
자격증 추천: SQLD, ADSP, 빅분기
데이터와 데이터베이스
데이터
| 구분 | 정량적 데이터(Quantitative) | 정성적 데이터(Qualitative) |
|---|---|---|
| 유형 | 정형 데이터, 반정형 데이터 | 비정형 데이터 |
| 특징 및 관점 | 여러 요소의 결합으로 의미 부여 주로 객관적 내용 | 객체 하나가 함축적 의미 내포 주로 주관적 내용 |
| 구성 및 형태 | 수치나 기호 스프레드시트, 데이터베이스 | 문자나 언어 웹로그, 텍스트 파일 |
| 위치 | DBMS, 로컬 시스템 등 내부 | 웹사이트, 모바일 플랫폼 등 외부 |
| 분석 | 통계 분석 시 용이 | 통계 분석 시 어려울 수 있음 |
정형 데이터(Structured Data)
- 정해진 형식과 구조에 맞게 저장되도록 구성된 데이터
- 연산 가능
- 관계형 데이터베이스의 테이블에 저장되는 데이터
반정형 데이터(Semi-structured Data)
- 데이터의 형식과 구조가 비교적 유연
- 스키마 정보를 데이터와 함께 제공하는 파일 형식의 데이터
- 연산 불가능(Parsing 필요)
- JSON, XML, RDF, HTML
비정형 데이터(Unstructured Data)
- 구조가 정해지지 않은 대부분의 데이터
- 연산 불가능
- 동영상, 이미지, 음성, 문서, 메일
데이터의 구분
수치형 자료(numerical data)
- 관측된 값이 수치로 측정되는 자료
- 연속형(continuous data): 키, 몸무게
- 이산형(discrete data): 자동차 사고
- 연속형은 실제 이산형태로 표시하지만 관측 가능한 값이 연속형이면 연속으로 간주
범주형 자료(categorical data)
- 관측된 결과가 범주, 항목 형태로 나타나는 자료
- 성별, 선호도, 혈액형, 지역
- 순위형 자료(ordinal data): 범주 간 순서가 있는 자료
- 명목형 자료(nominal data): 범주 간 순서의 의미가 없는 자료
- 범주형 자료도 수치형 자료처럼 쓸 수 있음
- 수치형 자료처럼 표현되어 있는 범주형 자료 구분 주의
데이터, 정보, 지식, 지혜
DIKW 피라미드(Data, Information, Knowledge, Wisdom)
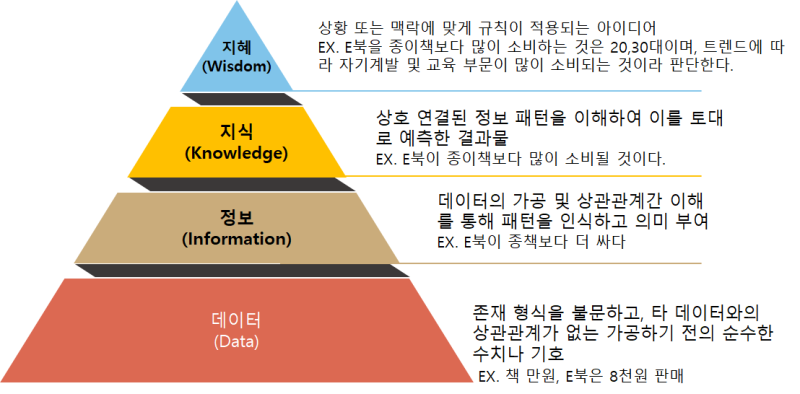
- 단순한 값의 나열인 데이터 수집
- 수집한 데이터 중 데이터 과학의 목적에 알맞은 데이터들을 정보로 분류
- 정보를 분석하여 지식 도출
- 얻은 지식에 상황이나 맥락을 더해 알맞게 활용하는 지혜 도출
빅데이터
기존 데이터베이스 관리도구의 능력을 넘어서는 대량(수십 테라바이트)의 정형 또는 비정형 데이터 집합을 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술
특징
3V: 양(Volume), 데이터 생성 속도(Velocity), 형태의 다양성(Variety)
- 양: 대량(수십 테라바이트)
- 속도: 대용량의 데이터를 빠르게 처리하고 분석할 수 있는 속성(저장, 유통, 수집, 분석처리 가능한 성능)
- 다양성: 정형, 반정형, 비정형
최근에는 가치(Value)나 복잡성(Complexity)을 덧붙이기도 함
시험에서 "다음 중 빅데이터의 특징 중 어느 특징을 말하는 예시인지" 고르는 것 존재
인과관계와 상관관계
- 과거: 데이터 질 / 현재: 양
- 절대적인 데이터량이 많아지면서 양질의 데이터도 자연스럽게 증가하기 때문
빅데이터와 데이터 리터러시
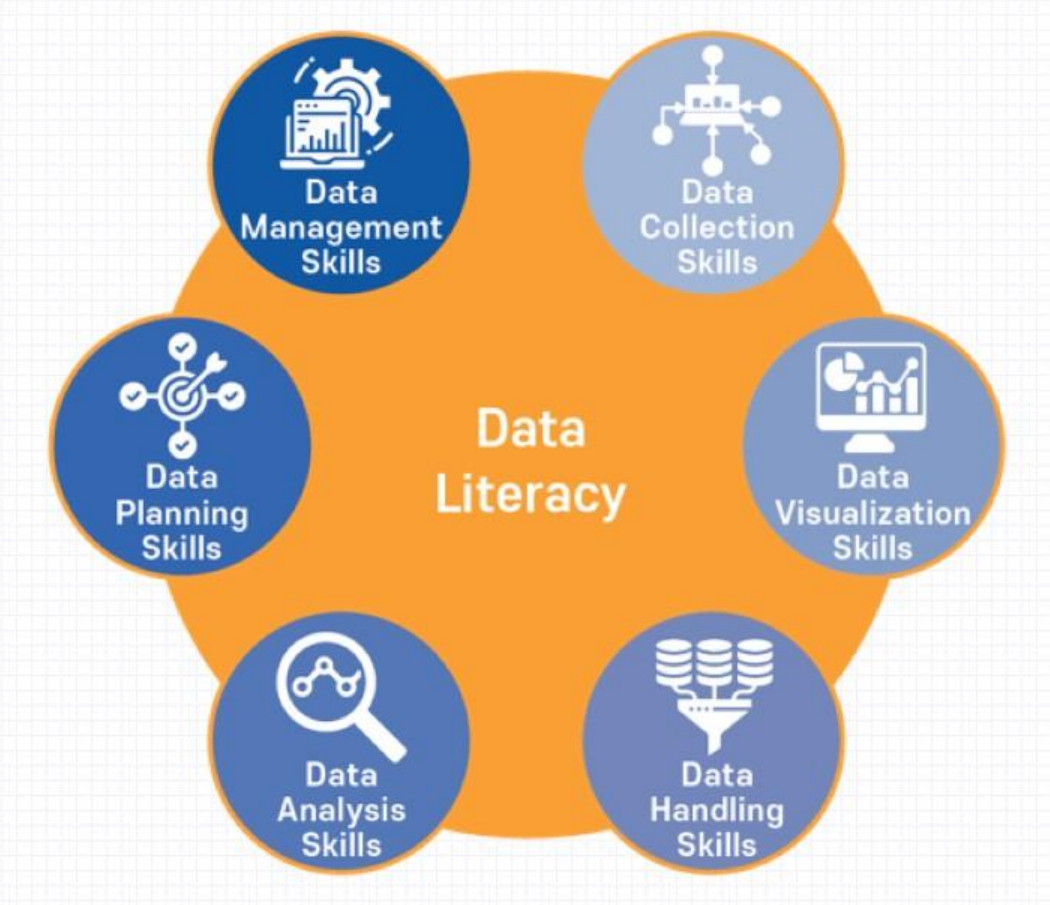
데이터 분석 과정
1. 문제 정의
2. 데이터 정의
- 분석의 목적
- 현상 파악
- 원인 분석
- 추세 예측
3. 데이터 수집
- 기업의 DB
- 제공되는 데이터셋(공공데이터, 민간데이터)
- 직접 수집
- 웹 스크래핑
4. 데이터 전처리
- 데이터 결측치, 이상치 제거
5. 데이터 분석, 시각화
- 통계적 분석, 탐색적 데이터 분석(EDA), 머신러닝/딥러닝
- 시각화
6. 정보 도출
데이터 분석 사례
- 서울시 심야버스 노선 결정(사용량 히트맵)
- 존 스노우의 콜레라 지도
- 정상 뇌와 알츠하이머 뇌 사진 분석을 통한 질병 진단(이미지 분류 딥러닝)
데이터 포털
- 공공 데이터 포털 http://data.go.kr
- 파일 데이터, 오픈API, 시각화 등 다양한 방식으로 제공
- 국가통계포털(통계청) https://kosis.kr/index/index.do
- 국내, 국제, 북한의 주요 통계를 한 곳에 모아 이용자가 원하는 통계를 한 번에 찾을 수 있도록 통계청이 제공하는 One-Stop 통계 서비스
- 기상자료 개방 포털 https://data/kma.go.kr/cmmn/main.do
- 대한민국 날씨 정보
- 고속도로 데이터포털(한국도로공사) https://data.ex.co.kr
- 서울 열린 데이터 광장(서울시) https://data.seoul.go.kr
- 서울시 및 자치구, 산하기관이 보유하는 공공데이터를 발굴, 개방하는 서비스
- 경기데이터드림(경기도) https://data.gg.go.kr
- 경기도가 보유한 공공데이터
- 부동산 실거래가 공개 시스템 https://rtdown.molit.go.kr
- AI Hub(NIA: 한국지능정보사회 진흥원) https://aihub.or.kr
- AI 기술 및 제품, 서비스 개발에 필요한 AI 인프라 지원
- 캐글(데이터 경연 플랫폼) http://www.kaggle.com
- 기업 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 분석하는 대회형 플랫폼
기타 총정리
| 분야 | 명칭 | URL | 비고 |
|---|---|---|---|
| 전체 | 공공 데이터 포털 | https://www.data.go.kr | |
| 전체 | 서울시 열린데이터 광장 | https://data.seoul.go.kr | |
| 행정 | 지방행정데이터 | http://localdata.kr | |
| 지도 | 국가 공간정보 포털 | http://nsdi.go.kr | |
| 건축 | 건축데이터 민간 개방 시스템 | http://open.eais.go.kr | |
| 기상 | 기상자료 개방 포털 | https://data.kma.go.kr | |
| 관광 | Tour API | http://api.visitkorea.or.kr | |
| 농림 | 농림축산부 | http://www.mafra.go.kr/mafra/322/subview.do | |
| 금융 | 금융 빅데이터 개방 시스템 | https://credb.kcredit.or.kr:3446/frt/login/idSearch.do | |
| 치안 | 경찰청 공공 데이터 개방 | https://www.police.go.kr/www/open/publice/publice01.jsp | |
| 문화 | 문화 데이터 광장 | https://www.culture.go.kr/data | |
| 복지 | 보건 복지 데이터 포털 | https://data.kihasa.re.kr | |
| 교통 | 교통 사고 분석 시스템 | http://taas.koroad.or.kr | |
| 전기 | 전력데이터 개방 포털 시스템 | https://bigdata.kepco.co.kr | |
| 기타 | 데이터 스토어 | https://www.datastore.or.kr | 데이터 거래 |
데이터베이스
특정 조직의 여러 사용자가 공유하여 사용할 수 있도록 통합해서 저장한 운영 데이터 집합
정보 시스템
조직 운영에 필요한 데이터를 수집하여 저장했다가 의사 결정이 필요할 때 유용한 정보를 만들어주는 수단
핵심 역할을 데이터베이스가 수행
데이터베이스 성질
| 구분 | 영문 | 설명 |
|---|---|---|
| 통합 데이터 | integrated data | 최소의 중복과 통제 가능한 중복만 허용하는 데이터 |
| 저장 데이터 | stored data | 컴퓨터가 접근할 수 있는 매체에 저장된 데이터 |
| 공유 데이터 | shared data | 특정 조직의 여러 사용자가 함께 소유하고 이용할 수 있는 공용 데이터 |
| 운영 데이터 | operational data | 조직의 주요 기능을 수행하기 위해 지속적으로 꼭 필요한 데이터 |
데이터베이스 특징
| 구분 | 영문 | 설명 |
|---|---|---|
| 실시간 접근 | real-time accessibility | 사용자의 데이터 요구에 실시간으로 응답 |
| 계속 변화 | continuous evolution | 데이터의 계속적인 삽입, 삭제, 수정을 통해 현재의 정확한 데이터를 유지 |
| 내용 기반 참조 | contents reference | 데이터가 저장된 주소나 위치가 아닌 내용으로 참조 예) 재고량이 1,000개 이상인 제품의 이름을 검색 |
| 동시 공유 | concurrent sharing | 서로 다른 데이터의 동시 사용뿐만 아니라 같은 데이터의 동시 사용도 지원 |
데이터베이스 종류
| 종류 | 목적 및 사용처 | DBMS |
|---|---|---|
| RDB | 가장 일반적인 테이블 형태. 엑셀의 시트와 같이 행과 열로 이루어져 있어 정형 데이터에 적합. 모든 산업군에서 널리 사용 | Oracle, MySQL, MariaDB, MS-SQL, PostgreSQL, Tibero 등 |
| NoSQL | 기존 RDB의 단점을 보완해 응답 속도나 처리 효율↑. Key-Value, Wide Column, Document, Graph 형태. 인스타그램, 넷플릭스 등의 SNS, OTT 산업군에 사용 | MongoDB, Hbase, Cassandra, Redis, Neo4J 등 |
| RTDB | 산업 현장의 센서에서 발생되는 방대한 데이터를 초고속으로 처리하기 위해 개발. 시계열 트렌드를 실시간으로 모니터링O 발전사, 정유사, 철강사 등 장치 산업군에 사용. | OSI PI System, dataPARC, Honeywell PHD, GE Historian 등 |
| DBMS | 제작사 | 작동 운영체제 | 기타 |
|---|---|---|---|
| MySQL | Oracle | Unix, Linux, Windows, Mac | 오픈 소스(무료), 상용, 대규모용 기능은 부족 |
| MariaDB | MariaDB | Unix, Linux, Windows | 오픈 소스(무료), MySQL 초기 개발자들이 독립해서 만듦, 동시접속 트랜젝션엔 부적합 |
| PostgreSQL | PostgreSQL | Unix, Linux, Windows, Mac | 오픈 소스(무료) |
| Oracle | Oracle | Unix, Linux, Windows | 상용 시장 점유율 1위, 자격증 비쌈 |
| SQL Server | Microsoft | Windows | 주로 중/대형급 시장에서 사용, 윈도우 기반 강력 |
| DB2 | IBM | Unix, Linux, Windows | 메인프레임 시장 점유율 1위 |
| Access | Microsoft | Windows | PC용 |
| SQLite | SQLite | Android, iOS | 모바일 전용, 오픈 소스(무료) |
DBMS(DataBase Management System)
데이터베이스 내의 정보를 구성하는 컴퓨터 프로그램의 집합. 자료의 중복성 제거. 무결성, 일관성, 유용성 보장을 위해 자료를 제거하고 관리하는 소프트웨어 체계
- 파일 시스템의 데이터 중복과 데이터 종속 문제를 해결하기 위해 제시된 소프트웨어
- 데이터베이스를 구축하는 틀 제공, 효율적인 데이터 검색 및 저장 기능 제공
- 응용프로그램용 접근 인터페이스 , 장애에 대한 복구 기능, 사용자 권한에 따른 보안성 유지 기능 제공
DBMS의 분류
계층형 DBMS
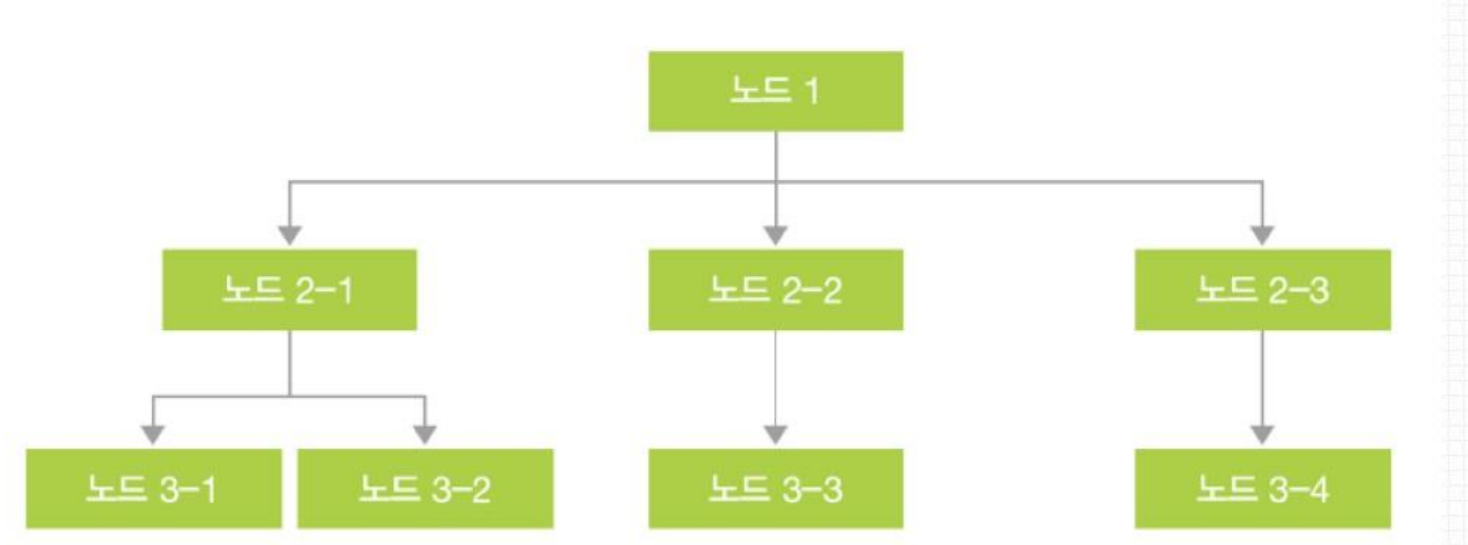
- 각 계층이 트리 형태 (1:N)
- 한 번 구축하면 구조 변경 까다로움
- 접근 유연성 부족, 임의 검색 어려움
망형 DBMS
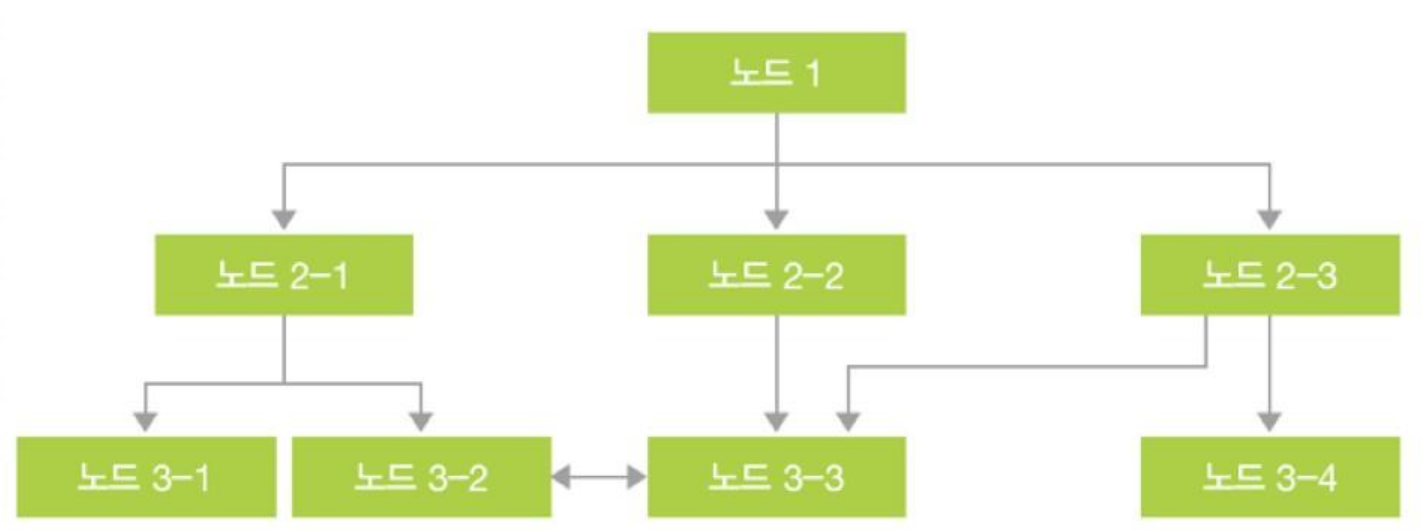
- 1:1, 1:N, N:M 관계 지원
- 효과적이고 빠른 데이터 추출 가능
- 매우 복잡한 내부 포인터
- 모든 구조를 이해해야 프로그램 작성 가능
관계형 DBMS
- 모든 데이터는 테이블에 저장
- 테이블 간 PK, FK로 관계 사용
- 업무 변화에 따라 바로 순응
- 유지 보수 용이
- 대용량 데이터 체계적 관리 가능
- 무결성 보장
- 시스템 자원 차지 ↑, 시스템 전반적으로 느려짐
DBMS의 장단점
장점
- 데이터 중복 통제
- 데이터 독립성 확보
- 데이터 동시 공유 가능
- 데이터 보안 향상
- 데이터 무결성 유지
- 표준화 가능
- 장애 발생 시 회복 가능
- 응용 프로그램 개발 비용 감소
단점
- 비용↑
- 백업과 회복 방법 복잡
- 중앙 집중 관리로 인한 취약점
DBMS 주요 기능
| 기능 분류 | 설명 |
|---|---|
| 정의 기능 | 데이터베이스 구조를 정의하거나 수정할 수 있음 |
| 조작 기능 | 데이터를 삽입·삭제·수정·검색하는 연산을 할 수 있음 |
| 제어 기능 | 데이터를 항상 정확하고 안전하게 유지할 수 있음 |
PostgreSQL Database
관계형 데이터베이스 관리 시스템
- RDBMS: Relational Databse Management System
- RDB라고 줄여부름. 통상적으로 DB는 RDB
- ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션 지원
SQL(Structured Query Language)
RDB에서 원하는 데이터를 불러오거나 수정하는데 사용되는 언어
Query

데이터베이스에서 데이터를 검색, 조작하기 위한 SQL 명령
- 보통 SELECT
- DML, DDL, DCL, TCL(Transaction Control Language)도 쿼리에 포함
- 시험 출제: 다음중 DML이 아닌것은? 같은거
RDBMS와 SQL
- 관계형 데이터베이스들은 대부분 SQL 기반
- 데이터 타입
- 함수 및 연산자
- 제약 조건 및 인덱스
- 조인 및 하위 쿼리
- 특수 기능 및 확장 기능
기본 문법
SELECTINSERTUPDATEDELETEWHEREORDER BYGROUP BYHAVINGJOINCOUNTSUMAVGMINMAX집계 함수, 문자열 함수, 날짜 함수
제약 조건 및 인덱스
| DBMS | 자동 증가 구현 방식 |
|---|---|
| PostgreSQL | SERIAL, BIGSERIAL |
| MySQL | AUTO_INCREMENT |
| Oracle | 자동 증가를 위한 고유 데이터 타입이나 속성 없음 |
| SQL Server | IDENTITY |
PostgreSQL
- Open Source RDBMS
- ANSI 표준 SQL을 90% 이상 준수
- 확장성: 대규모 데이터 처리 및 복잡한 쿼리 지원
- 다양한 데이터 타입: JSON, XML 등 다양한 데이터 타입 지원
설치
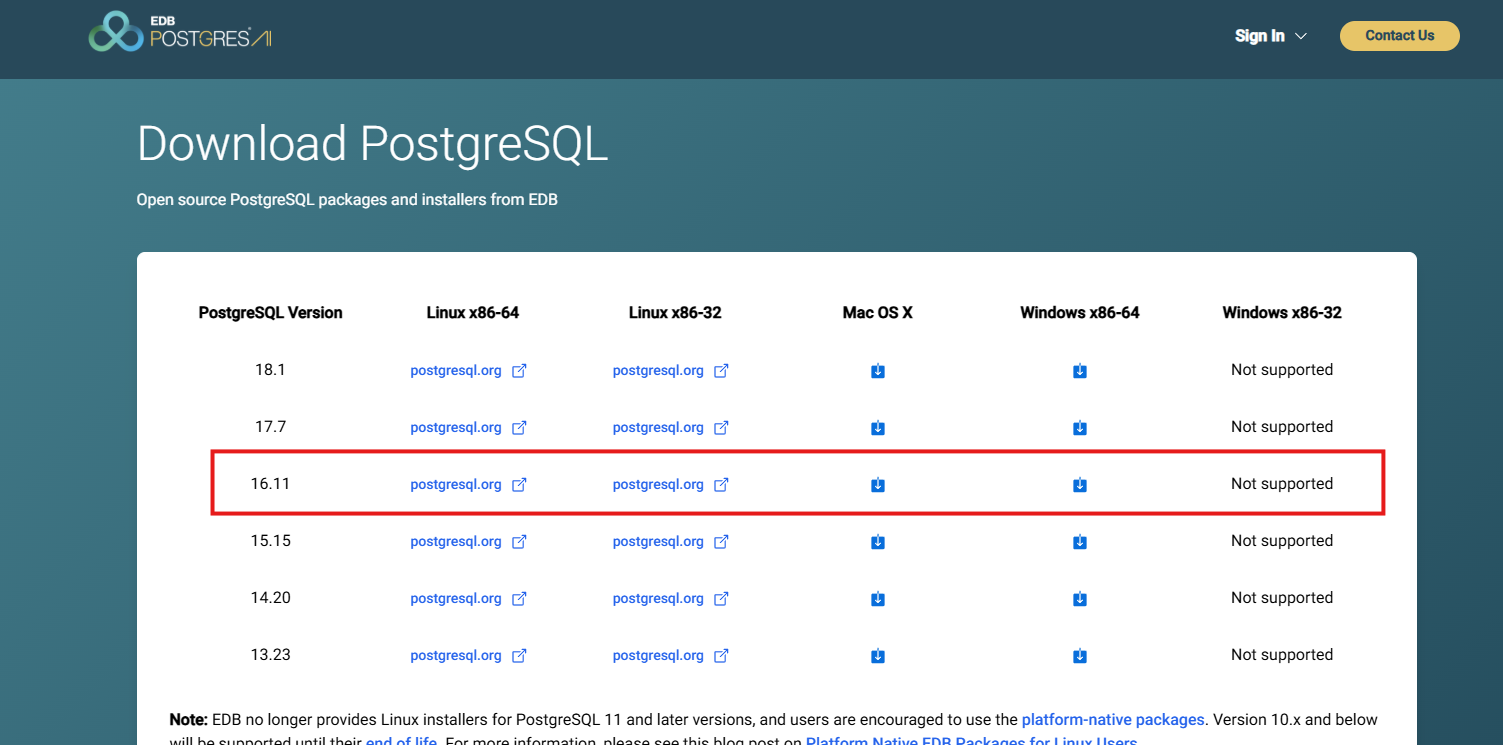
https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
16.11 사용
주의
어드민 비번 설정할 때 @를 넣으면, python에서 접속할 때 오류가 발생할 수 있으므로 자제하자.
포트
5432 기본. 혹시 겹치면 다른걸 쓰자
데이터베이스 접속하기(pgAdmin)
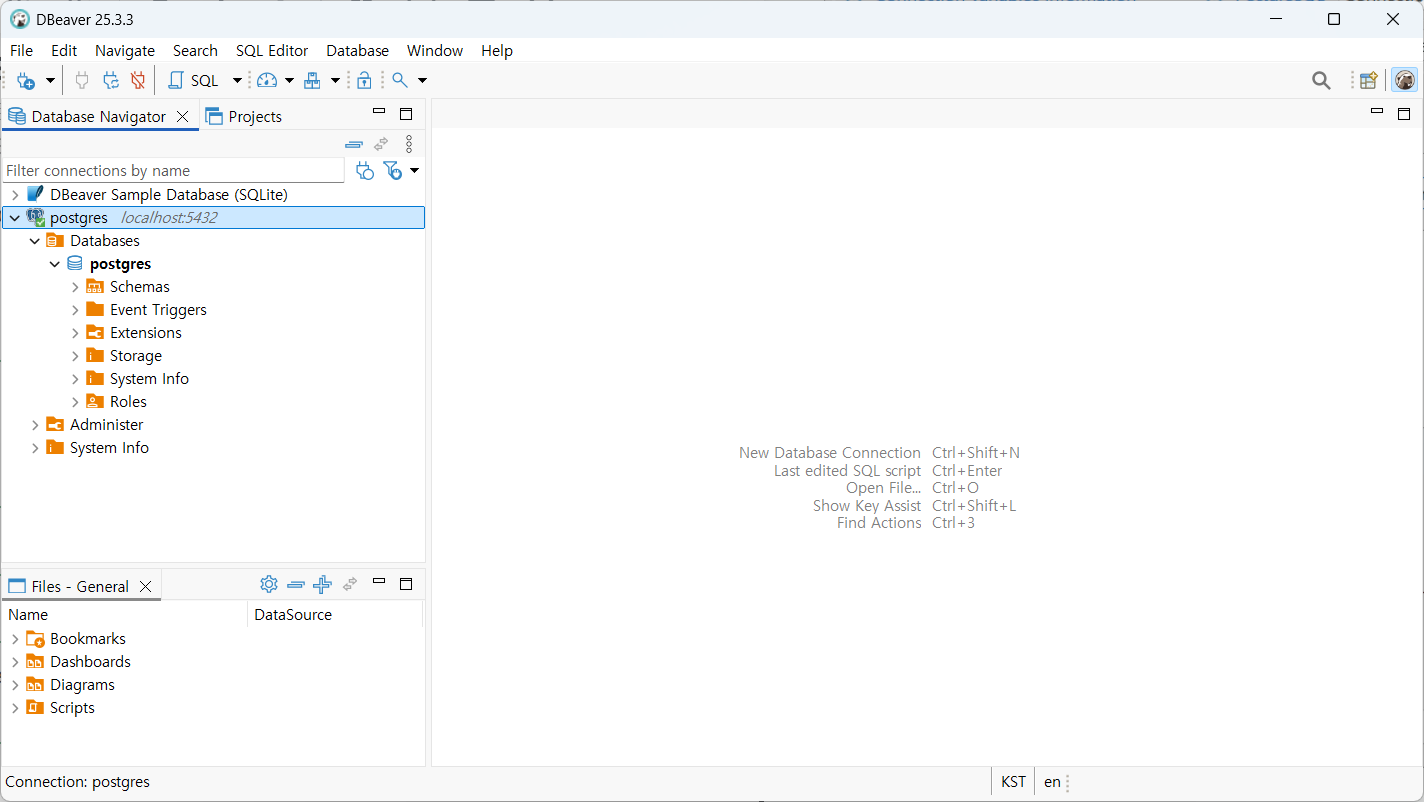
DBeaver
클라이언트 툴 중 하나
80여개의 DBMS에대한 접속과 관리를 지원
설치
연결
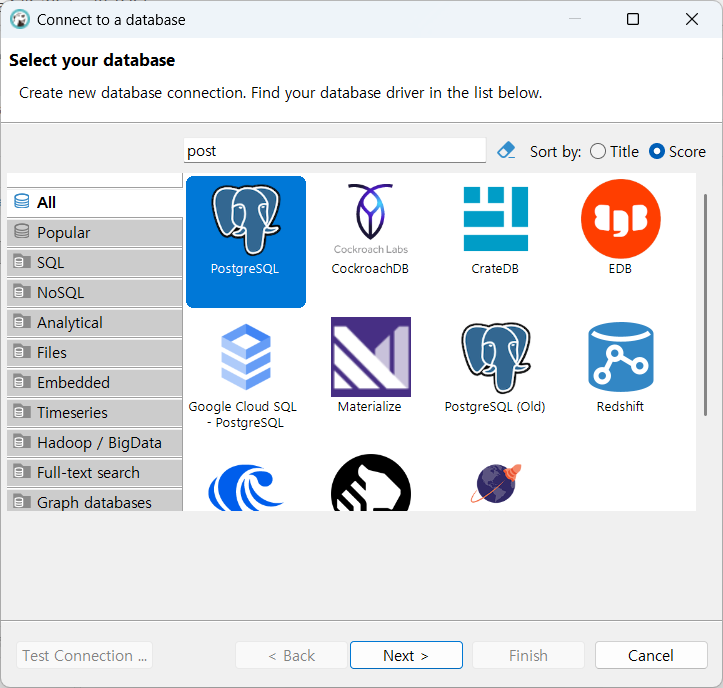
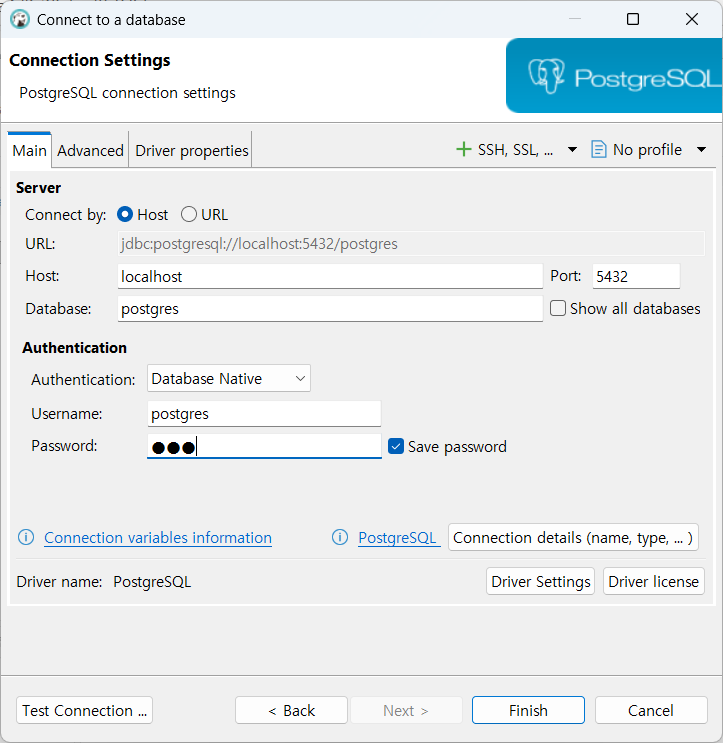
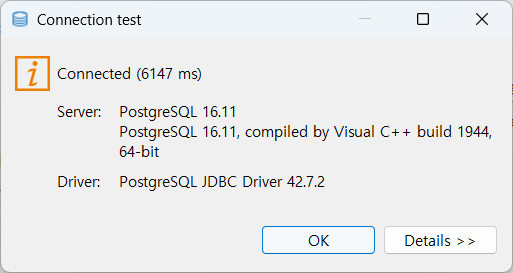
Test connection 하기
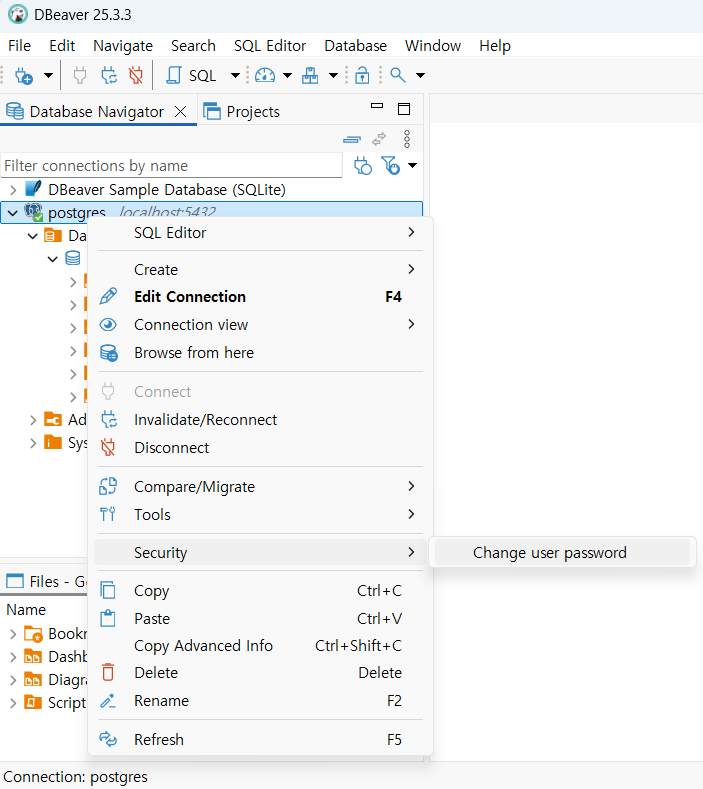
비밀번호 변경 방법
서버 돌아가는지 확인법
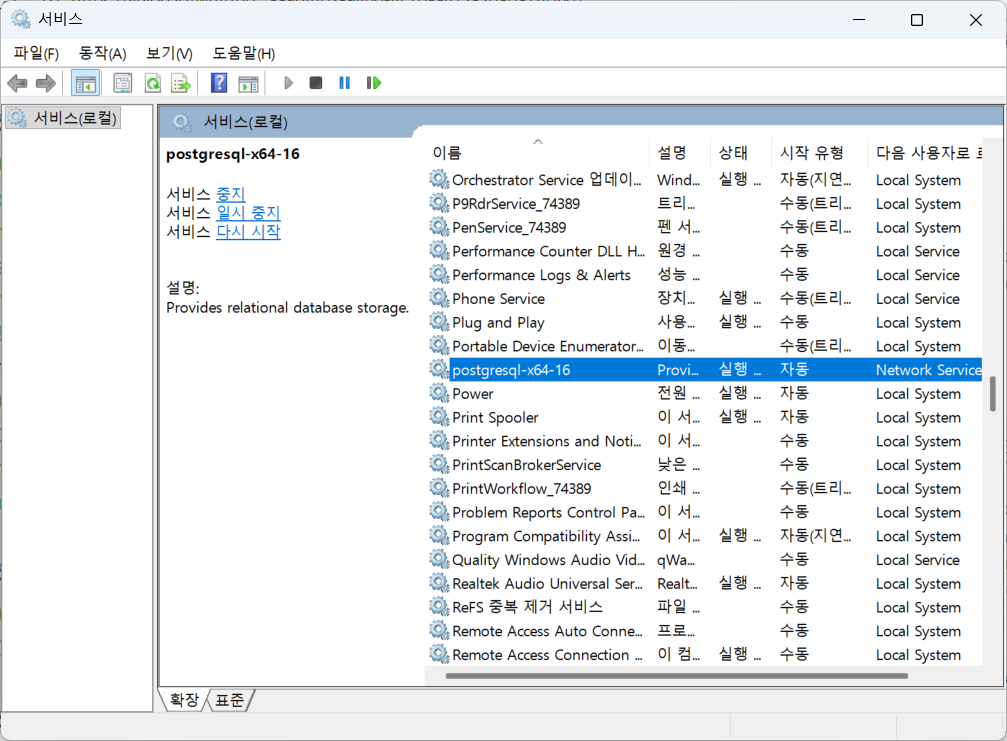
서비스 확인
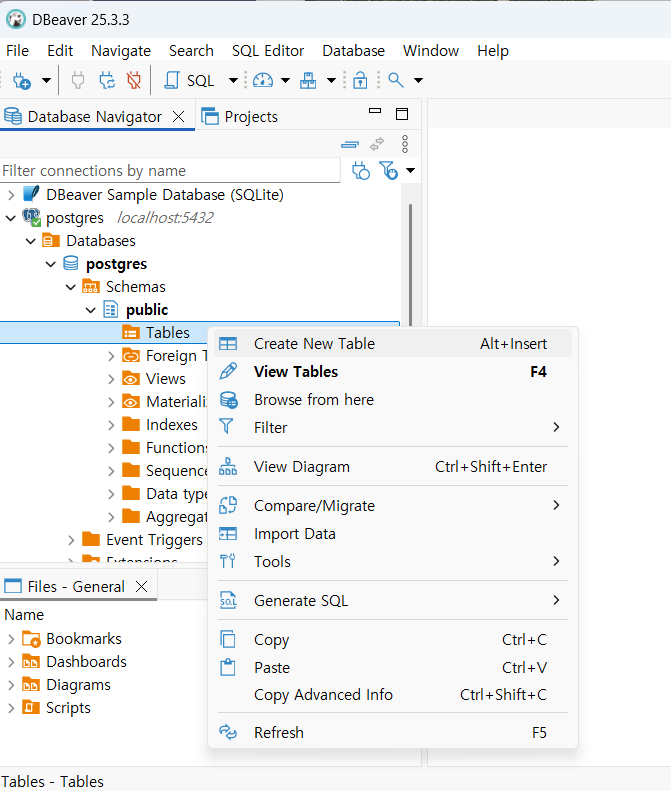
테이블 만들기
Column 만들기
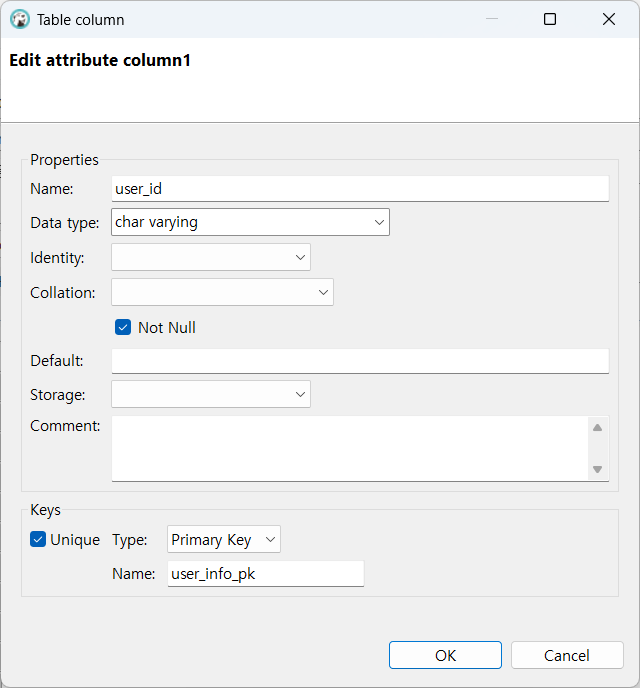
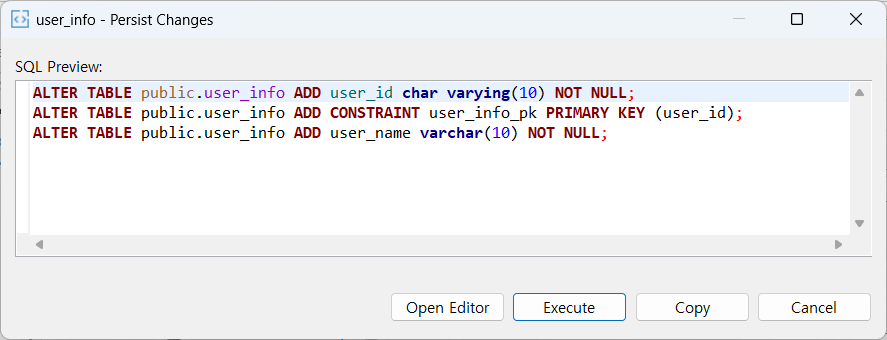
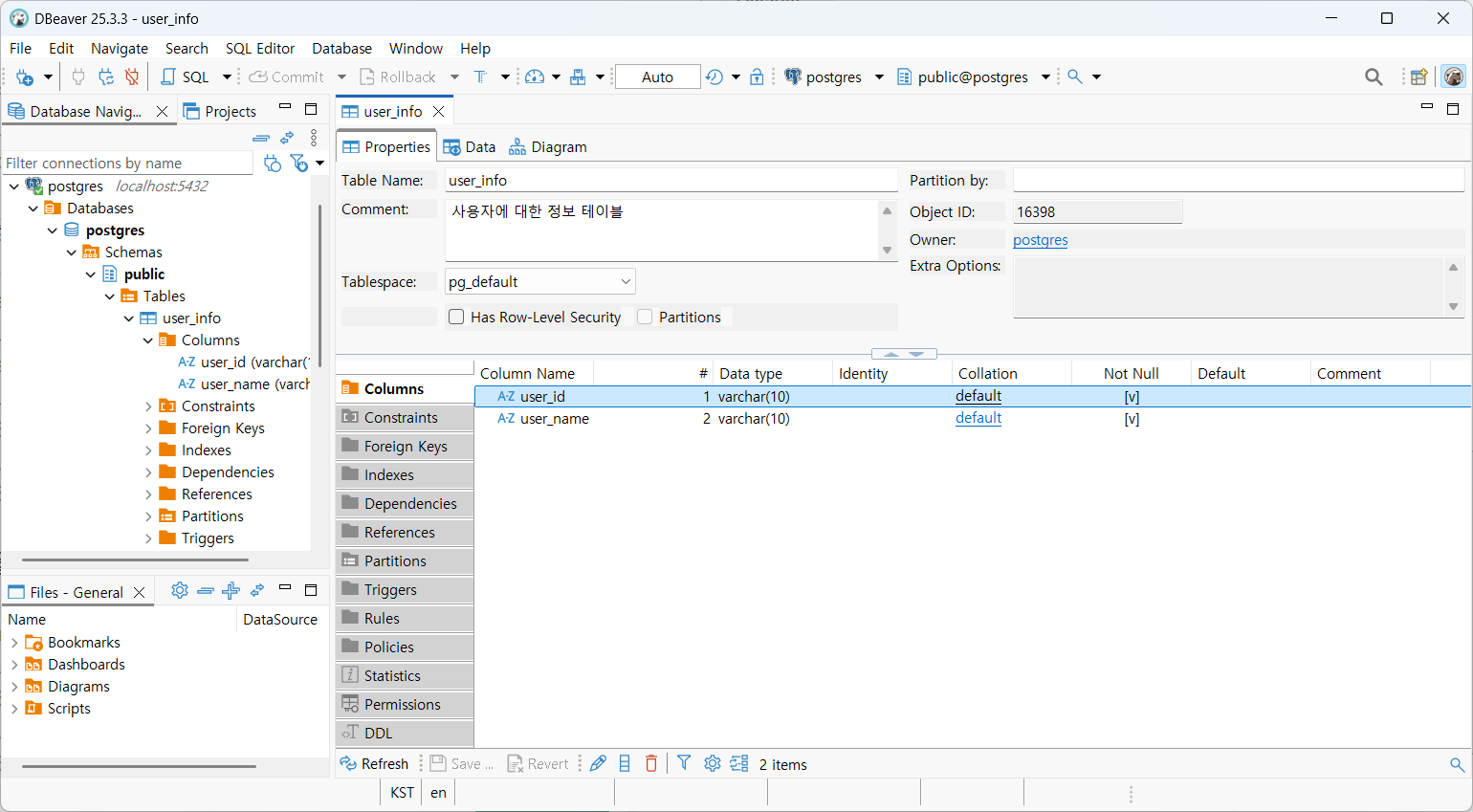
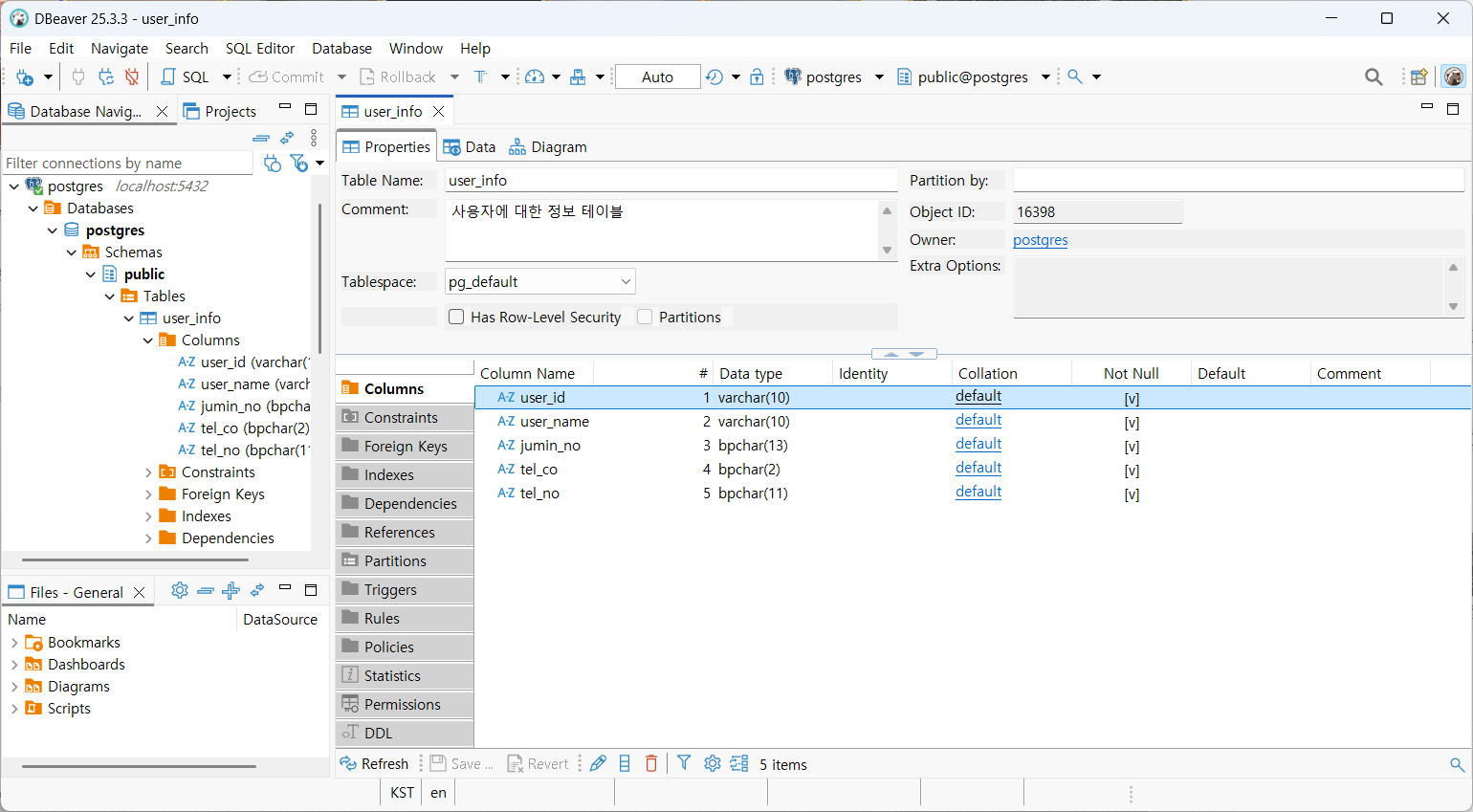
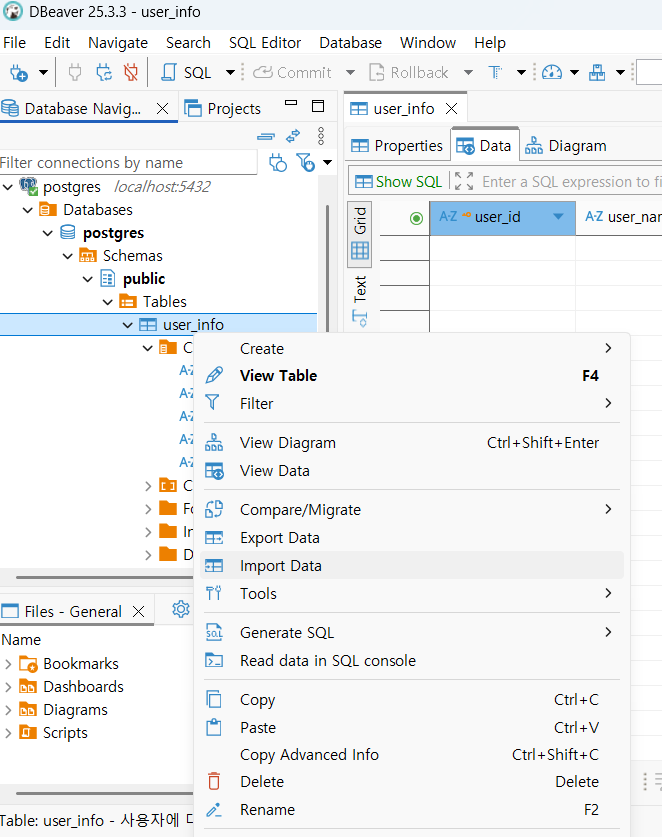
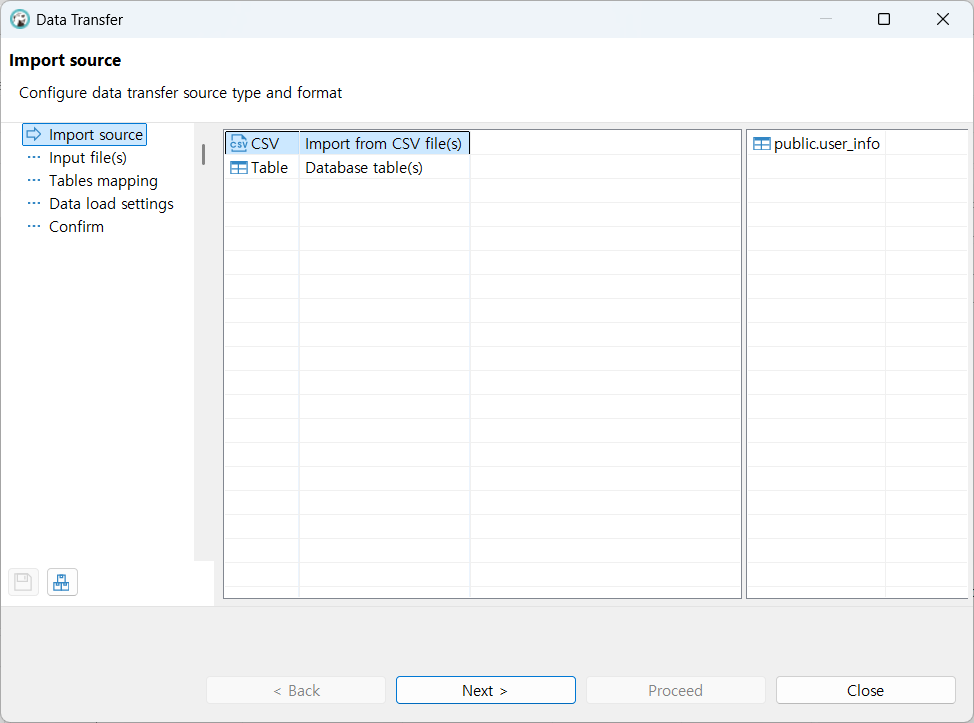
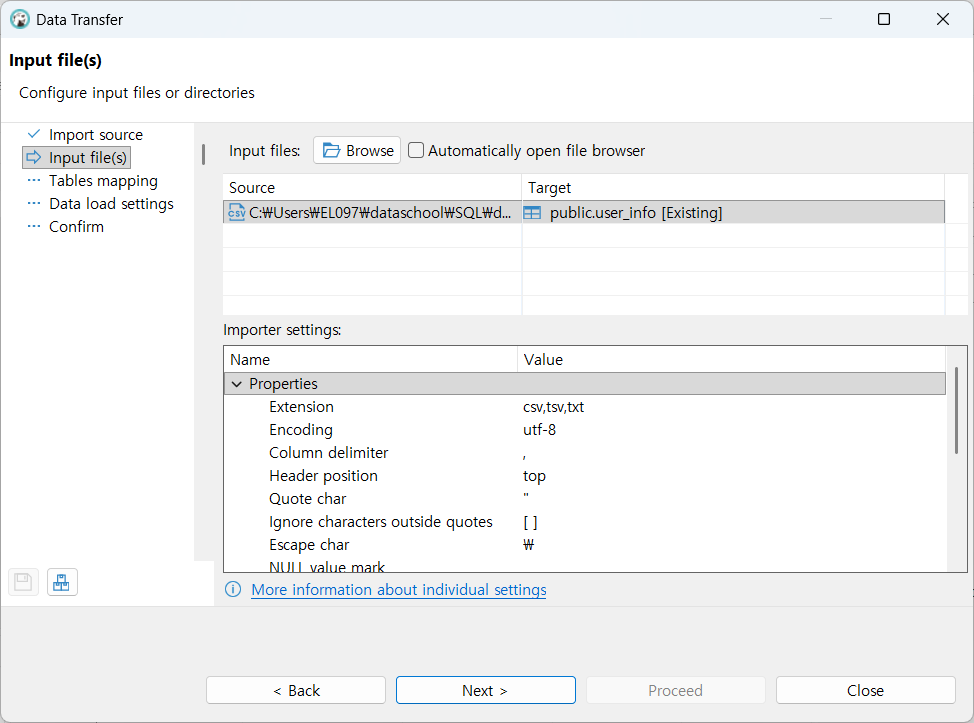
데이터 csv 임포트
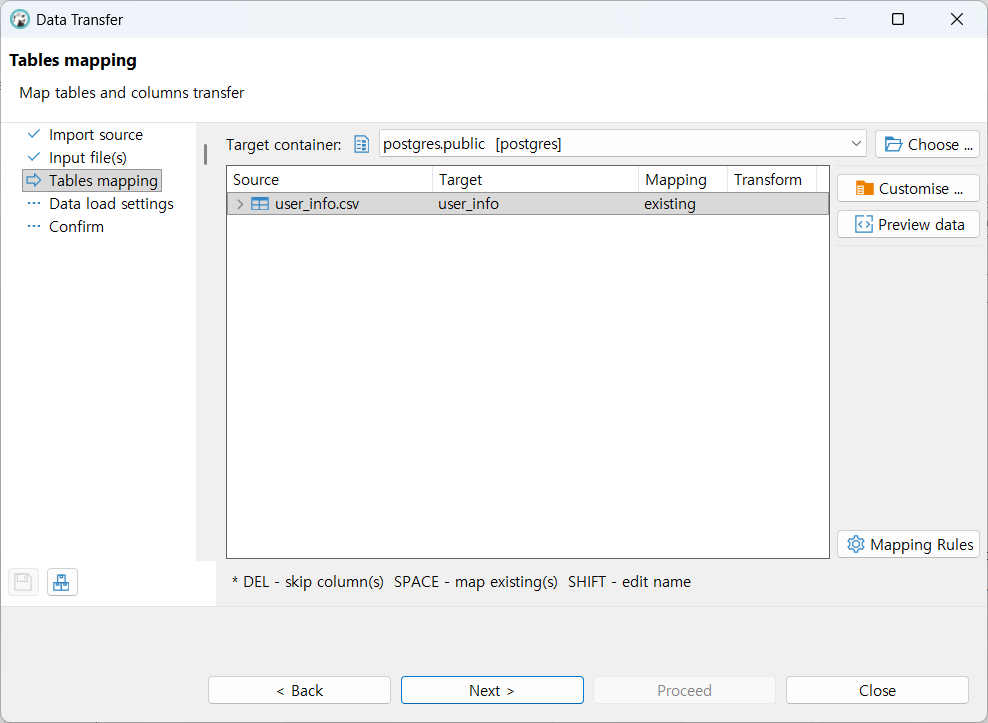
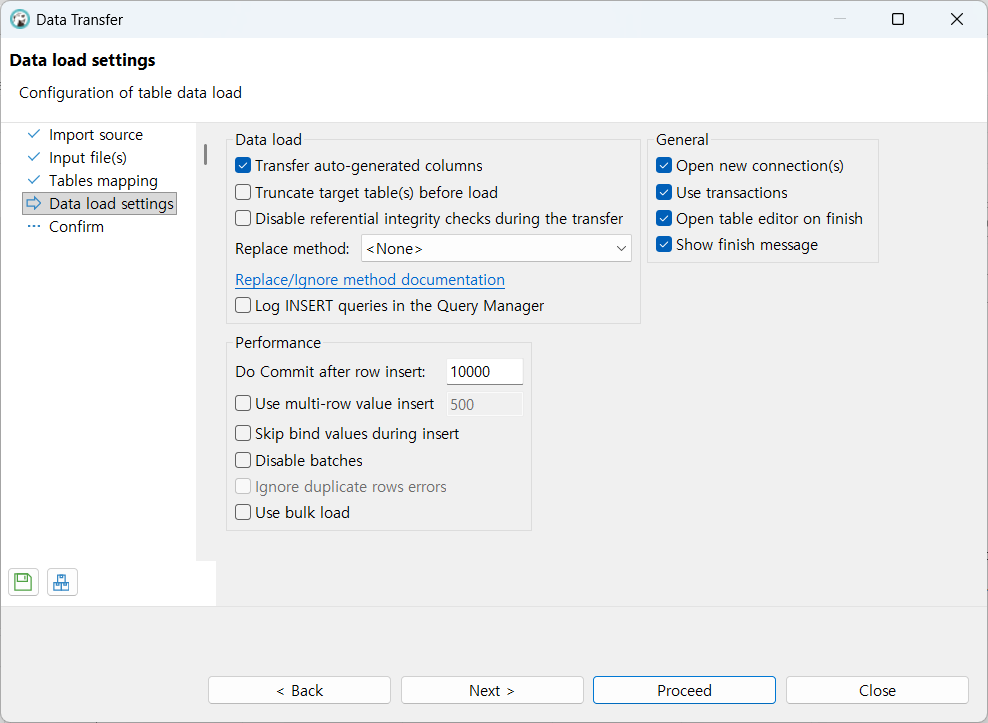
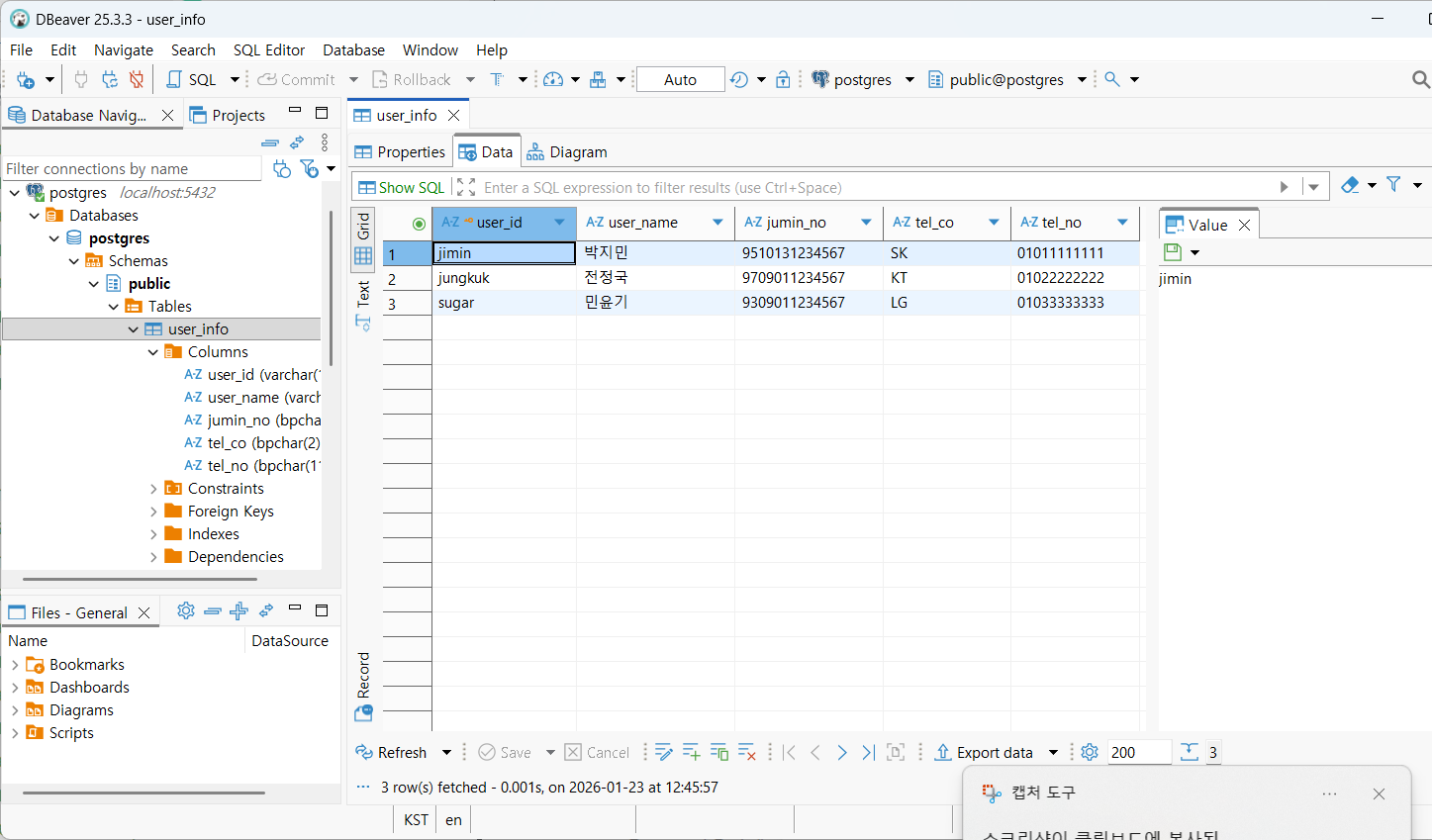
데이터베이스 기본
데이터형
- 문자열(string)
- 정수(integer)
- 실수(real)
- 날짜(Date)
- 불(boolean)
- 필드에 아무것도 저장하지 않을 경우
Null
정규화(normalization)
- 데이터베이스에서 중복을 제거하는 과정
- 데이터의 복제/중복을 피하는 것
인덱스
- 데이터베이스 테이블 상에서 데이터 검색 작업의 속도를 향상시키는 데이터 구조
시퀀스
- 테이블의 어떤 열을 위한 유일한 식별자를 생성하는데 쓰이는 유일 숫자 생성기
제약 조건, 기본키, 외래키
- 제약 조건은 관계 안에 있는 데이터가 모델 작성자의 데이터가 어떻게 저장되어야 하는지에 대한 시각과 일치하는지 확인하는 데 쓰임
- 기본키(PK): 레코드를 유일하게 만들어주는 하나 이상의 필드 값.보통 id라 하며, 시퀀스인 경우가 대부분
- 외래키(FK): 다른 테이블에 있는 유일한 레코드를 참조하는 데 쓰임
- ER 도표를 그릴 때, 테이블 사이의 연결은 보통 PK-FK 기반
데이터 타입
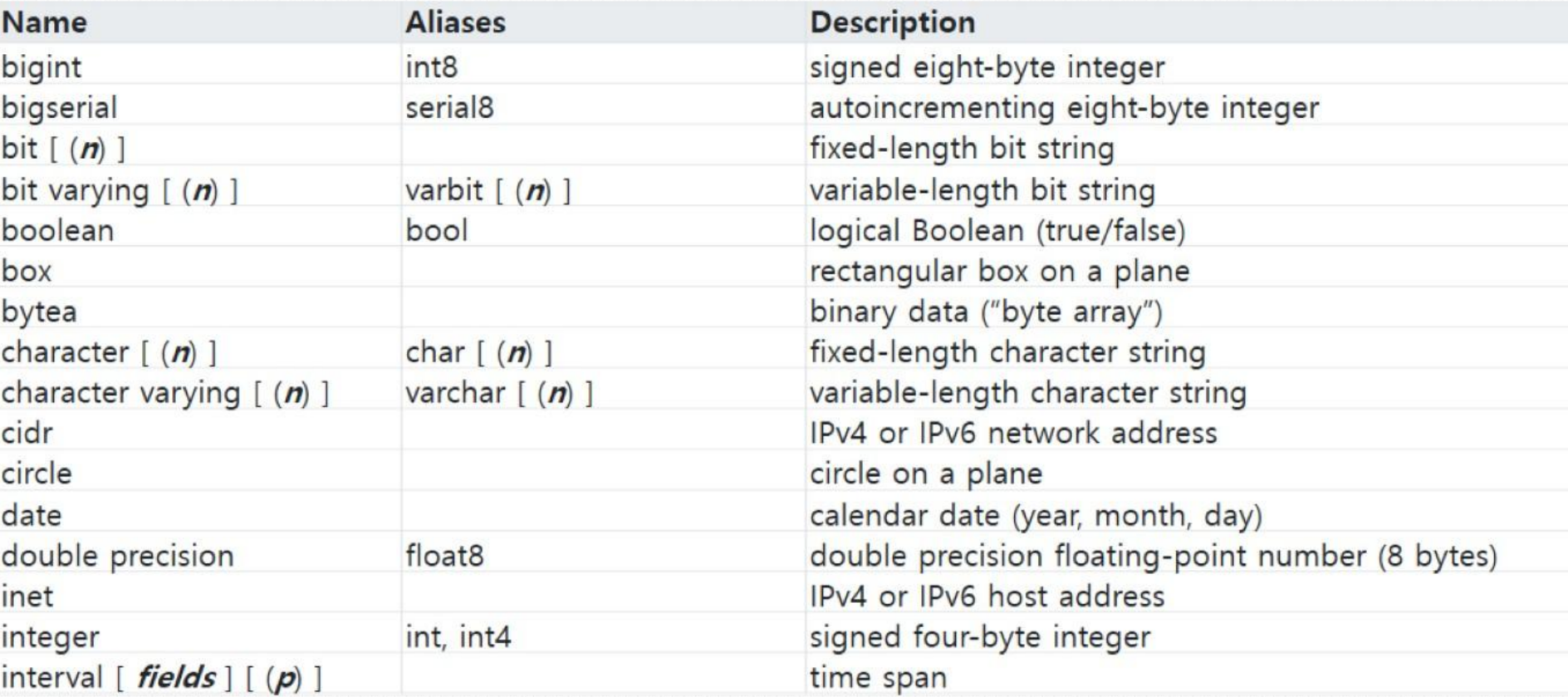

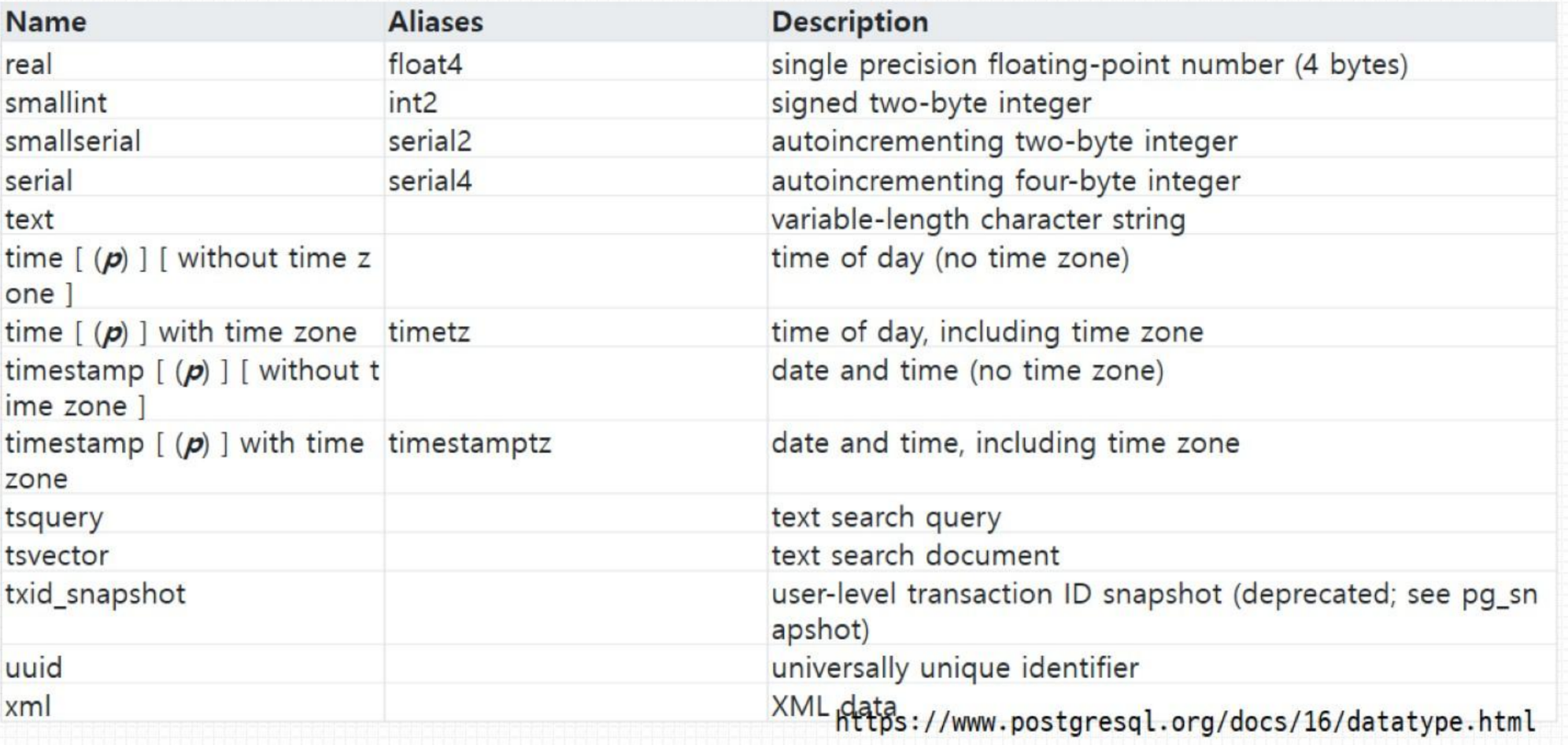
- DBeaver에서는
_가 붙은 데이터형은 리스트를 뜻한다 - char은 길이를 지정하지 않으면 1칸으로 인식할 수 있어서 지정해주는것이 좋다.
- bp의 뜻은 blank padding이다. 빈칸을 공백으로 채운다.
숫자형
| 이름 | 설명 | 예시 |
|---|---|---|
| INTEGER (또는 INT) | 4바이트 정수. 가장 일반적으로 사용되는 정수형. | 123456789 |
| SMALLINT | 2바이트 정수. 작은 범위의 정수 값에 적합. | 32767 |
| BIGINT | 8바이트 정수. 매우 큰 정수 값에 사용. | 987654321012345 |
| NUMERIC (또는 DECIMAL) | 정확한 소수점 처리가 필요한 금융 계산 등에 사용. | 1234.56 |
| REAL | 4바이트 단정밀도 부동 소수점. 근사치 값 저장. | 3.14159 |
| DOUBLE PRECISION | 8바이트 배정밀도 부동 소수점. REAL보다 더 정밀한 값 저장. | 1234.56789 |
날짜/ 시간형
| 이름 | 설명 | 예시 |
|---|---|---|
| DATE | 날짜만 저장. | '2025-10-14' |
| TIME | 시간만 저장. | '16:03:54' |
| TIMESTAMP | 날짜와 시간을 함께 저장. | '2025-10-14 16:03:54' |
| TIMESTAMPTZ | 날짜, 시간과 타임존을 함께 저장. | '2025-10-14 16:03:54+09' |
문자형
| 이름 | 설명 | 예시 |
|---|---|---|
| VARCHAR(n) | 가변 길이 문자열. 최대 길이 n을 지정해야 함. | 'Hello World' |
| TEXT | 가변 길이 문자열. 최대 길이 제한이 없으므로 긴 텍스트에 적합. | 'This is a very long text.' |
| CHAR(n) | 고정 길이 문자열. 지정된 길이보다 짧은 문자열을 저장하면 공백으로 채워짐. | 'A' |
이외 타입
- 논리형(Boolean)
- 화폐형(Monetary)
- 이산형(Binary)
- 배열(Arrays)
- JSON
데이터 무결성과 제약조건
데이터베이스의 필수적인 기능 요소로 데이터가 저장, 처리, 전송되는 모든 과정에서 변경되거나 손상되지 않고, 정확성과 일관성을 유지함을 보증하는 특성
- 데이터의 결함이 없음을 보장하는 것
PostgreSQL의 제약 조건
- NOT NULL
- Primary Key(고유성, NOT NULL)
- Foreign Key(참조 무결성)
- Check
- Unique
- Exclude
- Unique보다는 복잡한 제약조건. 칼럼의 조합이 유일해야한다는 조건(실무에서도 당연히 씀)
- ex) 예약 시스템에서 특정 회의실이 특정 시간에 중복 예약되는 것을 막음
Default: 제약조건이 아닌 옵션 중 하나. Date값에서 now 함수를 부르게한다던지
외래키 지정하기
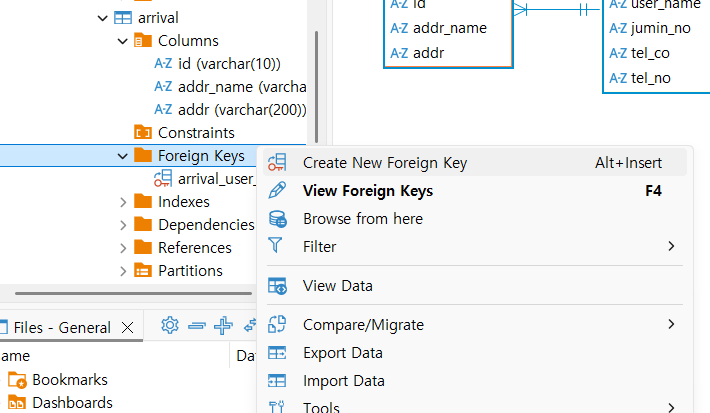
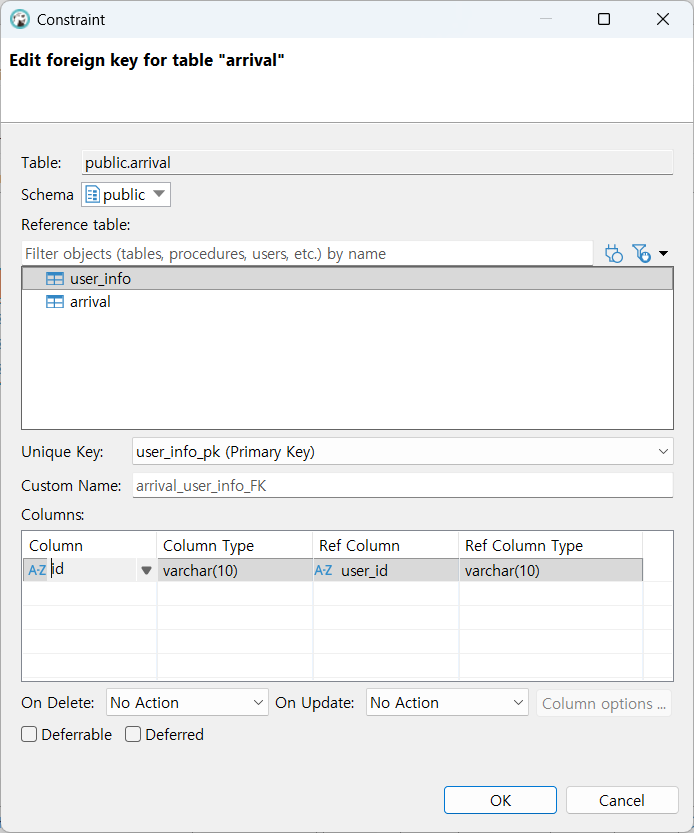
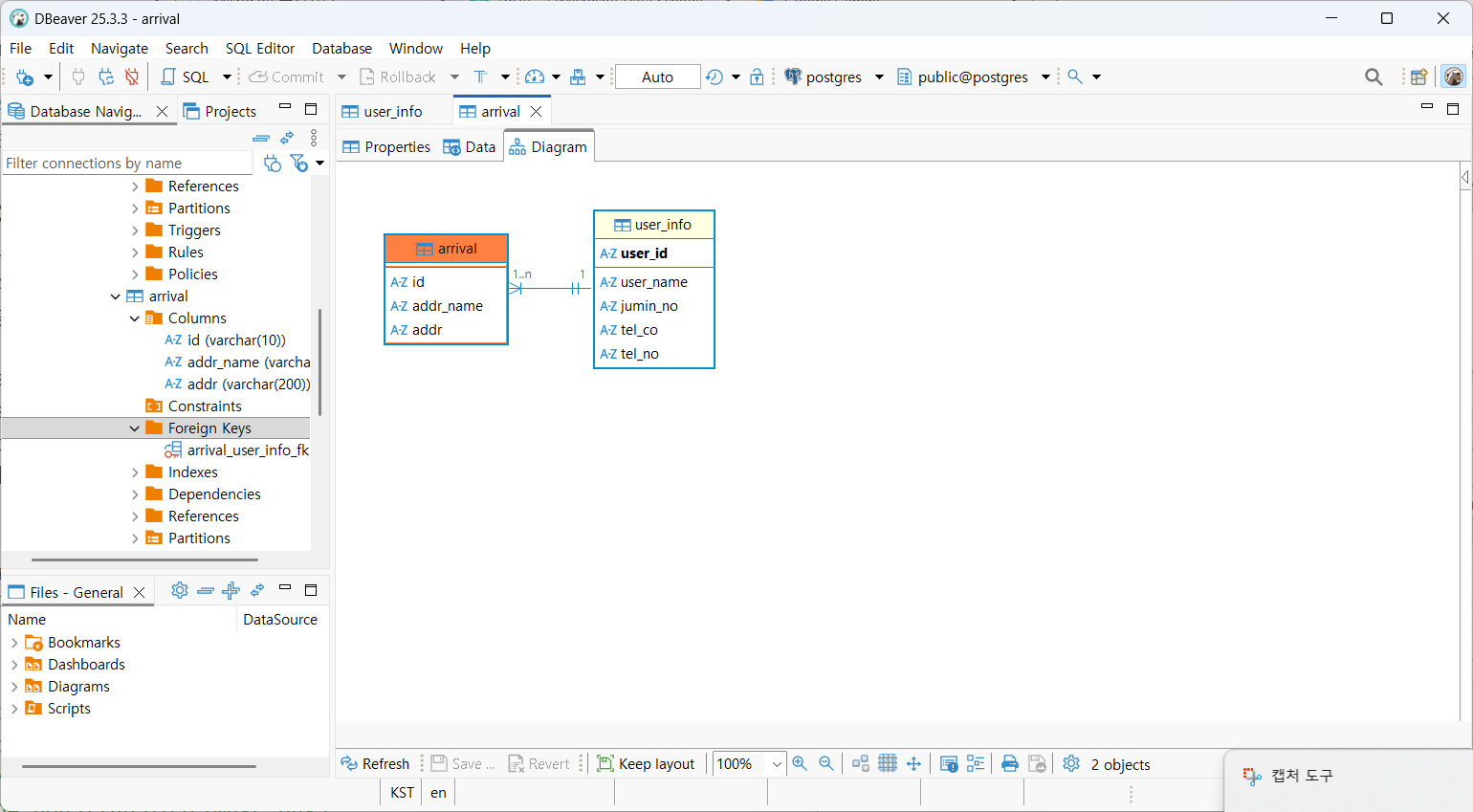
notation 조정하기
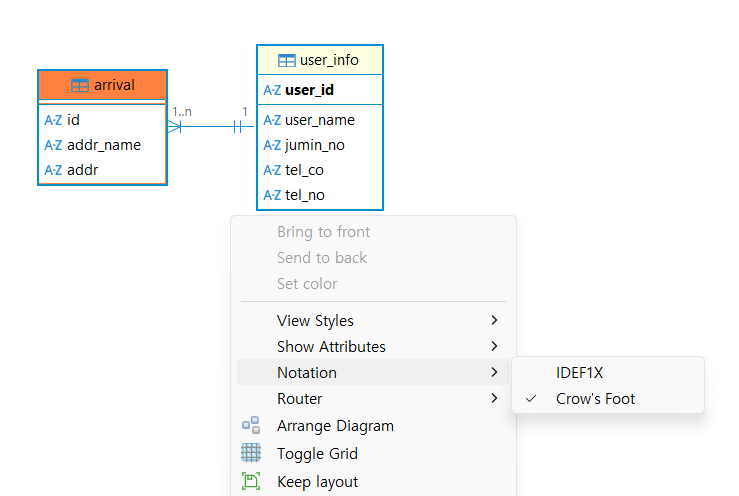
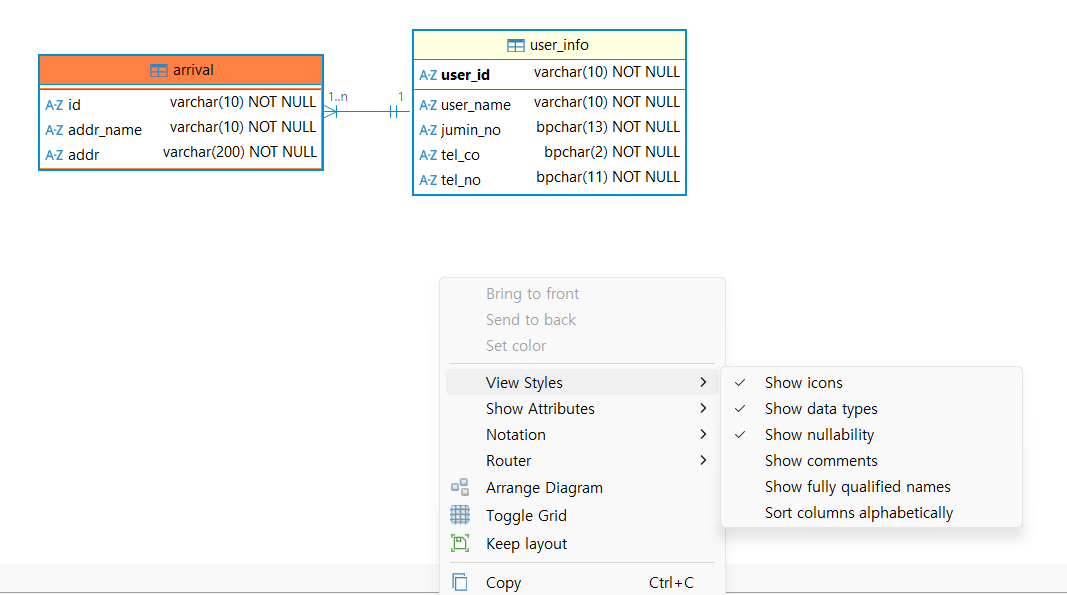
View Styles 조정하기
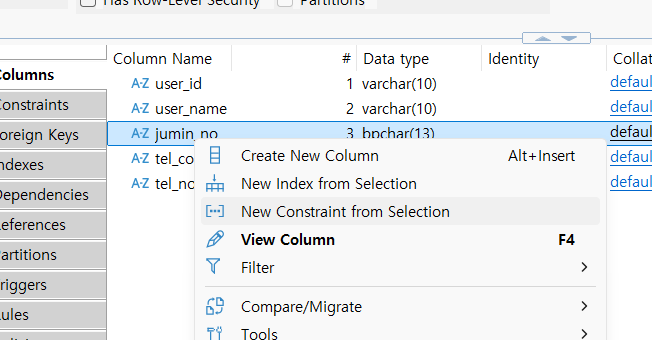
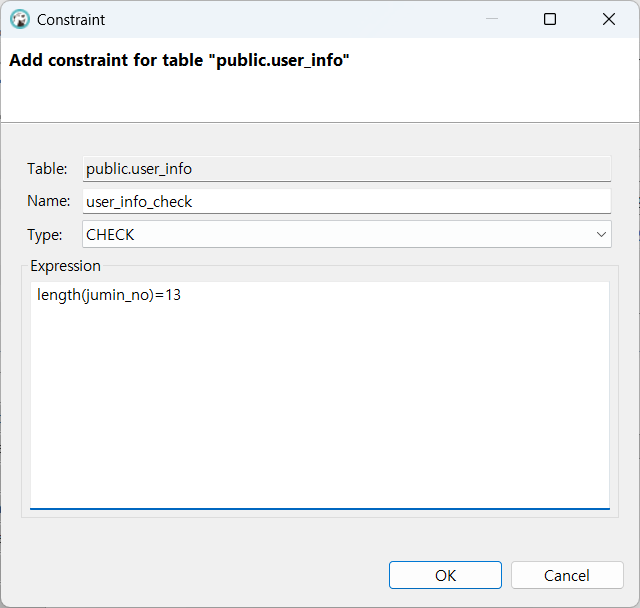
제약 조건 생성하기
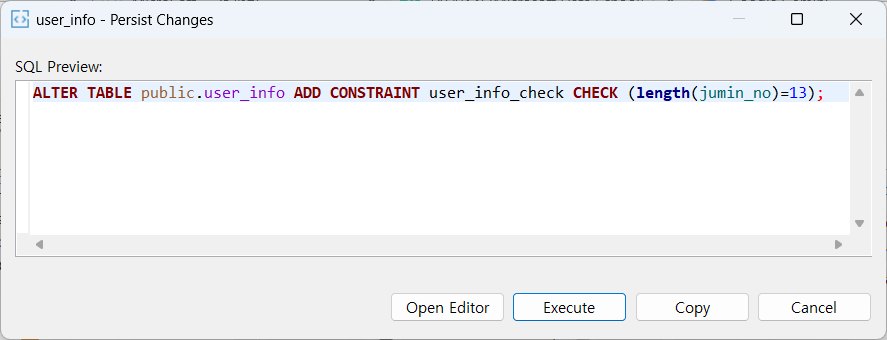
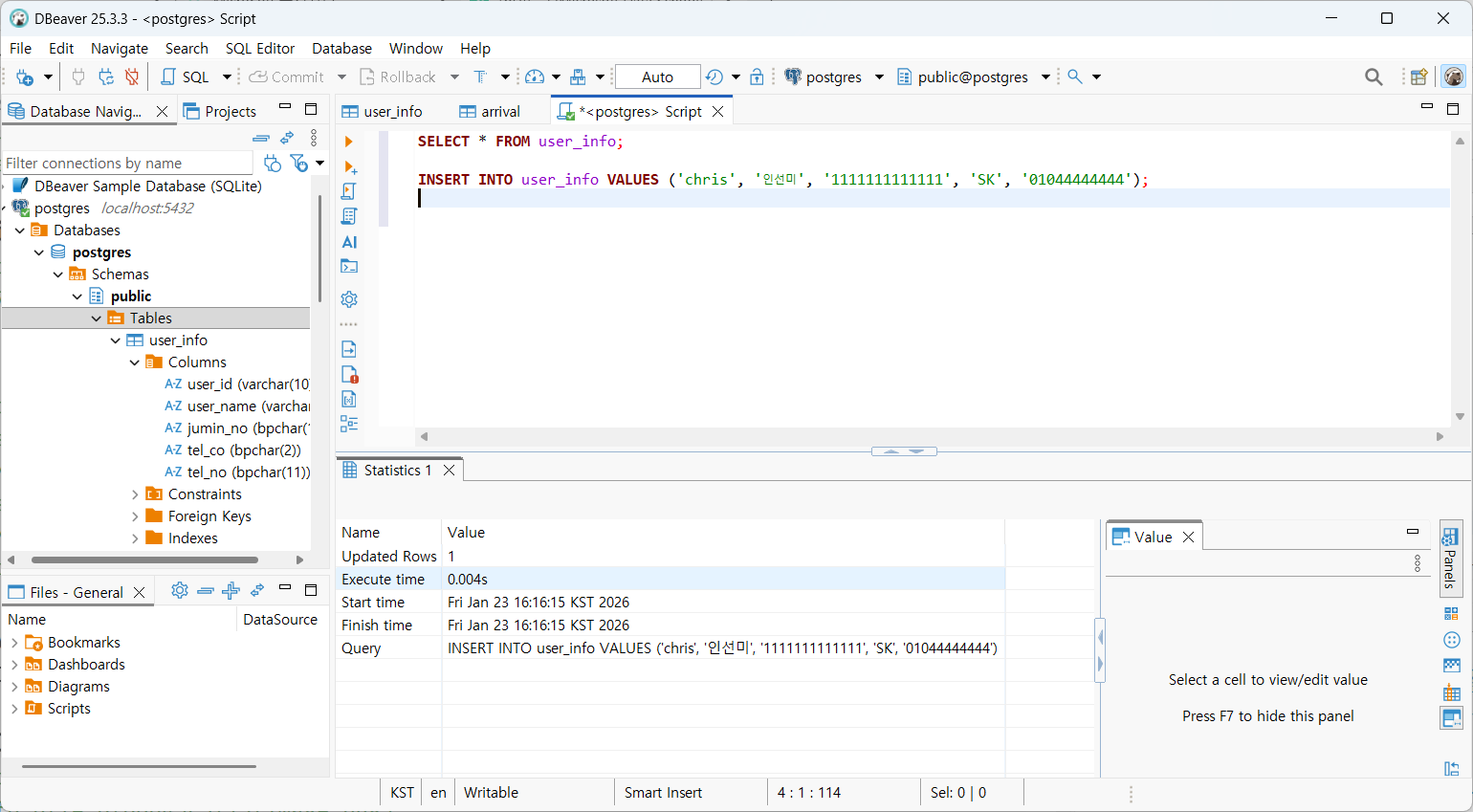
INSERT
- 테이블에 새 데이터 삽입
SQL Script
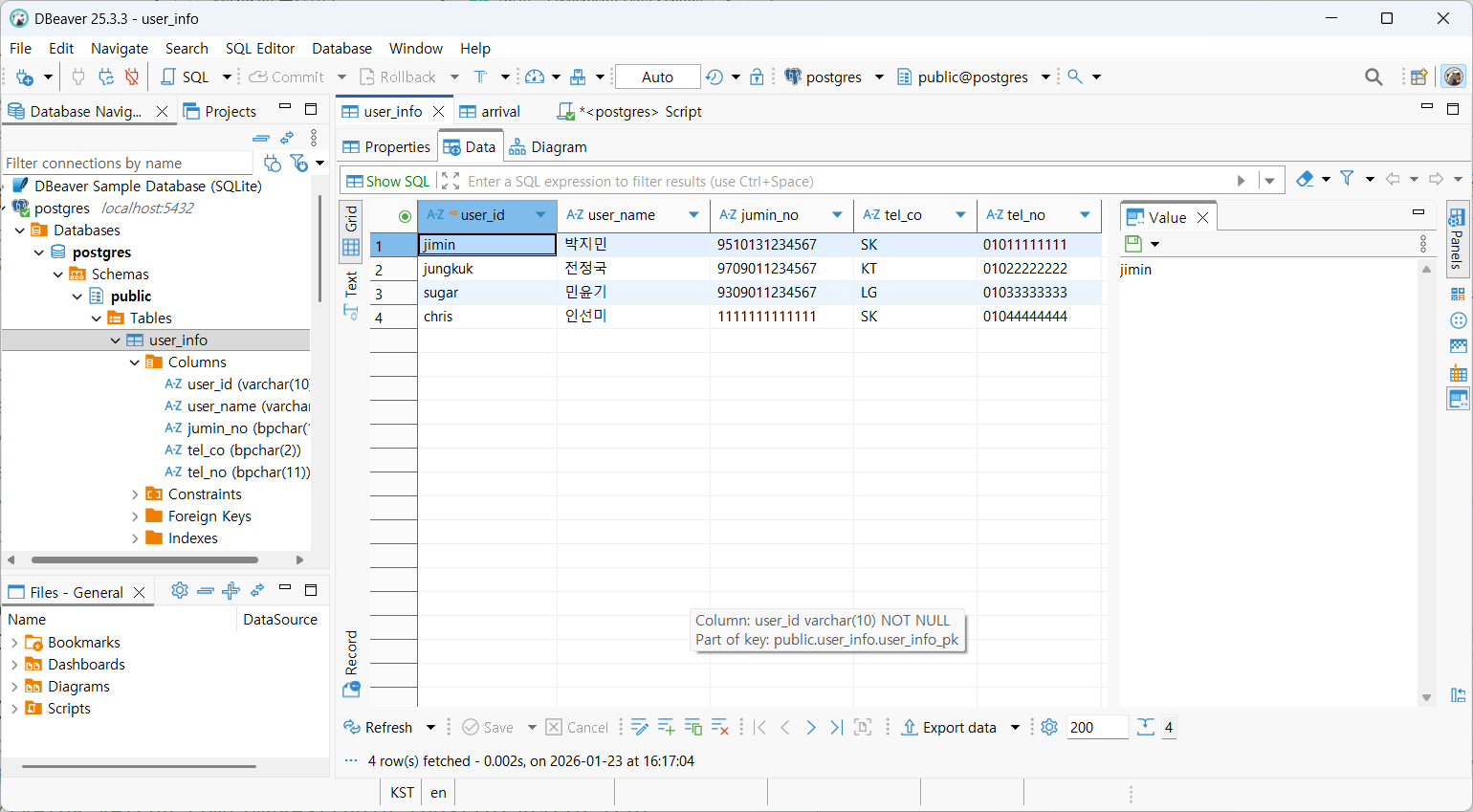
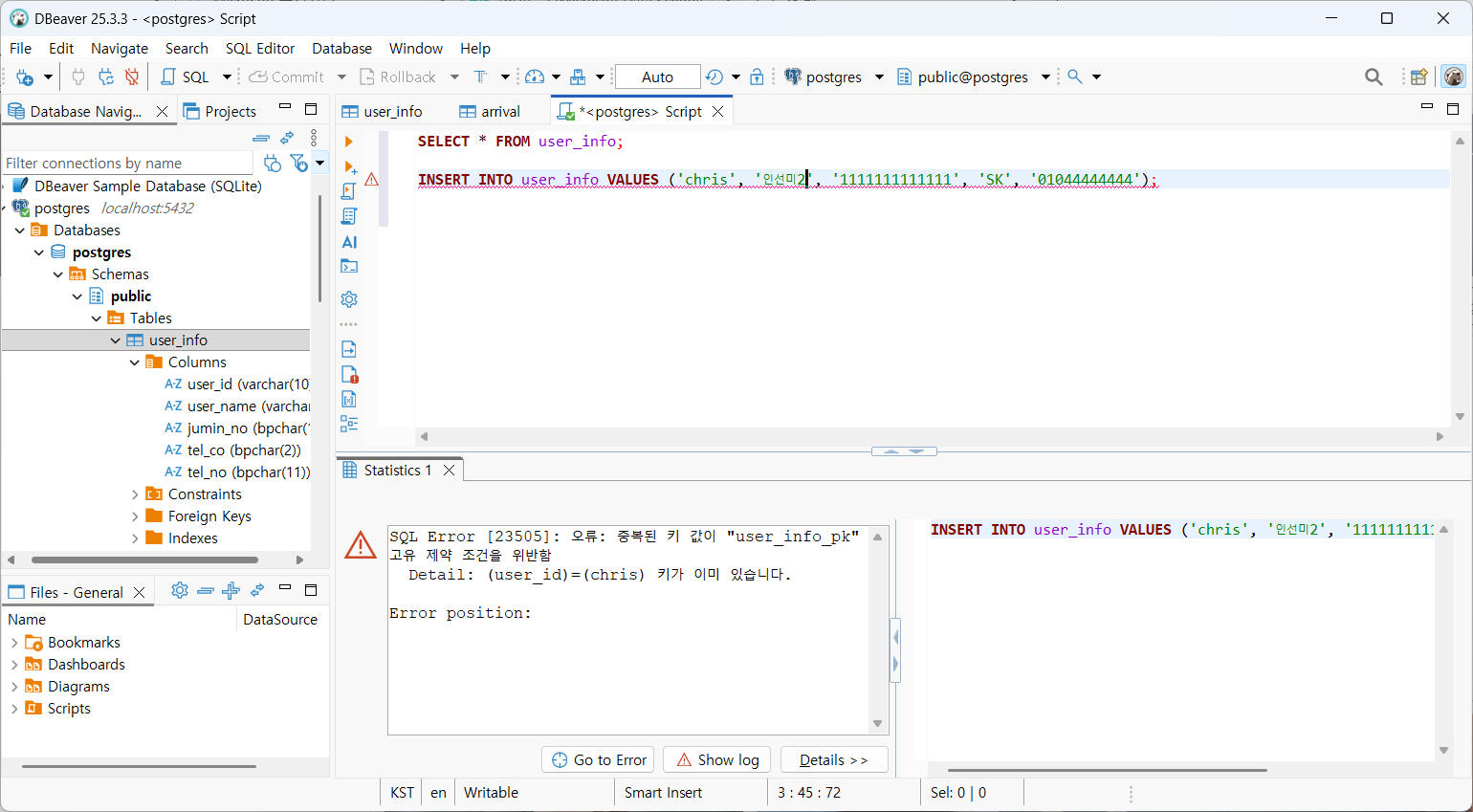
→ PK 제약 위반(Unique)
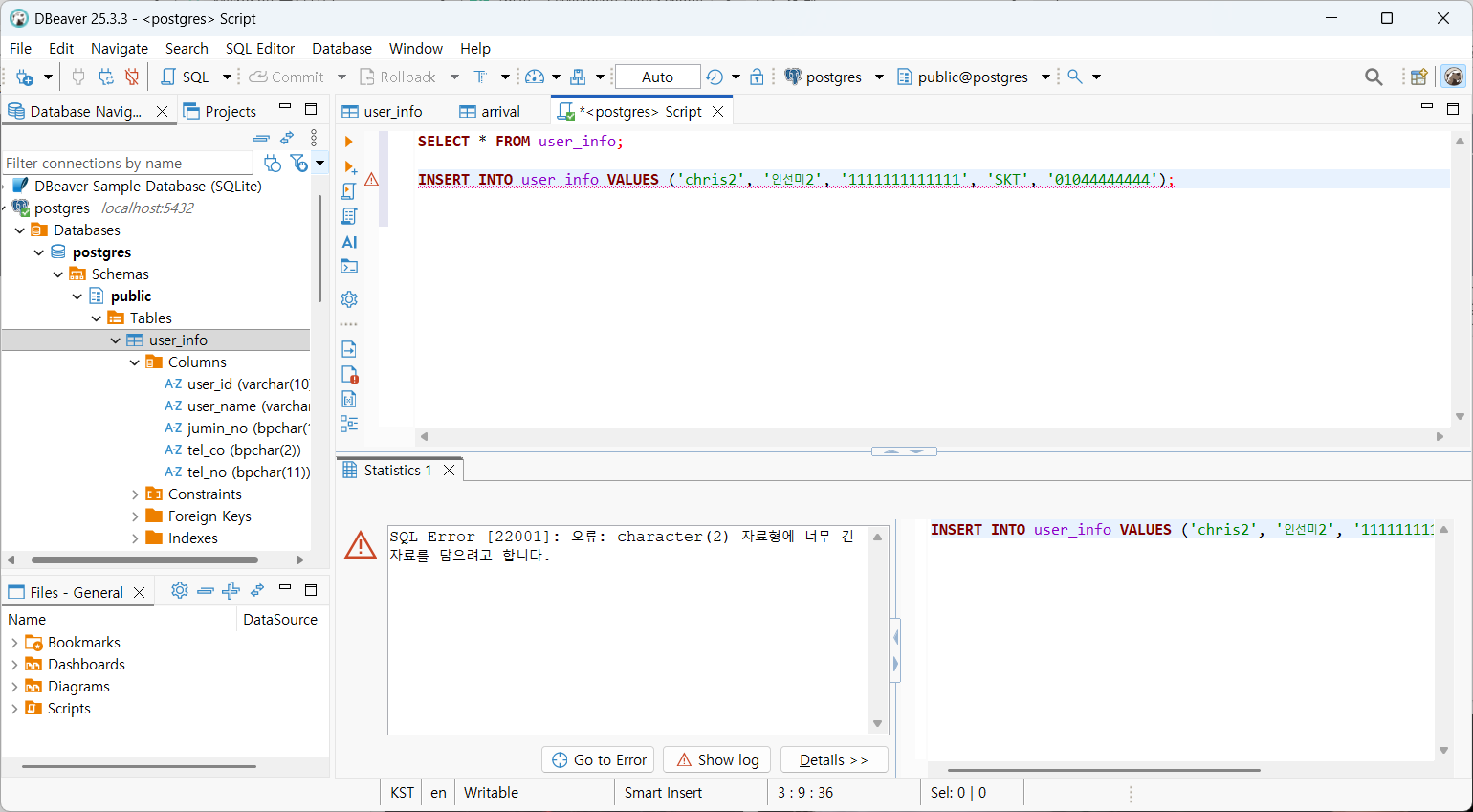
→ char(2)인데 char(3)값을 넣어 값 자료형 위반
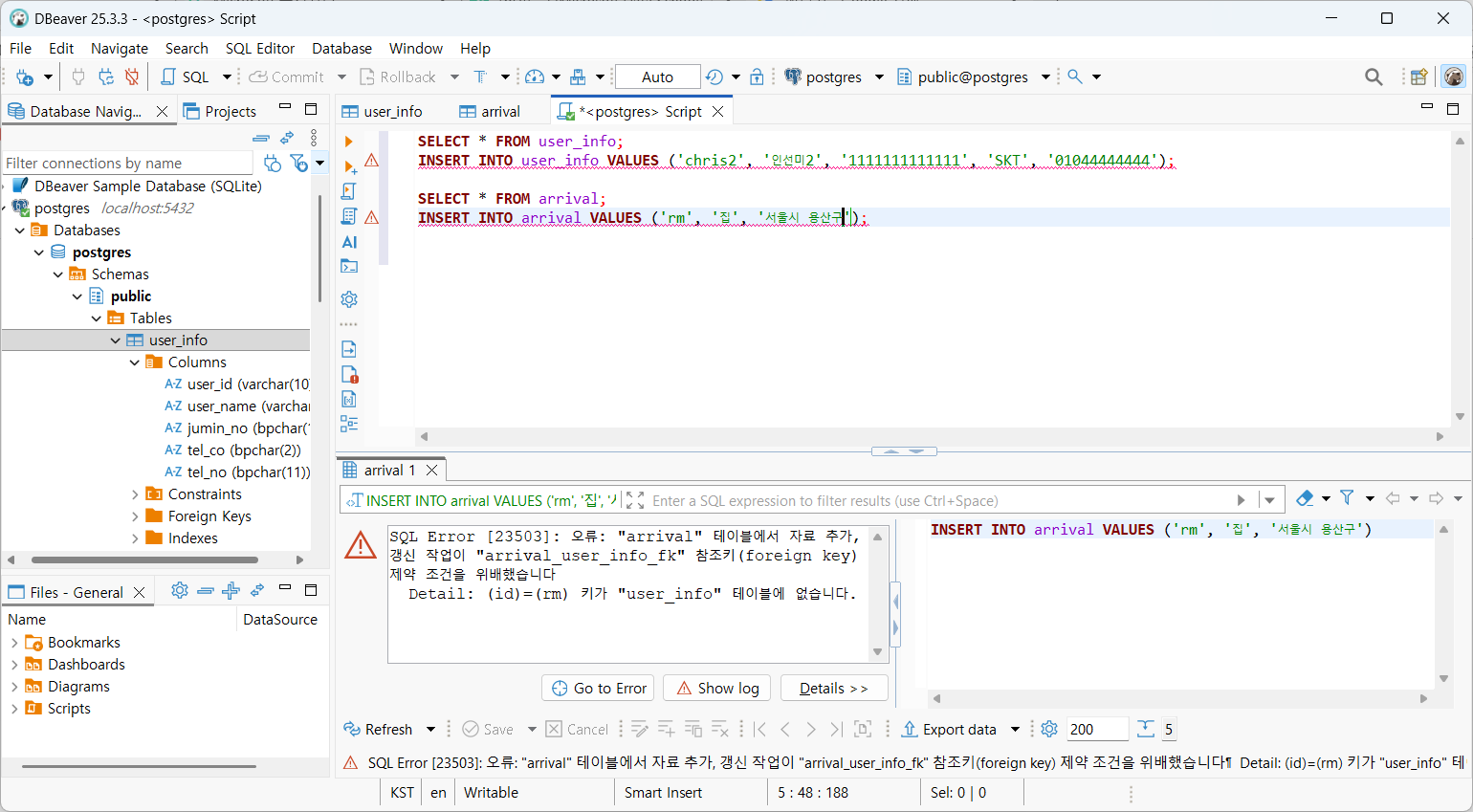
→ FK 위반(해당하는 PK 없음)
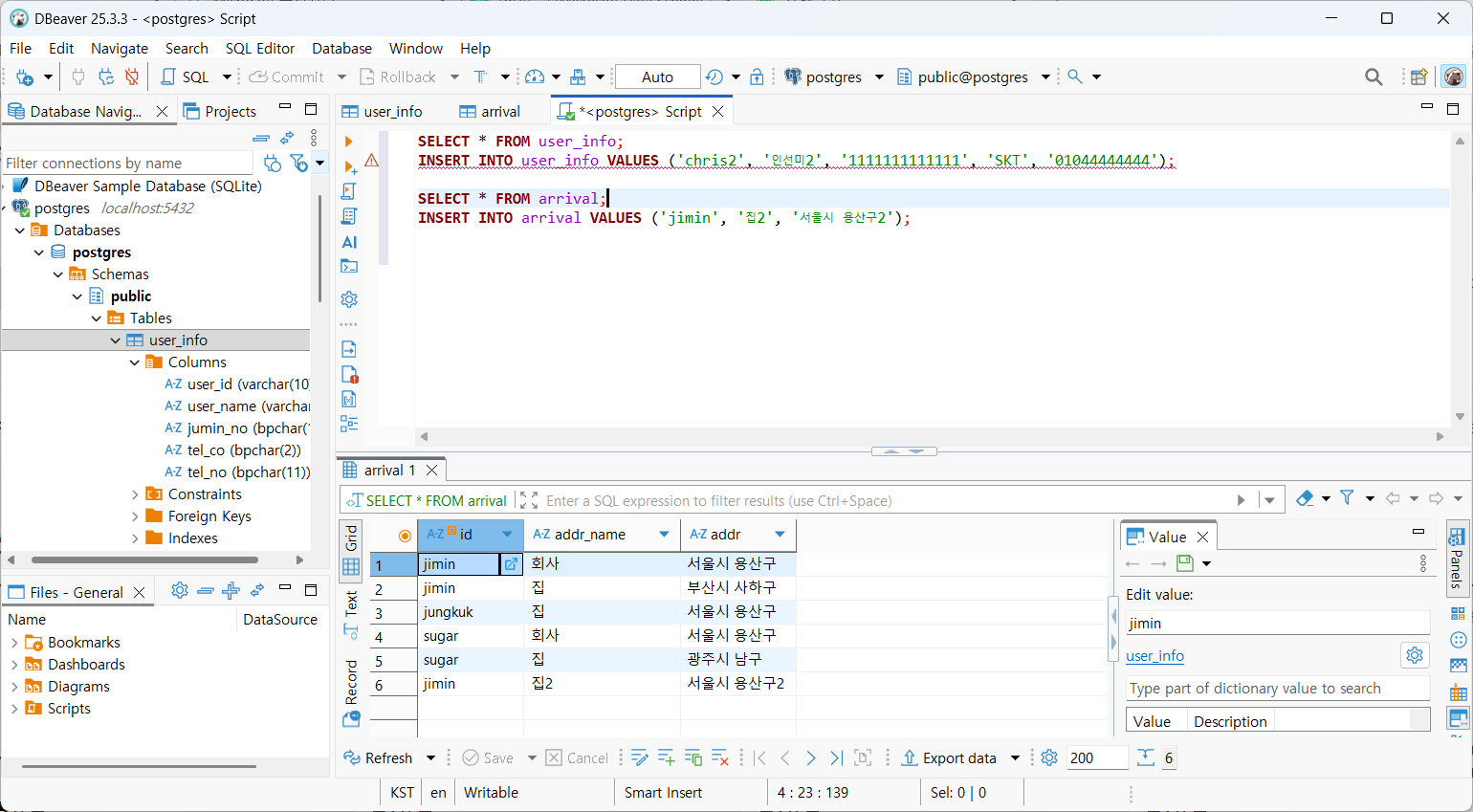
데이터셋 활용
https://github.com/jiminxchris/dataproject

CREATE TABLE IF NOT EXISTS practice.product_info (
serial_no char(8) PRIMARY KEY ,
model_id char(2) NOT NULL,
line_id char(1) NOT NULL,
prod_start_date date NOT NULL,
target_weight int NOT NULL,
process_step1 smallint,
process_step2 smallint,
factory_code char(1) NOT NULL
);
CREATE TABLE IF NOT EXISTS practice.delivery_log (
serial_no CHAR(8),
invoice_no CHAR(7) NOT NULL,
client_name varchar(20) NOT NULL,
due_date date NOT NULL,
shipped_date date NOT NULL,
destination varchar(10) NOT NULL,
FOREIGN KEY (serial_no) REFERENCES practice.product_info(serial_no)
);
CREATE TABLE IF NOT EXISTS practice.factory_data (
line_id char(1) NOT NULL,
check_date date NOT NULL,
temp int NOT NULL,
humid int NOT NULL,
op_hours int NOT NULL,
voltage int NOT null
);
CREATE TABLE IF NOT EXISTS practice.master_code(
column_nm varchar(15),
type varchar(10),
code varchar(10),
code_desc varchar(20)
);
CREATE TABLE IF NOT EXISTS practice.qa_result(
serial_no char(8) NOT NULL,
qa_date date NOT NULL,
net_weight int NOT NULL,
defect_yn char(2) NOT NULL,
grade_level int NOT NULL,
qa_status char(1) NOT NULL,
FOREIGN KEY (serial_no) REFERENCES practice.product_info(serial_no)
);
CREATE TABLE IF NOT EXISTS practice.sensor_log(
serial_no char(8) NOT NULL,
log_date date NOT NULL,
current_weight int NOT NULL,
cpu_temp numeric(3, 1) NOT NULL,
fan_rpm int NOT NULL,
power_usage int NOT NULL,
error_yn char(1) NOT NULL,
remarks text,
FOREIGN KEY (serial_no) REFERENCES practice.product_info(serial_no)
);
CREATE TABLE IF NOT EXISTS practice.unit(
column_nm varchar(15),
unit varchar(10)
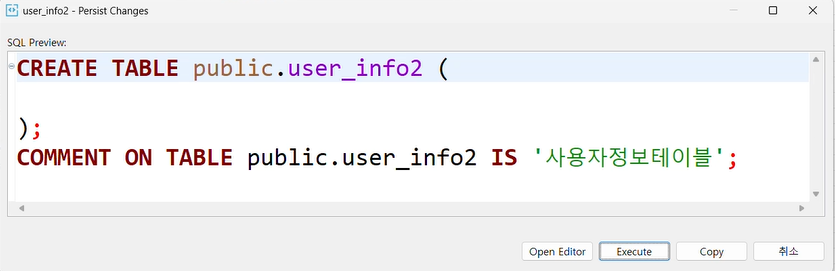
);코멘트 넣기
COMMENT ON COLUMN [스키마].[테이블].[칼럼] IS '설명';
