
PostgreSQL
기능
CREATE DATABASECREATE TABLEALTER TABLE- 인덱스
- 트랜잭션
- 서브쿼리
- 스토어드 프로시저 및 함수
- 쿼리 계획 및 분석
- 인덱스 최적화
- 파티셔닝
- 캐싱
pg_dumppg_restorePoint-in-Time Recovery(PITR)CREATE USERCREATE ROLEREVOKE- 암호화
- 접근 제어
pg_hba.conf
데이터베이스 기본
테이블
- 수직 열 + 수평 행 모델로 조직된 데이터 요소의 집합
- 열은 지정된 개수, 행은 무한대 확장 가능
- 각 행은 후보키라고 식별되는 특정 열 하위 집합에 나타나는 값으로 식별
- SQL 데이터베이스에서는 관계 라고도 함
열/필드
- 테이블 각 행의 특정 단순 유형 데이터 값들의 집합
- 열은 어떤 행들로 이루어지느냐에 따르는 구조 제공
- 대부분의 경우 필드는 한 행과 한 열의 교차 지점에 있는 단일 값
레코드
- 테이블의 행에 저장된 정보
- 각 레코드는 테이블에 있는 각 열의 필드 차지
인덱스
- 데이터베이스 테이블 상에서 데이터 검색 작업의 속도를 향상시키는 데이터 구조
시퀀스
- 테이블의 어떤 열을 위한 유일한 식별자를 생성하는데 쓰이는 유일 숫자 생성기
엔티티 관계 도표(ERD)
- 관계들 사이의 논리적 의존성을 설계하는데 엔티티-관계 도표(ER Diagram) 사용
트랜잭션
- 데이터베이스에서 데이터를 추가, 변경, 삭제할 때 뭔가 문제가 발생해도 데이터베이스는 언제나 양호한 상태로 남아있어야 함
- 데이터베이스에 대한 수정 작업이 계획대로 되지 않았을 경우 되돌아갈 수 있는 복원 지점을 생성할 수 있게 해줌
참고(대소문자 구문)
실무에서 일반적인 규칙
- SQL 키워드는 대문자, 이름은 소문자
- 귀찮아서 전부 소문자로 하는 경우도 있다.
- 이름은 소문자+
_ - 데이터 자체는 대소문자 구분
- 문자열은
', 식별자와 객체 이름은"
테이블 명세서
각 테이블의 사용목적, 이름, 작성자, 비고사항 등의 테이블에 대한 기록뿐만 아니라 테이블에 포함된 각 컬럼의 이름, 데이터 타입 및 제약조건을 기록한 문서양식
DDL
테이블 생성
CREATE TABLE 테이블이름(
id SERIAL PRIMARY KEY,
머시기 INT,
저시기 INT,
머시기 VARCHAR,
FOREIGN KEY 칼럼이름 REFERENCES 테이블이름 칼럼이름
);데이터 삽입
INSERT INTO 테이블 (필드이름1, 필드이름2, ...)
VALUES (값1, 값2, ...);테이블 구조 변경
ALTER TABLE 테이블이름
ADD COLUMN 컬럼이름 데이터타입;데이터베이스 객체 삭제
DROP TABLE 테이블이름;DML
대상 스키마 설정
-- 스키마 설정하여 이름 생략하기
SET search_path TO practice;데이터조회
특정 테이블에서 특정 열만 선택해 데이터를 조회
SELECT 열이름 FROM 테이블명;
-- 전체 데이터 조회
SELECT * FROM practice.product_info;
-- 전체 데이터 개수 출력
SELECT count(*) FROM practice.product_info;
-- 원하는 열만 조회
SELECT serial_no, prod_start_date, target_weight FROM practice.product_info;
-- 열 이름 바꿔 조회
SELECT serial_no AS sn, prod_start_date "생산일자" FROM practice.product_info;
-- 지금 date에서 1일 빼기
SELECT now() - INTERVAL '1 day';정렬
-- 정렬하여 조회(target_weight → prod_start_date 순 기준으로 정렬)
SELECT serial_no, prod_start_date, target_weight from product_info ORDER BY target_weight DESC, prod_start_date;DESCorASC
원하는 개수만
-- 특정 개수만 조회(offset만큼 건너뜀)
SELECT * FROM product_info LIMIT 6 OFFSET 2;LIMIT은 앞선 연산들이 모두 끝난 후 실행된다.
중복된 결과 제거
-- 유니크 조회
SELECT DISTINCT(컬럼이름) FROM 테이블;조건 조회
SELECT 컬럼이름 FROM 테이블명 WHERE 조건;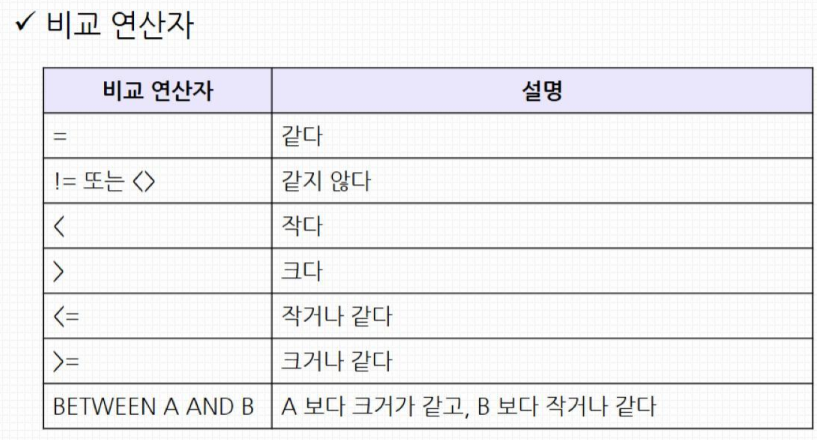
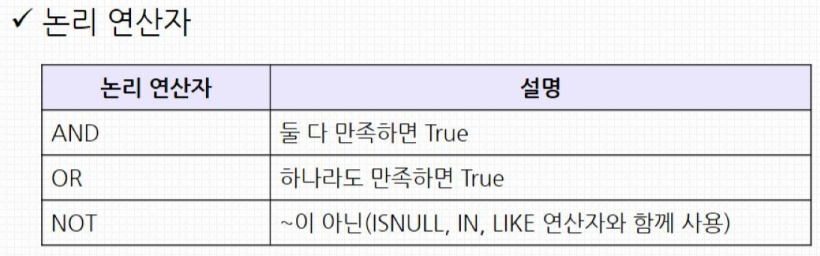
SELECT * FROM product_info WHERE factory_code = 'A';
SELECT * FROM product_info WHERE target_weight >= 70;
SELECT * FROM product_info WHERE prod_start_date BETWEEN '2026-01-01' AND '2026-01-02';
SELECT * FROM product_info WHERE target_weight > 69 OR target_weight <= 62;
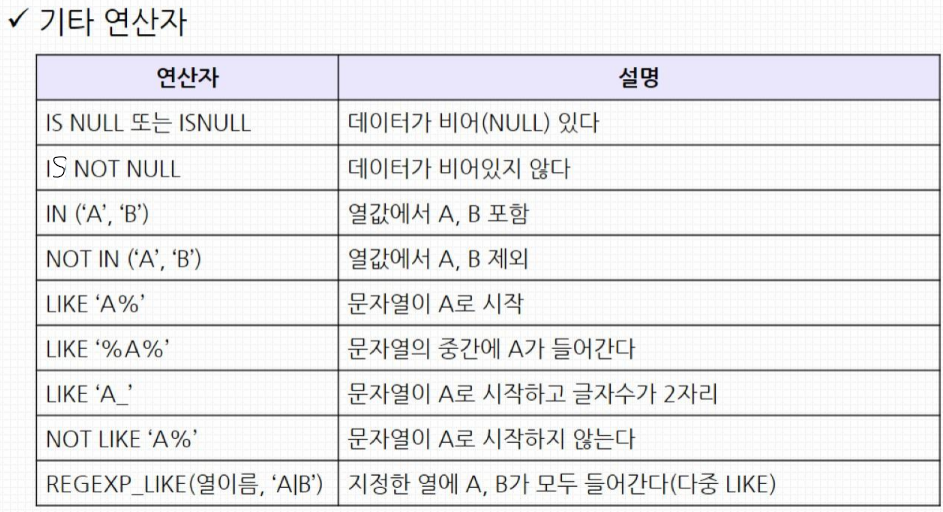
SELECT * FROM product_info WHERE model_id LIKE 'M%';
SELECT * FROM delivery_log WHERE destination IN ('Busan', 'Ulsan');
SELECT * FROM factory_env WHERE humid IS NULL;
SELECT * FROM sensor_log WHERE remarks IS NOT NULL;
SELECT * FROM product_info WHERE model_id BETWEEN 'M1' AND 'M2';
SELECT * FROM product_info WHERE model_id = 'M1' OR model_id = 'M2';
SELECT * FROM product_info WHERE model_id IN ('M1', 'M2');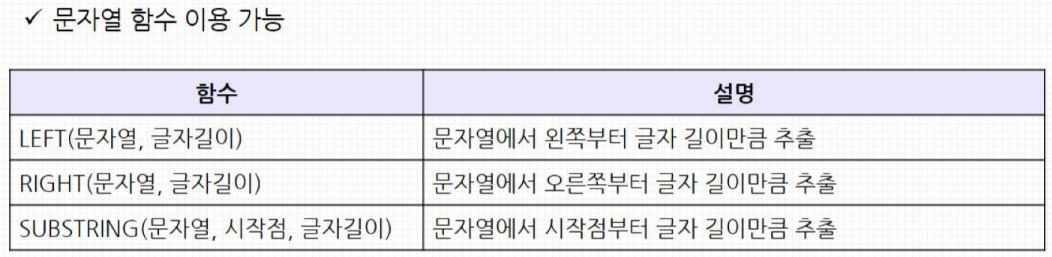
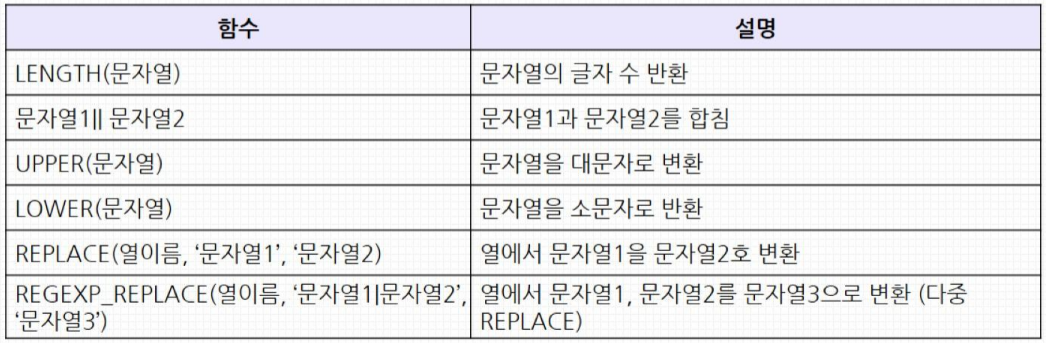
SELECT serial_no, left(serial_no, 1), substring(serial_no, 2, 3), right(serial_no, 4) FROM product_info LIMIT 5;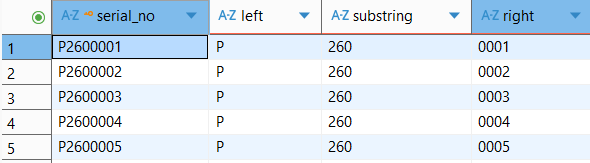
-- 글자수
SELECT length(serial_no) FROM product_info LIMIT 5;
-- 3개의 칼럼 데이터를 하나의 칼럼으로 합쳐 보여주기
SELECT REPLACE(REPLACE(factory_code, 'A', '평택공장'), 'B', '기흥공장')||line_id||model_id AS flm FROM product_info LIMIT 5;
-- 소문자 변환
SELECT lower(factory_code) FROM product_info LIMIT 5;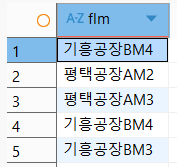
데이터 집계
- 집계 가능한 숫자형 열 타입에 대해 적용 가능
- count()의 경우 데이터 타입과 무관하게 행의 개수 구하기 가능
- 집계함수는 WHERE 절에서 사용 불가
SELECT
sum(target_weight) total_weight,
avg(target_weight) avg_weight,
max(target_weight) max_weight,
min(target_weight) min_weight,
count(*) AS total_count
FROM product_info;
-- →데이터 양이 늘어날수록 속도적 문제Group by
- 동일한 범주를 갖는 데이터를 하나로 묶어 범주별 통계를 내줌
SELECT 집계함수(열이름) FROM 테이블명 GROUP BY 범주열이름;
SELECT qa_date, sum(net_weight) AS qa
FROM qa_result
GROUP BY qa_date
LIMIT 5;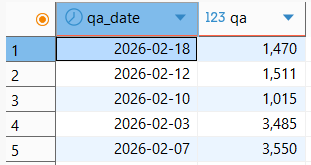
SELECT client_name, count(serial_no) AS cnt
FROM delivery_log
GROUP BY client_name;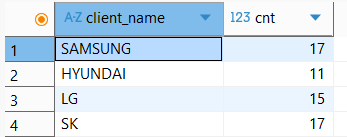
having
- where절은 집계 전 데이터에 조건을 걸 때, having절은 집계 후 데이터에 조건을 걸 때 사용
SELECT client_name, count(serial_no) AS cnt
FROM delivery_log
GROUP BY client_name
HAVING count(serial_no) >= 15;
--shipped date가 2026-02-05 이후인 데이터에 대해서 출하건수가 8개 이상인 고객사만 필터링
SELECT client_name, count(serial_no) AS "출하건수"
FROM delivery_log
WHERE shipped_date >= '2026-02-05'
GROUP BY client_name
HAVING count(*) >= 8;데이터 변환 및 조건
- 데이터 타입 변환
- 날짜나 숫자를 문자열로 변환 혹은 반대
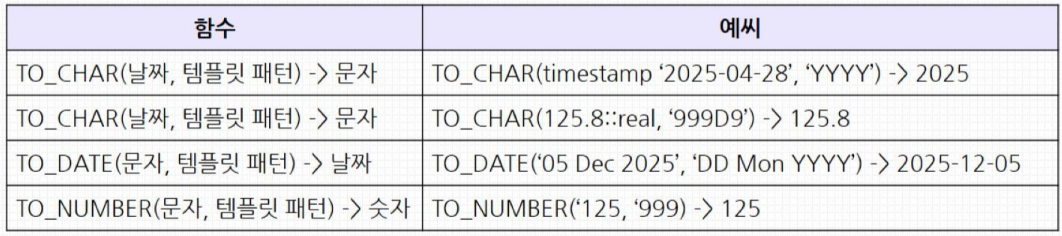
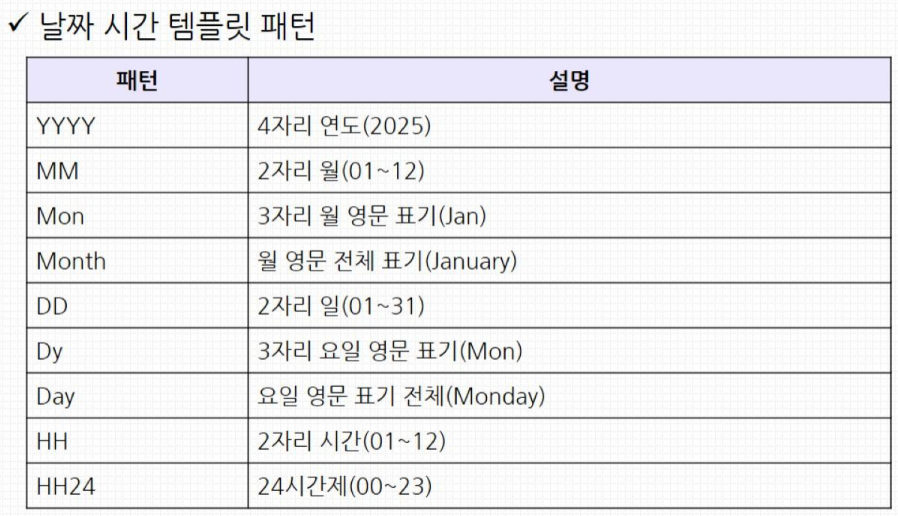
날짜 변환
SELECT prod_start_date , TO_CHAR(prod_start_date, 'Mon')
FROM product_info
LIMIT 5;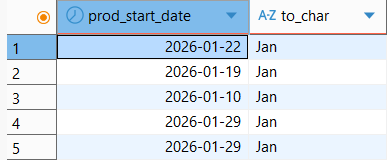
NULL 변환
COALESCE
-- NULL값을 60으로 대체
SELECT line_id, check_date , humid, coalesce(humid, 60)
FROM factory_env
WHERE check_date BETWEEN '2026-02-01' AND '2026-02-27'
AND line_id = 'A';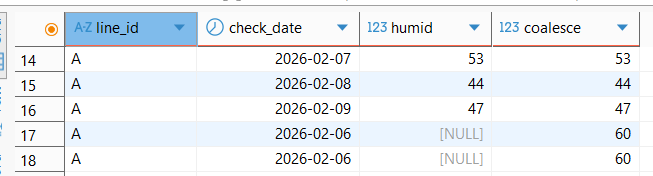
NULLIF
-- 해당하는 값을 NULL로 대체
SELECT line_id, check_date , humid, NULLIF(humid, 42)
FROM factory_env
WHERE check_date BETWEEN '2026-02-01' AND '2026-02-27'
AND line_id = 'A';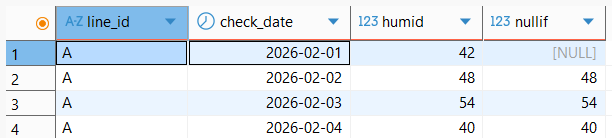
CASE
SELECT
serial_no,
target_weight,
CASE
WHEN target_weight > 600 THEN 'H'
WHEN target_weight > 500 THEN 'M'
ELSE 'L'
END "w_grade"
FROM product_info;기타

SELECT *
FROM product_info
ORDER BY target_weight desc
LIMIT 5;
SELECT *
FROM sensor_log
WHERE current_weight > 500 AND cpu_temp < 60; 
SELECT prod_start_date, count(serial_no) AS "count"
FROM product_info
GROUP BY prod_start_date
HAVING count(*) > 5;
SELECT line_id, count(DISTINCT check_date) AS "high_voltage_days"
FROM factory_env
WHERE voltage > 220
GROUP BY line_id;
SELECT serial_no, COALESCE (remarks , '없음')
FROM sensor_log;
SELECT serial_no,
CASE
WHEN remarks IS NULL OR remarks = '' THEN '없음'
ELSE remarks
END
FROM sensor_log;
SELECT AVG(target_weight)
FROM product_info;
SELECT *
FROM product_info
WHERE target_weight > 574;
-- 저도 서브쿼리 날려야 하는거 아는데 강사님이 이렇게 하라네요...
SELECT serial_no, qa_date,
REPLACE(REPLACE(qa_status, 'P', '합격'), 'F', '불합격') AS "qa_status"
FROM qa_result;
SELECT client_name, count(*) AS "order_cnt",
CASE
WHEN count(*) >= 17 THEN 'A등급'
WHEN count(*) >= 15 THEN 'B등급'
ELSE 'C등급'
END AS "grade"
FROM delivery_log
GROUP BY client_name;테이블 형태 변환 및 수정
테이블 합치기
JOIN
테이블이 두 개 이상인 경우 테이블을 합치거나 정보를 조합해야 할 때 사용
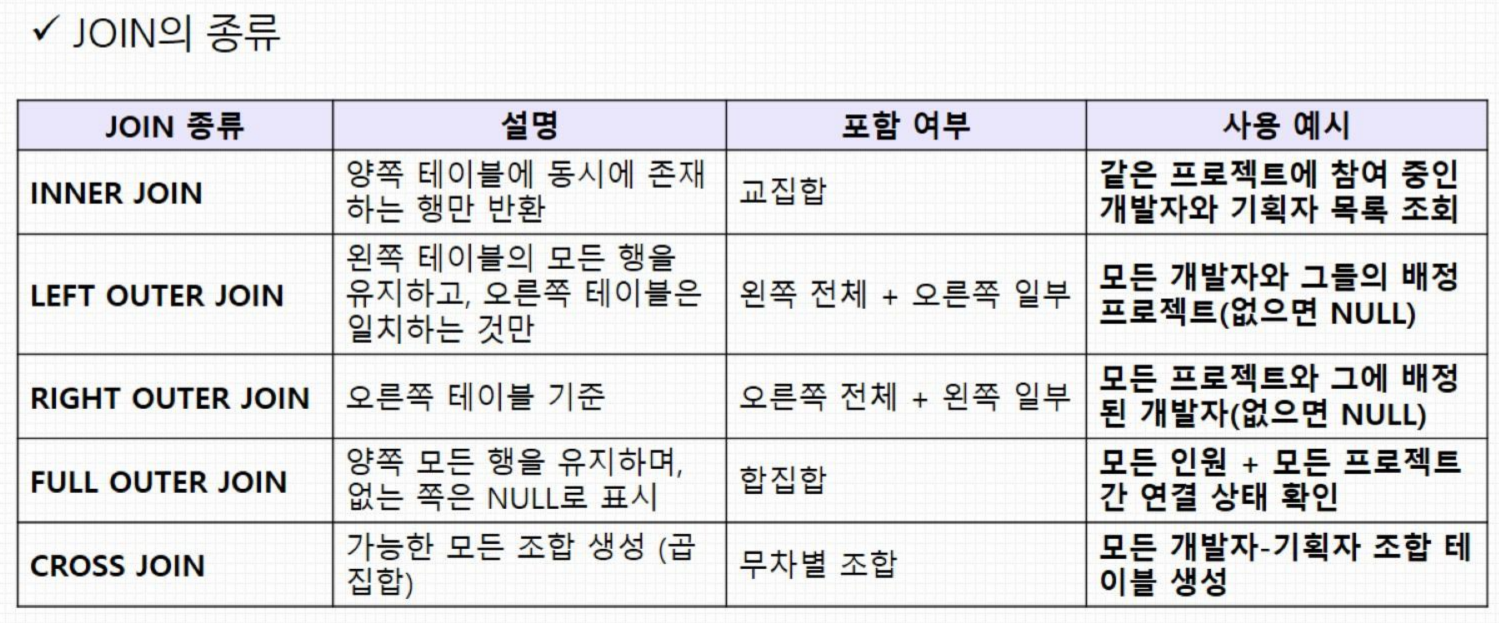
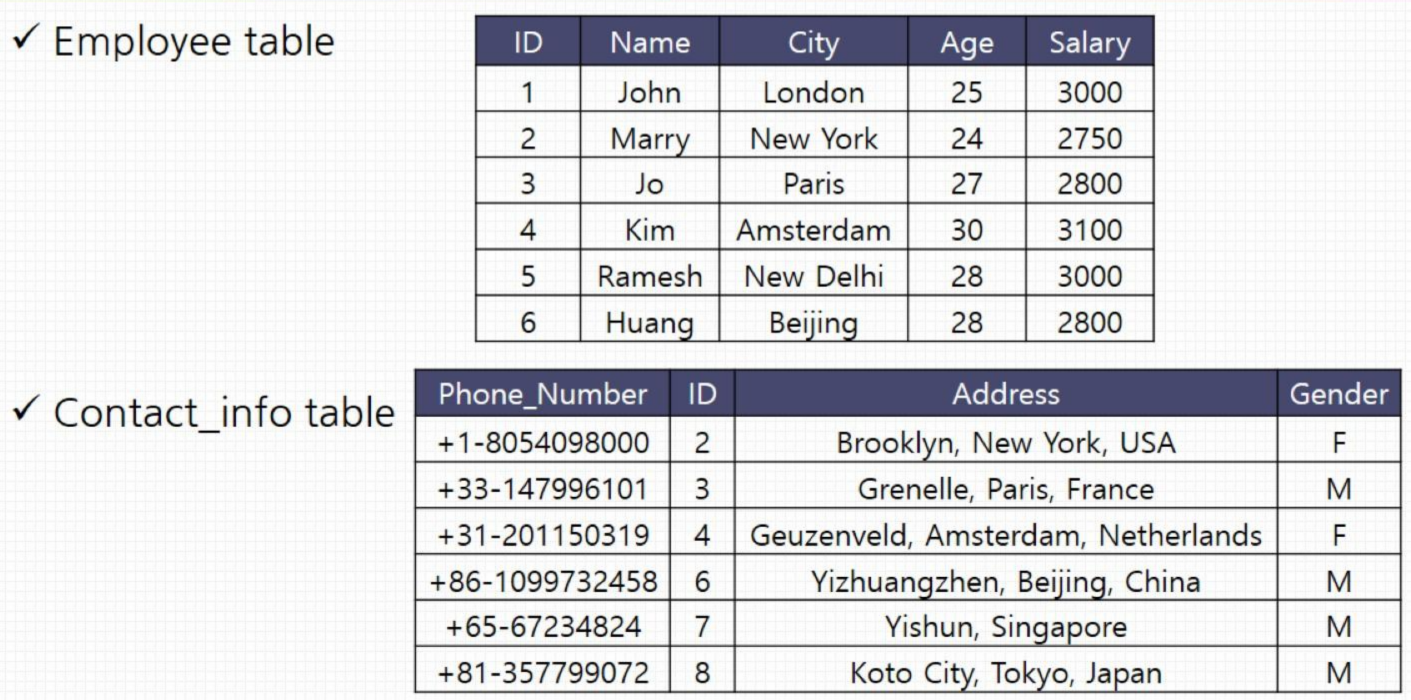
INNER Join
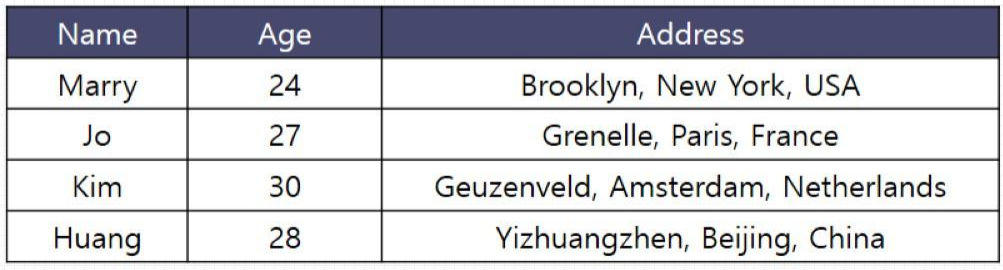
SELECT Employee.Name, Employee.Age, Contact_Info.Address
FROM Employee
INNER JOIN Conatact_Info
ON Employee.ID = Contact_Info.ID;SELECT *
FROM qa_result qr INNER JOIN delivery_log dl
ON qr.serial_no = dl.serial_no;
SELECT *
FROM qa_result qr, delivery_log dl
where qr.serial_no = dl.serial_no;
-- qa_result, product_info 생산 결과와 정보 조인하여 line_id별 평균 중량 구하기
SELECT line_id, avg(qr.net_weight)
FROM qa_result qr, product_info t
WHERE qr.serial_no = t.serial_no
GROUP BY t.line_id;
-- qa_result에서 defect가 있던 제품 리스트
SELECT t.serial_no, t.line_id, qr.qa_date
FROM qa_result qr, product_info t
WHERE qr.serial_no = t.serial_no
AND qr.defect_yn = 'Y';
LEFT OUTER JOIN
SELECT *
FROM qa_result qr LEFT OUTER JOIN delivery_log dl
ON qr.serial_no = dl.serial_no; UNION
열(Column)구조가 같은 두 쿼리 결과를 행(row) 단위로 붙임
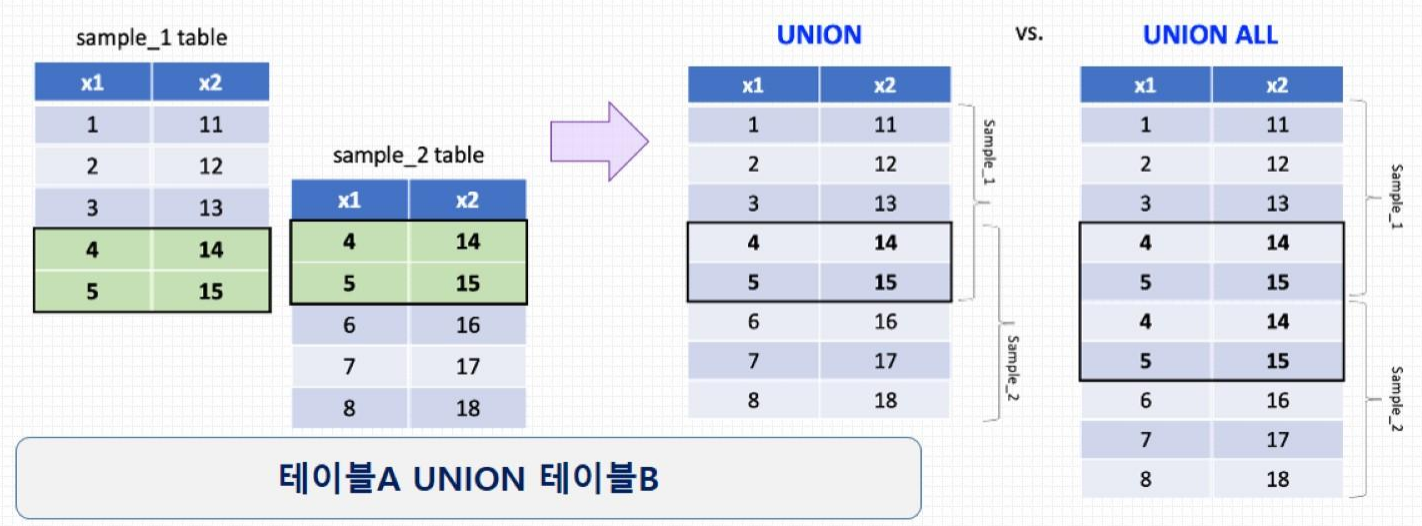
- 열이 아닌 행을 기준으로 데이터를 합치기 위해서는
UNION또는UNION ALL(중복) 절을 이용
(SELECT serial_no, model_id, prod_start_date
FROM product_info
WHERE line_id = 'A'
AND model_id = 'M2'
AND prod_start_date = '2026-01-22')
UNION
(SELECT '롸롸롸', '뫄뫄뫄', '2026-01-23');

성장하기 위한 기록