이번에는 Kaggle에서 키와 몸무게로 BMI 지수를 예측하는 데이터를 이용해 회귀와 분류로 DNN을 구성해보았습니다.
문제 이해
위의 사이트에서 데이터를 다운로드 한 뒤 Colab으로 옮겼습니다.
문제 설명
키와 몸무게를 통해 BMI 지수를 예측하는 문제입니다.
키와 몸무게라는 연속적인 데이터를 이용하기 때문에 회귀문제입니다
이번에는 각 BMI 등급을 나눠서 분류로도 문제를 풀어서 회귀와 어떤 차이가 있는지 확인해보았습니다
데이터 가져오기 및 데이터 이해
data = pd.read_csv("/content/NHANES Weight and Height.csv")
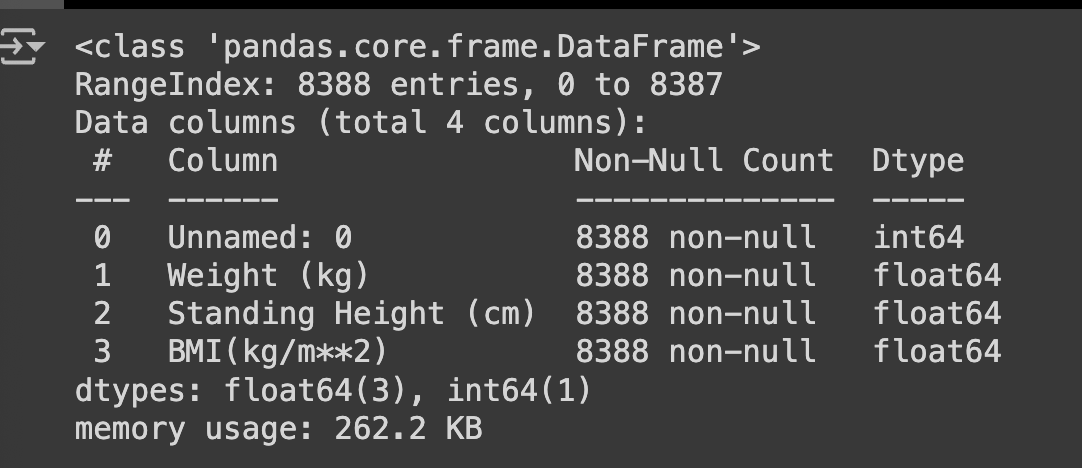
data.info()
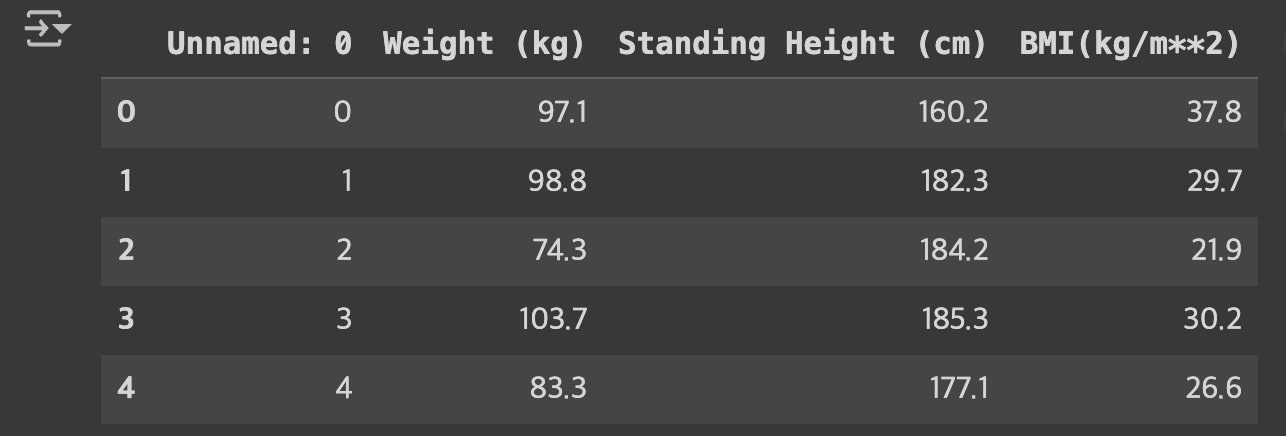
data.head()data.info() 를 이용해서 데이터의 타입과 각 데이터 수량을 확인했습니다
data.head() 를 통해 실제로 어떻게 데이터가 들어가 있는지 확인해보았습니다
앞에 Unanmed는 예측에 필요없는 데이터 이다
BMI가 이 데이터의 라벨(정답)이다
데이터 전처리 / 라벨 분리 / 훈련 - 테스트 데이터셋 나누기
data.isnull.any()위의 코드를 이용해서 null 즉 결측치가 있는지 가장 간단한 방식으로 확인 => 결측치는 없었습니다
이제 라벨을 분리한 뒤 훈련 / 테스트 데이터를 나누었습니다
# 라벨 분리 및 피처 만들기
feature_cols = ['Weight (kg)', 'Standing Height (cm)']
label = data.pop('BMI(kg/m**2)')
feature = data[feature_cols].copy()
# 훈련 / 테스트 데이터 나누기
train_x, test_x, train_y, test_y = train_test_split(feature, label, test_size=0.2, random_state=42)모델링하기 및 컴파일, 훈련
회귀 문제이기 때문에 손실함수를 mse, mae 중 하나를 사용하면 됩니다
여기서는 더 간단한 mae를 사용했습니다
mae = 결과에서 예측값 뺀 뒤 절대값으로 변경 -> 그리고 전부 합쳐서 평균을 계산!
model = Sequential([
Dense(64, activation='relu', input_shape=(2,)),
Dense(32, activation='relu'),
Dense(16, activation='relu'),
Dense(1)
])
model.summary()
model.compile(loss='mae', optimizer='adam', metrics=['mae'])
early_stopping = EarlyStopping(patience=20) # monitor='val_loss'안함
history = model.fit(train_x, train_y, epochs=100, validation_split=0.2, callbacks=[early_stopping])예상은 생각보다 잘 나올거라고 생각했습니다
그 이유는 매우 직관적으로 몸무게와 키로 예측을 할 수 있다고 생각했기 때문입니다!!
결과는 과연...
모델 평가 및 시각화
model.evaluate(test_x, test_y)
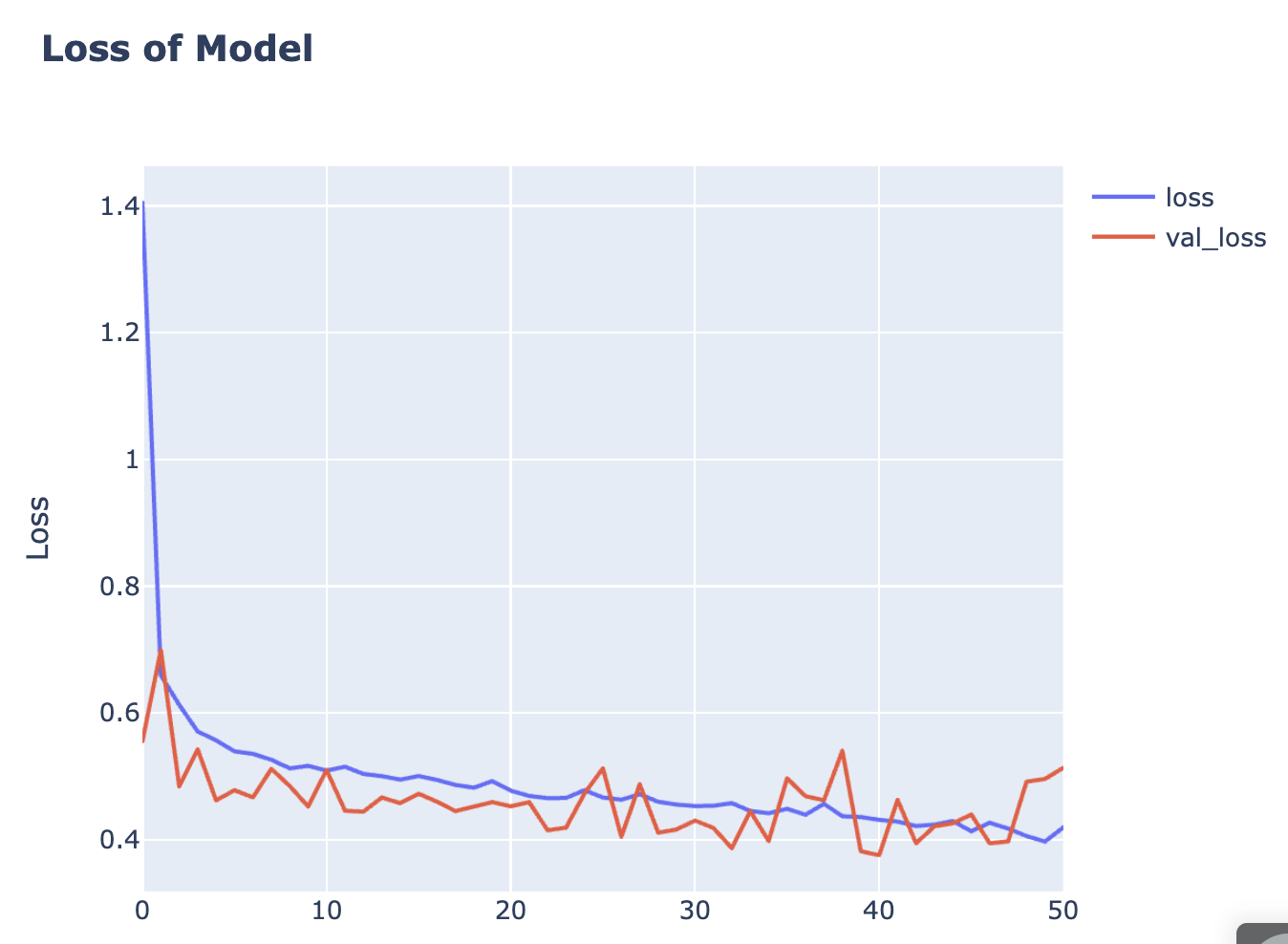
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scattergl(y=history.history['loss'], name='loss'))
fig.add_trace(go.Scattergl(y=history.history['val_loss'], name='val_loss'))
fig.update_layout(title="<b>Loss of Model</b>", xaxis_title="Epoch", yaxis_title="Loss")
fig.show()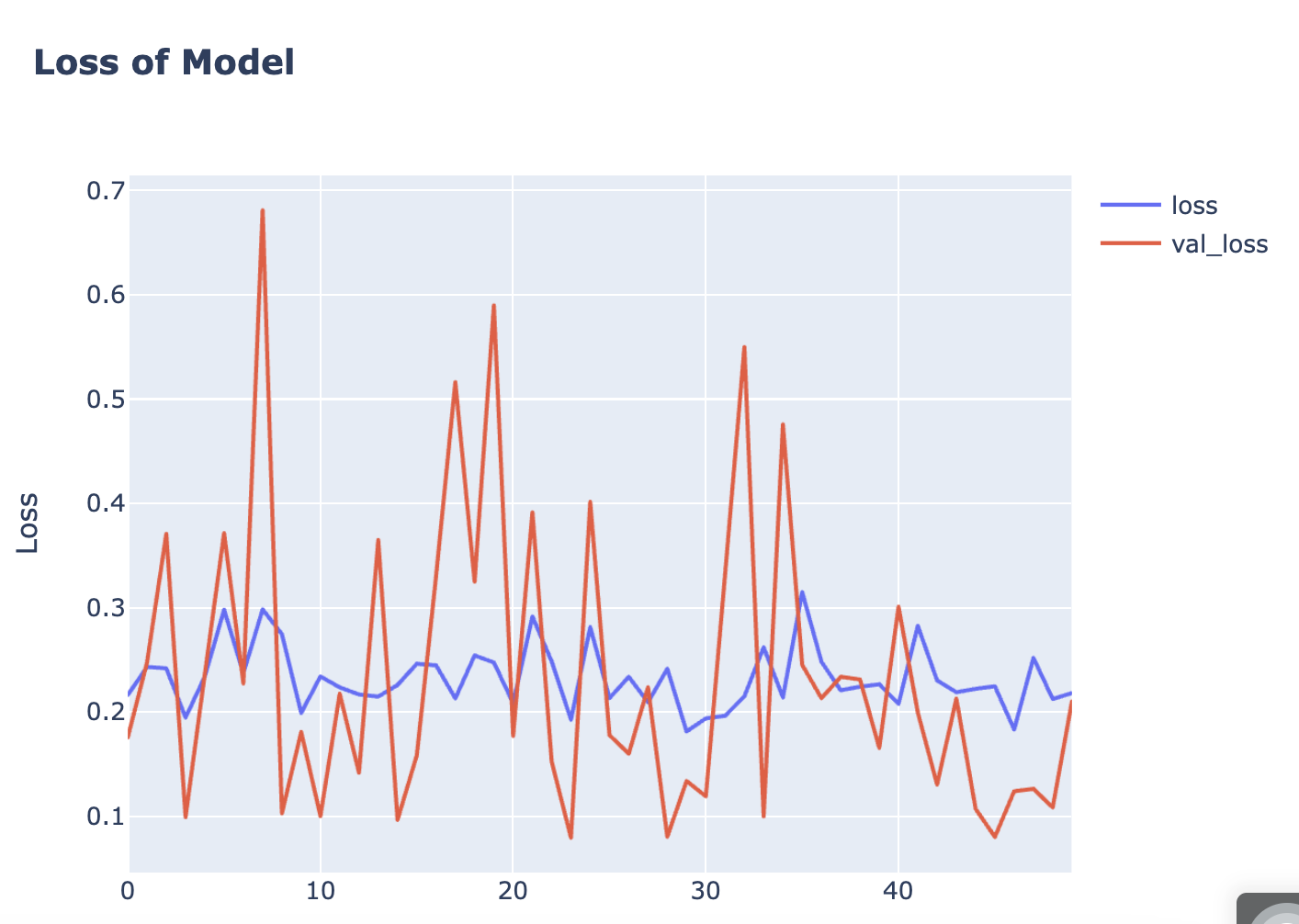
초반에 많이 왔다갔다(?)했지만 학습을 하면서 점점 더 나아진 모습을 볼 수 있습니다
x_t = [(91.1, 152.7)]
# y = 39.1
model.predict(x_t)array([[39.177517]], dtype=float32)로 거의 정확히 나왔습니다
분류로 문제 변형해서 풀어보기
회귀문제로서도 꽤나 정확한 결과를 보여주었지만 분류로 푼다면 어떻게 될까?
그래서 각 BMI 지수를 등급으로 나누어서 몸무게와 키를 넣으면 예측 등급이 나오는지 확인하는 AI모델을 만들었습니다
분류 해주는 함수 만들기
일단 BMI의 최댓값과 최솟값을 확인했습니다
data["BMI(kg/m**2)"].describe()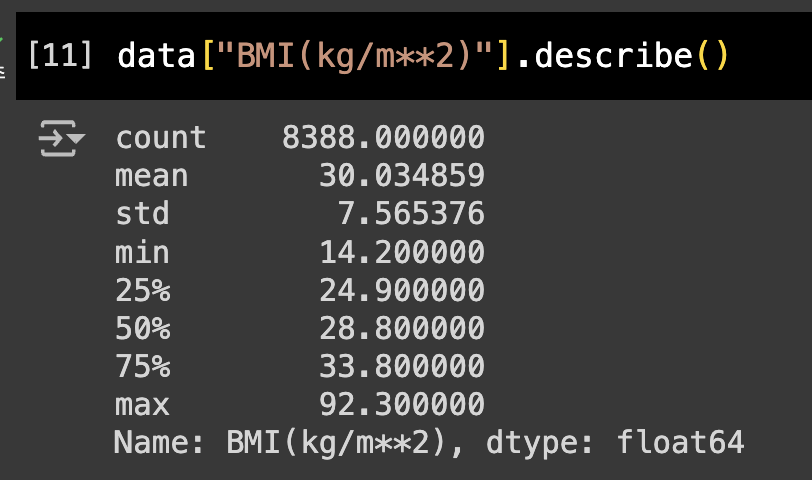
평균이 30, 최소가 14, 최대가 92로 확인했습니다
등급은 저체중 / 정상 / 과체중 / 비만 / 고도비만 으로 분류했습니다
def BMI_Classification(BMI):
if BMI <= 18.5:
return 0
elif 18.5 < BMI <= 23 :
return 1
elif 23 < BMI <= 25 :
return 2
elif 25 < BMI <= 30 :
return 3
elif 30 < BMI:
return 4그리고 data에 하나의 열을 만들어 넣어줬습니다
data["BMI_CF"] = data["BMI(kg/m**2)"].apply(BMI_Classification)
data.head()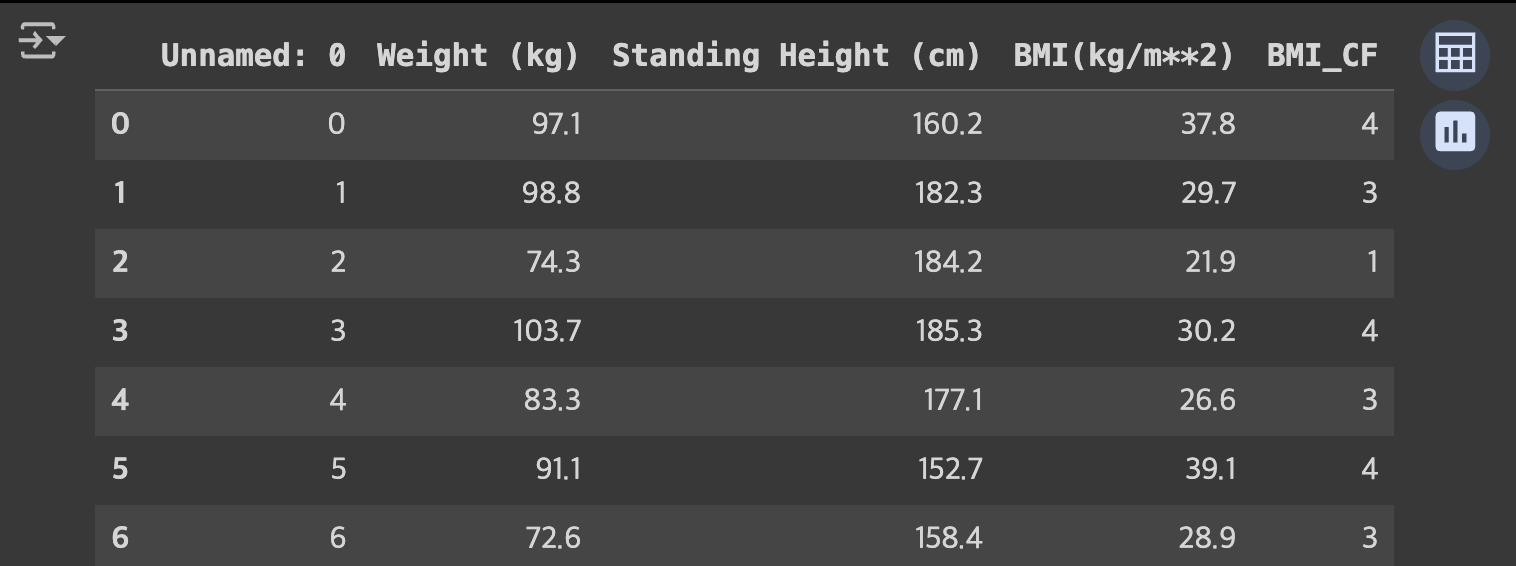
라벨, 피처 나누기
이 부분과 아래 데이터 나누는 부분은 위의 회귀문제와 크게 차이가 없습니다...
feature_cols = ["Weight (kg)", "Standing Height (cm)"]
label = data['BMI_CF"]
feature = data[feature_cols].copy()훈련-검증-테스트 나누기 / 모델링하기
훈련, 테스트를 나누고 검증 데이터를 나누었습니다
train_x, test_x, train_y, test_y = train_test_split(feature, label, test_size=0.2, random_state=42)
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size=0.2, random_state=42)- 훈련데이터 -> 6710개
- 검증 데이터 -> 1342개
- 테스트 데이터 -> 1678개
이제 모델링을 해보겠습니다
여기서는 5개의 등급으로 분류하기 때문에 softmax를 사용했고 과적합 방지를 위해 EarlyStopping을 사용했습니다
model = Sequential([
Dense(64, activation='relu', input_shape=(2,)),
Dense(32, activation='relu'),
Dense(16, activation='relu'),
Dense(5, activation='softmax')
])
model.summary()모델 컴파일 및 훈련, 평가하기
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
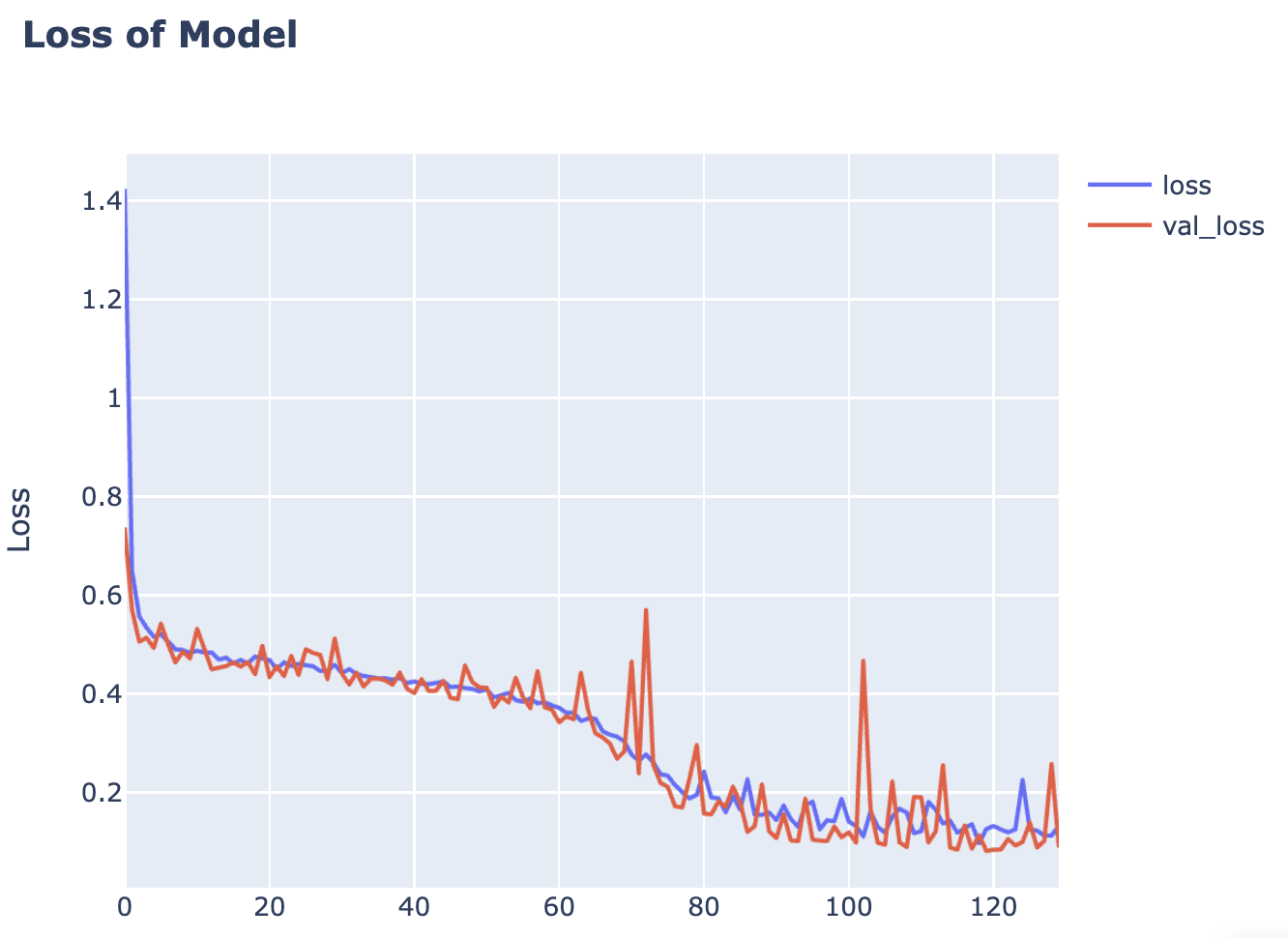
history = model.fit(train_x, train_y, epochs=1000, batch_size=32, validation_data=(val_x, val_y), callbacks=[early_stopping])130번대에서 조기 종료됨!
x_t = [(91.1, 152.7)]
np.argmax(model.predict(x_t)) # 4 나옴 정답!!
model.evaluate(test_x, test_y)loss: 0.09
accuracy : 96% 라는 높은 정확성을 나타냄
Dropout을 이용해서 일반화하기
사실 위에 까지만 해도 사용하는데 문제는 없지만 혹시 훈련 데이터에만 잘 사용되는건 아닌가?
할 수도 있어서 Dropout을 사용해서 일반화 성능도 높여보고자 했습니다
나중에 나오지만 큰 차이 없었습니다..
오히려 Dropout 안한게 더 정확했습니다!!
model = Sequential([
Dense(1024, activation='relu', input_shape=(2,)),
Dropout(0.3),
Dense(1024, activation='relu'),
Dropout(0.3),
Dense(1024, activation='relu'),
Dropout(0.3),
Dense(5, activation='softmax'),
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
history = model.fit(train_x, train_y, validation_data=(val_x, val_y),batch_size=32, epochs=1000, callbacks=[early_stopping])
피드백
회귀 문제를 분류로 바꿔서도 풀어볼만 하구나! 를 좀 알게되었습니다.
그리고 Dropout을 무조건적으로 사용하는건 지양하자!