[MicrosoftDataSchool] 74일차 - Fabric T-SQL, Data Warehouse, Direct Lake, KQL
Microsoft Data School 3기

Microsoft Fabric Data Warehouse를 활용한 고성능 T-SQL 분석 및 데이터 통합
SQL Endpoint vs Dedicated Warehouse
Microsoft Fabric는 전통적인 Data Warehouse 외에도 Lakehouse에 정제된 데이터를 두고 SQL Endpoint로 읽는 방법도 제공
| 특징 | SQL Endpoint (Lakehouse) | Dedicated Warehouse | 선택 기준 |
|---|---|---|---|
| 용도 | 읽기 전용 분석 (Silver/Gold) | 읽기/쓰기 모두 가능 | 데이터를 쓰냐? → DW, 읽기만? → Endpoint |
| 데이터 위치 | Lakehouse의 Delta Table 직접 액세스 | 독립적 저장소 | 이미 Lakehouse 있다? → Endpoint |
| 성능 | V-Order 최적화 활용 | 전용 리소스 | 대용량 DW 작업 → DW, 분석 → Endpoint |
| 비용 | 저렴 (공유 리소스) | 높음 (전용 리소스) | 예산 조건 확인 |
| Power BI 연결 | Direct Lake 최적 | Direct Query / Import | Direct Lake 필요 → Endpoint |
| T-SQL 지원 | 완전 지원 | 완전 지원 | 문법 동일 |
Spark SQL vs T-SQL
| 기능 영역 | Spark SQL (Databricks/Fabric Notebook) | T-SQL (Fabric Warehouse/Endpoint) |
|---|---|---|
| 주 목적 | 대용량 데이터 처리 및 ETL 변환 | 정형 데이터 조회, 보고, 비즈니스 로직 구현 |
| 로직 구현 | UDF (Python/Scala 결합) | Stored Procedure (SQL 전용) |
| 트랜잭션 | 파일 기반 (ACID), 암시적 | 세션 기반, 명시적 (BEGIN TRAN) |
| 제어 흐름 | 외부 코드 (Python/Scala)에 의존 | SQL 자체 지원 (IF, WHILE, 변수) |
| 사용자층 | 데이터 엔지니어, 데이터 사이언티스트 | 데이터 분석가, BI 개발자, DBA |
| 문법 특징 | LIMIT, current_date(), approx_distinct() | TOP, GETDATE(), COUNT(DISTINCT) |
T-SQL: Microsoft SQL Server와 Azure SQL Database에서 사용하는 표준 SQL 언어의 확장판으로서 데이터 정의, 데이터 조작, 데이터 제어 뿐만 아니라, 절차적 프로그래밍 기능을 추가하여 복잡한 비즈니스 로직을 서버 측에서 구현
T-SQL을 쓰는 이유
- Universal Connectivity: Excel, 3rd Party BI도구와 높은 호환성
- Standard Governance: GRATN/DENY 기반의 명확한 오브젝트 레벨 권한 관리
- Logic Encapsulation: Stored Procedure를 통해 비즈니스 로직을 DB 내부에 안전하게 격리
Cross-Database Query

다른 Database, 다른 Lakehouse에 있는 테이블을 JOIN 하기 위해서 데이터를 이동할 필요가 없음
Power BI Direct Lake Mode
- Import는 메모리 한계가 있고 Direct Query는 느림
- 이럴때 Direct Lake를 사용하면 빠른 속도에 대용량 파일도 로드 가능
| Feature | Import | Direct Query | Direct Lake |
|---|---|---|---|
| Speed | Very Fast | Slow | Very Fast |
| Data Copy | Yes (Duplication) | No | No (Zero Copy) |
| Freshness | Schedule Refresh | Real-time | Real-time |
| Limit | Memory Limit | DB Load | Large Scale Support |
Semantic Models
Direct Lake모드가 제공하는 빠른 속도 덕분에 기본 모델 생성을 해서 BI 리포트 생성을 좀 더 편하게 해주는 default semantic model 기능이 제공되었으나, 자동 생성의 부작용으로 필요 없는 모델들이 생기고 워크스페이스가 복잡해짐에 따라서 해당 기능은 중단되었고, 대신 사용자가 명시적으로 생성하도록 변경
실습: Microsoft Fabric에서 Data Warehouse 쿼리
Data Warehouse 쿼리
SQL 쿼리 편집기는 IntelliSense, 코드 완성, 구문 강조 표시, 클라이언트 측 구문 분석(parsing) 및 유효성 검사를 지원합니다. Data Definition Language (DDL), Data Manipulation Language (DML) 및 Data Control Language (DCL) 문을 실행할 수 있다.
SELECT
D.MonthName,
COUNT(*) AS TotalTrips,
SUM(T.TotalAmount) AS TotalRevenue
FROM dbo.Trip AS T
JOIN dbo.[Date] AS D
ON T.[DateID]=D.[DateID]
GROUP BY D.MonthName;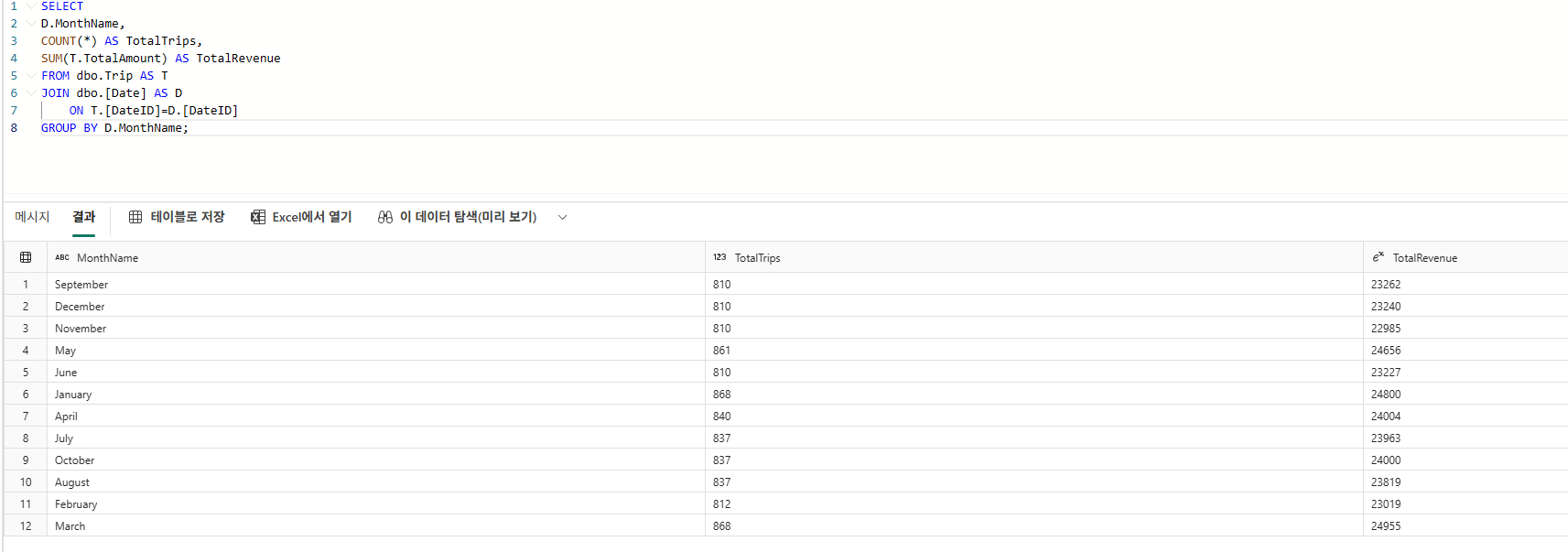
이 쿼리를 통해 각 월별 전체 이동 횟수와 총 수익을 확인할 수 있다.
다음으로 요일별 평균 이동 시간과 평균 이동 거리를 분석한다.
SELECT
D.DayName,
AVG(T.TripDurationSeconds) AS AvgDuration,
AVG(T.TripDistanceMiles) AS AvgDistance
FROM dbo.Trip AS T
JOIN dbo.[Date] AS D
ON T.[DateID]=D.[DateID]
GROUP BY D.DayName;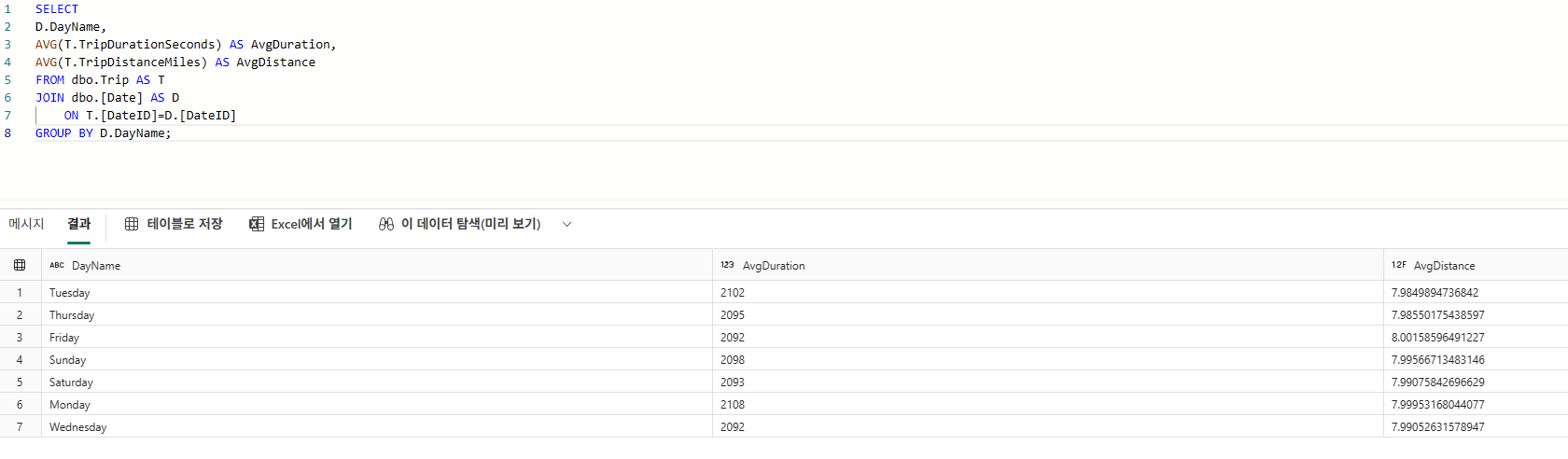
이를 통해 요일별 이동 패턴을 파악할 수 있다.
또한, 이동이 많이 발생한 도시를 확인하기 위해
도시별 이동 수 상위 10개를 조회한다.
SELECT TOP 10
G.City,
COUNT(*) AS TotalTrips
FROM dbo.Trip AS T
JOIN dbo.Geography AS G
ON T.DropoffGeographyID=G.GeographyID
GROUP BY G.City
ORDER BY TotalTrips DESC;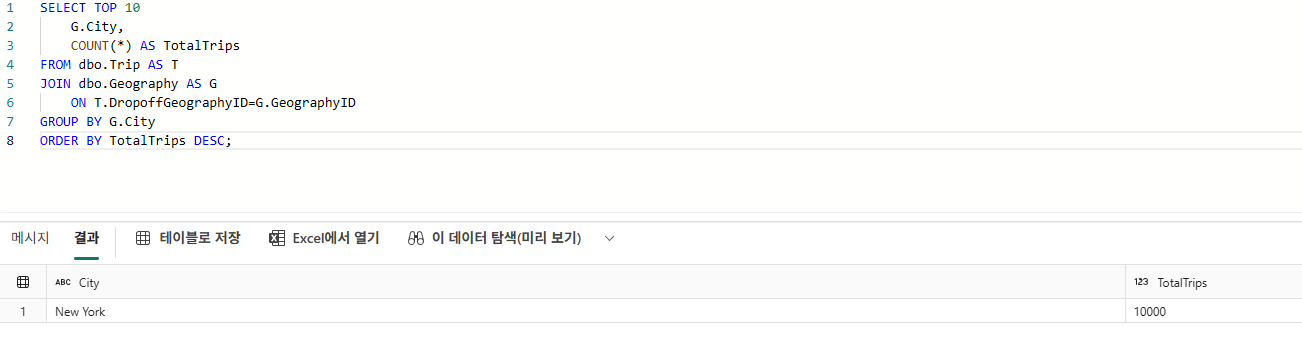
이 쿼리는 특정 도시에서의 이동량이 얼마나 집중되는지 확인하는 데 유용하다.
데이터 일관성 확인
분석 결과의 신뢰성을 확보하기 위해 데이터의 일관성을 확인한다.
먼저 비정상적으로 긴 이동 시간이 존재하는지 확인한다.
(24시간 = 86400초 기준)
-- Check for trips with unusually long duration
SELECT COUNT(*) FROM dbo.Trip WHERE TripDurationSeconds > 86400; -- 24 hours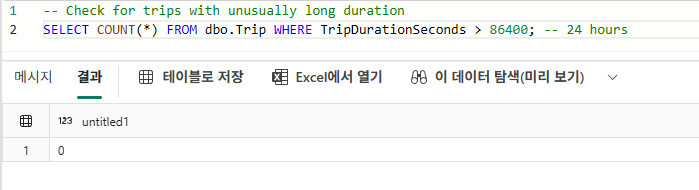
이 값이 존재한다면 데이터 오류 가능성을 의심할 수 있다.
다음으로 음수 이동 시간이 존재하는지 확인한다.
-- Check for trips with negative trip duration
SELECT COUNT(*) FROM dbo.Trip WHERE TripDurationSeconds < 0;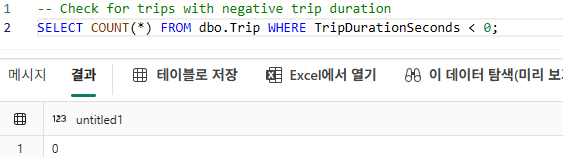
음수 이동 시간은 명백한 데이터 오류이므로 반드시 제거해야 한다.
확인된 데이터 오류를 제거하여 데이터 품질을 개선한다.
-- Remove trips with negative trip duration
DELETE FROM dbo.Trip WHERE TripDurationSeconds < 0;이 과정을 통해 분석에 사용되는 데이터의 정확도를 높일 수 있다.
뷰로 저장
이제 자주 사용하는 분석 쿼리를 View로 저장하여 재사용할 수 있도록 한다.
먼저 기본 집계 쿼리를 작성한다.
SELECT
D.DayName,
AVG(T.TripDurationSeconds) AS AvgDuration,
AVG(T.TripDistanceMiles) AS AvgDistance
FROM dbo.Trip AS T
JOIN dbo.[Date] AS D
ON T.[DateID]=D.[DateID]
GROUP BY D.DayName;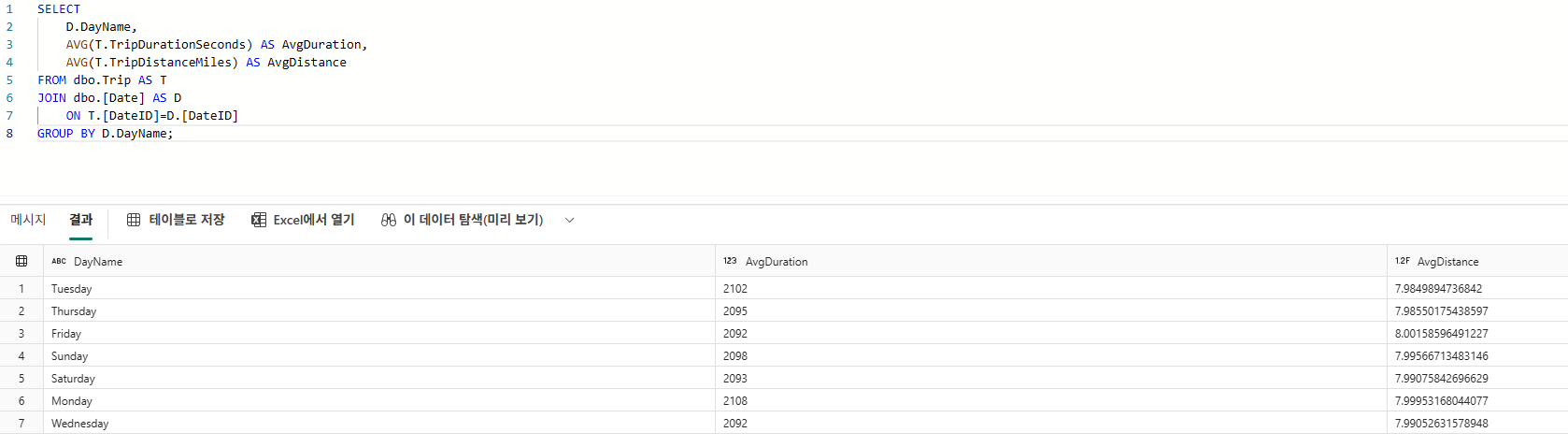
이후 특정 조건(예: 1월 데이터)으로 필터링한다.
SELECT
D.DayName,
AVG(T.TripDurationSeconds) AS AvgDuration,
AVG(T.TripDistanceMiles) AS AvgDistance
FROM dbo.Trip AS T
JOIN dbo.[Date] AS D
ON T.[DateID]=D.[DateID]
WHERE D.Month = 1
GROUP BY D.DayName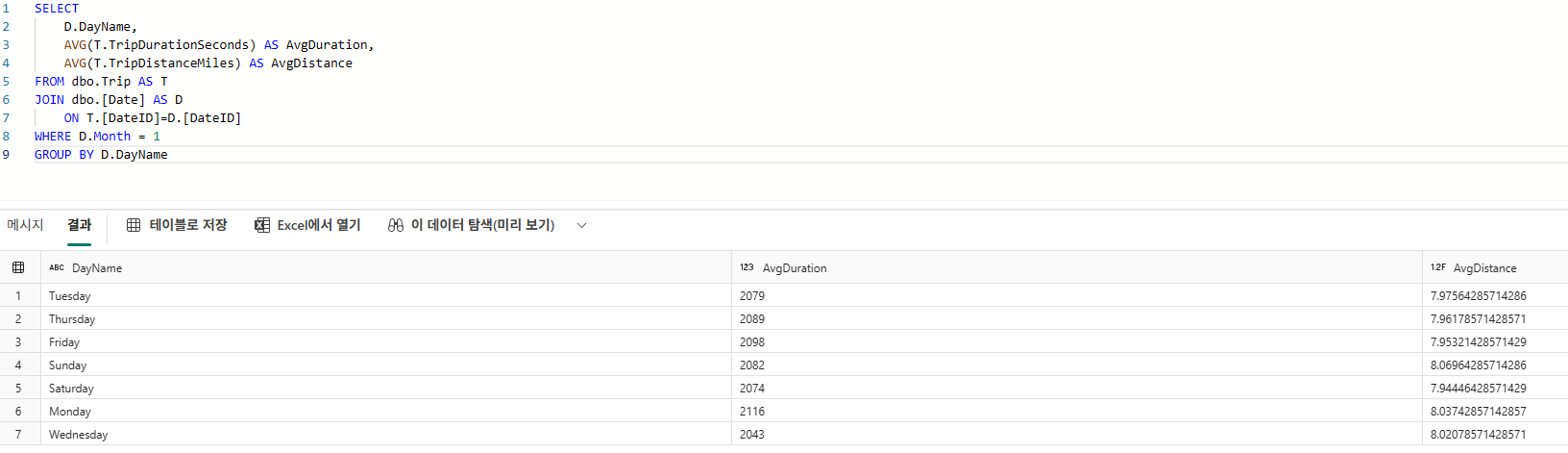
해당 쿼리를 선택한 후 Save as view 기능을 사용하여
vw_JanTrip이라는 이름으로 저장한다.
이렇게 생성된 View는 이후 반복적인 분석이나 BI 도구에서 재사용할 수 있다.
T-SQL을 사용하여 Data Warehouse에 데이터 로드
Lakehouse 생성 및 데이터 준비
먼저 Microsoft Fabric에서 Workspace를 생성한 뒤, Lakehouse를 생성한다.
이후 제공된 sales.csv 파일을 Lakehouse의 Files 영역에 업로드한다.
업로드한 파일을 기반으로 테이블을 생성(Create table) 하여 staging_sales 테이블을 만든다.
이 테이블은 이후 Data Warehouse로 데이터를 적재하기 위한 Staging 영역 역할을 한다.
Data Warehouse 생성
다음으로 Data Warehouse를 생성한다.
이 Warehouse는 Lakehouse의 데이터를 기반으로
분석용 Fact/Dimension 테이블을 구성하는 공간이다.
Warehouse에서 안하고 Lakehouse에서 하면 create table 할때 denied되니 명심하자
Fact 및 Dimension 테이블 생성
Warehouse에서 SQL Query를 열고,
Fact 테이블과 Dimension 테이블을 생성한다.
CREATE SCHEMA Sales;
GO
CREATE TABLE Sales.Fact_Sales
(
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber INT NOT NULL,
OrderDate DATE NOT NULL,
CustomerKey INT NOT NULL,
ItemKey INT NOT NULL,
Quantity INT,
UnitPrice FLOAT,
Tax FLOAT
);
GO
CREATE TABLE Sales.Dim_Customer
(
CustomerKey INT IDENTITY(1,1) NOT NULL,
CustomerName NVARCHAR(100),
Email NVARCHAR(100)
);
GO
CREATE TABLE Sales.Dim_Item
(
ItemKey INT IDENTITY(1,1) NOT NULL,
ItemName NVARCHAR(100)
);
GOFact_Sales→ 판매 데이터 저장 (Fact Table)Dim_Customer,Dim_Item→ 차원 테이블
Staging 데이터 연결 (View 생성)
Lakehouse의 staging_sales 테이블을 Warehouse에서 참조하기 위해 View를 생성한다.
CREATE VIEW Sales.Staging_Sales
AS
SELECT *
FROM staging_sales;이 View를 통해 Lakehouse 데이터를 Warehouse에서 직접 조회할 수 있다.
데이터 로드를 위한 저장 프로시저 생성
Staging 데이터를 Fact/Dimension 테이블로 적재하기 위해
저장 프로시저를 생성한다.
CREATE PROCEDURE Sales.LoadDataFromStaging (@OrderYear INT)
AS
BEGIN
-- Load customers
INSERT INTO Sales.Dim_Customer (CustomerName, Email)
SELECT DISTINCT CustomerName, Email
FROM Sales.Staging_Sales
WHERE YEAR(OrderDate) = @OrderYear
AND CustomerName NOT IN (SELECT CustomerName FROM Sales.Dim_Customer);
-- Load items
INSERT INTO Sales.Dim_Item (ItemName)
SELECT DISTINCT Item
FROM Sales.Staging_Sales
WHERE YEAR(OrderDate) = @OrderYear
AND Item NOT IN (SELECT ItemName FROM Sales.Dim_Item);
-- Load fact table
INSERT INTO Sales.Fact_Sales
SELECT
s.SalesOrderNumber,
s.SalesOrderLineNumber,
s.OrderDate,
c.CustomerKey,
i.ItemKey,
s.Quantity,
s.UnitPrice,
s.Tax
FROM Sales.Staging_Sales s
JOIN Sales.Dim_Customer c
ON s.CustomerName = c.CustomerName
JOIN Sales.Dim_Item i
ON s.Item = i.ItemName
WHERE YEAR(s.OrderDate) = @OrderYear;
END;이 프로시저는 다음 작업을 수행한다.
- 고객 데이터 적재
- 상품 데이터 적재
- Fact 테이블 적재
데이터 로드 실행
2021년 데이터를 Warehouse로 로드한다.
EXEC Sales.LoadDataFromStaging 2021;데이터 분석
데이터가 정상적으로 로드되었는지 확인하기 위해
분석 쿼리를 실행한다.
고객별 총 판매액
SELECT
c.CustomerName,
SUM(f.Quantity * (f.UnitPrice + f.Tax)) AS TotalSales
FROM Sales.Fact_Sales f
JOIN Sales.Dim_Customer c
ON f.CustomerKey = c.CustomerKey
GROUP BY c.CustomerName
ORDER BY TotalSales DESC;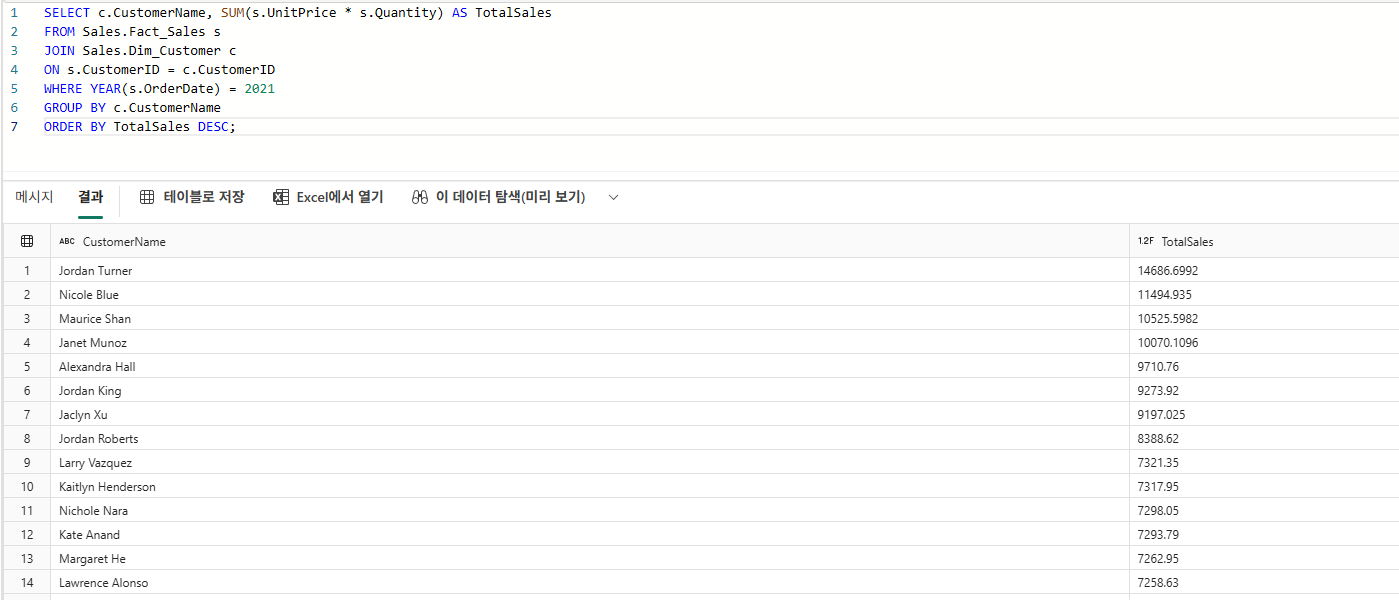
상품별 총 판매액
SELECT
i.ItemName,
SUM(f.Quantity * (f.UnitPrice + f.Tax)) AS TotalSales
FROM Sales.Fact_Sales f
JOIN Sales.Dim_Item i
ON f.ItemKey = i.ItemKey
GROUP BY i.ItemName
ORDER BY TotalSales DESC;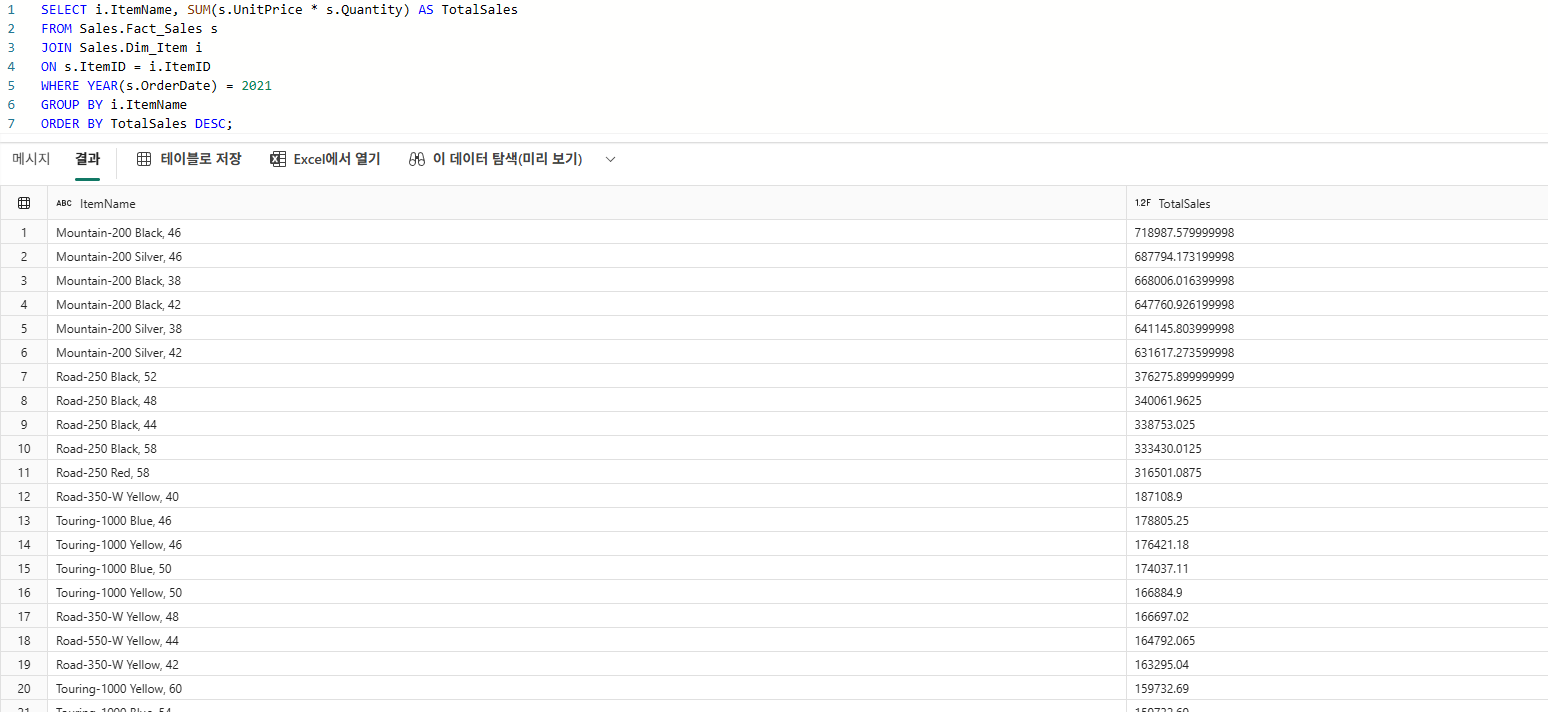
카테고리별 상위 고객 분석
WITH SalesCTE AS
(
SELECT
c.CustomerName,
i.ItemName,
SUM(f.Quantity * (f.UnitPrice + f.Tax)) AS TotalSales,
CASE
WHEN i.ItemName LIKE '%Bike%' THEN 'Bike'
ELSE 'Other'
END AS Category
FROM Sales.Fact_Sales f
JOIN Sales.Dim_Customer c
ON f.CustomerKey = c.CustomerKey
JOIN Sales.Dim_Item i
ON f.ItemKey = i.ItemKey
GROUP BY c.CustomerName, i.ItemName
)
SELECT *
FROM
(
SELECT *,
ROW_NUMBER() OVER (PARTITION BY Category ORDER BY TotalSales DESC) AS rn
FROM SalesCTE
) t
WHERE rn <= 5;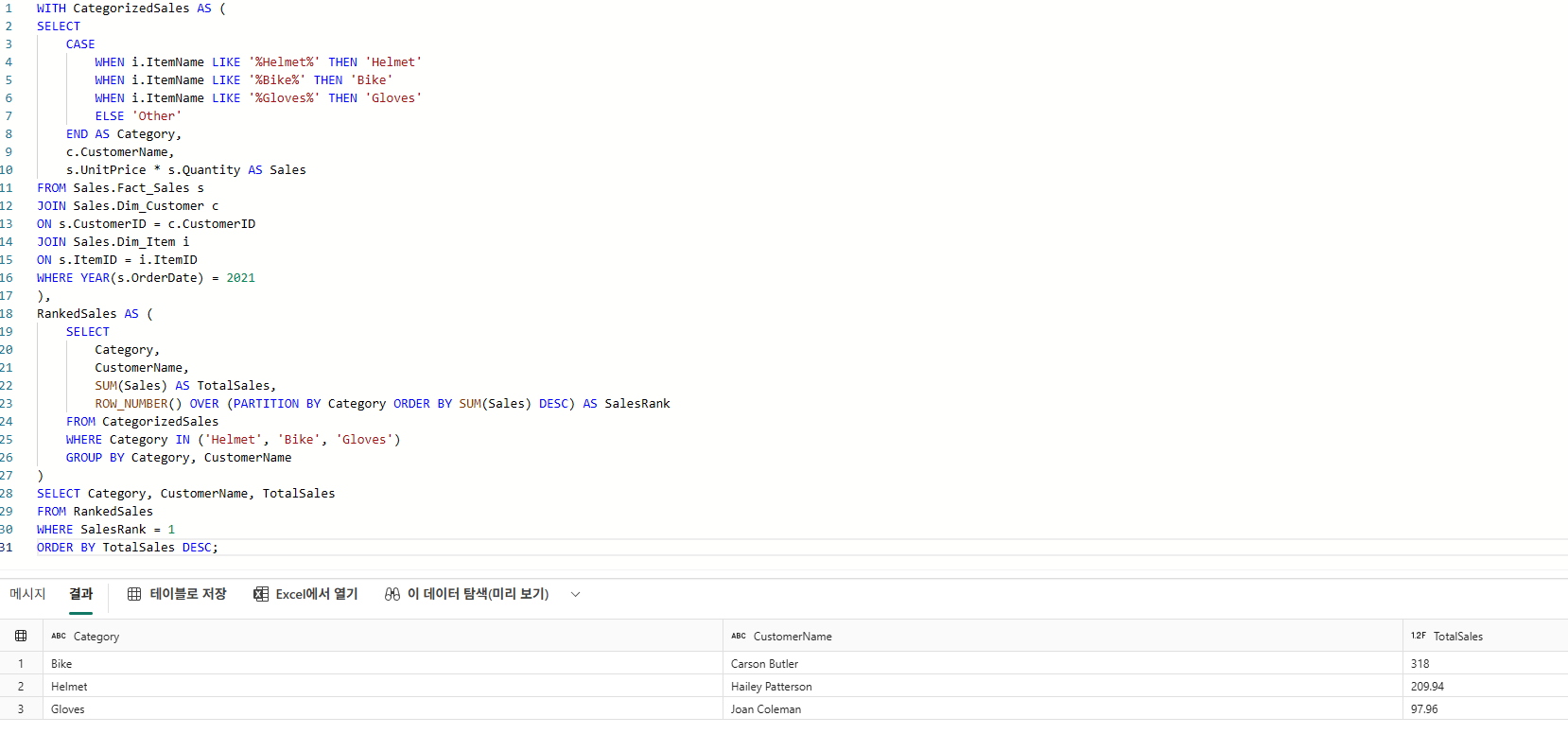
자습서: Direct Lake 의미 체계 모델 및 Power BI 보고서 만들기
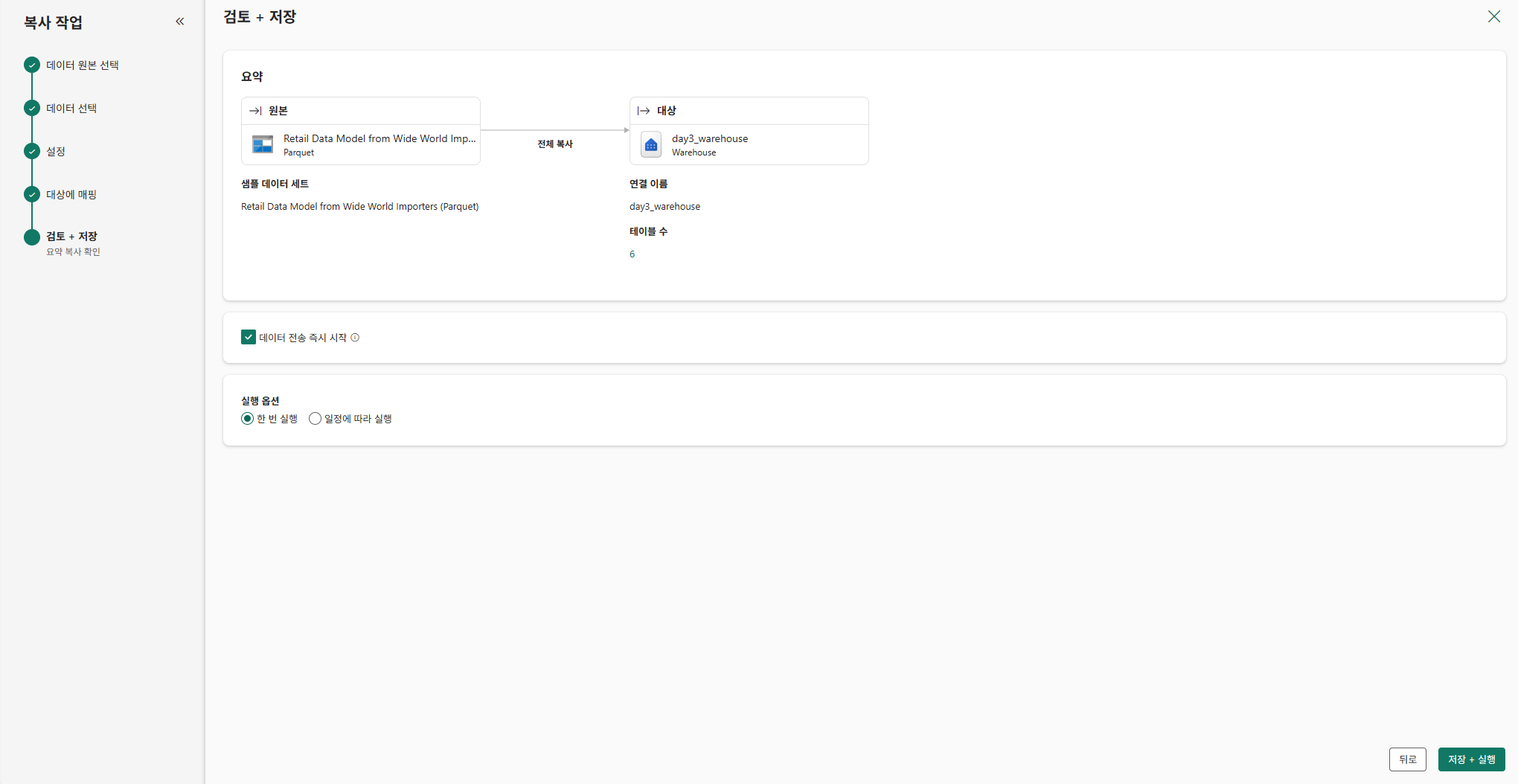
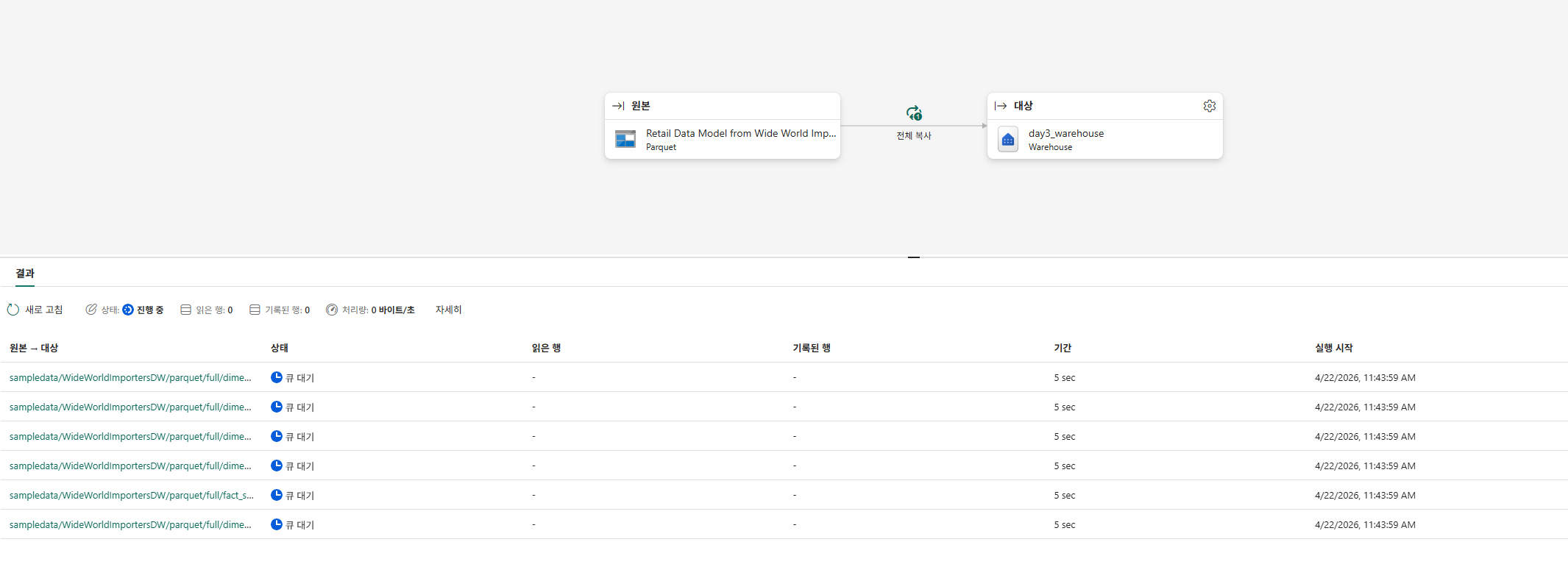
데이터 가져오기
Warehouse에서 데이터 가져오기 선택
샘플 데이터의 Retail~ 선택
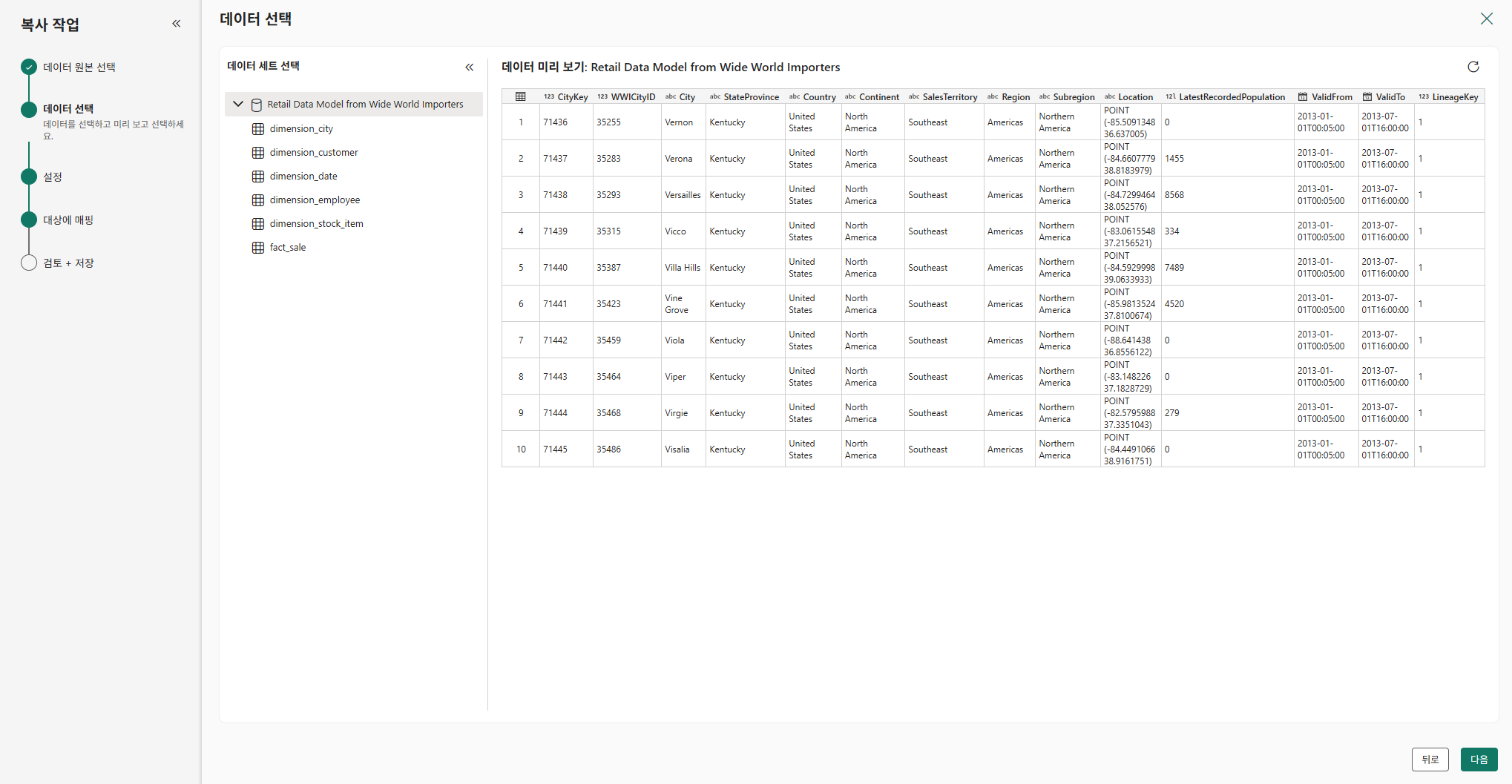
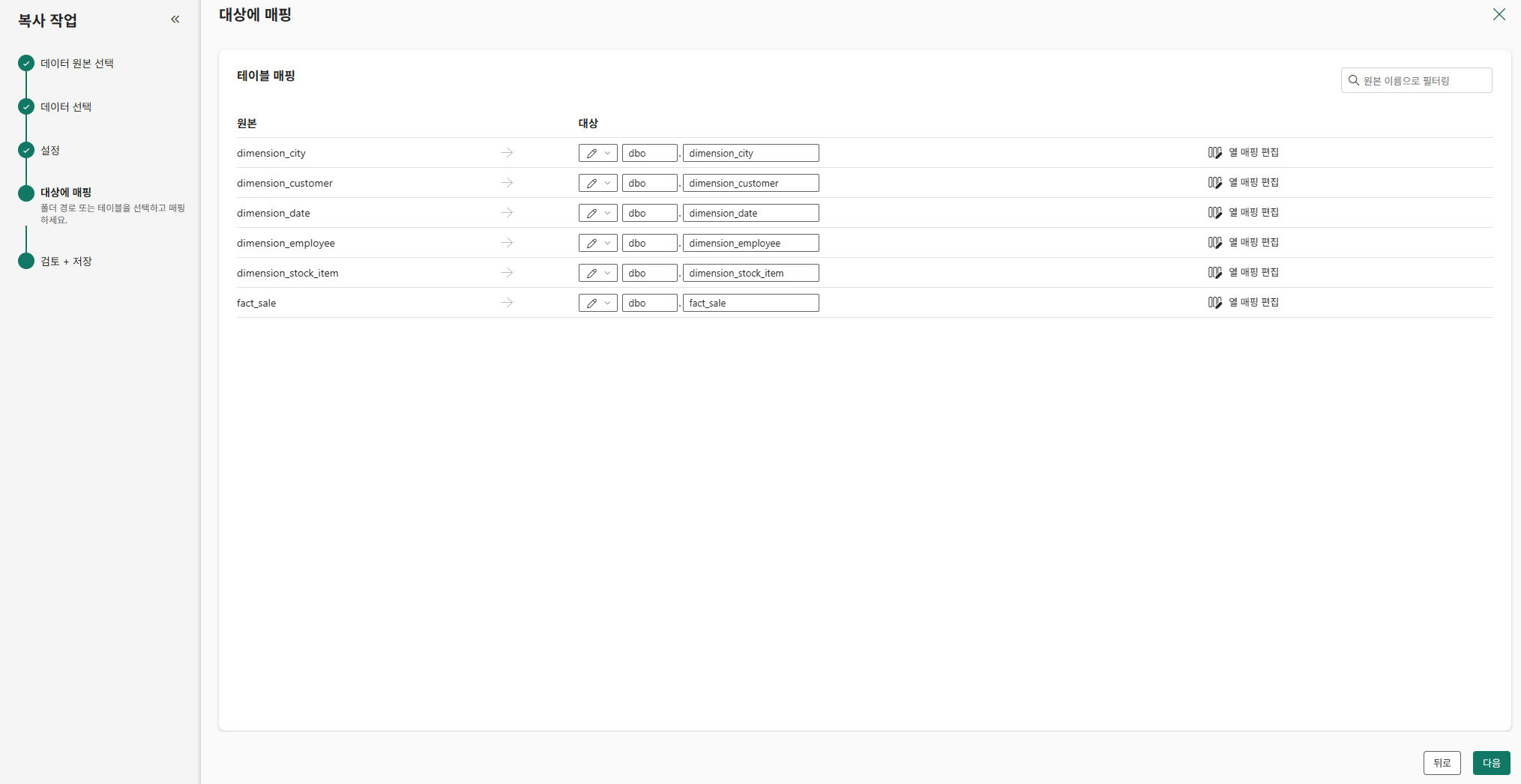
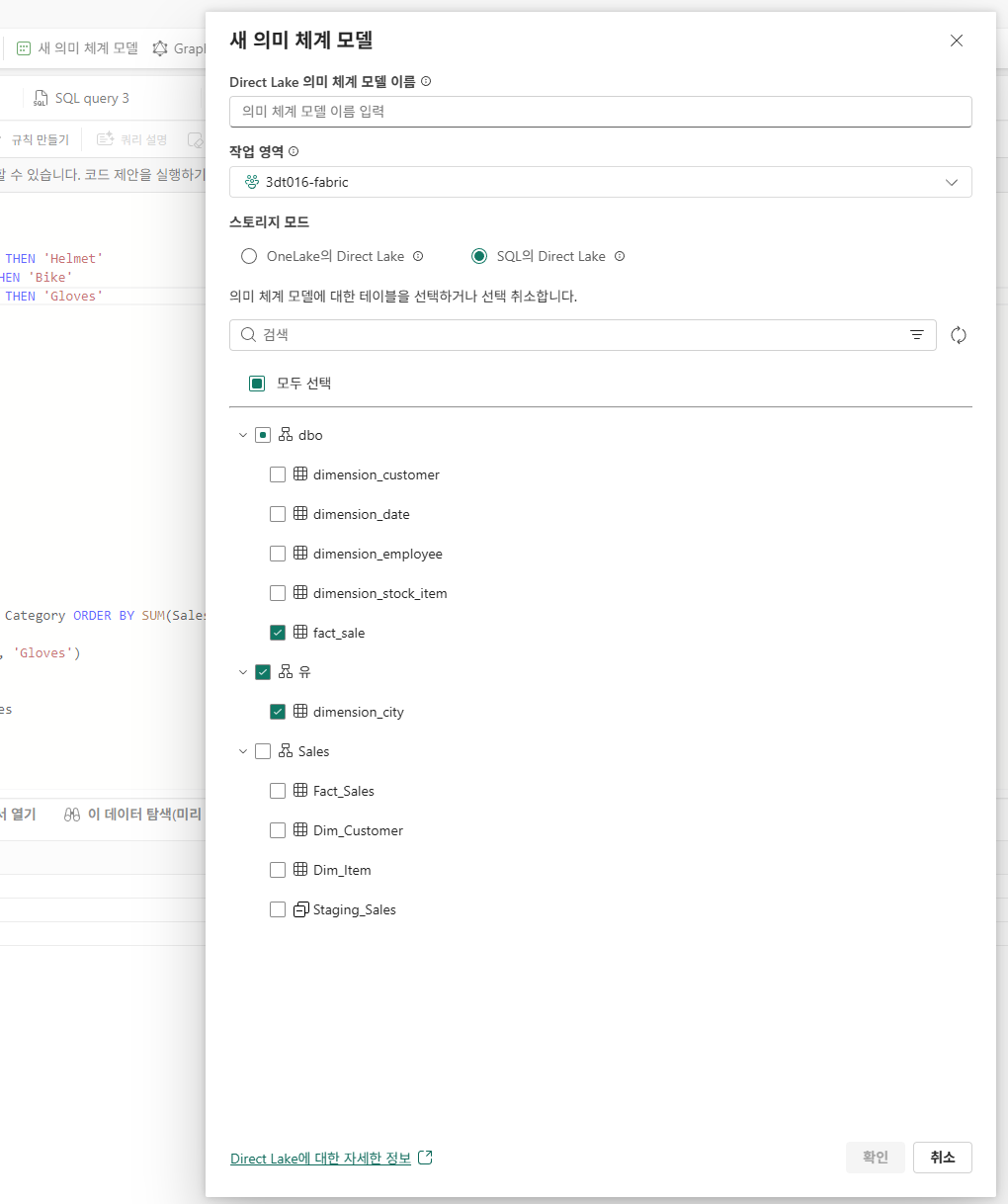
의미체계 모델 만들기
만들어진 의미체계 모델은 작업 영역에서 확인 가능
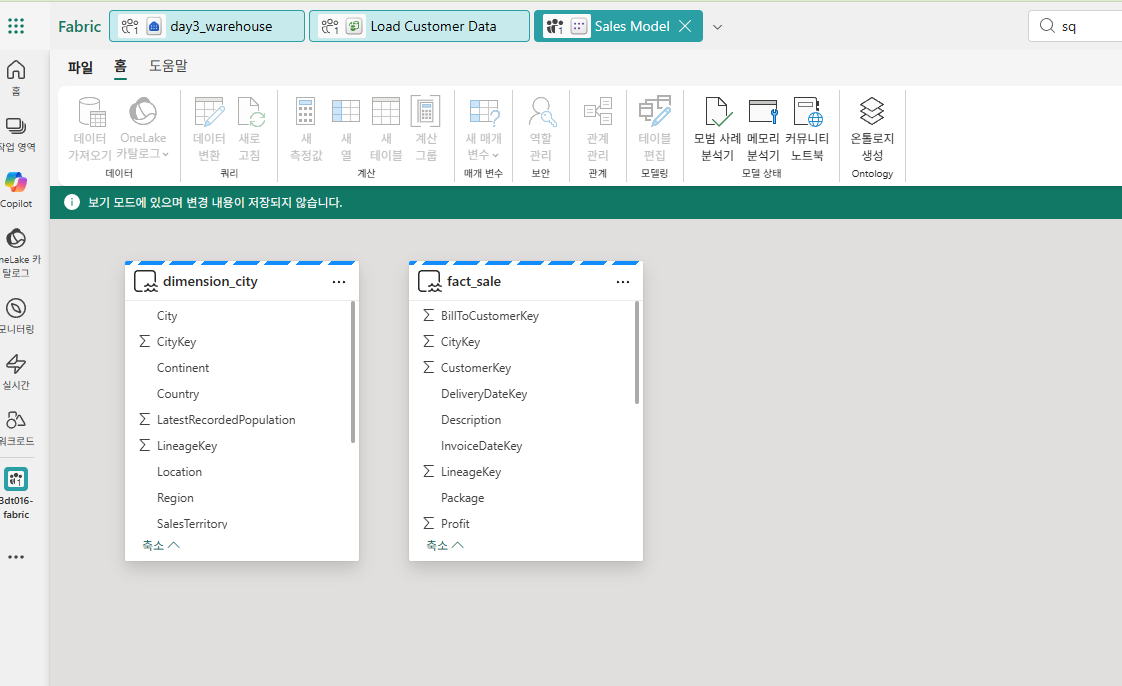
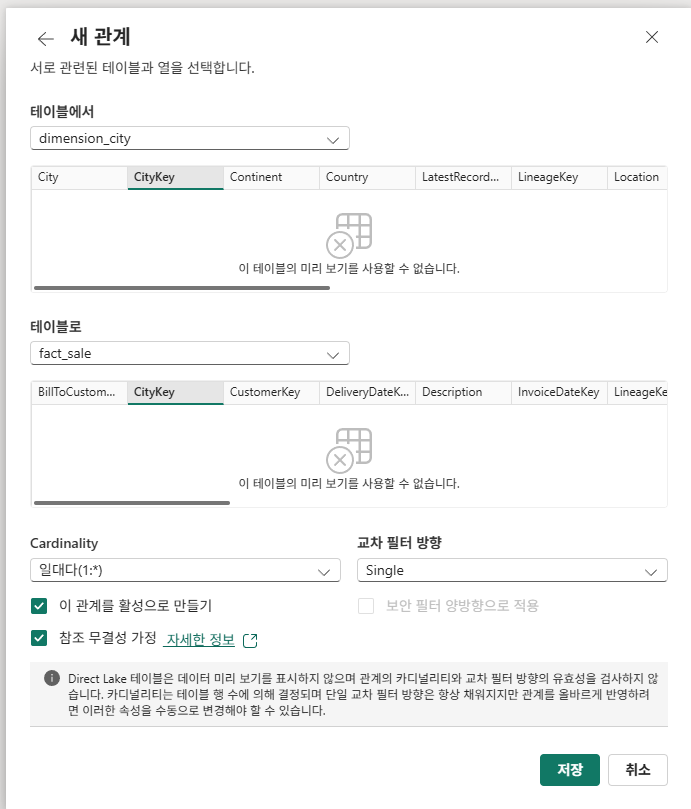
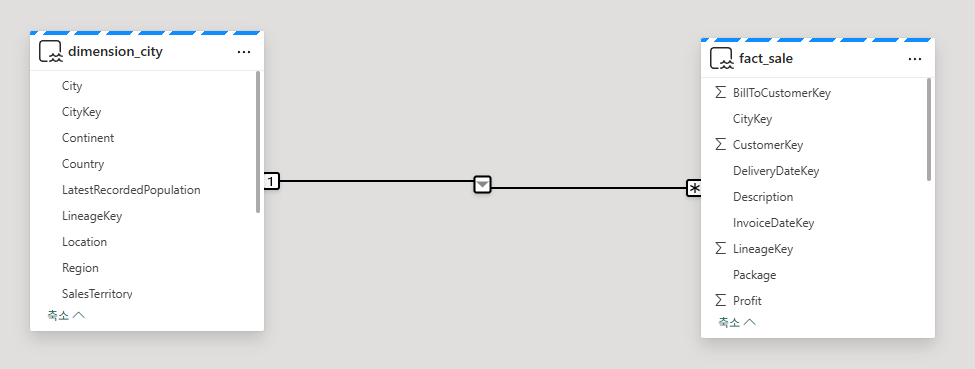
관계 관리
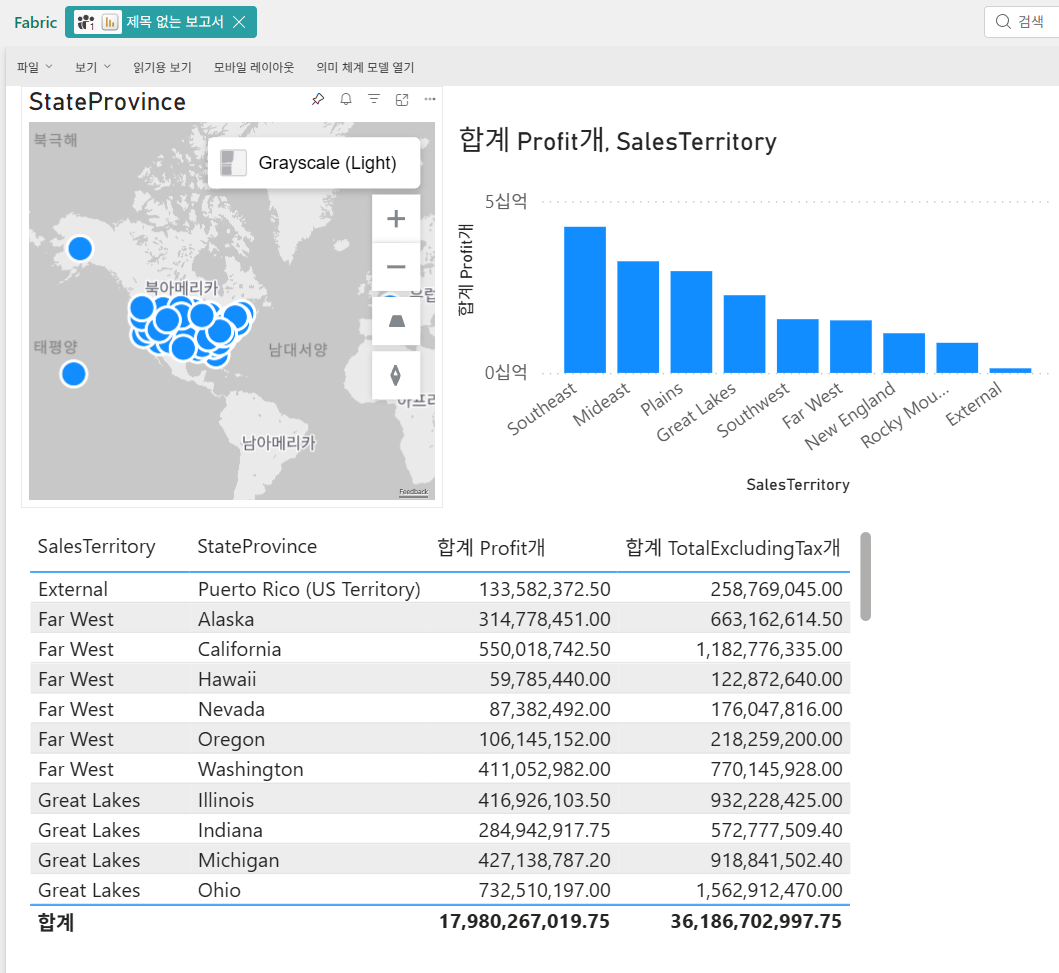
보고서 만들기
Fabric을 활용한 실시간 분석
Security Architecture & Hierarchy
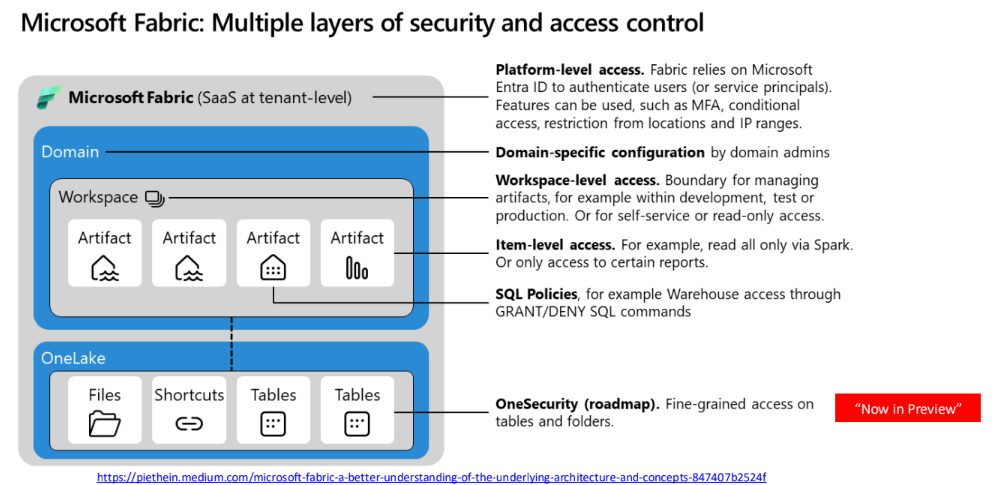
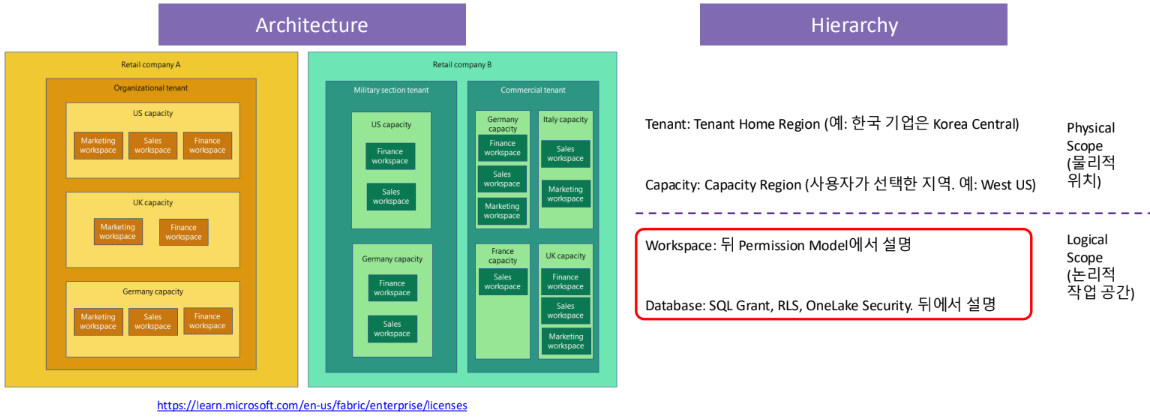
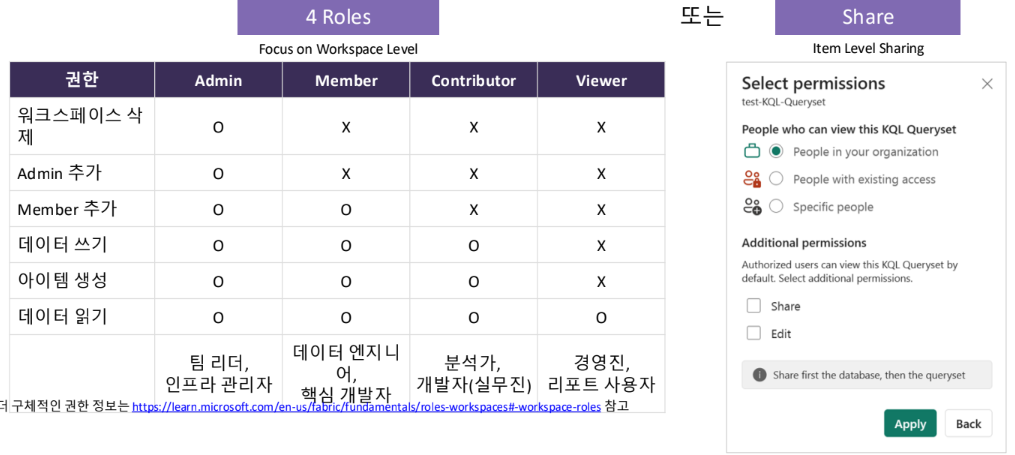
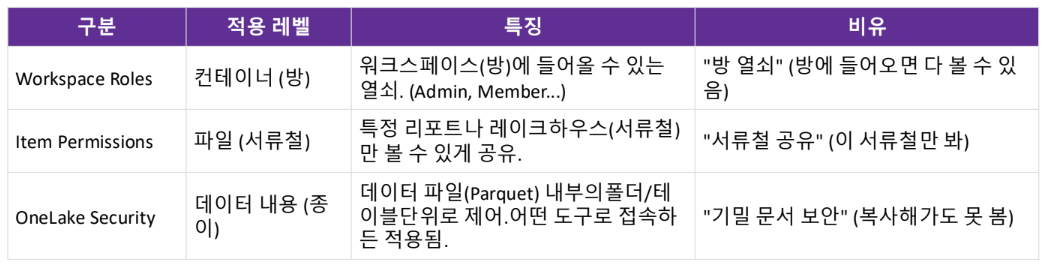
Workspace Roles & Permissions
단위입니다. 팀 리더, 데이터 엔지니어, 분석가, 보고서 사용자 등
역할에 따라 Admin, Member, Contributor, Viewer 중 하나를 부여하여 필요한 권한만 제공
더 세밀한 제어가 필요하면 'Share'로 특정 아이템만 공유
OneLake Security
데이터 자체(테이블, 폴더)에 대한 접근을 제어.
Row-Level Security(RLS)
사용자의 권한(User Context)에 따라 테이블의 특정 행(Row)만 조회되도록 필터링하는 보안 기능
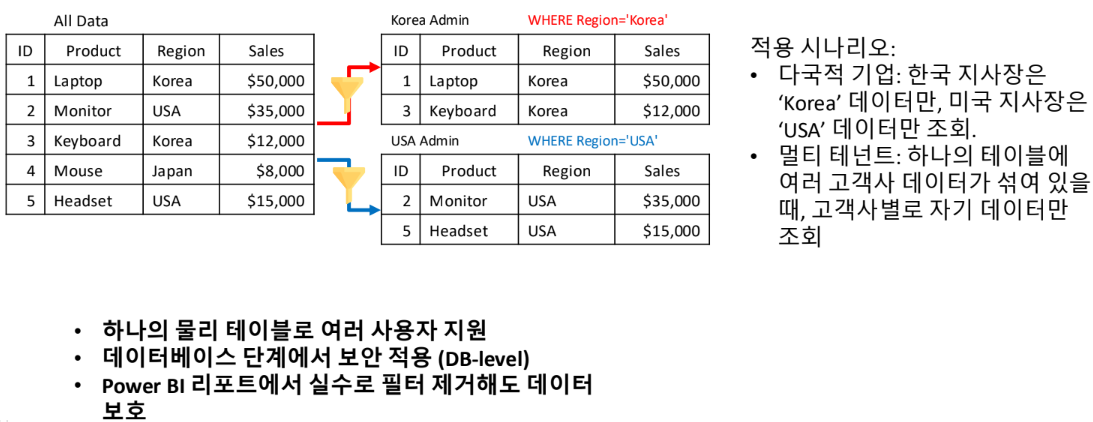
Implementing RLS with T-SQL
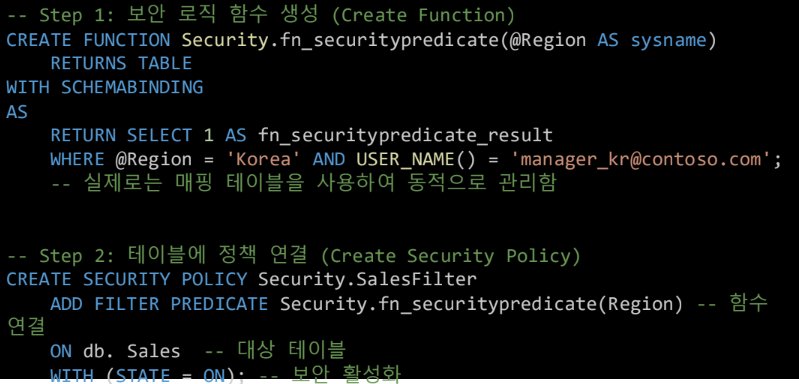
1. 보안 함수 생성
USER_NAME() 함수를 사용하여 현재 접속한 사용자 식별
2. 보안 정책 적용
위에서 만든 함수를 실제 테이블에 결합
STATE = ON 으로 설정하는 즉시 모든 쿼리에 필터가 적용
SQL Permissions: GRANT, Deny & Column-Level Security

Governance: Purview, Lineage & Endorsement
Purview Hub (데이터 보호)
• MIP Label: 데이터에 '기밀(Confidential)’ tag를 붙이면, 엑셀로 다운로드해도 암호화가 유지
• 인사이트: "우리 회사에 민감 정보가 얼마나 있지?"를 대시보드로 표시
Data Lineage (데이터 족보)
• 자동 시각화: 원본 데이터가 어떤 파이프라인을 거쳐 어떤 리포트가 되었는지 자동 생성
• 영향도 분석: "이 테이블 고치면 어떤 리포트가 깨질까?“ 미리 알 수 있음
Endorsement (신뢰 마크)
• Certified (인증됨): IT 부서가 "이건 믿고 써도 됨"이라고 보증한 데이터.
• Promoted (홍보됨): 팀 리더가 "우리 팀 데이터 공유할게"라고 내놓은 데이터.
Real-Time Intelligence: KQL Database & Eventstream
KQL Database (저장소)
• 고성능 로그 분석: 기존 SQL DB는 로그 쌓이면 느려지지만, KQL DB는 페타바이트급 로그도 순식간에 검색
• 비정형 데이터: JSON, 텍스트 로그 등 구조가 일정하지 않은 데이터도 그대로 넣고 바로 쿼리
Eventstream (연결 통로)
• No-Code 연결: IoT 센서, 앱 로그, Kafka 등을 코딩 없이 클릭만으로 연결
• 실시간 처리: 데이터가 들어오는 즉시 필터링하거나 변환해서 KQL DB나 Lakehouse로 전송
KQL (Kusto Query Language)

데이터를 탐색하고 패턴을 발견하고, 변칙과 이상값을 식별하고, 통계 모델링을 만드는 등의 작업을 수행할 수 있는 강력한 도구로서 Microsoft에서 만들었으며 Azure Data Explorer, Azure Monitor, Microsoft Fabric 등에 사용
대소문자를 구분함
Fabric Activator (formely Reflex)
데이터 소스에서 특정 패턴이나 조건이 감지될 때 자동으로 작업을 실행하는
코드 없는 저지연 이벤트 감지 엔진
- 1초 미만의 대기 시간으로 데이터 원본을 지속적으로 모니터링
- 임계값이 충족되거나 특정 패턴이 검색되면 작업 (예: 전자메일 또는 Teams 알림 보내기, Power Automate 흐름 시작, 타사 시스템 통합 등)을 시작
- 데이터가 지속적으로 흐르는 반응형 이벤트 기반 아키텍처에 적합하며, 이벤트 데이터의 상태 저장 평가에 따라 거의 실시간으로 결정
실습: Microsoft Fabric 데이터 웨어하우스 보안 설정
테이블의 Column에 동적 데이터 마스킹 규칙 적용
동적 데이터 마스킹 규칙은 테이블 수준의 개별 Column에 적용되므로 모든 Query가 마스킹의 영향을 받습니다. 기밀 데이터를 볼 명시적인 권한이 없는 사용자는 Query 결과에서 마스킹된 값을 보게 되며, 데이터를 볼 명시적인 권한이 있는 사용자는 마스킹되지 않은 데이터를 봅니다. 마스크에는 기본(default), 이메일(email), 무작위(random), 사용자 지정 문자열(custom string)의 네 가지 유형이 있습니다.
- Warehouse에서 T-SQL 타일을 선택하고, 다음 T-SQL 문을 사용하여 테이블을 생성하고 데이터를 삽입하고 조회합니다.
CREATE TABLE dbo.Customers
(
CustomerID INT NOT NULL,
FirstName varchar(50) MASKED WITH (FUNCTION = 'partial(1,"XXXXXXX",0)') NULL,
LastName varchar(50) NOT NULL,
Phone varchar(20) MASKED WITH (FUNCTION = 'default()') NULL,
Email varchar(50) MASKED WITH (FUNCTION = 'email()') NULL
);
INSERT dbo.Customers (CustomerID, FirstName, LastName, Phone, Email) VALUES
(29485,'Catherine','Abel','555-555-5555','catherine0@adventure-works.com'),
(29486,'Kim','Abercrombie','444-444-4444','kim2@adventure-works.com'),
(29489,'Frances','Adams','333-333-3333','frances0@adventure-works.com');
SELECT * FROM dbo.Customers;마스크 해제된 데이터를 볼 수 없는 사용자가 테이블을 Query할 때, FirstName Column은 문자열의 첫 글자와 XXXXXXX를 표시하고 마지막 문자는 표시하지 않습니다. Phone Column은 xxxx를 표시합니다. Email Column은 이메일 주소의 첫 글자 다음에 XXX@XXX.com을 표시합니다. 이 접근 방식은 민감한 데이터가 기밀을 유지하도록 보장하면서도 제한된 사용자가 테이블을 Query할 수 있도록 합니다.

- ▷ 실행 버튼을 사용하여 SQL 스크립트를 실행합니다. 이 스크립트는 Data Warehouse의 dbo Schema에 Customers라는 새 테이블을 생성합니다.
- 그런 다음, 탐색기 창에서 Schemas > dbo > Tables를 확장하고 Customers 테이블이 생성되었는지 확인합니다. Workspace 생성자로서 마스크 해제된 데이터를 볼 수 있는 Workspace Admin 역할의 멤버이므로, SELECT 문은 마스크 해제된 데이터를 반환합니다.
행 수준 보안(Row-level security) 적용
CREATE TABLE dbo.Sales
(
OrderID INT,
SalesRep VARCHAR(60),
Product VARCHAR(10),
Quantity INT
);
--Populate the table with 6 rows of data, showing 3 orders for each test user.
INSERT dbo.Sales (OrderID, SalesRep, Product, Quantity) VALUES
(1, '<username1>@<your_domain>.com', 'Valve', 5),
(2, '<username1>@<your_domain>.com', 'Wheel', 2),
(3, '<username1>@<your_domain>.com', 'Valve', 4),
(4, '<username2>@<your_domain>.com', 'Bracket', 2),
(5, '<username2>@<your_domain>.com', 'Wheel', 5),
(6, '<username2>@<your_domain>.com', 'Seat', 5);
SELECT * FROM dbo.Sales; 
새 Schema, Function으로 정의된 보안 Predicate, 그리고 보안 정책을 생성
--Create a separate schema to hold the row-level security objects (the predicate function and the security policy)
CREATE SCHEMA rls;
GO
/*Create the security predicate defined as an inline table-valued function.
A predicate evaluates to true (1) or false (0). This security predicate returns 1,
meaning a row is accessible, when a row in the SalesRep column is the same as the user
executing the query.*/
--Create a function to evaluate who is querying the table
CREATE FUNCTION rls.fn_securitypredicate(@SalesRep AS VARCHAR(60))
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS fn_securitypredicate_result
WHERE @SalesRep = USER_NAME();
GO
/*Create a security policy to invoke and enforce the function each time a query is run on the Sales table.
The security policy has a filter predicate that silently filters the rows available to
read operations (SELECT, UPDATE, and DELETE). */
CREATE SECURITY POLICY SalesFilter
ADD FILTER PREDICATE rls.fn_securitypredicate(SalesRep)
ON dbo.Sales
WITH (STATE = ON);
GO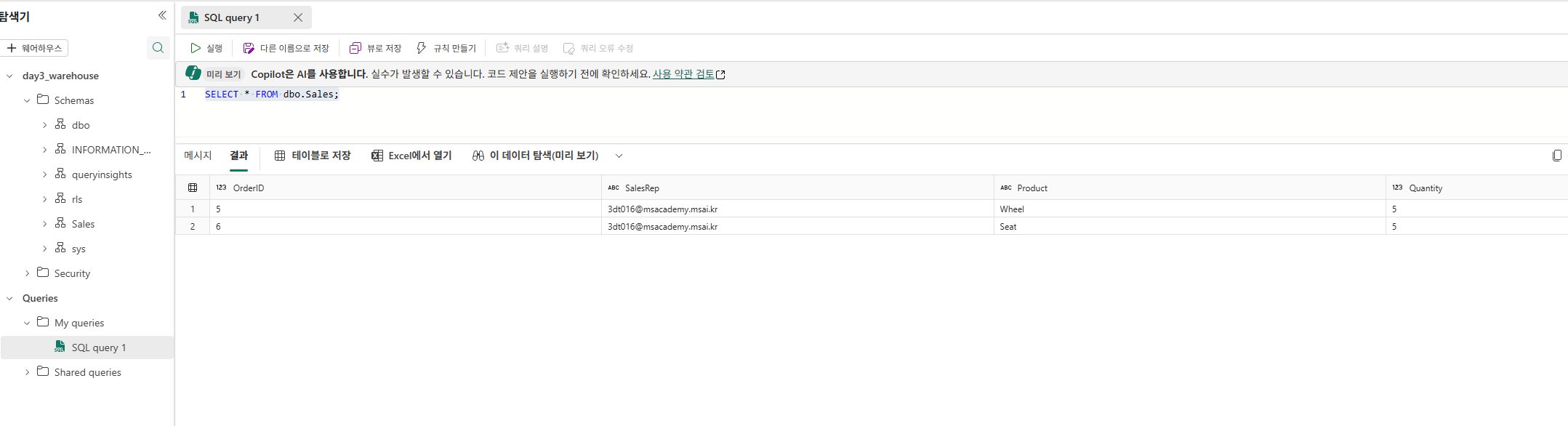
열 수준 보안(Column-level security) 구현
열 수준 보안은 어떤 사용자가 테이블의 특정 Column에 접근할 수 있는지 지정할 수 있도록 합니다. 이는 Column 목록과 Column을 읽을 수 있거나 없는 사용자 또는 역할을 지정하여 테이블에 GRANT 또는 DENY 문을 발행함으로써 구현됩니다. 접근 관리를 간소화하기 위해 개별 사용자 대신 역할에 권한을 할당합니다. 이 실습에서는 테이블을 생성하고, 테이블의 Column 하위 집합에 접근 권한을 부여하며, 제한된 Column이 본인 외의 사용자에게는 보이지 않는지 테스트합니다.
CREATE TABLE dbo.Orders
(
OrderID INT,
CustomerID INT,
CreditCard VARCHAR(20)
);
INSERT dbo.Orders (OrderID, CustomerID, CreditCard) VALUES
(1234, 5678, '111111111111111'),
(2341, 6785, '222222222222222'),
(3412, 7856, '333333333333333');
SELECT * FROM dbo.Orders;DENY SELECT ON dbo.Orders (CreditCard) TO [<username1>@<your_domain>.com];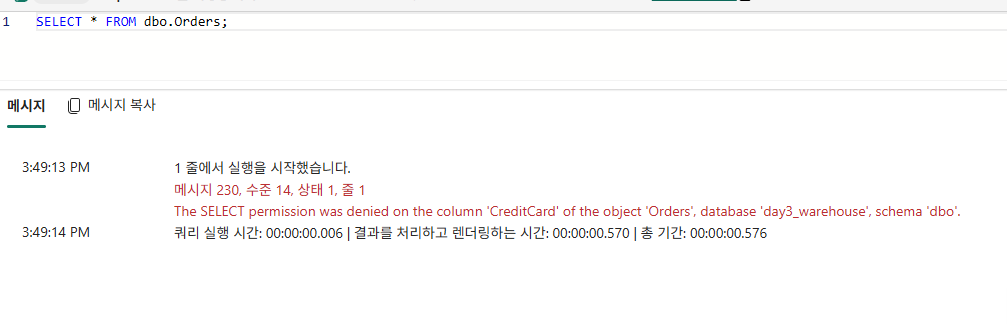
T-SQL을 사용하여 SQL 세분화된 권한 구성
Fabric은 Workspace 수준 및 항목 수준에서 데이터 접근을 제어할 수 있는 권한 모델을 가지고 있습니다. Fabric Warehouse의 보안 개체(securables)를 사용자들이 무엇을 할 수 있는지 더 세밀하게 제어해야 할 때, 표준 SQL 데이터 제어 언어(DCL) 명령어인 GRANT, DENY, REVOKE를 사용할 수 있습니다. 이 실습에서는 객체(objects)를 생성하고, GRANT 및 DENY를 사용하여 객체를 보호한 다음, Query를 실행하여 세분화된 권한 적용의 효과를 확인합니다.
CREATE PROCEDURE dbo.sp_PrintMessage
AS
PRINT 'Hello World.';
GO
CREATE TABLE dbo.Parts
(
PartID INT,
PartName VARCHAR(25)
);
INSERT dbo.Parts (PartID, PartName) VALUES
(1234, 'Wheel'),
(5678, 'Seat');
GO
/*Execute the stored procedure and select from the table and note the results you get
as a member of the Workspace Admin role. Look for output from the stored procedure on
the 'Messages' tab.*/
EXEC dbo.sp_PrintMessage;
GO
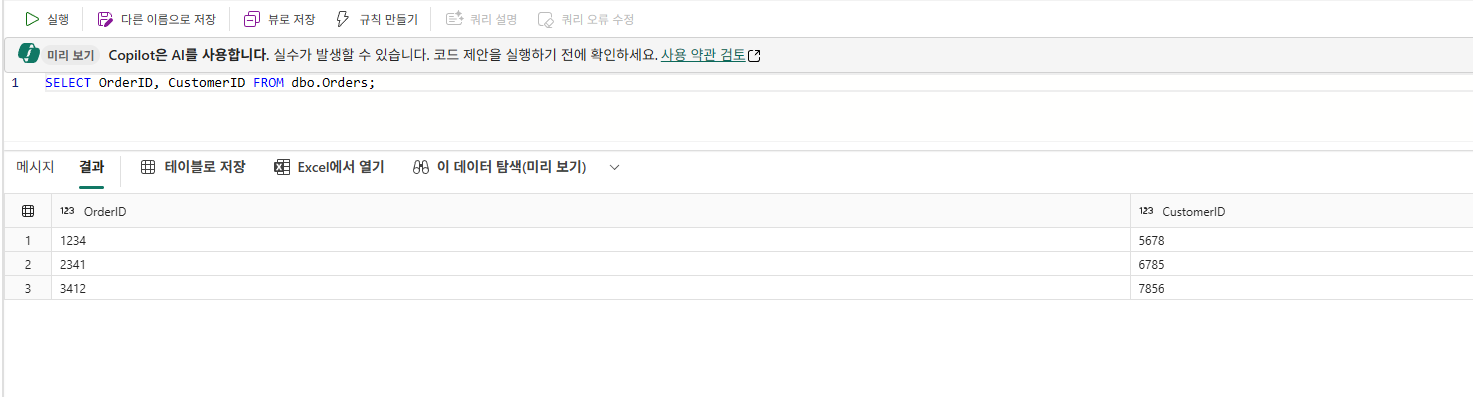
SELECT * FROM dbo.Parts다음으로, Workspace Viewer 역할의 멤버인 사용자에게 테이블에 대한 DENY SELECT 권한을 부여하고, 동일한 사용자에게 프로시저에 대한 GRANT EXECUTE 권한을 부여합니다. <username1>@<your_domain>.com을 Workspace에 Viewer 권한을 가진 사용자의 사용자 이름으로 대체합니다.
DENY SELECT on dbo.Parts to [<username1>@<your_domain>.com];
GRANT EXECUTE on dbo.sp_PrintMessage to [<username1>@<your_domain>.com];Microsoft Fabric에서 Eventstream을 사용하여 실시간 데이터 수집
Eventstream은 Microsoft Fabric의 기능으로, 실시간 이벤트를 캡처, 변환 및 다양한 대상으로 라우팅합니다. Eventstream에 이벤트 데이터 원본, 대상 및 변환을 추가할 수 있습니다.
Eventhouse 만들기
작업 영역에서 + 새 항목을 선택
Eventstream 만들기
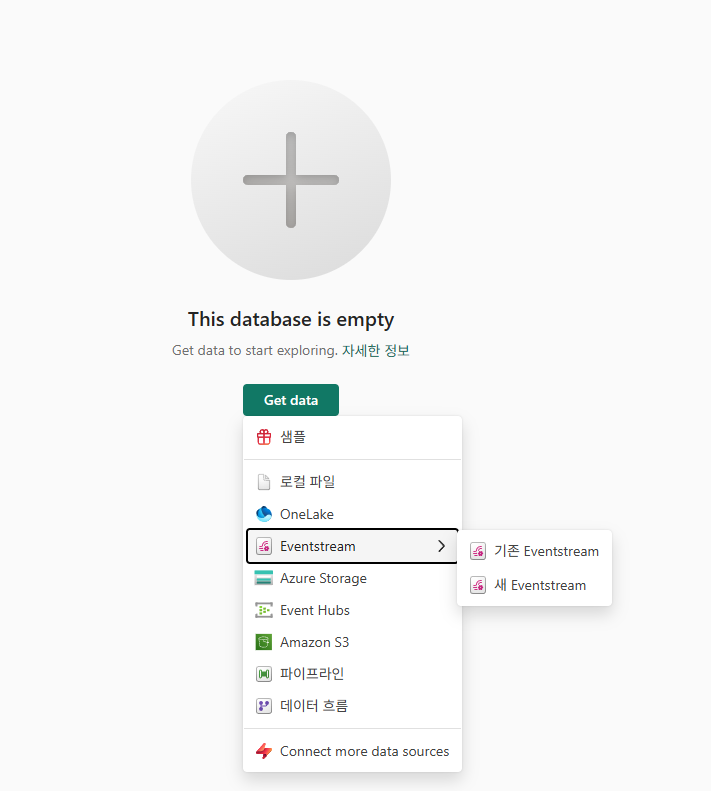
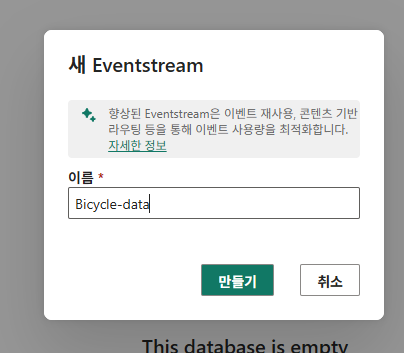
샘플 데이터 사용
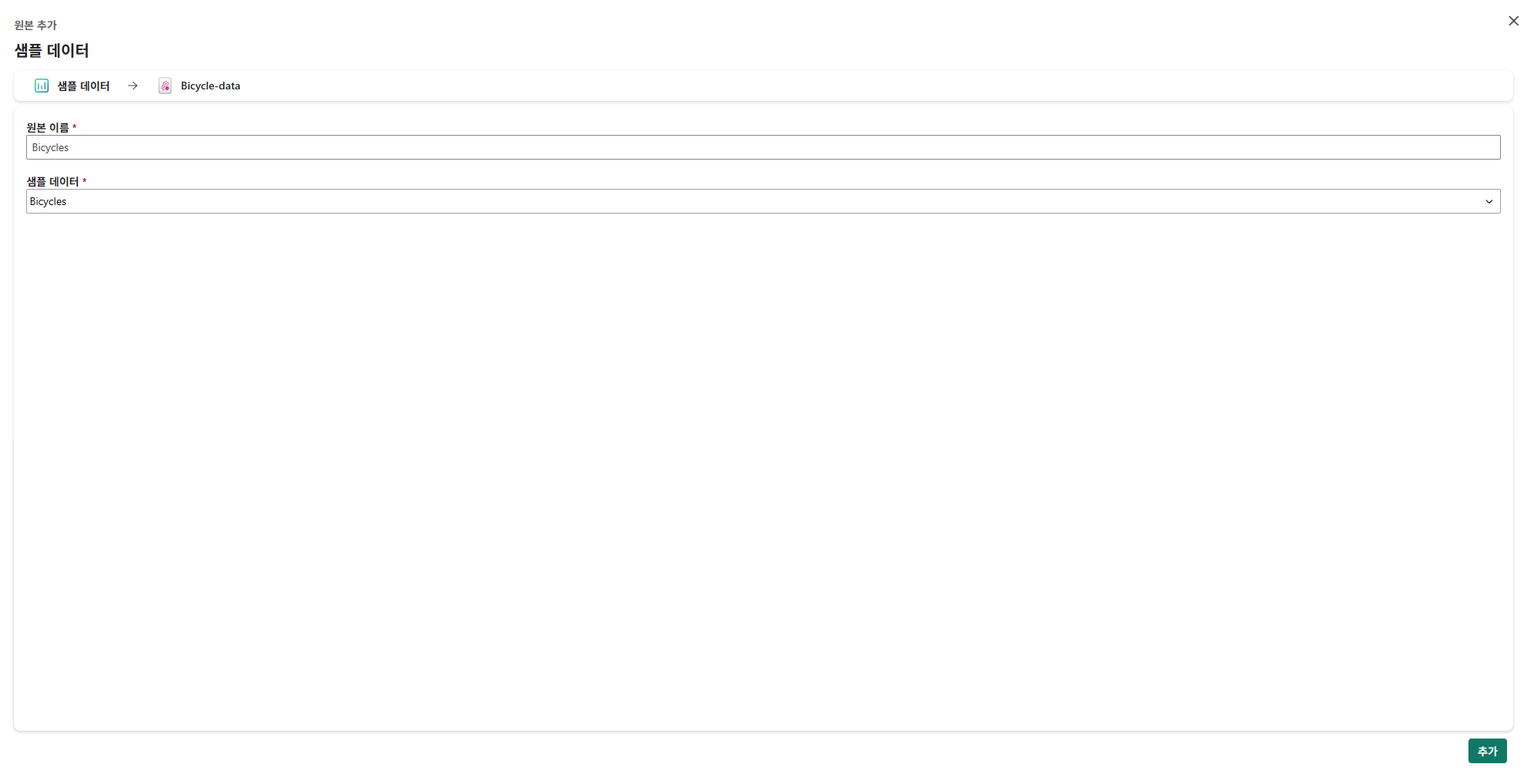
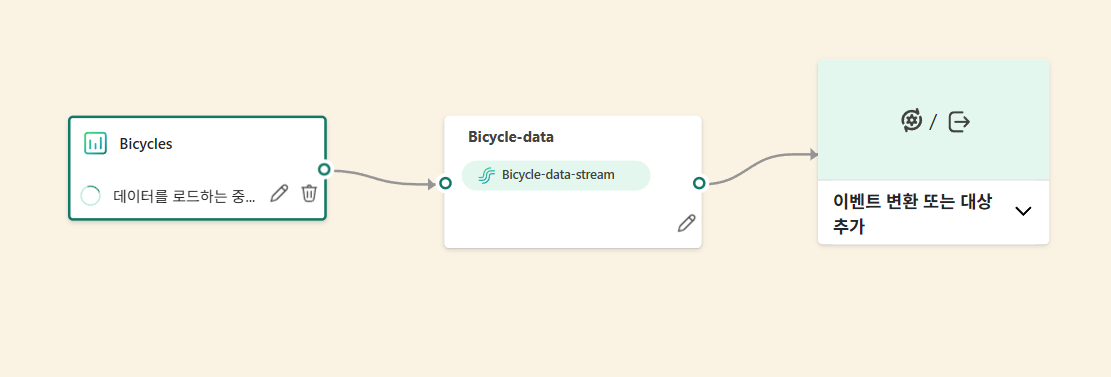
원본 추가
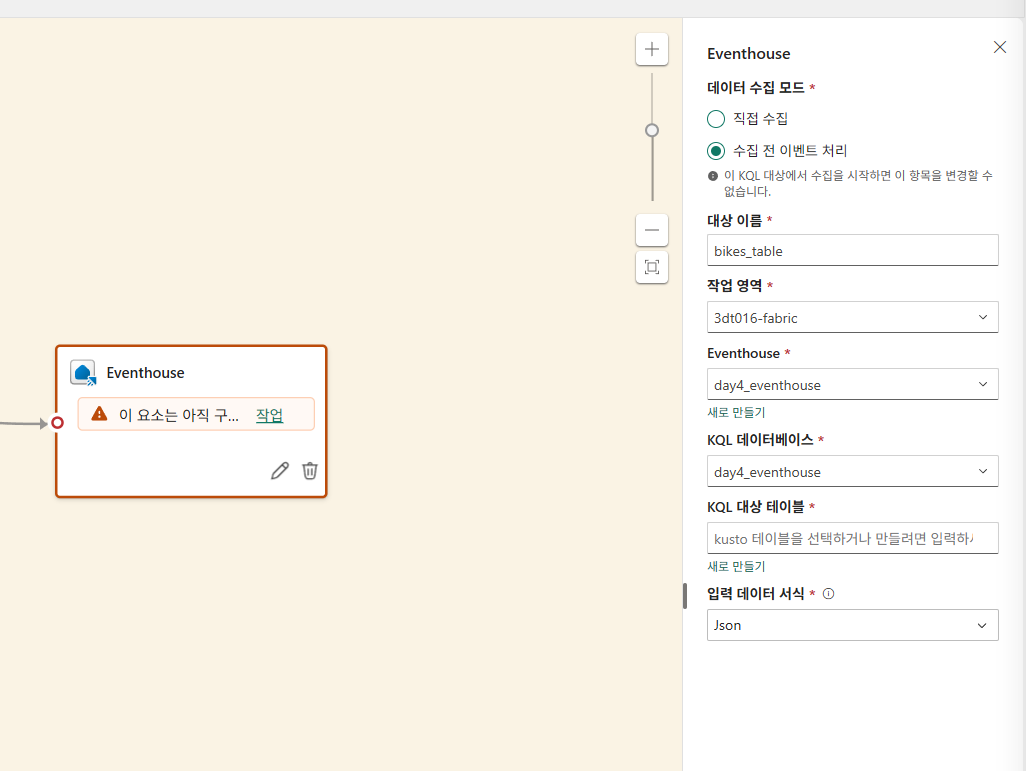
대상 추가
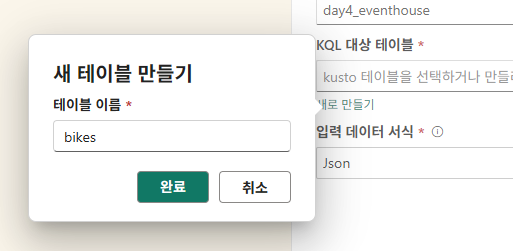
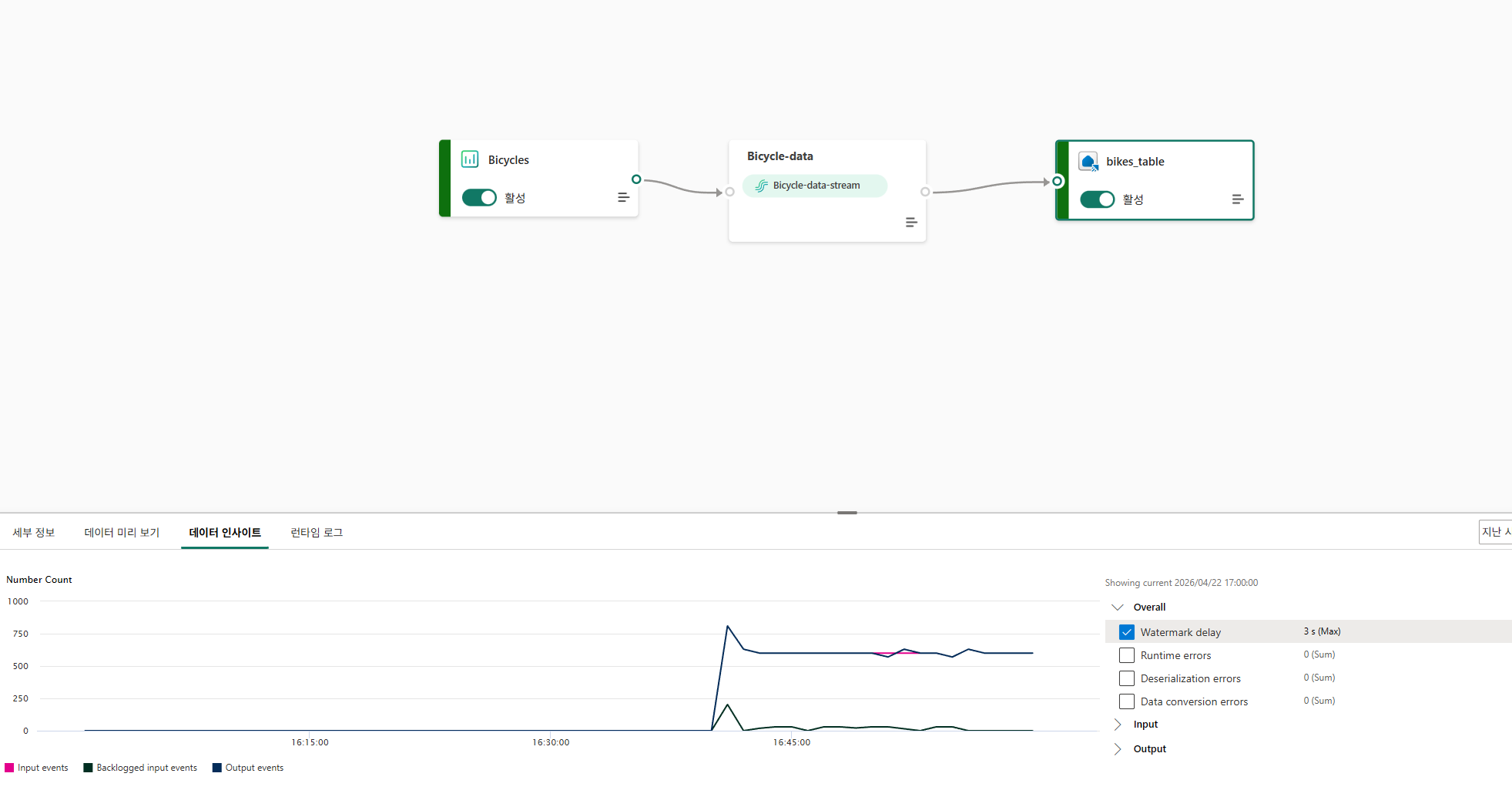
watermark delay: 데이터가 늦게 도착해도 윈도우(결과 집계)를 닫지 않고 얼마나 더 기다려줄 것인가
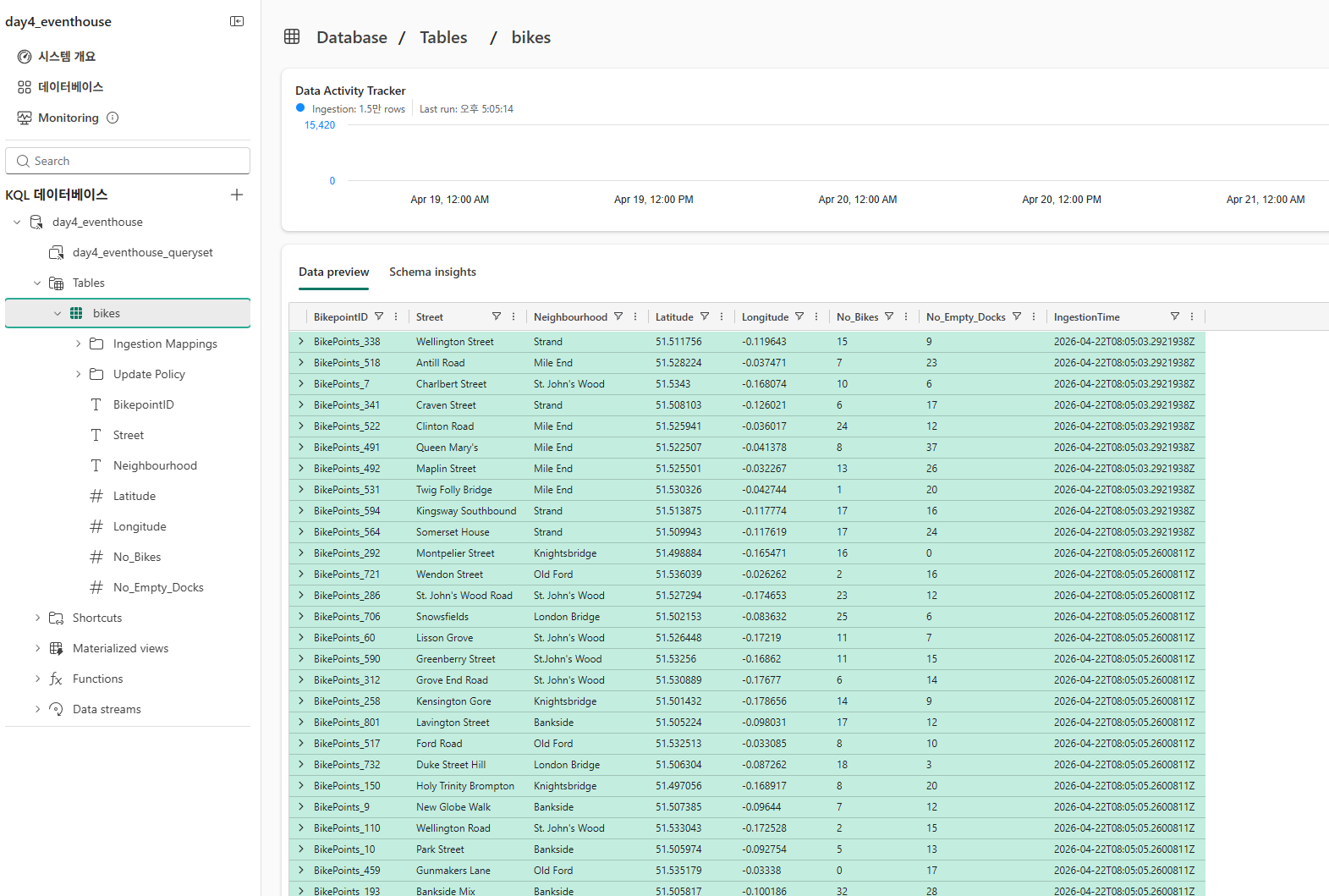
캡처된 데이터 쿼리
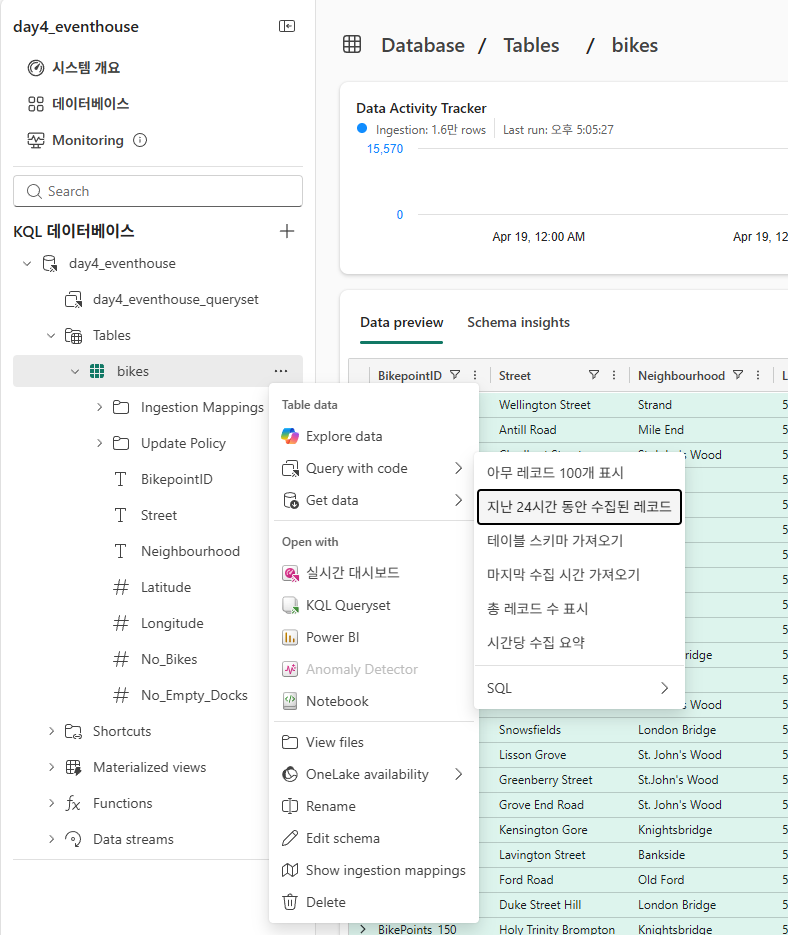
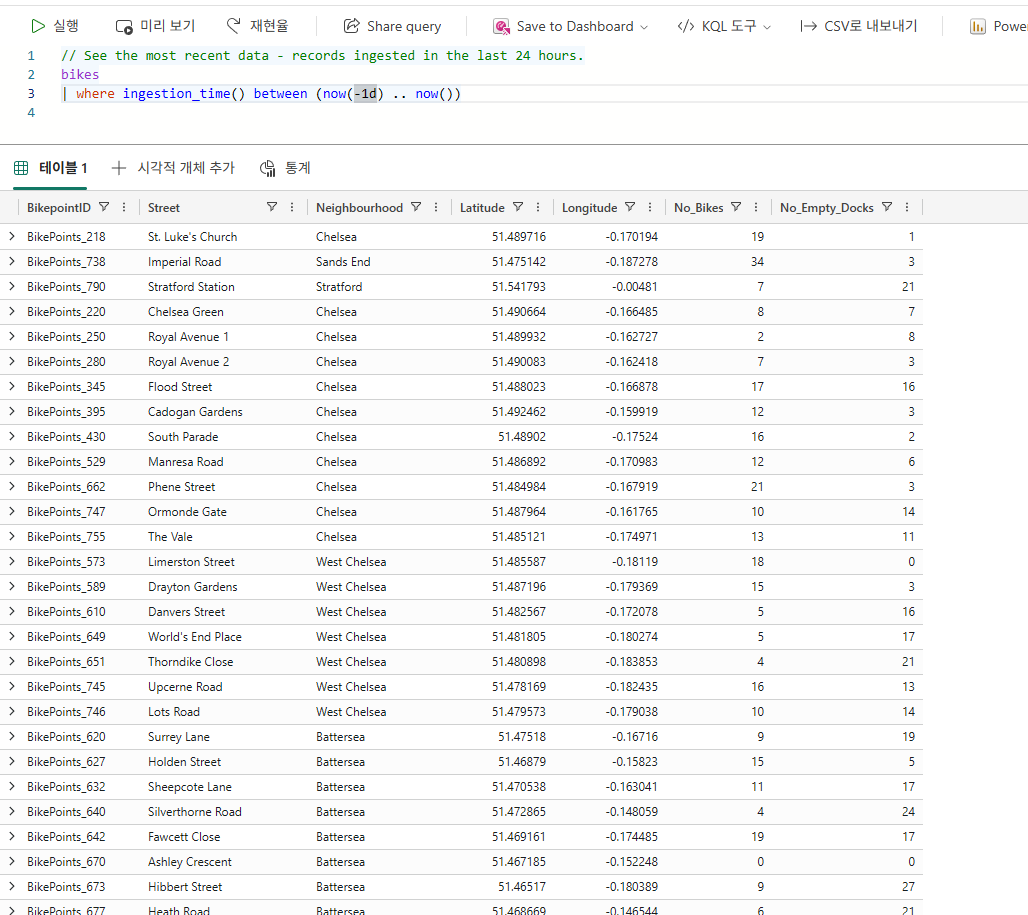
이벤트 데이터 변환
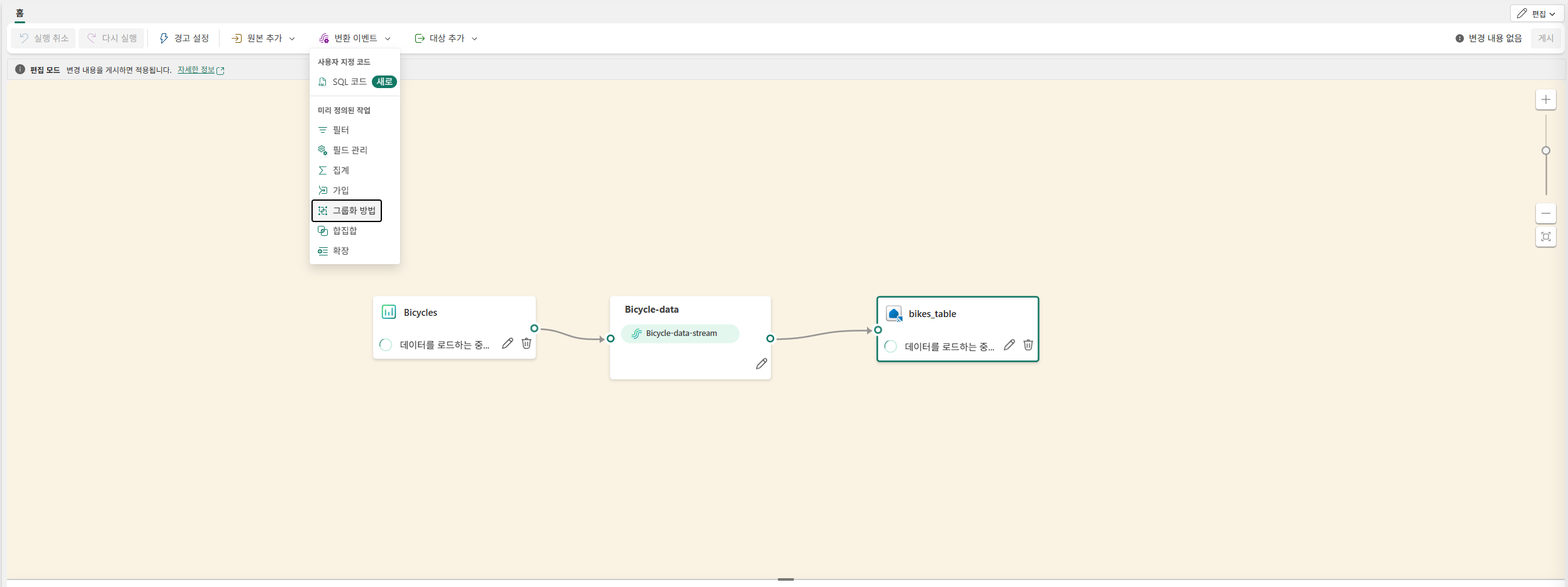
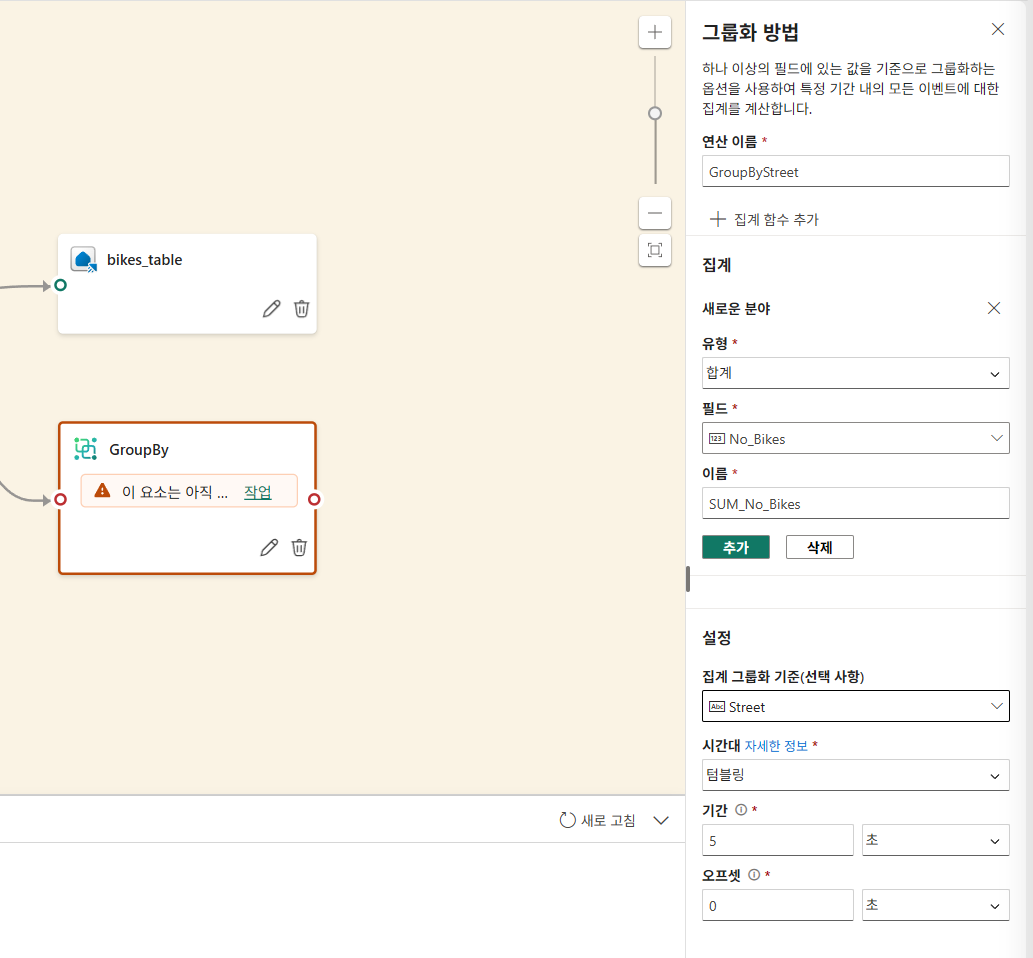
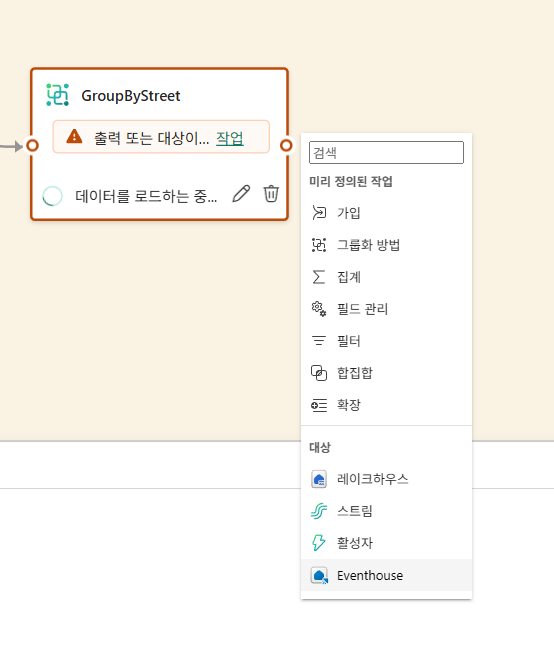
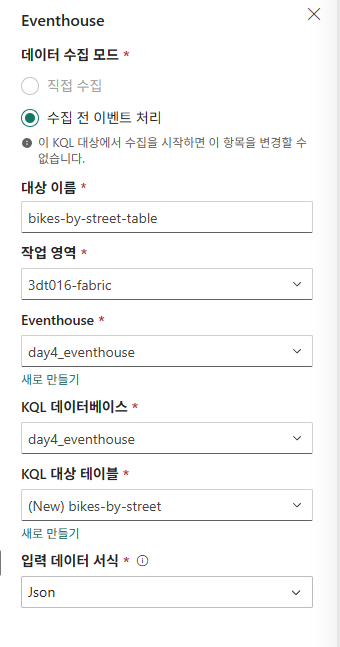
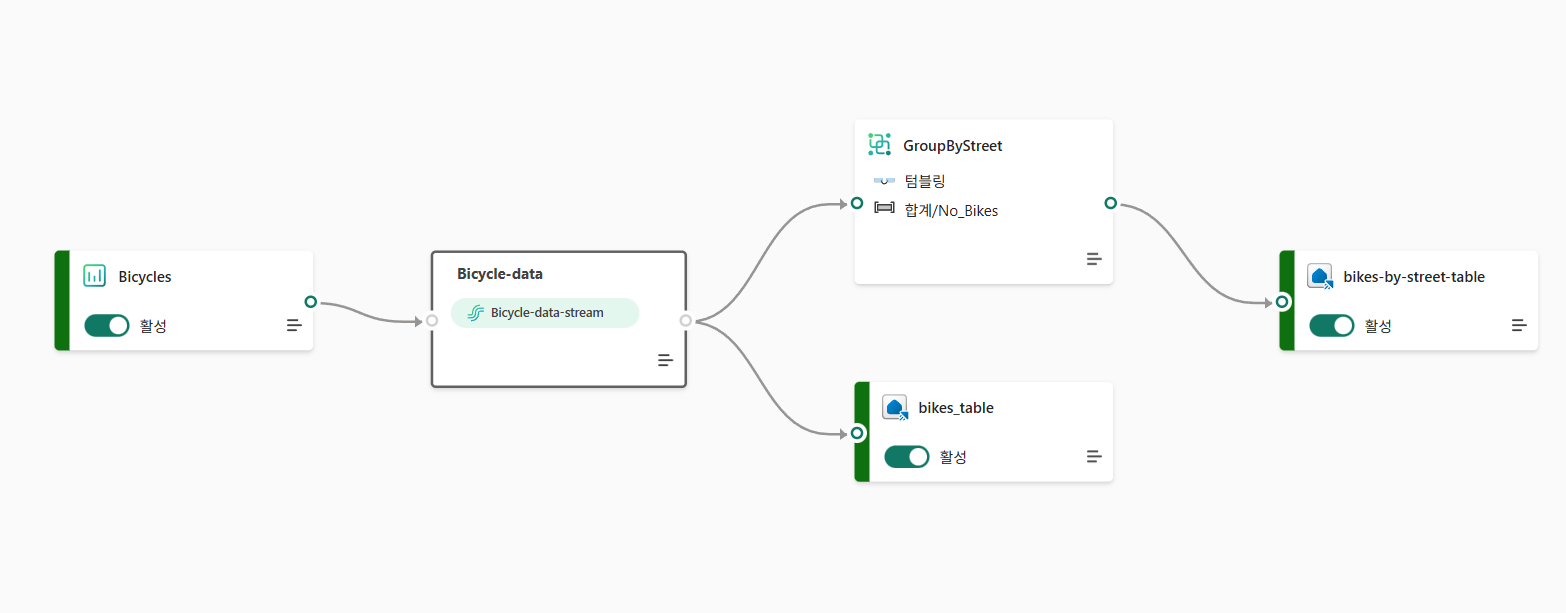
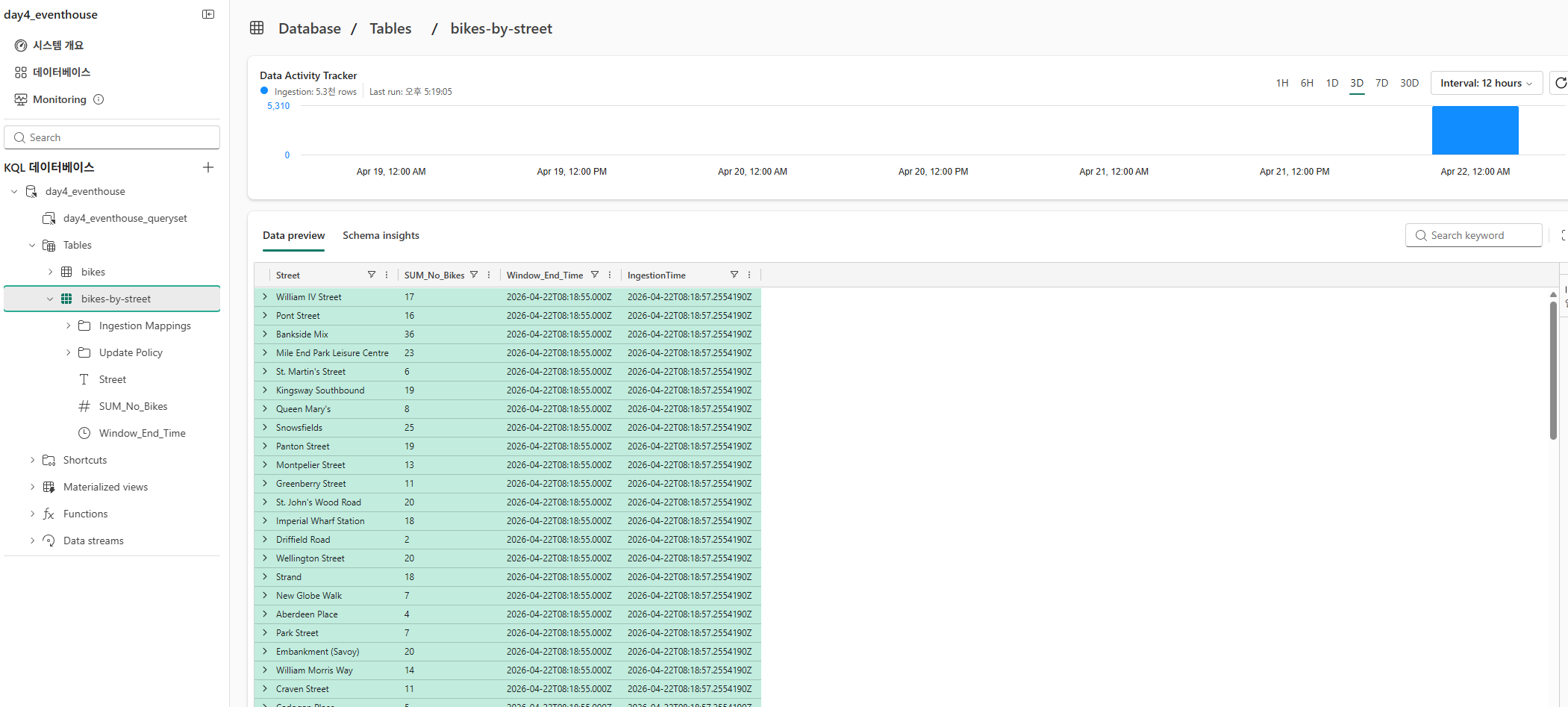
변환된 데이터 쿼리
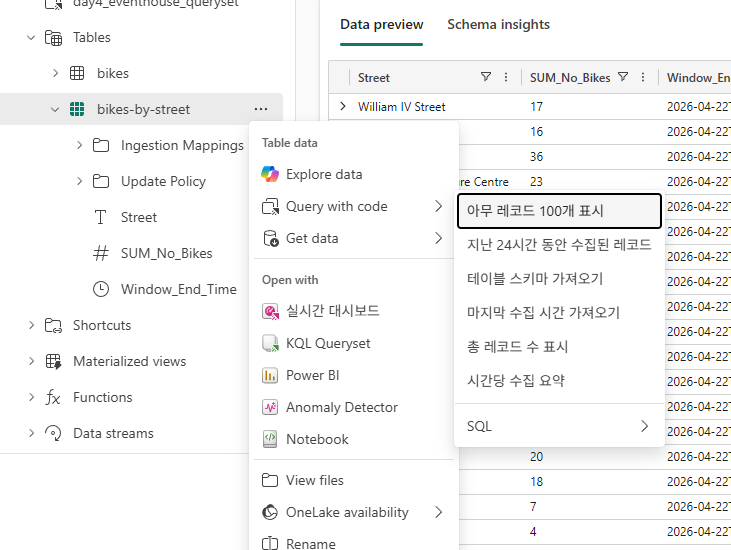
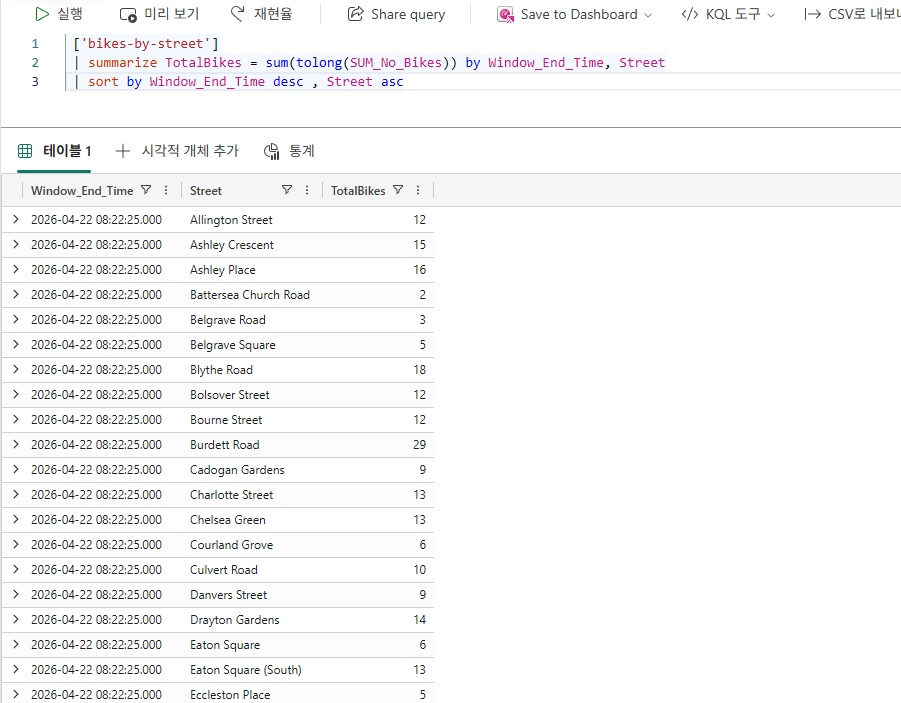
Microsoft Fabric Eventhouse에서 데이터 작업
KQL을 사용하여 데이터 쿼리
// Use 'project' and 'take' to view a sample number of records in the table and check the data.
Bikestream
| project Street, No_Bikes
| take 10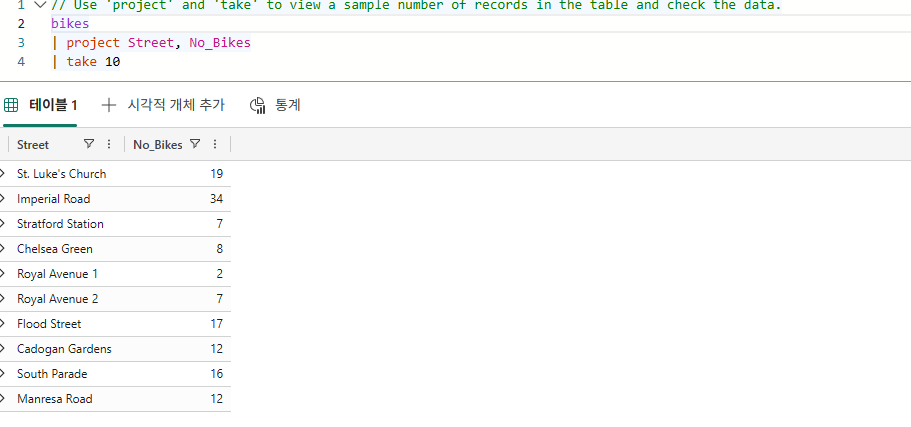
Bikestream
| project Street, ["Number of Empty Docks"] = No_Empty_Docks
| take 10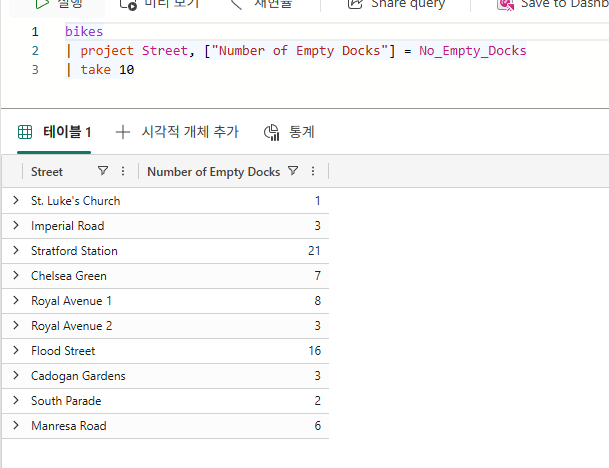
Bikestream
| summarize ["Total Number of Bikes"] = sum(No_Bikes)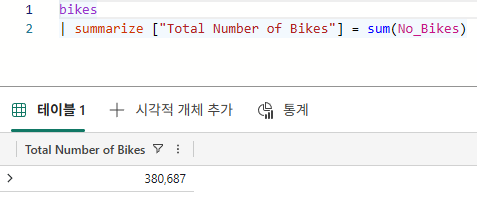
Bikestream
| summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood
| project Neighbourhood, ["Total Number of Bikes"]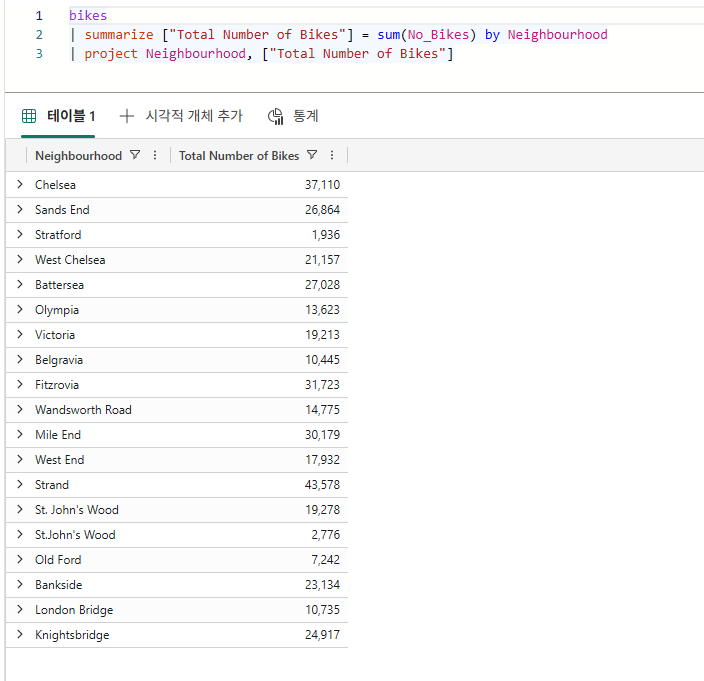
Bikestream
| summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood
| project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]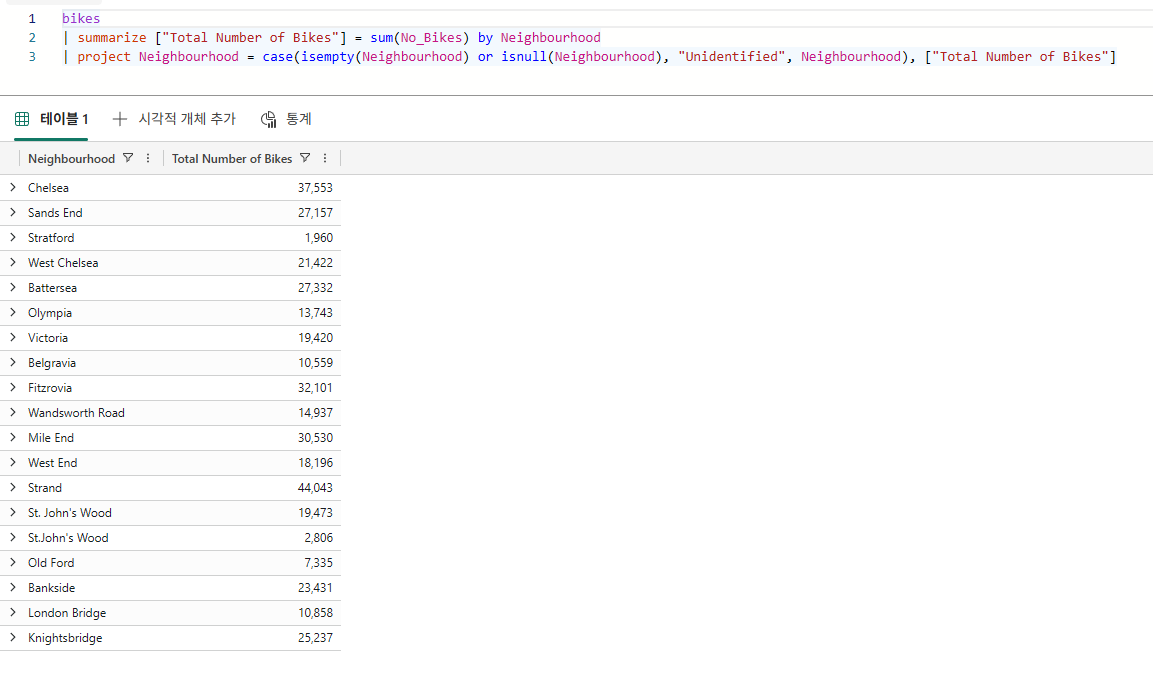
Bikestream
| summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood
| project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]
| sort by Neighbourhood asc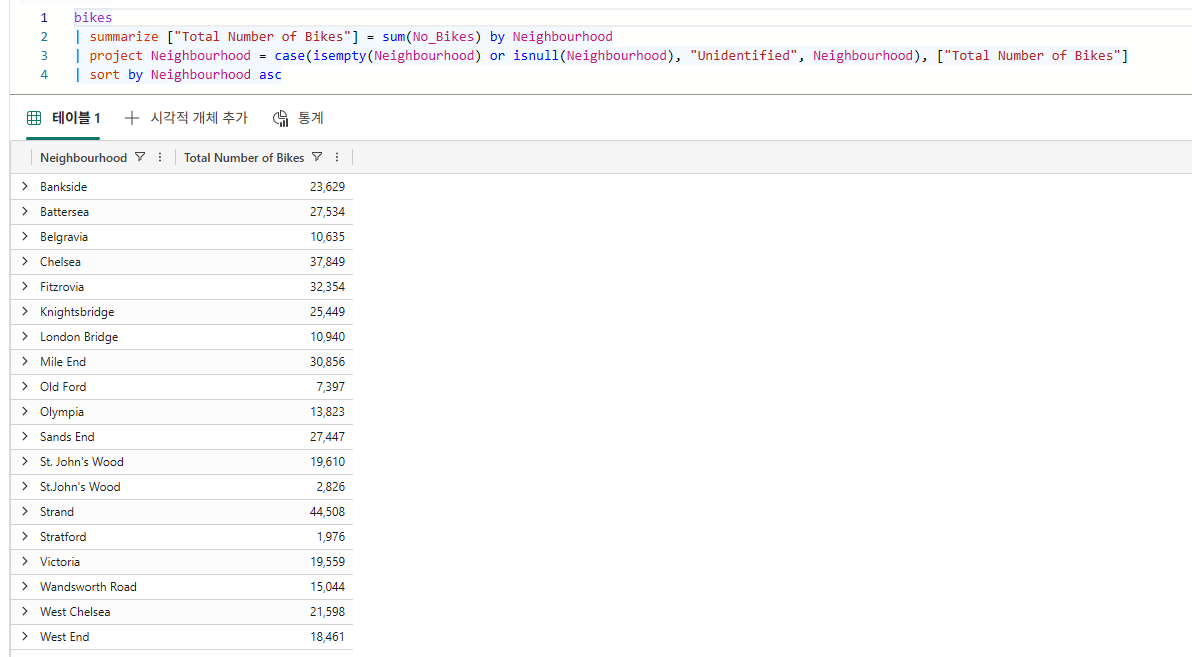
Bikestream
| summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood
| project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]
| order by Neighbourhood asc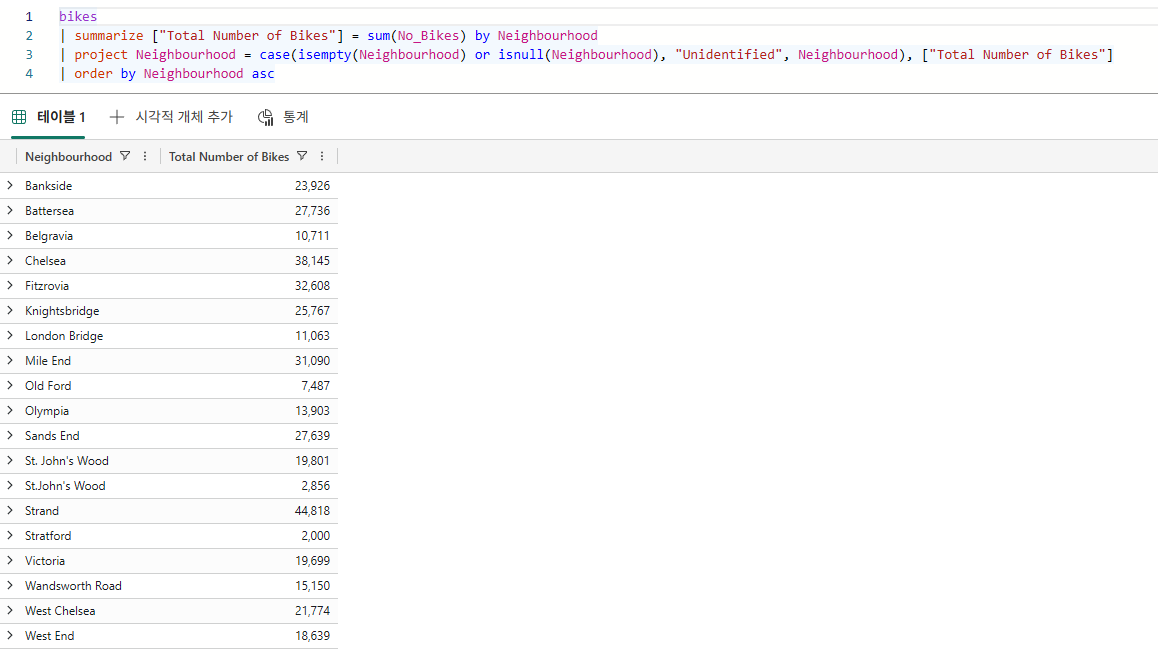
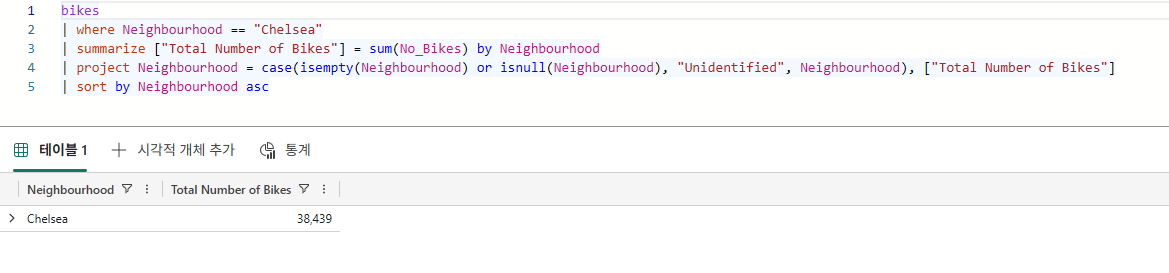
Bikestream
| where Neighbourhood == "Chelsea"
| summarize ["Total Number of Bikes"] = sum(No_Bikes) by Neighbourhood
| project Neighbourhood = case(isempty(Neighbourhood) or isnull(Neighbourhood), "Unidentified", Neighbourhood), ["Total Number of Bikes"]
| sort by Neighbourhood asc