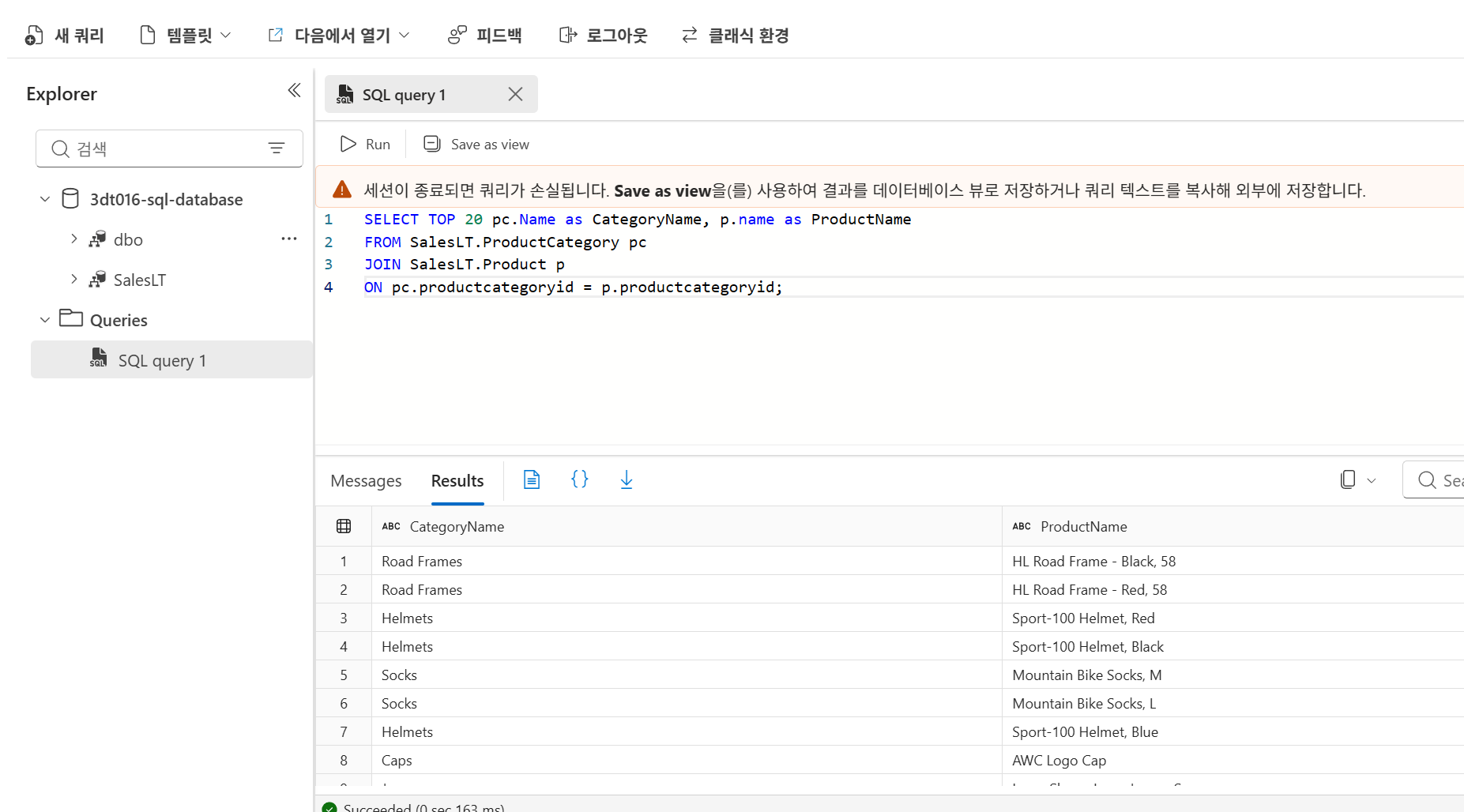
Azure SQL Database 정리
Azure SQL 개요
Azure SQL은 Azure 클라우드에서 SQL Server 데이터베이스 엔진을 사용하는 관리형, 보안 및 인텔리전트 제품군이다. SQL Server 엔진 기반이기 때문에 기존 애플리케이션을 비교적 쉽게 마이그레이션할 수 있고, 익숙한 도구와 언어, 리소스를 계속 사용할 수 있다.
Azure SQL 제품군은 크게 세 가지로 나뉜다.
| 제품 | 설명 | 적합한 상황 |
|---|---|---|
| Azure SQL Database | 서버리스 컴퓨팅을 포함하는 인텔리전트 관리형 데이터베이스 서비스 | 클라우드에서 새로운 앱을 구축하는 경우 |
| Azure SQL Managed Instance | SQL Server 데이터베이스 엔진과 거의 100% 동일한 기능을 제공하는 완전 관리형 인스턴스 | 기존 SQL Server 애플리케이션을 대규모로 현대화하거나 마이그레이션하는 경우 |
| Azure VM 위의 SQL Server | SQL Server 워크로드를 Azure VM으로 리프트 앤 시프트하며 SQL Server 호환성과 OS 수준 액세스를 유지 | OS 수준 제어와 완전한 호환성이 필요한 경우 |
리프트 앤 시프트는 주로 IaaS 환경에서 많이 한다.
Azure SQL 포트폴리오 비교
Azure SQL은 SQL Server 엔진을 기반으로 구축된 통합 SQL 포트폴리오이다. 서비스 선택은 관리 책임, 호환성, 제어 수준에 따라 달라진다.
| 구분 | Azure Virtual Machines 위의 SQL Server | Azure SQL Managed Instance | Azure SQL Database |
|---|---|---|---|
| 서비스 유형 | IaaS | PaaS | PaaS |
| 가장 적합한 앱 | 리호스팅 및 OS 수준 액세스/제어가 필요한 앱 | 기존 앱 현대화 | 클라우드 신규 앱 구축 |
| 주요 특징 | 자동화된 관리 기능 및 OS 수준 액세스 | SQL Server와의 높은 호환성, 기본 VNet 지원 | 사전 프로비저닝 또는 서버리스 컴퓨팅, 하이퍼스케일 스토리지 |
| 제어 수준 | 가장 높음 | 중간 | 가장 낮음 |
| 관리 부담 | 가장 큼 | 중간 | 가장 작음 |
리호스팅은 IT 시스템 마이그레이션에서 대표적으로 사용되는 방식으로, 기존 시스템을 큰 변경 없이 다른 환경으로 이전하는 방법이다.(센터 이전도 가능)
신기능은 Azure Virtual Machines 외의 2종류 정도에만 잘 들어간다.
Versionless Database 엔진과 호환성
Azure VM 위의 SQL은 선택한 특정 SQL Server 버전에 묶여 있다. 반면 Azure SQL Database와 Azure SQL Managed Instance는 PaaS 특성상 특정 버전에 종속되지 않는다. 특히 Always-up-to-date 업데이트 정책을 사용하면 최신 클라우드 기능을 빠르게 반영할 수 있다.
| 구분 | SQL Server 2025 업데이트 정책 | Always-up-to-date 업데이트 정책 |
|---|---|---|
| 특징 | SQL Server 2025 버전과의 호환성 유지 | 최신 클라우드 기능 즉시 반영 |
| 장점 | 온프레미스 SQL 2025로 복원 및 링크 가능 | 최신 엔진 성능 및 보안 업데이트 자동 적용 |
| 제한 | 최신 클라우드 전용 엔진 기능 사용 불가 | 이전 버전 정책으로 복구 불가, 하향 불가 |
핵심은 SQL Server, Azure SQL Database, Managed Instance가 하나의 공통 코드베이스를 기반으로 최신 엔진 기능을 제공한다는 점이다. SQL Server 버전은 몇 년 단위로 출시되지만, PaaS 서비스는 지속적으로 엔진이 업데이트된다. 이 구조 덕분에 OS 및 SQL Server 패치 부담이 줄어든다.
Azure SQL 서비스 비교
Azure SQL 서비스는 Bare Metal부터 PaaS까지 다양한 형태로 SQL Server를 사용할 수 있게 한다.
(Bare Metal은 가상화 없이 사용하는 것)
Private Cloud는 자체적으로 구축한 클라우드 환경
| 구분 | Azure SQL Database | Azure SQL Managed Instance | Azure VM의 SQL Server |
|---|---|---|---|
| 지원 기능 | 대부분의 SQL DB 기능 지원, 일부 제약 | 거의 모든 온프레미스 인스턴스 수준 | 모든 온프레미스 기능 지원 |
| 가용성/확장성 | 99.995% SLA, 단일/풀링 지원 | 99.99% SLA, 단일/풀링 가능 | 99.99% SLA, VM 크기/구성에 따름 |
| 유지 관리/패치 | 자동 패치·백업 | 자동 패치·백업 | 직접 관리 필요, 일부 자동 기능 지원 |
| 네트워크 접근 | Azure Private Link 등 지원 | ExpressRoute, VPN Gateway 등 지원 | Azure Virtual Network 내에 배치 |
| 최대 저장 공간 | 128TB | 16TB | 256TB 이상, 스토리지 추가 가능 |
| 마이그레이션 용이성 | 일부 SQL Server 기능 제한적 호환 | 더 높은 호환성, 마이그레이션 쉬움 | 온프레미스와 동일, 완벽 호환 |
| 운영 책임 | 대부분 Azure에서 관리 | 일부 Azure와 공동 책임 모델 | 사용자 직접 관리 |
| 온프레미스 연계 | 기본 제공, 제한적 | 네트워크/도메인 연계 지원 | 도메인/애플리케이션 등 완벽 연동 |
| 사용 사례 | SaaS 앱, 단일/풀링 DB | 리프트 앤 시프트, 복잡한 SQL 앱 | 레거시 이전, 사용자화 앱, 고도의 통제 필요 |
Azure SQL 결정 트리
Azure SQL 결정 트리는 신규 앱인지, 기존 DB 마이그레이션인지, OS 접근이 필요한지, SQL Server 호환성이 어느 정도 필요한지에 따라 서비스를 선택하도록 돕는다.
- 신규 클라우드 앱이면 Azure SQL Database가 우선 고려된다.
- 기존 SQL Server 앱을 마이그레이션하고 호환성이 중요하면 Managed Instance가 적합하다.
- OS 수준 접근, 특정 SQL Server 기능, 완전한 제어가 필요하면 SQL Server on Azure VM이 적합하다.
- 대규모 확장, 서버리스, 하이퍼스케일 요구가 있으면 Azure SQL Database의 Hyperscale 또는 Serverless 옵션을 고려한다.
Azure SQL DB 내부 구조: Control Ring vs Data Ring
Azure SQL은 단일 서버가 아니라 Control Ring과 Data Ring으로 나뉜 분산 시스템이다. Control Ring은 라우팅을 담당하고, Data Ring은 실제 연산을 수행한다. 백엔드 노드에 장애가 발생해도 Control Ring이 정상 노드로 트래픽을 우회하여 연결 단절을 최소화한다.
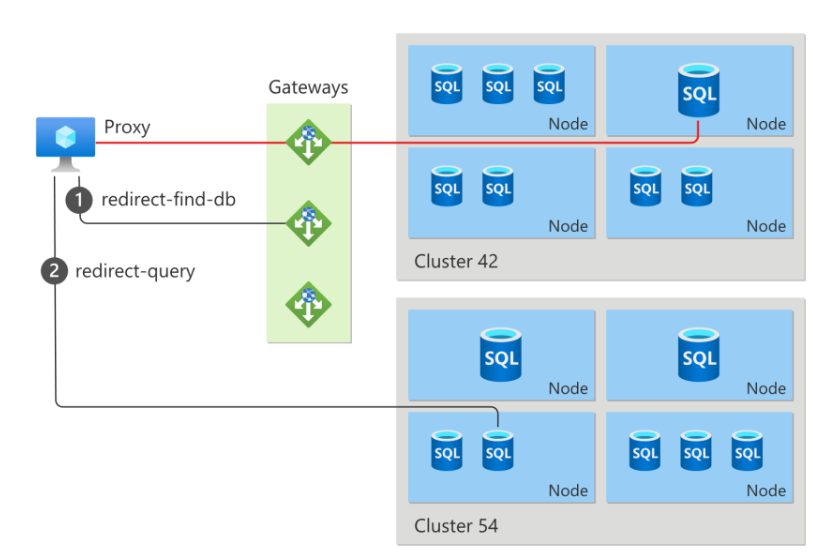
| 구성 요소 | 역할 |
|---|---|
| 클라이언트 App | 포트 1433으로 쿼리 요청 |
| Control Ring / Gateway Layer | TDS 프로토콜의 앞문 역할, 인증 처리, 방화벽 검사, DB 위치 메타데이터 확인 |
| Data Ring / Database Compute Layer | SQL Server 프로세스가 동작하는 컨테이너/VM 풀, 쿼리 파싱·컴파일·실행 |
| Storage Layer | Azure Blob Storage 기반 데이터 및 로그 파일 저장 |
연결 토폴로지: Proxy vs Redirect
Azure SQL은 성능과 네트워크 보안 요구에 따라 Proxy와 Redirect 방식의 연결 토폴로지를 제공한다.
| 구분 | Proxy 모드 | Redirect 모드 |
|---|---|---|
| 작동 방식 | 모든 통신이 Gateway를 경유하여 Data Node로 전달 | 최초 연결 시 Gateway에 노드 위치를 질의한 뒤, 이후 Data Node에 직접 연결 |
| 포트 요구사항 | 아웃바운드 TCP 1433만 개방 | TCP 1433 + 11000~11999 범위 개방 필요 |
| 장점 | 보안 설정이 단순함 | 지연 시간 최소화, 처리량 극대화 |
| 사용 환경 | 인터넷을 통한 외부 연결 시 기본값 | Azure 내부망, VNet, VM 연결 시 기본값 또는 성능 권장 방식 |
Azure SQL 주요 기능
Azure SQL은 안전하고 안정적인 운영을 위해 다양한 기능을 제공한다.
| 기능 | 설명 |
|---|---|
| Business continuity | 비즈니스 연속성 보장 |
| High Availability | 고가용성 구성 |
| Automated Backups | 자동 백업 |
| Geo-replication | 지리적 복제 |
| Scalability | 확장성 |
| Automated patching | 자동 패치 |
| Security | 보안 |
| Automatic tuning | 자동 튜닝 |
| Built-in monitoring and intelligence | 내장 모니터링 및 지능형 분석 |
| Migrating to Azure | Azure 마이그레이션 지원 |
구매 모델 및 스케일링 전략
Azure SQL 배포 옵션
Azure SQL은 다양한 워크로드 요구 사항에 맞게 여러 배포 옵션을 제공한다.
| 배포 옵션 | 설명 | 대표 형태 |
|---|---|---|
| SQL virtual machines | OS 수준 접근이 필요한 마이그레이션 및 애플리케이션에 적합 | SQL virtual machine |
| Managed instances | 리프트 앤 시프트 마이그레이션에 적합 | Single instance, Instance pool |
| Databases | 최신 클라우드 애플리케이션에 적합 | Single database, Elastic pool |
SQL virtual machines는 SQL Server와 OS를 직접 접근하고 관리할 수 있다. Managed Instance는 SQL Server surface area 대부분을 지원하면서도 완전 관리형 서비스이다. Database는 Hyperscale, Serverless, Elastic Pool 등을 통해 최신 앱에 적합한 운영 방식을 제공한다.
Elastic이라는 단어가 들어갔다면 확장성에 집중한 모델임을 알 수 있다.
DTU vs vCore 모델
Azure SQL Database는 DTU 기반 구매 모델과 vCore 기반 구매 모델을 제공한다. vCore 기반 모델이 권장된다.
| 구매 모델 | 설명 | 적합한 대상 |
|---|---|---|
| DTU 기반 | 컴퓨팅, 스토리지, IO 리소스를 번들로 묶은 측정값 기반. 단일 DB는 DTU, 탄력적 풀은 eDTU로 표시 | 간단하고 미리 구성된 리소스 옵션을 원하는 고객 |
| vCore 기반 | 컴퓨팅과 스토리지 리소스를 독립적으로 선택 가능. Azure 하이브리드 혜택으로 비용 절감 가능 | 유연성, 제어, 투명성을 중요시하는 고객 |
DTU는 단순하고 미리 구성된 리소스 옵션을 제공하는 반면, vCore는 CPU와 스토리지 등 리소스를 더 투명하게 선택할 수 있다.
Provisioned vs Serverless 설계 및 Auto-pause
워크로드 패턴에 따라 고정 리소스 방식과 자동 스케일링 방식을 선택할 수 있다.
| 구분 | Provisioned | Serverless |
|---|---|---|
| 동작 방식 | 24시간 내내 지정된 vCore와 메모리 항상 할당 | 최소~최대 vCore 범위 안에서 수요에 따라 자동 스케일링 |
| 과금 | 시간당 고정 과금 | 초 단위 과금 |
| 장점 | 성능이 일정하고 쿼리 응답 지연이 없음 | 사용하지 않을 때 비용 절감 가능 |
| Auto-pause | 없음 | 지정 시간 동안 쿼리가 없으면 DB 일시 중지, 스토리지 비용만 청구 |
| Auto-resume | 없음 | 새 연결 발생 시 자동 재개, 첫 연결 시 1~2초 지연 가능 |
| 적용 대상 | 트래픽이 꾸준하거나 리소스 사용량을 예측 가능한 Production 워크로드 | 간헐적·예측 불가능한 워크로드, 야간 트래픽 없는 시스템, Dev/Test 환경 |
Scalability
Azure SQL 서비스 유형별 확장 방식과 특징은 다르다.
| 서비스 유형 | 확장 방식 | 주요 특징 및 옵션 | 유의할 점 |
|---|---|---|---|
| Azure SQL Database (PaaS) | 포털에서 CPU/메모리/스토리지 슬라이더로 즉시 상향/하향 조정, Elastic Pool/서버리스 등 리소스 풀링·자동 확장 | 다운타임 없이 수분 내 리소스 증감, Elastic Pool로 여러 DB 간 자원 공유, 서버리스 부하 기반 자동 확장/축소, Premium·Hyperscale·DTU/vCore 옵션 | 자동 확장/축소는 서버리스 전용, Elastic/Hyperscale은 별도 과금 및 일부 제한 |
| Azure SQL Managed Instance | 인스턴스 단위 CPU/메모리/스토리지 증감, Instance Pool로 여러 인스턴스 자원 풀링 | Portal/CLI에서 인스턴스 리사이즈, Instance Pool 활용 가능 | 자동화 옵션 없음, 수동 확장, 증설 시 엔진 재구동 등 단기 중단 가능 |
| SQL Server on Azure VM (IaaS) | VM 크기 변경, 디스크 추가/변경, AG 등으로 Scale-Out | Azure VM 관리화면에서 VM 스펙 교체, 스토리지 추가, AG로 수평 분산 가능 | VM 리사이즈나 스토리지 증설 시 OS/DB 재시작 필요, 직접 관리 필요 |
Elastic Database 풀
Elastic Database Pool은 여러 데이터베이스 또는 인스턴스 간에 리소스를 공유하고 비용을 최적화하는 기능이다.
| 구분 | SQL Database Elastic Pool | SQL Managed Instance Pool |
|---|---|---|
| 개념 | 하나의 프로비저닝된 SQL Database 리소스 세트 내에서 여러 DB 호스트 | 여러 Managed Instance를 호스트하고 리소스를 공유 |
| 장점 | 여러 DB 성능을 하나의 간소화된 방식으로 관리·모니터링 | 컴퓨팅 리소스를 사전 프로비저닝하여 배포 시간 단축, 더 작은 MI 구성 가능 |
| 적합 사례 | SaaS 애플리케이션 또는 공급자 | 대규모 Managed Instance 마이그레이션 및 통합 |
| 상태 | 일반적으로 사용 | 공개 미리 보기 상태로 언급됨 |
Paychex 사례에서는 여러 고객의 시간 및 결제 관리를 개별 DB로 운영하면서도 비용 절감을 위해 SQL Database Elastic Pool을 선택했다.
하이퍼스케일 모델: 지역 중복 가용성
하이퍼스케일 모델은 기존 로컬/공유 스토리지 모델과 달리 컴퓨트와 스토리지 계층을 완전히 분리한다. 이로 인해 대용량 데이터, 빠른 확장성, 효율적 장애 복구를 제공한다.
| 구성 요소 | 설명 |
|---|---|
| 컴퓨팅 노드 | 읽기/쓰기 노드와 읽기 전용 노드 등으로 구성 가능 |
| 페이지 서버 | 데이터 페이지를 관리하는 분산 스토리지 계층 |
| 로그 서비스 | 로그 처리를 담당하는 고가용성 구성 요소 |
| 영구 스토리지 | Azure Storage 기반, 네이티브 고가용성 및 중복 기능 제공 |
| Azure Service Fabric | 구성 요소 상태를 제어하고 장애 시 정상 노드로 장애 조치 수행 |
하이퍼스케일 모델의 특징은 다음과 같다.
- 컴퓨트와 스토리지가 완전히 분리된다.
- 여러 컴퓨트와 여러 스토리지 구성 요소가 독립적으로 확장된다.
- 노드 장애 시 다른 컴퓨트 노드에서 서비스를 재개할 수 있다.
- 수십 TB급 대용량 데이터베이스에 적합하다.
- 새 복제본 또는 스냅샷을 빠르게 생성할 수 있다.
하이퍼스케일 모델: 영역간 중복 가용성
영역 중복성을 선택하면 하이퍼스케일 계층 전체에 대해 가용성 영역 간 복제가 적용되어 영역 수준 복원력이 보장된다.
- 애플리케이션 로직 변경 없이 엔터프라이즈급 내결함성 구성 가능
- 한 가용성 영역 장애 시 실시간 자동 failover 지원
- 데이터 손실 없는 고가용성 보장
- 서비스 중단 없이 패치 및 업그레이드 가능
- 대용량 확장성과 빠른 복구 제공
네트워크 보안
방화벽 규칙: 서버 수준 vs DB 수준
Azure SQL 방화벽은 서버 수준과 데이터베이스 수준 두 겹으로 동작한다. 최소 권한 원칙에 따라 특정 DB에만 접근을 허용하는 데이터베이스 수준 방화벽 규칙이 권장된다.
| 구분 | 서버 수준 방화벽 | 데이터베이스 수준 방화벽 |
|---|---|---|
| 적용 범위 | 논리적 SQL 서버에 속한 모든 DB 접근 허용 | 규칙이 생성된 특정 단일 DB에만 접근 허용 |
| 설정 방법 | Azure Portal, PowerShell, Azure CLI, REST API | 포털 설정 불가, T-SQL sp_set_database_firewall_rule 사용 |
| 보안성 | 범위가 넓어 상대적으로 낮음 | 특정 DB만 허용하므로 높음 |
| 주의사항 | “Azure 서비스 및 리소스에서 이 서버에 액세스하도록 허용” 옵션은 전 세계 Azure 서비스 IP를 허용하므로 위험 | 규칙 관리가 T-SQL 기반 |
규칙 평가 순서는 데이터베이스 수준 규칙이 먼저이며, 매칭되면 해당 DB만 접속된다. 데이터베이스 수준 규칙이 없으면 서버 수준 규칙을 확인하고, 둘 다 없으면 접속이 차단된다.
VNet Service Endpoint vs Private Link
PaaS 데이터베이스를 퍼블릭 인터넷에서 격리하고 회사 내부망과 연동하는 방식은 서비스에 따라 다르다.
온프레미스라면 VNet Injection이 적합(다만 전용인 VNet Injection이 더 비쌈)
각각 공용, 전용
| 구분 | Azure SQL Database: Private Link | SQL Managed Instance: VNet Injection |
|---|---|---|
| 방식 | 프라이빗 엔드포인트 사용 | 가상 네트워크 주입 방식 |
| 구조 | 기존 VNet 변경 불필요, 개별 DB 단위 사설 IP 매핑 | MI 전용 서브넷 필수 |
| 인프라 | 외부 PaaS 인프라 유지 | 내 VNet 안에 서버를 통째로 넣는 구조 |
| 장점 | 개별 DB 단위로 안전하게 사설 접근 가능 | 완벽한 양방향 통신, 온프레미스 VPN 연동, 물리적 격리에 가까운 수준 |
데이터베이스 보안 및 관리
데이터 암호화 및 접근 제어
Azure SQL은 TDE, Always Encrypted, RLS, DDM 등 다계층 데이터 보호를 제공한다.
| 구분 | 기능 | 설명 |
|---|---|---|
| 물리적 암호화 | TDE | 디스크에 저장되는 데이터와 백업 파일을 실시간 암호화. 기본값 ON. 디스크 탈취 시에도 데이터 보호 |
| 물리적 암호화 | Always Encrypted | 클라이언트 애플리케이션에서 데이터를 암호화한 뒤 DB 엔진으로 전송. DB 메모리에서도 암호화 상태 유지 |
| 논리적 필터링 | RLS | 로그인 사용자 권한에 따라 보이는 행을 필터링. 예: 서울 지점 직원은 서울 지점 매출만 조회 |
| 논리적 필터링 | DDM | 주민등록번호, 신용카드 번호 등 민감한 열을 마스킹해 반환. 실제 데이터는 변경되지 않음 |
Microsoft Entra ID 및 비밀번호 없는 연결
Azure SQL은 SQL Server 인증 대신 Microsoft Entra ID 기반 토큰 인증을 지원한다. 이를 통해 소스코드에서 비밀번호를 제거할 수 있다.
| 항목 | 내용 |
|---|---|
| 중앙 집중식 통제 | 퇴사자 발생 시 Entra ID에서 계정만 비활성화하면 DB 접근 차단 |
| MFA 지원 | 로그인 시 스마트폰 앱 승인 등 추가 인증 강제 가능 |
| 온프레미스 AD 연동 | 기존 사내 Active Directory와 동기화하여 SSO 가능 |
| Managed Identity | Azure 리소스에 고유 ID를 부여하고, Connection String에 Authentication=Active Directory Managed Identity를 사용 |
| Entra-only authentication | SQL sa 계정 로그인을 원천 차단하고 토큰 기반 접근만 허용 |
Azure SQL Ledger
Azure SQL Ledger는 블록체인의 SHA-256 해시 기술을 관계형 데이터베이스 엔진에 탑재하여 데이터 위변조를 탐지할 수 있도록 하는 기능이다.
| 구분 | 설명 |
|---|---|
| 작동 원리 | INSERT/UPDATE/DELETE 발생 시 트랜잭션 내용을 SHA-256 해시로 암호화하여 블록 생성 |
| 해시 체인 | 이전 트랜잭션 해시를 다음 트랜잭션이 참조하여 중간 데이터 조작 시 전체 해시값이 깨짐 |
| Updatable Ledger | 일반 테이블처럼 UPDATE/DELETE 가능. 변경 이력은 History Table에 영구 보존 |
| Append-Only Ledger | INSERT만 가능. UPDATE/DELETE는 엔진 레벨에서 거부 |
| 사용 사례 | SIEM, 보안 감사 로그, 금융 거래, 결제 내역, 외부 감사용 데이터 무결성 증명 |
성능 모니터링 및 최적화
Built-in monitoring and intelligence
Azure SQL은 여러 도구를 통해 모니터링과 성능 분석을 제공한다.
| 기능/도구 | 설명 | Azure SQL Database | Managed Instance | SQL on Azure VM |
|---|---|---|---|---|
| Azure Monitor | CPU, 메모리, 저장소, 연결 등 리소스 실시간 관찰, 알림 및 진단 로그 집계 | 지원 | 지원 | 지원 |
| Database Watcher | DB 성능, 건강 상태, 트랜잭션 등 심층 모니터링 및 대시보드 | 지원 | 지원 | 미지원 |
| Query Performance Insights | 상위 리소스 소모/비효율 쿼리 현황 시각화, 실행 성능 분석 | 지원 | 일부 지원 | SSMS에서 지원 |
| Intelligent Insights | AI 기반 장애/성능 저하 원인 자동 감지 및 해결 가이드 제공 | 지원 | 지원 | 미지원 |
| Alert & 대시보드 | 포털 기반 임계치 알림, 상태/로그 대시보드 제공 | 지원 | 지원 | Portal/Log Analytics 지원 |
| Deep Query Analytics | Query Store 등으로 쿼리 실행 이력, 실행 계획, 상세 워크로드 분석 | 지원 | 지원 | 직접 또는 외부 도구 활용 |
| Best Practice 검사 | 보안, 아키텍처, 성능 등 운영 모범 실천 기준 자동 점검 및 경고 | 지원 | 지원 | IaaS Agent 필요 |
대기 통계 Wait Stats 분석 방법
Wait Stats는 쿼리가 실행되는 동안 어떤 자원을 기다리느라 시간이 소요되었는지 알려주는 성능 트러블슈팅 핵심 지표이다.
| 항목 | 설명 |
|---|---|
| Wait Stats 의미 | SQL 엔진이 필요한 자원을 기다린 시간과 이유를 기록한 데이터 |
| 분석 가치 | “쿼리가 느리다”를 “디스크 읽기를 기다리느라 70% 시간을 썼다”처럼 구체화 가능 |
| DMV | sys.dm_db_wait_stats를 통해 DB 레벨 누적 대기 통계 확인 |
| Query Store | 특정 쿼리별, 시간대별 대기 통계를 과거 이력까지 추적 |
| 주요 Wait Type | 의미 | 해결 방향 |
|---|---|---|
| PAGEIOLATCH_* | 디스크에서 데이터 페이지를 메모리로 읽어오기를 기다림 | 인덱스 튜닝, 메모리 증설 |
| LCKM* | 다른 쿼리가 테이블/행 잠금을 잡고 있어 해제를 기다림 | 트랜잭션 최적화 |
| CXPACKET | 병렬 쿼리 처리 중 스레드 간 속도 차이로 인한 대기 | MAXDOP 설정 조정 |
Automatic tuning 및 지능형 인사이트
PaaS 서비스인 Azure SQL Database와 Managed Instance는 AI 기반 자동/추천 성능 최적화 기능을 제공한다. VM 기반 SQL은 운영자가 직접 튜닝해야 한다.
| 서비스 유형 | 지원 여부 | 주요 기능/특징 |
|---|---|---|
| Azure SQL Database (PaaS) | 기본 제공, 자동/수동 설정 | 자동 인덱스 관리, 인덱스 자동 생성/삭제, 실행 계획 비효율 발견 시 자동 롤백, 지속적 성능 분석, 튜닝 이력 제공 |
| Azure SQL Managed Instance | 기본 제공, 동일 | Azure SQL Database와 동일 |
| SQL Server on Azure VM (IaaS) | 미지원, 직접 관리 | 수동 튜닝 필수, 자동 제안/적용 기능 없음 |
고가용성 아키텍처 및 재해 복구
High Availability
Azure SQL의 고가용성 내부 구현은 서비스 계층에 따라 다르다.
| 특성 | General Purpose 계층 | Business Critical 계층 | Hyperscale 계층 |
|---|---|---|---|
| 적용 서비스 | Azure SQL Database & Managed Instance | Azure SQL Database & Managed Instance | Azure SQL Database 전용 |
| HA 설계 원칙 | 컴퓨팅/스토리지 분리 | Always On 가용성 그룹 | 분산 함수 모델, 컴퓨팅·스토리지·로그 분리 |
| 아키텍처 구성 | 스테이트리스 컴퓨팅 노드 클러스터, Azure Premium Storage, 3중 복제 스토리지 | 1개 주 복제본(RW), 3개 보조 복제본(RO), 모든 복제본 로컬 SSD 사용 | 1개 주 복제본(RW), 0~4개 HA 보조 복제본(RO), 분산 페이지 서버, 고가용성 로그 서비스 |
| 데이터 복제 방식 | 스토리지 계층에서 3중 복제(LRS/ZRS) | 동기식 복제 | 로그 서비스 및 페이지 서버를 통한 비동기 복제 |
| 장애 조치 메커니즘 | 컴퓨팅 노드 장애 시 다른 정상 노드로 연결 자동 전환 | 주 복제본 장애 시 보조 복제본 중 하나로 자동 승격 | 주 컴퓨팅 복제본 장애 시 HA 복제본 중 하나로 초고속 승격 |
| RTO | 수십 초 | 일반적으로 10초 이내 | 수 초 |
| RPO | 0, 커밋된 데이터 손실 없음 | 0, 데이터 손실 없음 | 0, 데이터 손실 없음 |
| 읽기 스케일 아웃 | 제한적 | 보조 복제본을 통한 읽기 스케일 아웃 가능 | HA 보조 복제본을 통한 읽기 스케일 아웃 가능 |
| 스토리지 유형 | 원격 Azure Premium Storage | 로컬 SSD | 분산 페이지 서버 기반 관리형 스토리지 |
| 주요 장점 | 비용 효율성, 컴퓨팅/스토리지 독립 확장성 | 높은 성능, 낮은 RTO/RPO, 미션 크리티컬 워크로드 적합 | 극대화된 확장성, 초고속 복구, 대규모 워크로드 적합 |
Availability Architectural Models
Azure SQL Database와 SQL Managed Instance는 각각 고유한 고가용성 아키텍처 모델을 제공한다.
| 서비스 | 고가용성 아키텍처 모델 |
|---|---|
| Azure SQL Database | General Purpose: 원격/로컬 저장소 분리, Business Critical: Always On/로컬 스토리지/복제, Hyperscale: 분산 스토리지·컴퓨트 계층 구조 |
| SQL Managed Instance | General Purpose: Standard Availability, Business Critical: Always On 기반 고가용성 클러스터 |
Azure SQL Database 가용성 모델
| 서비스 티어 | 고가용성 모드 | 지역 중복 가용성 | 영역간 중복 가용성 |
|---|---|---|---|
| General Purpose (vCore) | 원격 스토리지 | 예 | 예 |
| Business Critical (vCore) | 로컬 스토리지 | 예 | 예 |
| Hyperscale (vCore) | 하이퍼스케일 | 예 | 예 |
| Basic (DTU) | 원격 스토리지 | 예 | 아니오 |
| Standard (DTU) | 원격 스토리지 | 예 | 아니오 |
| Premium (DTU) | 로컬 스토리지 | 예 | 예 |
Azure SQL Managed Instance 가용성 모델
| 서비스 티어 | 고가용성 모드 | 지역 중복 가용성 | 영역간 중복 가용성 |
|---|---|---|---|
| General Purpose (vCore) | 원격 스토리지 | 예 | 예 |
| Next-gen General Purpose (vCore) - preview | 원격 스토리지 | 예 | 예 |
| Business Critical (vCore) | 로컬 스토리지 | 예 | 예 |
원격 스토리지 모델: 지역 중복 가용성
DTU 기반 Basic/Standard 계층과 vCore 기반 General Purpose 계층은 Remote Storage 가용성 모델을 사용한다. 컴퓨팅 레이어와 저장소 계층이 분리되어 있다.
Stateful한건 늘리거나 하지 않고, Stateless에 computing 가능한 부분을 두어 늘릴 수 있게 함.
예를 들자면, 홈쇼핑 데이터베이스라면 주 기능에 관한건 Stateful한 부분에, 그리고 접속이나 계산 등 computing하고 가변적으로 늘려야 하는 부분은 Stateless 사용
| 계층 | 설명 |
|---|---|
| Stateless compute layer | 데이터베이스 엔진 프로세스를 실행하는 컴퓨팅 계층. 장애 시 다른 노드로 전환 가능 |
| Stateful data layer | Azure Blob/Premium Storage에 데이터 파일과 로그 파일 저장. 원격 스토리지 기반 복제 제공 |
로컬 스토리지 모델: 지역 중복 가용성
DTU Premium 계층과 vCore Business Critical 계층은 컴퓨팅 리소스와 로컬 SSD 스토리지를 단일 노드에 통합하는 로컬 스토리지 모델을 사용한다.
- 각 컴퓨트 노드에는 데이터베이스 엔진과 로컬 SSD가 결합되어 있다.
- 주요 데이터 파일과 로그 파일이 각 노드의 로컬 SSD에 저장된다.
- Always On Availability Group을 통해 노드 간 동기화 복제를 수행한다.
- 로컬 SSD 직접 접근으로 IO 지연이 낮고 성능이 높다.
- 장애 발생 시 동기화된 Secondary 노드가 Primary로 승격된다.
로컬이 더 비싸고 빠름
원격 스토리지 모델: 영역간 중복 가용성
Zone-redundant 옵션을 사용하면 하나의 Region 내 서로 다른 가용성 영역에 컴퓨트 노드가 분산 배치된다.
| 구분 | 설명 |
|---|---|
| Remote storage model | 컴퓨트와 스토리지가 분리. 컴퓨트 노드는 stateless, 영구 데이터는 Azure Premium Storage 등에 저장 |
| Zone redundant availability | 여러 Azure Zone에 Control Ring, 노드, 스토리지 계층이 존재. 데이터와 로그는 ZRS 등 zone-redundant storage에 보관 |
| 장애 대응 | Azure Traffic Manager를 통해 정상 Zone 노드로 자동 우회 |
로컬 스토리지 모델: 영역간 중복 가용성
Premium 또는 Business Critical 계층에서 영역 중복을 사용하면 복제본이 동일 지역의 여러 가용성 영역에 배치된다.
- SPOF 제거를 위해 Control Ring이 여러 영역에 걸쳐 복제된다.
- 게이트웨이 링 라우팅은 Azure Traffic Manager가 제어한다.
- 기존 복제본을 다양한 가용성 영역에 배치하므로 추가 비용 없이 사용할 수 있다.
- 데이터센터 중단 같은 큰 장애에도 탄력적으로 복구 가능하다.
- 기존 Premium/Business Critical DB 또는 Elastic Pool을 영역 중복 구성으로 변환할 수 있다.
Automated Backups
Azure SQL 서비스별 자동 백업 방식은 다르다.
| 유형 | 자동 백업 기본 제공 | 백업 종류/주기 | 보존 기간 | 백업 저장 위치 | 추가 설정/특징 |
|---|---|---|---|---|---|
| Azure SQL Database | O, 자동 | 주 1회 전체, 12시간마다 증분, 약 10분마다 로그 | 7~35일 기본, 최대 10년 LTR 옵션 | RA-GRS | PITR, LTR 지원 |
| SQL Managed Instance | O, 자동 | 전체, 차등, 로그 | 7~35일 기본, 최대 10년 LTR | RA-GRS | PaaS 서비스의 통합 자동 백업 관리 |
| SQL on Azure VM | X, 별도 설정 필요 | 사용자 지정 | 사용자 지정 | Azure Storage, Recovery Services Vault, 외부 저장소 | SQL IaaS Agent, Azure Backup 등 설정 필요. 관리자가 주기·보존·저장소 직접 결정 |
LTR: Long Term Retention
Automated Patching
Azure SQL Database와 Azure SQL Managed Instance는 PaaS 서비스이므로 OS와 SQL 데이터베이스 엔진의 최신 보안 업데이트 및 성능 개선 패치가 자동 적용된다.
| 구분 | 내용 |
|---|---|
| Azure SQL Database / Managed Instance | OS 및 SQL 엔진 패치 자동 적용, 관리자가 별도 패치하지 않아도 최신 버전과 보안 수준 유지 |
| Managed Instance 유지 관리 기간 | 자동 패치가 적용될 주간 시간대를 선택해 단기 가용성 영향을 제어 가능 |
| Managed Instance 업데이트 정책 | Always Up-to-date 정책 또는 지연 정책 선택 가능 |
| SQL Server on Azure VM | SQL IaaS Agent Extension 등록 및 별도 설정 필요. Windows Update, 보안 패치, SQL Patch 스케줄을 관리자가 직접 구성 가능 |
Business Continuity 참고
Business Continuity는 기업의 핵심 자산, 서비스, 수익에 대한 위협을 식별하고, 주요 비즈니스 기능이 재난이나 장애 상황에서도 계속 운영될 수 있도록 하는 전략이다.
Azure SQL Database에서는 내장된 고가용성, 지역 중복, 장애 복구 기능을 통해 서비스 지속성을 보장한다. SPOF는 시스템, 네트워크, 소프트웨어 등 특정 지점 장애가 전체 시스템 중단으로 이어지는 단일 실패 지점을 의미한다.
Azure Site Recovery 참고
Azure Site Recovery는 Microsoft Azure에서 제공하는 재해 복구 서비스이다. 주요 IT 중단 발생 시에도 비즈니스 애플리케이션과 워크로드를 계속 실행하여 Business Continuity를 보장하도록 돕는다.
Geo-replication
Geo-replication은 Azure SQL Database, Managed Instance, SQL Server on Azure VM에 따라 지원 방식이 다르다.
| 서비스 계층 | 주요 Geo-replication 옵션 | 복제 방향/방식 | 페일오버/관리 특징 | 지원 및 제한 사항 |
|---|---|---|---|---|
| Azure SQL Database (PaaS) | Active Geo-replication: 최대 4개 세컨더리 지원, Failover groups: 그룹 단위 페일오버/엔드포인트 자동 전환 | 단일 DB, Elastic Pool, 그룹 단위. 단방향/읽기 전용 세컨더리 | 자동 복제, 수동/자동 페일오버 선택. Failover group으로 일괄 관리, 연결 엔드포인트 자동 생성 | PaaS라 설정/운영 간편. 서버리스, Hyperscale 등은 제한적 지원 |
| Azure SQL Managed Instance | Failover groups: 전체 인스턴스 단위 DR, Geo-replication 일부 | 인스턴스 전체/그룹 단위, 읽기/쓰기 세컨더리 | Failover group 자동/수동, 엔드포인트 리디렉션, 정책에 따른 자동 복구 | Managed Instance 전용. 일부 설정/기능 변동 가능 |
| SQL Server on Azure VM (IaaS) | Always On Availability Groups, Distributed Availability Group | VM 간 멀티 리전, 양방향 AG, 복수 세컨더리 | 쿼럼/AG 정책에 따른 페일오버. 복수 세컨더리로 로드 분산 가능. 수동/자동 다양 | IaaS 직접 구성. Windows Failover Cluster 필요, 네트워크/쿼럼 설정 직접 관리, 비용/관리 책임 |
Migration & Innovation
Migrating to Azure
Azure는 온프레미스 SQL Server, 다른 클라우드, 타 DB 등에서 Azure SQL 제품으로 안전하게 이전하기 위한 절차와 도구를 제공한다.
| 도구/방식 | 대상 플랫폼 | 주요 방식/설명 | 지원 대상/특이사항 |
|---|---|---|---|
| Azure Database Migration Service (DMS) | 온프레미스 SQL Server, 타 클라우드 DB, Oracle, MySQL 등 | 온라인/오프라인 마이그레이션, 다운타임 최소화, 스키마+데이터+보안+연결 전환 지원 | Azure SQL Database, Managed Instance, SQL Server on VM |
| Dacpac / BACPAC | 모든 SQL Server/DB | 스키마 및 데이터 옵션을 dacpac/bacpac 파일로 추출 후 신규 DB에 업로드 및 Import | 소형 또는 부분 데이터 이전에 적합 |
| Log Replay Service | 온프레미스 SQL → Managed Instance | 트랜잭션 로그 전송, 실시간 또는 순차적 로그 누적 적용 | Managed Instance 전용 |
| Managed Instance Link | 온프레미스/VM SQL Server → Managed Instance | Always On AG 기술 활용, 실시간 데이터 싱크 | Hybrid DR, 긴밀한 실시간 연동에 적합 |
| Native backup/restore | 온프레미스/VM SQL Server → Managed Instance | 백업 파일을 Azure Storage로 업로드 | 대용량, 장기 보관, 이관, 복구에 적합 |
| Distributed Availability Groups | 온프레미스 ↔ Azure VM 상 SQL Server | AG 기반 장애 복구, 저지연 클러스터, VM 간 이중화 복제, 직접적 고가용성 구성 | IaaS VM 기반 SQL 전용 |
| Azure Migrate/Arc | 대규모, 복합 자원, 하이브리드 등 다양한 환경 | 전체 인프라/워크로드 평가, 추천, 예측, DB 포함 전체 인프라 및 서비스 분석·상품 제안 | 대형·엔터프라이즈·하이브리드 환경에 적합 |
클라우드 마이그레이션: 비즈니스 드라이버 및 전략
성공적인 클라우드 마이그레이션은 기술 이동만이 아니라 명확한 비즈니스 이유를 기반으로 전략을 선택하는 과정이다.
| 단계 | 설명 |
|---|---|
| 비즈니스 목표 정의 | 클라우드 채택으로 달성하려는 상위 수준 성과 정의. 예: AI 도입, 민첩성 향상, 비용 절감, 혁신 가속화 |
| 격차 식별 | 현재 상태와 목표 수준 간 차이 분석. 성능, 확장성, 규정 준수, 아키텍처 제한 식별 |
| 비즈니스 드라이버 결정 | 파악된 격차를 메워야 하는 구체적이고 실행 가능한 이유 확정. 최적의 8R 전략 선택 기준 |
| 비즈니스 드라이버 | 마이그레이션 전략 |
|---|---|
| 중복되거나 가치가 낮은 워크로드를 용도 폐기 | Retire |
| 비즈니스 중단 최소화, 가까운 시일 내 현대화 계획 없음 | Rehost |
| 관리 부담을 줄이고 신뢰성을 높이기 위해 PaaS 솔루션과 최소한의 코드 수정 필요 | Replatform |
| 기술 부채를 줄이거나 클라우드 최적화를 위해 코드 수정 필요 | Refactor |
| 클라우드 네이티브 기능 활용을 위해 아키텍처 변경 필요 | Rearchitect |
| 운영 단순화를 위해 SaaS/AI 솔루션 필요 | Replace |
| 요구사항 충족을 위해 새로운 클라우드 네이티브 솔루션 필요 | Rebuild |
| 안정성이 필요하고 변경 사항이 없어야 함 | Retain |
Azure Cloud Migration Strategy: 8R
| 전략 | Business driver | 주요 지표 |
|---|---|---|
| Retire | 중복되거나 가치가 낮은 워크로드를 용도 폐기 | 현재 또는 미래 비즈니스 가치 제한, 마이그레이션/현대화 비용이 이점보다 큼 |
| Rehost | 비즈니스 중단 최소화, 현대화 계획 없음 | 워크로드 안정적, Azure 호환, 마이그레이션 리스크 낮음, 단기 클라우드 도입 목표, 현대화 급하지 않음, 자본 지출 절감, 데이터센터 공간 확보, Azure 경험 부족 |
| Replatform | 관리 부담 감소, 신뢰성 향상, PaaS와 최소 코드 수정 필요 | 안정성과 재해 복구 단순화, OS 및 라이선스 관리 부담 감소, 적절한 투자로 전환 시간 단축, 애플리케이션 컨테이너화 |
| Refactor | 기술 부채 감소 또는 클라우드 최적화를 위한 코드 수정 | 유지보수 비용 감소, 기술 부채 감소, Azure SDK 사용, 코드 성능 개선, 코드 비용 최적화, 클라우드 디자인 패턴 적용, 모니터링용 코드 계측 적용 |
| Rearchitect | 클라우드 네이티브 기능 활용을 위한 아키텍처 변경 | 애플리케이션 모듈화/서비스 분해 필요, 구성 요소별 확장 요구 다름, 미래 혁신 지원 필요, 기술 스택 혼재 |
| Replace | 운영 단순화를 위해 SaaS/AI 솔루션 필요 | 운영 단순화, 내부 개발 리소스를 다른 곳에 활용, 커스터마이징 필요성 적음 |
| Rebuild | 새로운 클라우드 네이티브 솔루션 필요 | 레거시 시스템이 낡거나 유연하지 않음, 더 빠른 개발/출시 필요, 운영 비용 절감, 최신 프레임워크와 도구 필요 |
| Retain | 안정성이 필요하고 변경 사항이 없어야 함 | 워크로드 안정적, 규정 준수, 비즈니스 요구 충족, 단기 이동 동인 없음, ROI 낮음 |
참고로 Gartner의 5R 이후 AWS에서는 Repurchase를 추가한 6R 및 7R이 많이 활용되며, Azure에서는 8R로 분류해 설명한다.
AWS Cloud Migration Strategy 참고
AWS 7R은 다음과 같이 시각적으로 정리된다.
| 그룹 | 전략 | 설명 |
|---|---|---|
| Sustain | Rehost | Lift and shift, Amazon EC2에 호스트 |
| Sustain | Relocate | Hypervisor-level lift and shift, 인프라를 클라우드로 이동 |
| Optimize | Replatform | Lift and reshape, 일부 클라우드 기능 활용 |
| Optimize | Repurchase | Drop and shop, 일반적으로 SaaS 제품으로 전환 |
| Grow | Refactor | Re-architect, Amazon Aurora나 DynamoDB 등 목적 기반 DB 활용 |
| 별도 판단 | Retain | 유지 |
| 별도 판단 | Retire | 폐기 |
최신 기능
Vector 데이터 지원 및 RAG 아키텍처
Azure SQL Database는 VECTOR 데이터 형식과 VECTOR_DISTANCE 함수를 지원하여 별도 벡터 DB 없이 기존 관계형 데이터와 함께 RAG 아키텍처를 구현할 수 있다.
| 구분 | 설명 |
|---|---|
| VECTOR 데이터 타입 | OpenAI 등 AI 모델이 생성한 다차원 임베딩 배열을 테이블 컬럼에 직접 저장 가능 |
| VECTOR_DISTANCE 함수 | 코사인 유사도 등을 이용해 사용자 질문과 의미가 비슷한 데이터를 SQL 쿼리로 검색 |
| 기존 문제 | RDBMS 데이터와 벡터 DB가 분리되어 데이터 동기화 및 조인 분석이 어려움 |
| 해결 방식 | Azure SQL 하나에서 일반 데이터 필터링과 의미론적 벡터 검색을 동시에 수행. RLS 정책도 유지 가능 |
JSON Native Support
기존에는 JSON을 NVARCHAR 문자열 컬럼에 담아 처리했지만, JSON 타입으로 처리하면서 성능 개선이 가능해졌다.
| 항목 | 개선 내용 |
|---|---|
| Total Storage Footprint | 약 82% 감소 |
| Data I/O | 약 80% 감소 |
| Query Execution | 약 2.5~4배 빠름 |
| Throughput | 약 20~40배 증가 |
| CPU Usage | 약 27% 감소 |
| Logical Reads | 쿼리 실행당 약 80% 감소 |
| 예시 저장 공간 | 사용량이 5.94GB 수준에서 1.06GB 수준으로 감소한 비교 화면 제시 |
Fabric Mirrored Databases 연동
Azure SQL은 Microsoft Fabric의 Mirrored Database와 연결된다. 포털에서 미러링을 켜면 Azure SQL 데이터가 Fabric OneLake에 실시간에 가깝게 Delta 포맷으로 복제된다.
| 특징 | 설명 |
|---|---|
| Zero-ETL | 복잡한 파이프라인 개발 없이 버튼 클릭만으로 연동 |
| Near Real-time | Insert, Update, Delete 변경분을 실시간에 가깝게 증분 복제 |
| Delta Parquet | 분석에 최적화된 개방형 포맷으로 자동 변환 저장 |
| 성능 격리 | 원본 운영 DB 성능 저하 없이 OLAP 분석 가능 |
사례
Azure Virtual Machines의 SQL Server 사례: Allscripts
Allscripts는 의료 서비스 소프트웨어 제조업체이다. 애플리케이션을 안전하고 안정적으로 호스트하기 위해 Azure로 빠르게 이동하려 했고, Azure Site Recovery를 사용해 약 1,000개의 VM에서 실행 중이던 애플리케이션 수십 개를 3주 만에 Azure로 마이그레이션했다.
| 구분 | 내용 |
|---|---|
| 고객 과제 | 애플리케이션을 자주 변환하고 안정적으로 호스트해야 함 |
| 선택 서비스 | Azure Virtual Machines의 SQL Server |
| 주요 도구 | Azure Site Recovery |
| 결과 | 약 1,000개 VM 기반 애플리케이션을 빠르게 Azure로 이동 |
Azure SQL Managed Instance 사례: Komatsu
Komatsu는 건설용 중장비 제조 회사로, 여러 메인프레임 애플리케이션의 다양한 데이터를 통합적으로 파악하고 오버헤드를 줄이고자 했다. SQL Server 기능 호환성이 중요했기 때문에 Azure SQL Managed Instance를 선택했다.
| 구분 | 내용 |
|---|---|
| 고객 과제 | 여러 메인프레임 애플리케이션 통합, 관리 오버헤드 절감 |
| 선택 서비스 | Azure SQL Managed Instance |
| 이전 데이터 | 약 1.5TB |
| 주요 혜택 | 자동 패치, 버전 업데이트, 자동 백업, 고가용성, 관리 오버헤드 절감 |
| 결과 | 약 49% 비용 절감, 약 25~30% 성능 향상 |
Azure SQL Database 사례: AccuWeather
AccuWeather는 날씨 분석 및 예측 기업으로, 빅데이터, 머신러닝, AI 기능을 활용하기 위해 Azure를 선택했다. 데이터베이스 관리보다 모델과 애플리케이션 구축에 집중하고자 SQL Database를 Azure Data Factory, Azure Machine Learning 등과 함께 사용했다.
| 구분 | 내용 |
|---|---|
| 고객 과제 | 기상 분석 및 예측 기능을 강화하고 빅데이터/AI 기능 활용 필요 |
| 선택 서비스 | Azure SQL Database |
| 연계 서비스 | Azure Data Factory, Azure Machine Learning |
| 목적 | 매출 및 고객 예측을 위한 내부 애플리케이션 빠른 배포 |
| 주요 장점 | 관리 부담 감소, 확장성, 최신 클라우드 서비스와의 연계 |
전체 정리
Azure SQL은 SQL Server 엔진을 기반으로 한 Azure의 통합 데이터베이스 제품군이다. Azure SQL Database, Azure SQL Managed Instance, SQL Server on Azure VM은 각각 관리 수준, 호환성, 제어 범위가 다르며, 워크로드 특성에 따라 선택해야 한다.
PaaS 기반의 Azure SQL Database와 Managed Instance는 자동 패치, 자동 백업, 고가용성, 보안, 성능 모니터링, 자동 튜닝을 제공한다. 특히 Serverless, Elastic Pool, Hyperscale, Private Link, Entra ID 인증, Ledger, Vector, Fabric Mirroring 등 최신 기능을 통해 운영 부담을 줄이면서 확장성과 보안성을 강화할 수 있다.
마이그레이션 관점에서는 DMS, BACPAC, Log Replay Service, Managed Instance Link, Native backup/restore, Azure Migrate/Arc 등 다양한 도구를 제공한다. 클라우드 이전 전략은 Retire, Rehost, Replatform, Refactor, Rearchitect, Replace, Rebuild, Retain의 8R 관점에서 비즈니스 목표와 워크로드 특성에 맞게 선택해야 한다.
한 줄 요약
Azure SQL은 SQL Server 기반 워크로드를 Azure에서 운영하기 위한 통합 데이터베이스 플랫폼이며, 서비스 유형별로 관리 책임과 호환성, 확장성, 보안 기능이 다르므로 워크로드 특성에 맞는 선택이 중요하다.
실습
Azure SQL 생성