
[Azure Data Factory] 필터 활동 (Filter Activity)
1. 개요
필터 활동은 필터 변환과 달리, 파이프라인 내에서 배열(Array) 데이터(예: Lookup, Get Metadata, Web Activity 등에서 반환된 값)를 조건에 따라 필터링하는 활동(Activity)입니다.
- 사용 위치: 파이프라인(컨트롤 플로우)에 배치하여 실행
- 적용 대상: 일반적으로 JSON 배열, 객체 배열 등 구조화된 리스트 데이터
- 주요 예시:
- Get Metadata로 파일 목록을 받아온 후, 특정 확장자만 필터링
- Lookup으로 여러 레코드의 배열을 가져온 후, 특정 조건에 맞는 레코드만 추출
필터 활동 vs 필터 변환 비교
| 구분 | 필터 활동 | 필터 변환 |
|---|---|---|
| 적용 위치 | 파이프라인(Activity) | 매핑 데이터 플로우(Transformation) |
| 적용 대상 | 배열 데이터(Array, JSON 등) | 테이블 데이터(행/컬럼 기반) |
| 조건 작성 방식 | 파이프라인 식(표현식) | 데이터 플로우 내 식(식 편집기) |
| 용도 | 리스트, 메타데이터 등 구조화된 배열 | 레코드(행) 기반 데이터 처리 |
| 주요 사용 예시 | 파일/테이블/객체 리스트 조건 분기 | 데이터 필터링(컬럼 조건에 따라 행 추출) |
2. 실습 준비
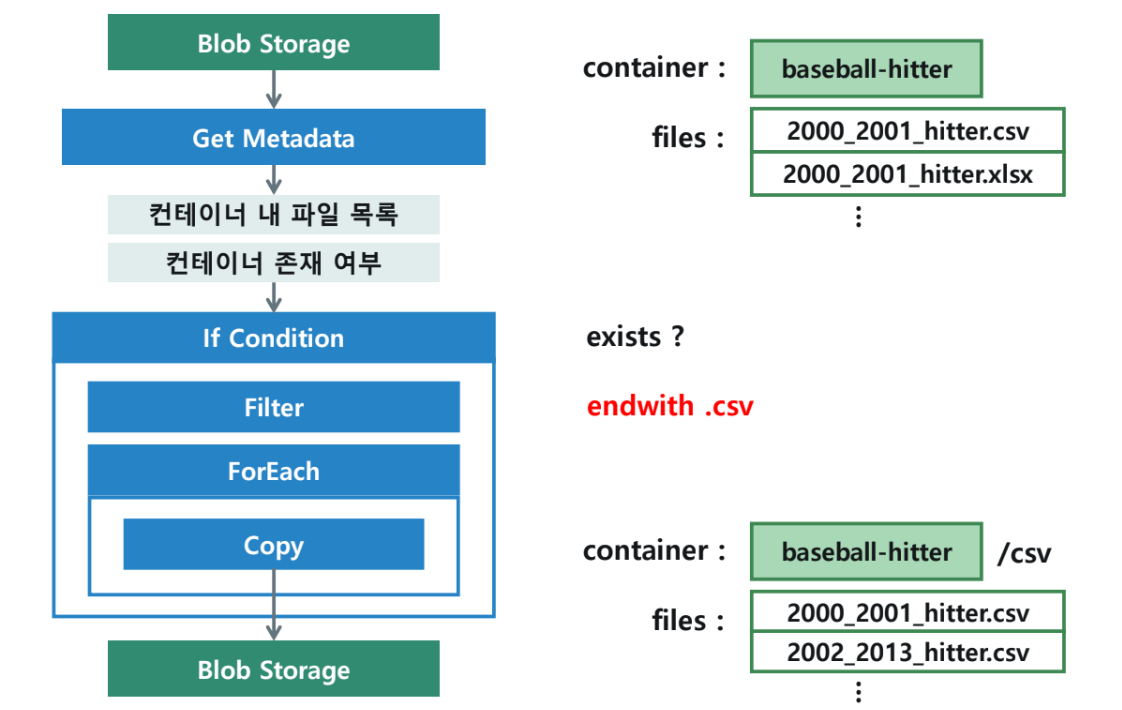
2-1. 입력 컨테이너 및 파일 준비
- Storage Account:
a000storagedemo - Container:
baseball-hitter - 준비 파일 목록:
2000_2001_hitter.csv2000_2001_hitter.xlsx2002_2013_hitter.csv2002_2013_hitter.xlsx2014_hitter.csv2014_hitter.xlsx
2-2. 링크드 서비스 확인
- 이름:
BlobStorage1 - 형식: Azure Blob Storage
- 통합 런타임:
AutoResolveIntegrationRuntime
3. 메인 파이프라인 구성 (FilterCsvFiles_PL)
3-1. Get Metadata 활동 (Get Metadata - List Files)
- 데이터 세트:
baseballinput_DS(baseball-hitter 컨테이너 연결) - 필드 목록:
existschildItems
- 실행 결과(출력 예시):
{ "exists": true, "itemName": "baseball-hitter", "itemType": "Folder", "childItems": [ { "name": "2000_2001_hitter.csv", "type": "File" }, { "name": "2000_2001_hitter.xlsx", "type": "File" }, ... ] }
3-2. If Condition 활동 (If Exist)
- 식(Expression):
@activity('Get Metadata - List Files').output.exists - True 작업: 내부에 필터 및 후속 활동 배치
[중요] 설계 변경 사유
- 제약 사항: 중첩된 ForEach 작업은 지원되지 않으며, ForEach 작업을 If Condition activity 범위 내에서 사용할 수 없습니다.
- 해결 방법: If Condition 내에서 Execute Pipeline 활동을 사용하여 자식 파이프라인을 호출하는 방식으로 구성합니다.
4. 자식 파이프라인 구성 (FilterForEachCopy_PL)
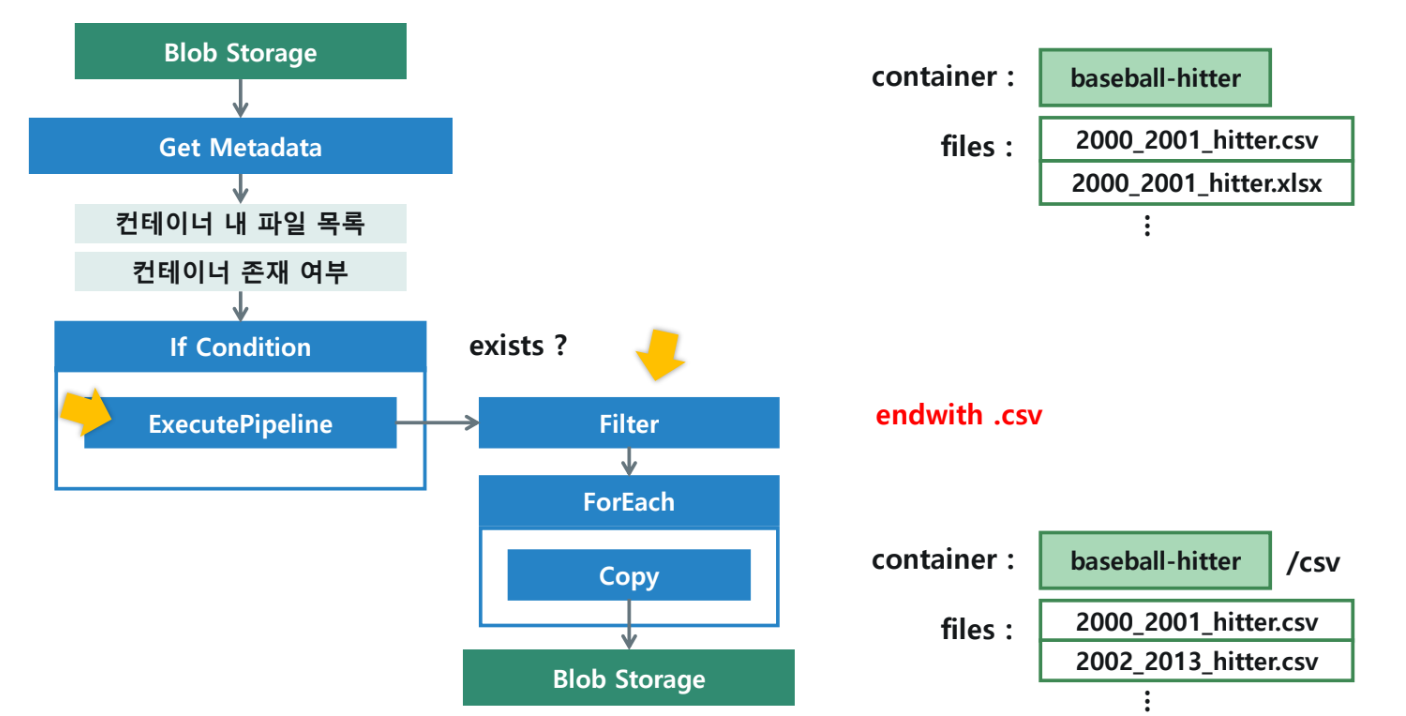
4-1. 매개변수 설정
- 이름:
fileListToProcess - 형식:
Array
4-2. 필터 활동 (Filter CSV)
- 항목(Items):
@pipeline().parameters.fileListToProcess - 조건(Condition):
@and( equals(item().type, 'File'), endswith(item().name, '.csv') )
4-3. ForEach 활동 (ForEach Files)
- 항목(Items):
@activity('Filter CSV').output.value
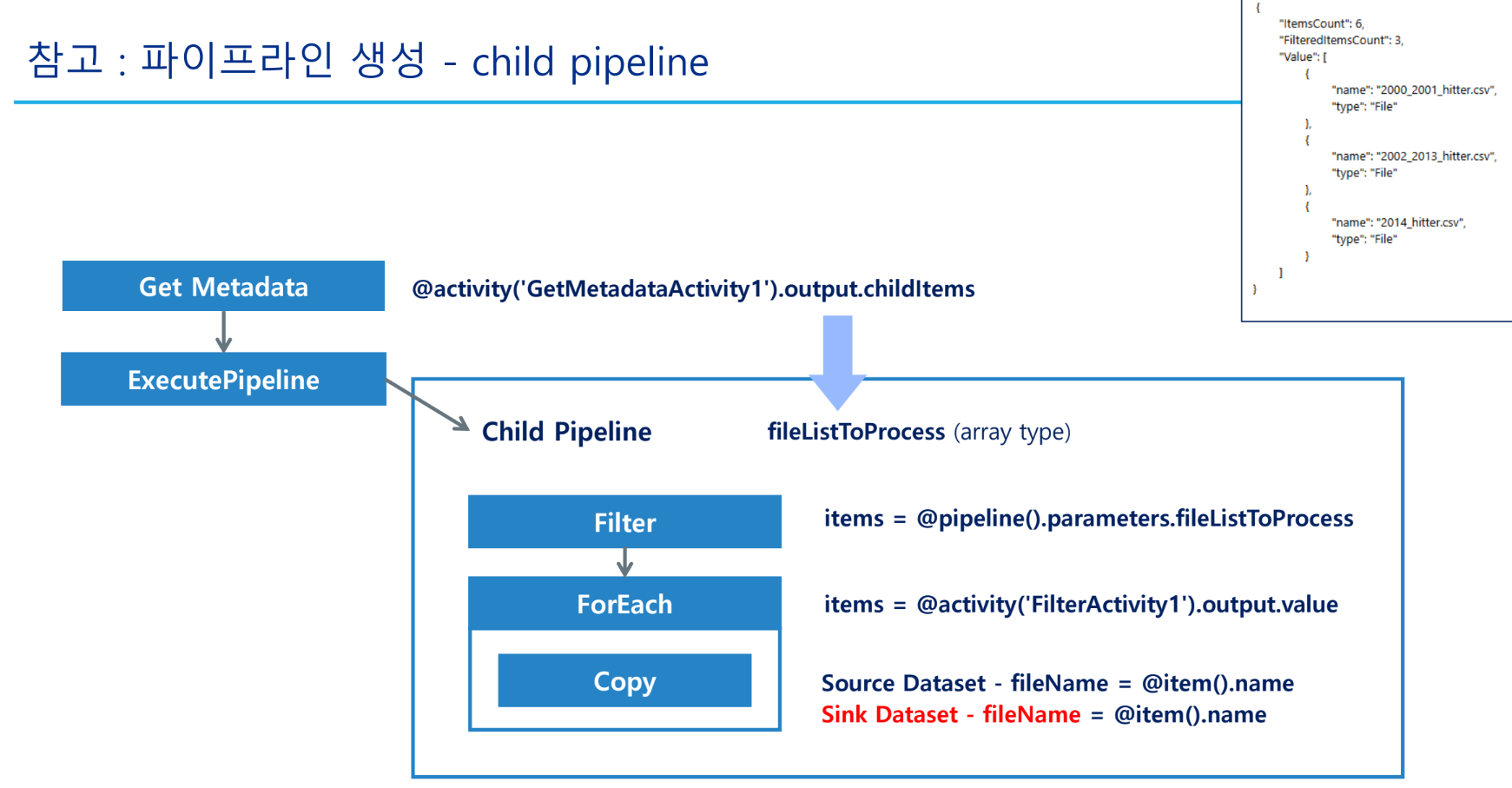
4-4. 복사 활동 (Copy Files)
- 원본 데이터 세트:
baseballCopyInput_DS- 매개변수
fileName사용:@dataset().fileName - 값 매핑:
@item().name
- 매개변수
- 싱크 데이터 세트:
baseballCopyOutput_DS- 경로:
baseball-hitter/csv - 매개변수
fileName사용:@dataset().fileName - 값 매핑:
@item().name
- 경로:
5. 메인 파이프라인 수정 및 실행,
5-1. Execute Pipeline 활동 추가
- If Condition의 True 섹션에
Execute Pipeline활동을 추가합니다. - 호출된 파이프라인:
FilterForEachCopy_PL - 매개변수(
fileListToProcess) 전달:@activity('Get Metadata - List Files').output.childItems
5-2. 실행 결과 확인
- Get Metadata: 성공 (6개 항목 조회)
- If Exist: 성공 (True 분기)
- Execute Pipeline: 성공 (자식 파이프라인 호출)
- 입력 데이터 확인:
.csv와.xlsx파일이 모두 포함된 배열 전달
- 입력 데이터 확인:
- 자식 파이프라인 내 Filter: 성공 (6개 중
.csv파일 3개만 필터링)
5-3. 최종 스토리지 확인,
baseball-hitter/csv폴더 내에 필터링된 파일들이 정상 복사되었는지 확인합니다:2000_2001_hitter.csv2002_2013_hitter.csv2014_hitter.csv
마무리: Filter 활동을 통해 파이프라인 흐름 제어 단계에서 배열 데이터를 정교하게 제어할 수 있으며, If Condition과 결합 시 자식 파이프라인 호출 방식을 활용해야 함을 유의하시기 바랍니다.
[Azure Data Factory] 파생열 및 조건부 분할 변환 (Derived Column & Conditional Split)
1. 개요
파생열 변환 (Derived Column Transformation)
파생열 변환은 기존 데이터 컬럼을 가공하거나 새로운 컬럼을 추가할 때 사용하는 변환 단계입니다. 입력된 데이터의 컬럼 값을 수식/표현식으로 가공하여 파생 컬럼을 생성하거나 기존 컬럼 값을 대체할 수 있습니다.
- 구성 요소:
- 파생 컬럼(Derived Column): 새로운 컬럼 추가 또는 기존 컬럼 값 대체
- 표현식(Expression): 문자열, 수치, 날짜, 논리 연산 등 다양한 함수/연산자 지원
- 미리보기(Data Preview): 변환 결과를 즉시 확인할 수 있는 기능
- 장점:
- 기존 문자열 컬럼에서 특정 패턴 추출하여 파생 정보 제공
- 데이터 전처리 및 가공의 자동화
- 별도의 데이터 소스 수정 없이 컬럼 가공 가능
- 다양한 비즈니스 로직 반영 가능
- 사용 시나리오:
- 성적 데이터에서 점수에 따라 "합격/불합격" 여부 컬럼 추가
- 주문 데이터에서 단가 × 수량으로 총액(Total) 컬럼 추가
- 날짜 데이터를 가공하여 연도, 월 등 새로운 컬럼 추출
조건부 분할 변환 (Conditional Split Transformation)
조건부 분할 변환은 입력 데이터 행(Row)을 지정한 조건(수식/표현식)에 따라 여러 그룹(분기)으로 나누어 주는 변환 단계입니다.
- 구성 요소:
- 분기 조건(Condition): 분리 기준이 되는 조건을 작성하며, 하나의 데이터 행에 대해 첫 번째로 참이 되는 조건에 따라 분기함
- 기본 분기(Default Output): 모든 조건을 만족하지 않을 때 데이터를 분리할 기본 분기 지정
- 미리보기(Data Preview): 분할 결과를 즉시 확인할 수 있는 기능
- 장점:
- 조건별로 데이터 흐름을 분리하여 후처리 용이
- 복잡한 분기 로직을 시각적으로 설계 가능
- 다양한 조건별 분석 및 후속 처리 지원
- 사용 시나리오:
- 점수 90점 이상/80점 이상/기타 등급별로 데이터 분할
- 주문 상태(배송완료/배송중/취소 등)에 따라 데이터 분할
- 거래 금액이 임계값 이상/미만인 고객 분리
2. 실습 준비
2-1. 실습 데이터 (employee.csv)
ID, Name, Salary, Address, Location, Email
1, 김철수, 2750000, 서울 강남구, Korea, chulsu.kim@example1.com
2, 이영희,, Irvine CA, US, younghee.lee@example3.com
3, 박민준, 3820000, 인천 연수구, Korea, minjun.park@example1.com
4, 최지영, 4500000, 부산 해운대구, Korea, jiyoung.choi@example2.com
5, 정윤화, 2810000, 대구 수성구, Korea, yoonhwa.chung@example2.com
6, 강서준, 3540000,, China, seojun.kang@example2.com
7, 윤아영,, 제주 제주시, Korea, ayoung.yoon@example3.com2-2. 컨테이너 및 데이터 세트 준비
- Storage:
a000storagedemo2내employee컨테이너 생성 및employee.csv업로드. - 데이터 흐름 디버그 켜기: Small 컴퓨팅, 1시간 TTL 설정.
- 소스 데이터 세트 (
sourceCsv_DS):employee.csv연결, 첫 번째 행을 머리글로 설정.
3. [실습 1] 데이터 정제 및 파생열 생성
3-1. 주소 누락값 처리 (missingValueAddress)
- 열:
Address - 식:
iif(isNull(Address), 'unknown', Address)
3-2. 급여 누락값 처리 (missingValueSalary)
- 열:
Salary - 식:
iif(isNull(Salary), '2500000', Salary)
3-3. 국가 컬럼 대문자 변환 (upperLocationToCountry)
- 열:
Country(새로 만들기) - 식:
upper(Location)
3-4. 싱크 설정 및 파이프라인 실행
- 싱크(
sink1):employee_processed.csv로 단일 파일 출력. - 파이프라인:
employee1_PL생성 후 데이터 흐름 실행. - 결과:
employee_processed.csv생성 완료.
4. [실습 2] 복합 파생열 및 조건부 분할 (Advanced)
기존 파이프라인에 추가 실습 구성을 연결합니다.
4-1. 급여 등급 컬럼 생성 (addSalaryGrade)
- 열:
SalaryGrade - 식:
iif(toInteger(Salary) <= 3000000, 'Low', iif(toInteger(Salary) <= 4000000, 'Mid', 'High'))
4-2. 이메일 도메인 추출 (addEmailDomain)
- 열:
EmailDomain - 식:
split(Email,'@')
4-3. 조건부 분할 (SplitByLocation)
- 스트림 1 (
headquarters):- 조건:
Location == 'Korea'
- 조건:
- 스트림 2 (
Branch):- 조건: (기본 분기 - 조건을 충족하지 않는 행)
4-4. 다중 싱크 설정
- 본사 싱크 (
headquaterSink):- 파일 이름:
headquarters-employee.csv - 내용: 한국(Korea) 근무자 데이터 5건.
- 파일 이름:
- 지사 싱크 (
branchSink):- 파일 이름:
branch-employee.csv - 내용: 해외(US, China) 근무자 데이터 2건.
- 파일 이름:
5. 최종 결과 확인
headquarters-employee.csv 예시:
ID, Name, Salary, Address, Location, Email, Country, SalaryGrade, EmailDomain
1, 김철수, 2750000, 서울 강남구, Korea, chulsu.kim@example1.com, KOREA, Low, example1.com
3, 박민준, 3820000, 인천 연수구, Korea, minjun.park@example1.com, KOREA, Mid, example1.com
4, 최지영, 4500000, 부산 해운대구, Korea, jiyoung.choi@example2.com, KOREA, High, example2.com
...branch-employee.csv 예시:
ID, Name, Salary, Address, Location, Email, Country, SalaryGrade, EmailDomain
2, 이영희, 2500000, Irvine CA, US, younghee.lee@example3.com, US, Low, example3.com
6, 강서준, 3540000, unknown, China, seojun.kang@example2.com, CHINA, Mid, example2.com6. 실습 마무리
실습이 완료된 후에는 불필요한 비용이 발생하지 않도록 데이터 흐름 디버그 모드를 반드시 중지하고 게시(Publish)를 확인합니다.
[Azure Data Factory] Until 활동 및 Set Variable 활동
1. 개요
Until 활동 (Until Activity)
Until 활동은 지정한 조건이 만족될 때까지 내부에 정의한 액티비티를 반복 실행하는 파이프라인 제어 단계입니다.
- 구성 요소:
- 반복 조건(Expression): 반복을 종료할 시점을 결정하는 논리식 (예:
@equals(variables('fileFound'), true)) - 내부 액티비티(Activities): 반복 루프 내에서 매회 수행할 액티비티 (예: Get Metadata → If Condition → Copy Data 등)
- 대기 간격(Timeout/Interval): 두 반복 사이에 대기할 시간(초 단위)을 설정하여 과도한 호출 방지
- 반복 조건(Expression): 반복을 종료할 시점을 결정하는 논리식 (예:
- 장점:
- 알려지지 않은 반복 횟수를 처리할 수 있어, 파일 도착·상태 변경 등 비동기 이벤트 대기 시 유용
- 복잡한 루프 로직(분기, 에러 처리)을 시각적으로 설계 가능
- 반복 중간에 변수 업데이트나 외부 서비스 호출을 결합하여 동적 파이프라인 구현 지원
- 사용 시나리오:
- 외부 시스템 파일 도착 여부를 확인하여, 파일이 준비될 때까지 반복 폴링
- 메타데이터 기준으로 데이터 누적이 완료될 때까지 복사/병합 작업 반복
- API 호출 응답 상태가 원하는 결과가 나올 때까지 재시도
Set Variable 활동 (Set Variable Activity)
Set Variable 활동은 파이프라인 변수(Pipeline Variable)의 값을 동적으로 변경하는 액티비티입니다.
- 구성 요소:
- 변수 이름(Variable Name): 미리 선언된 파이프라인 변수 중 업데이트할 변수 선택
- 값 표현식(Value/Expression): 고정 값 또는 동적 콘텐츠 (예:
@item().name,@add(variables('count'),1)) - 데이터 형식(Type): String, Bool, Array 등 변수 선언 시 지정된 형식
2. 실습 준비
2-1. 실습 데이터 (employee_batch.csv)
ID, Name, Department, Salary, Location
1, 오준호, IT, 69190, Gwangju
2, 최예린, Finance, 61538, Daegu
3, 강다은, Finance, 55729, Seoul
4, 정우성, Marketing, 46409, Gwangju
5, 오준호, Marketing, 57249, Seoul
6, 서지아, HR, 45784, Incheon
7, 박지훈, HR, 53096, Seoul
8, 오준호, Marketing, 52560, Seoul
9, 강다은, Finance, 57533, Seoul
10, 정우성, IT, 52343, Daegu
11, 최예린, Marketing, 52206, Seoul
12, 강다은, HR, 66980, Gwangju
13, 강다은, Finance, 50801, Incheon
14, 박지훈, Marketing, 64190, Incheon
15, 한수진, Marketing, 61921, Seoul
16, 정우성, Finance, 50986, Daegu
17, 이서연, Marketing, 63225, Daegu
18, 강다은, Finance, 55647, Gwangju
19, 한수진, IT, 53716, Seoul
20, 이서연, Finance, 68355, Incheon
21, 정우성, Finance, 67009, Daegu
22, 김민준, Finance, 64334, Seoul
23, 서지아, Marketing, 69376, Daegu
24, 한수진, Marketing, 57323, Daegu
25, 윤도현, Finance, 49780, Incheon
26, 김민준, Marketing, 47368, Busan
27, 서지아, HR, 57039, Gwangju
28, 박지훈, HR, 51655, Gwangju
29, 오준호, Marketing, 53173, Incheon
30, 최예린, Marketing, 49495, Daegu
31, 윤도현, Finance, 55893, Seoul
32, 박지훈, IT, 67386, Daegu
33, 정우성, Marketing, 67998, Incheon
34, 박지훈, HR, 58403, Gwangju
35, 오준호, Finance, 58121, Daegu
36, 정우성, Marketing, 67303, Gwangju
37, 윤도현, HR, 55966, Seoul
38, 오준호, HR, 45853, Gwangju
39, 이서연, IT, 65530, Gwangju
40, 최예린, Finance, 65153, Busan
41, 윤도현, Finance, 61958, Busan
42, 이서연, IT, 62532, Busan
43, 서지아, IT, 67677, Gwangju2-2. 컨테이너 준비
- input:
employee_batch.csv업로드 완료 - output: 비어있는 상태로 준비
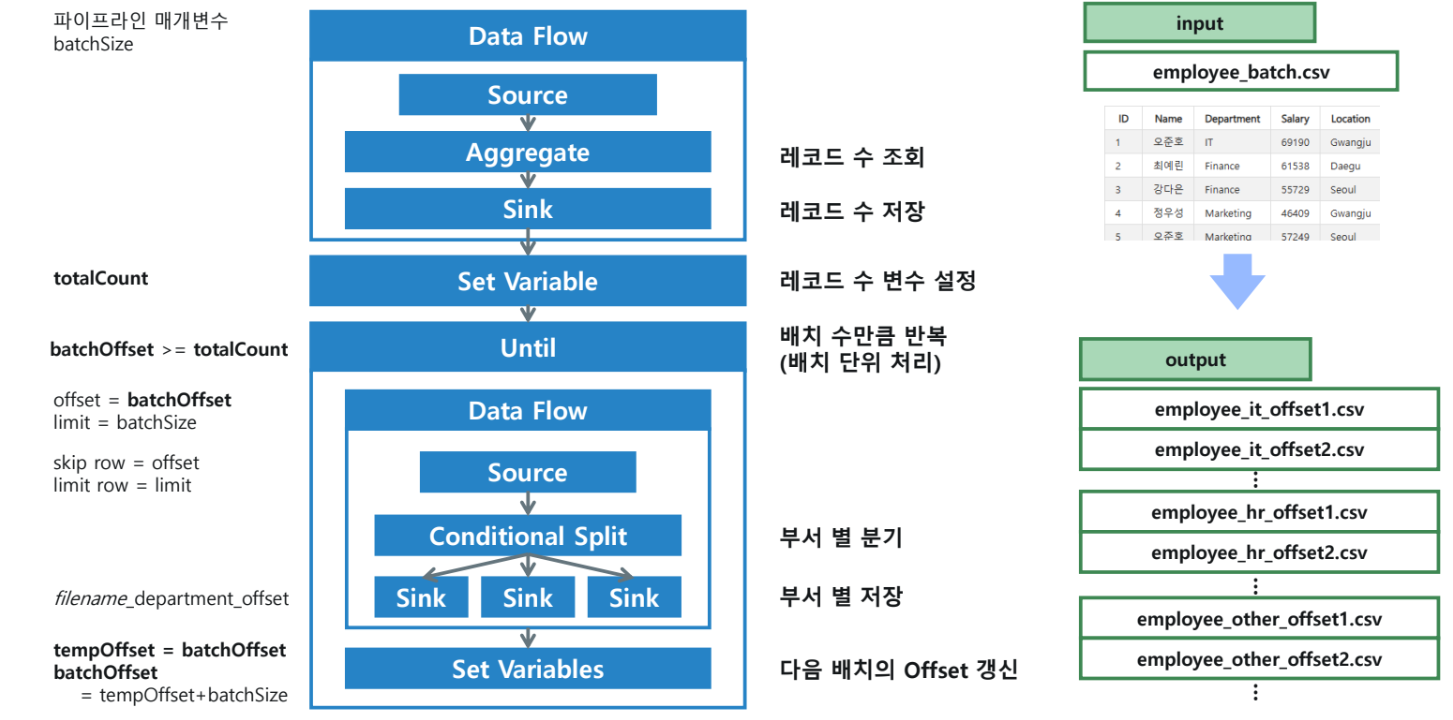
3. [실습 1] 레코드 수 조회 (Data Flow: GetTotalCount_DF)
전체 레코드 수를 계산하여 파일로 저장하는 데이터 플로우를 구성합니다,.
3-1. 소스 및 집계 설정
- 소스 (
employeeBatchData):employee_batch.csv연결. - 집계 (
aggregateCount):- 그룹화 방법: 열별 그룹화 없음.
- 집계 열:
totalRecords - 식:
count(ID).
3-2. 싱크 설정 (sinkTotalCount)
- 싱크 형식: Delimited Text (인라인).
- 파일 이름 옵션: 단일 파일로 출력.
- 단일 파일로 출력:
total_count.csv. - 최적화: 단일 파티션 설정.
4. [실습 2] 배치 및 분기 처리 (Data Flow: ProcessEmployeeBatches_DF)
데이터를 배치 단위로 읽어 부서별로 분기하여 저장합니다,.
4-1. 데이터 플로우 매개변수 정의
offset(integer): 시작 지점limit(integer): 읽어올 행 수
4-2. 소스 설정 (employeeBatchData2)
- 원본 옵션:
- 건너뛰기 줄 수:
$offset - 행 제한:
$limit
- 건너뛰기 줄 수:
4-3. 조건부 분할 (SplitByDepartment)
- HR:
Department=='HR' - IT:
Department=='IT' - OtherEmployees: (조건을 충족하지 않는 행)
4-4. 다중 싱크 및 동적 파일명 설정
- SinkHR:
concat('employee_hr_',toString($offset),'.csv') - SinkIT:
concat('employee_it_',toString($offset),'.csv') - sinkOther:
concat('employee_others_',toString($offset),'.csv') - 모든 싱크는 '단일 파일로 출력' 및 '단일 파티션' 설정을 사용합니다.
5. 파이프라인 구성 (ProcessEmployeeBatch_PL)
5-1. 매개변수 및 변수 선언
- 매개변수:
batchSize(Int, 기본값: 50) - 변수:
batchOffset(Integer, 기본값: 0)totalCount(Integer, 기본값: 0)tempOffset(Integer, 기본값: 0)
5-2. 전체 레코드 수 조회 및 저장
- Data Flow 활동 (
GetDataFlowTotalCount):GetTotalCount_DF실행. - Set Variable 활동 (
SetTotalCount): 조회된 행 수를 변수에 저장.- 값 식:
@activity('GetDataFlowTotalCount').output.runStatus.metrics.sinkTotalCount.sources.employeeBatchData.rowsRead ```,
- 값 식:
5-3. Until 활동 (UntilAllBatches)
- 반복 종료 조건:
@greaterOrEquals(variables('batchOffset'), variables('totalCount')) ```,
5-4. Until 내부 액티비티 구성
- Data Flow 활동 (
ProcessBatchDataFlow): 데이터를 배치 단위로 처리.offset파라미터 매핑:variables('batchOffset')limit파라미터 매핑:pipeline().parameters.batchSize
- Set Variable 활동 (
SetOffset): 현재 오프셋 임시 저장.tempOffset=variables('batchOffset')
- Set Variable 활동 (
SetOffset2): 다음 실행을 위한 오프셋 갱신.batchOffset=@add(variables('tempOffset'), pipeline().parameters.batchSize)
6. 결과 확인 및 마무리,
6-1. 파이프라인 실행 결과 모니터링
GetDataFlowTotalCount: 성공 (200개 레코드 조회 확인)SetTotalCount: 성공 (totalCount = 200 설정)UntilAllBatches: 성공 (배치 크기 50 기준 총 4회 반복 실행)ProcessBatchDataFlow(각 회차): 성공
6-2. 최종 생성 파일 목록 (output 컨테이너)
total_count.csv(200 저장 확인)employee_hr_0.csv,employee_hr_50.csv,employee_hr_100.csv,employee_hr_150.csvemployee_it_0.csv,employee_it_50.csv,employee_it_100.csv,employee_it_150.csvemployee_others_0.csv,employee_others_50.csv,employee_others_100.csv,employee_others_150.csv
6-3. 파일 내용 상세 예시,,
- HR 0번 오프셋: ID 6(서지아), 7(박지훈), 12(강다은) 등 포함.
- IT 0번 오프셋: ID 1(오준호), 10(정우성), 19(한수진) 등 포함.
- Others 0번 오프셋: ID 2(최예린), 3(강다은), 4(정우성) 등 포함.
실습 완료 후에는 비용 발생 방지를 위해 데이터 흐름 디버그 모드를 반드시 중지하십시오.
[Azure Data Factory] Join 변환 (Join Transformation)
1. Join 변환 개요
Join 변환(Join Transformation)은 두 개의 입력 스트림을 지정된 키를 기준으로 병합(Join)하는 데이터 변환 단계입니다.,
구성 요소
- Join 조건(Join Conditions): 두 입력 간 조인할 기준 컬럼 설정 (예: ID, Email 등)
- Join 유형(Join Type): Inner, Left Outer, Right Outer, Full Outer 중 선택
- 키 충돌 시 처리 방식: 동일한 이름의 컬럼이 양쪽에 있는 경우 우선순위 설정 가능
사용 시나리오
- 사용자 정보와 주문 정보를 ID 기준으로 병합
- 로그 정보와 에러 코드 목록을 조인하여 분석
- 마스터 테이블과 세부 정보 테이블 병합
장점
- 다양한 조인 방식 제공으로 유연한 병합 구조 설계 가능
- 조건 기반 병합 처리로 데이터 정합성 확보
- 하나의 데이터 흐름 안에서 복잡한 관계형 연산 처리 가능
2. Join 유형별 상세 설명
1) Inner Join (ID - 고객ID 기준)
두 테이블 모두에 조인 키가 존재하는 데이터만 반환합니다.
| A.ID | A.이름 | A.도시 | B.주문ID | B.고객ID | B.상품명 |
|---|---|---|---|---|---|
| 1 | 김철수 | 서울 | 101 | 1 | 노트북 |
| 1 | 김철수 | 서울 | 104 | 1 | 모니터 |
| 2 | 이영희 | 부산 | 102 | 2 | 마우스 |
2) Full Outer Join
양쪽 테이블의 모든 데이터를 반환하며, 짝이 없는 경우 NULL로 표시됩니다.
| A.이름 | A.ID | A.도시 | B.주문ID | B.고객ID | B.상품명 |
|---|---|---|---|---|---|
| 김철수 | 1 | 서울 | 101 | 1 | 노트북 |
| 김철수 | 1 | 서울 | 104 | 1 | 모니터 |
| 이영희 | 2 | 부산 | 102 | 2 | 마우스 |
| 박민준 | 3 | 서울 | NULL | NULL | NULL |
| 최지우 | 5 | 인천 | NULL | NULL | NULL |
| NULL | NULL | NULL | 103 | 4 | 키보드 |
3) Left Join
왼쪽 테이블(고객 정보)의 모든 데이터와 오른쪽 테이블(주문 정보)의 매칭되는 데이터를 반환합니다.
| A.ID | A.이름 | A.도시 | B.주문ID | B.고객ID | B.상품명 |
|---|---|---|---|---|---|
| 1 | 김철수 | 서울 | 101 | 1 | 노트북 |
| 1 | 김철수 | 서울 | 104 | 1 | 모니터 |
| 2 | 이영희 | 부산 | 102 | 2 | 마우스 |
| 3 | 박민준 | 서울 | NULL | NULL | NULL |
| 5 | 최지우 | 인천 | NULL | NULL | NULL |
4) Right Join
오른쪽 테이블(주문 정보)의 모든 데이터와 왼쪽 테이블(고객 정보)의 매칭되는 데이터를 반환합니다.
| A.ID | A.이름 | A.도시 | B.주문ID | B.고객ID | B.상품명 |
|---|---|---|---|---|---|
| 1 | 김철수 | 서울 | 101 | 1 | 노트북 |
| 1 | 김철수 | 서울 | 104 | 1 | 모니터 |
| 2 | 이영희 | 부산 | 102 | 2 | 마우스 |
| NULL | NULL | NULL | 103 | 4 | 키보드 |
3. 실습 준비
3-1. 실습 데이터 준비
- customers.csv
ID, Name, Address 1, 김철수, 서울 2, 이영희, 부산 3, 박민준, 서울 5, 최지우, 인천 - orders.csv
OrderID, CustomerID, ProductName 101, 1, 노트북 102, 2, 마우스 103, 4, 키보드 104, 1, 모니터
3-2. 컨테이너 준비,
- input:
customers.csv,orders.csv업로드 - output: 비어있는 상태로 준비
4. [실습 1] 기본 Join 데이터 플로우 구성
4-1. 소스 설정,
- Source 1 (
customerData):CustomersInput_DS연결 (customers.csv). - Source 2 (
ordersData):Orderinput_DS연결 (orders.csv).- 두 소스 모두 프로젝션 가져오기를 통해 ID, OrderID 등을 integer 형식으로 정의합니다.,
4-2. Join 변환 설정 (joinCustomerOrders)
- 왼쪽 스트림:
customerData - 오른쪽 스트림:
ordersData - 조인 유형:
내부(Inner) - 조인 조건:
- 왼쪽:
ID - 오른쪽:
CustomerID
- 왼쪽:
4-3. 싱크 설정 (sinkJoinedData)
- 데이터 세트:
JoinedOutputCSV_DS - 설정: 단일 파티션, 단일 파일로 출력.
- 파일명:
joined_customer_orders.csv
4-4. 파이프라인 실행 및 결과 확인,
- 파이프라인:
JoinCustomerOrders_PL - 활동:
ExecuteJoin_DF(Join_DF 실행) - 결과:
output컨테이너에 3개의 행이 포함된 파일 생성 확인.,
5. [실습 2] 고급 데이터 변환 (집계 및 필터)
5-1. 고객별 주문 건수 집계 (aggregateTotalOrdersByCustomer)
- 들어오는 스트림:
joinCustomerOrders - 그룹화 방법:
ID,Name - 집계 컬럼:
totalOrders - 식:
count(OrderID) - 결과 싱크:
customer_total_orders.csv
5-2. 서울 주문 데이터 필터링 (filterSeoulCustomers)
- 들어오는 스트림:
joinCustomerOrders - 필터 식:
Address == '서울' - 결과 싱크:
seoul_customer_orders.csv,
6. 최종 실행 결과 요약
- joined_customer_orders.csv: 조인된 전체 데이터 (3건)
- customer_total_orders.csv:
- 이영희: 1건
- 김철수: 2건
- seoul_customer_orders.csv:
- 김철수(서울)의 주문 데이터 2건 (모니터, 노트북)
실습 마무리: 모든 작업이 완료되면 비용 발생 방지를 위해 데이터 흐름 디버그 모드를 종료합니다.
