
RAG 시스템 구축
Trigger sync 문제
항상 deploy를 한 번만 하면 업로드가 안되고, 두 번 해야 적용이 되는 현상이 있었다. AI에게 물어보니 Trigger Sync 문제일 수 있다 하였다.
해결방법은 아래와 같다고...
- Azure Portal에서 함수앱 Stop
- VSCode에서 deploy
- Portal에서 Start
- Functions → Sync triggers
데이터 저장
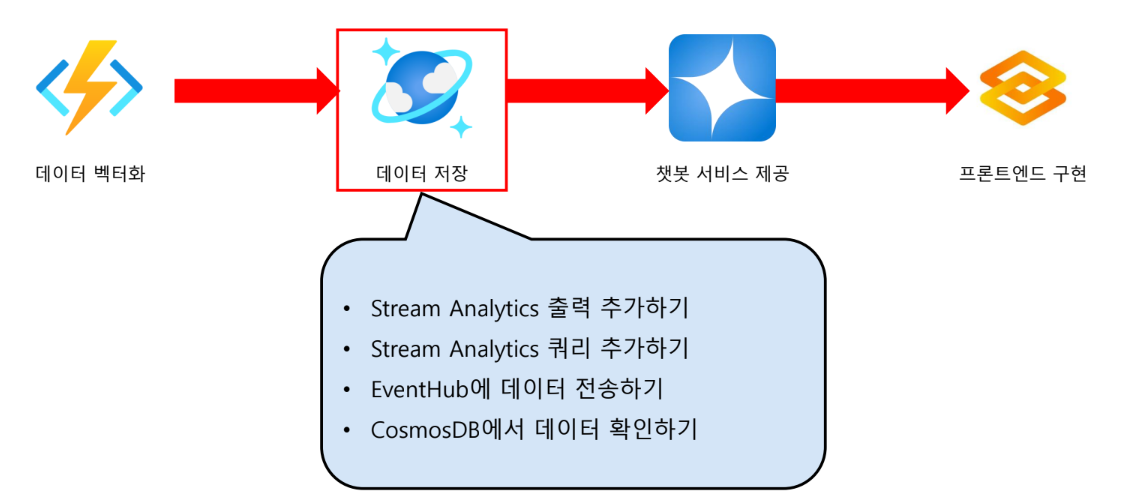
Azure Stream Analytics 페이지 접속
- Stream Analytics 에서
쿼리메뉴 선택
- 작업 중지 클릭
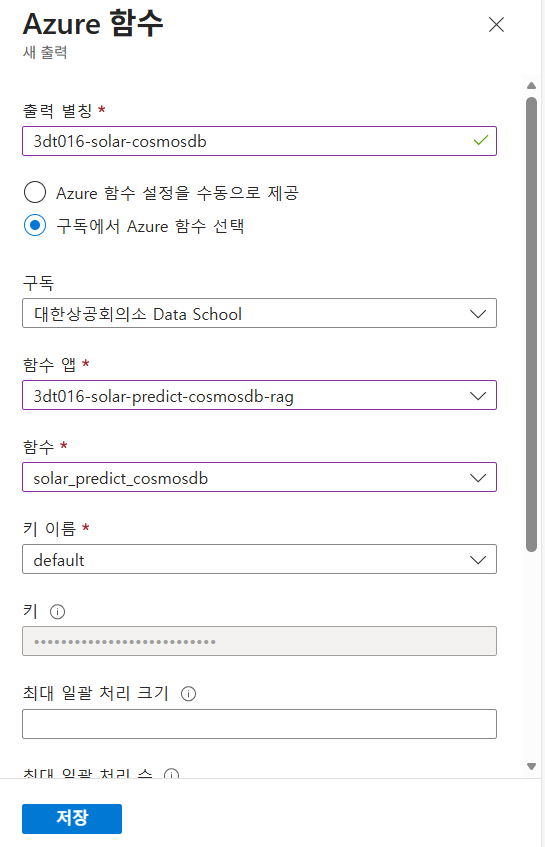
Azure Function App 출력 추가하기
- 출력 메뉴 클릭
- 출력 추가 - Azure 함수
- 출력별칭, 함수 앱, 함수, 키이름 지정 후 저장
여기에서 테스트를 실패했는데, 앞에서 azure functions를 생성할 때, 안전한 고유한 기본 호스트 이름을 사용해보세요 라디오 버튼을 비활성하지 않았기 때문이었다.
그래서 함수를 삭제 후 다시 생성해주었다.
Azure Stream Analyctics 쿼리 추가하기
- 쿼리 탭
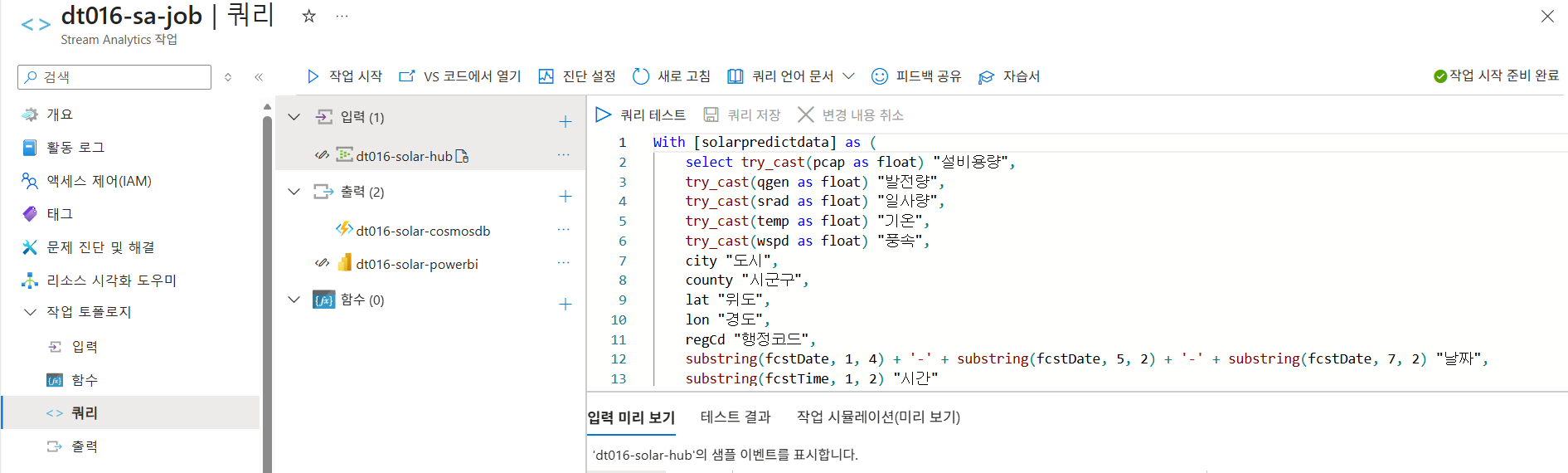
- 쿼리 입력
with
[solarpredictdata] as (
select
try_cast(pcap as float) "설비용량",
try_cast(qgen as float) "발전량",
try_cast(srad as float) "일사량",
try_cast(temp as float) "기온",
try_cast(wspd as float) "풍속",
city "도시",
county "시군구",
lat "위도",
lon "경도",
regCd "행정코드",
substring(fcstDate, 1, 4) + '-' + substring(fcstDate, 5, 2) + '-' + substring(fcstDate, 7, 2) "날짜",
substring(fcstTime, 1, 2) "시간"
from [dt016-solar-hub]
),
[processed_data] as (
select round(try_cast(([solarpredictdata].[발전량] / [solarpredictdata].[설비용량]) * 100 as bigint), -1) "이용률",
([solarpredictdata].[발전량] / [solarpredictdata].[설비용량]) * 100 "실제이용률",
*,
case
when try_cast([solarpredictdata].[시간] as bigint) < 12 then '오전'
else '오후'
end "오전오후구분",
CONCAT([solarpredictdata].[날짜], '_',
[solarpredictdata].[시간], '_',
[solarpredictdata].[행정코드]) as id
from solarpredictdata
)
select *
into [dt016-solar-powerbi]
from [processed_data];
select try_cast(pcap as float) pcap,
try_cast(qgen as float) qgen,
try_cast(srad as float) srad,
try_cast(temp as float) temp,
try_cast(wspd as float) wspd,
city,
county,
lat,
lon,
regCd,
substring(fcstDate, 1, 4) + '-' + substring(fcstDate, 5, 2) + '-' + substring(fcstDate, 7, 2) fcstDate,
substring(fcstTime, 1, 2) fcstTime
into [dt016-solar-cosmosdb]
from [dt016-solar-hub];- 작업 시작
태양광 발전량 예측 데이터 전송 함수 호출하기
Azure Cosmos DB에서 태양광 발전량 예측 데이터 확인하기
- Azure Cosmos DB 페이지에서
데이터 탐색기메뉴 선택 solar-predict-database-solar-predict-container선택- 태양광 발전량 데이터 확인
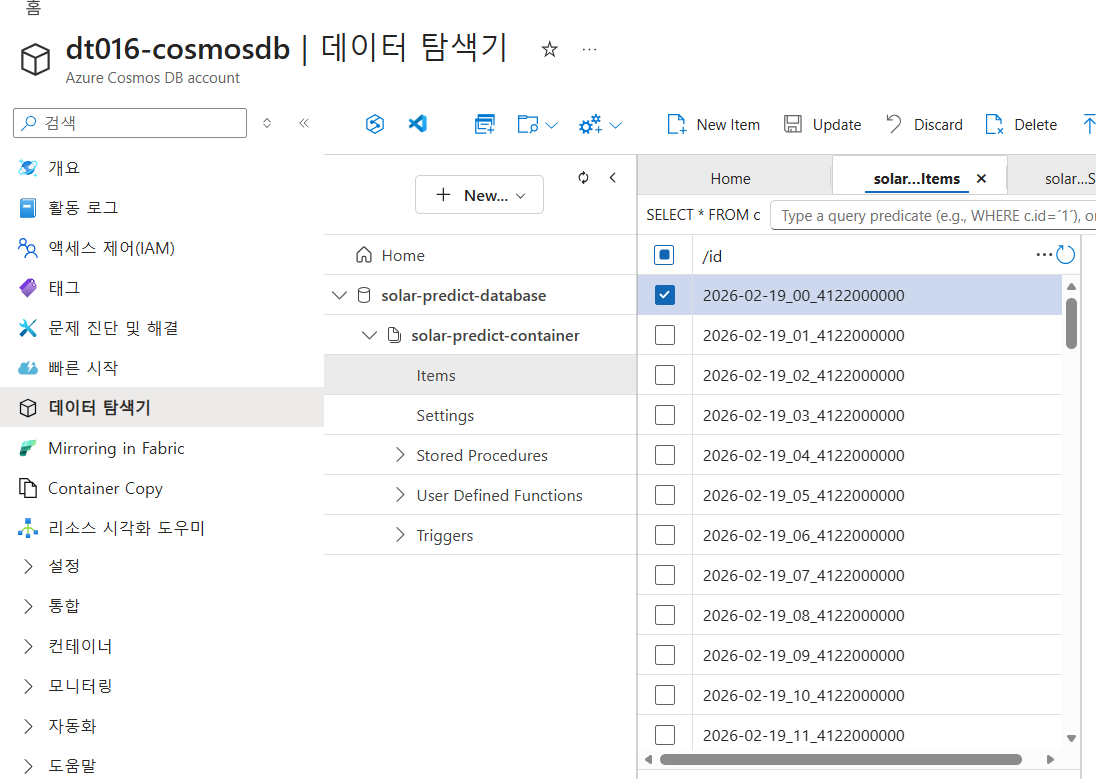
만약 vector값이 0값으로 뜬다면, Azure AI에서 text-embedding 설정을 잘못한것이다.(혹은 없거나)
실제 트러블슈팅은 text-embedding 모델에서 표준이 아닌 국제 표준으로 생성했을 때 정상작동되었다고 한다.
챗봇 서비스
Azure OpenAI의 GPT 모델을 사용하는 Azure Function App 엔드포인트를 활용
챗봇 URL 복사하기
- URL 복사
- .env 파일 생성

CHAT_RAG_ENDPOINT=복붙프론트엔드 구현
Gradio를 사용하여 태양광 발전량 예측 데이터를 제공하는 RAG 시스템의 프론트엔드 환경을 구현
Gradio: 머신러닝 모델, 딥러닝 모델, 혹은 임의의 파이썬(Python) 함수를 웹 기반의 인터랙티브한 사용자 인터페이스(UI)로 매우 빠르게 변환해주는 파이썬 라이브러리
Gradio 실행하기
-
Gradio 설치
pip install gradio -
실행
# ----- 태양광 발전 데이터 챗봇 Gradio 인터페이스 -----
# Gradio를 이용한 웹 인터페이스 구현 코드
# ----- 필요한 라이브러리 임포트 -----
import gradio as gr # 웹 인터페이스 생성을 위한 Gradio 라이브러리
import requests # HTTP 요청을 보내기 위한 라이브러리
import os # 환경 변수 접근을 위한 라이브러리
# ----- 환경 변수에서 API 엔드포인트 URL 로드 -----
# Azure Functions에 배포된 chat_rag 엔드포인트 주소를 환경 변수에서 가져옴
chat_rag_endpoint = os.environ.get("CHAT_RAG_ENDPOINT")
def api_request(text, _):
"""
사용자 입력을 받아 API에 요청을 보내고 응답을 반환하는 함수
매개변수:
text (str): 사용자가 입력한 질문 텍스트
_ : Gradio의 상태 변수(여기서는 사용하지 않음)
반환값:
str: API로부터 받은 응답 텍스트
"""
# API 엔드포인트로 POST 요청 전송
# JSON 형식으로 질문 데이터 전달
response = requests.post(chat_rag_endpoint, json={"question": text})
# API 응답에서 'items' 필드 추출하여 반환
# 이 값은 Azure Functions에서 생성된 AI 응답 텍스트
return response.json().get("items")
# ----- Gradio 인터페이스 설정 -----
# ChatInterface: 채팅 형태의 UI 자동 생성
iface = gr.ChatInterface(
fn=api_request, # 채팅 메시지 처리 함수
title="태양광 발전 데이터 챗봇", # 웹 페이지 제목
description="전국 태양광 발전량 데이터를 저장하고 있는 챗봇과 대화하세요.", # 웹 페이지 설명
)
# ----- Gradio 앱 실행 -----
# share=False: 로컬에서만 접근 가능한 모드로 실행
# share=True로 설정하면 임시 공개 URL이 생성됨
iface.launch(share=False)
RAG 테스트
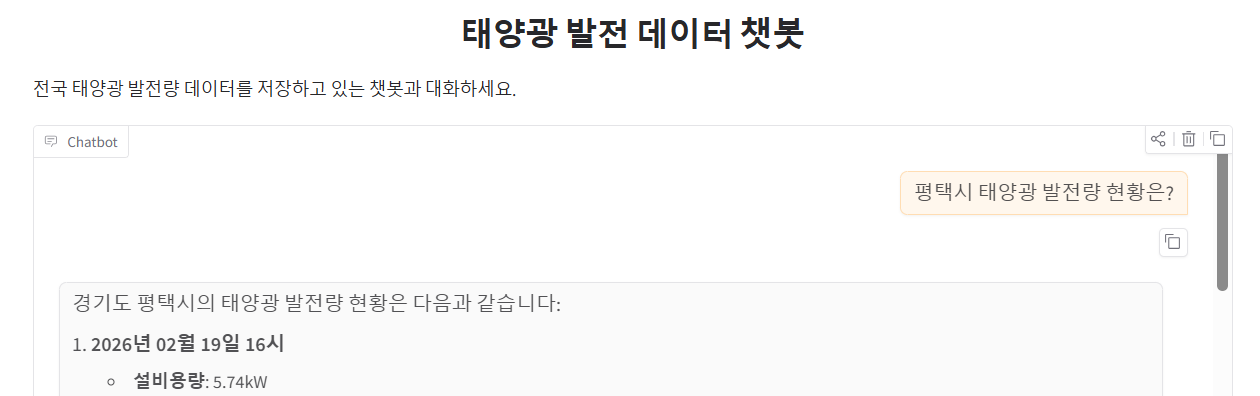

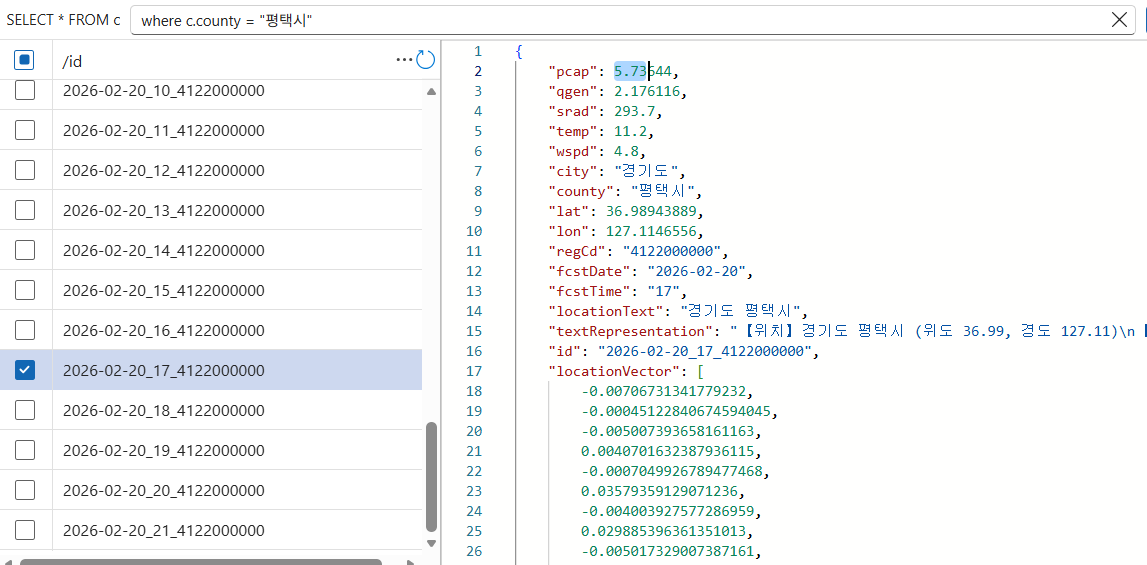
.env 파일명을 env로 해서 오류가 발생했었다.
바꿔준 뒤에도 오류가 났었는데, 이는 restart해서 커널 재시작 후, run all을 해주면 된다.
정리
질문을 벡터 형식으로 변환 → 저장된 데이터의 벡터값이 유사한 데이터를 반환하는 원리
1. 챗 봇이 CosmosDB에 저장되어 있는 데이터 중 잘 응답하도록 여러가지 질문을 시험 해보세요.
시간 지정
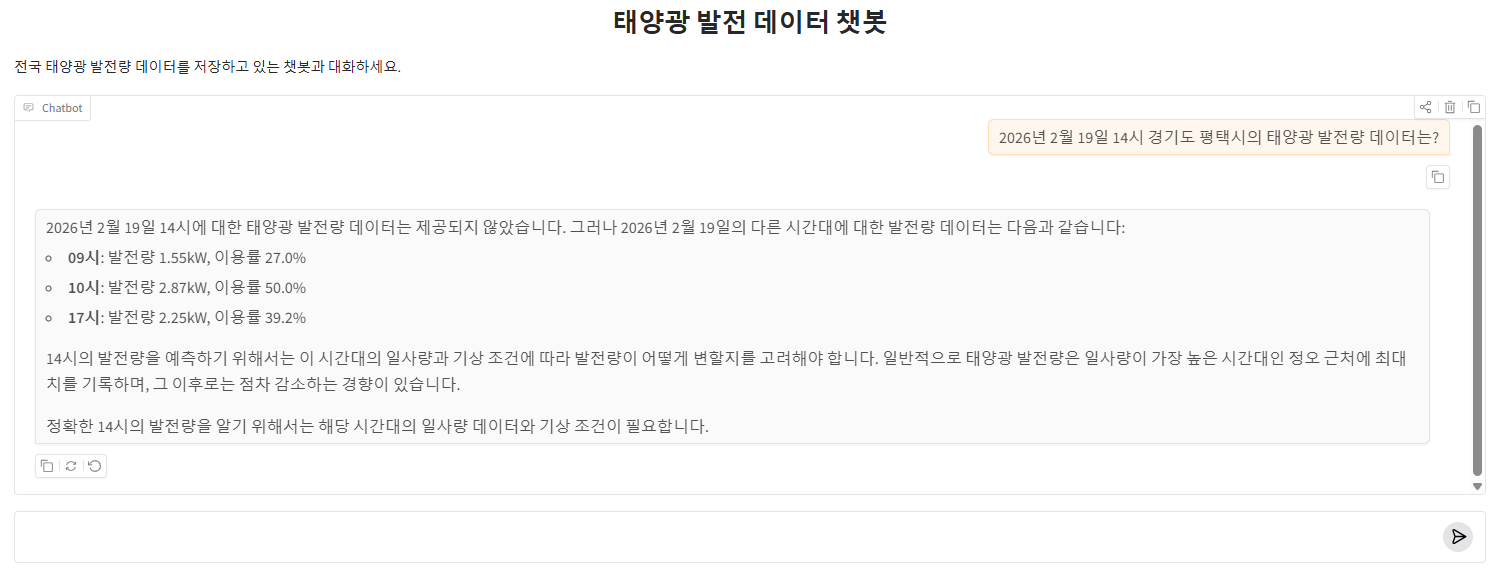
시간까지 지정해서 질문하면 응답 시간이 오래걸린다(20초가량)
없는 데이터 질문

순위
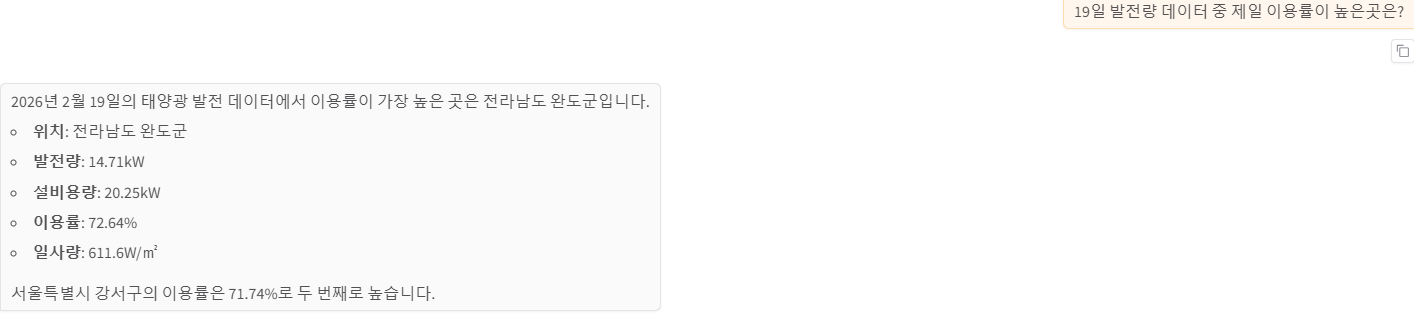
2. CosmosDB에서 컨테이너를 생성할 때 거리 계산 함수 방식을 유클리드 거리, 코사인, 내적 3가지 방법을 각각 사용해본 후 정확도를 비교해보세요.
공통 질문: 19일 평택시의 평균 발전량은?
유클리드 거리

코사인
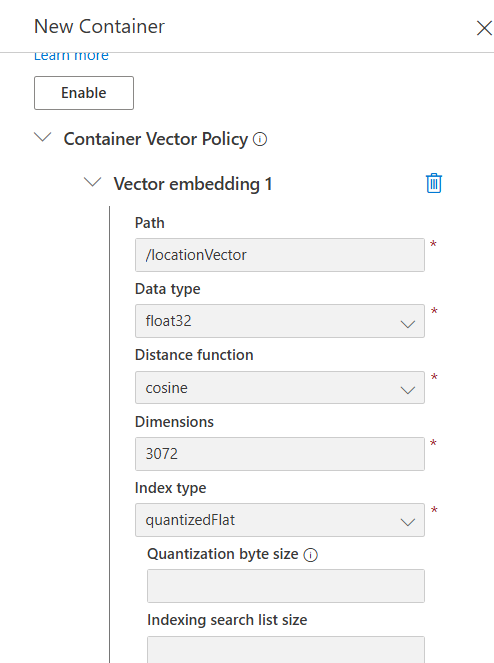
1. local.settings.json의 COSMOSDB_CONTAINER 수정
2. 스케줄러 함수 실행하여 eventhub에서 cosmosdb의 해당 컨테이너로 데이터 출력

내적
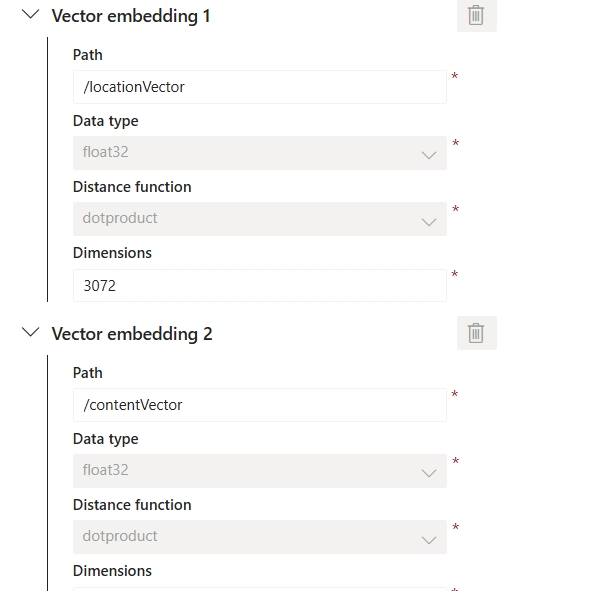

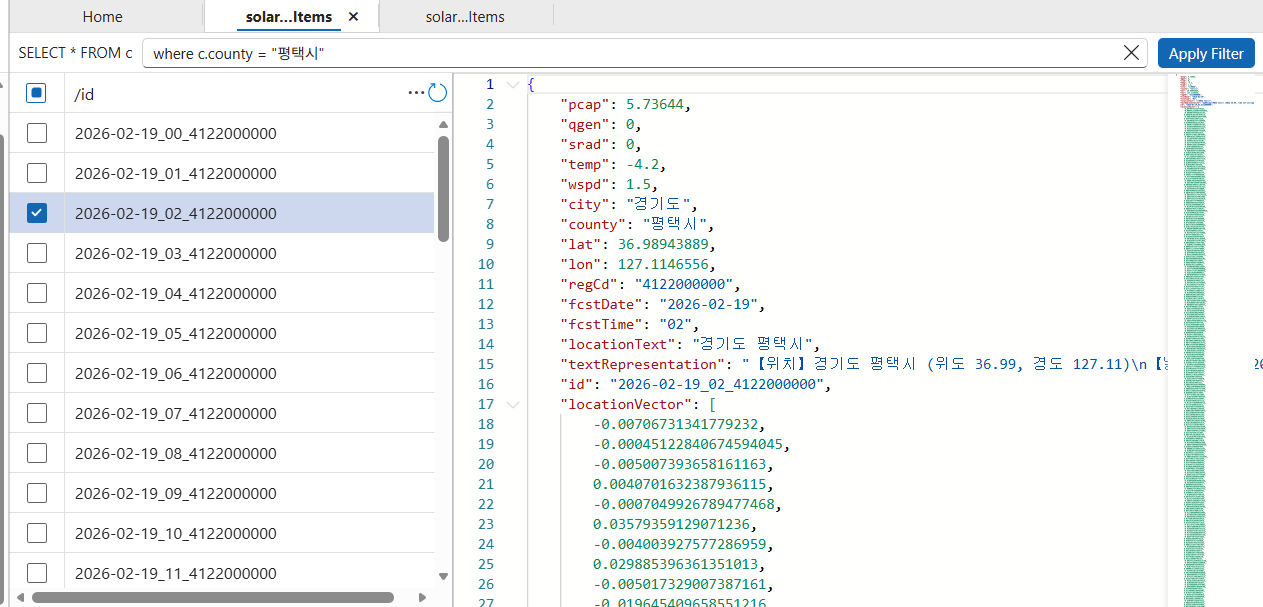
참고로 데이터가 있는데 없다고 출력되고 있다.
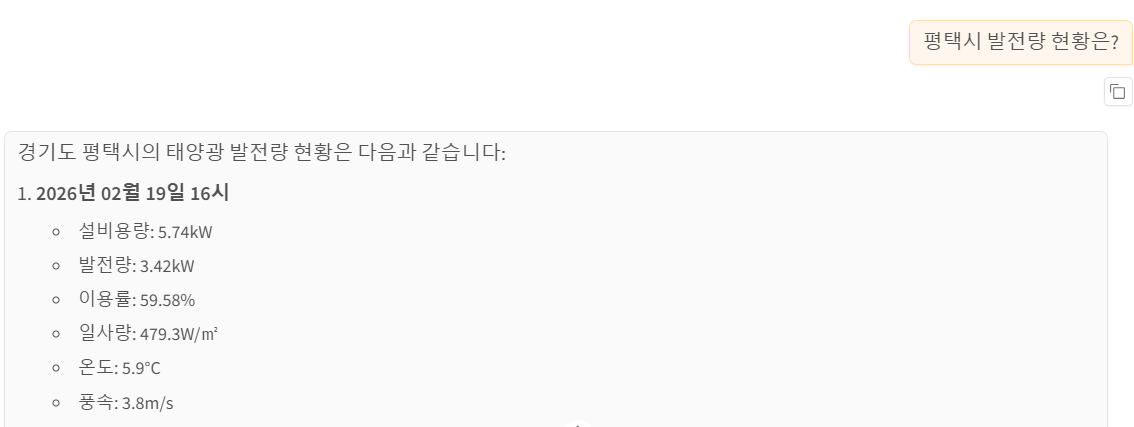
현황을 물어보면 또 있다고 대답한다.
3. 인덱스 생성 방식을 DiskANN, QuantizedFlat 등 다양하게 시도해 본 뒤 속도나 다른 변화가 있는지 비교해보세요.
거리계산 방식은 euclidian 을 기준으로 작업했다.
DiskANN
약 5.5초 걸림
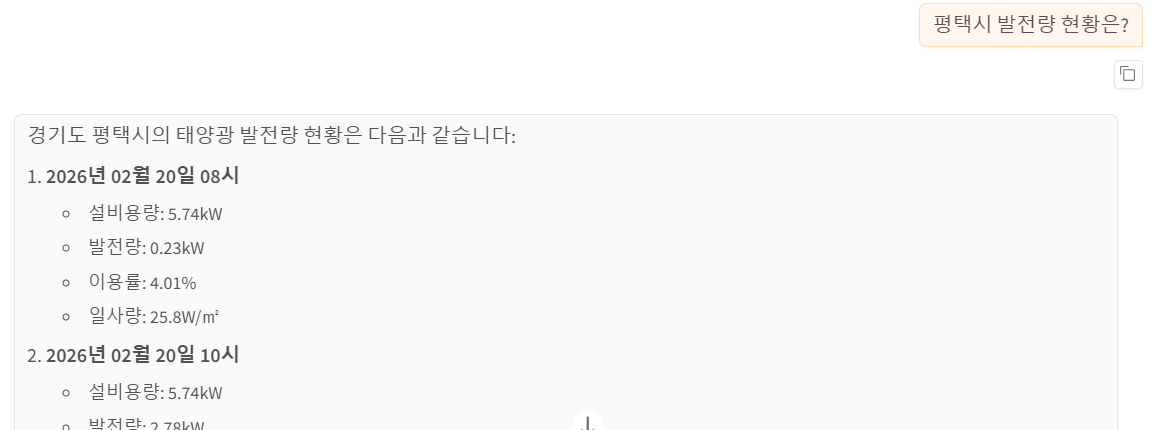
답을 20일 → 19일 순으로 나열
QuantitizedFlat
약 5.4초 걸림
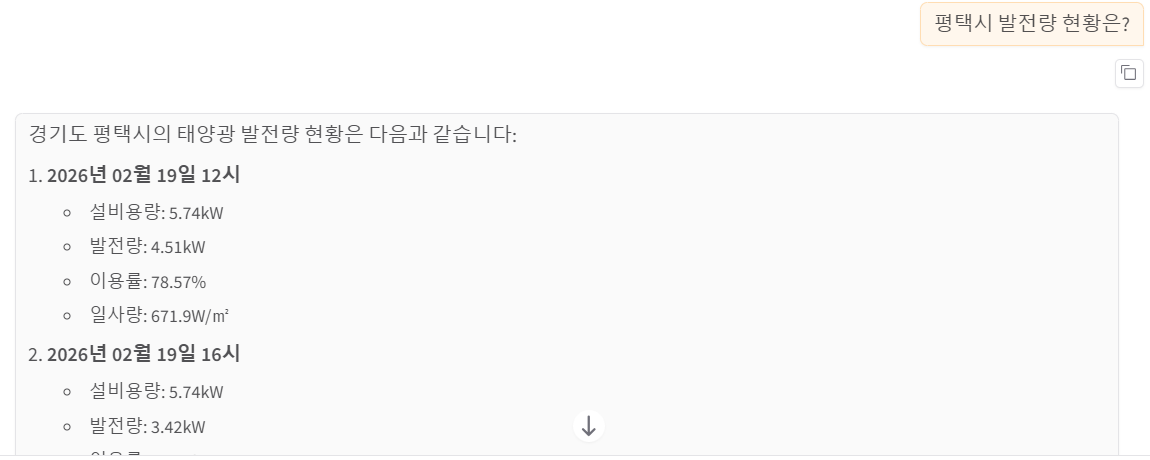
답을 19일 → 20일 순으로 나열
4. text-embedding-3-large 모델과 text-embedding-3-small 모델을 사용했을 때 어느 모델이 더 좋은 결과를 가져오는지 비교 해보세요.
공통: 거리는 euclidian, 인덱싱은 quantitizedFlat
large
small
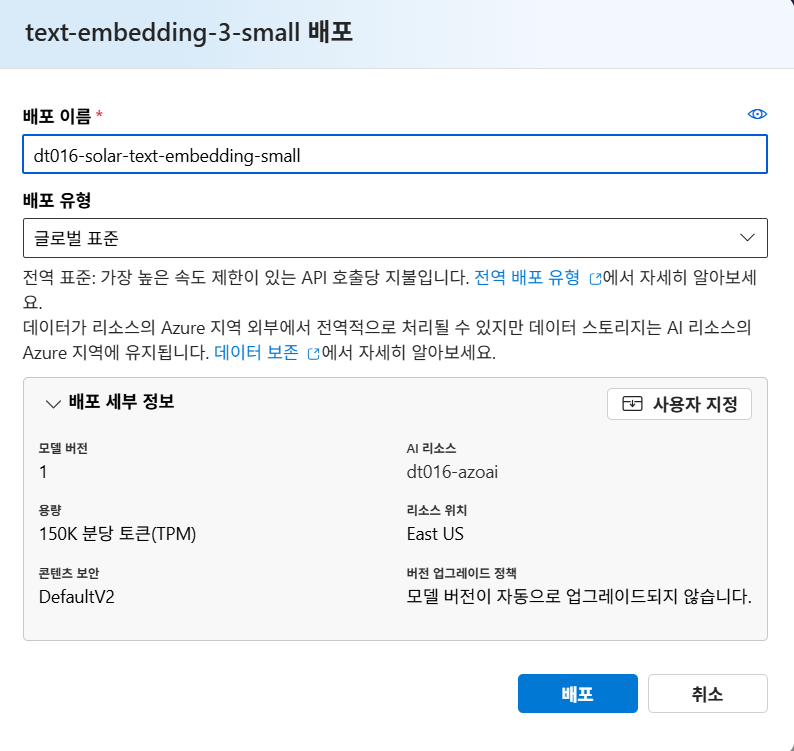
이후 local.settings.json 파일의 OPENAI_EMBEDDING_DEPLOYMENT 수정
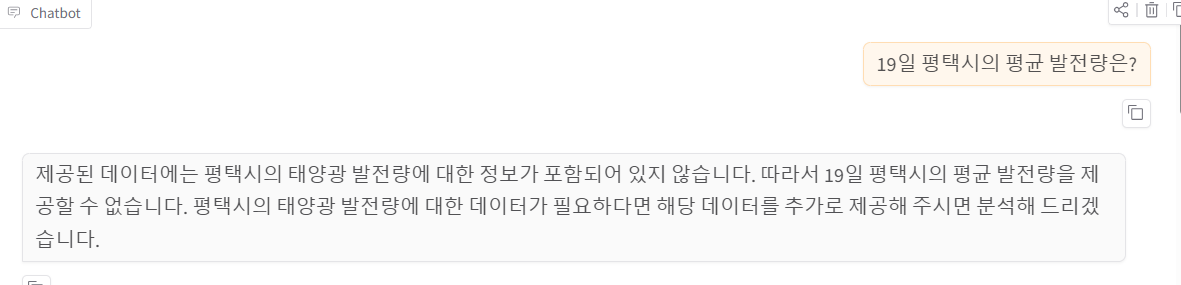
데이터가 이미 있는데도 없다고 한다.
결론은 large모델이 더 좋은 결과를 가져온다.
