
제공해주신 소스 파일 "03-30-2.03 데이터플로우_v12.pdf"의 모든 페이지 내용을 생략 없이, 특히 누락되었던 적용 예시와 수식들을 원문 그대로 포함하여 정리해 드립니다. 여러 줄로 된 부분은 합치지 않고 소스 형태를 유지했습니다.
[Azure Data Factory] 데이터 플로우
1. 매핑 데이터 플로우 개요
매핑 데이터 플로우는 데이터 변환을 시각적으로 설계할 수 있는 기능으로, 코딩 없이 GUI 기반으로 데이터 흐름을 정의하고 실행할 수 있도록 지원합니다.
특징
- 코드 작성 없이 ETL 작업 가능
- 병렬 처리 기반 대용량 데이터 변환
- Spark 기반 백엔드 자동 실행
- ADF 파이프라인 내 액티비티로 실행 가능
적용 예시
- Raw 데이터 정제 및 변환 작업
- 데이터 웨어하우스 적재 전 변환
- 로그 데이터의 전처리 및 분석 준비
2. 주요 구성요소 및 기능
- Source: 데이터 가져오기 (Blob, SQL 등)
- Transformation: 변환 로직 적용
- Sink: 결과 저장 (Blob, SQL 등)
변환 기능
- Select: 컬럼 선택 및 이름 변경
- Filter: 조건에 따라 행 필터링
- Join: 다른 스트림과 조인
- Aggregate: 그룹화 및 집계
- Derived Column: 계산 컬럼 생성
- Sort: 정렬 수행
- Pivot: 데이터 형태 변환
변환 기능 적용 예시
- 시험 점수를 과목별 평균으로 집계
- 이벤트 로그에서 '오류'만 필터링하여 저장
흐름 제어 기능
- Conditional Split: 조건에 따라 경로 분기
- Exists: 조건 충족 여부 확인
- Lookup: 외부 값 참조
흐름 제어 기능 적용 예시
- 고객 나이에 따라 다른 테이블에 저장
- 기존 고객 여부 확인 후 신규 등록 여부 결정
3. Pipeline vs MDF 및 실행 방식
역할 구분
| 구분 | 파이프라인 | 데이터 플로우 |
|---|---|---|
| 역할 | 실행 제어 / 전체 흐름 관리 | 데이터 변환 수행 |
데이터 흐름 디버그
- 디버그 모드: 파이프라인 실행 전, 결과를 미리 확인 가능하며 Sample Data 기반으로 변환 결과를 확인합니다.
- 예시
- 변환 로직 개발 중 오류 확인
- 실시간으로 컬럼 파생 결과 시각화 확인
MDF 실행 방식
- 파이프라인 내 Data Flow Activity로 호출
- Integration Runtime(IR)을 통해 Spark 클러스터 생성 (클러스터는 자동 생성 및 종료)
- 예시
- 주기적으로 정해진 시간마다 ETL 실행
- 조건 만족 시 트리거로 Data Flow 자동 실행
4. [실습 준비] 데이터 및 환경 세팅
실습 데이터: Student Performance in Exams
- Kaggle 데이터 활용 (StudentsPerformance.csv)
- 컬럼 구성
- gender, race/ethnicity, parental level of education, lunch, test preparation course, math score, reading score, writing score
환경 준비
- 실습 컨테이너 준비:
input,output컨테이너의 기존 데이터 삭제 후StudentsPerformance.csv업로드. - 링크드 서비스 준비:
BlobStorage1(Azure Blob Storage) 생성 및 연결 테스트 성공 확인. - 데이터세트 생성:
- 입력(
StudentsInputDS):input컨테이너,StudentsPerformance.csv참조, 첫 번째 행을 머리글로 설정, 스키마 가져오기(연결/저장소에서). - 출력(
StudentsOutputDS):output컨테이너 참조, 첫 번째 행을 머리글로 설정.
- 입력(
5. [실습 1] 데이터 정제 및 등급 부여
5-1. 매핑 데이터 플로우 생성 및 소스 추가
- 이름:
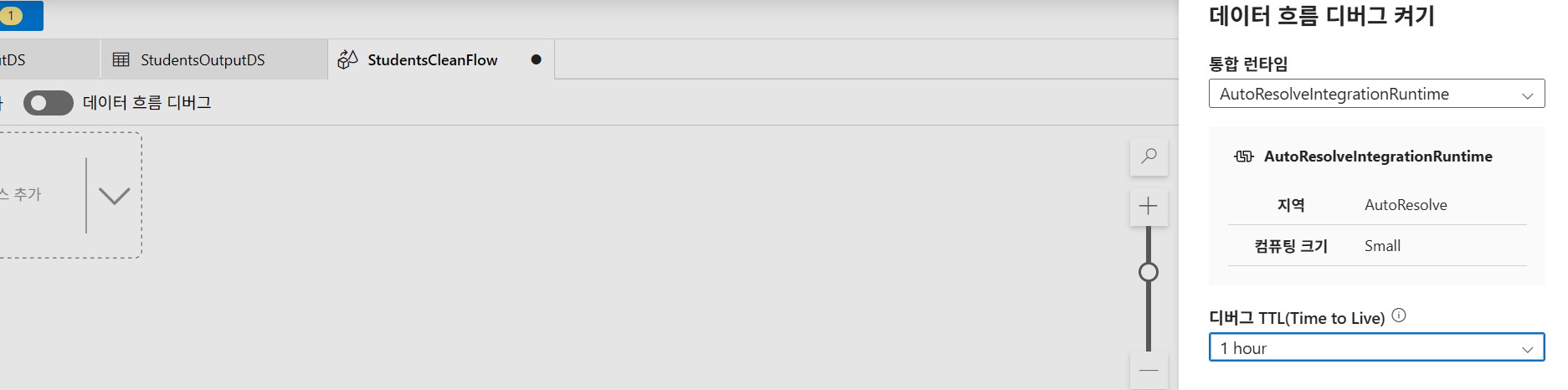
StudentsCleanFlow - 데이터 흐름 디버그 켜기: AutoResolveIntegrationRuntime, Small, TTL 1시간 설정.
- 소스(
Students):StudentsInputDS연결 후 프로젝션 가져오기를 통해 데이터 형식 검색.
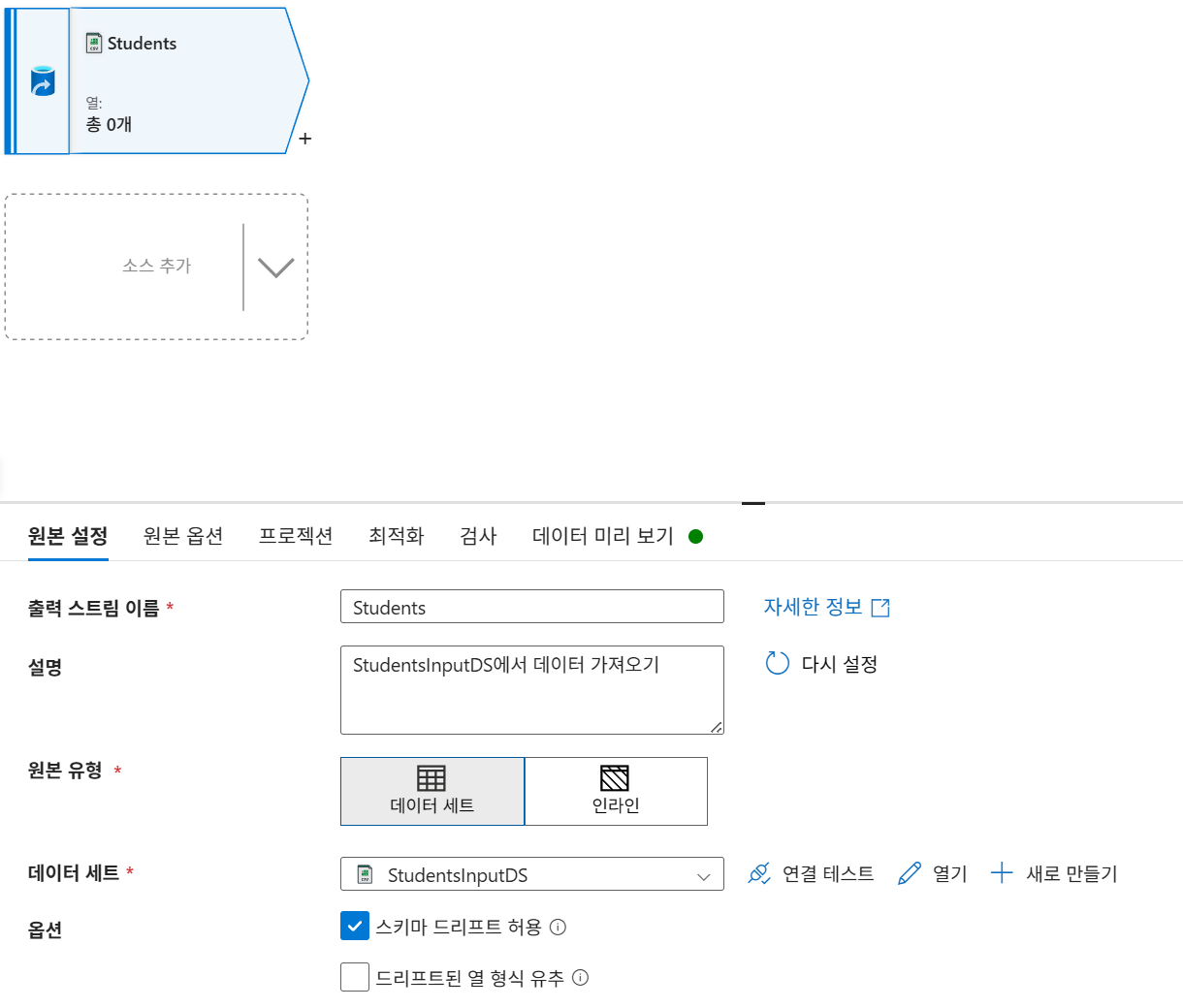
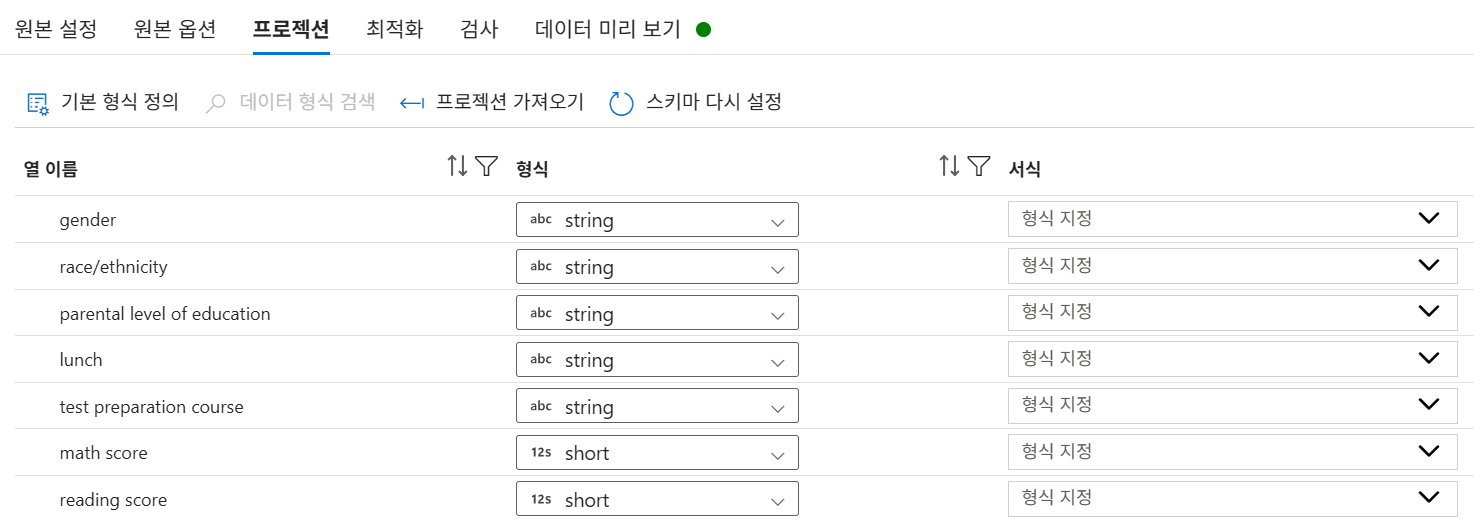
스키마 드리프트: 원본이 아닌 별도의 테이블을 만들어 사용할 때 어느정도의 오류는 ok 하는 기능
5-2. 평균 점수 계산 (Derived Column - AverageScore)
컴포넌트 옵션에는 항상 출력, 입력 스트림이 존재함
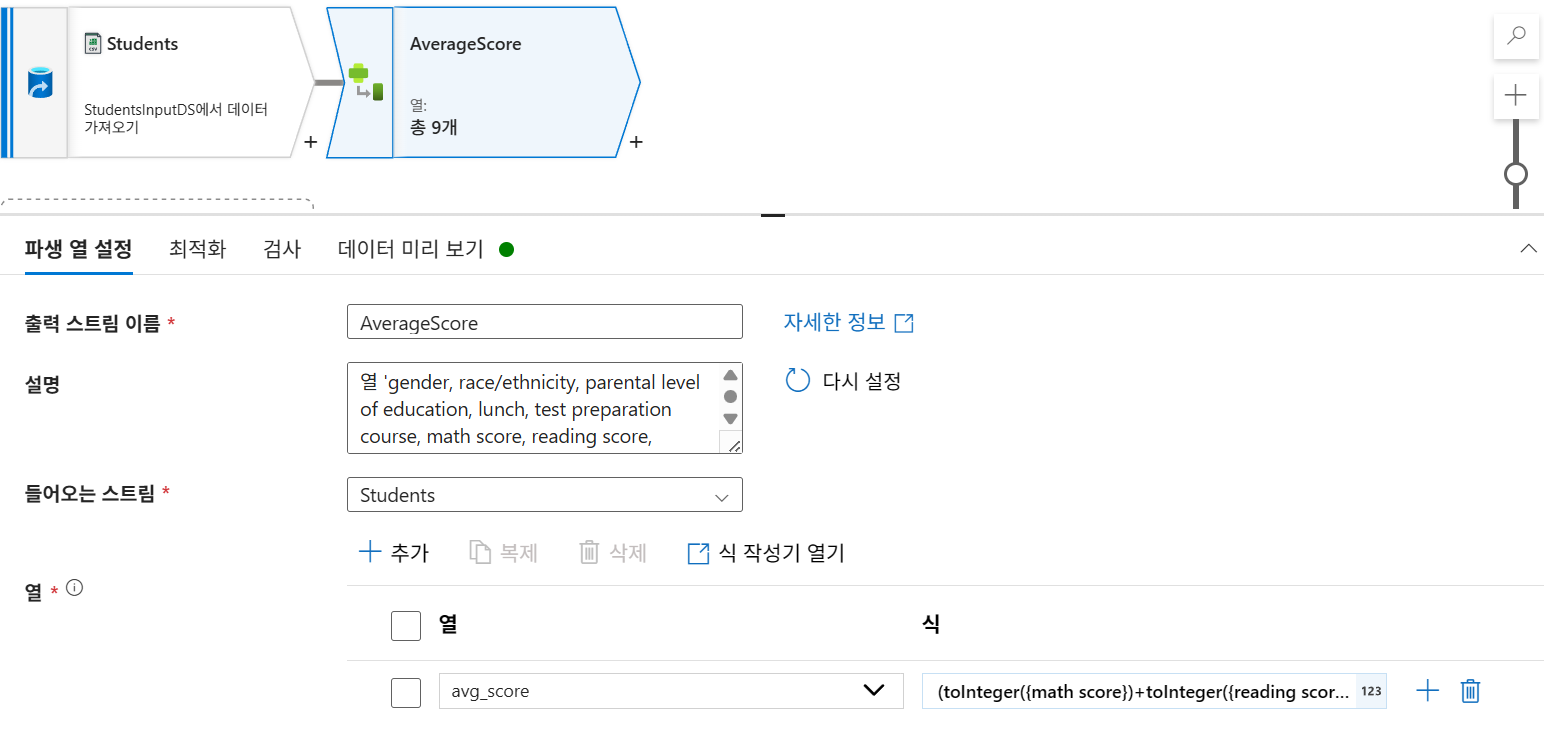
+누른 후파생 열추가- 출력 스트림 이름:
AverageScore - 열 이름:
avg_score - 식:
(toInteger({math score})+toInteger({reading score})+toInteger({writing score}))/3
5-3. 등급 부여 (Derived Column - GradeLevel)
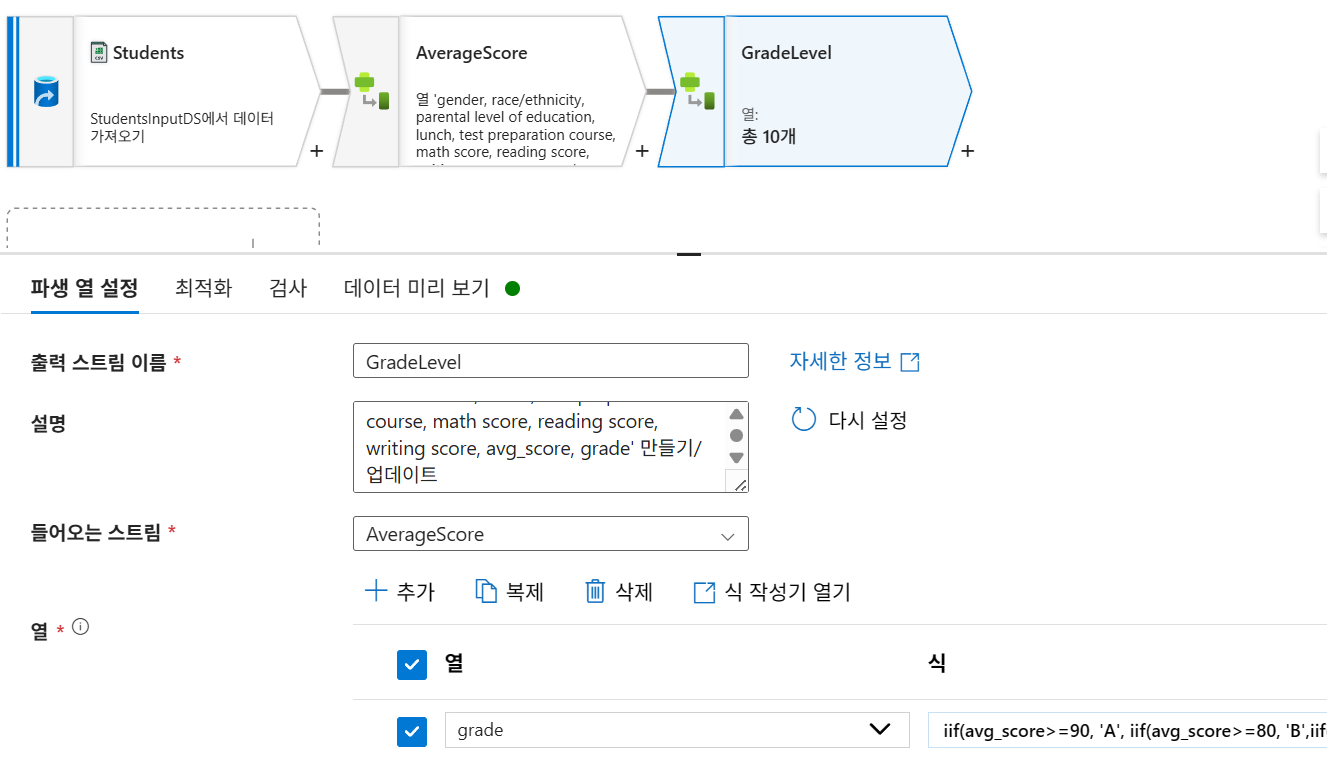
- 출력 스트림 이름:
GradeLevel - 열 이름:
grade - 식:
iif(avg_score>=90, 'A',
iif(avg_score>=80, 'B',
iif(avg_score>=70, 'C',
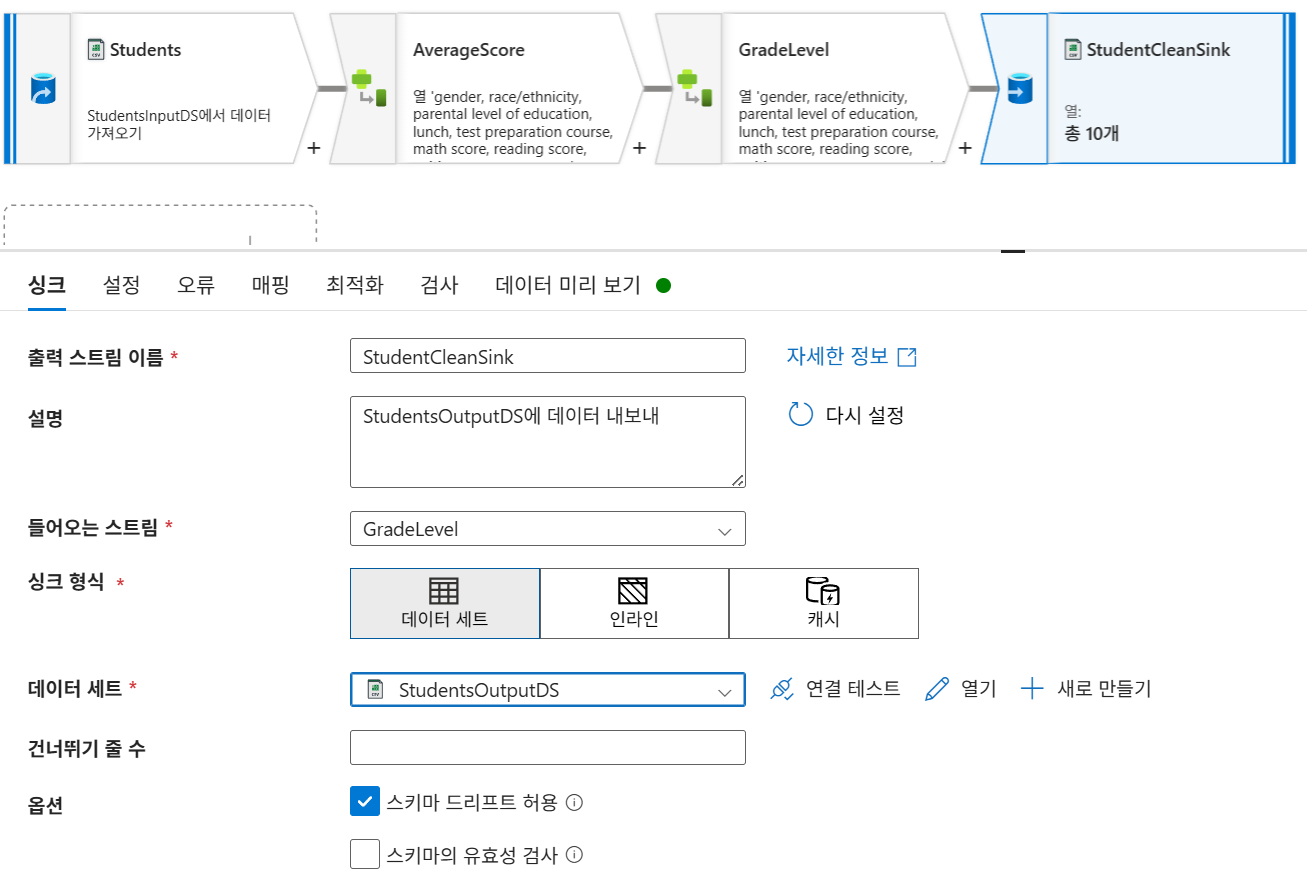
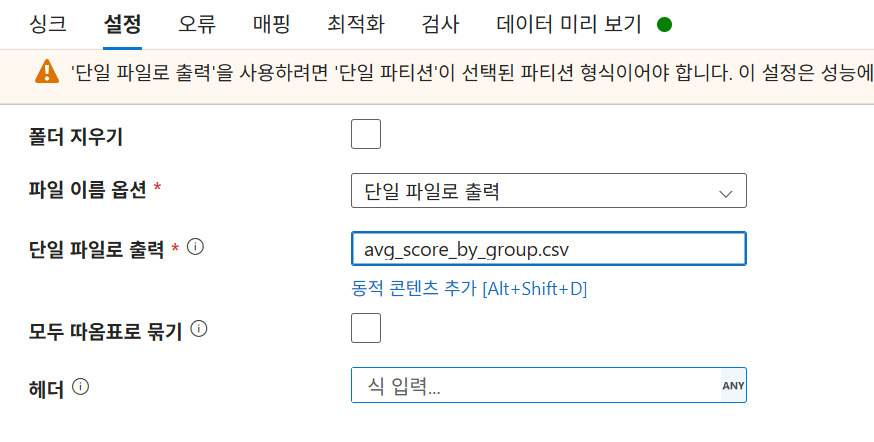
iif(avg_score>=60, 'D', 'F'))))5-4. 싱크 설정 (StudentCleanSink)
-
데이터 세트:
StudentsOutputDS -
설정: 파티션 설정을 '단일 파티션'으로 변경 후 단일 파일로 출력 선택. (기본적으로는 분산 저장을 지원)
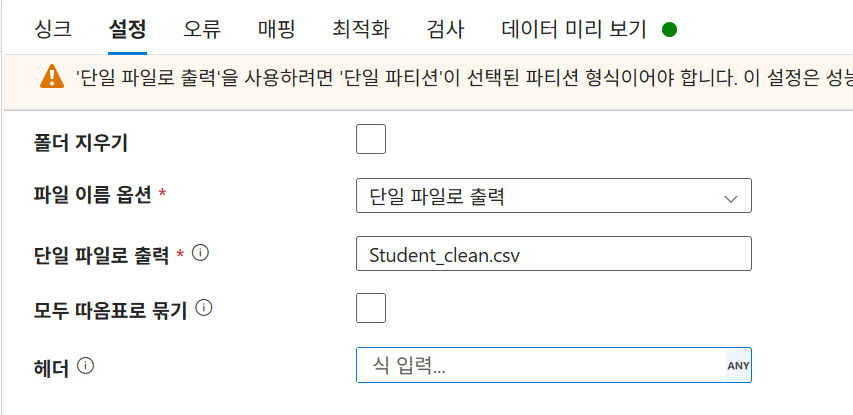
-
파일명:
Students_clean.csv
5-5. 파이프라인 실행 및 결과 확인
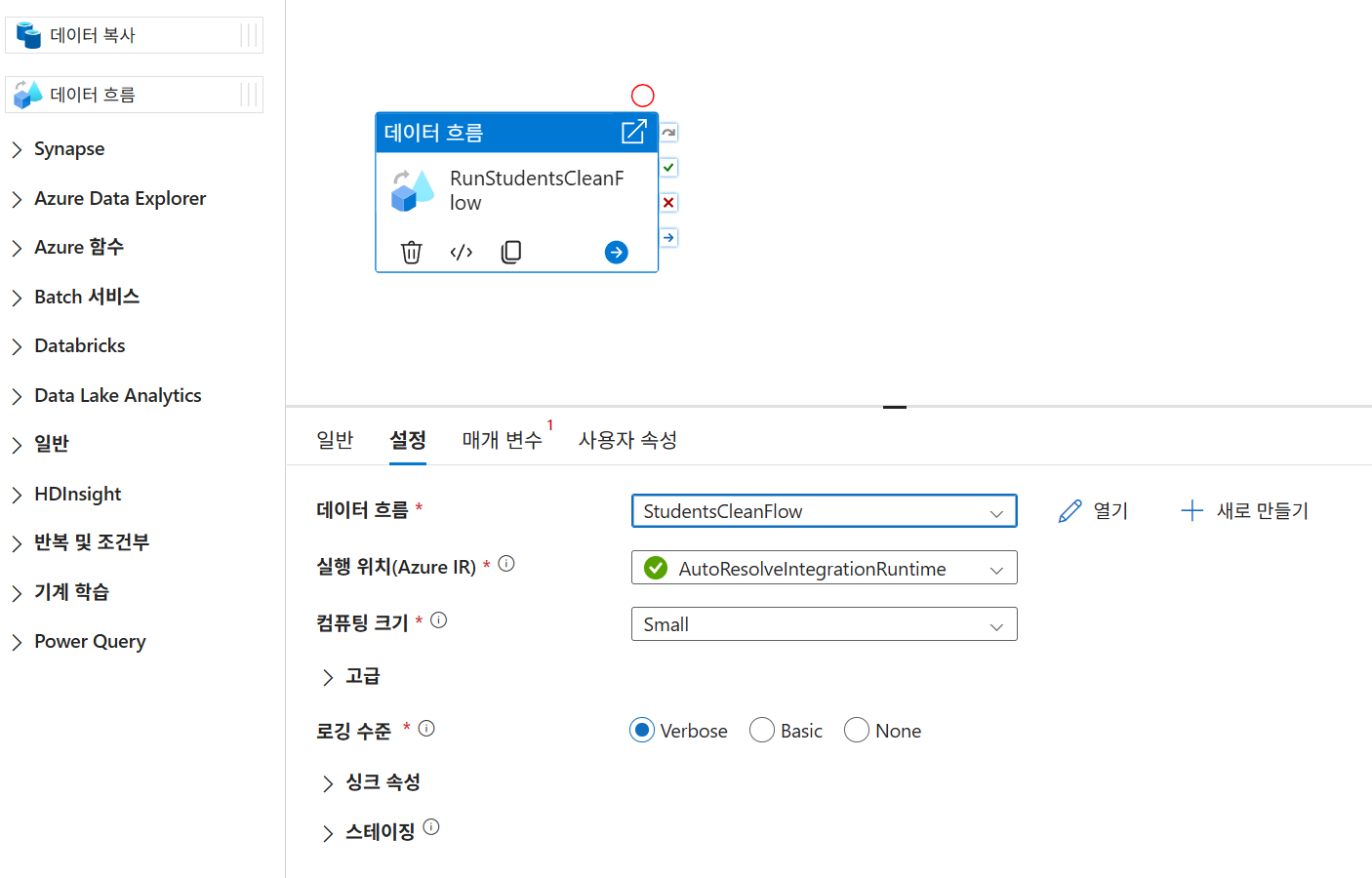
- 파이프라인 생성:
StudentsPerformancePipeline에Data Flow활동(RunStudentsCleanFlow) 추가. - 실행: 모두 게시 후 디버그 실행.
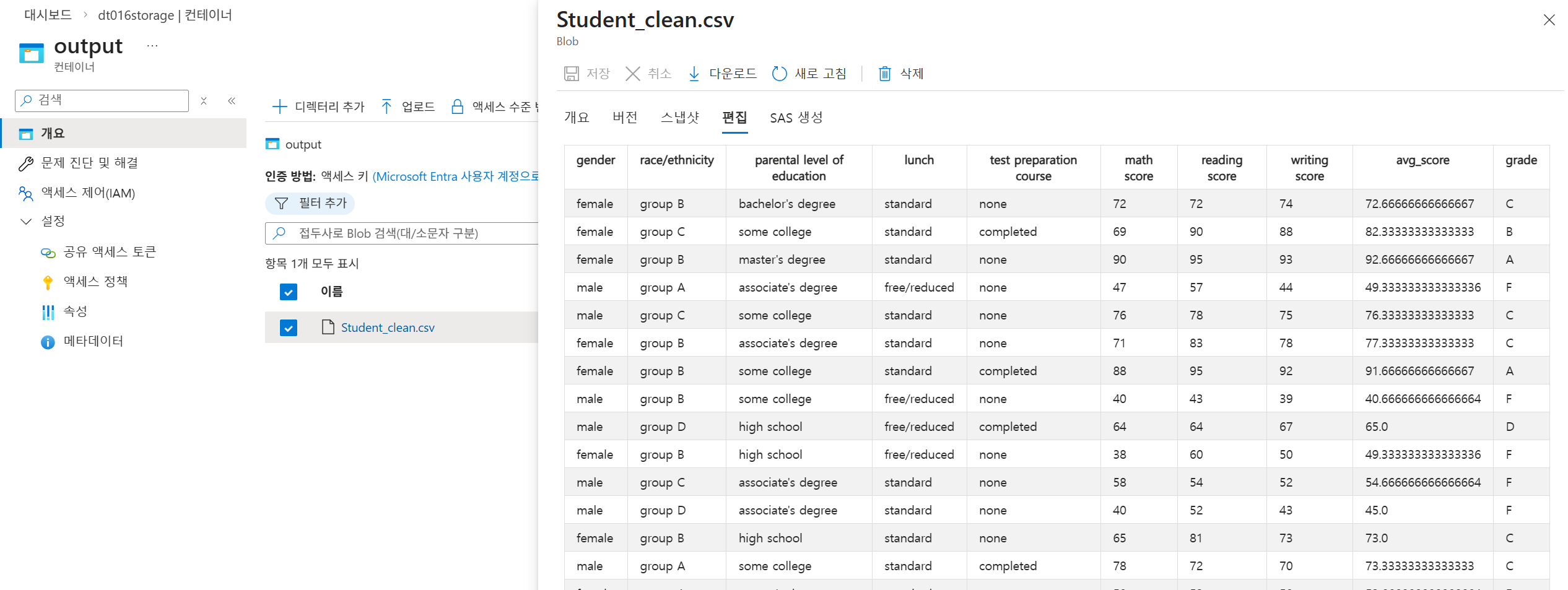
- 결과 확인:
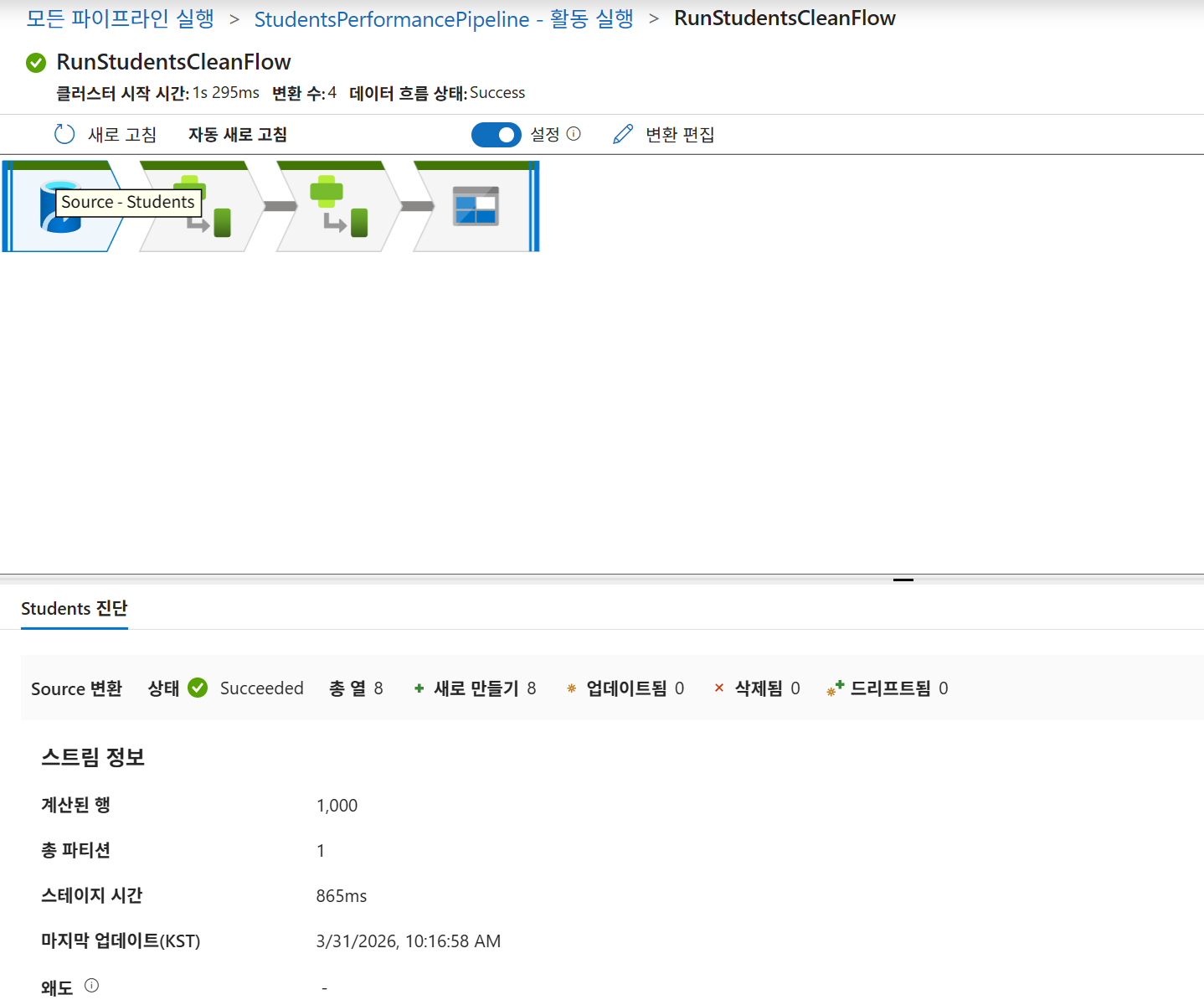
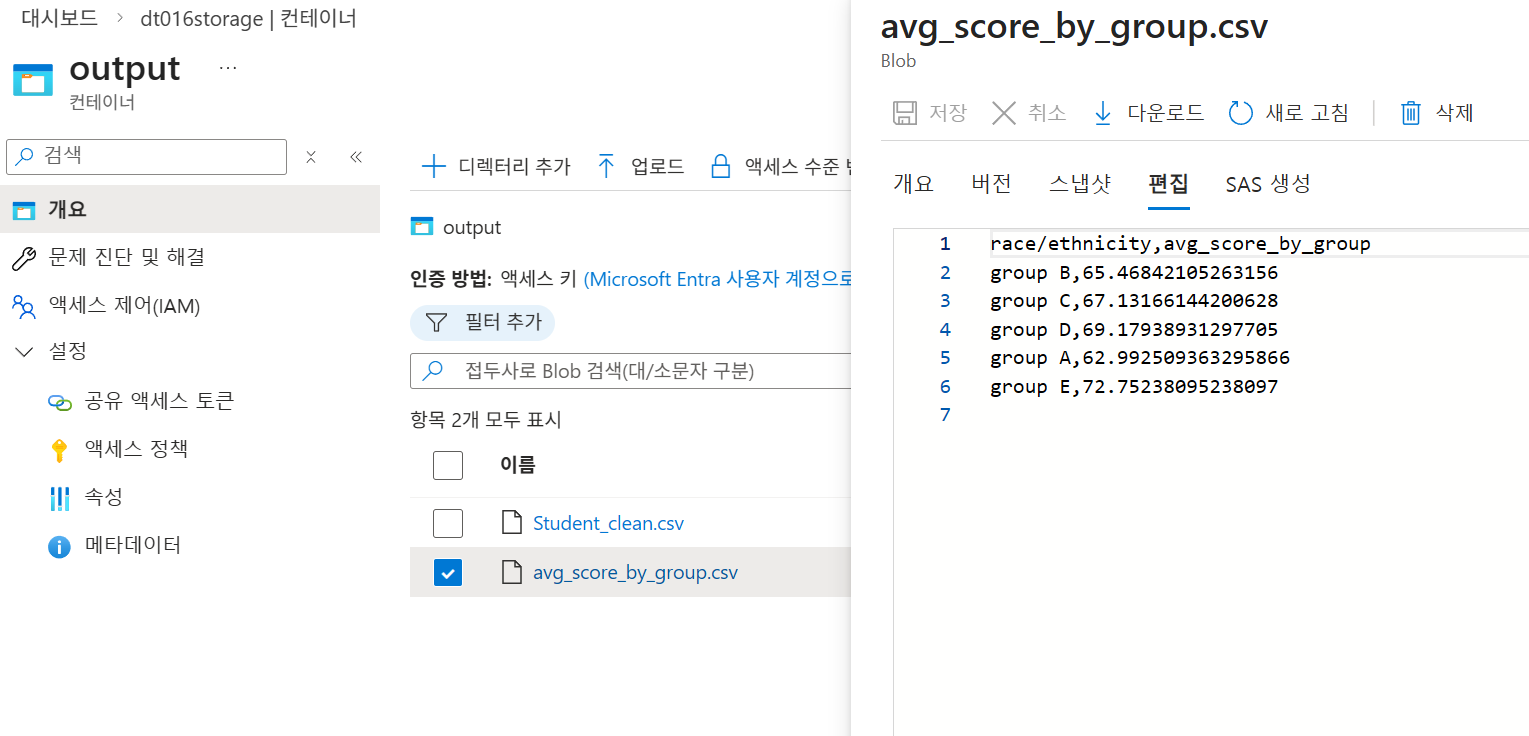
output컨테이너의Students_clean.csv에서 평균 점수와 등급(A~F) 확인. - 모니터링: 각 단계별(Source, AverageScore, GradeLevel) 처리 시간 및 기록된 행(1,000행) 진단 정보 확인.
6. [실습 2] 그룹별 집계 실습 (Advanced)
6-1. 데이터 플로우 편집 및 분기
AverageScore단계에서 새 분기(New Branch) 추가.
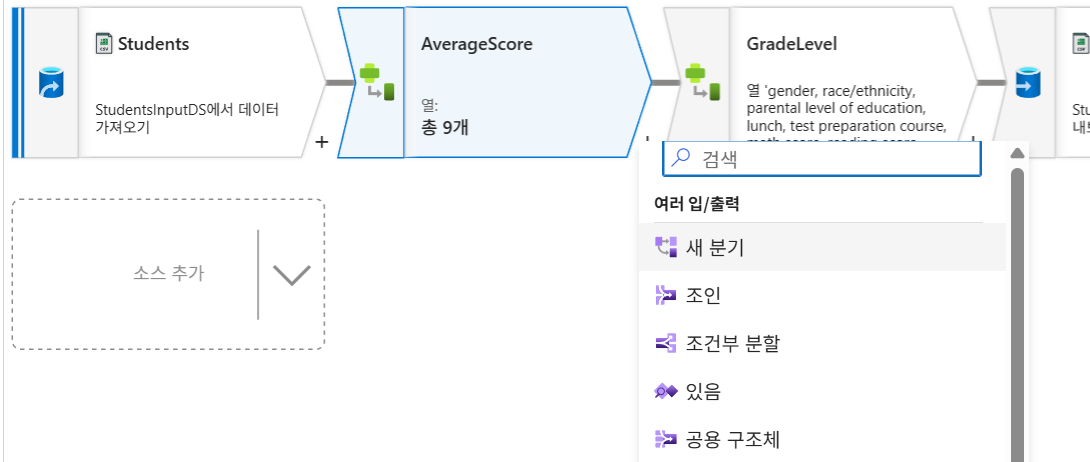
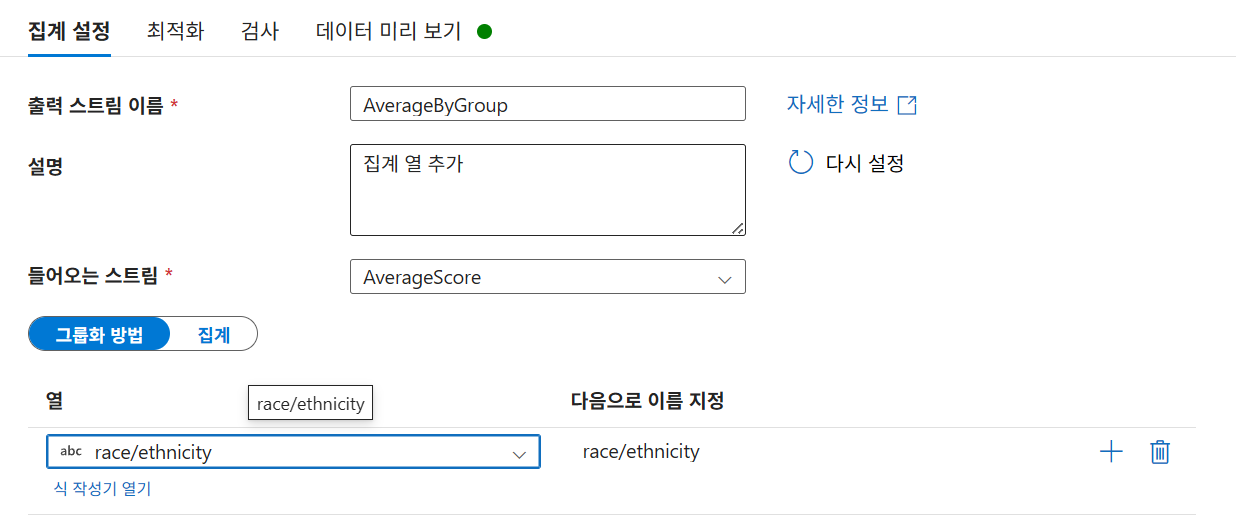
6-2. 데이터 집계 (Aggregate - AverageByGroup)

-
출력 스트림 이름:
AverageByGroup -
그룹화 방법:
race/ethnicity열 기준.
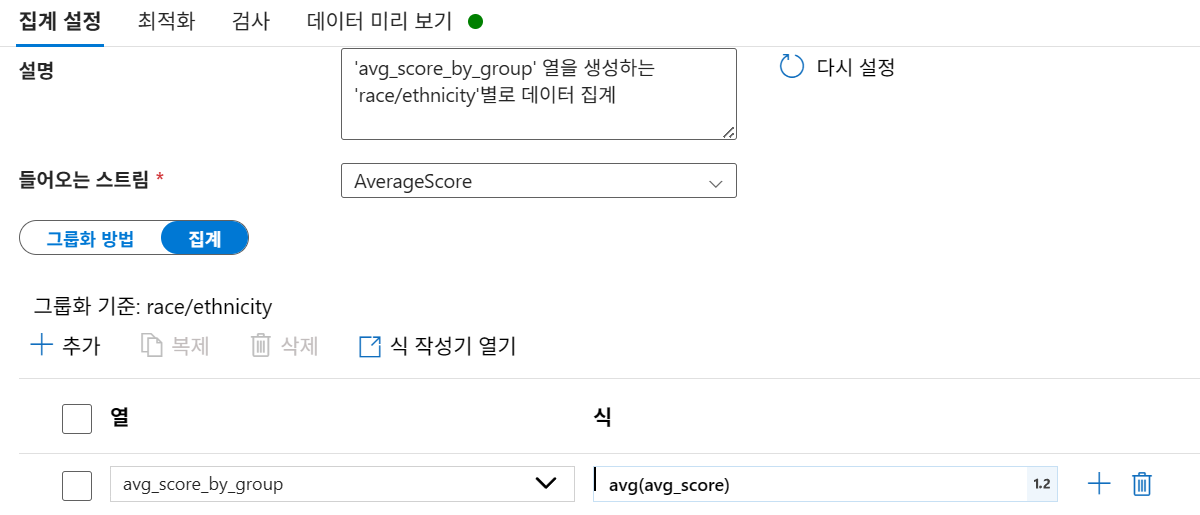
-
집계 컬럼:
avg_score_by_group -
식:
avg(avg_score)
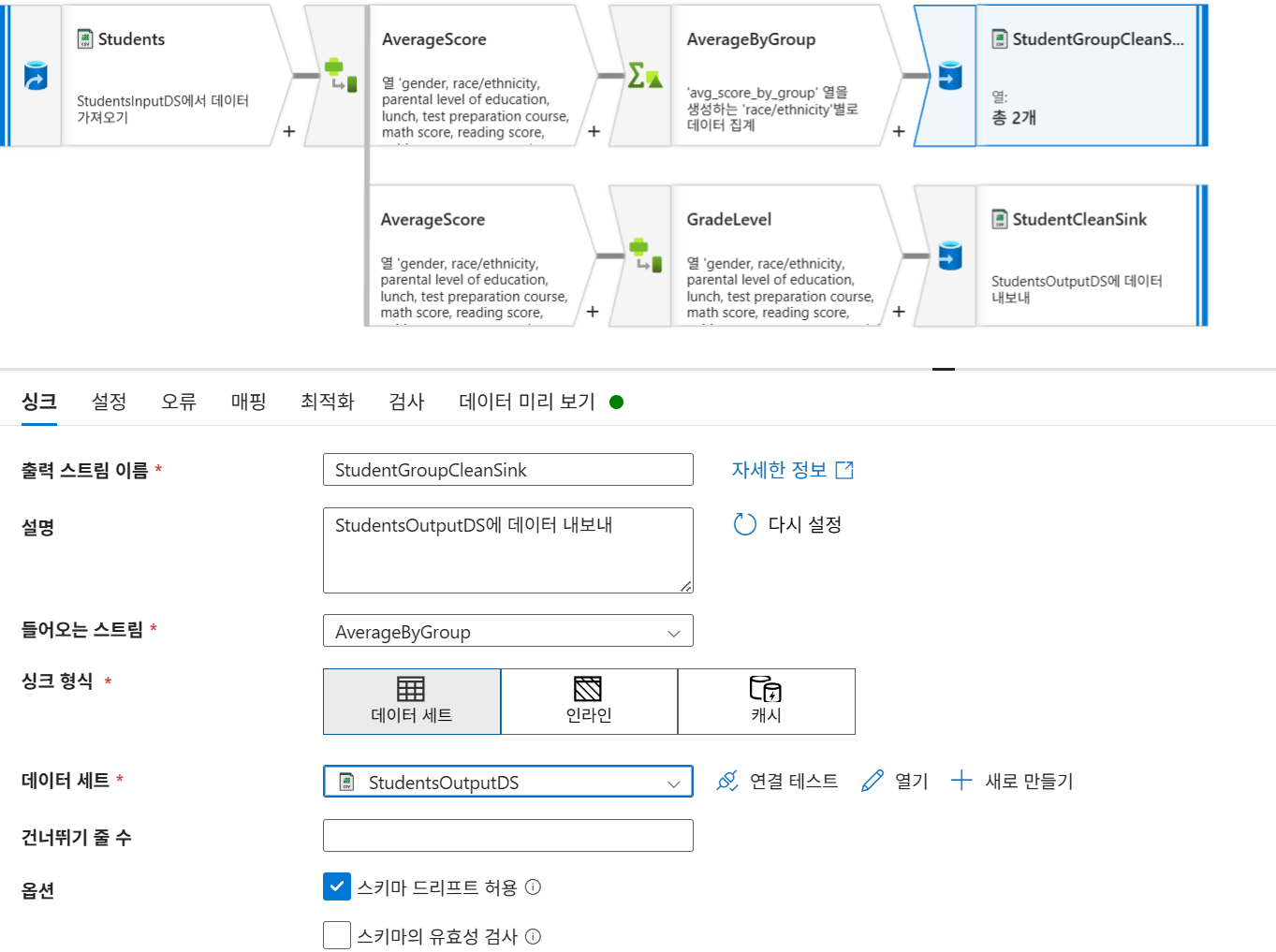
6-3. 새로운 싱크 추가 (StudentGroupCleanSink)
- 데이터 세트:
StudentsOutputDS - 설정: 단일 파티션, 단일 파일로 출력.
- 파일명:
avg_score_by_group.csv
6-4. 최종 실행 및 확인
- 변경 사항 게시 후 파이프라인 재실행.
7. 마무리
- 실습 완료 후 비용 발생 방지를 위해 데이터 흐름 디버그 모드를 반드시 중지합니다.
[Azure Data Factory] 통합 런타임 (Integration Runtime)
1. 통합 런타임 개요
통합 런타임(Integration Runtime)은 Azure Data Factory에서 데이터 이동, 변환, 실행 등의 기능을 수행하기 위한 컴퓨팅 인프라 역할을 수행합니다.
Integration Runtime의 핵심
- ADF의 모든 데이터 처리 작업은 통합 런타임(IR)을 통해 실행됩니다.
- IR은 다양한 네트워크 환경 및 데이터 소스/싱크와의 연결을 지원합니다.
- 작업 목적과 데이터 위치에 따라 적절한 IR 유형을 선택해야 합니다.
| IR의 수행 기능 | IR의 수행 내용 |
|---|---|
| 활동 실행 | Copy, 외부 리소스 실행 등 여러 가지 활동의 지원 |
| 데이터 이동 | 클라우드 ↔ 온프레미스 간 안전한 복사 수행 |
| 데이터 흐름 실행 | Mapping Data Flow 등 고급 데이터 변환 지원 * Azure IR 전용 |
IR은 "ADF의 실행 엔진"이며, 어떤 네트워크에서 데이터를 가져오고 어디로 보낼 것인지에 따라 적절한 유형을 선택하는 것이 필수적입니다.
2. 통합 런타임의 유형
데이터 팩토리에서는 다양한 환경에 맞게 세 가지 유형의 통합 런타임을 제공합니다. 각 유형은 사용자의 네트워크 구조, 데이터 위치, 기존 시스템 여부에 따라 선택해야 합니다.
통합 런타임의 세 가지 유형
| 통합 런타임 유형 | 주요 목적 및 특성 |
|---|---|
| Azure Integration Runtime | Azure 내부 서비스 간 데이터 이동 및 변환, 완전 관리형, 서버리스 컴퓨팅 환경 |
| Self-hosted IR (SHIR) | 온프레미스 또는 VNet 내 리소스와 연결, 사용자 컴퓨터/VM에 런타임 설치 필요 |
| Azure-SSIS IR | SSIS 패키지를 Azure에서 실행하기 위한 전용 런타임, SQL Managed Instance 필요 |
통합 런타임 유형별 특성
| 구분 | Azure IR | SHIR | Azure-SSIS IR |
|---|---|---|---|
| 관리 주체 | Microsoft | 사용자 직접 관리 | Microsoft |
| 설치 필요 여부 | 없음 | 설치 필요 | 설치 필요 |
| 데이터 흐름 지원 여부 | 지원 | 미지원 | 미지원 |
| 사용 위치 | Azure 간 서비스 | 온프레미스, VNet 리소스 | SSIS 기반 데이터 마이그레이션 |
IR 선택은 데이터의 출발지/도착지, 네트워크 형태(공용/사설), 기존 시스템 여부(SSIS 등) 등을 고려하여 결정합니다.
3. Self-Hosted 통합 런타임 (SHIR)
Self-Hosted 통합 런타임은 Azure Data Factory에서 사설 네트워크나 온프레미스 환경의 데이터에 접근할 수 있도록 해주는 소프트웨어 컴포넌트입니다.
SHIR의 필요성
- 가상 사설망(VNet) 내의 데이터 및 리소스 접근 필요 시
- 온프레미스의 데이터베이스와의 연동 시
- 전용 드라이버 및 커넥터를 사용해야 하는 특수 데이터 환경
네트워크별 IR 지원 현황
| 유형 | Azure Cloud | Private Network |
|---|---|---|
| Azure IR | Activity 실행, 데이터 이동, 데이터 플로우 | 지원 안함 |
| Self-hosted IR | Activity 실행, 데이터 이동 | Activity 실행, 데이터 이동 |
| Azure-SSIS IR | SSIS 패키지 실행 (제한적) | SSIS 패키지 실행 |
- 온프레미스 DB(예: Oracle, MySQL, MSSQL 등)와 연동이 필요한 경우에는 SHIR가 반드시 필요합니다.
- SHIR은 로컬 머신 또는 VM에 설치되며, Azure Portal에서 연결 상태의 모니터링도 가능합니다. (보통 데이터 이관용이다. 데이터플로우 지원 X)
4. [실습] SHIR 환경 구축 및 데이터 복사
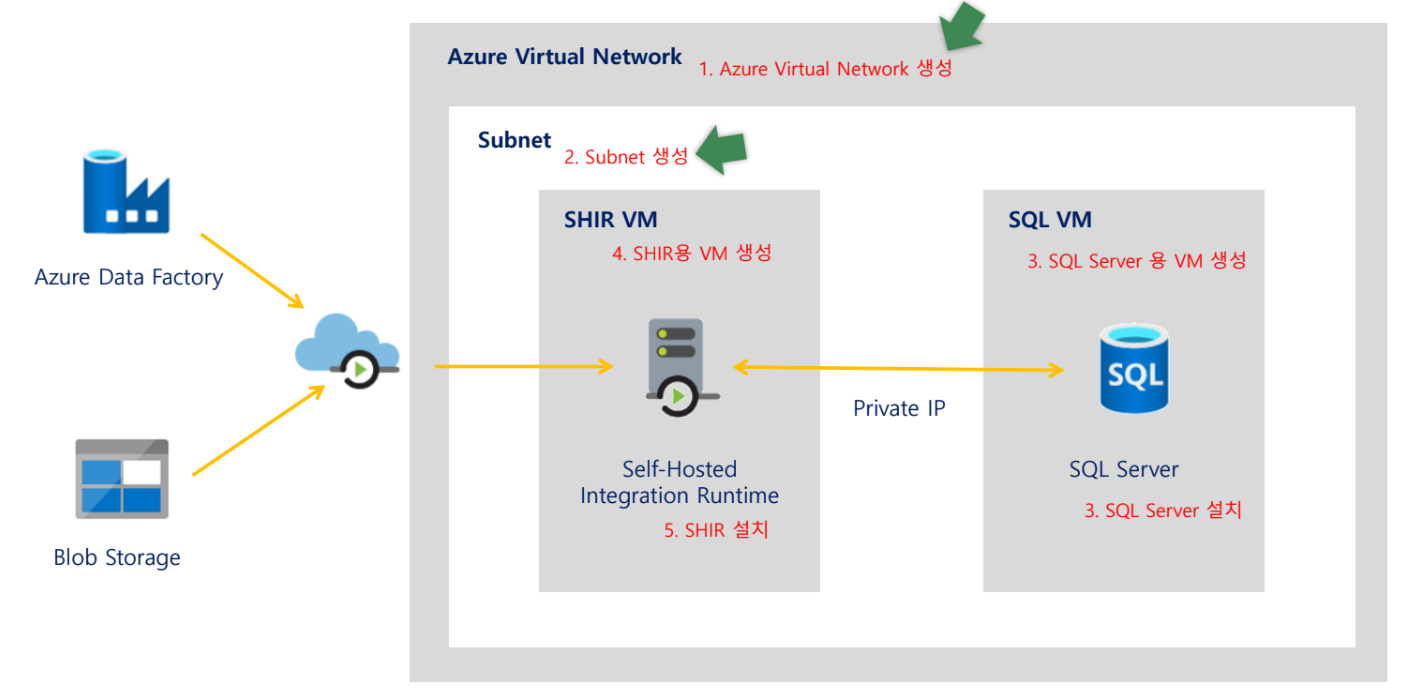
Step 1: 실습 환경 구성 (인프라)
실습을 위해 다음과 같은 리소스를 순차적으로 생성합니다.
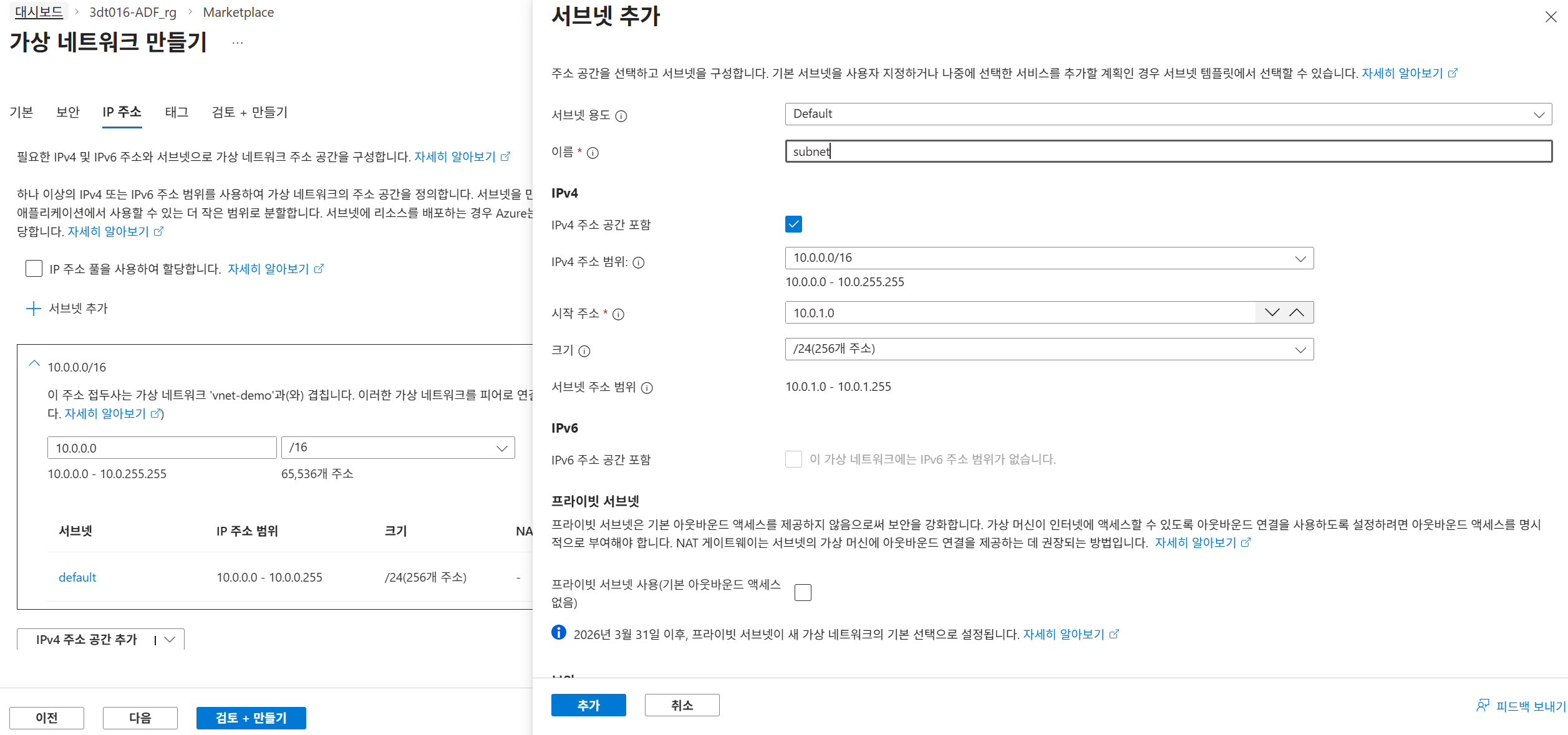
1. Azure Virtual Network 생성: vnet (주소 공간: 10.0.0.0/16).

2. Subnet 생성: subnet (주소 범위: 10.0.1.0/24)
3. SQL Server용 VM 생성: SQL-vm

-
이미지: SQL Server 2019 Developer on Windows Server 2019
모든 이미지 보기 선택
만들기 후 2세대 선택 -
크기: Standard_B2ms (2 vcpu, 8 GiB 메모리)

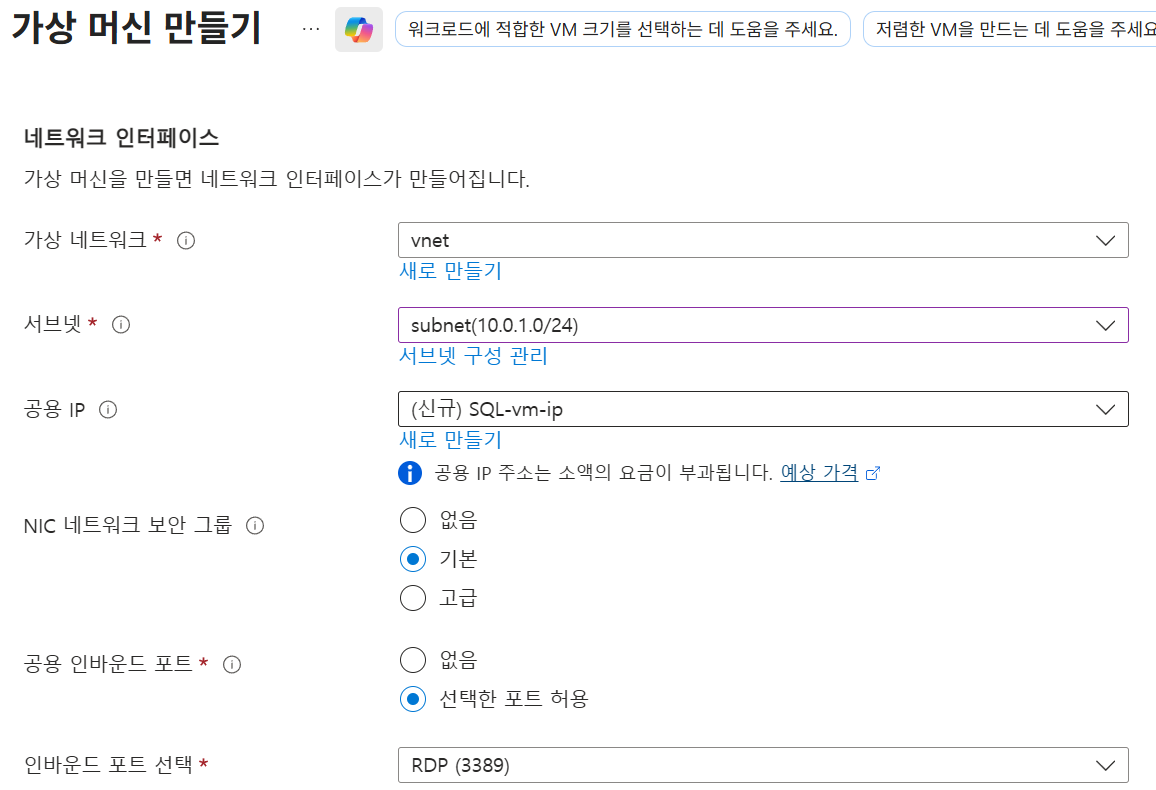
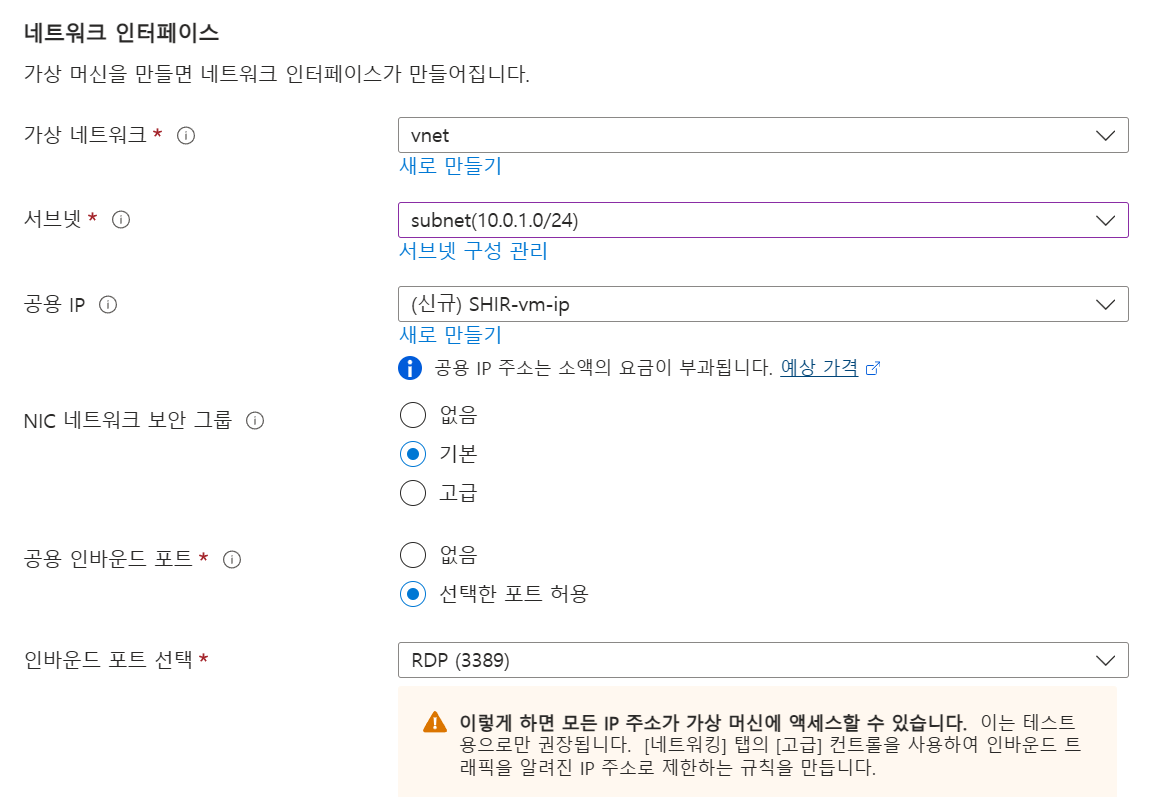
- 서브넷 설정
- 인바운드 포트: RDP(3389) 허용
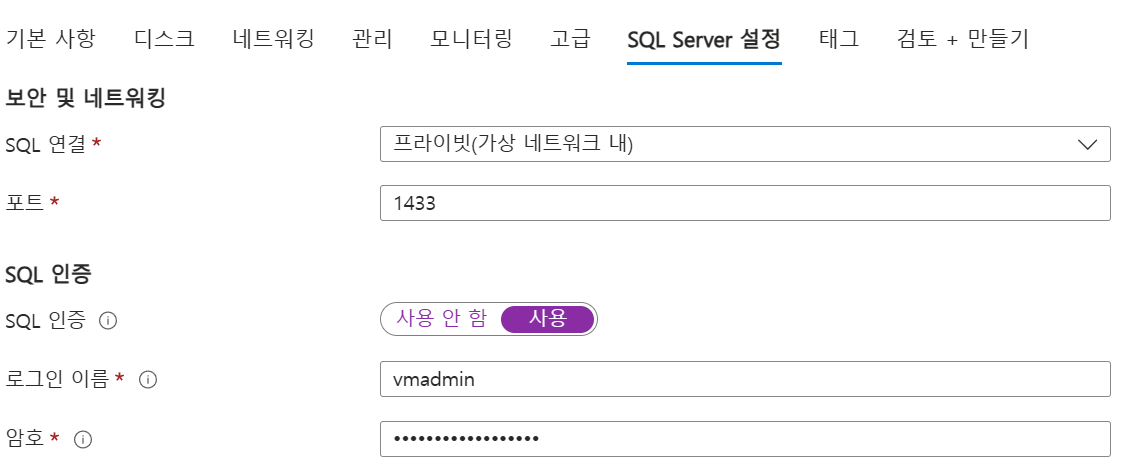
- SQL 연결: 프라이빗(가상 네트워크 내), 포트 1433
- SHIR용 VM 생성:
SHIR-vm
-
이미지: Windows Server 2019 Datacenter
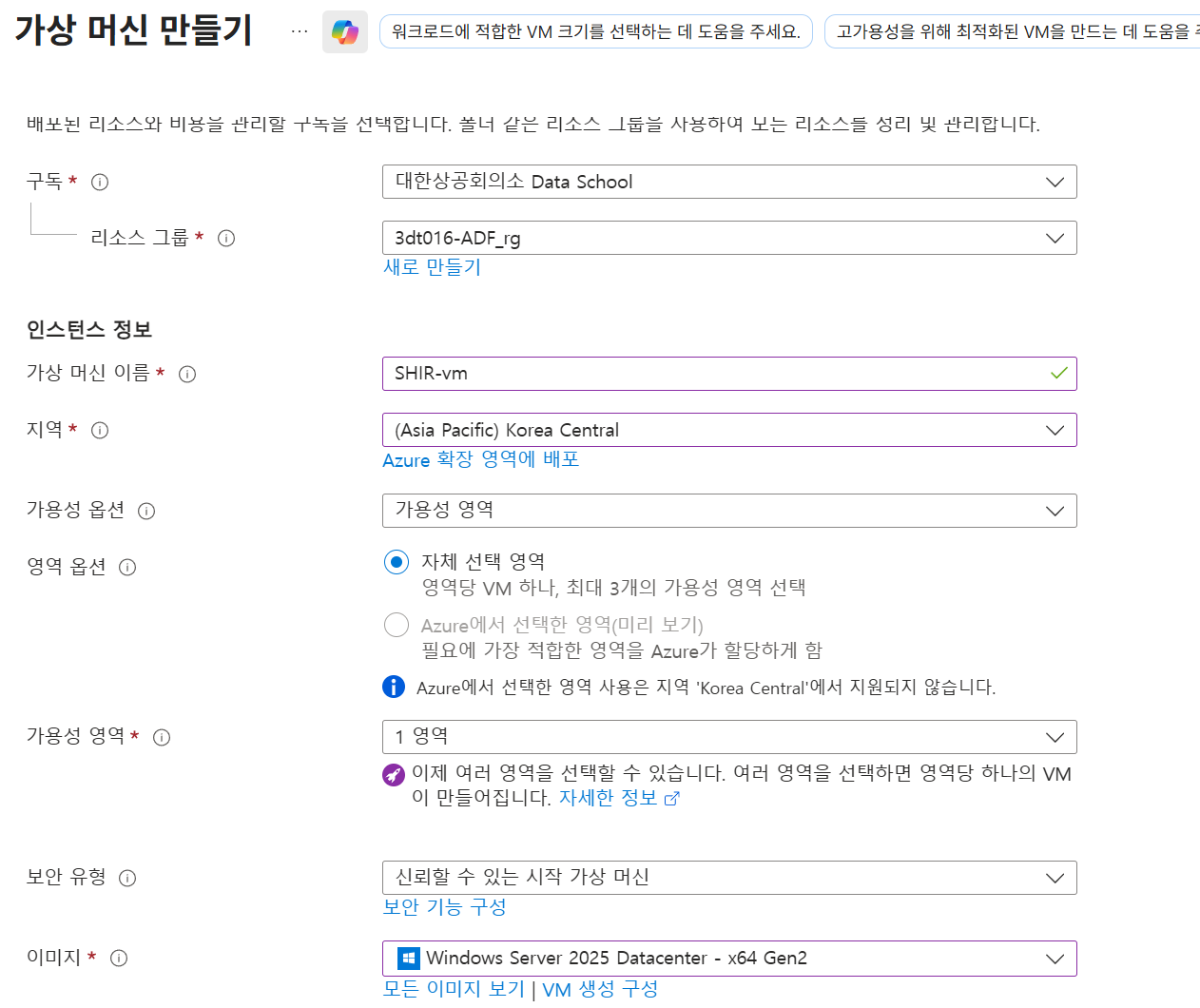
-
디스크 표준으로 설정
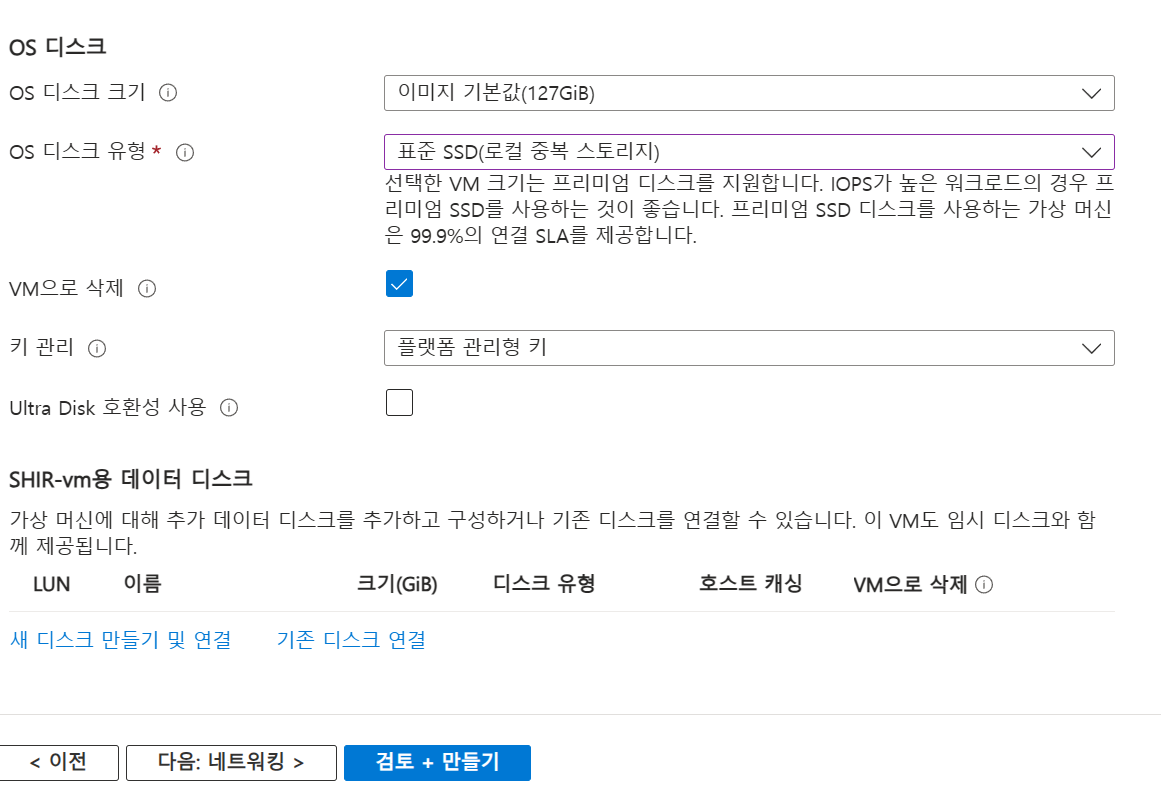
-
네트워크:
vnet/subnet연결
Step 2: SHIR 설치 및 등록
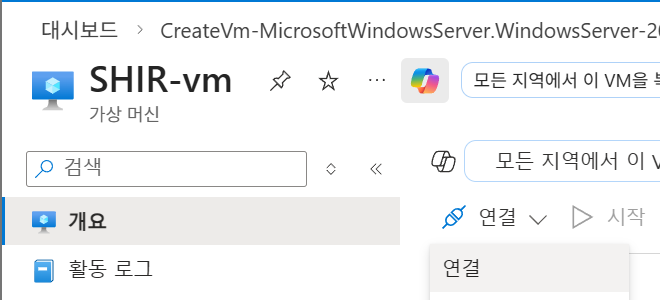
들어가서 RDP 파일 다운로드
-
SHIR-vm 접속: RDP를 통해 가상 머신에 접속합니다.
-
런타임 다운로드: VM 내부 브라우저에서 'Microsoft Integration Runtime'을 검색하여 설치 파일을 다운로드합니다.
-
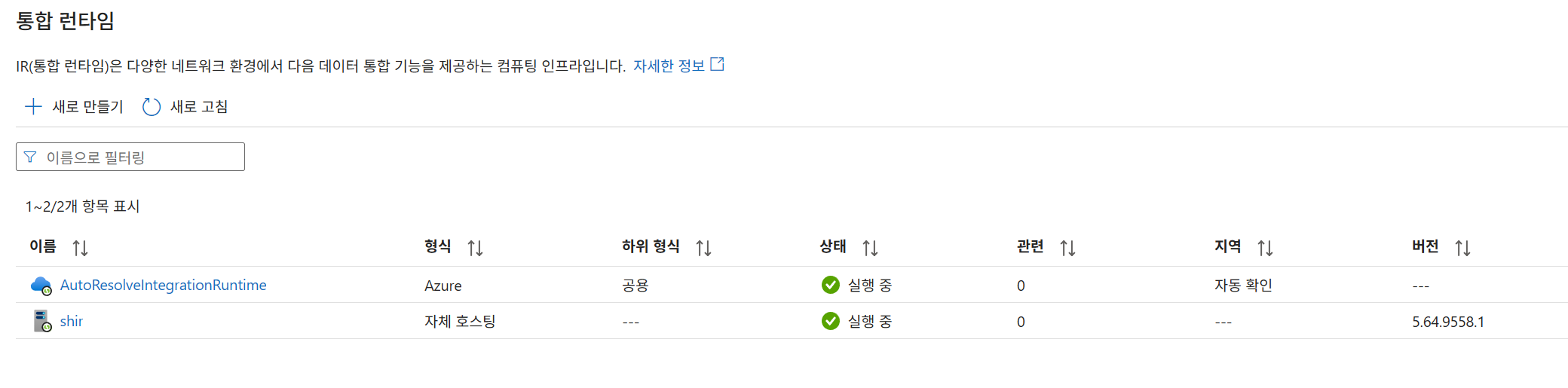
ADF에서 SHIR 생성: ADF Studio의 [관리] > [통합 런타임]에서 '자체 호스팅' 유형으로
shir를 생성하고 인증 키를 복사합니다.

-
노드 등록: VM에 설치된 Configuration Manager를 실행하고 복사한 인증 키를 입력하여 등록을 완료합니다.
ADF 관리탭에서도 표시된다.
Step 3: 데이터 준비 (원본 및 싱크)
- 원본 데이터: Blob Storage의
input컨테이너에StudentsPerformance.csv업로드. - 싱크 테이블 생성:
SQL-vm내 SSMS를 실행하여 데이터베이스와 테이블을 생성합니다.(동일하게 SQL-vm의 rdp 파일 설치 후 실행)

Trust server certificate 체크
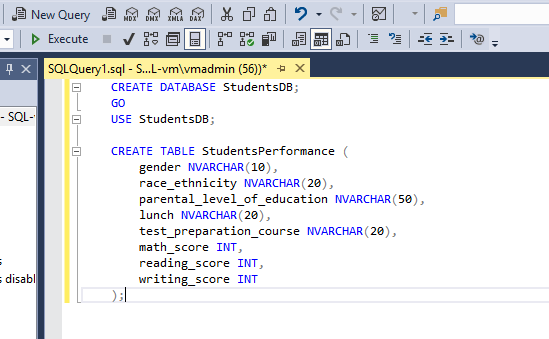
CREATE DATABASE StudentsDB;
GO
USE StudentsDB;
CREATE TABLE StudentsPerformance (
gender NVARCHAR(10),
race_ethnicity NVARCHAR(20),
parental_level_of_education NVARCHAR(50),
lunch NVARCHAR(20),
test_preparation_course NVARCHAR(20),
math_score INT,
reading_score INT,
writing_score INT
);Step 4: 링크드 서비스 및 데이터세트 구성
-
링크드 서비스 (원본):
BlobStorage1(AutoResolveIntegrationRuntime 사용).
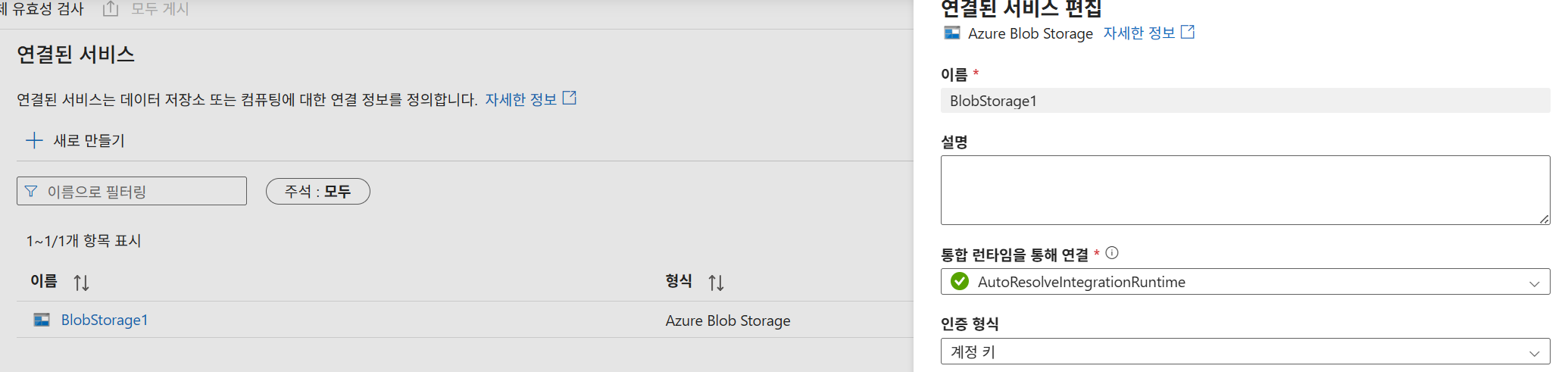
-
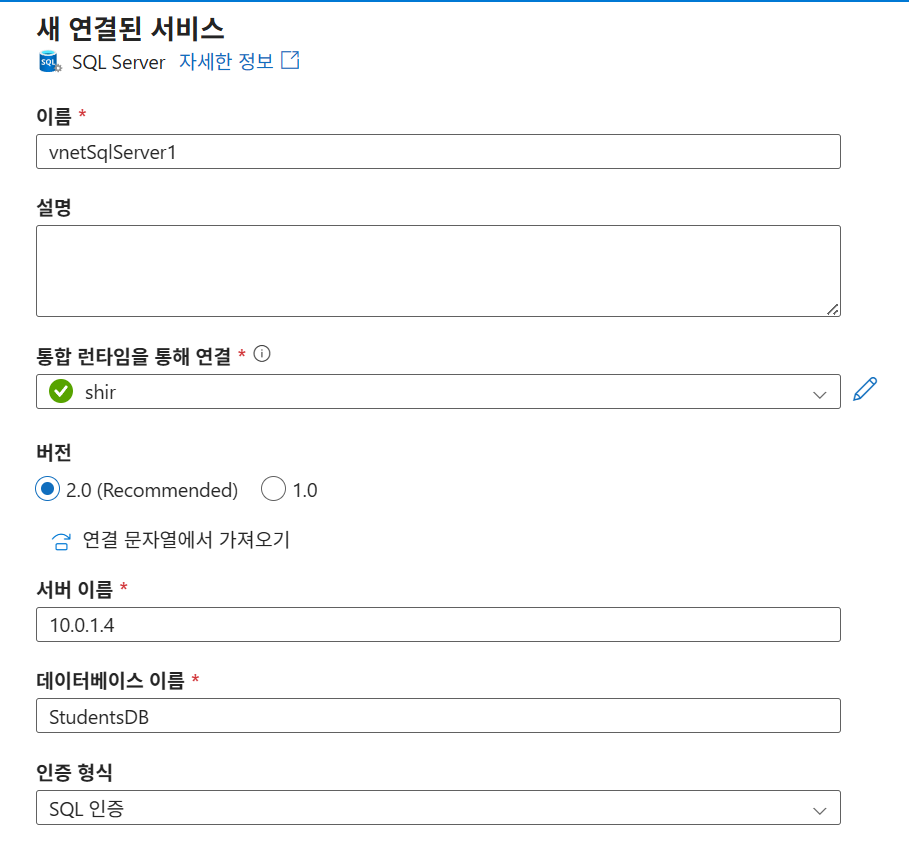
링크드 서비스 (싱크):
vnetSqlServer1- 통합 런타임:
shir선택 - 서버 이름: SQL-vm의 프라이빗 IP (
10.0.1.4) - 데이터베이스:
StudentsDB
- 통합 런타임:


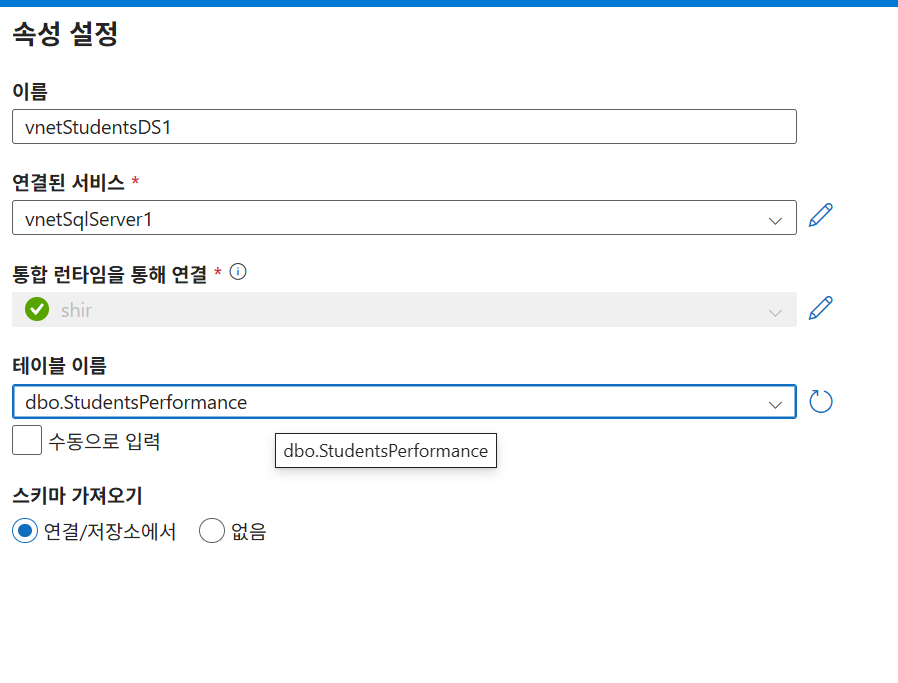
- 데이터세트:
원본:StudentsInputDS(DelimitedText)
싱크:vnetStudentsDS1(SQL Server 테이블)

Step 5: 파이프라인 생성 및 실행
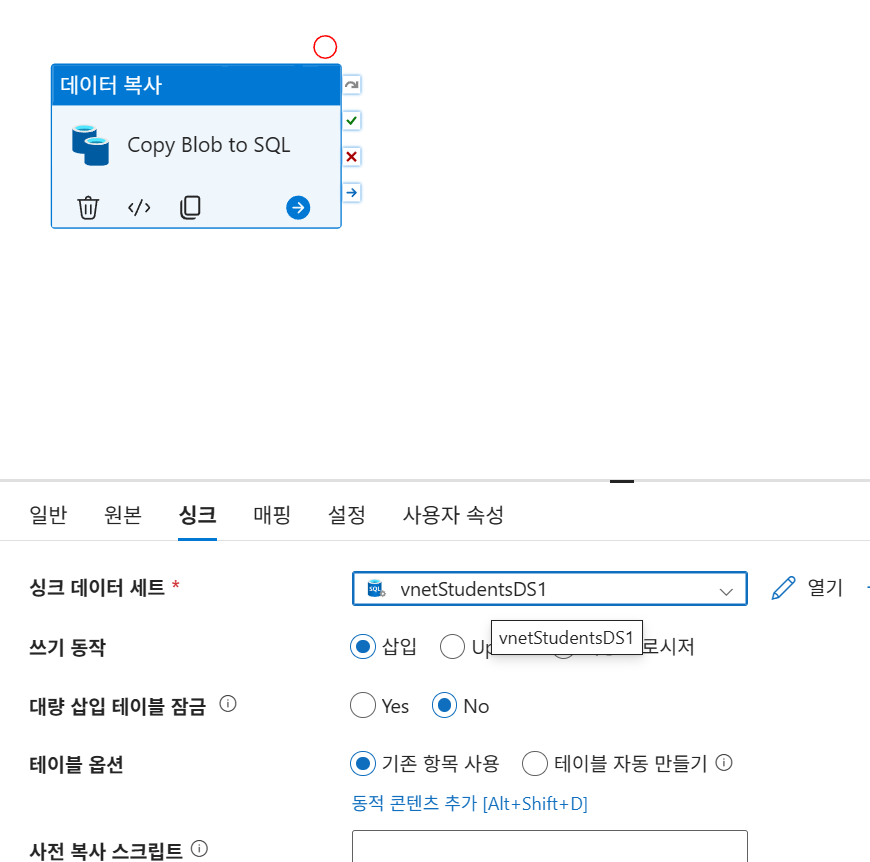
- 활동: Copy Data 활동(
Copy Blob to SQL) 추가. - 매핑(Mapping): 원본 CSV 컬럼과 SQL 테이블 컬럼을 매핑합니다 (gender, math_score 등).
스키마 가져오기후 매핑
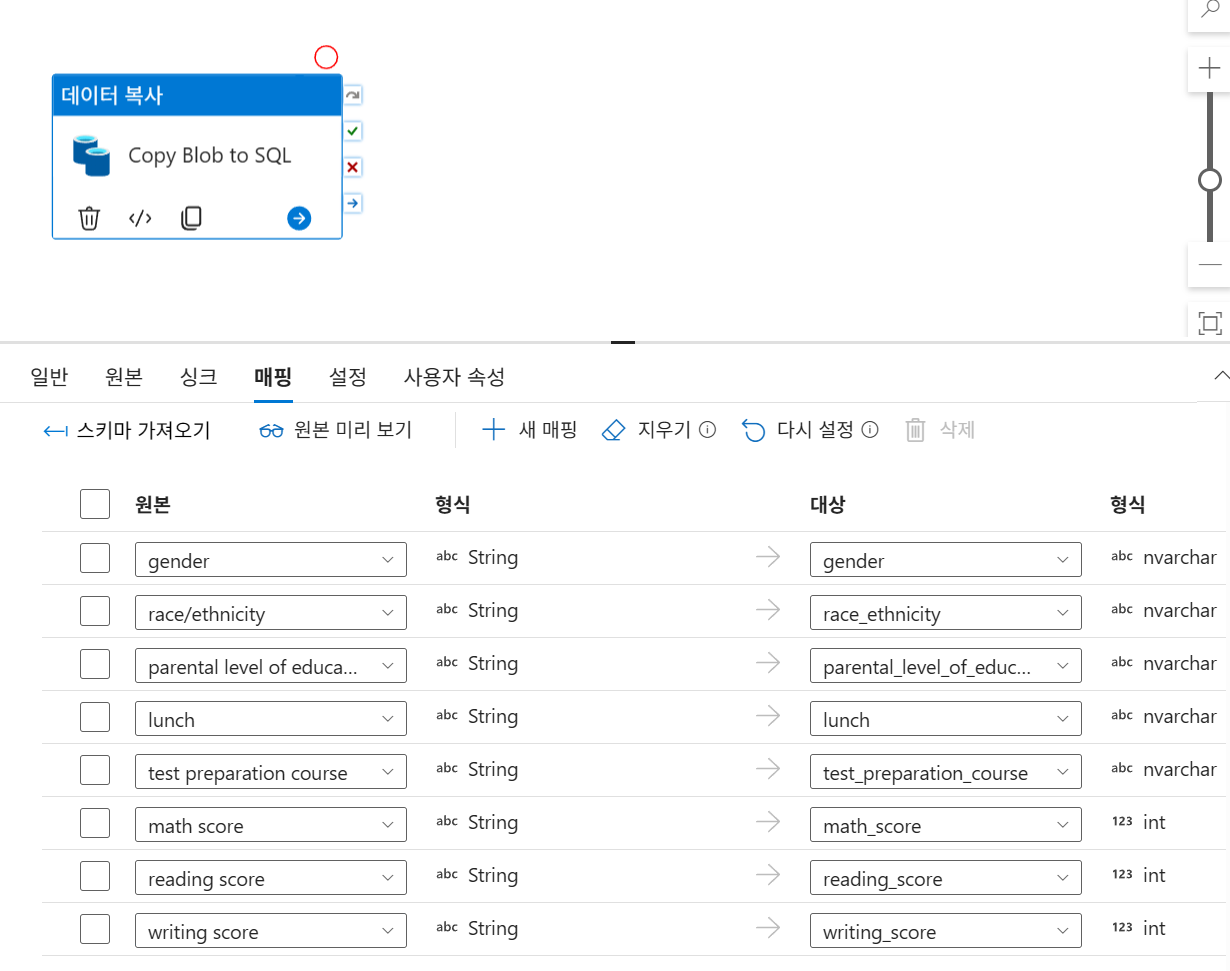
- 실행: 파이프라인을 게시한 후 디버그를 실행하여 '성공' 상태를 확인합니다.
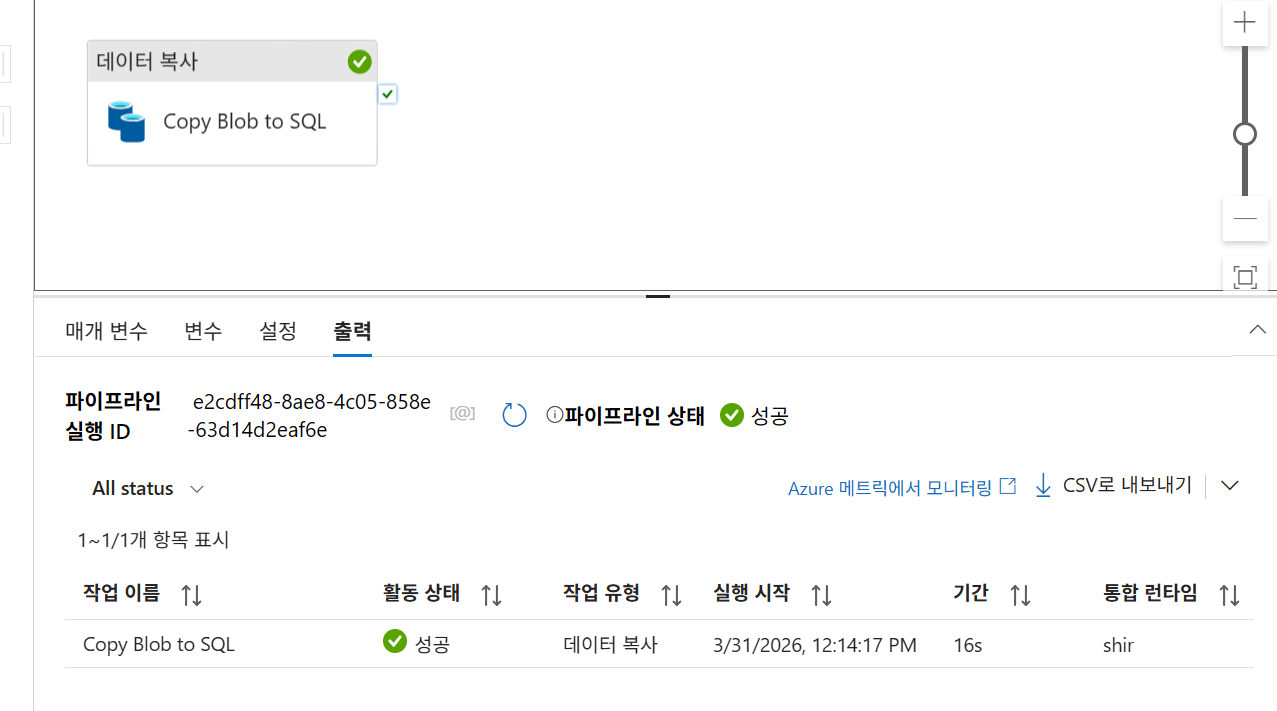
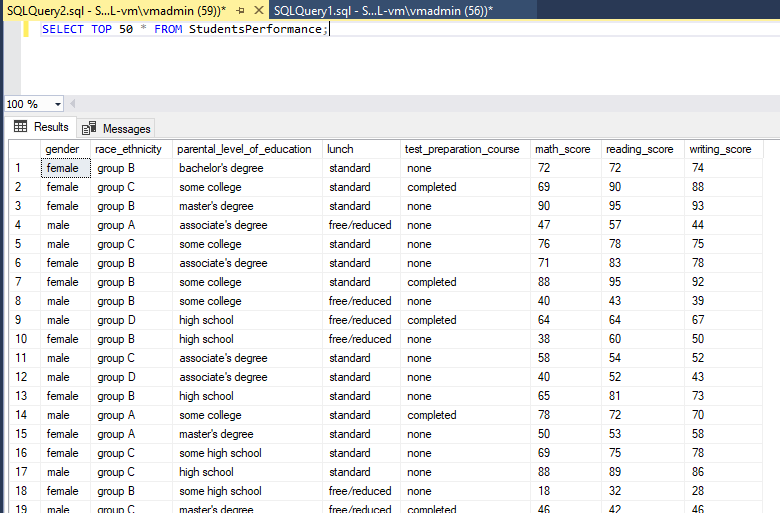
- 결과 확인: SQL-vm에서
SELECT TOP 50 * FROM StudentsPerformance;쿼리를 통해 데이터 복사 여부를 검증합니다.
5. 실습 마무리 및 리소스 정리
실습 완료 후 비용 발생을 방지하기 위해 다음 리소스들을 반드시 삭제해야 합니다.
- 가상 머신:
SHIR-vm,SQL-vm - 관련 리소스: 공용 IP 주소, 네트워크 인터페이스(NIC), 디스크, 네트워크 보안 그룹(NSG)
- 네트워크:
vnet-demo(가상 네트워크)
주의: SHIR 노드가 설치된 VM을 삭제하면 ADF Studio에서 해당 통합 런타임 상태가 '사용할 수 없음'으로 표시됩니다. 필요하지 않은 경우 ADF 내의 통합 런타임과 연결된 서비스도 함께 삭제하여 정리합니다.
- SQL-VM
- VM 2개
- NIC
- IP, NSG, Disk
- V-NET
순으로 삭제
이후 연결된 서비스에서 vnetSqlServer1의 통합 런타임 연결을 AutoResolveIntegrationRuntime으로 변경하여 적용 후 데이터세트의 vnetStudentsDS1, 파이프라인의 CopyStudentPerformance 삭제, 게시 후 연결된서비스 마저 삭제
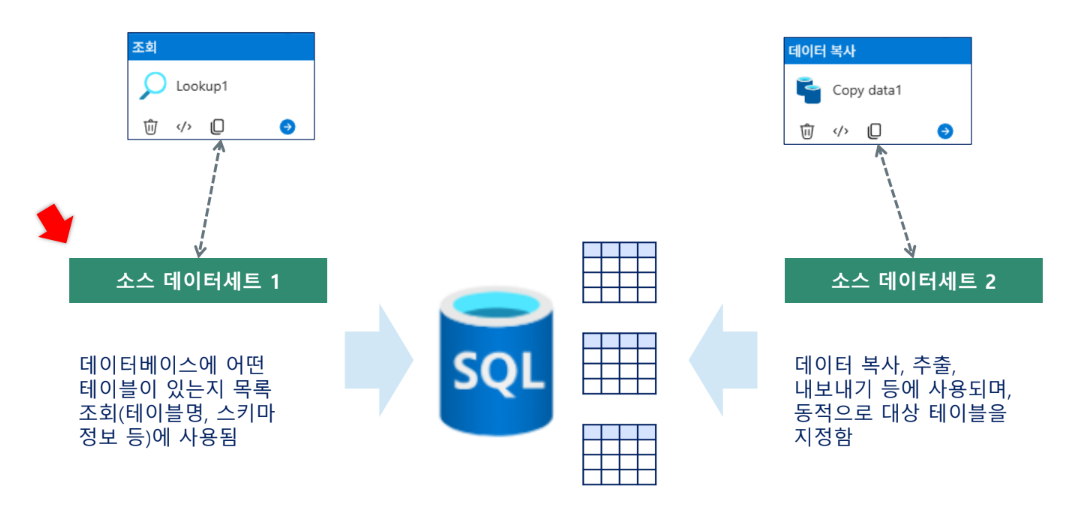
[Azure Data Factory] Lookup 및 ForEach 활동을 활용한 동적 데이터 처리
1. 개요
Lookup Activity
Lookup 활동을 통해 다양한 데이터 소스에서 목록이나 데이터를 조회하여, 파이프라인의 동적인 데이터 처리 흐름을 설계할 수 있습니다. Lookup 활동은 반복 작업의 시작점이 되는 정보를 제공합니다.
- Lookup 활동 개요
- 외부 데이터 소스(파일, 테이블 등)에서 데이터를 읽어오는 활동
- 파이프라인 내에서 동적으로 사용할 데이터 목록을 조회
- 다양한 데이터 소스와 호환됨
- Lookup 활동의 주요 기능
- 파일 또는 테이블의 내용을 읽어와 결과를 파이프라인 변수로 저장
- 주로 목록(리스트) 형태의 데이터를 반환
- 결과를 다음 활동(예: ForEach)에 전달하여 반복 작업의 입력값으로 활용
- 활용 예시
- 데이터베이스 테이블에서 처리 대상 파일 목록 조회
- Blob Storage 내 폴더의 파일 리스트 추출
- JSON/CSV 파일에서 데이터 로드
ForEach Activity
ForEach 활동을 사용하면, 조회된 데이터 목록을 활용하여 각 항목별로 동일하거나 다양한 작업을 반복 실행할 수 있습니다. ForEach 활동을 통해 대량 데이터의 일괄 처리와 자동화가 가능합니다.
- ForEach 활동 개요
- 반복 작업(Loop)을 수행하는 활동
- 입력받은 목록(배열, 리스트)의 각 항목에 대해 지정된 하위 활동 집합을 실행
- Lookup 등 다른 활동의 결과를 받아 반복 처리에 활용
- ForEach 활동의 주요 기능
- 배열(리스트) 형태의 입력 데이터에 대해 작업 반복
- 각 항목마다 복사, 변환, 로깅 등 다양한 하위 활동 실행 가능
- 병렬 또는 순차적(직렬) 실행 방식 선택 가능
- 활용 예시
- 여러 파일을 반복적으로 복사(Copy)
- 여러 테이블에 데이터 일괄 적재
- 개별 레코드/오브젝트마다 별도 처리 로직 실행
2. Lookup - ForEach 절차 및 예시
실행 절차
- Lookup 활동 실행: 외부 데이터 소스(예: 데이터베이스, Blob Storage 등)에서 처리 대상 목록을 읽어옴
- 결과값 전달: Lookup의 결과(리스트)를 ForEach 활동에 입력
- ForEach 반복 실행: 리스트의 각 항목마다 Copy, 변환, 알림 등 지정된 하위 작업을 순차적/병렬로 실행
- 각 항목별 결과 처리: 성공/실패 로깅, 후속 작업 연결 등
활용 예시
- 여러 파일을 일괄 데이터베이스에 적재
- 테이블 행별로 데이터 처리 반복
- 여러 시스템에 동일 처리 반복
3. 실습 준비
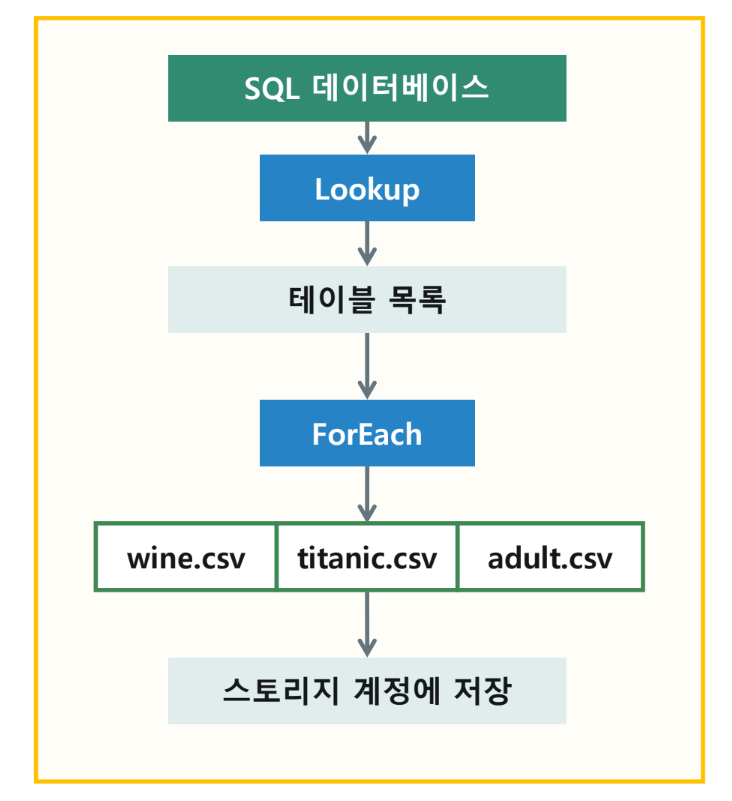
3-1. 리소스 구성
- 리소스 그룹
- 데이터 팩터리(V2)
- Logic app
- 스토리지 계정
- SQL 데이터베이스
- SQL Server
3-2. 실습 데이터
- Red Wine Quality:
winequality-red.csv(또는wine.csv) - Titanic Dataset:
titanic.csv - Adult Census Income:
adult.csv
3-3. 목적지(Sink) 컨테이너 준비
- 스토리지 계정 내에
output컨테이너를 준비합니다.
3-4. 소스 데이터베이스 테이블 생성
SQL 데이터베이스에서 다음 쿼리를 실행하여 테이블을 생성합니다.
wine 테이블 생성
CREATE TABLE wine (
fixed_acidity FLOAT,
volatile_acidity FLOAT,
citric_acid FLOAT,
residual_sugar FLOAT,
chlorides FLOAT,
free_sulfur_dioxide FLOAT,
total_sulfur_dioxide FLOAT,
density FLOAT,
pH FLOAT,
sulphates FLOAT,
alcohol FLOAT,
quality INT
);titanic 테이블 생성
CREATE TABLE titanic (
PassengerId INT,
Survived INT,
Pclass INT,
Name NVARCHAR(100),
Sex NVARCHAR(10),
Age FLOAT,
SibSp INT,
Parch INT,
Ticket NVARCHAR(20),
Fare FLOAT,
Cabin NVARCHAR(20),
Embarked NVARCHAR(5)
);adult 테이블 생성
CREATE TABLE adult (
age INT,
workclass NVARCHAR(20),
fnlwgt INT,
education NVARCHAR(20),
education_num INT,
marital_status NVARCHAR(30),
occupation NVARCHAR(20),
relationship NVARCHAR(20),
race NVARCHAR(20),
sex NVARCHAR(10),
capital_gain INT,
capital_loss INT,
hours_per_week INT,
native_country NVARCHAR(30),
income NVARCHAR(10)
);이후 컨테이너에 csv파일을 올리고, 이전 매개변수 실습에서 사용했던 파이프라인을 이용하여 해당 테이블에 csv의 데이터들을 넣고 input 스토리지에서 파일 삭제
4. 실습 단계
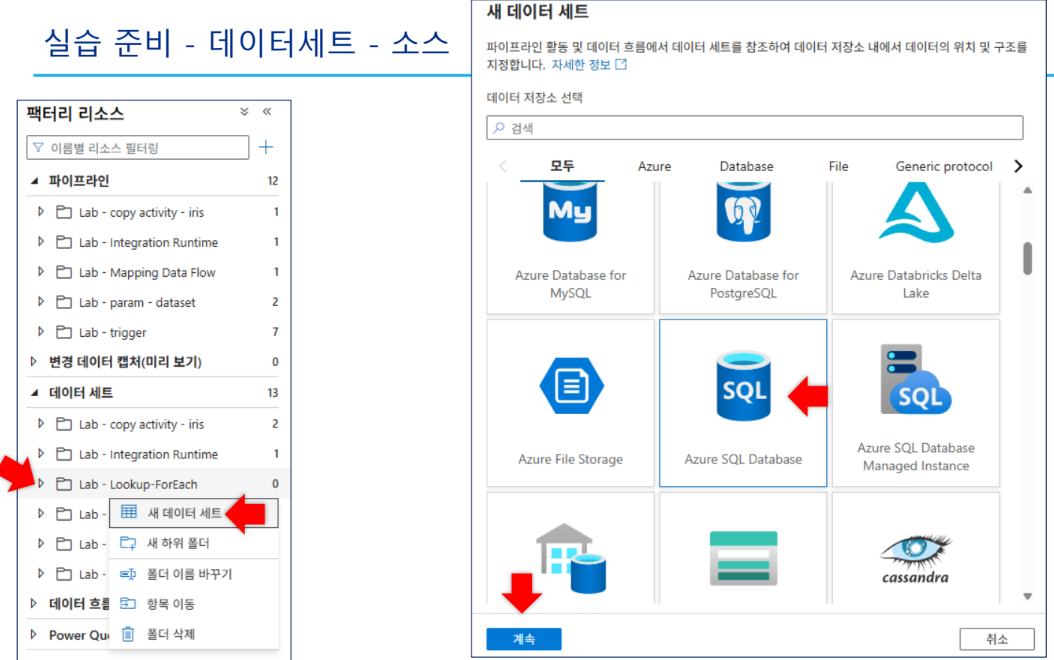
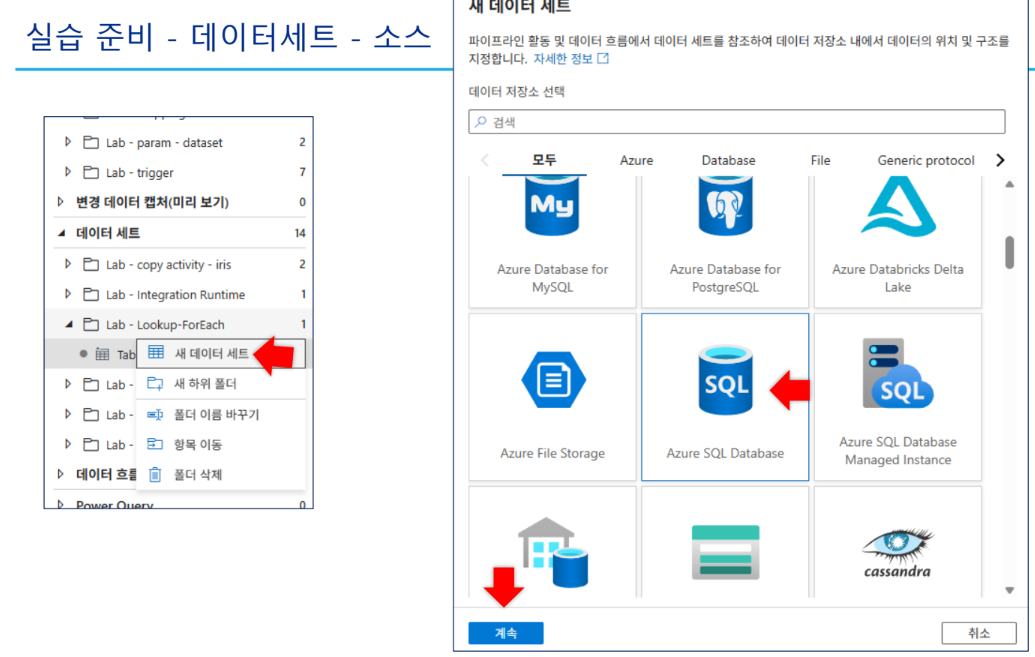
4-1. 링크드 서비스 및 데이터세트 설정
연결된 서비스(Linked Service)
- BlobStorage1: Azure Blob Storage 연결
- outputSQL: Azure SQL Database 연결
데이터세트(Dataset)
- TableListDS: SQL DB의 테이블 목록 조회용
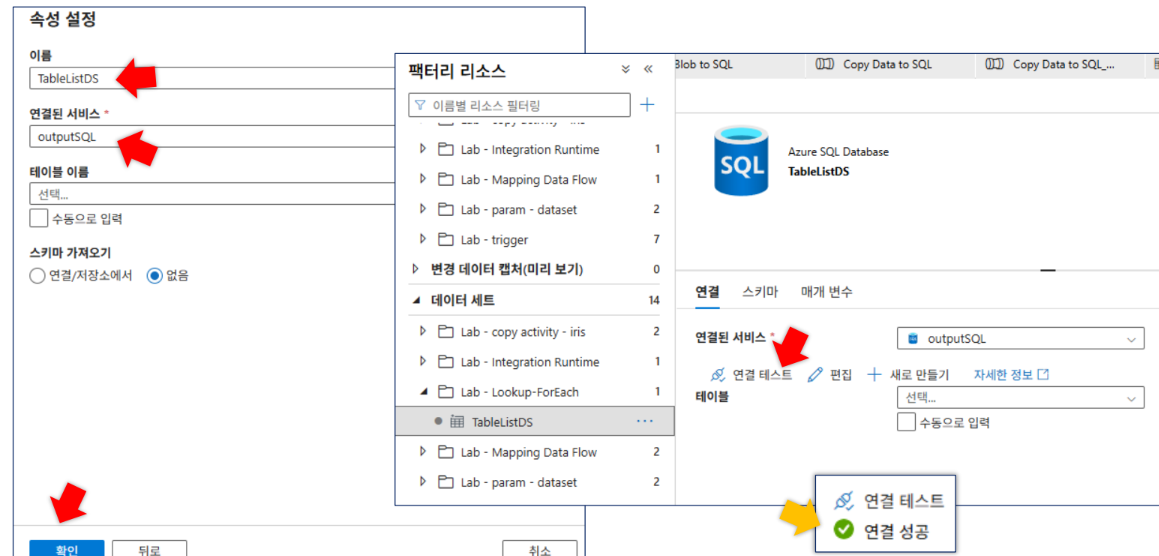
-
SourceTableDS: 매개변수(
schemaName,tableName)를 사용하여 동적으로 테이블을 지정함schemaName식:@dataset().schemaNametableName식:@dataset().tableName
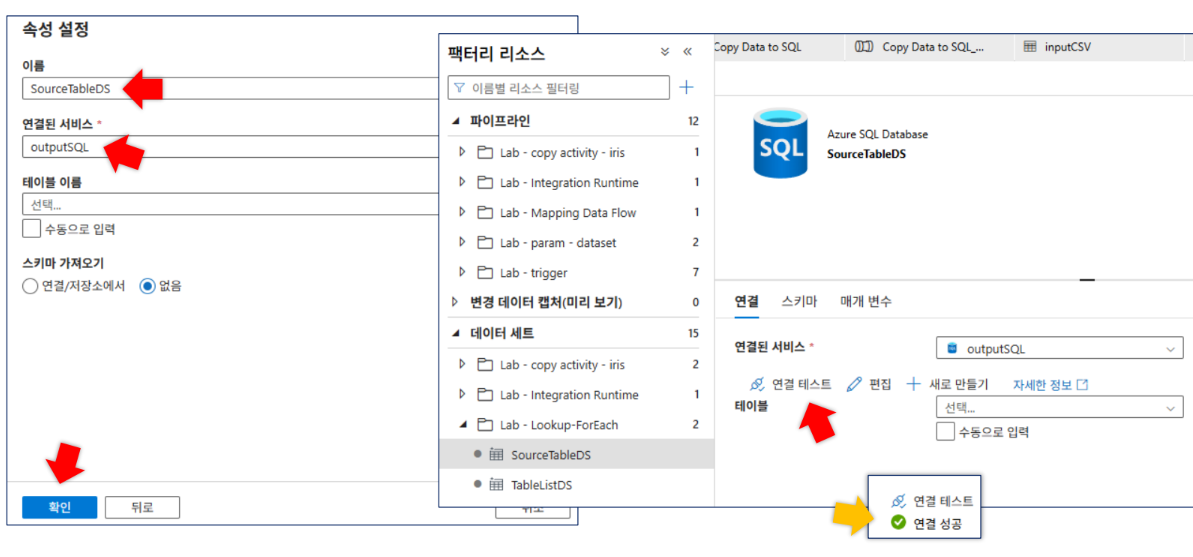
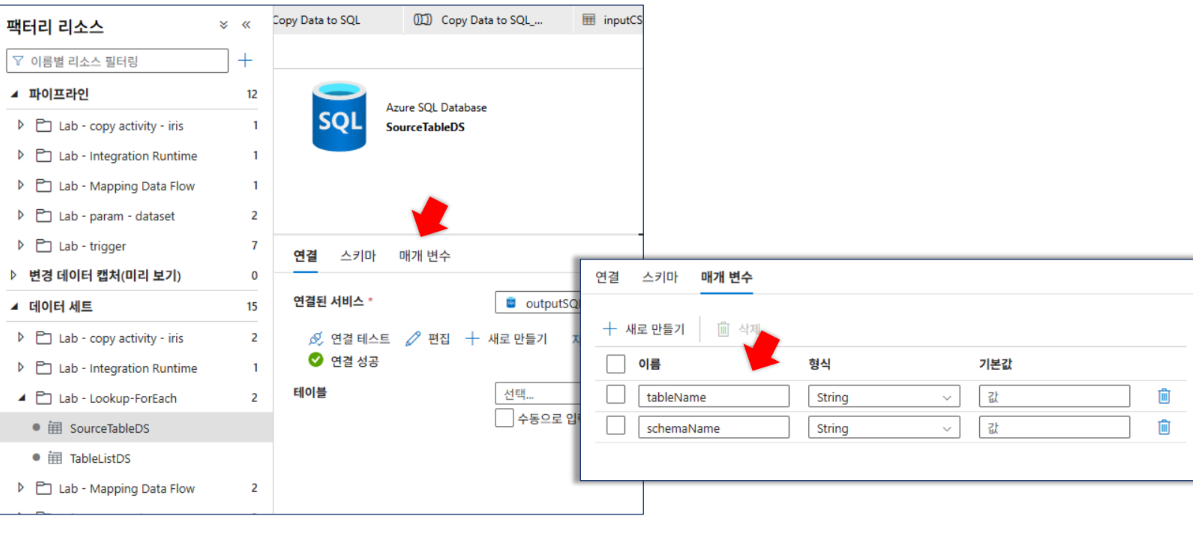
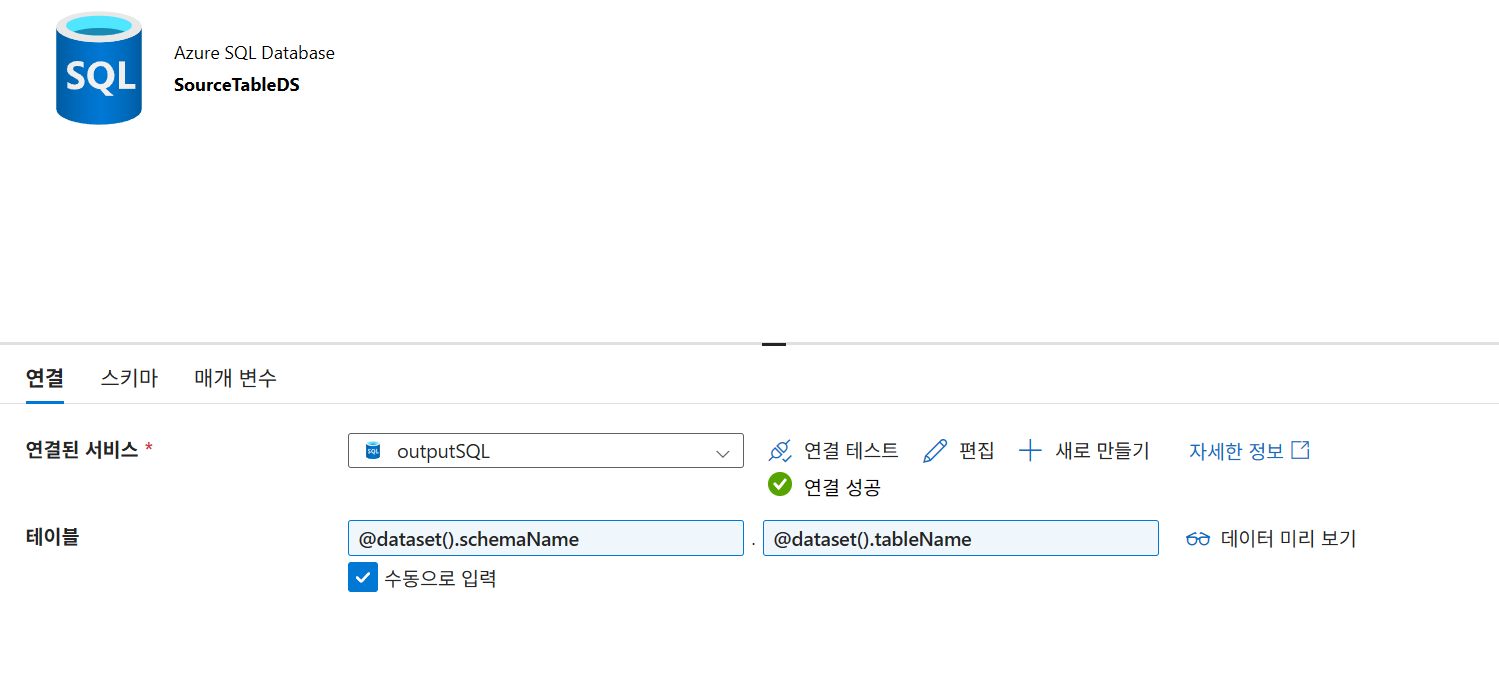
-
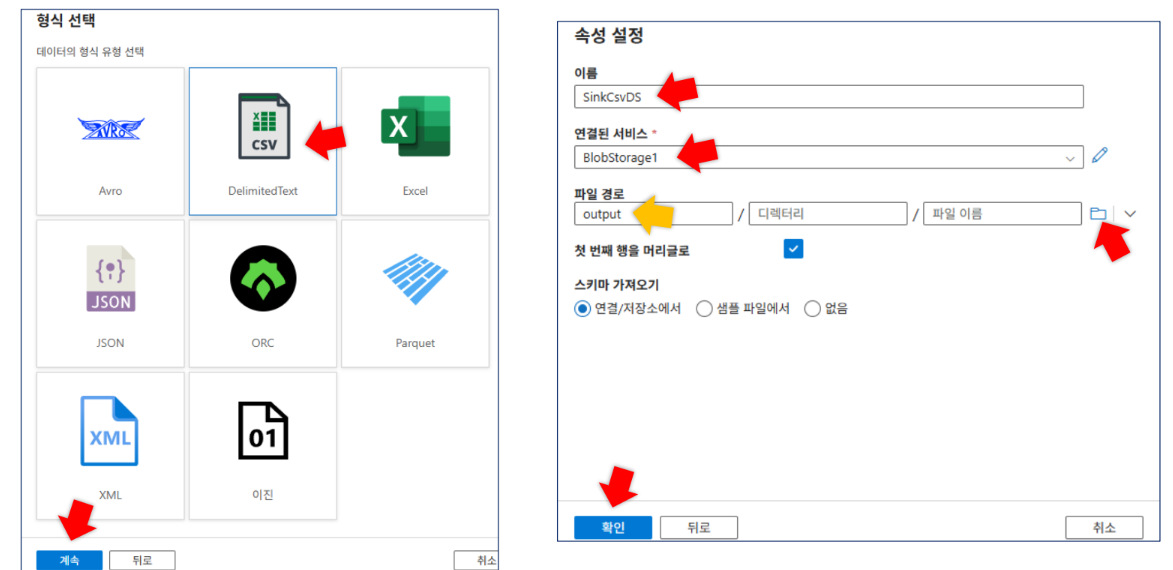
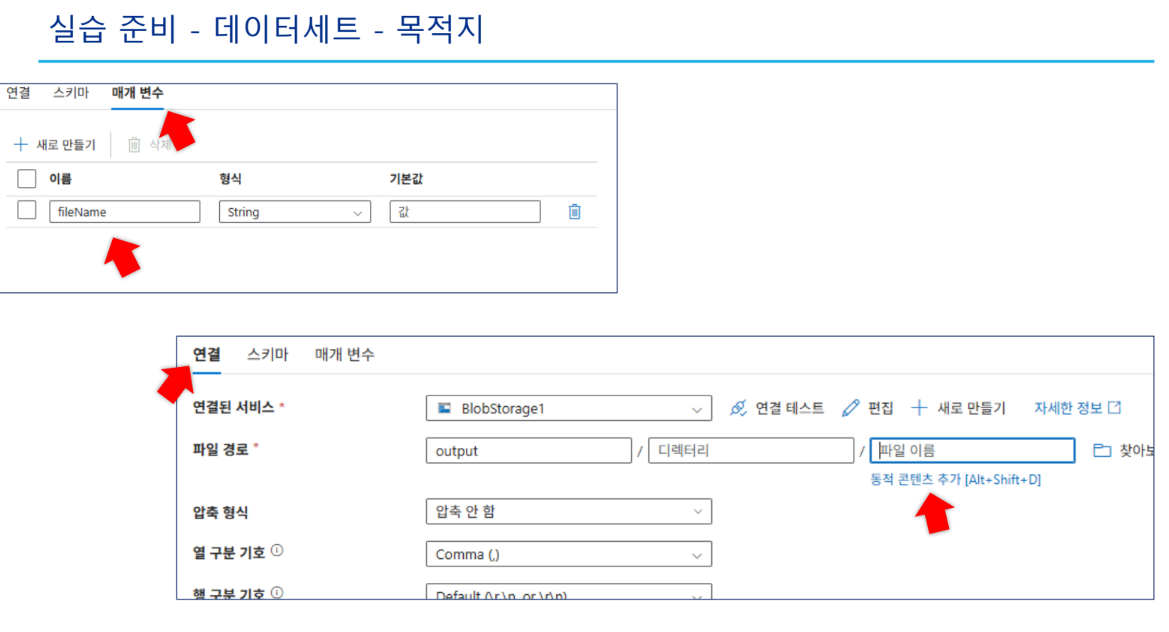
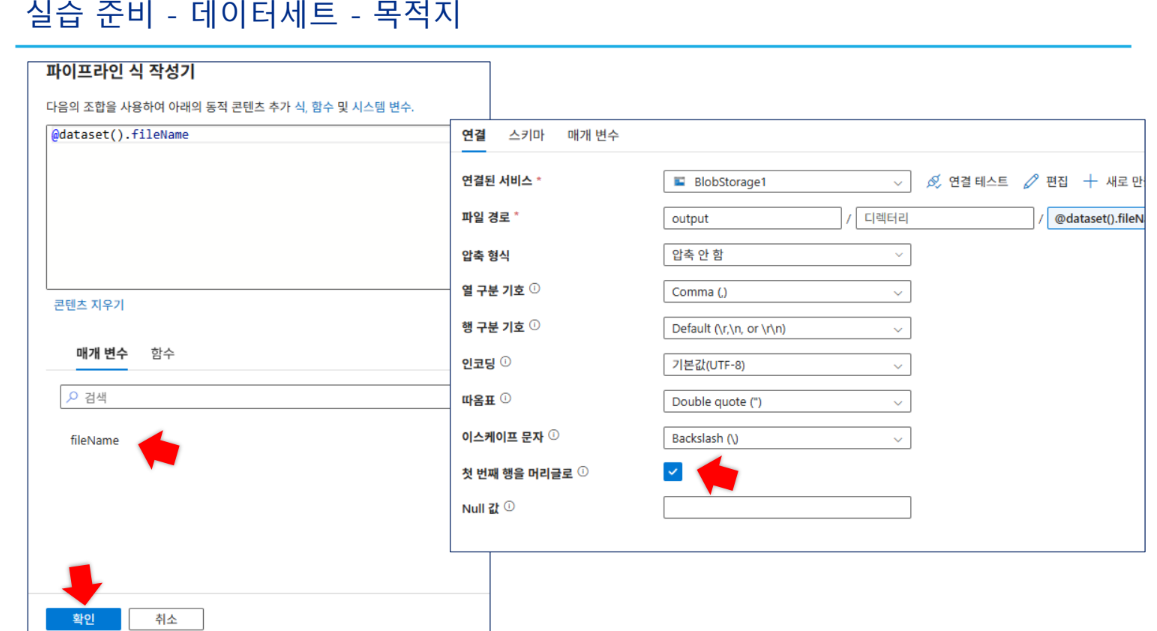
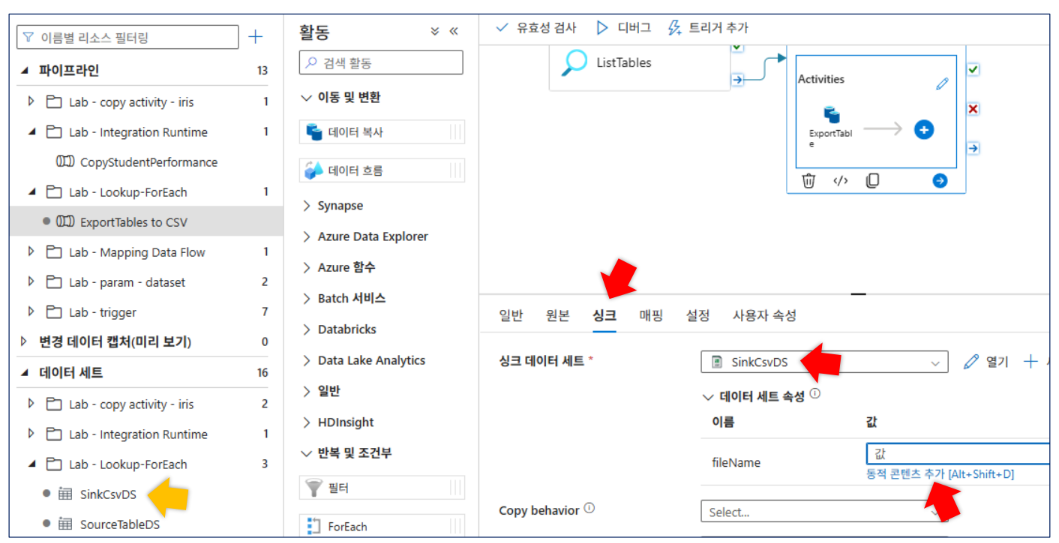
SinkCsvDS: 매개변수(
fileName)를 사용하여 동적으로 출력 파일명을 지정함
*fileName식:@dataset().fileName
4-2. 파이프라인 구성: Lookup 활동
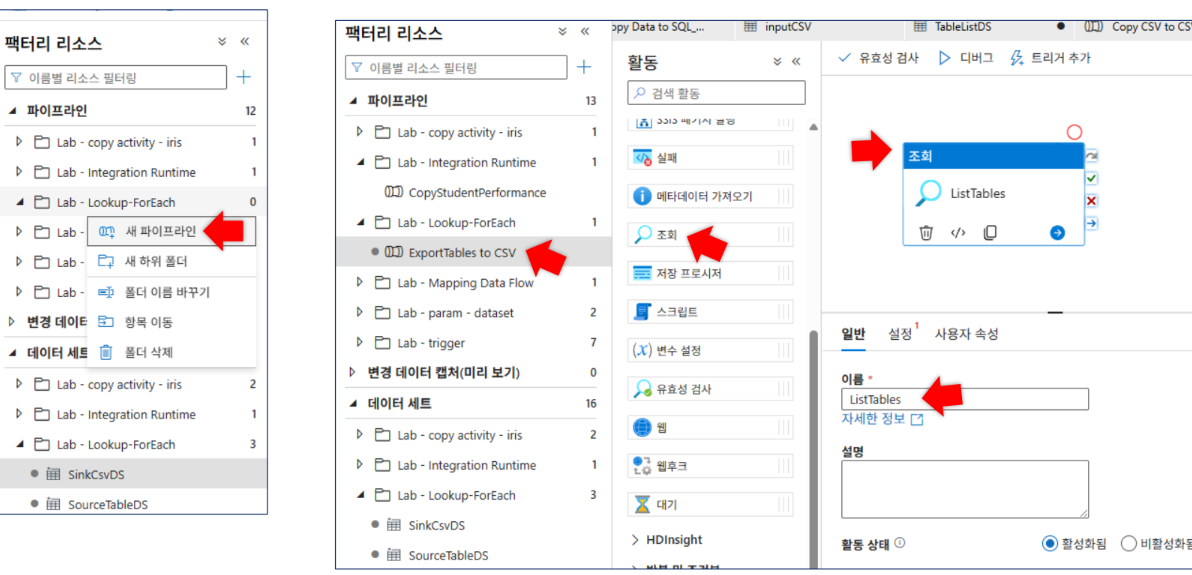
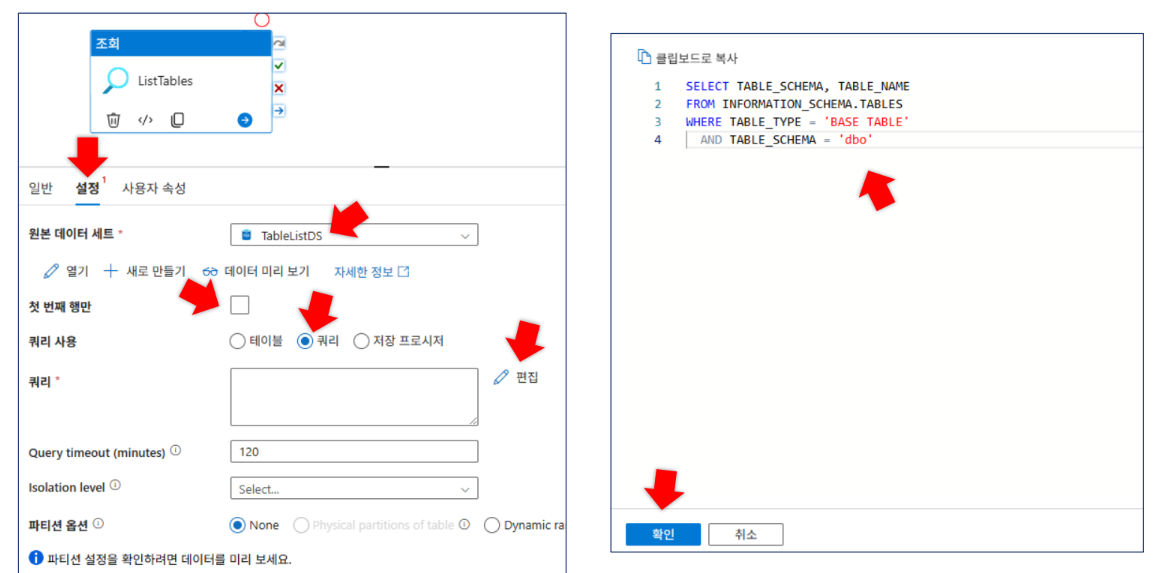
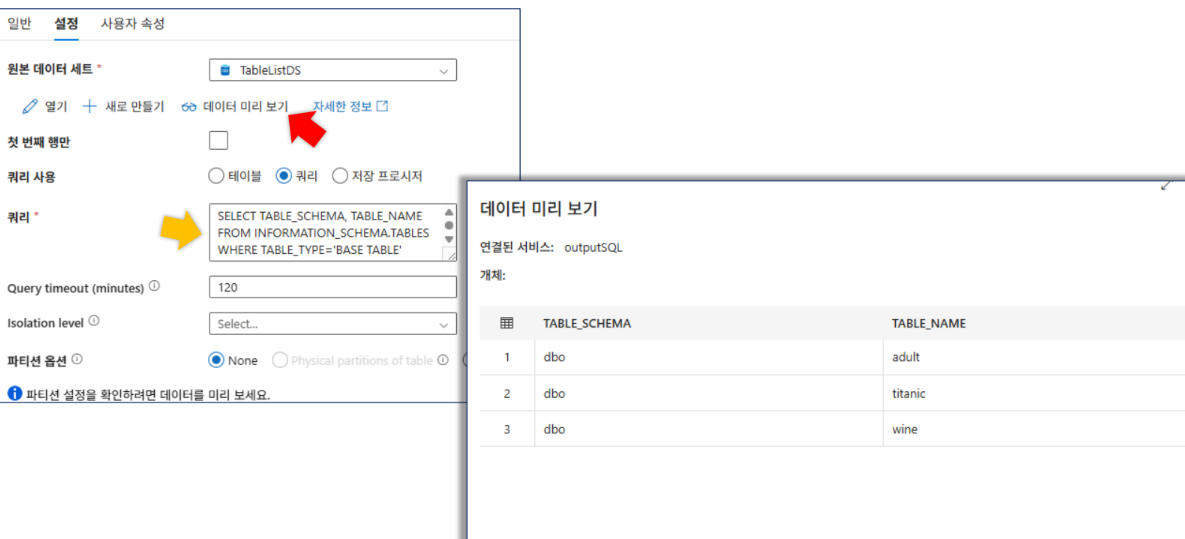
- 활동 이름:
ListTables - 원본 데이터세트:
TableListDS - 쿼리 실행:
SELECT TABLE_SCHEMA, TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE' AND TABLE_SCHEMA = 'dbo'
4-3. 파이프라인 구성: ForEach 활동
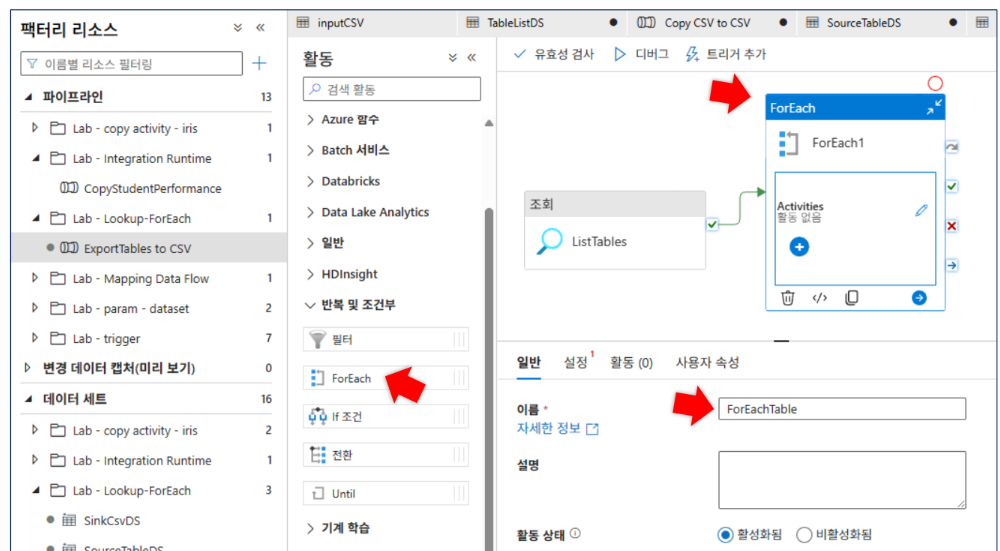
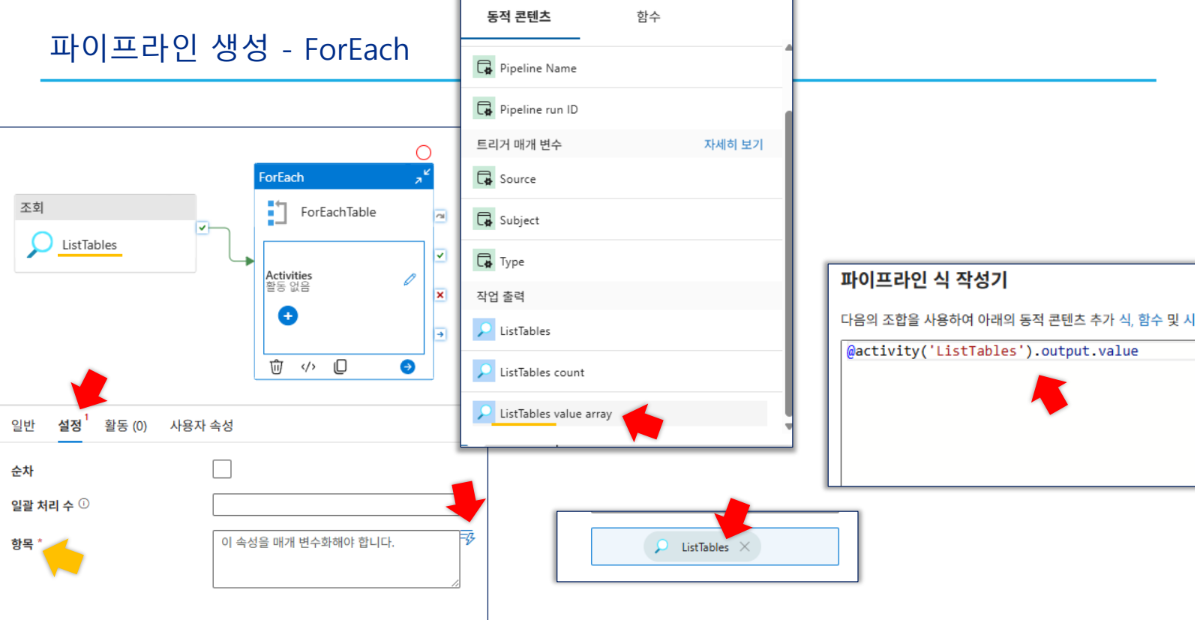
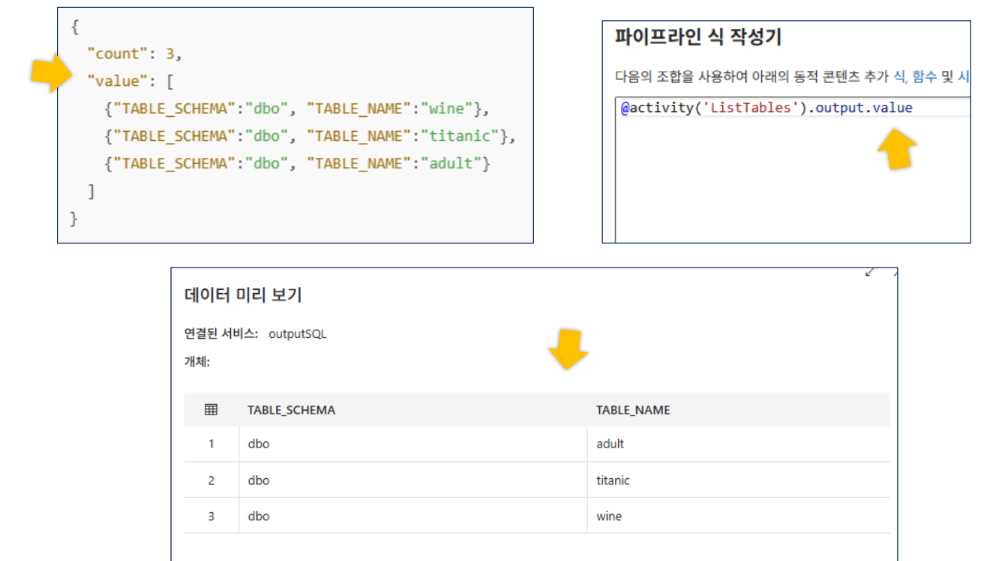
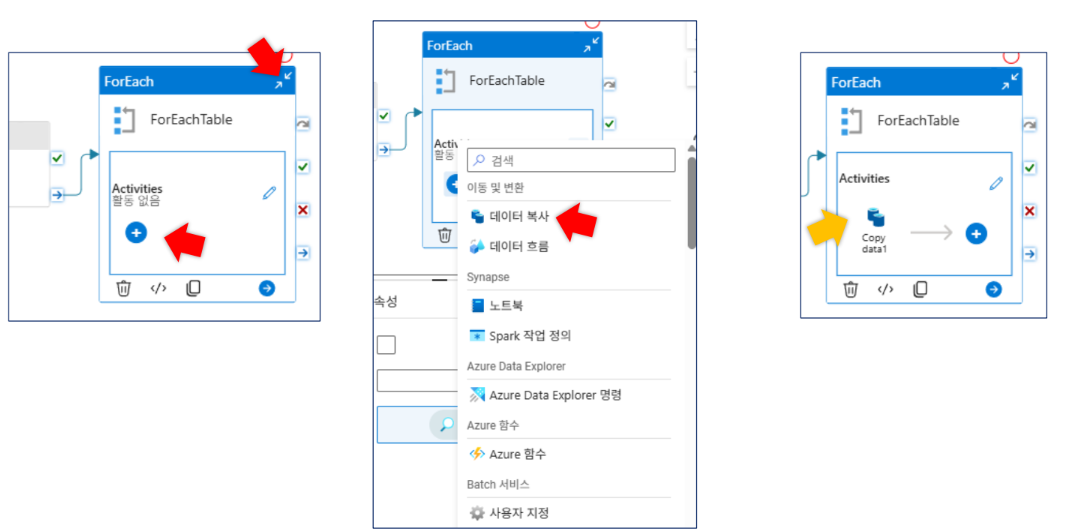
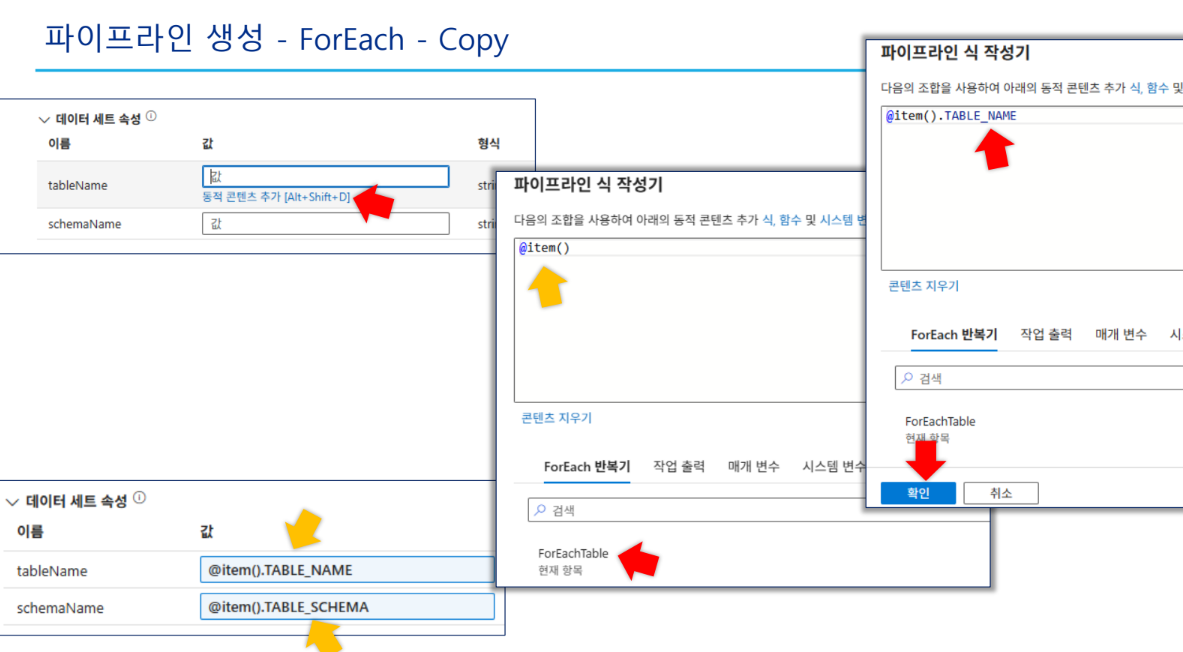
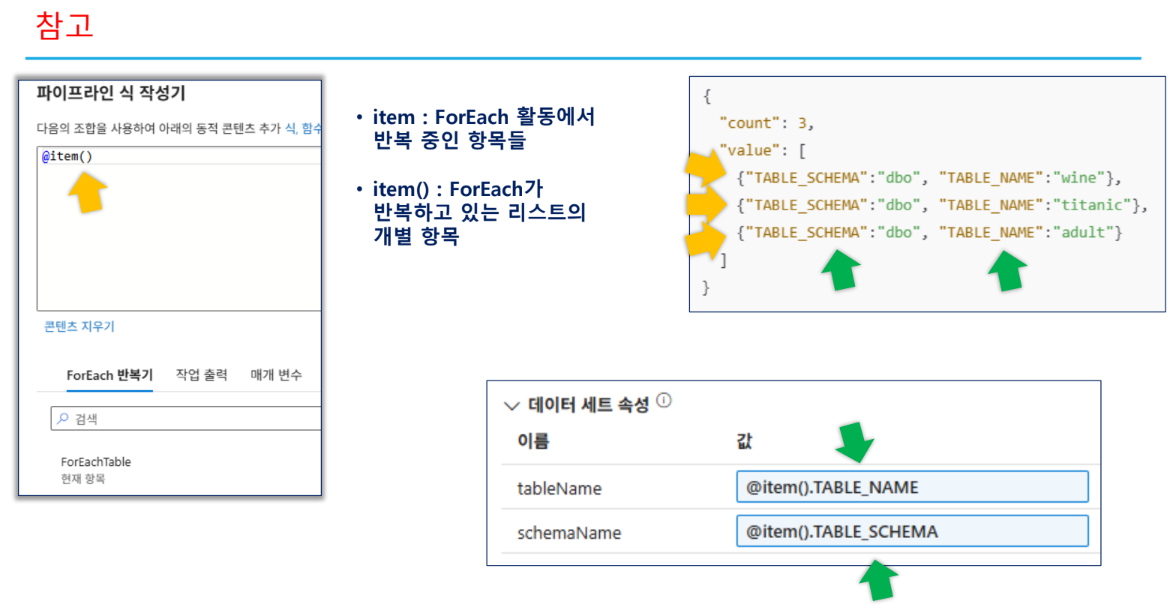
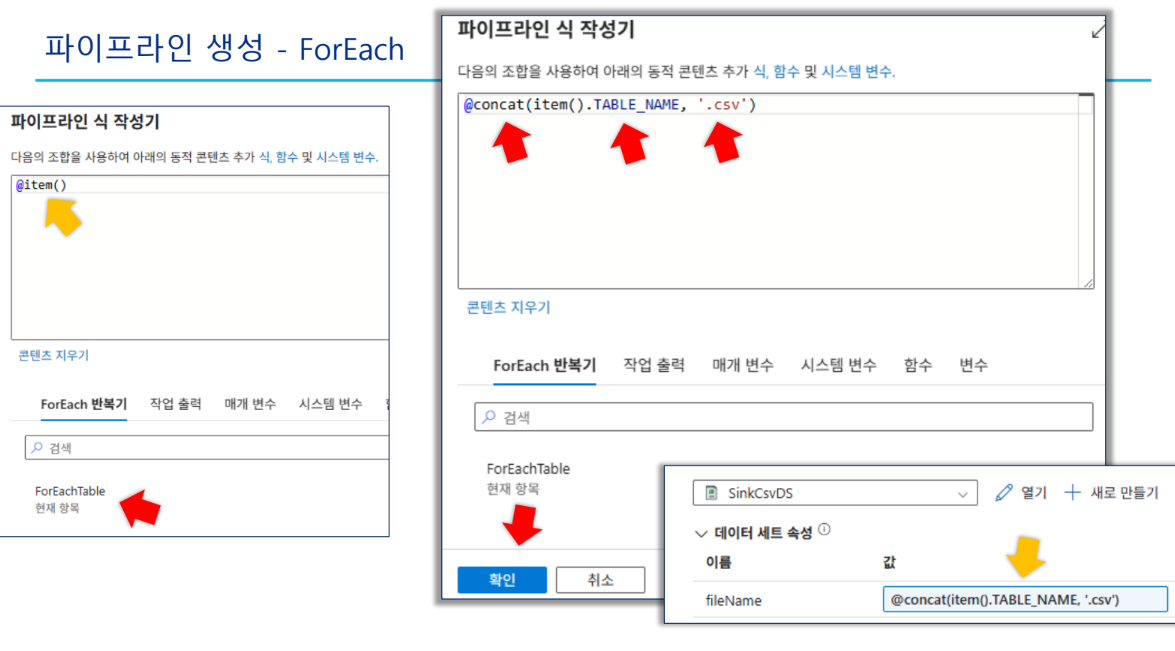
- 활동 이름:
ForEachTable - 항목(Items) 설정:
- 식:
@activity('ListTables').output.value
- 식:
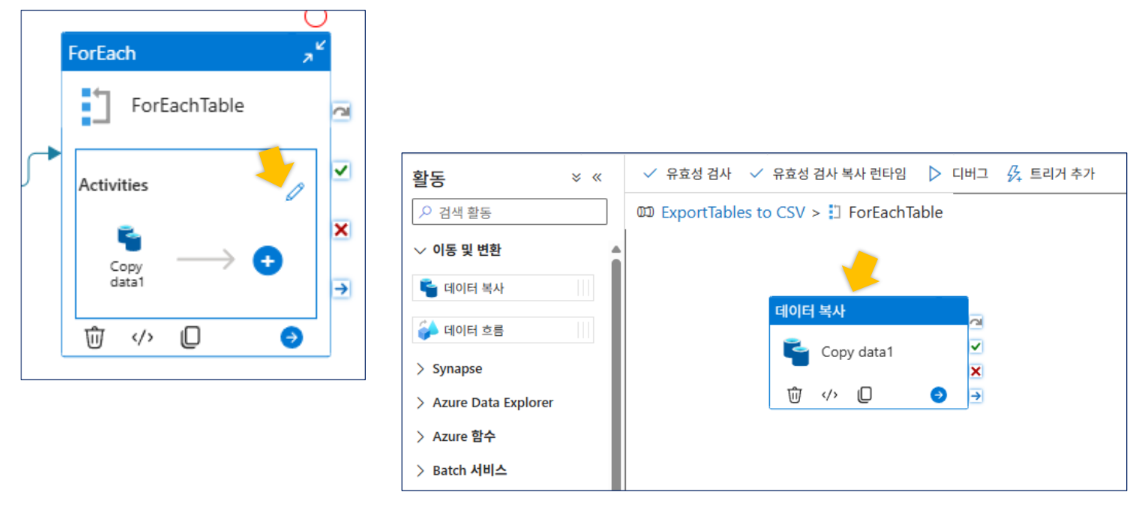
- 하위 활동(Copy Data):
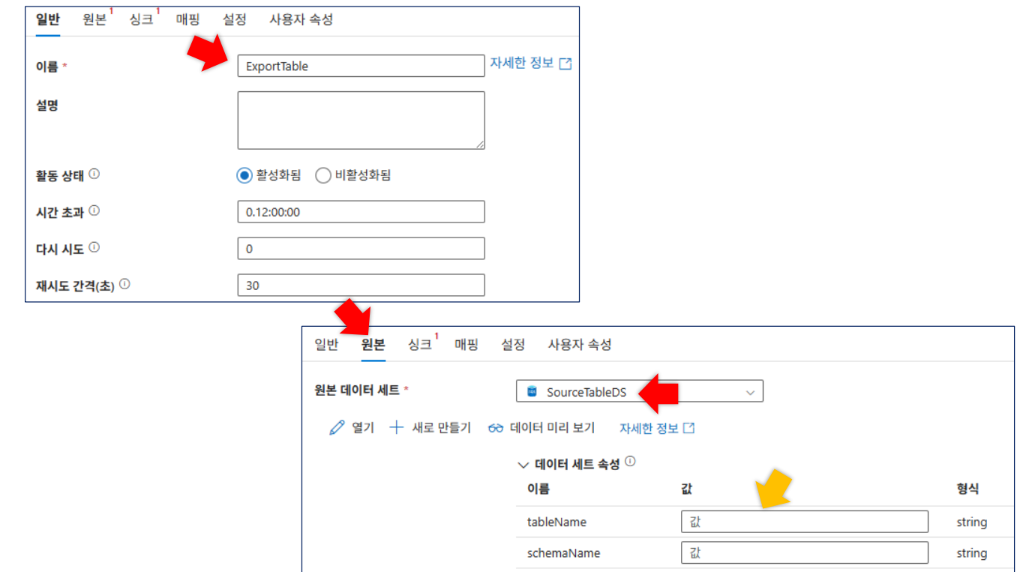
- 이름:
ExportTable - 원본(Source) 설정:
SourceTableDStableName:@item().TABLE_NAMEschemaName:@item().TABLE_SCHEMA
- 싱크(Sink) 설정:
SinkCsvDSfileName:@concat(item().TABLE_NAME, '.csv')
- 이름:
5. 결과 확인
-
파이프라인 실행: '모두 게시' 후 파이프라인을 실행합니다.
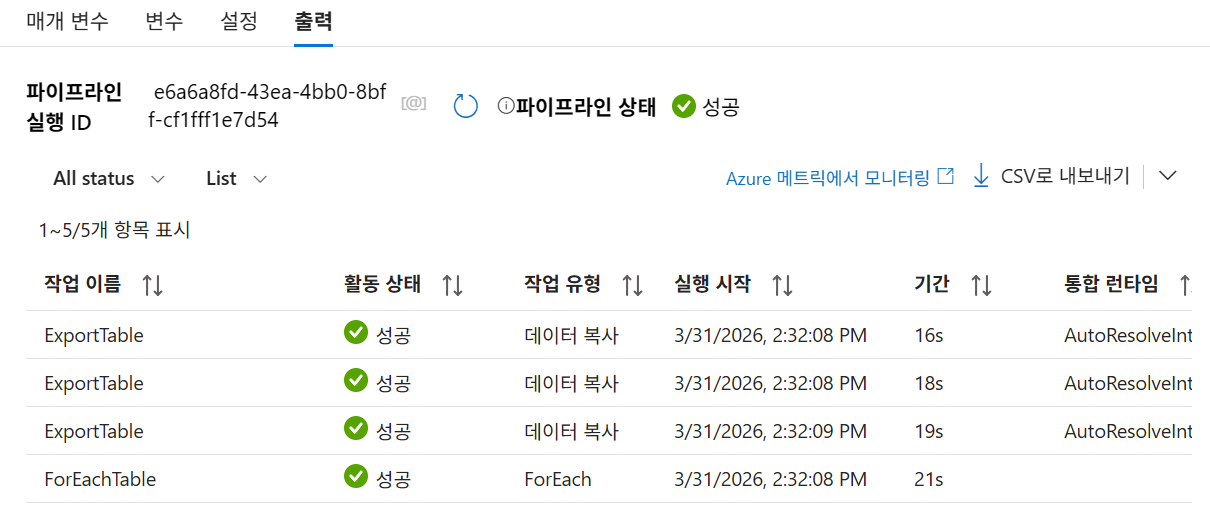
-
모니터링:
ListTables성공 후ForEachTable내에서 각 테이블(adult,titanic,wine)에 대한ExportTable활동이 성공했는지 확인합니다. -
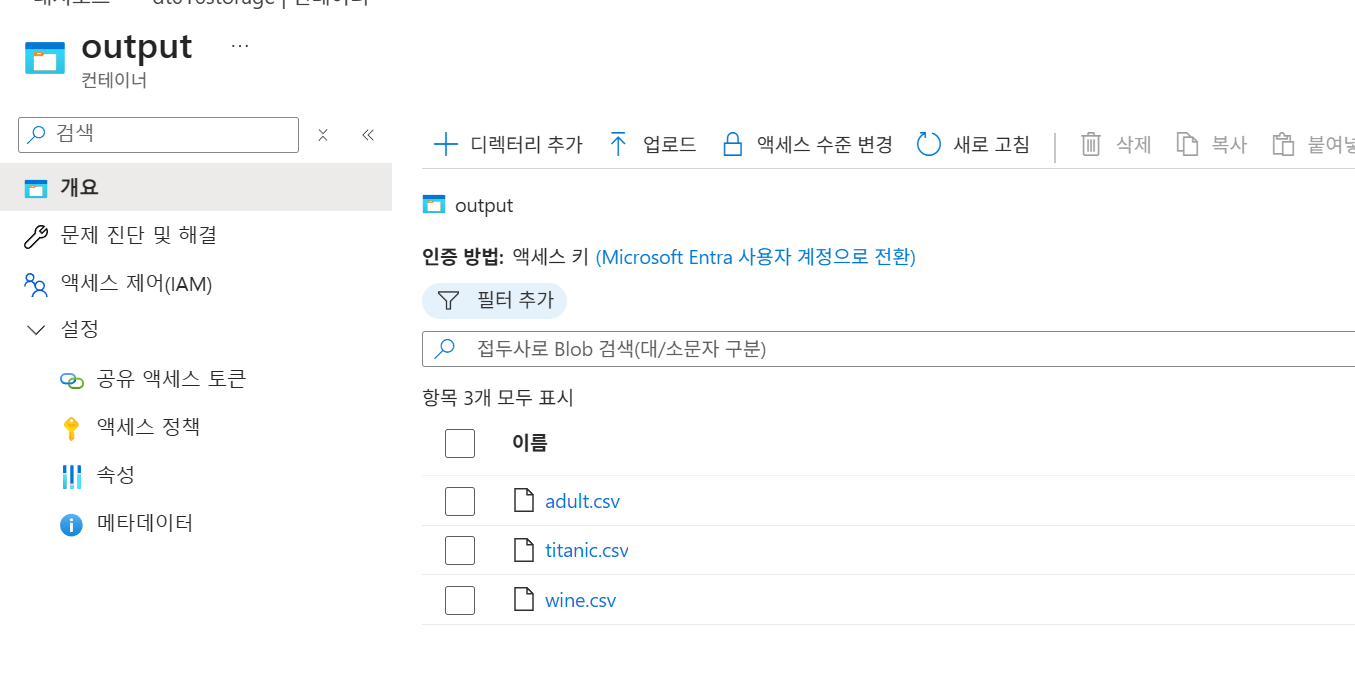
출력 확인: 스토리지의
output컨테이너에adult.csv,titanic.csv,wine.csv파일이 생성되었는지 확인합니다.
[Azure Data Factory] 이메일 알림 (Email Notification)
1. Azure Data Factory 이메일 알림 개요
다양한 상황에서 Azure Data Factory의 데이터 처리 상태를 사용자에게 알릴 필요가 있습니다. 이메일 알림은 이런 요구를 충족시키기 위한 유용한 수단입니다.
알림의 필요성
- 데이터 파이프라인이 자동으로 수행되기 때문에, 처리 상태에 대한 가시성이 부족할 수 있음.
- 운영자가 실시간으로 상태를 확인하기 어렵기 때문에, 자동 알림을 통해 시스템 신뢰도를 높일 수 있음.
- 알림을 통해 문제 발생 시 즉각적인 조치가 가능하며, 운영 효율성 향상에 기여.
알림 사용 사례
| 분류 | 사례 | 설명 |
|---|---|---|
| 개발/운영 | ETL 오류 또는 성능 지연 발생 | 운영팀에 오류 발생 사실 실시간 전달 |
| 보안/감사 | 민감한 데이터 이동 완료 시 | 감사 로그 목적의 알림 전송 |
| 데이터 분석 | 외부 시스템에서 데이터 수집 시작 시 | 자동화된 분석 시작 시점 감지 가능 |
| 보고서 갱신 | 데이터 변환 후 Power BI 리프레시 완료 | 사용자에게 최신 리포트 반영 시점 안내 |
2. 이메일 알림 구현 방식
Azure Data Factory는 이메일 알림을 위한 두 가지 구현 방식을 고려할 수 있습니다. 각 방식은 사용자의 목적에 따라 선택 가능합니다.
| 옵션 | 설명 | 장점 | 권장 시나리오 |
|---|---|---|---|
| Azure Monitor Alerts | Azure에서 기본 제공하는 모니터링 및 경보 기능을 통해 이메일 알림을 전송 | 설정 간편, 추가 비용 없음 | 단순 성공/실패 모니터링, 장애 감지 시 알림 |
| Web Activity + Logic Apps | ADF의 Web Activity에서 Logic Apps 호출 후, HTTP 트리거 기반의 이메일 전송 | 유연한 구성, 세부 커스터마이징 가능, HTML 이메일 가능 | 알림 내용 및 대상 사용자 지정, 포맷 설정 필요 시 |
- Azure Monitor Alerts는 사전 정의된 메트릭 조건 기반으로 동작하며, 주로 파이프라인 실패나 시간 초과 같은 이벤트 감지에 적합합니다.
- Logic Apps는 REST API 호출을 기반으로 하므로, 이메일 제목, 수신자, 본문 내용을 동적으로 설정할 수 있습니다. 특히 Power BI 리포트 생성 완료 후 알림, 맞춤형 템플릿 발송 등 세밀한 알림 제어가 필요할 경우 매우 유용합니다.
3. 실습 1 - Azure Monitor를 이용한 알림
3-1. Azure Monitor 개요
Azure Monitor는 Azure에서 기본 제공되는 종합 모니터링 및 알림 솔루션으로, 다양한 리소스 상태를 감시하고 이벤트 발생 시 알림을 보냅니다.
- 주요 기능: 클라우드 및 온프레미스 리소스 모니터링 가능, 응용/VM/DB/API 지원, Metric 기반 조건 설정 및 Alerts 트리거, Event Hub 및 Logic Apps 연동 가능,.
- 구성 요소: 특정 Activity/Pipeline 상태 감지 → 메트릭 조건 충족 시 알림 생성 → 이메일, SMS, Logic Apps 채널로 전달.
3-2. Azure Monitor 알림의 단점
- 이메일 포맷 변경 등은 제한적임.
- 고급 설정은 복잡함.
- 알림 전달까지 시간 지연이 있을 수 있음.
- 이메일의 가독성이 떨어질 수 있음.
3-3. 실습 단계
-
파이프라인 준비:
Lab - Email Alert내에AzureMonitorAlert파이프라인을 생성하고 실패를 유도하는 복사 활동을 구성합니다 -
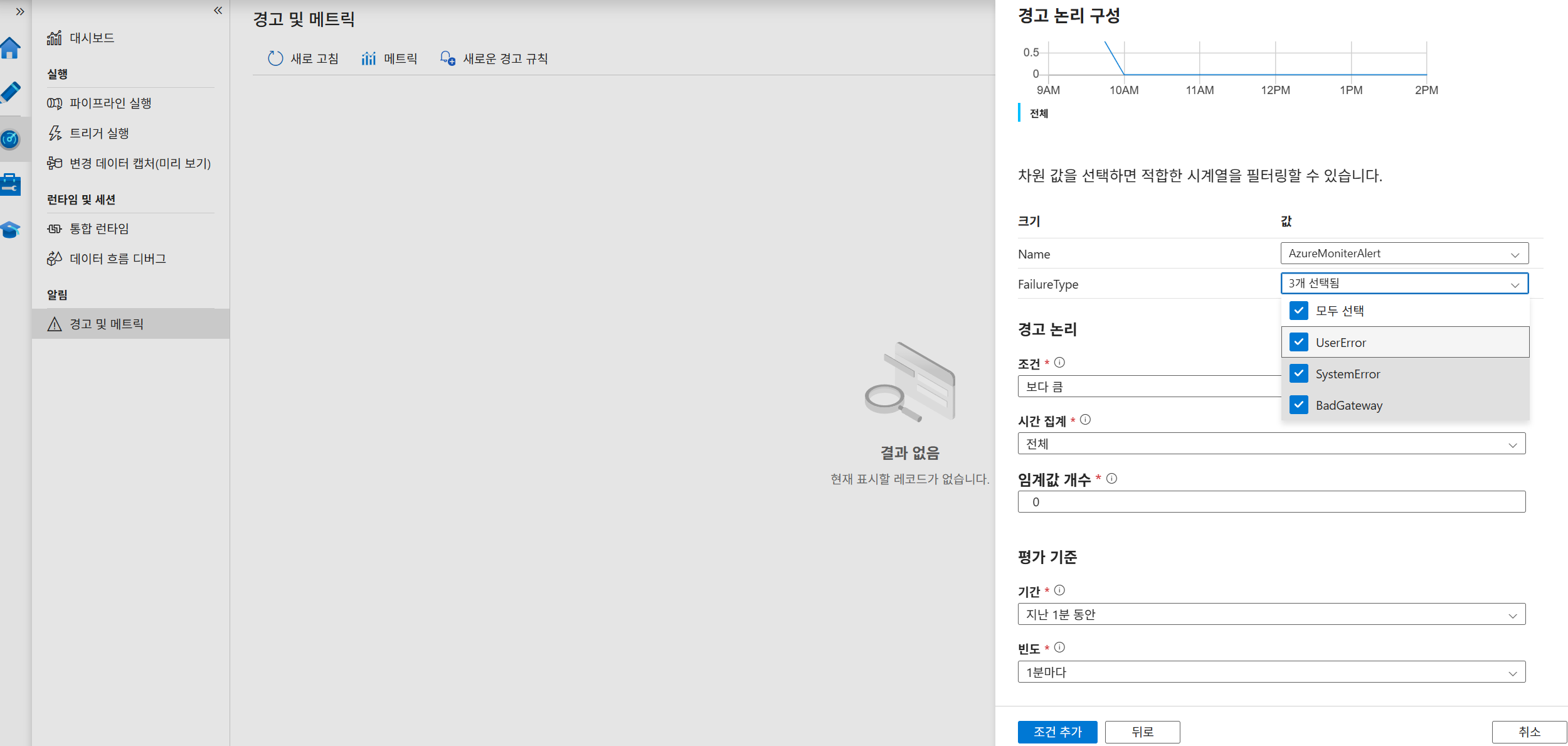
경고 규칙 생성: ADF 모니터링 탭의 [경고 및 메트릭]에서 [새로운 경고 규칙]을 클릭합니다.
-
조건 구성:
- 메트릭:
Failed pipeline runs metrics. - 경고 논리 조건: '보다 큼', 임계값 개수 '0'.
- 차원:
FailureType(UserError, SystemError, BadGateway 선택). - 평가 기준: 기간 '지난 1분 동안', 빈도 '1분마다'.
- 메트릭:
-
알림 및 작업 그룹 구성:
- 작업 그룹 이름:
Test group. - 알림 유형: '이메일' 선택 후 수신 메일 주소 입력
- 작업 그룹 이름:
-
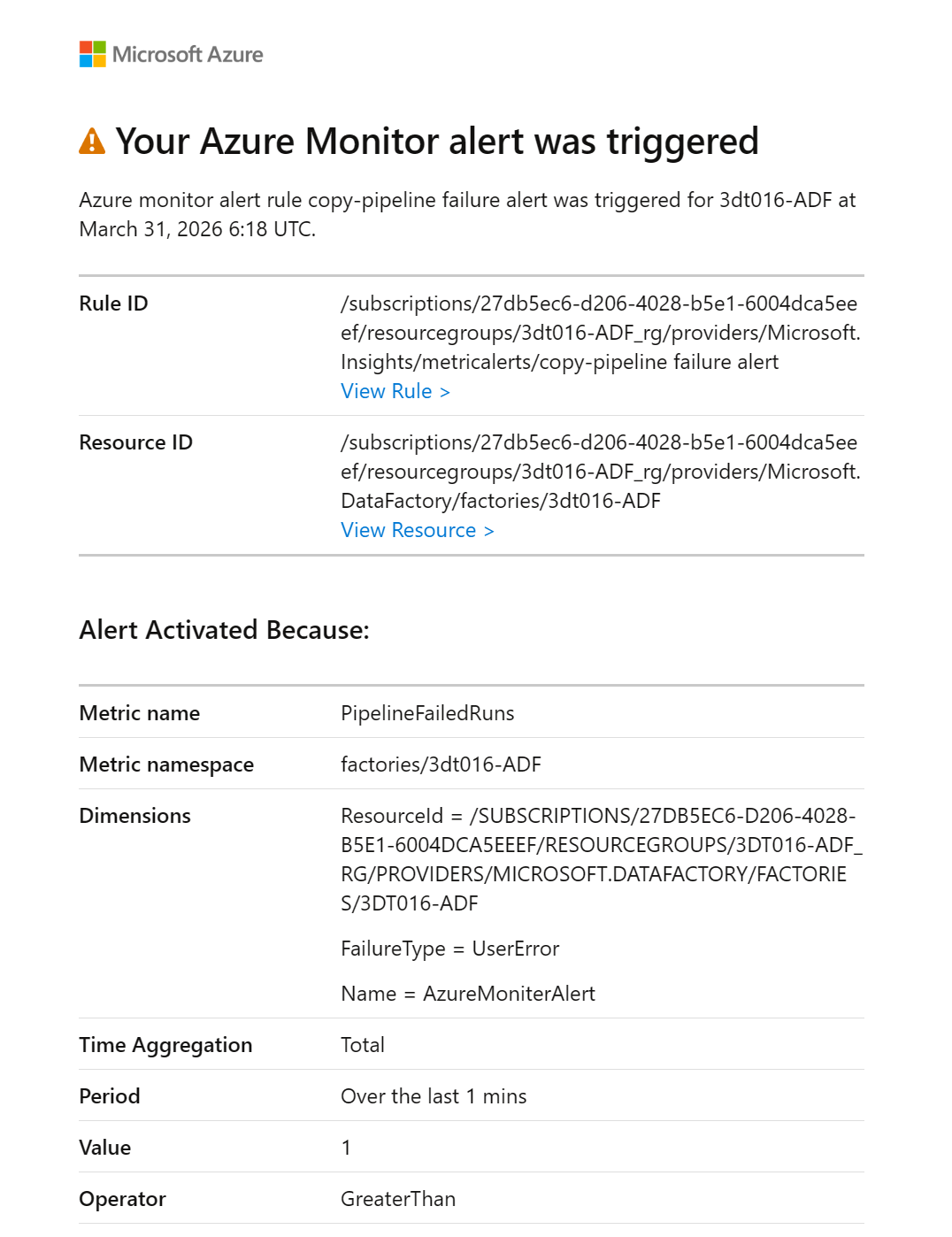
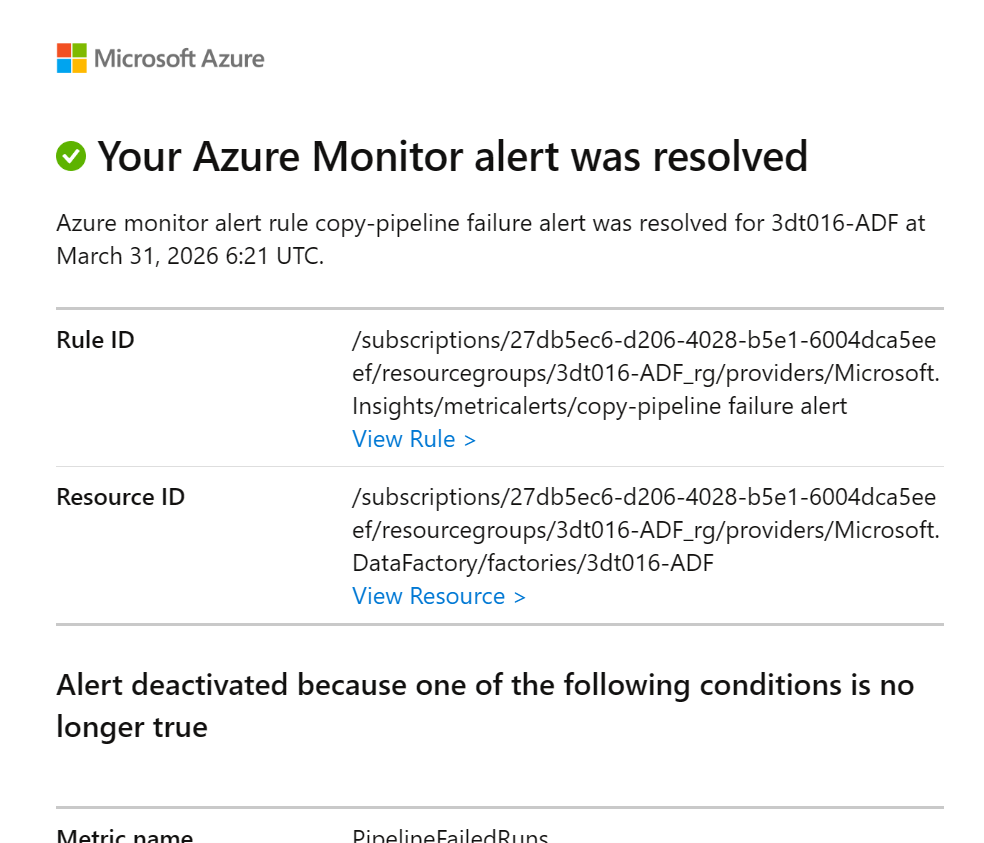
테스트 및 확인: 파이프라인 실행 후 실패가 발생하면 설정한 메일로 알림이 오는지 확인합니다. (디버그하면 안됨, 트리거 사용)
[수신 이메일 예시 - Activated]
Your Azure Monitor alert was triggered
Rule: copy-pipeline failure alert
Metric: PipelineFailedRuns
Value: 1
,
[수신 이메일 예시 - Deactivated]
Your Azure Monitor alert was resolved
Alert deactivated because one of the following conditions is no longer true.
4. 실습 2 - Web Activity와 Logic Apps를 이용한 알림
4-1. 절차 및 장점
- 절차: ADF 내 Web Activity에서 Logic Apps HTTP 트리거 호출 → Logic Apps에서 이메일 전송 및 응답 처리.
- 장점: 내용 및 포맷 자유 구성 가능, 조건에 따른 분기 처리, HTML 이메일 구현 가능.
4-2. 실습 준비
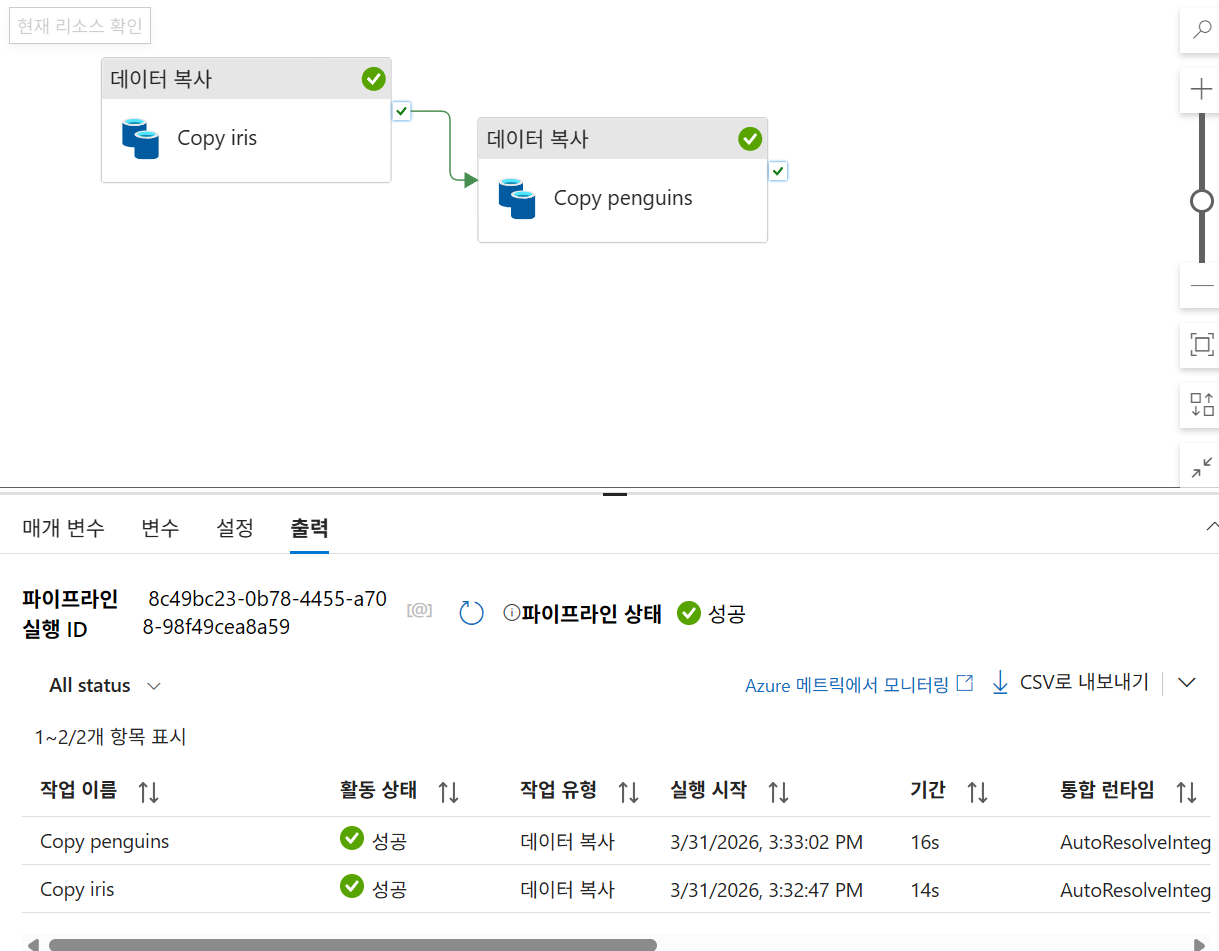
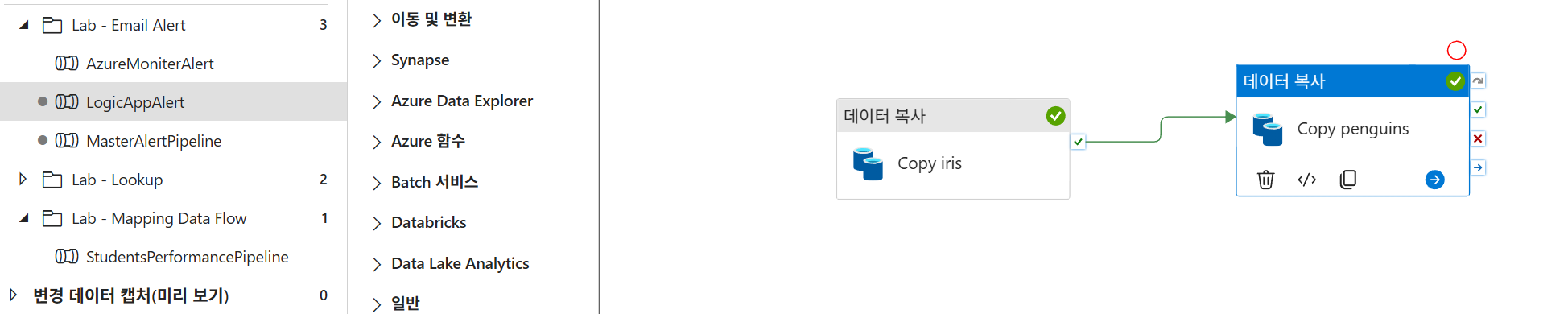
- 복사 파이프라인:
Copy iris,Copy penguins활동을 포함하는LogicAppAlert파이프라인을 생성합니다,. - 데이터:
iris.csv,penguins.csv파일을 스토리지에 준비합니다,.
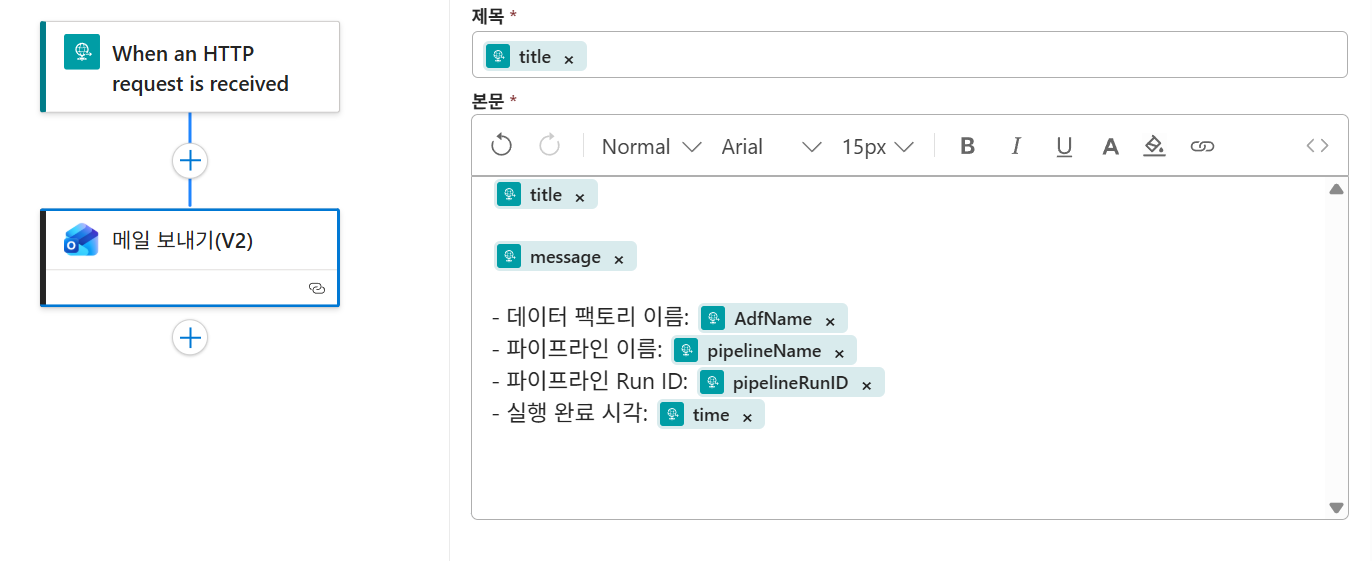
4-3. Logic App 생성 및 트리거 구성
- 리소스 생성: Azure Portal에서 '논리 앱(Logic App)'을 검색하여 '소비(Consumption)' 플랜으로 생성합니다,,.
- HTTP 트리거 추가: 논리 앱 디자이너에서 'When an HTTP request is received' 트리거를 추가합니다.
- JSON 스키마 생성: 아래 샘플 페이로드를 사용하여 스키마를 생성합니다
{
"type": "object",
"properties": {
"title": {
"type": "string"
},
"message": {
"type": "string"
},
"AdfName": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"pipelineRunID": {
"type": "string"
},
"time": {
"type": "string"
}
}
}
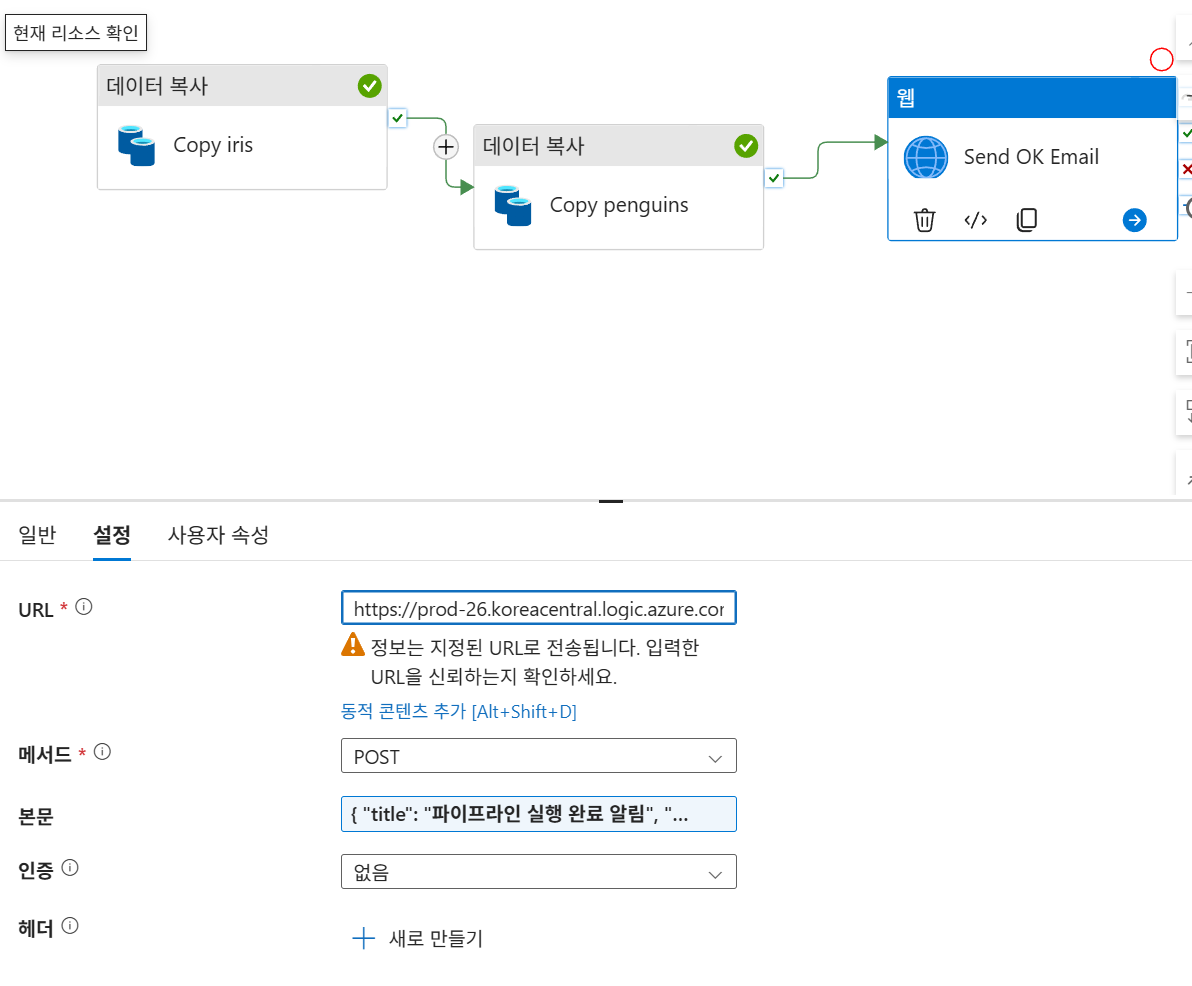
4-4. ADF Web Activity 설정
- 활동 추가:
Send OK Email이름의 Web 활동을 추가합니다. - 설정:
- URL: Logic App에서 생성된 HTTP POST URL.
- 메서드:
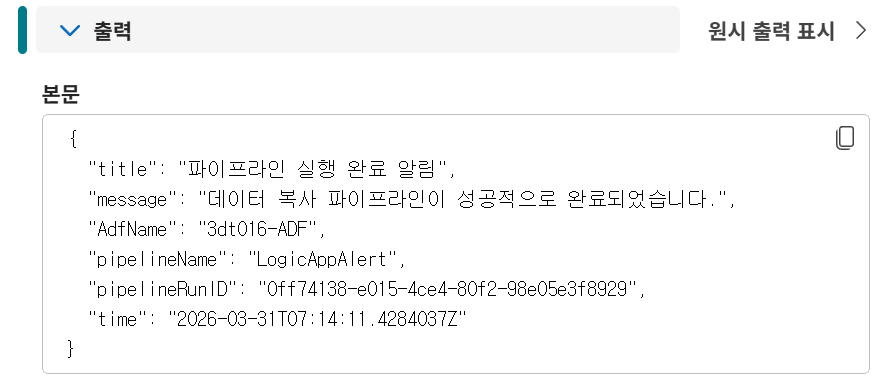
POST. - 본문(Body): 아래 동적 콘텐츠 식을 입력합니다
{
"title": "파이프라인 실행 완료 알림",
"message": "데이터 복사 파이프라인이 성공적으로 완료되었습니다.",
"AdfName": "@{pipeline().DataFactory}",
"pipelineName": "@{pipeline().Pipeline}",
"pipelineRunID": "@{pipeline().RunId}",
"time": "@{utcNow()}"
}
4-5. Logic App 이메일 동작 추가
- 동작 추가: 'Outlook.com' 커넥터의 '메일 보내기(V2)'를 선택합니다,.
- 본문 구성: HTTP 트리거에서 받은 동적 콘텐츠를 사용하여 HTML 포맷으로 본문을 작성합니다.
- 제목:
title - 본문 예시:
- 데이터 팩토리 이름: AdfName - 파이프라인 이름: pipelineName - 파이프라인 Run ID: pipelineRunID - 실행 완료 시각: time - 제목:
4-6. 결과 확인
- 성공 시 이메일 제목:
파이프라인 실행 완료 알림. - 본문 내용에 실제 ADF 리소스 이름과 실행 시각 등이 포함되어 전송됩니다.
5. 파이프라인 실패 알림 추가 (심화)
성공 알림뿐만 아니라 실패 시에도 알림을 보내기 위해 파이프라인을 확장합니다.
- 실패용 활동 추가:
send NOK Email이름의 Web 활동을 생성하고 실패 경로(빨간색 선)로 연결합니다. - 본문 설정:
{ "title": "파이프라인 실행 실패 알림", "message": "데이터 복사 파이프라인의 실행이 실패하였습니다.", "AdfName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "pipelineRunID": "@{pipeline().RunId}", "time": "@{utcNow()}" }
Master 파이프라인 활용
실제 운영 시에는 개별 파이프라인에 매번 알림을 넣기보다 MasterAlertPipeline을 구축하여 호출된 파이프라인의 에러 메시지를 전달하는 방식이 효율적입니다,.
- 실패 메시지 전달 식:
```json { "title": "파이프라인 실행 실패 알림", "message": "@{activity('Execute Pipeline1').error.message}", "AdfName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "pipelineRunID": "@{pipeline().RunId}", "time": "@{utcNow()}" } ```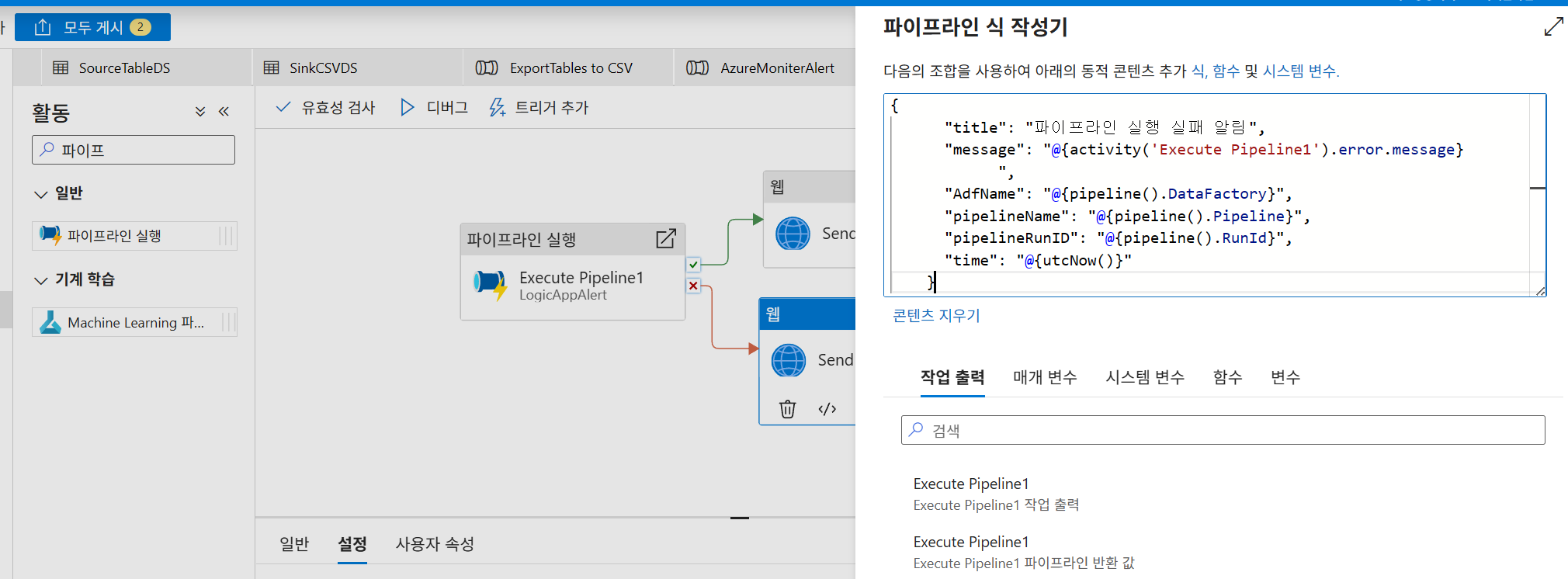
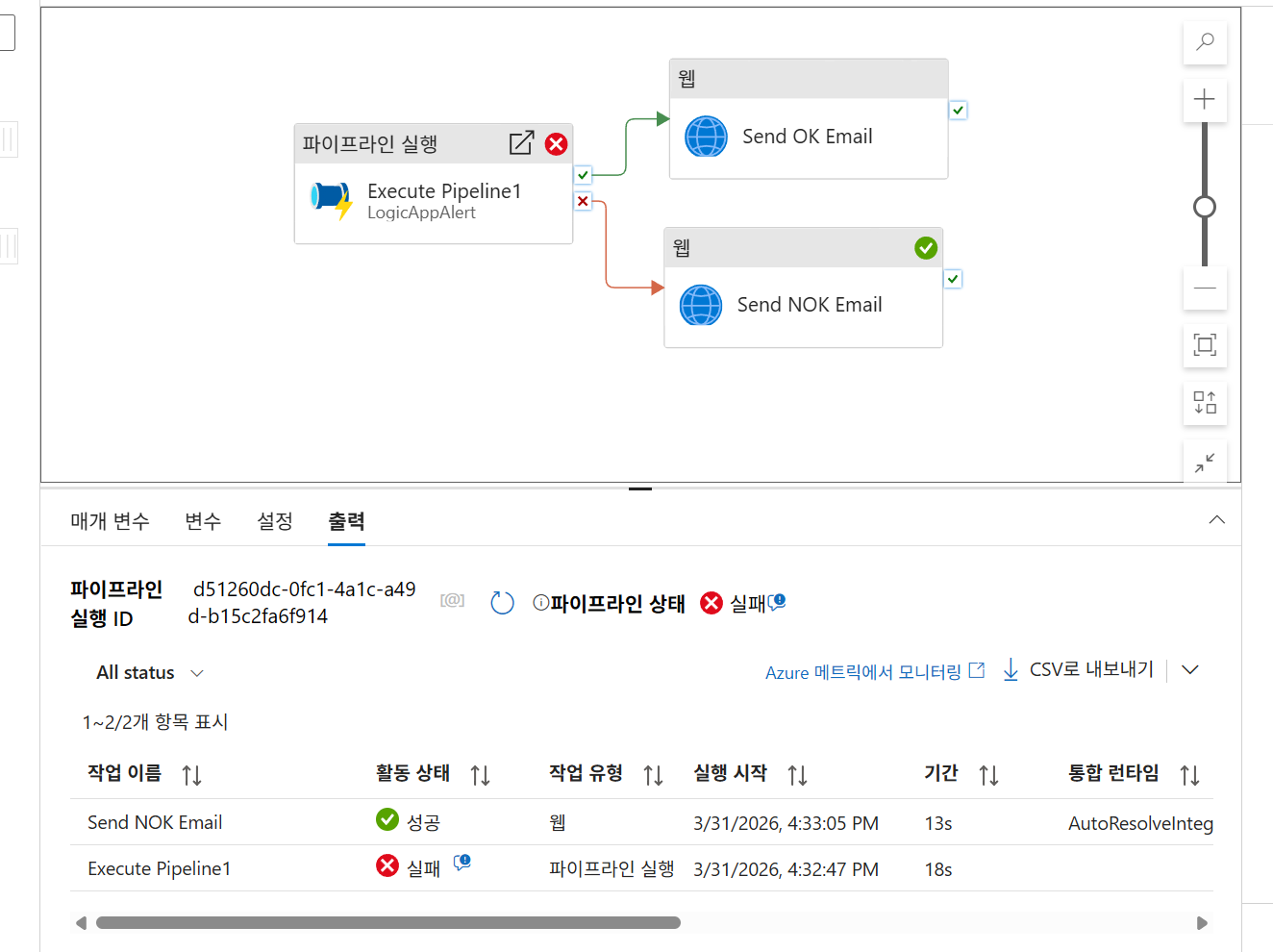
최종 테스트 결과 (실패 시)
- 원본 파일을 삭제한 후 실행하면 다음과 같은 에러 메시지가 포함된 이메일이 수신됩니다.
6. 실습 마무리
실습이 끝나면 불필요한 비용 발생을 방지하기 위해 생성한 모든 리소스(Logic App, API Connection, Action Group 등)와 리소스 그룹을 삭제합니다,.
[Azure Data Factory] 필터 및 정렬 변환 (Filter-Sort Transformation)
1. 개요
데이터 변환 과정에서 특정 조건에 맞는 데이터를 선별하거나, 분석 효율을 높이기 위해 데이터를 정렬하는 과정은 필수적입니다. Azure Data Factory의 매핑 데이터 플로우(MDF)는 이를 시각적으로 구성할 수 있는 기능을 제공합니다.
필터 변환 (Filter Transformation)
필터 변환은 소스 데이터에서 지정한 조건을 만족하는 행(row)만 선택해 통과시키는 변환 단계입니다.
- 구성 요소:
- 조건식(Condition Expression): 특정 컬럼에 대한 비교 연산자(=, <, >, <=, >=, != 등) 및 논리 연산자(and, or)를 사용합니다.
- 예)
Score > 80,Category == 'A' and Region != 'Seoul'
- 예)
- 미리보기(Data Preview): 조건식 적용 후 결과를 즉시 확인할 수 있습니다.
- 조건식(Condition Expression): 특정 컬럼에 대한 비교 연산자(=, <, >, <=, >=, != 등) 및 논리 연산자(and, or)를 사용합니다.
- 장점:
- 불필요한 데이터를 미리 제거하여 후속 처리 성능을 향상시킵니다.
- 비즈니스 로직에 따른 데이터 선별을 시각적으로 구성 가능합니다.
- 사용 시나리오:
- 특정 기준 점수 이상인 학생만 추출
- 거래 상태가 '완료(Completed)'인 주문만 처리
- 결측치(null)나 이상치(outlier)를 제거
정렬 변환 (Sort Transformation)
정렬 변환은 입력된 데이터 세트를 하나 이상의 컬럼을 기준으로 오름차순 또는 내림차순으로 정렬하는 변환 단계입니다.
- 구성 요소:
- 정렬 키(Sort Key): 정렬 기준이 되는 컬럼을 선택합니다. 다중 컬럼 지정 시 우선순위에 따라 차례대로 정렬됩니다.
- 정렬 순서(Order): 오름차순(Ascending) 또는 내림차순(Descending)을 선택합니다.
- 미리보기(Data Preview): 정렬 결과를 즉시 확인할 수 있습니다.
- 장점:
- 사용자 요구에 따른 출력 순서를 제어합니다.
- 데이터 집계나 순위 분석 전에 데이터 순서를 명확히 정의합니다.
- 사용 시나리오:
- 시험 점수를 높은 순서대로 정렬해 상위 10명 출력
- 거래 일자 기준으로 과거 → 최신 순으로 정렬
- 고객 등급과 가입 일자를 복합 기준으로 정렬
2. 실습 준비
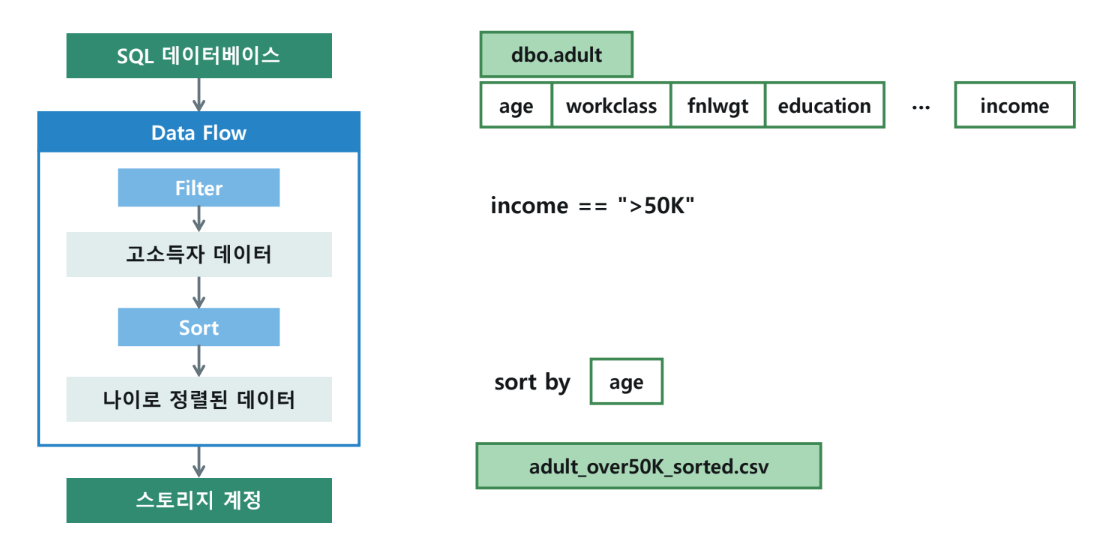
실습 구성
- SQL 데이터베이스:
dbo.adult테이블 사용 (age, workclass, income 등 포함). - Data Flow:
- Filter:
income == ">50K"(고소득자 데이터 선별). - Sort: 나이(age) 기준으로 오름차순 정렬.
- Filter:
- 스토리지 계정:
adult_over50K_sorted.csv파일로 저장.
데이터 및 테이블 준비
- 실습 데이터: Adult Census Income (Kaggle 데이터).
- 테이블 생성 쿼리 (필요 시 실행):
CREATE TABLE adult ( age INT, workclass NVARCHAR(20), fnlwgt INT, education NVARCHAR(20), education_num INT, marital_status NVARCHAR(30), occupation NVARCHAR(20), relationship NVARCHAR(20), race NVARCHAR(20), sex NVARCHAR(10), capital_gain INT, capital_loss INT, hours_per_week INT, native_country NVARCHAR(30), income NVARCHAR(10) ); - 데이터 확인:
select count(*) from [dbo].[adult]실행 시 32,561건 확인. - 목적지 컨테이너: 스토리지 계정 내
output컨테이너 준비.
링크드 서비스 및 데이터세트 구성
- 링크드 서비스:
outputSQL(Azure SQL DB),BlobStorage1(Azure Blob Storage). - 소스 데이터세트 (
AdultSqlInput_DS): SQL DB의dbo.adult테이블 연결. - 싱크 데이터세트 (
AdultCsvOutput_DS): Blob Storage의output컨테이너 연결.
3. [실습 1] 필터 및 정렬 변환 구성

3-1. 데이터 플로우 생성 및 소스 추가
- 매핑 데이터 플로우 생성: 이름
FilterSort_DF. - 데이터 흐름 디버그 켜기: Small 크기, 1시간 TTL 설정.
- 소스 추가:
- 출력 스트림 이름:
adult. - 데이터 세트:
AdultSqlInput_DS. - 프로젝션: age(integer), workclass(string), income(string) 등 형식 확인.
- 출력 스트림 이름:
3-2. 필터 변환 설정 (FilterHighIncome)
- 필터 활동 추가: 소스 뒤에
Filter활동 연결. - 속성 설정:
- 출력 스트림 이름:
FilterHighIncome. - 들어오는 스트림:
adult.
- 출력 스트림 이름:
- 필터 식 입력 (식 작성기 활용):
income == ">50K" - 미리보기: 데이터가
>50K인 행만 남는지 확인.
3-3. 정렬 변환 설정 (SortByAge)
- 정렬 활동 추가: 필터 활동 뒤에
Sort활동 연결. - 속성 설정:
- 출력 스트림 이름:
SortByAge. - 들어오는 스트림:
FilterHighIncome.
- 출력 스트림 이름:
- 정렬 조건:
- 열:
age. - 순서:
오름차순 (Ascending).
- 열:
- 미리보기: 나이가 적은 순서(22, 23, 24...)로 정렬되는지 확인.
3-4. 싱크 설정 및 파이프라인 실행
- 싱크 추가:
AdultHighIncomeSortedSink추가 및AdultCsvOutput_DS연결. - 설정: '단일 파티션' 지정 후 단일 파일로 출력 선택, 파일명
adult_highincome_sorted.csv입력. - 파이프라인 생성:
FilterSortAdult_PL생성 후 데이터 플로우 활동 추가. - 실행 및 확인: 파이프라인 성공 후
output컨테이너에서 결과 파일 확인.
4. [실습 2] 필터 및 정렬 매개변수화 (Advanced)
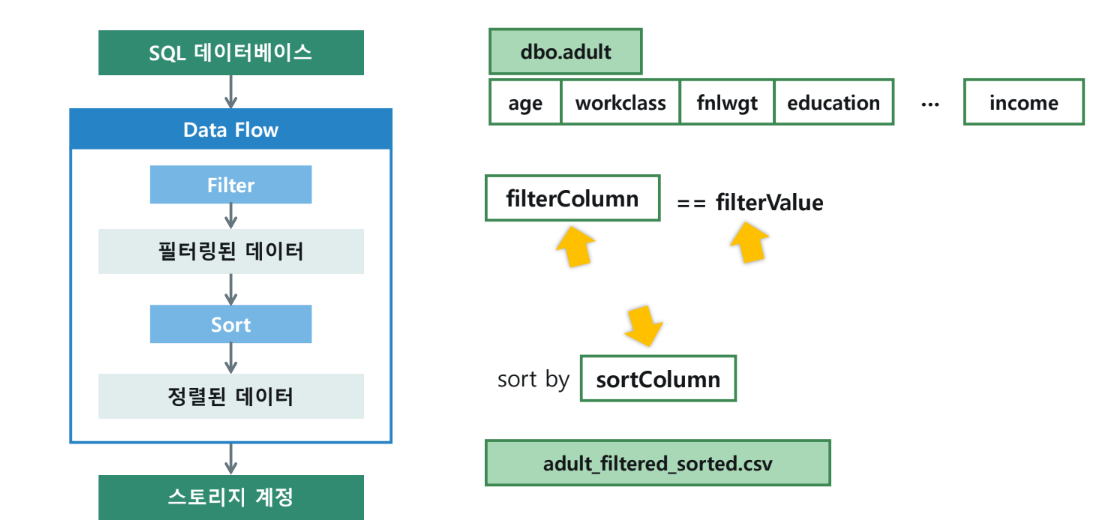
고정된 값이 아닌, 실행 시점에 입력받은 값으로 필터링하고 정렬할 수 있도록 구성을 변경합니다.
4-1. 데이터 플로우 매개변수 정의
매핑 데이터 플로우의 [매개 변수] 탭에서 다음 항목을 추가합니다.
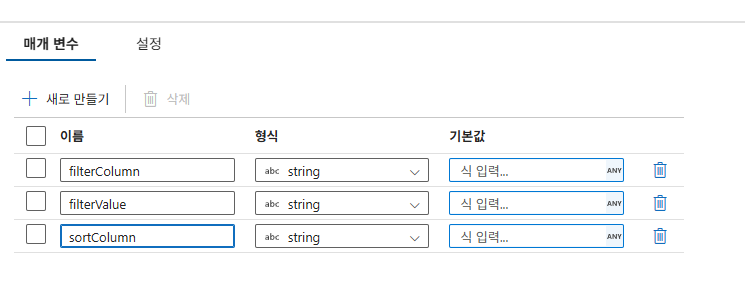
filterColumn(string): 필터링할 컬럼 이름.filterValue(string): 필터링할 기준 값.sortColumn(string): 정렬할 컬럼 이름.
4-2. 매개변수 기반 식 작성
- 필터 식 수정 (
FilterAdult):
컬럼의 데이터 형식을 고려하여 동적으로 비교하는 식을 작성합니다.case( type(byName($filterColumn))=='Integer', toInteger(byName($filterColumn)) == toInteger($filterValue), toString(byName($filterColumn)) == $filterValue ) - 정렬 식 수정 (
SortByParam):
정렬 조건의 열을 식 작성기에서 매개변수로 지정합니다.byName($sortColumn)
4-3. 파이프라인 매개변수 연결
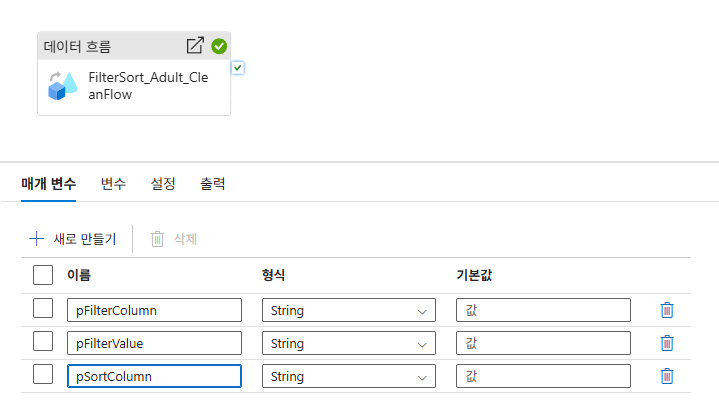
- 파이프라인 매개변수 생성:
pFilterColumn,pFilterValue,pSortColumn생성. - 매핑: 파이프라인 활동의 [매개 변수] 탭에서 데이터 플로우 매개변수와 파이프라인 매개변수를 연결합니다.
filterColumn=@pipeline().parameters.pFilterColumnfilterValue=@pipeline().parameters.pFilterValuesortColumn=@pipeline().parameters.pSortColumn
4-4. 실행 및 결과 확인
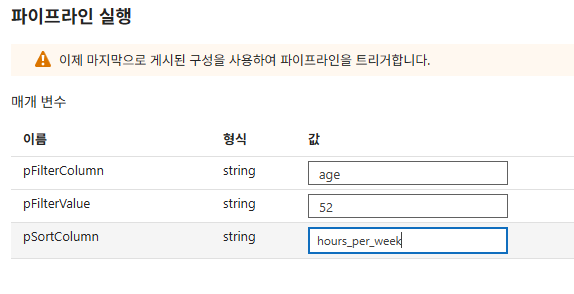
- 지금 트리거 클릭 후 매개변수 값 입력 예시:
pFilterColumn:agepFilterValue:52pSortColumn:hours_per_week
- 결과: 나이가 52세인 데이터들만 추출되어 주당 근무 시간순으로 정렬된
adult_filtered_sorted.csv파일이 생성됩니다.

실습 마무리: 모든 작업이 완료되면 비용 발생 방지를 위해 데이터 흐름 디버그 모드를 반드시 중지하십시오.
[Azure Data Factory] 메타데이터 활동 (Get Metadata Activity)
1. 메타데이터 활동(Get Metadata Activity) 개요
Get Metadata 활동은 데이터 소스(파일, 폴더, 테이블 등)의 메타데이터(크기, 수정일, 컬럼 목록 등)를 조회하는 데이터팩토리의 처리 단계입니다.
구성 요소
- 데이터셋(Dataset): 데이터 소스의 연결 정보 및 경로를 지정합니다.
- 조회할 필드(Field list): 다음과 같은 필요한 메타데이터 항목을 선택합니다.
childItems: 폴더 내 하위 항목 목록exists: 데이터 소스 존재 여부lastModified: 마지막 수정 시간size: 파일 크기structure: 데이터 구조(컬럼 목록) 등
- 필터(Pattern/Field filter): 특정 파일 확장자나 경로 패턴에 따라 조회 대상을 제한합니다.
장점
- 동적 분기 처리: 메타데이터를 기반으로 조건 분기 및 재시도 로직 구현이 가능합니다.
- 효율적 파이프라인 설계: 사전 검증을 통해 불필요한 복사 및 변환 작업을 예방합니다.
- 재사용성: 공통 메타데이터 조회 로직을 모듈화하여 여러 파이프라인에서 동일하게 활용할 수 있습니다.
사용 시나리오
- 파일 존재 여부 확인: 파이프라인 실행 전 대상 파일이 있는지 분기 처리합니다.
- 폴더 목록 조회: 폴더 내 파일, 하위 폴더 목록을 동적으로 파이프라인에 전달합니다.
- 테이블 스키마 조회: 테이블 컬럼 구조를 미리 확인하여 후속 매핑 데이터 흐름에 활용합니다.
2. [실습 1] 기본 메타데이터 조회
실습 준비
- 실습 데이터: UC Irvine Machine Learning Repository의 Wine Quality 데이터셋을 활용합니다.
- 데이터 특성: 레드 와인(
winequality-red.csv)과 화이트 와인(winequality-white.csv)의 화학적 테스트 결과 데이터입니다. - 데이터 형식: 세미콜론(
;)을 구분자로 사용하는 CSV 파일입니다. - 스토리지 구성:
wine-quality컨테이너 내에 위 두 파일을 업로드합니다.
파이프라인 및 데이터 세트 생성
- 파이프라인 생성:
GetMetadataWine_PL파이프라인을 생성하고 메타데이터 가져오기 활동을 추가합니다. - 데이터 세트 설정 (
wineContainer_DS):- 형식: Delimited Text (Azure Blob Storage).
- 연결된 서비스:
BlobStorage1. - 파일 경로:
wine-quality컨테이너 지정. - 열 구분 기호: Semicolon (;) 설정.
필드 목록 설정 및 실행
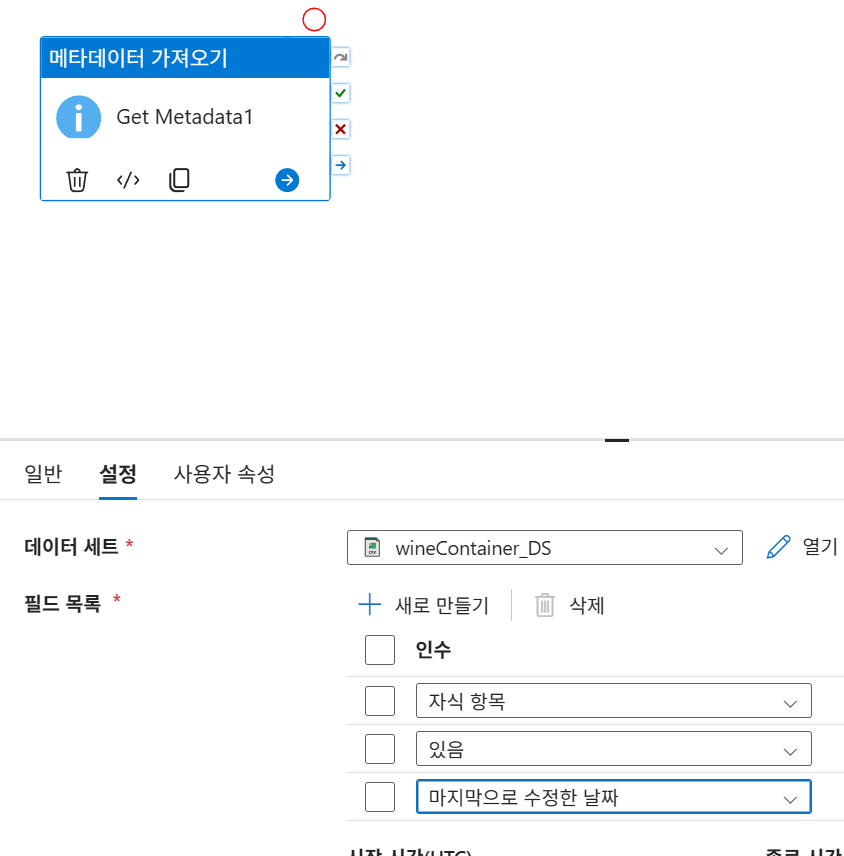
- 활동의 설정 탭에서 필드 목록을 다음과 같이 추가합니다.
existslastModifiedchildItems
- 결과 확인 (JSON 출력):

3. [실습 2] 메타데이터를 활용한 동적 파일 복사
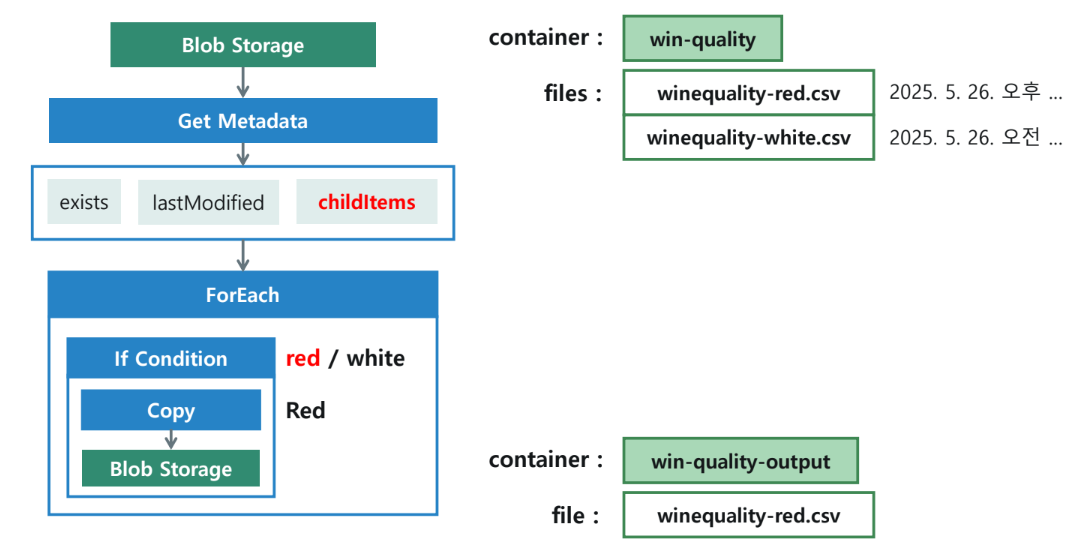
조회된 메타데이터 목록을 바탕으로 특정 조건(파일명에 'red' 포함)에 맞는 파일만 다른 컨테이너로 복사하는 실습입니다.
전체 흐름
- Get Metadata: 컨테이너 내 파일 목록 확인.
- ForEach: 파일 목록을 순회하며 반복.
- If Condition: 파일 이름에 'red'가 포함되어 있는지 확인.
- Copy Data: 조건이 참인 경우
wine-quality-output컨테이너로 복사.
활동별 세부 설정
1) ForEach 활동 (ForEachWineFiles)
- 항목(Items) 설정 식:
@activity('WineFiles').output.childItems
2) If Condition 활동 (If Red)
- 식(Expression) 설정 식:
@contains(item().name, 'red')
3) Copy Data 활동 (Copy Red Wine)
- 원본 데이터 세트 (
wineContainerInput_DS):- 매개 변수:
fileName생성. - 연결 설정 식:
@dataset().fileName. - 활동 내 값 매핑:
@item().name.
- 매개 변수:
- 싱크 데이터 세트 (
wineContainerOutput_DS):- 파일 경로:
wine-quality-output. - 매개 변수:
fileName생성. - 활동 내 값 매핑:
@item().name.
- 파일 경로:
4. 실행 및 결과 검증
실행 결과 모니터링
- WineFiles: 성공 (메타데이터 조회).
- ForEachWineFiles: 성공 (반복 처리).
- If Red: 성공 (조건 판단 - 두 개의 파일에 대해 각각 실행).
- Copy Red Wine: 성공 (조건이 참인 'red' 파일에 대해서만 실행).
최종 데이터 확인
wine-quality-output컨테이너에winequality-red.csv파일이 정상적으로 복사되었음을 확인합니다.- 복사된 파일의 내용을 미리 보기 하여 데이터 정합성을 확인합니다.
5. 실습 마무리
- 실습이 완료된 후에는 비용 발생 방지를 위해 데이터 흐름 디버그 모드를 반드시 중지합니다.
