[MicrosoftDataSchool] 31일차 - Azure Cosmos DB, Microsoft Foundry, RAG
Microsoft Data School 3기

Azure Cosmos DB
AI 애플리케이션 및 에이전트를 위한 완전 관리형 NoSQL 및 벡터 데이터베이스
- SQL과 유사한 쿼리 언어
- 턴키 방식의 전역 배포
SAL
다중 지역 구성 시 업계 최고 수준의 가용성 보장
P99
읽기 쓰기 모두 99번째 백분위수에서 한 자리 밀리초 속도
데이터처리
대량의 JSON 및 벡터 데이터 처리에 최적화된 아키텍처
AI에이전트
벡터 데이터베이스 기능을 포함하여 RAG(검색 증강 생성) 아키텍처 지원
실시간 워크로드
고성능 분산 처리가 필요한 시나리오에 이상적
유연성
데이터 구조가 자주 변하는 IoT, 전자 상거래 플랫폼 최적화
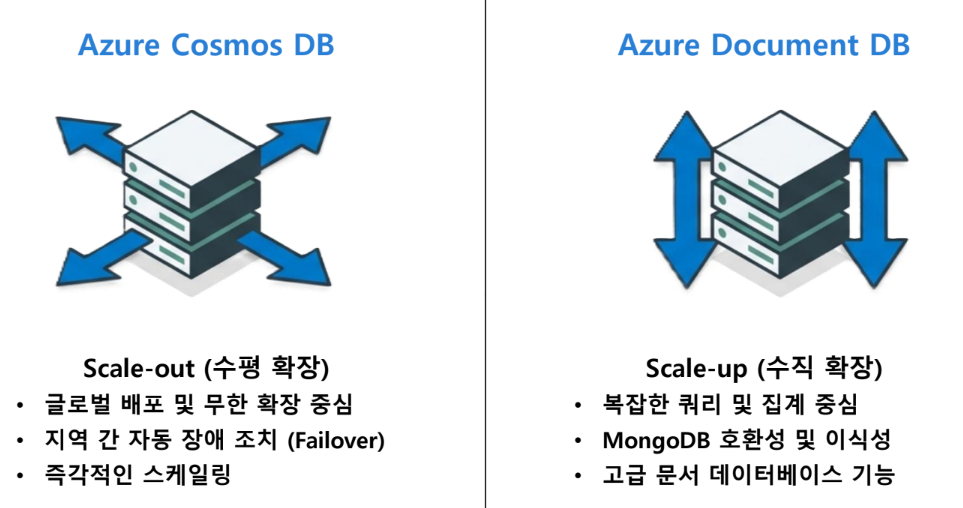
턴키(Turnkey) 전역 배포 시스템
1. 수평적 확장
여러 지역에 걸쳐 수평으로 확장하도록 설계
2. 자동화된 관리
성능 및 스토리지 요구 사항에 맞춰 분할 및 크기 조정을 자동으로 처리
3. 사용자 경험
전 세계 어디서나 데이터에 대한 짧은 대기 시간 액세스 보장
워크로드에 따른 유연한 비용 관리 모델
RU/s (요청 단위) 모델
처리량을 미리 예측하고 예약
지속적이고 예측 가능한 트래픽에 최적
서버리스
처리량을 예측할 수 없다면 선택
사용한 만큼만 지출
간헐적이거나 예측 불가능한 트래픽에 최적
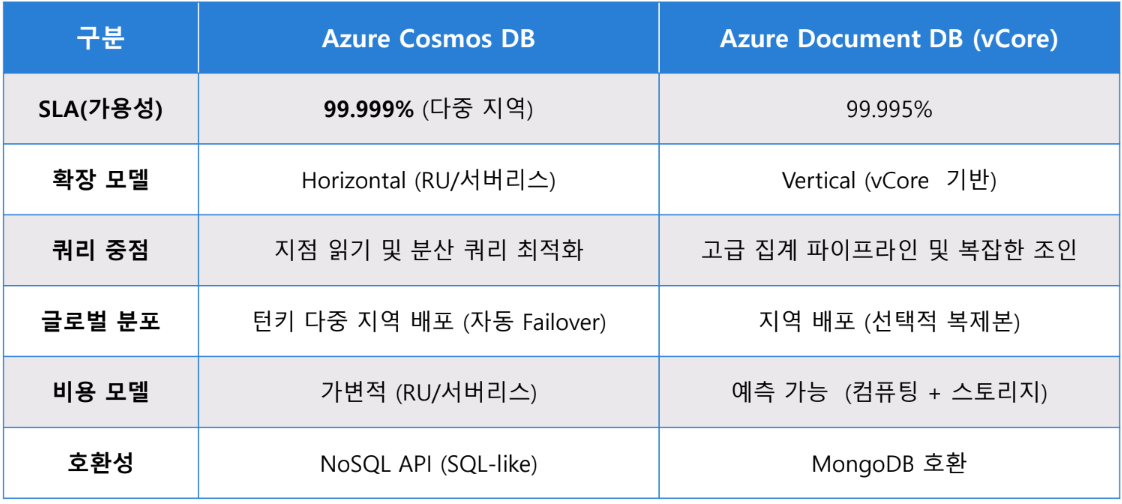
Azure Cosmos DB vs Azure Document DB
Microsoft Foundry
엔터프라이즈 AI 운영, 모델작성, 애플리케이션 개발을 위한 통합 Azure PaaS 솔루션
New 버전
- 다중 에이전트 오케스트레이션: C# 및 Python SDK를 사용한 고급 자동화 및 협업 워크플로
- 고급 메모리 기능: 상호 작용 간 문맥 유지 및 사용자 맞춤형 환경 제공
- 확장된 도구: 1400개 이상의 도구 연결 및 M365/Teams/BizChat 통합 지원
- 지식 통합: Foundry IQ를 통해 인용 기반의 신뢰할 수 있는 답변 제공
- 중앙 집중식 자산 관리
Classic 버전
- 생성형 AI 앱 구축
- 모델 탐색 및 테스트
- 전체 수명 주기 관리
- 리소스 다양성: AzureOpenAIm 허브 기반 프로젝트 등
프로젝트 아키텍처 선택 가이드
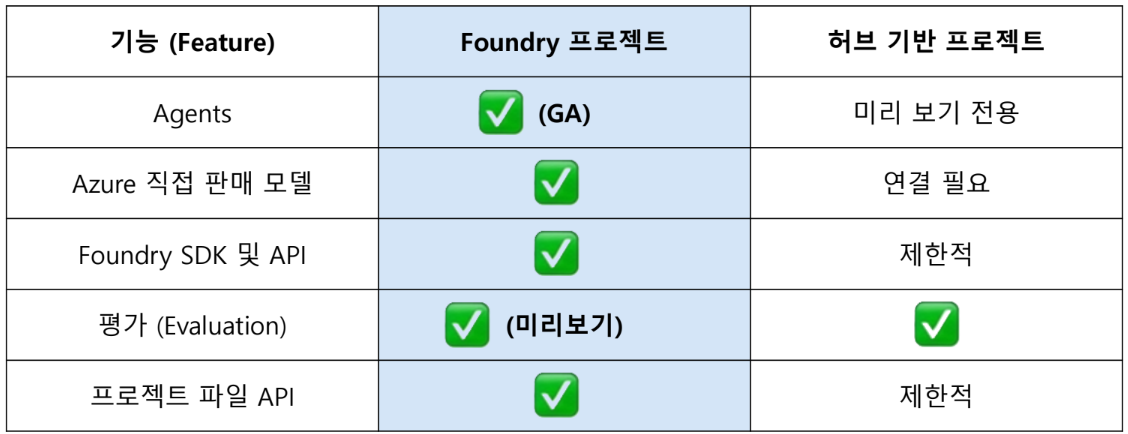
Foundry 프로젝트(권장)
- 독립적인 컨테이너, Foundry 리소스로 관리
- 추가 리소스 생성 없이 사용 사례 간 작업 분리
- 최신 에이전트 기능 및 모델 중심 역량 사용 가능
- Home > ProjectName (Foundry)
허브 기반 프로젝트
- Microsoft Foundry 허브에서 호스팅
- IT 관리 팀이 중앙에서 허브를 생성/관리하는 경우 사용
- Home> Project Name
Azure OpenAI 서비스
- Gpt 5.2
- 소라
- codex-mini
- Embeddings(text-embedding-3-large, small)
- 이미지 생성(gpt-image-1, mini)
GPT 시리즈
- 자연어 이해 및 생성 (NLU/NLG)
- 질의응답
- 텍스트요약
Embeddings 모델
- 역할: 텍스트를 고차원 벡터 공간의 점(임베딩)으로 변환
- 의미 기반 검색: 사용자 질문과 가장 의미적으로 유사한 정보 검색
- 데이터 분석: 텍스트 데이터의 의미적 유사성 분석, 군집화 등
RAG
LLM의 기능을 정보 검색 시스템과 결합하여 미리 학습된 데이터에만 의존하지 않고 실시간 정보를 바탕으로 응답을 생성하는 기술
- Azure Cosmos DB는 벡터 검색을 지원하는 운영 데이터베이스, 별도의 솔루션 도입 없이 단일 플랫폼에서 운영 워크로드와 AI 분석 워크로드를 동시에 처리
- 통합성: 데이터와 벡터의 공존으로 아키텍처 단순화
- 실시간성: 데이터 생성 즉시 검색 및 AI 반영
- 엔터프라이즈 준비: 글로벌 확장성, SLA 보장
생성형 AI의 한계와 RAG의 필요성
기존 LLM의 한계
- 미리 학습된 데이터에 의존
- 최신 정보 부재 및 할루시네이션 발생 가능성
RAG의 해결책
- 외부 지식 베이스를 실시간 검색하여 LLM에 주입
- 사용 가능한 가장 관련성이 높은 최신 데이터 기반의 정확한 응답
RAG 아키텍처 워크플로
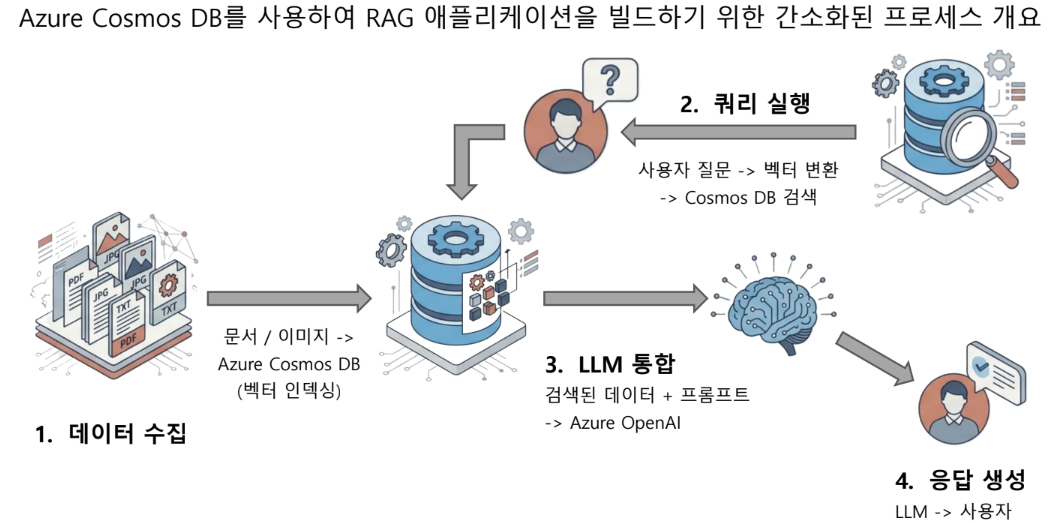
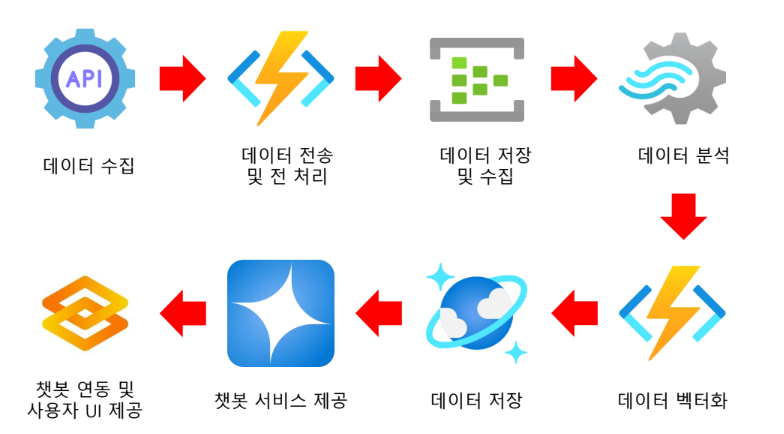
1. 데이터 수집 및 벡터화
- 저장: 문서, 이미지 및 기타 콘텐츠 형식을 Azure Cosmos DB에 저장
- 인덱싱: 데이터베이스의 벡터 검색 지원을 활용하여, 저장과 동시에 콘텐츠를 벡터화하고 인덱싱
- 특징: 운영 데이터와 벡터 데이터가 동일한 파이프라인에서 처리되므로 데이터 일관성이 보장
2. 벡터 검색 실행
- 검색 트리거: 사용자가 질문을 제출하면 프로세스가 시작
- 고속 검색: Azure Cosmos DB는 내장된 벡터 검색 기능을 사용하여 사용자의 질문 벡터와 가장 유사한 데이터를 신속하게 찾아냄
- 알고리즘: kNN(k-Nearest Neighbors) 및 ANN(Approximate Nearest Neighbors)과 같은 알고리즘을 활용하여 가장 관련성 높은 데이터를 추출
3, 4. LLM 통합 및 응답 생성
- 통합: 검색된 데이터를 "Grounding Data"로서 LLM에 전달
- 품질 향상: Cosmos DB가 제공하는 잘 구조화된(Well-structured) 데이터는 모델 출력의 품질과 정확성을 대폭 향상
- 생성: LLM은 전달받은 상황별 데이터를 처리하여 포괄적인 응답을 생성하고 사용자에게 전달
입력과 토큰화

AI 모델이 텍스트 입력을 받으면 텍스트를 토큰으로 분해
이 상태에서 의미가 부여된 벡터 상태가 되지는 않음
임베딩 생성 모델
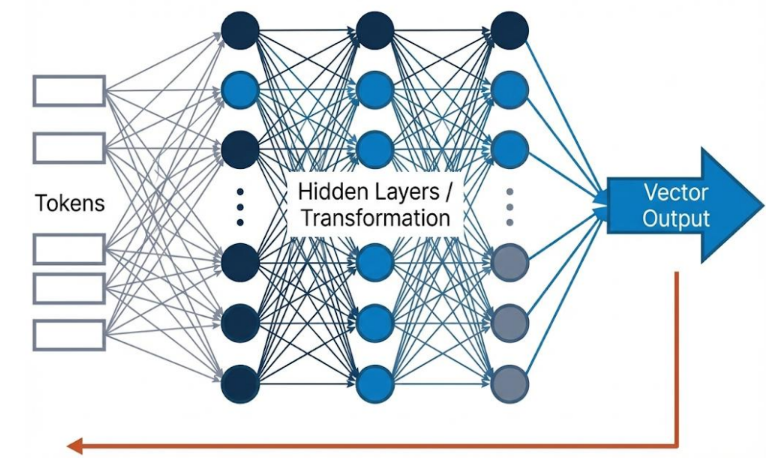
모델은 여러 계층(Layer)을 통해 데이터를 처리하며 텍스트내의 패턴과 관계를 캡처
Reverse Capability: 필요한 경우, 출력된 임베딩을 다시 역변환하여 사람이 읽을 수 있는 텍스트로 생성 가능
Supported Models
Azure OpenAI 임베딩
Hugging Face
벡터의 실체

각 임베딩은 부동 소수점 숫자의 배열
데이터 타입은 주로 float32 float16
이 숫자의 나열은 무작위가 아니라, 고차원 공간에서의 정확한 좌표를 나타냄
데이터베이스에 저장되는 실제 데이터
차원: 특징의 수치화
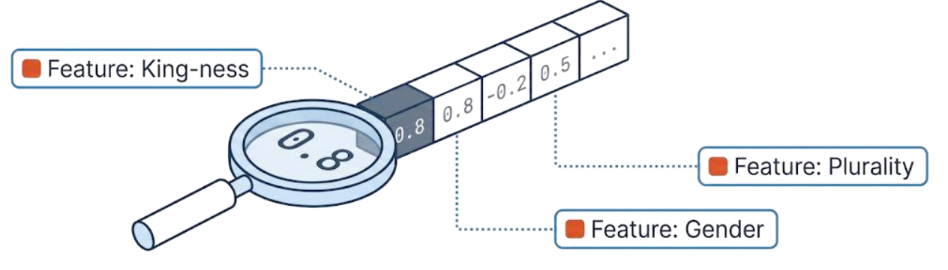
벡터 배열 내의 부동 소수점 숫자가 들어있는 각 상자는 하나의 차원에 해당
각 차원은 인간이 이해할 수 있는 데이터의 특정 기능(Feature)또는 특성(Characteristic)을 나타냄
스케일
- LLM: 일반적으로 수천개의 차원(Thousands of dimensions)을 가짐
- 복잡한 데이터 모델: 수만개의 차원(Tens of thousands of dimensions)을 가질 수 있음
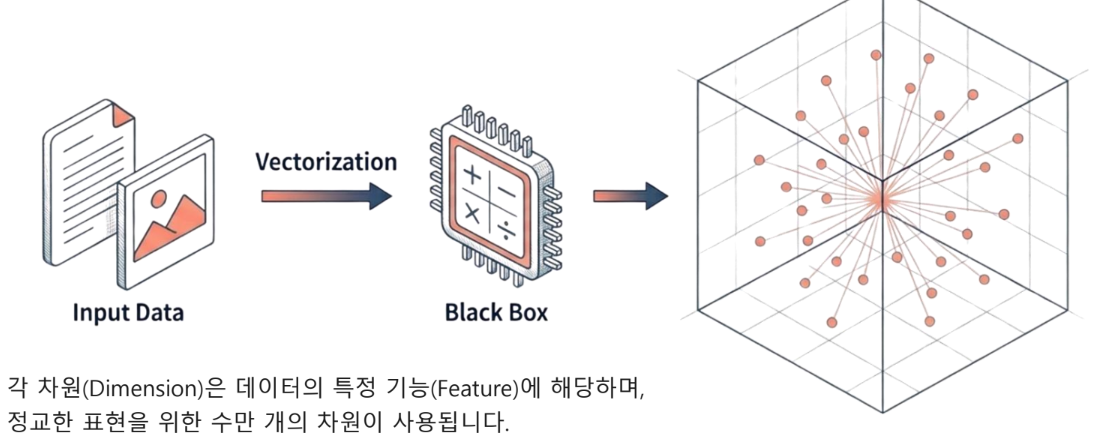
고차원 공간의 시각화
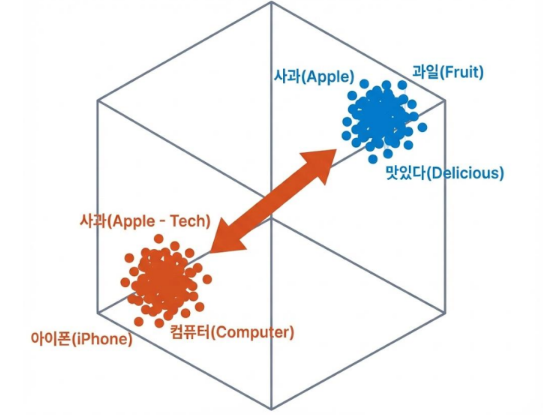
수천 개의 차원을 시각적으로 표현하기 위해 3차원 공간으로 축소하여 표현
유사한 벡터(공간적 근접성)과 크게 다른 벡터 간의 관계를 보여줌
데이터베이스는 거리르 계산하여 검색을 수행
벡터 데이터베이스
고차원 공간에서 데이터의 수학적 표현인 벡터 임베딩을 저장하고 관리하도록 설계된 시스템
임베딩
기계 학습 모델이 이해할 수 있는 부동 소수점 숫자의 배열(벡터)
작동 원리
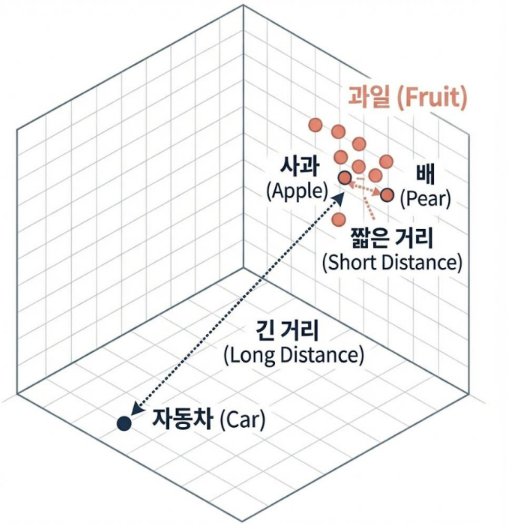
의미가 비슷할수록, 벡터 공간상에서 두 임베딩 사이의 거리(Distance) 가 가까워짐
정확한 키워드 일치가 아닌, 의미적 유사성을 통해 데이터를 찾음
인덱싱 아키텍처
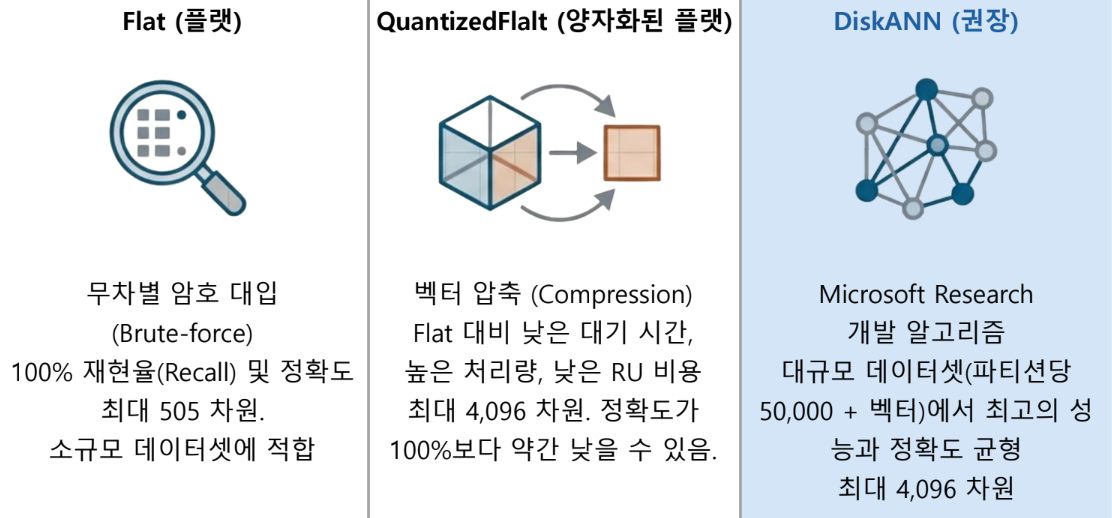
전락적 인덱스 선택 가이드
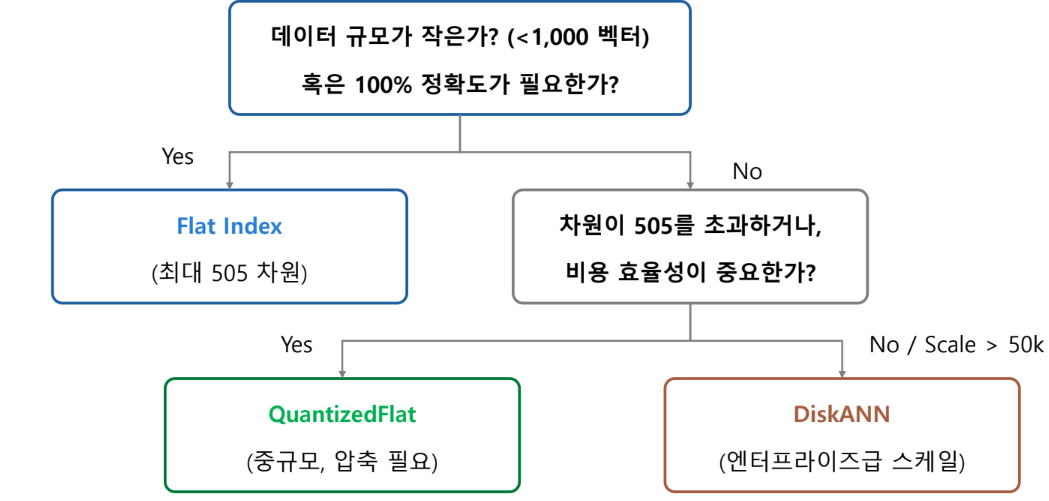
*QuantizedFlat 및 DiskANN은 양자화 정확도를 보장하기 위해 최소 1000개 이상의 벡터가 필요. 그 미만일 경우 전체 스캔이 발생하여 비용 증가
컨테이너 벡터 정책 정의
{
"vectorEmbeddings": [
{
"path": "/vector1",
"datatype": "float16",
"distanceFunction": "dotproduct",
"dimensions": 100
}
]
}Configuration Parameters
- Path: 벡터가 저장된 경로 속성(필수)
- Datatype: float32, float16(추천), int8, uint8
- Dimensions: 벡터의 길이(예: 1536). 경로 내 모든 벡터 일치 필수
- DistanceFunciton: cosine, dotproduct, euclidean
인덱싱 정책 구성
{
"indexingMode": "consistent",
"includedPaths": [{ "path": "/*" }],
"excludedPaths": [
{ "path": "/_etag/?" },
{ "path": "/vector1/*" }
],
"vectorIndexes": [
{ "path": "/vector1", "type": "diskANN" }
]
}- excludedPaths엔 벡터 경로를 반드시 제외해야 함(비용 절감 및 최적화)
- vectorIndexes는 벡터 전용 인덱싱 유형(diskAnn 등) 지정
거리 함수
벡터 간의 유사성 또는 유사도를 측정하는 수학적 수식
NoSQL 및 벡터 검색 환경에서 이 측정은 두 데이터가 얼마나 밀접하게 관련되어 있는지 결정하는 핵심 매커니즘
맨허튼 거리(Manhattan Distance): 그리드 위의 이동
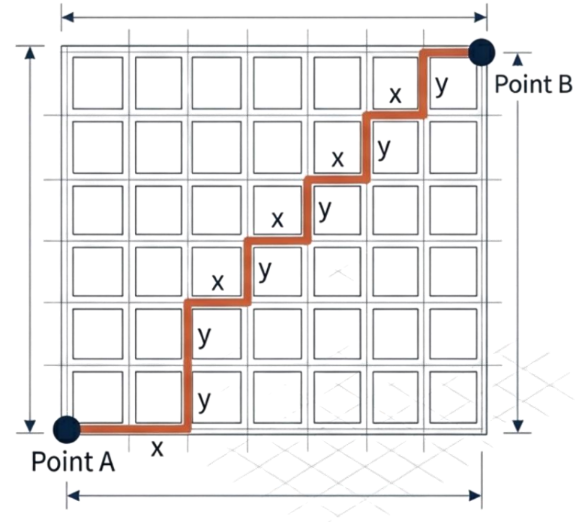
좌표 사이의 절대 차이를 합산하여 거리 측정
남북 이동 블록 수+동서 이동 블록 수
유클리드 거리(Euclidean Distance): 직선
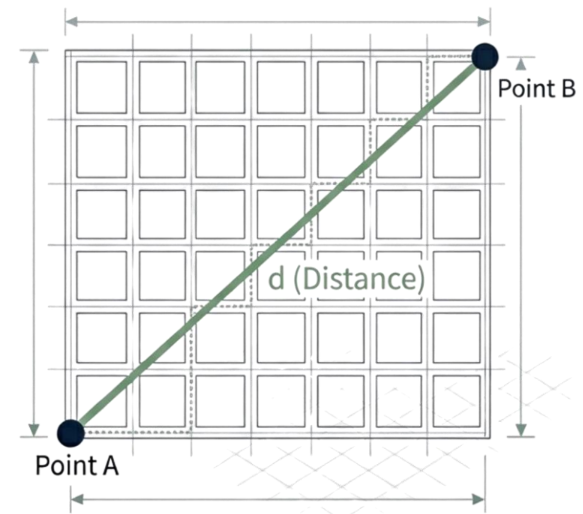
두 점 사이를 잇는 가장 짧은 직선거리 측정
장애물이 없는 공간에서의 직접적인 이동 거리를 의미
코사인 유사성(Cosine Similarity): 거리가 아닌 각도
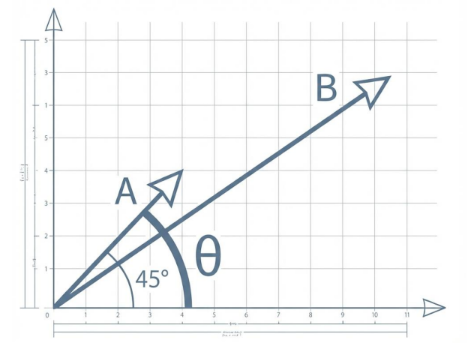
다차원 공간에 투영된 두 벡터 사이의 각도의 코사인을 측정
벡터의 크기보단 방향을 중시
두 데이터가 물리적으로 떨어져있어도, 같은 방향을 가리킨다면 주제적으로 유사할 수 있음
문서 크기와 유사성의 관계
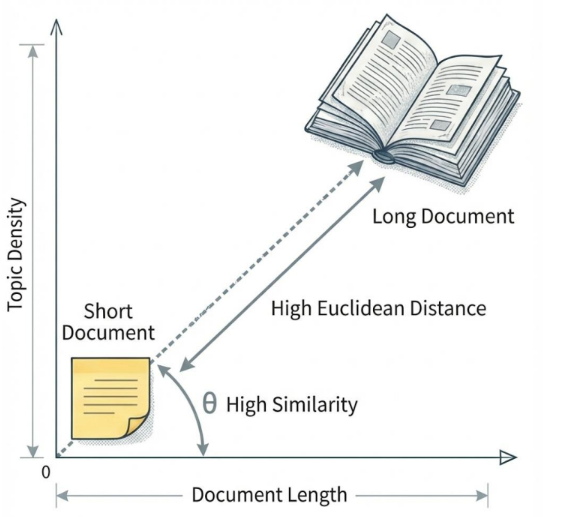
하나의 긴 문서(큰 벡터)와 하나의 짧은 문서(작은 벡터)가 있을 때, 문서의 길이 차이 때문에 유클리드 거리로는 두 점이 매우 멀리 떨어져 있을 수 있음. 그러나 두 문서가 비슷한 주제를 다루고 있다면 벡터 사이의 각도는 작아 코사인 유사성은 높게 측정됨
내적(Dot Product): 크기와 방향을 결합
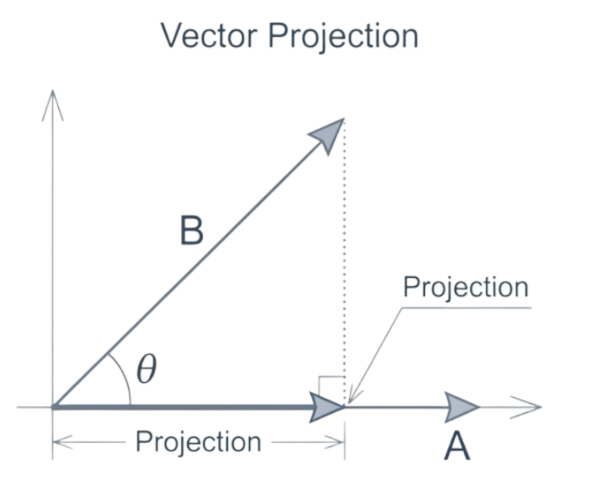
두 벡터를 곱하여 단일 숫자(Scalar)을 반환하는 연산
매커니즘
두 벡터의 크기(Magnitude)와 그 사이의 각도 코사인을 결합
한 벡터가 다른 벡터의 방향으로 얼마나 강력하게 이동(push)하거나 투영(project)되는지를 결정
KNN(k-Nearest Neighbors): 타협하지 않는 정확성

k값의 딜레마
K값(참조할 이웃의 수)설정에 따라 모델의 성능이 달라짐
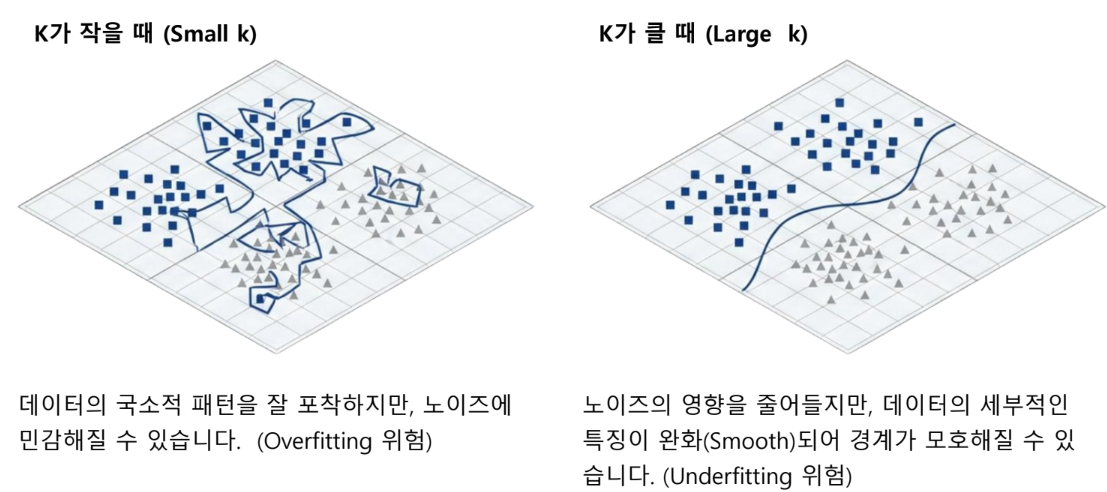
예측 매커니즘
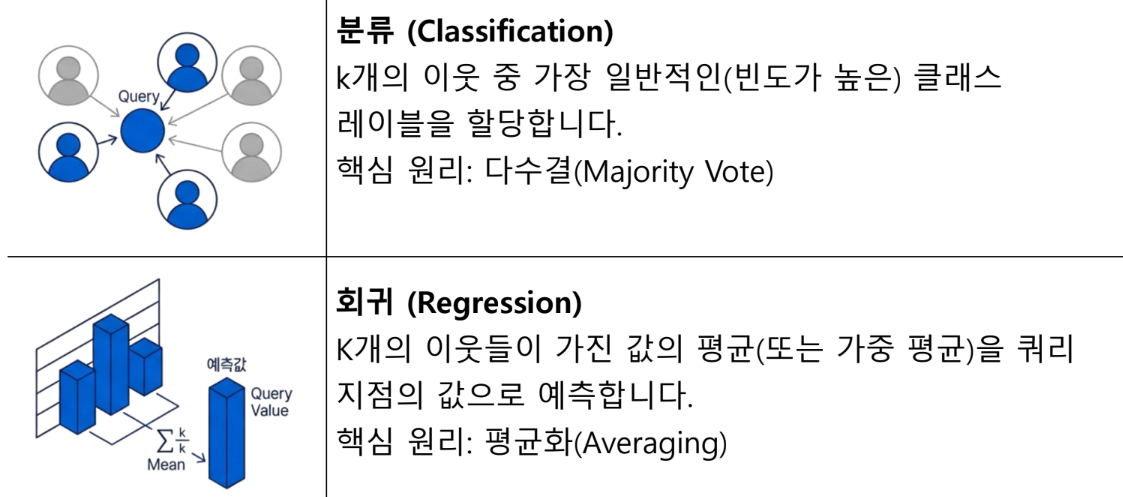
ANN(Approximate Nearest Neighbors)
정확도와 효율성 사이의 균형을 제공하는 알고리즘
모든 거리를 계산하는 대신, 데이터 구조를 미리 파악하여 검색 범위를 좁힘
100% 정확한 이웃을 보장하지 않지만, 실용적인 목적에 충분히 부합하는 근사치를 빠르게 찾아냄
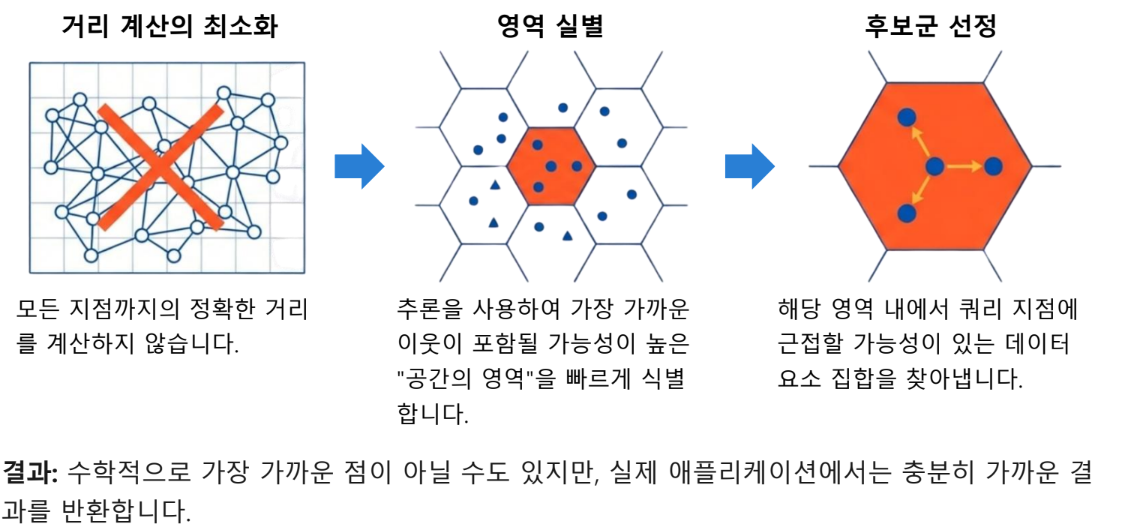
인공 신경망과 다른 것
인덱싱과 데이터 구조
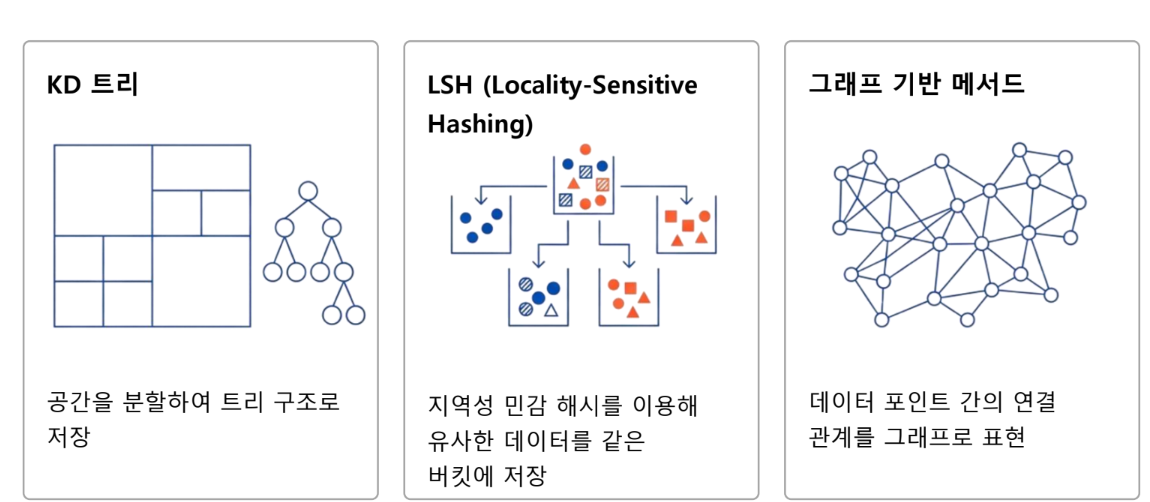
추론과 영역 탐색
Gradio

RAG 시스템 구축
태양광 발전량 예측 정보 제공 RAG 시스템 구축
Cosmos DB, Azure OpenAI, Gradio
Azure Cosmos DB 리소스 탐색
리소스 그룹에서 만들기 후 Azure Cosmos DB 선택

Azure Cosmos DB for NoSQL 선택
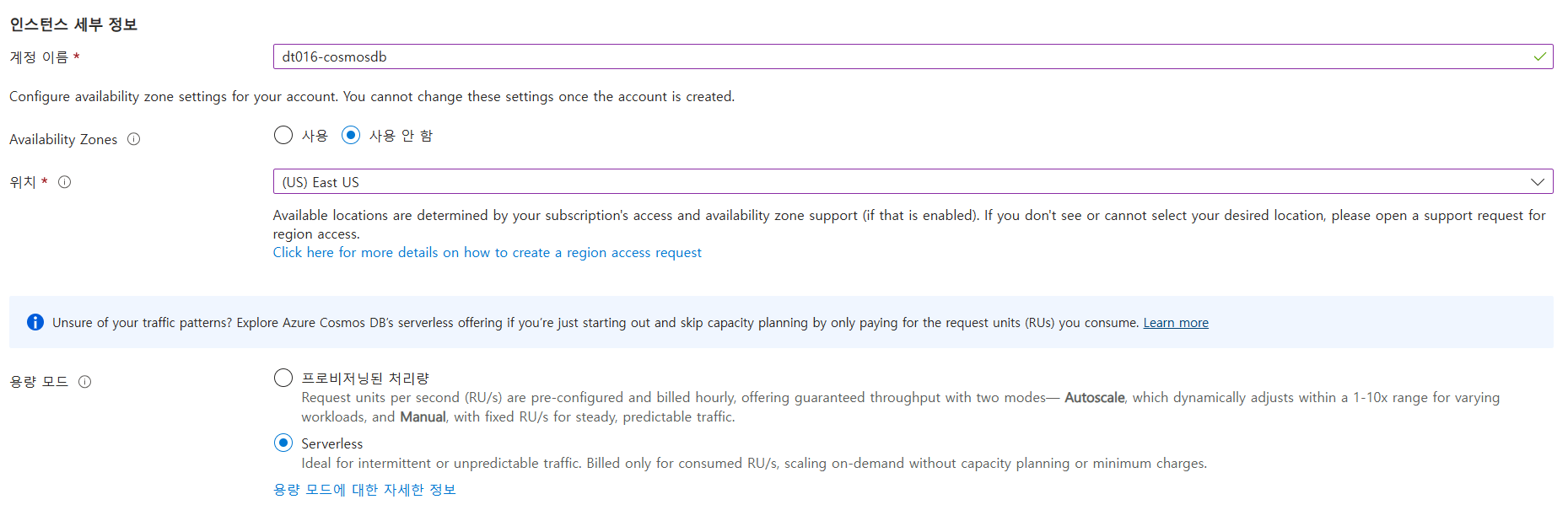
Azure Cosmos DB 페이지 접속하기
- 생성 후 리소스로 이동
- cosmosdb 페이지의 왼쪽 메뉴 중 설정 메뉴 클릭
Vector Search for NoSQL API 설정하기
- 기능 메뉴 클릭
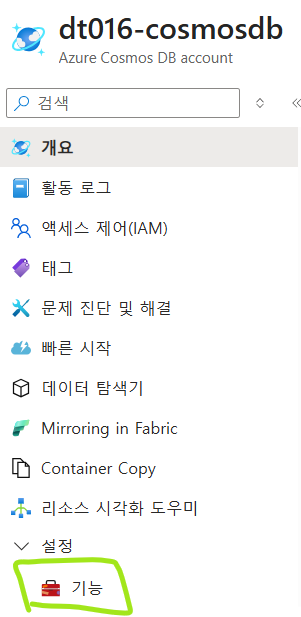
- Vector Search for NoSQL API 클릭
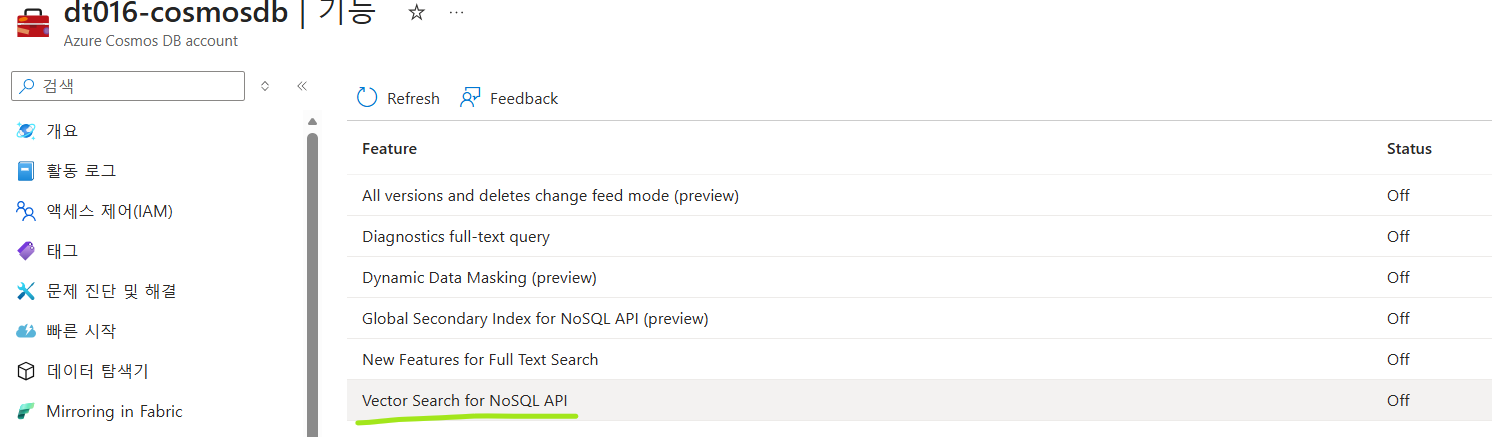
- Vector Search for NoSQL API 모달 창에서 사용 버튼 클릭
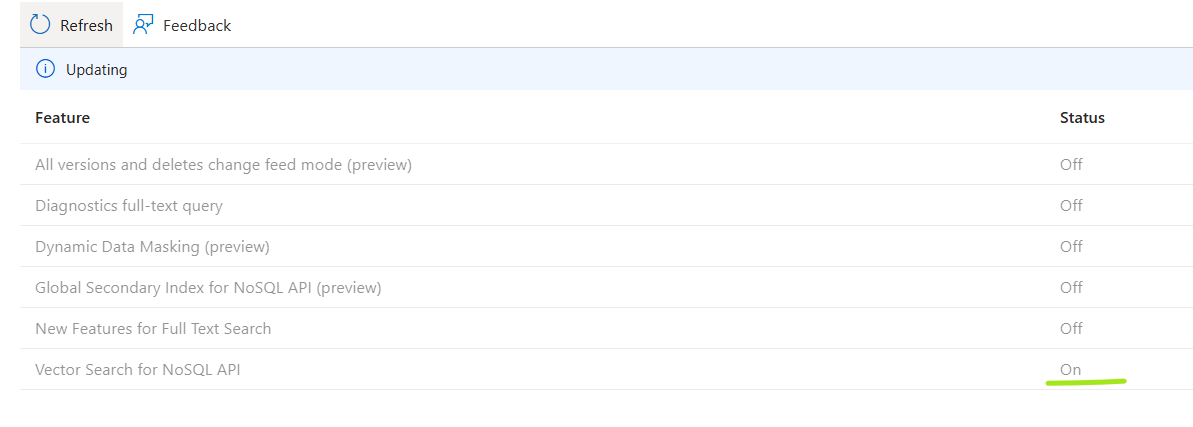
Vector Search for NoSQL API 상태 확인 및 컨테이너 만들기
- on 상태 확인
- 데이터 탐색기 메뉴 선택
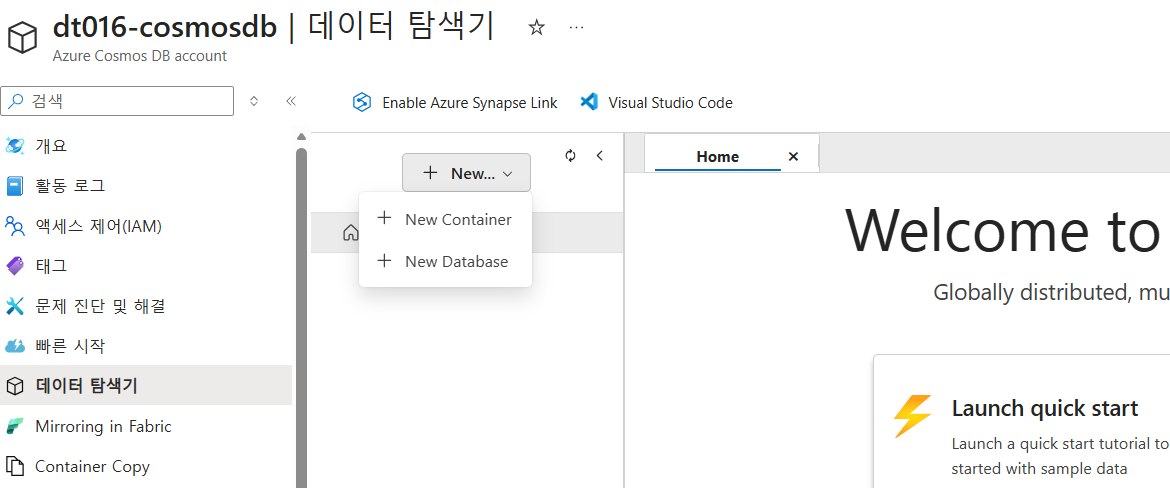
- New Container 버튼 클릭
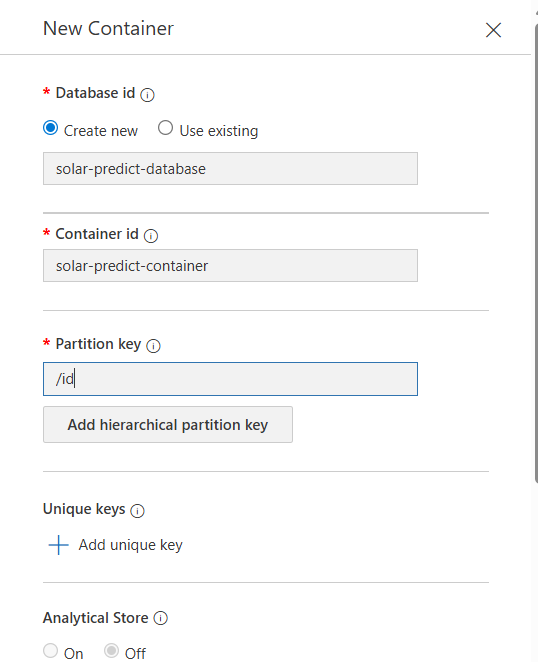
- Database id, Container id, Partition key 입력
- Add vector embedding 2번 클릭
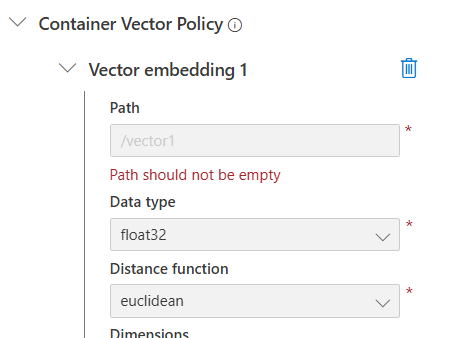
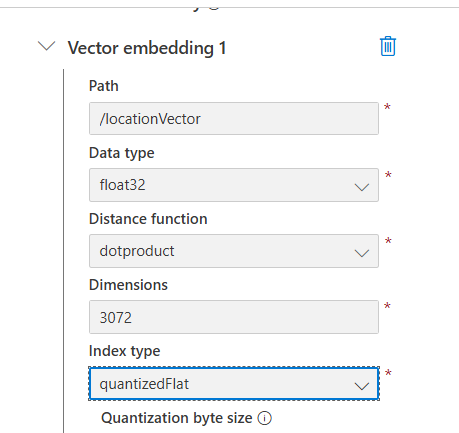
- Vector embedding 1에 path, data type, distance function, dimensions, index type 입력
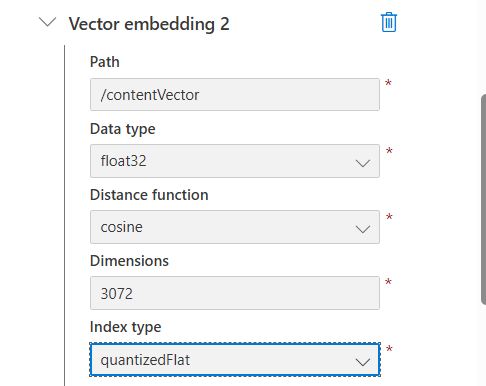
- Vector embedding 2도 동일하게 처리
이후 Vector Embedding을 수정하고싶다면 불가능하므로 컨테이너를 삭제한 뒤 다시 생성해야 한다.
Azure OpenAI 리소스 탐색
- 리소스그룹 이동
- 만들기에서 azure openai 검색
- 만들기
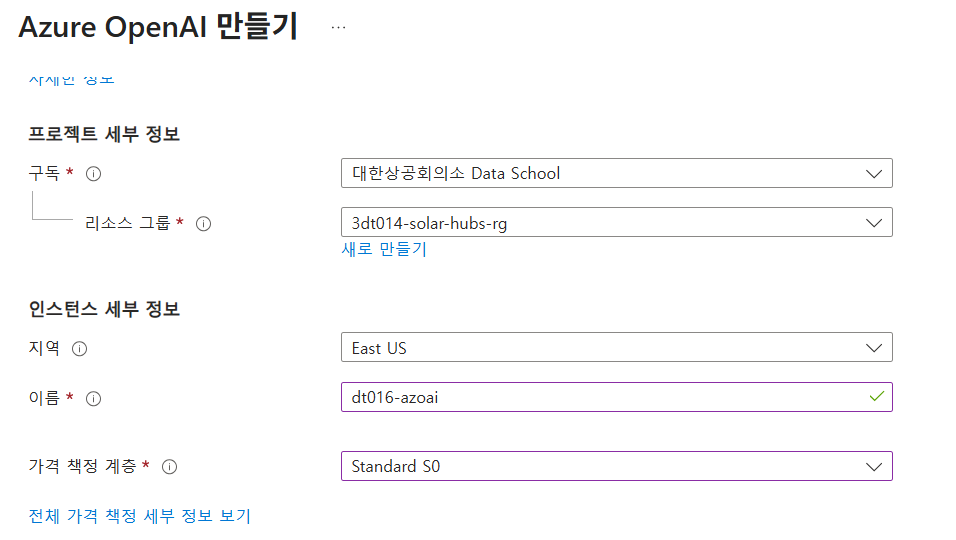
이후 탭은 모두 스킵 후 만들기
Azure AI Foundry Portal 페이지 접속

모델 배포하기
-
계정 선택에서 Azure 구독이 되어있는 계정 선택
-
배포 메뉴 클릭
-
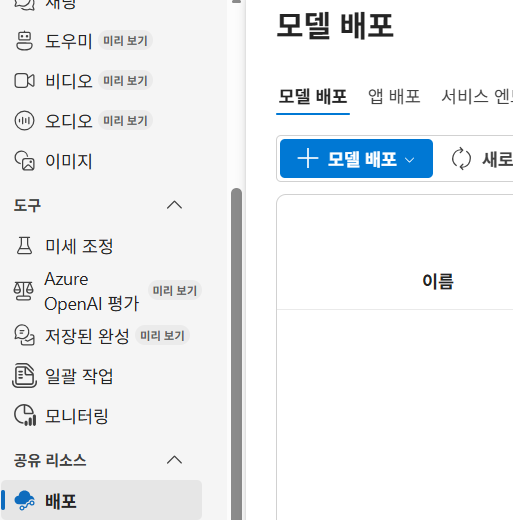
모델 배포 버튼 클릭
-
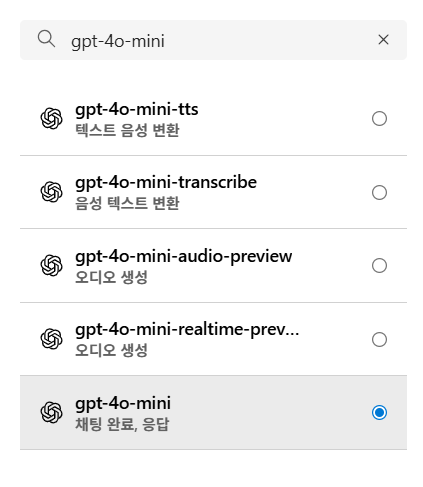
gpt-4o-mini 선택
-
배포
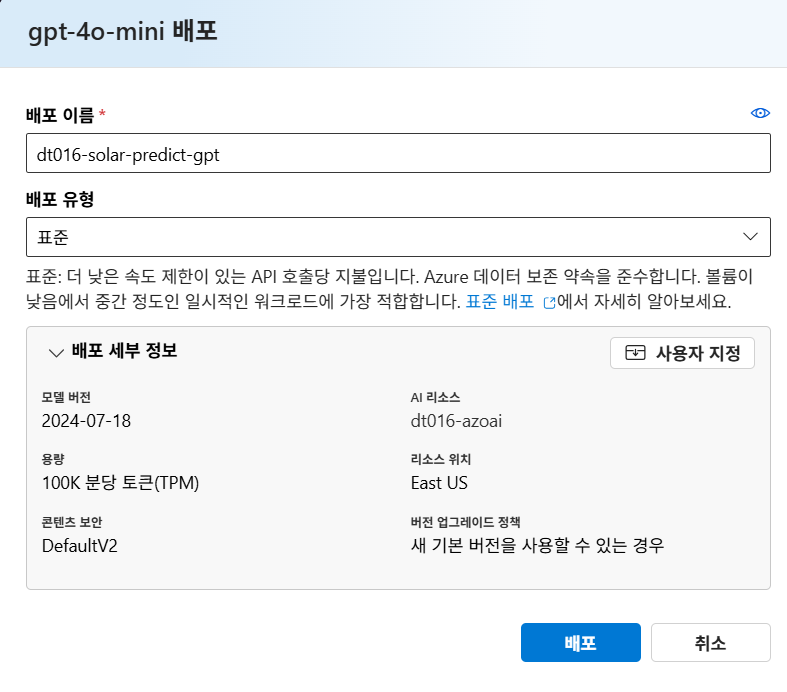
Text Embedding 모델 배포하기
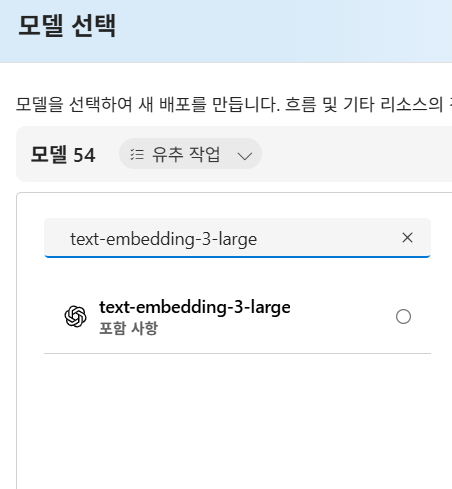
- 모델 배포 클릭
- text-embedding-3-large 검색 후 클릭
- 생성
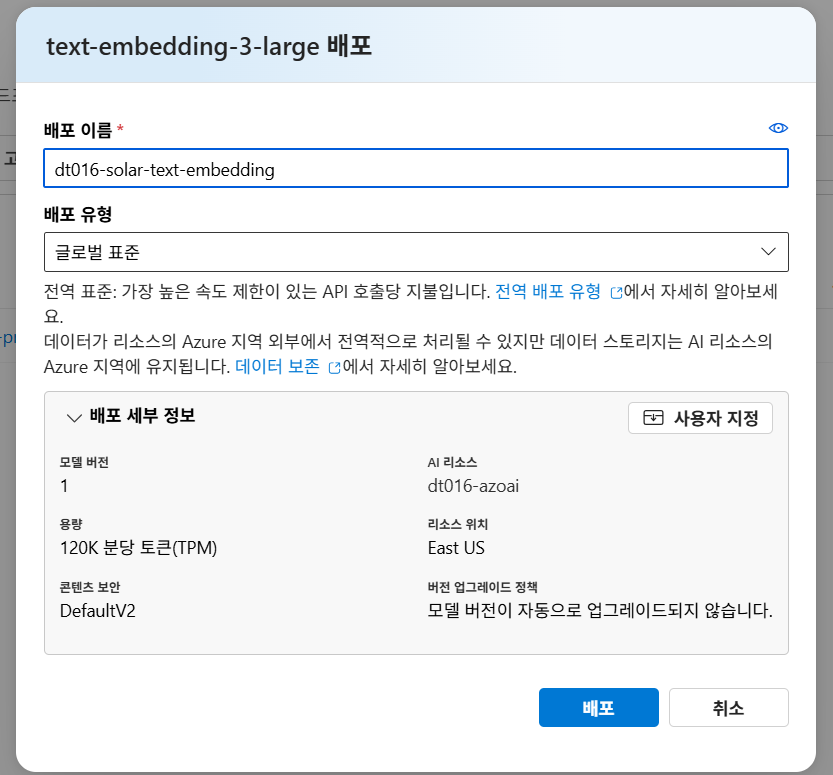
데이터 벡터화
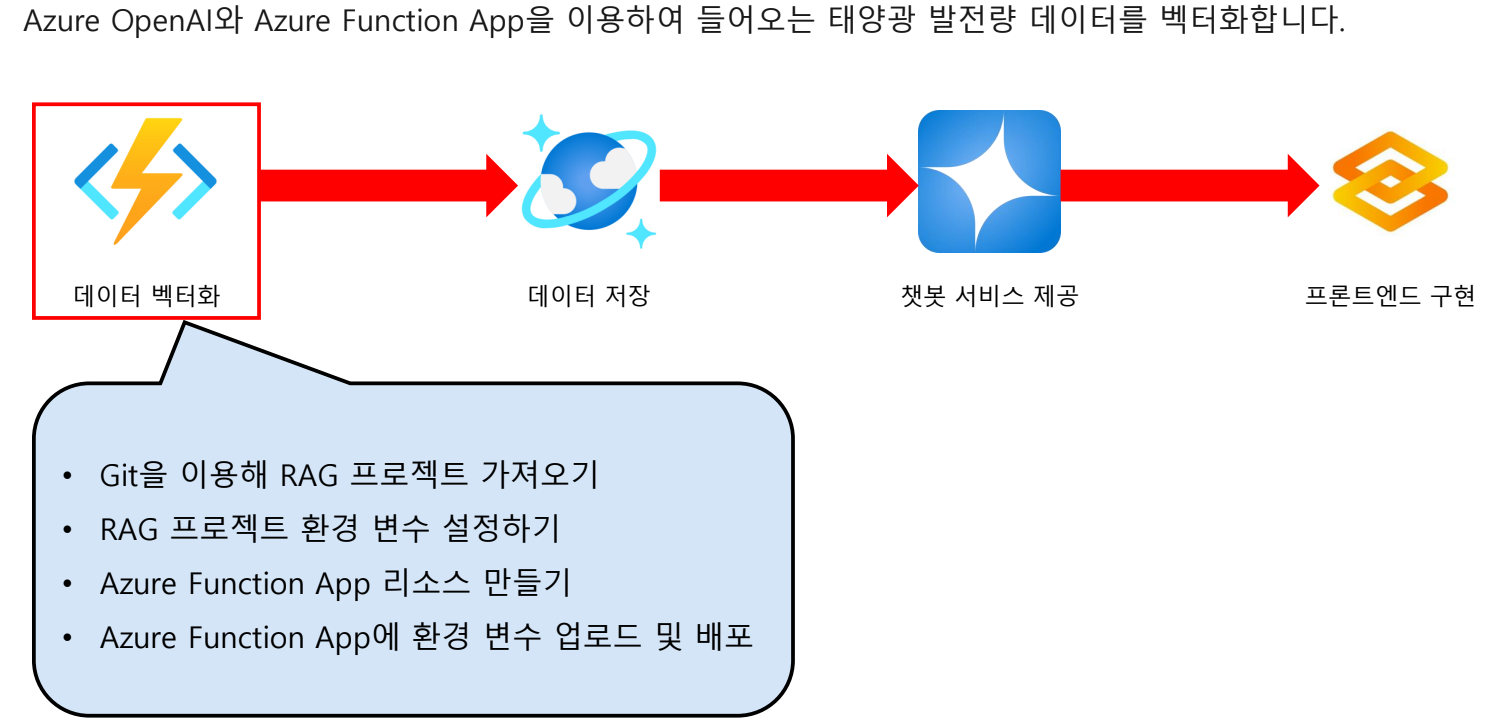
Git을 이용해 RAG 프로젝트 가져오기
git clone https://토큰@깃헙주소
Azure Functions 환경변수 설정
local.settings.json 추가
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python"
}
}Azure OpenAI 키 및 엔드포인트 설정하기
-
키 및 엔드포인트 메뉴 클릭
-
키 1의 복사 버튼 클릭
-
엔드포인트의 복사 버튼 클릭
-
local.settings.json 파일에
OPENAI_ENDPOINTOPENAI_KEYOPENAI_API_VERSION입력
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"OPENAI_ENDPOINT": "엔드포인트",
"OPENAI_KEY": "키1복사값",
"OPENAI_API_VERSION": "2025-01-01-preview"
}
}Azure OpenAI 모델 배포 이름 설정
local.settings.json 파일에 OPENAI_GPT_MODEL OPENAI_EMBEDDINGS_DEPLOYMENT 정보 입력
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"OPENAI_ENDPOINT": "엔드포인트",
"OPENAI_KEY": "키1복사값",
"OPENAI_API_VERSION": "2025-01-01-preview",
"OPENAI_GPT_MODEL": "gpt모델이름",
"OPENAI_EMBEDDINGS_DEPLOYMENT": "text embedding 모델 이름"
}
}
Azure Cosmos DB URI와 PRIMARY KEY 설정
-
CosmosDB 페이지에서 키 메뉴 선택
-
키 페이지에서 URI 복사 버튼 클릭
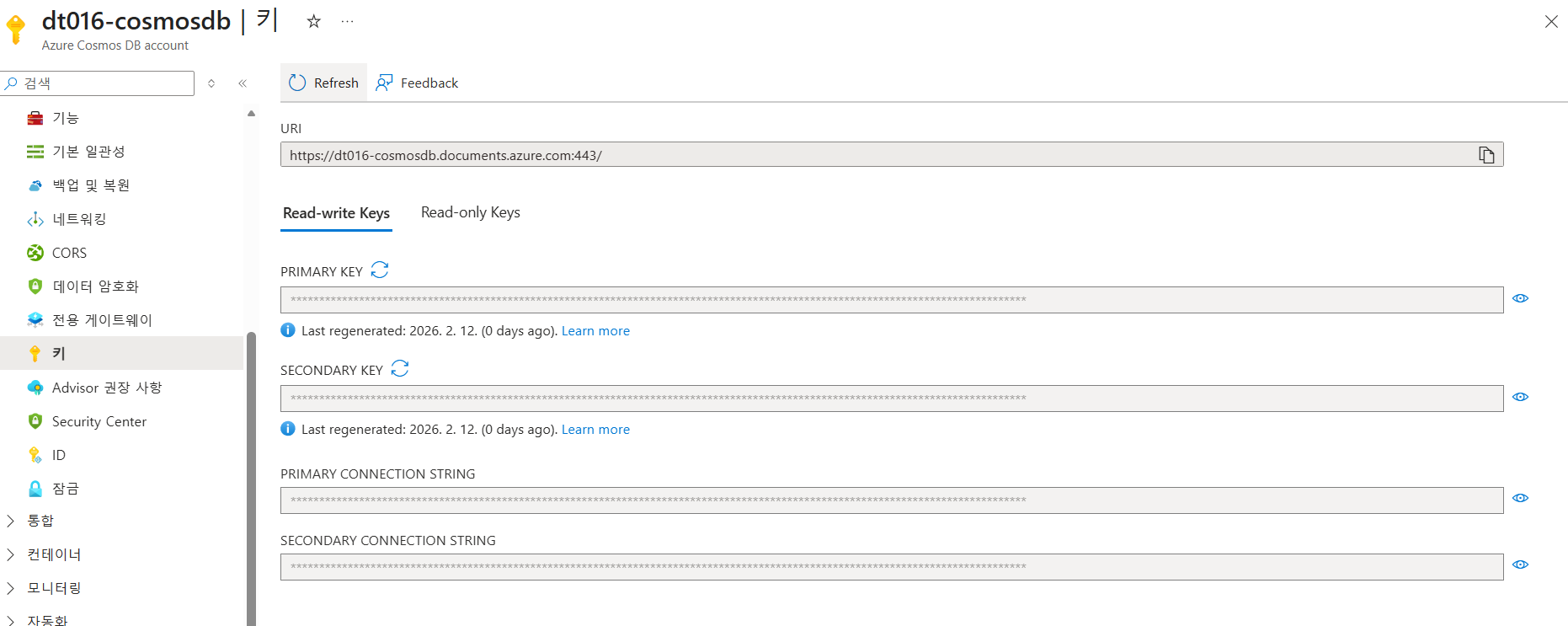
-
PRIMARY KEY 복사 버튼 클릭
-
local.settings.json 파일에
COSMOSDB_ENDPOINTCOSMOSDB_KEY정보 입력
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"OPENAI_ENDPOINT": "엔드포인트",
"OPENAI_KEY": "키1복사값",
"OPENAI_API_VERSION": "2025-01-01-preview",
"OPENAI_GPT_MODEL": "gpt모델이름",
"OPENAI_EMBEDDINGS_DEPLOYMENT": "text embedding 모델 이름",
"COSMOSDB_ENDPOINT": "엔드포인트",
"COSMOSDB_KEY": "키복사값"
}
}Azure Cosmos DB Database와 Container 설정하기
- 데이터 탐색기 메뉴 클릭
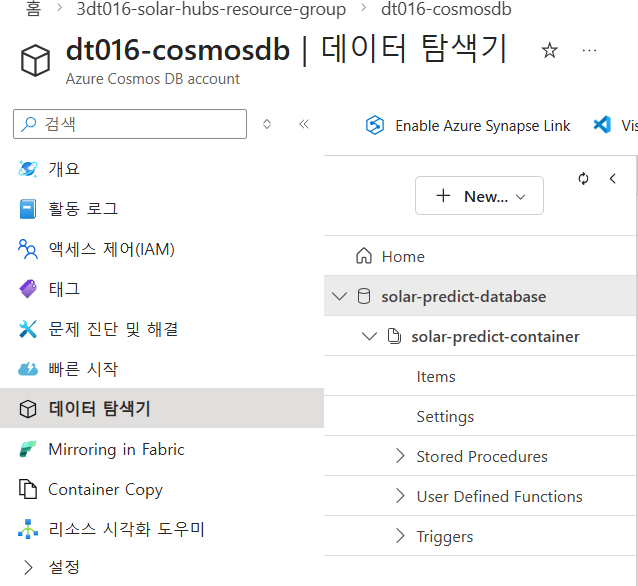
- 데이터 베이스 이름과 컨테이너 이름 복사
local.settings.json파일에COSMOSDB_DATABASECOSMOSDB_CONTAINER정보 입력
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"OPENAI_ENDPOINT": "엔드포인트",
"OPENAI_KEY": "키1복사값",
"OPENAI_API_VERSION": "2025-01-01-preview",
"OPENAI_GPT_MODEL": "gpt모델이름",
"OPENAI_EMBEDDINGS_DEPLOYMENT": "text embedding 모델 이름",
"COSMOSDB_ENDPOINT": "엔드포인트",
"COSMOSDB_KEY": "키복사값",
"COSMOSDB_DATABASE": "데이터베이스 이름",
"COSMOSDB_CONTAINER": "컨테이너 이름"Azure Function 생성
function을 위한 리소스그룹 생성
함수 앱 생성
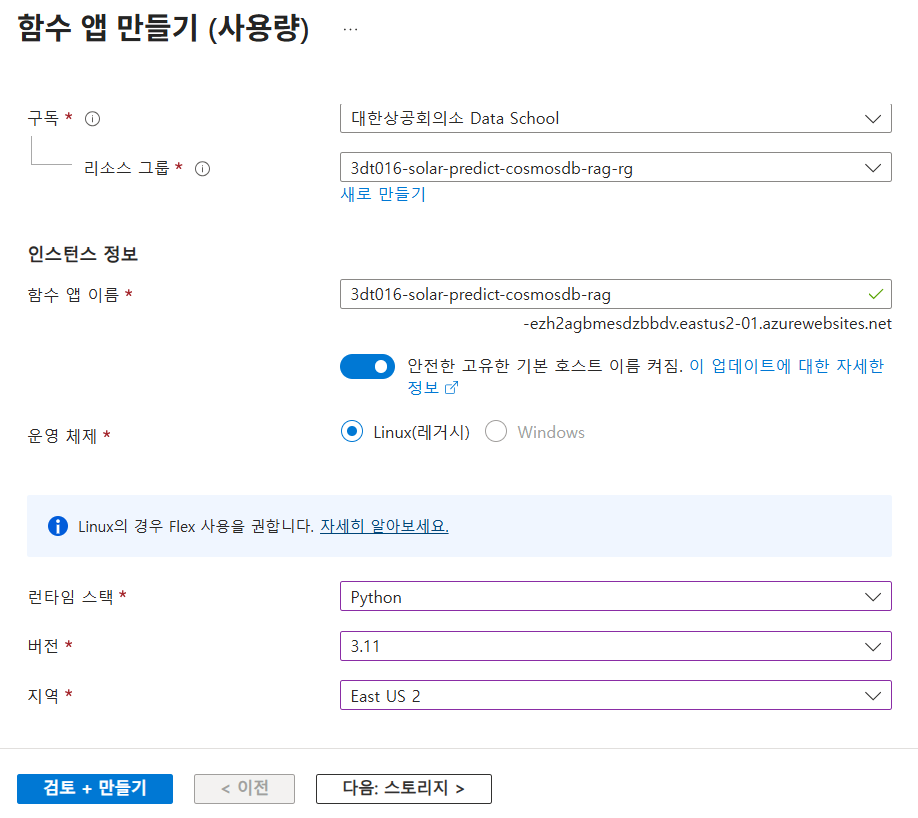
주의: 사진과 같이 안전한 이름 켜두면 챗봇 실행에서 엔드포인트를 못잡으니, 꺼주도록 하자
Azure Function App 환경 변수 업로드하기
- VSCode에서 F1키 입력
- Azure Functions: Upload Local Settings... 명령 실행
- Azure Functions App 이름 입력
- 우측 하단의 Azure Functions App 환경 변수 업로드 메시지 확인
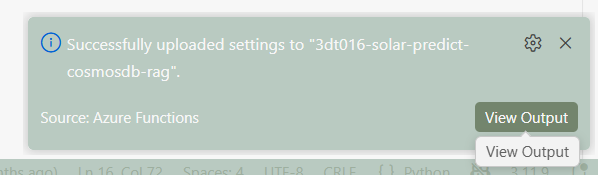
Azure Function App 배포하기
- VSCode에서 F1키 입력
- Azure Functions: Deploy to Function App.. 명령을 실행
- Azure Functions App 이름 입력
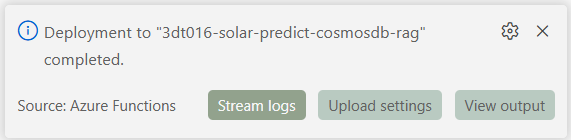
배포된 Azure Function App 확인하기