핵심 Method 요약
Input/Output
- Input: Time series query sequence + Historical time series sequences
- Output: Retrieved similar time series sequences + Enhanced forecasting predictions
- Transformation: Time series → Knowledge Base construction → DTW-based retrieval → LLM forecasting
알고리즘 구조
- Time Series Knowledge Base: Sequential slicing + K-means clustering + Representative sequence selection
- DTW-based Retrieval: Dynamic Time Warping을 이용한 유사 시퀀스 검색
- LLM-based Forecasting: TimeLLM with reprogramming layer (Llama3 기반)
핵심 수식
- Euclidean Distance for Clustering:
- DTW Similarity:
- Key Point: K-means clustering으로 대표 시퀀스 선별, DTW로 temporal distortion에 강건한 검색
1. 연구 배경 및 동기
기존 LLM 기반 시계열 예측의 한계
기존 Large Language Model을 시계열 예측에 적용하는 접근법들은 여러 근본적 문제점들을 가지고 있다.
도메인 적응의 어려움
- LLM 훈련은 계산 비용이 매우 크고 특정 도메인에 최적화된다
- 새로운 도메인의 시계열 데이터에 쉽게 적응하기 어렵다
- 전이 학습(Transfer Learning) 능력의 한계
환각 문제 (Hallucination)
- LLM이 시계열 예측에서 부정확한 예측이나 이상치를 생성할 수 있다
- 데이터와 일치하지 않는 허위 패턴을 만들어낼 수 있다
- 해석 가능성(Interpretability)의 부족
복잡한 패턴 인식의 한계
- 대규모 순차 데이터의 복잡하고 다양한 패턴을 포착하기 어렵다
- Hidden dependencies와 long-term dependencies 모델링의 어려움
- 전통적인 deep learning 방법(LSTM, Transformer 등)도 이러한 한계를 가진다
연구의 핵심 질문
"LLM의 강력한 능력을 활용하면서도 시계열 예측의 정확성과 해석가능성을 높일 수 있는 방법은 무엇인가?"
→ Retrieval-Augmented Generation (RAG)을 시계열 예측에 적용하여 해결하자!
2. Method
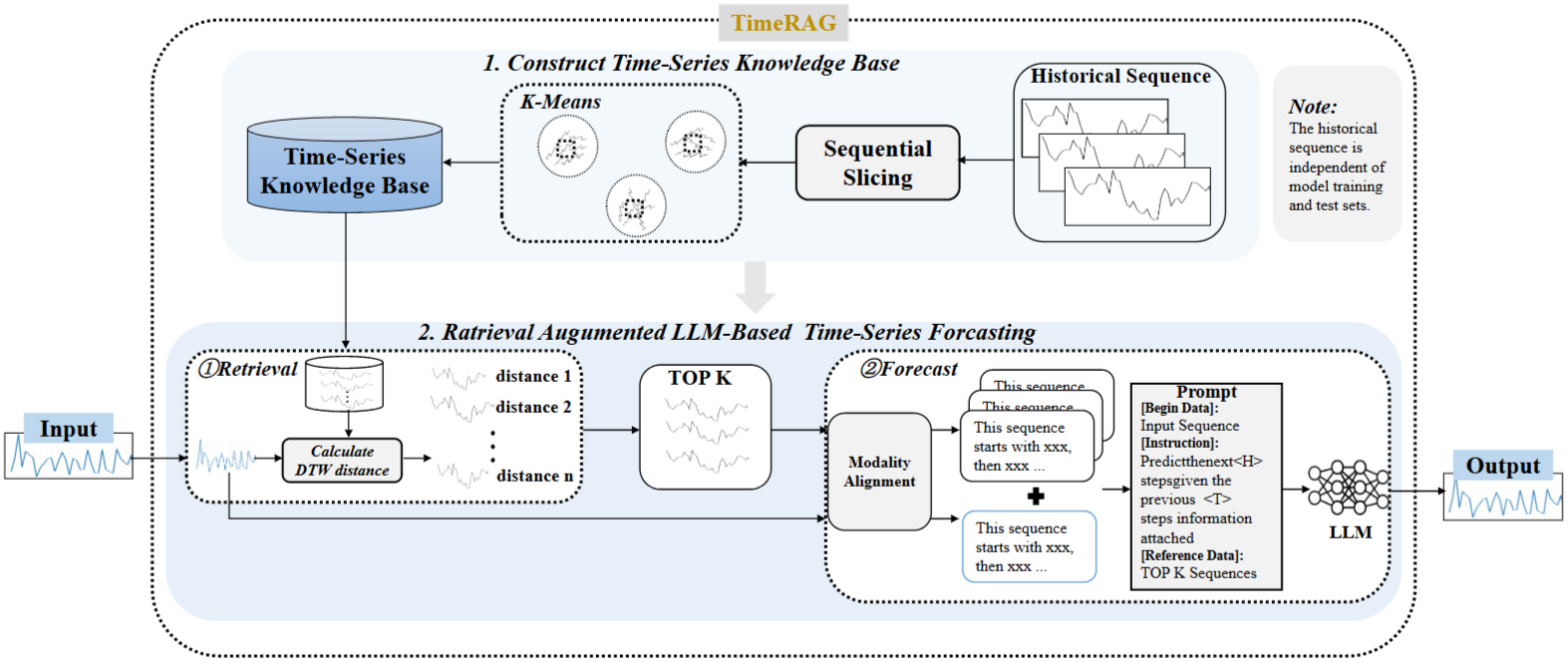
전체 아키텍처 개요
TimeRAG는 두 가지 주요 컴포넌트로 구성된다
Stage 1: Time Series Knowledge Base 구축
- 역사적 시계열 데이터에서 대표적인 패턴들을 추출하여 지식 베이스를 구축한다
- Sequential slicing과 K-means clustering을 통해 효율적인 저장과 검색을 가능하게 한다
Stage 2: RAG 기반 시계열 예측
- DTW를 사용해 쿼리와 유사한 시퀀스들을 검색한다
- 검색된 시퀀스들과 원본 쿼리를 결합하여 자연어 프롬프트로 변환한다
- 사전 훈련된 LLM이 enhanced context를 바탕으로 예측을 수행한다
Time Series Knowledge Base 설계
Sequential Slicing 전략
- 긴 시계열을 처리하기 위해 sliding window 기법을 사용한다
- Window length , Step size 로 원본 시퀀스 을 sub-sequences 로 분할한다
- 이는 LLM이 긴 시퀀스에서 핵심 정보를 놓치는 문제를 해결한다
K-means Clustering 기반 대표 시퀀스 선별
목표: N개의 시퀀스 조각 Q_L = {X_Li}에서 k개의 대표 시퀀스 추출
1. k개의 cluster centroid C = {X_c1, ..., X_ck} 초기화
2. 각 X_Li를 가장 가까운 centroid에 할당 (Euclidean distance 사용)
3. Centroid를 클러스터 내 시퀀스들의 평균으로 업데이트
4. 수렴할 때까지 반복
5. 각 클러스터에서 centroid에 가장 가까운 시퀀스를 지식 베이스에 저장왜 Euclidean Distance를 사용했나?
- 시계열의 magnitude와 shape 정보를 동시에 고려한다
- K-means의 표준 거리 메트릭으로 안정적인 clustering을 보장한다
- 계산 효율성이 높다
DTW 기반 Cross-Modal Retrieval 메커니즘
Dynamic Time Warping의 핵심 아이디어
- 시간축 왜곡(temporal distortion)에 강건한 시퀀스 유사도 측정이다
- 서로 다른 길이의 시퀀스 간에도 유사도를 측정할 수 있다
- 시계열의 shape와 trend를 중요시한다
DTW 알고리즘 구현
입력 쿼리 과 지식 베이스의 시퀀스 에 대해
- Distance Matrix 구성: 크기의 매트릭스 생성
- 각 원소 는
- Warping Path 탐색: 동적 계획법을 사용해 최단 경로 W 찾기
- 경로는 에서 까지 연결된다
- 유사도 계산
DTW 선택의 이유
- Temporal Flexibility: 시간축 변형에 강건하다
- Shape Preservation: 전체적인 패턴 형태를 잘 보존한다
- Domain Agnostic: 다양한 도메인의 시계열에 적용 가능하다
LLM-based Enhanced Forecasting
Reprogramming Layer 활용
- TimeLLM의 접근 방식을 따라 시계열을 자연어 모달리티에 정렬한다
- Frozen LLM (Llama3)의 파라미터는 고정하고 reprogramming layer만 학습한다
프롬프트 구성 전략
[Begin Data]: Input Sequence
[Instruction]: Predict the next <H> steps given the previous <T> steps information attached
[Reference Data]: TOP K Sequences (retrieved via DTW)
Zero-shot Adaptation
- LLM의 기존 파라미터는 변경하지 않는다
- 지식 베이스의 참조 시퀀스들이 context를 풍부하게 만든다
- 이는 computational cost를 크게 줄이면서도 성능을 향상시킨다
3. 실험 설계 및 결과 분석
데이터셋
M4 Competition Dataset
- 가장 널리 사용되는 시계열 예측 벤치마크이다
- 6개의 서로 다른 주기를 가진 100,000개의 시계열이다:
- Yearly (23,000개), Quarterly (24,000개), Monthly (48,000개)
- Weekly (359개), Daily (4,227개), Hourly (414개)
- 금융, 인구통계, 마케팅 등 다양한 도메인을 포괄한다
Knowledge Base 구축 통계
- 총 179,895개의 시퀀스 세그먼트가 지식 베이스에 저장되었다
- 각 주기별로 별도의 지식 베이스를 구축했다
- 원본 샘플보다 더 많은 수의 세그먼트가 생성된 것은 sequential slicing 때문이다
평가 Metric 및 Baseline
평가 지표
- SMAPE (Symmetric Mean Absolute Percentage Error)
- 시계열 예측에서 널리 인정받는 정확도 측정 지표이다
- 실제값에 대한 상대적 퍼센트 오류를 계산한다
- MASE (Mean Absolute Scaled Error)
- naive forecast 전략 대비 모델의 예측 정확도를 평가한다
- 스케일에 무관하고 다양한 크기의 시계열에 대해 강건하다
- OWA (Overall Weighted Average)
- N-BEATS 방법론에서 채택한 종합 평가 지표이다
- SMAPE와 MASE를 통합하여 전체적인 성능을 평가한다
Baseline 모델들
- Transformer 계열: iTransformer, FEDformer, Pyraformer, Autoformer, Informer, Reformer
- 기타 SOTA 모델들: Time-LLM, DLinear, TSMixer, MICN, FiLM, LightTS
- 총 12개의 경쟁 모델과 비교했다
실험 결과
Time-LLM 대비 성능 향상
| 지표 | Time-LLM | TimeRAG | 개선률 |
|---|---|---|---|
| SMAPE | 12.766 | 12.623 | 1.13% ↓ |
| MASE | 2.855 | 2.718 | 4.78% ↓ |
| OWA | 1.056 | 1.025 | 3.00% ↓ |
- 전체 평균 개선률: 2.97%
- 최대 개선: Weekly 주기에서 MASE 13.12% 향상
SOTA 모델들과의 비교
TimeRAG는 다음과 같은 우수한 성과를 보였다:
- MASE에서 전체 1위: 2.718로 모든 모델 중 최고 성능
- OWA에서 전체 1위: 1.025로 종합 평가에서 최우수
- 일관된 Top-3 성능: 18개 비교 항목 중 14개에서 상위 3위 달성
주기별 상세 성능
| 주기 | SMAPE | MASE | OWA | 특이사항 |
|---|---|---|---|---|
| Yearly | 15.317 | 2.678 | 0.825 | Time-LLM과 거의 동등 |
| Quarterly | 10.941 | 1.230 | 0.952 | 안정적 성능 |
| Monthly | 13.529 | 1.141 | 0.940 | 가장 많은 데이터에서 우수 |
| Weekly | 14.227 | 3.762 | 1.279 | MASE에서 큰 개선 |
| Daily | 3.572 | 3.348 | 1.057 | 고빈도 데이터 처리 우수 |
| Hourly | 18.150 | 4.151 | 1.095 | 실시간성 데이터에서 개선 |
핵심 성과 요약
- 도메인 전반에 걸친 일관된 성능: 모든 시간 주기에서 안정적 결과
- RAG의 효과적 활용: 지식 베이스 기반 참조가 실질적 성능 향상 달성
- 계산 효율성: LLM 파라미터 변경 없이도 의미있는 개선
4. 한계점
Architecture에서의 한계
Sequential Slicing의 정보 손실
- Sliding window 접근법이 시계열의 글로벌 의존성을 파괴할 수 있다
- Window 경계에서 중요한 패턴이 분할될 위험이 있다
- Long-term trend가 local segments로 분해되면서 손실될 수 있다
K-means Clustering의 단순함
- Euclidean distance만으로는 시계열의 복잡한 temporal patterns을 충분히 포착하지 못한다
- Seasonal patterns, cyclical behaviors 등의 고차원 특성이 간과될 수 있다
- Cluster 수 k의 설정이 경험적이고 도메인 특화 튜닝이 필요하다
DTW의 계산 복잡성
- DTW는 O(n×m)의 시간 복잡도를 가져 대규모 지식 베이스에서는 비효율적이다
- 실시간 검색이 어려울 수 있다
- Memory 사용량도 상당할 수 있다
실험 설계의 제약
데이터셋의 한계
- M4 데이터셋만으로는 일반화 성능을 완전히 검증하기 어렵다
- 특정 도메인(금융, 에너지, 의료 등)에 특화된 평가가 부족하다
- 실제 산업 환경의 noisy, irregular 시계열에 대한 검증이 필요하다
Baseline 비교의 한계
- 최신 foundation model 기반 시계열 예측 모델들과의 비교가 부족하다
- Computational cost 대비 성능에 대한 정량적 분석이 없다
- RAG component별 ablation study가 부족하다
평가 지표의 제한
- SMAPE, MASE, OWA 외에 probabilistic forecasting 측면의 평가가 없다
- 불확실성 정량화(Uncertainty Quantification) 관련 평가가 부족하다
- Calibration, Sharpness 등의 고급 평가 메트릭이 누락되었다
5. 개선 방향 및 Future Work
Temporal Modeling 강화
Hierarchical Representation Learning
- Multi-scale temporal patterns을 동시에 모델링하는 계층적 구조 도입
- Wavelet transform이나 multi-resolution analysis 기법 활용
- Short-term fluctuations와 long-term trends를 분리하여 처리
Advanced Clustering Techniques
- Time series specific clustering 방법 도입 (e.g., K-shape, TADPole)
- DTW-based clustering을 knowledge base 구축에 직접 활용
- Adaptive cluster 수 선정을 위한 automatic methods 적용
Retrieval 메커니즘 개선
Efficient Similarity Search
- DTW의 계산 복잡성을 해결하기 위한 approximate methods 도입
- LSH (Locality Sensitive Hashing) for time series 활용
- Neural embedding 기반 fast similarity search 구현
Multi-Modal Retrieval
- 시계열 외에 metadata, contextual information도 함께 활용
- Seasonal patterns, domain information을 고려한 hybrid retrieval
- Graph-based knowledge representation으로 관계성 모델링
도메인 및 태스크 확장
Multi-Domain Adaptation
- 금융, 에너지, 의료, IoT 등 다양한 도메인별 특화 버전 개발
- Domain-adaptive knowledge base 구축 방법론 개발
- Transfer learning 기법으로 도메인 간 지식 공유
다양한 예측 태스크 지원
- Point forecasting 외에 probabilistic forecasting 지원
- Anomaly detection, change point detection 등 관련 태스크 확장
- Multi-variate, multi-horizon forecasting 성능 개선
해석가능성 및 신뢰성 강화
Explainable Retrieval
- 왜 특정 시퀀스가 검색되었는지에 대한 설명 가능성 제공
- DTW alignment path visualization으로 유사성 근거 제시
- Attention mechanism으로 중요한 time segments 하이라이트
Uncertainty Quantification
- 예측 결과의 신뢰도를 정량화하는 메커니즘 구축
- Retrieval quality가 예측 품질에 미치는 영향 분석
- Calibrated probability 제공으로 실용성 향상
6. 가능한 질문들
"정말로 RAG가 시계열 예측에 효과적인가?"
- 2.97%의 평균 개선이 통계적으로 유의미한가?
- Computational overhead를 고려했을 때 cost-effective한가?
- 더 간단한 ensemble 방법과 비교했을 때의 장단점은?
"Knowledge Base의 품질이 성능에 미치는 영향은?"
- K-means의 cluster 수 k는 어떻게 결정해야 하는가?
- 지식 베이스의 크기와 다양성이 성능에 어떤 영향을 미치는가?
- Outdated patterns이 포함된 경우 성능 저하는 없는가?
"DTW가 정말 최선의 선택인가?"
- Euclidean distance나 다른 시계열 거리 메트릭과 비교했을 때의 장점은?
- DTW의 계산 복잡성이 실제 응용에서 문제가 되지 않는가?
- Approximate DTW나 다른 fast similarity methods는 고려하지 않았는가?
"실제 산업 환경에 적용 가능한가?"
- Real-time inference에서도 동일한 성능을 보장할 수 있는가?
- Missing values, irregular sampling 등의 실제 데이터 이슈는 어떻게 처리하는가?
- 데이터 프라이버시와 보안 측면에서의 고려사항은?
"LLM의 근본적 한계를 해결했는가?"
- Hallucination 문제는 정말로 해결되었는가?
- 도메인 지식이 부족한 경우에도 잘 작동하는가?
- Fine-tuning 없이도 모든 도메인에서 일반화가 가능한가?
종합 평가
TimeRAG는 "RAG를 시계열 예측에 적용한 최초의 연구"로서 중요한 의미를 가진다. 특히 LLM의 파라미터 변경 없이도 의미있는 성능 향상을 달성한 것은 실용적 가치가 크다.
강점
- 새로운 연구 방향을 제시하고 실제 성능 향상을 검증했다
- 계산 효율적인 접근법으로 산업 적용 가능성이 높다
- 다양한 시간 주기에서 일관된 성능을 보였다
개선 필요 사항
- Architecture의 단순함으로 인한 정보 손실 문제가 존재한다
- 더 정교한 temporal modeling과 retrieval 메커니즘이 필요하다
- 광범위한 도메인과 실제 환경에서의 검증이 요구된다
향후 연구에서는 이러한 한계점들을 체계적으로 개선하여 더욱 강력하고 실용적인 시계열 예측 시스템을 구축할 수 있을 것으로 기대된다.
