
결과: WavRAG는 모든 데이터셋과 평가지표에서 원본 모델을 압도적으로 능가했다. Recall@1 성능은 최대 +0.3437, nDCG@10 성능은 최대 +0.4169까지 향상되었다.
→ 이러한 성능 향상은 대조 학습 프레임워크가 MLLM을 멀티모달 검색 작업에 맞게 성공적으로 조정했음을 입증한다.
-
- 지식 확장 품질 평가
→ 자체 제작한 멀티모달 데이터셋에서 무작위로 추출한 700개의 샘플을 평가했다.
- 평가 기준
평가자들은 5점 척도를 사용하여 네 가지 차원을 평가했다: 문법성(Grammaticality), 사실적 정확성(Factual accuracy), 관련성(Relevance), 전반적인 유용성(Helpfulness). - 결과
- 대부분의 샘플이 문법성, 사실적 정확성, 관련성에서 최고점인 5점을 받았습니다. 이는 생성된 지식의 품질이 매우 높다는 것을 의미한다.
- 또한, 대부분의 샘플이 "유용하다(Helpful)"고 평가받았다.
→ 확장된 지식이 오디오를 이해하는 데 긍정적인 영향을 미친다는 것을 보여준다.
6. Conclusions
WavRAG는 기존의 자동 음성 인식(ASR)에 의존하는 방식에서 크게 벗어나, 원시 오디오 입력을 직접 처리하여 임베딩하고 검색하는 방식을 사용한다.
이 접근법은 다음과 같은 몇 가지 주요 이점을 제공한다.
- 계산 오버헤드 감소
- 풍부한 음향 정보의 보존
- 오디오와 텍스트가 통합된 멀티모달 지식 베이스를 활용하는 능력
연구팀은 정량적 평가와 정성적 분석을 포함한 포괄적인 실험을 통해 WavRAG의 효과를 입증했다. 실험 결과, WavRAG는 기존의 방식이나 베이스라인 모델들과 비교했을 때 검색 및 생성 성능 모두에서 상당한 향상을 보였다.
한계점 (Limitations)
WavRAG는 의미 정보와 음향 정보를 모두 활용하여 응답의 의미적 품질을 향상시키는 방법을 탐구했지만, 음성 대화 시스템에서 똑같이 중요한 다른 요소들이 있다. 바로 응답의 음향적 측면이다.
RAG 기술이 다음과 같은 응답의 음향적 측면을 개선하는 데 얼마나 기여할 수 있을지는 아직 해결되지 않은 문제이며, 추가적인 연구가 필요합니다.
- 감정적인 톤(emotional tone)
- 운율(prosody)
- 표현력(expressiveness)
- 화자 스타일(speaker style)
⇒ WavRAG는 성능과 효율성을 크게 향상시킨 성공적인 프레임워크이지만, 생성되는 답변의 내용(의미)뿐만 아니라 목소리의 톤이나 스타일(음향)까지 제어하는 단계까지는 나아가지 못한 점을 한계로 명시하고 있다.
