
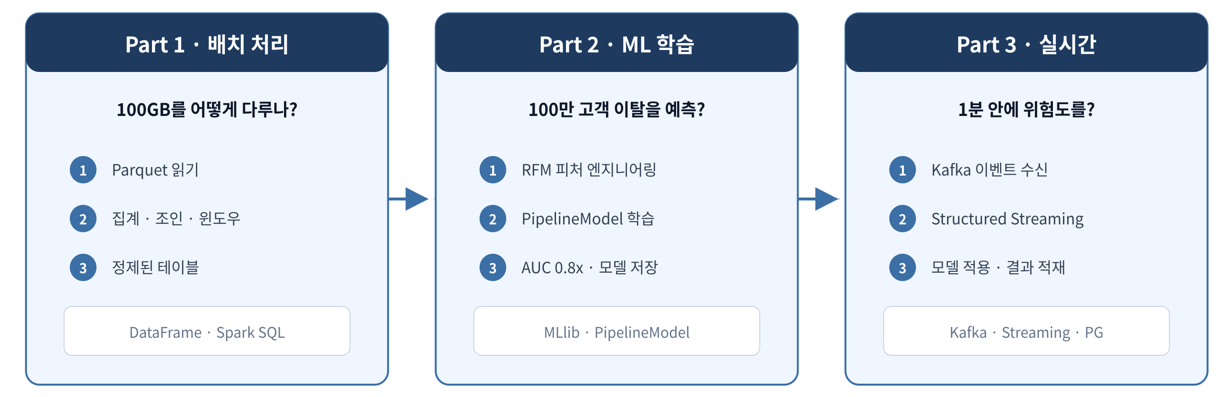
사용하게되는 배경
- 데이터가 너무 커진 경우 → 배치 처리
- sklearn으로는 학습이 안끝나 분산 ML이 필요한 경우 → ML 파이프라인
- 실시간(1분내)로 보고받고 싶은 경우 → 스트리밍
1. 배치처리
분산 처리
| 구분 | 단일 서버 | 분산 처리 |
|---|---|---|
| 구조 | 고사양 서버 1대 사용 | 여러 대의 서버를 묶어 처리 |
| 데이터 처리 | 메모리 부족 시 전체 데이터 적재 어려움 | 데이터를 여러 노드에 분산 저장 |
| 확장 방식 | 수직 확장 (CPU/메모리 증설) | 수평 확장 (노드 추가) |
| 장애 대응 | 서버 1대 장애 시 전체 중단 위험 | 일부 노드 장애 시 다른 노드가 대체 |
| 비용 구조 | 고사양 서버 비용 급증 | 일반 서버 여러 대로 비용 효율 |
| 재시작 비용 | 처음부터 다시 읽어야 함 | 캐시 및 분산 저장 활용 가능 |
| 예시 | 16코어 / 64GB 서버 1대로 100GB 처리 | 8코어 서버 10대로 데이터 분산 처리 |
Spark 아키텍처
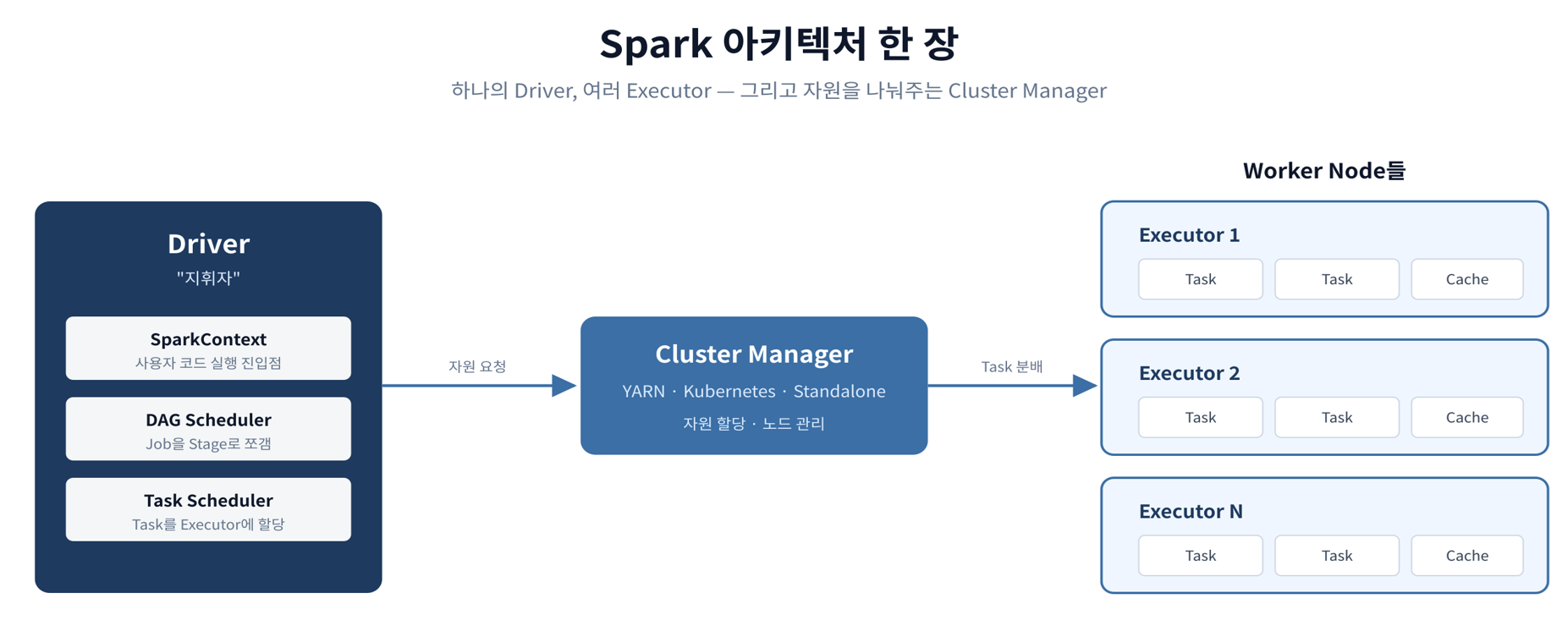
Driver은 1개, Worker Node는 여러개. 작업이 끝나면 Worker Node는 자원을 반납
핵심 추상화
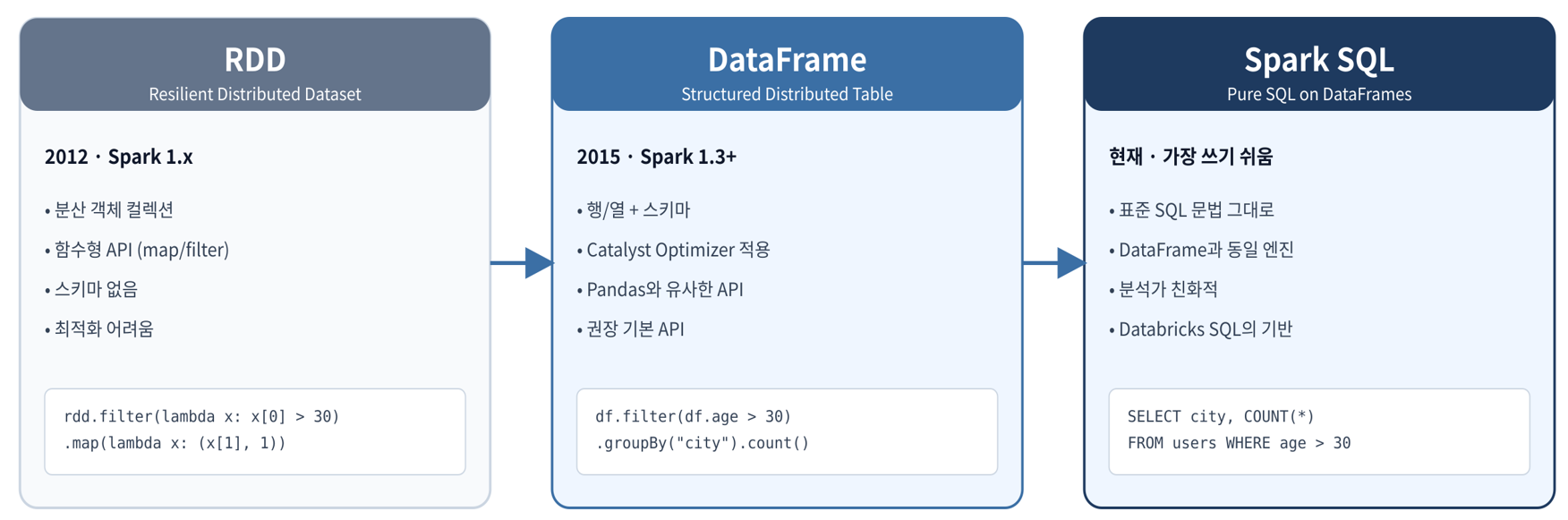
Pandas, DF, SQL
| 비교 항목 | Pandas | Spark DataFrame | Spark SQL |
|---|---|---|---|
| 실행 환경 | 단일 서버 메모리 | 여러 노드 분산 | 여러 노드 분산 |
| 처리 한계 | 수 GB | 수십 ~ 수백 TB | 수십 ~ 수백 TB |
| 문법 친밀도 | 매우 높음 (Python) | Pandas와 유사 | SQL 기반, 분석 친화 |
| 최적화 | 수동 | 자동 (Catalyst) | 자동 (Catalyst) |
| 대화형 분석 | Jupyter 최적 | Notebook 가능 | BI 도구와 직접 연결 |
지연 실행(Lazy Evaluation)
Spark에서는 Transformation 연산을 수행한다고 해서 즉시 데이터 처리가 실행되지 않는다.
filter(), select(), groupBy(), join(), orderBy() 와 같은 연산은 실제 계산을 수행하는 것이 아니라, 어떤 작업을 수행할지에 대한 실행 계획만 생성한다.
df = spark.read.parquet('orders/')
df2 = df.filter(df.amount > 100)
df3 = df2.groupBy('city').count()
df4 = df3.orderBy('count', desc=True)이 과정에서는 실제로 데이터 파일을 읽거나 계산하지 않는다.
Spark는 단지 “데이터를 읽고 → 필터링하고 → 그룹화하고 → 정렬한다” 라는 작업 흐름(DAG, Directed Acyclic Graph)만 내부적으로 구성한다.
즉, 위 코드는 실행 계획만 수립한 상태이며, 아직 클러스터 자원도 거의 사용하지 않는다.
실제 실행은 Action 연산이 호출되는 순간 발생한다.
df4.show(20)show()가 실행되는 시점에 Spark는 지금까지 쌓아둔 Transformation 작업들을 하나의 최적화된 실행 계획으로 구성한 뒤 한 번에 수행한다.
이때 Spark 내부에서는 다음과 같은 작업이 실제로 실행된다.
- 데이터 읽기(read)
- filter 수행
- groupBy 집계
- 정렬(sort)
- limit 처리
이처럼 Spark는 필요한 순간까지 실행을 미루었다가(Action 호출 시점) 최적화된 형태로 한 번에 처리하는데, 이를 지연 실행(Lazy Evaluation) 이라고 한다.
대표적인 Action 연산
show()collect()count()first()take()foreach()toPandas()write.parquet()write.format()
Spark UI 읽는 법
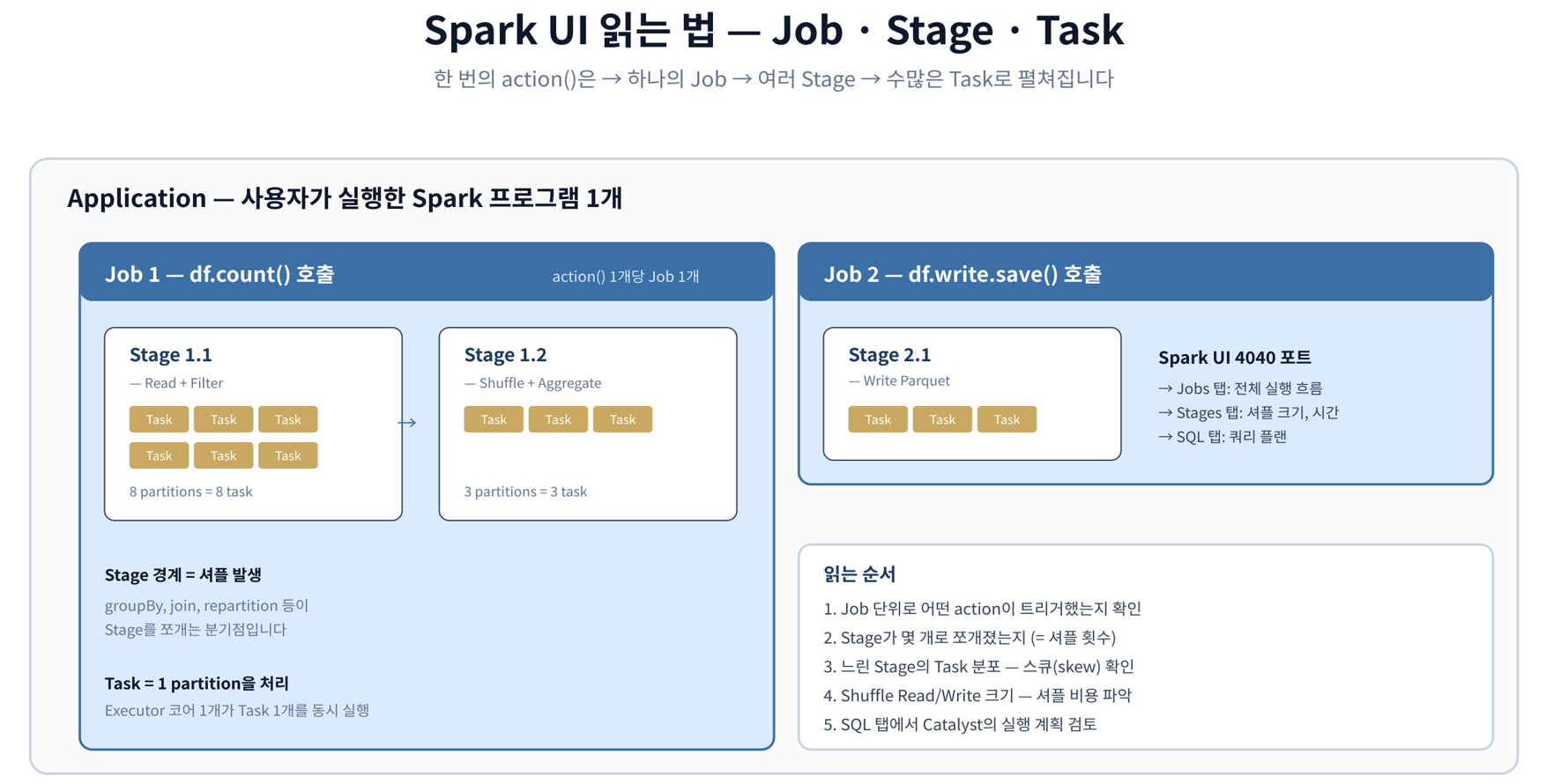
실습 순서
- Parquet 읽고 스키마 확인
transactions.parquet 5M 행 읽기, printSchema(), describe()
- 집계와 groupBy
고객별 거래 횟수, 지역별 매출 합계 — DataFrame API와 SQL을 같은 결과로 비교
- 조인과 윈도우 함수
customers ⋈ transactions, 고객별 누적 매출 랭킹 — Window.partitionBy()
- Spark UI 분석
방금 돌린 쿼리의 Job/Stage/Task 확인, 셔플 크기, 쿼리 플랜 읽기
자주 발생하는 문제
작은 파일 문제
Kafka 적재 결과를 그대로 Parquet으로 저장하면 수만 개의 작은 파일이 생깁니다. 다음 배치 작업의 메타데이터 로딩이 데이터 처리보다 오래 걸리는 사태가 발생합니다.
→ 해법: coalesce(N) 또는 OPTIMIZE/compaction
셔플(shuffle) 과다
groupBy, join, repartition은 네트워크로 데이터를 재분배합니다. 1TB 셔플 = 1TB 네트워크 트래픽 + 디스크 IO. 가장 비싼 연산입니다.
→ 해법: 셔플 전 filter로 데이터 줄이기, 적절한 partition 수
broadcast join을 안 쓸 때
작은 테이블(< 100MB)과 큰 테이블을 join할 때 broadcast hint를 안 주면 양쪽 모두 셔플됩니다.
→ 해법: broadcast(small_df) 명시 또는 spark.sql.autoBroadcastJoinThreshold 조정
ML 파이프라인
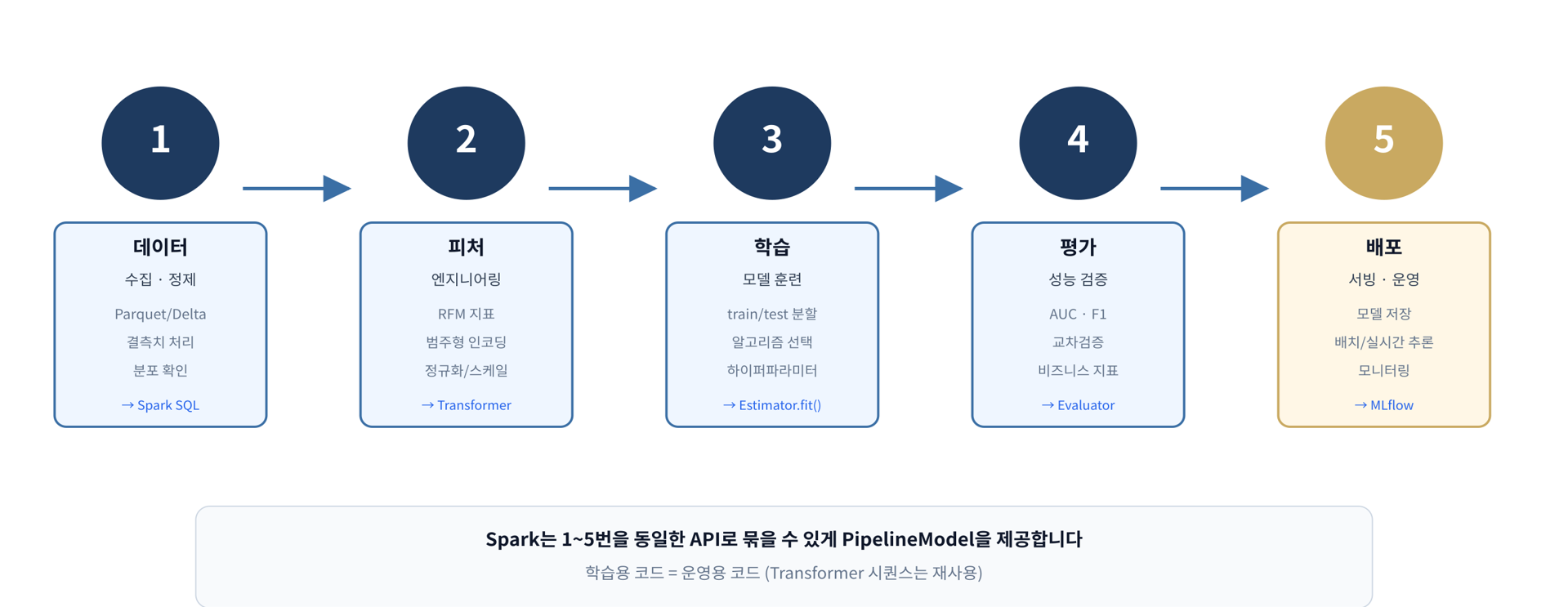
sklearn이 아닌 Spark MLlib를 쓰는 이유
안되는 순간이 온다.

PipelineModel
Transformer는 변환, Estimator는 학습. 둘을 합쳐서 PipelineModel
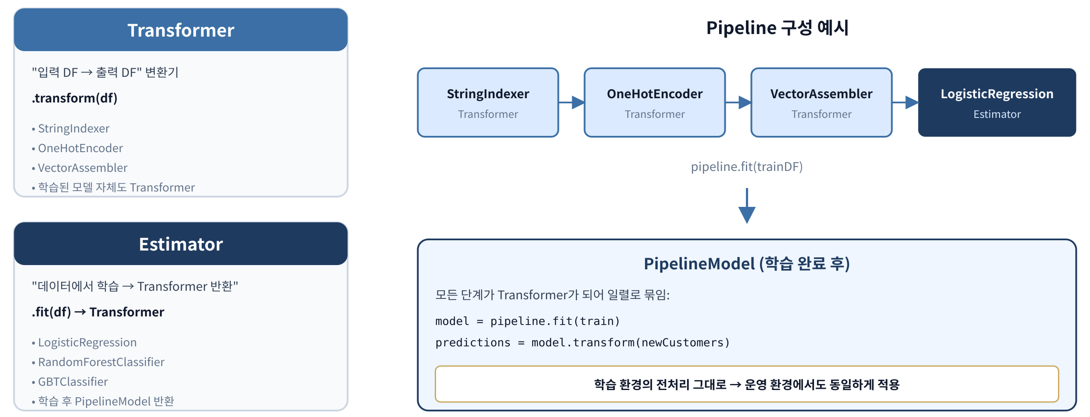
범주형 처리 - StringIndexer + OneHotEncoder

- StringIndexer만 쓰면
서울=0, 부산=1, 대구=2가 되어 모델이 대구 > 서울이라고 잘못 학습
handelInvalid='keep'
학습에 없던 카테고리가 운영에서 들어와도 모델이 죽지 않도록 하는 옵션

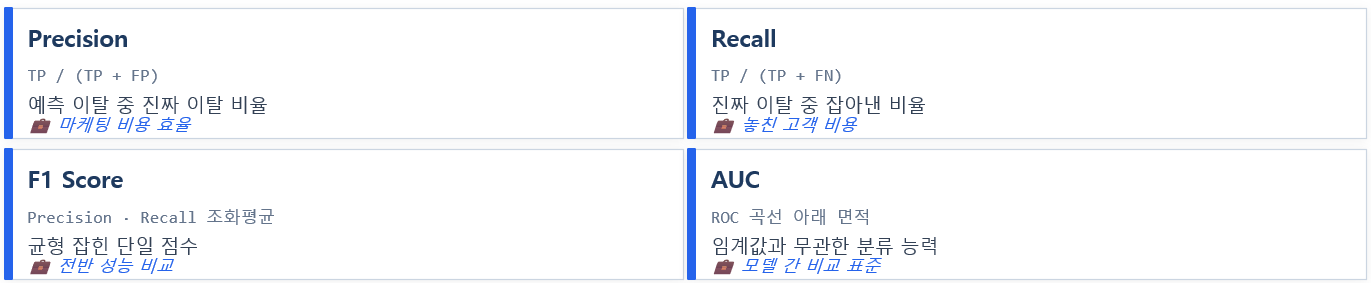
모델 평가 지표
모델 저장과 로드
노트북에서 학습한 모델을 다른 곳에서 쓰는 방법
학습 환경 (노트북/GPU 클러스터)
# 학습 후 저장
pipeline = Pipeline(stages=[...])
model = pipeline.fit(trainDF)
# 디스크/스토리지에 저장
model.write().overwrite() \
.save('s3://models/churn/v1')
# 또는 MLflow 레지스트리
mlflow.spark.log_model(model)
- 모든 Transformer + Estimator 상태 저장
- 학습한 인덱싱 사전, 가중치, 분기 규칙 모두
- MLflow 사용시 버전 관리 자동
서빙 환경 (실시간 추론 클러스터)
# 운영 환경에서 로드
from pyspark.ml import PipelineModel
model = PipelineModel.load(
's3://models/churn/v1'
)
# 새 데이터에 그대로 적용
predictions = model.transform(newCustomers)
predictions.select('id', 'prediction').show()
- 학습 코드의 전처리 그대로 재현됨
- 환경만 다르면 됨 — 코드는 동일
- Part 3 스트리밍에서도 그대로 사용
실시간 스트리밍 - Kafka + Structured Streaming

배치 Batch
특징
- 데이터를 모아서 한 번에 처리
- 처리량 지연: 분~시간 단위
- 처리량이 크고 비용 효율적
- 데이터 경계가 명확 (시작/끝)
언제 쓰나
- 일배치 리포트, 월말 정산, ML 학습
- "어제까지의 데이터로 OK"인 경우
- DataFrame · spark.read.parquet()
스트리밍 Streaming
특징
- 데이터가 도착하는 즉시 처리
- 지연: 초~분 단위
- 24시간 무중단, 운영 부담
- 데이터 경계가 모호 (스트림은 끝이 없음)
언제 쓰나
- 실시간 추천, 이상 탐지, 알림
- "지금 막 일어난 일에 반응" 필요
- spark.readStream.format("kafka")
Lambda 아키텍처
배치의 정확성 + 스트리밍 즉시성

Kafka
분산 메시지 큐의 표준

필요한 이유
DB에 직접 쓰면 안되는 이유
제공해주신 이미지 속에 적힌 텍스트를 그대로 추출하여 정리해 드립니다.
1. 트래픽 흡수
Peak 시점 보호
광고 폭주, 이벤트로 초당 트래픽이 10배 뛰어도 Kafka가 흡수.
Consumer는 자기 속도로 처리.
DB가 죽지 않음
2. 데이터 내구성
재처리 가능
메시지는 디스크에 저장 Consumer 장애 시 처음부터 재처리.
일주일 전 데이터도 다시 읽기 가능.
데이터 손실 없음
3. 다중 소비자
Pub/Sub
한 번 적재한 데이터를 Spark Streaming, 알림 시스템, 분석 DB가 각자 독립 소비.
Producer는 누가 읽는지 몰라도 됨.
소비자 추가 자유
4. 비동기 분리
느슨한 결합
Producer와 Consumer가 같은 시간에 살 필요 없음.
Consumer가 잠시 죽어도 Producer는 계속 발행.
시스템 독립성
Structured Streaming
실시간 스트림 = 무한히 자라는 테이블.
그 테이블에 대한 SQL은 짧은 주기로 다시 실행됩니다.

체크포인트와 멱등성
Checkpoint
Spark가 처리 상태를 디스크에 주기 저장
query = df.writeStream \
.option(
'checkpointLocation',
's3://checkpoints/job1/'
) \
.start()
저장되는 것
- 어디까지 처리했는가 (Kafka offset)
- 진행 중이던 집계 상태
- 메타데이터 로그
재시작 시 정확히 그 지점부터 이어서 처리
멱등성 (Idempotency)
같은 메시지가 두 번 와도 결과 같게 만들기
왜 필요한가
Kafka는 "at-least-once" 보장. 장애 복구 시 같은 메시지가 두 번 처리될 수 있음.
멱등 적재 패턴
- Primary Key 기반 upsert (MERGE)
- Delta Lake MERGE INTO 활용
- 메시지 ID로 중복 제거
Checkpoint + 멱등 = effectively exactly-once
실습
Docker로 Kafka 띄우기 Producer 만들기 Topic 설계 Partition 실험
Structured Streaming 첫 쿼리 JSON 파싱 윈도우 집계 trigger 비교
Part 2의 PipelineModel 로드 실시간 추론 PostgreSQL 멱등 적재
프로듀서 강제 종료 체크포인트 복구 검증 exactly-once 확인
환경 준비
- azure portal에서 vm 생성
- 쉘에서 ssh로 접속
- 가상머신에 라이브러리 설치
APT (Advanced Package Tool): Debian/Ubuntu 계열 패키지 관리자. apt update로 패키지 목록 갱신, apt upgrade로 실제 업그레이드.OpenJDK 17: 오라클 JDK의 오픈소스 구현. Spark 3.5.x는 Java 8/11/17 공식 지원.JDK vs JRE: JDK = JRE + 컴파일러/디버거. 개발용은 JDK, 실행만 한다면 JRE. Spark도 PySpark 호출 시 내부적으로 JVM 실행이 필요하므로 JDK 권장.PEP 668 (Externally Managed Environment): Ubuntu 23.04부터 시스템 Python에 pip install을 직접 막는 정책. 시스템 패키지(apt)와 pip 패키지 충돌로 인한 OS 손상 방지가 목적. 해결책은 venv 가상환경 사용 (권장) 또는 --break-system-packages 플래그 (비권장).
sudo apt update && sudo apt upgrade -y
sudo apt install -y openjdk-17-jdk
sudo apt install -y python3-pip python3-venv python3-full wget curl
python3 -m venv ~/sparkenv
source ~/sparkenv/bin/activateSpark 설치
Apache Spark: 분산 데이터 처리 엔진. 메모리 기반 연산으로 Hadoop MapReduce 대비 빠름. SQL/스트리밍/ML/그래프 통합 API 제공.Spark 3.5.8: 3.5 LTS 라인의 최신 maintenance 릴리스 (2027.11까지 보안 패치). Java 17 정식 지원.Hadoop3 prebuilt: Spark는 Hadoop의 HDFS 클라이언트 라이브러리를 사용해 다양한 스토리지(S3, ADLS 등) 접근. bin-hadoop3 패키지는 Hadoop 3.x 라이브러리가 포함된 사전 빌드 버전 → 별도 빌드 불필요.Standalone 모드: Spark 자체 클러스터 매니저. 본 핸즈온은 단일 노드에서 standalone(또는 local) 모드로 동작./opt: Linux 전통적으로 third-party 애플리케이션 설치 디렉터리. /usr/local도 가능하나 /opt가 더 격리적.
cd ~
wget https://dlcdn.apache.org/spark/spark-3.5.8/spark-3.5.8-bin-hadoop3.tgz
tar -xzf spark-3.5.8-bin-hadoop3.tgz
sudo mv spark-3.5.8-bin-hadoop3 /opt/spark
sudo chown -R azureuser:azureuser /opt/spark
rm spark-3.5.8-bin-hadoop3.tgz📂 리눅스 주요 디렉토리 구조
1. /opt (Optional)
- 의미: 추가적인 독립 소프트웨어 패키지가 설치되는 곳입니다.
- 용도: 시스템 기본 패키지 관리자(apt)가 관리하지 않는, 외부 서드파티 애플리케이션(예: Google Chrome, 전용 데이터베이스, 특정 벤더의 도구 등)이 설치됩니다.
- 특징: 보통 한 프로그램이 하나의 하위 디렉토리에 모든 파일(bin, lib 등)을 통째로 가지고 있는 경우가 많습니다.
2. /var (Variable)
- 의미: 시스템 운영 중 내용이 시시각각 변하는 파일들이 저장되는 곳입니다.
- 용도: */var/log: 시스템 및 애플리케이션의 로그 파일 (가장 자주 확인하게 되는 곳).
- /var/lib: 데이터베이스나 패키지 상태 정보.
- /var/spool: 메일이나 인쇄 대기열.
- 특징: 용량이 계속 늘어날 수 있는 데이터가 많아, 서버 구축 시 별도의 파티션으로 분리하기도 합니다.
3. /etc (Et cetera / Editable Text Configuration)
- 의미: 시스템 전체의 설정 파일(Configuration files)이 들어있는 곳입니다.
- 용도: 네트워크 설정, 사용자 비밀번호 파일, 설치된 프로그램의 설정값(.conf) 등이 위치합니다.
- 특징: 텍스트 파일로 되어 있어 관리자가 직접 수정할 수 있습니다.
4. /usr (Unix System Resources)
- 의미: 사용자가 실행하는 대부분의 프로그램과 읽기 전용 데이터가 들어있습니다.
- 용도: */usr/bin: 일반 사용자가 실행하는 실행 파일.
- /usr/local: 사용자가 소스 코드로 직접 빌드해서 설치한 프로그램이 위치하는 곳 (/opt와 유사하지만 더 전통적인 방식).
| 폴더 | 주요 내용물 | 비유 |
|---|---|---|
| /bin | 기본적인 필수 실행 명령 (ls, cp, mv) | 생존을 위한 필수 도구 |
| /etc | 시스템 설정 파일 | 기기 환경 설정 메뉴 |
| /home | 일반 사용자들의 개인 폴더 | 각자의 개인 사물함 |
| /opt | 서드파티 전용 소프트웨어 | 별도로 설치한 전문 장비 |
| /root | 최고 관리자(root) 전용 홈 폴더 | 관리자의 개인실 |
| /tmp | 임시 파일 | 쓰고 버리는 메모지 |
| /var | 로그, 캐시 등 가변 데이터 | 계속 기록되는 일기장/장부 |
Windows와 Linux 경로 비교
| Windows 항목 | Linux 경로 | 설명 |
|---|---|---|
| C:\Windows | /boot, /lib, /bin | 운영체제 핵심 파일들이 분산 저장됨 |
| C:\Program Files | /usr/bin, /opt | 프로그램 실행 파일 및 외부 설치 앱 |
| C:\Users\Jay | /home/jay | 사용자의 개인 파일, 설정, 바탕화면 등 |
| C:\Windows\System32\config | /etc | 시스템 전체 설정 (레지스트리 대신 텍스트 파일 사용) |
| AppData\Local\Temp | /tmp | 임시 파일 저장소 (재부팅 시 보통 삭제됨) |
환경변수 설정
nano ~/.bashrc파일 맨 아래에 추가
# ===== Apache Spark =====
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
export SPARK_HOME=/opt/spark
export PYSPARK_PYTHON=python3
# Python venv 자동 활성화
source ~/sparkenv/bin/activate
# Python venv 활성화 후 path 추가
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin#적용
source ~/.bashrcSpark Shell 실행
spark-shell --master "local[2]" --driver-memory 2g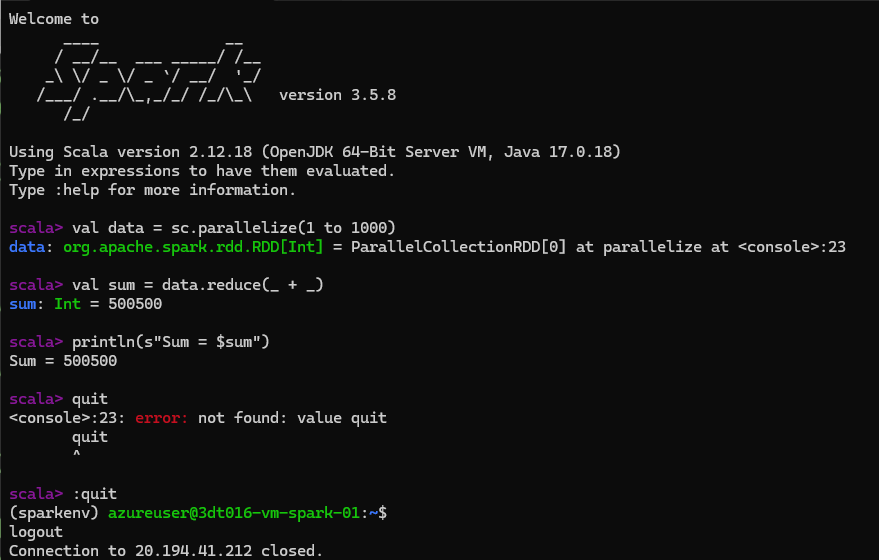
PySpark
pyspark --master "local[2]" --driver-memory 2g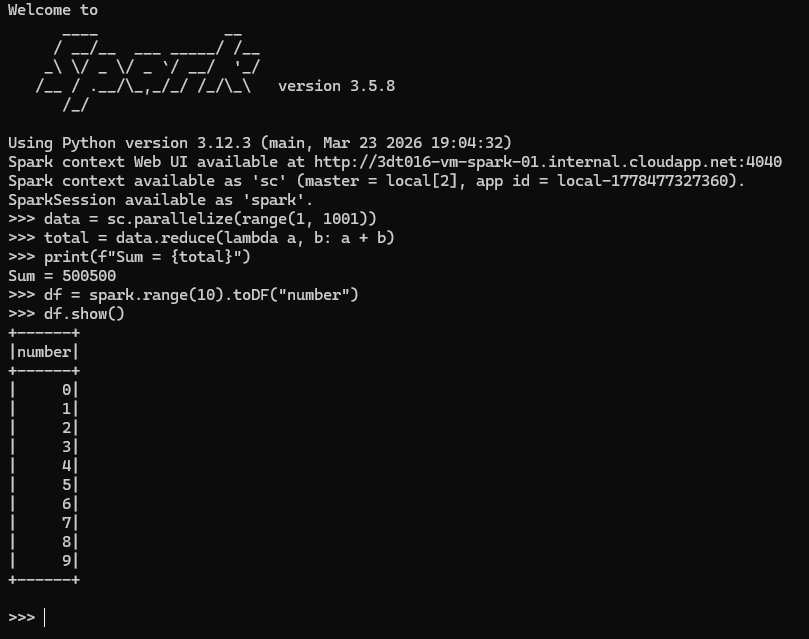
SparkPi
spark-submit \
--master "local[2]" \
--driver-memory 2g \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.5.8.jar \
100jupyter lab 연동
Jupyter Lab: 노트북 기반 인터랙티브 개발 환경. 코드/마크다운/시각화를 셀 단위로 실행.포트 8888: Jupyter Lab 기본 포트. Azure NSG에서 별도 허용 필요.SSH 터널링 (권장): Jupyter 포트를 외부에 직접 노출하지 않고, SSH 채널을 통해 로컬 PC의 포트로 포워딩. 보안적으로 안전.
설치
pip install --upgrade pip
pip install jupyterlab pyspark==3.5.8 pandas matplotlib참고: pyspark==3.5.8 은 /opt/spark 설치본과 별도로 Python에서 import 가능하도록 PyPI 패키지 설치. 두 버전이 일치해야 충돌 없음.
실행(8888 터널링)
jupyter lab --no-browser --ip=0.0.0.0 --port=8888이후 token 부분 복사
새 로컬 쉘에서 실행
ssh -L 8888:localhost:8888 azureuser@<VM_PUBLIC_IP>이후 http://localhost:8888/lab?token=<위에서_복사한_토큰> 접속

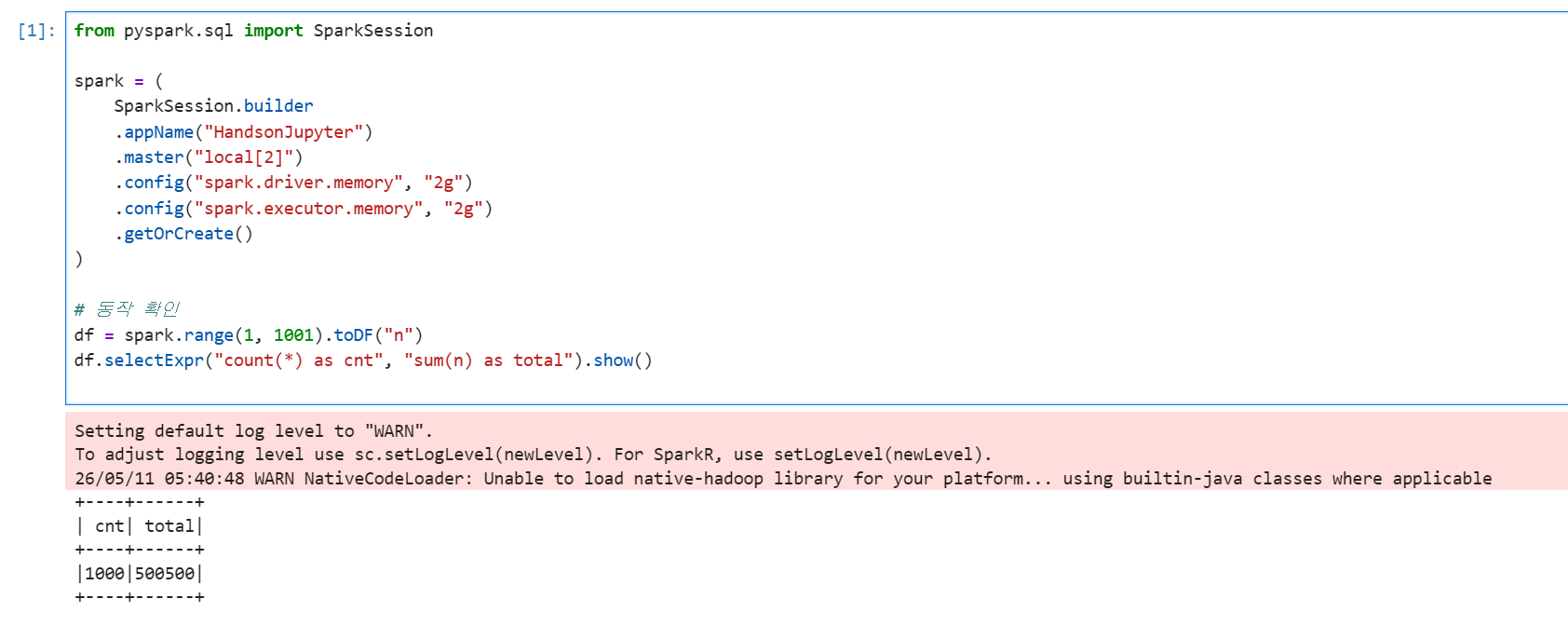
메모리 설정
spark.driver.memory: 드라이버 JVM 힙 크기. SparkContext가 사용. collect()로 큰 결과를 가져올 때 이 값이 부족하면 OOM.spark.executor.memory: 익스큐터 JVM 힙 크기. 실제 task 실행 메모리. 단일 노드 local 모드에선 driver와 executor가 같은 JVM이라 driver memory만 의미 있음. standalone/YARN/K8s 클러스터에선 별개.spark.driver.maxResultSize: collect() 결과 최대 크기. 기본 1g. 초과 시 abort.JVM 오버헤드: 힙 크기 외에 메타스페이스, 코드 캐시, GC 등 추가 메모리 (보통 힙의 10~15%).OS 점유: Ubuntu + 시스템 데몬 = 약 600MB~1GB.
cp $SPARK_HOME/conf/spark-defaults.conf.template $SPARK_HOME/conf/spark-defaults.conf
nano $SPARK_HOME/conf/spark-defaults.conf밑에 추가
spark.driver.memory 3g
spark.driver.maxResultSize 1g
spark.sql.shuffle.partitions 4데이터 정제와 머신러닝
합성 데이터 생성: Faker + Spark로 현실적인 더티 데이터 만들기
EDA & 정제: 결측/중복/이상치/일관성 문제를 PySpark로 처리
피처 엔지니어링: 두 테이블 join, 집계, 타겟 변수 생성
분류 ML: Pipeline API로 고객 이탈 예측 모델 구축 및 평가
회귀 ML (보너스): 거래액 예측 모델
Faker: Python의 가짜 데이터 생성 라이브러리. 이름·주소·이메일·날짜 등 현실적인 더미 데이터 생성. 학습/테스트용 데이터 제작에 표준.합성 데이터 (Synthetic Data): 실제 데이터를 모방해 생성한 인공 데이터. 개인정보 우려 없이 ML 학습/테스트 가능.Parquet: 컬럼 지향(Columnar) 압축 포맷. CSV 대비 1) 압축률 5~10배, 2) 스키마 보존, 3) 컬럼 단위 읽기 가능 → Spark 표준 포맷.dirty data 주입: 학습용 데이터에 의도적으로 결측·중복·이상치를 섞는 기법. 정제 실습에 필수.
추가 라이브러리 설치
source ~/sparkenv/bin/activate
pip install faker
합성데이터 생성
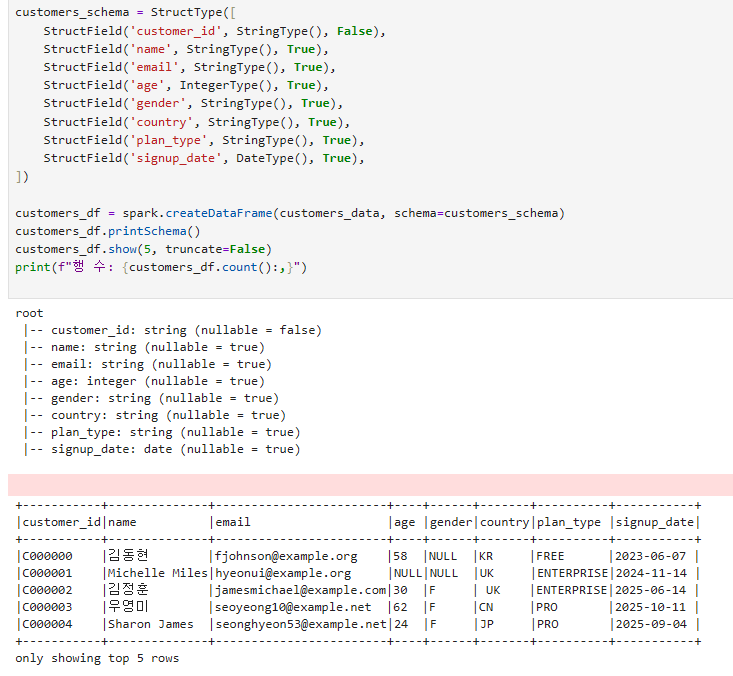
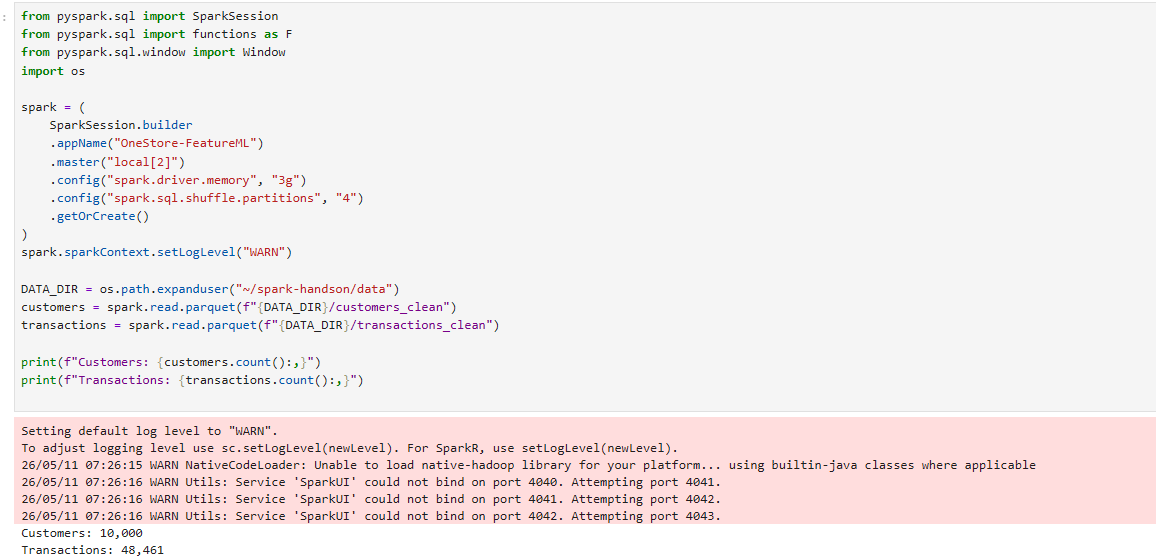
SparkSession.createDataFrame(): Python 리스트/Pandas DataFrame을 Spark DataFrame으로 변환. driver 메모리 사용하므로 대용량은 부적합.schema 명시: StructType으로 스키마 명시 → 자동 추론보다 빠르고 정확.Spark 데이터 타입: IntegerType, LongType, StringType, TimestampType, DoubleType, BooleanType 등.결측 표현: Spark는 None (Python) → null (Spark)로 변환. NumPy의 NaN과 다름 주의..write.mode("overwrite").parquet(): 기존 디렉터리 덮어쓰기. mode("append")는 추가, mode("error")는 기본값.
SparkSession 생성

데이터 생성

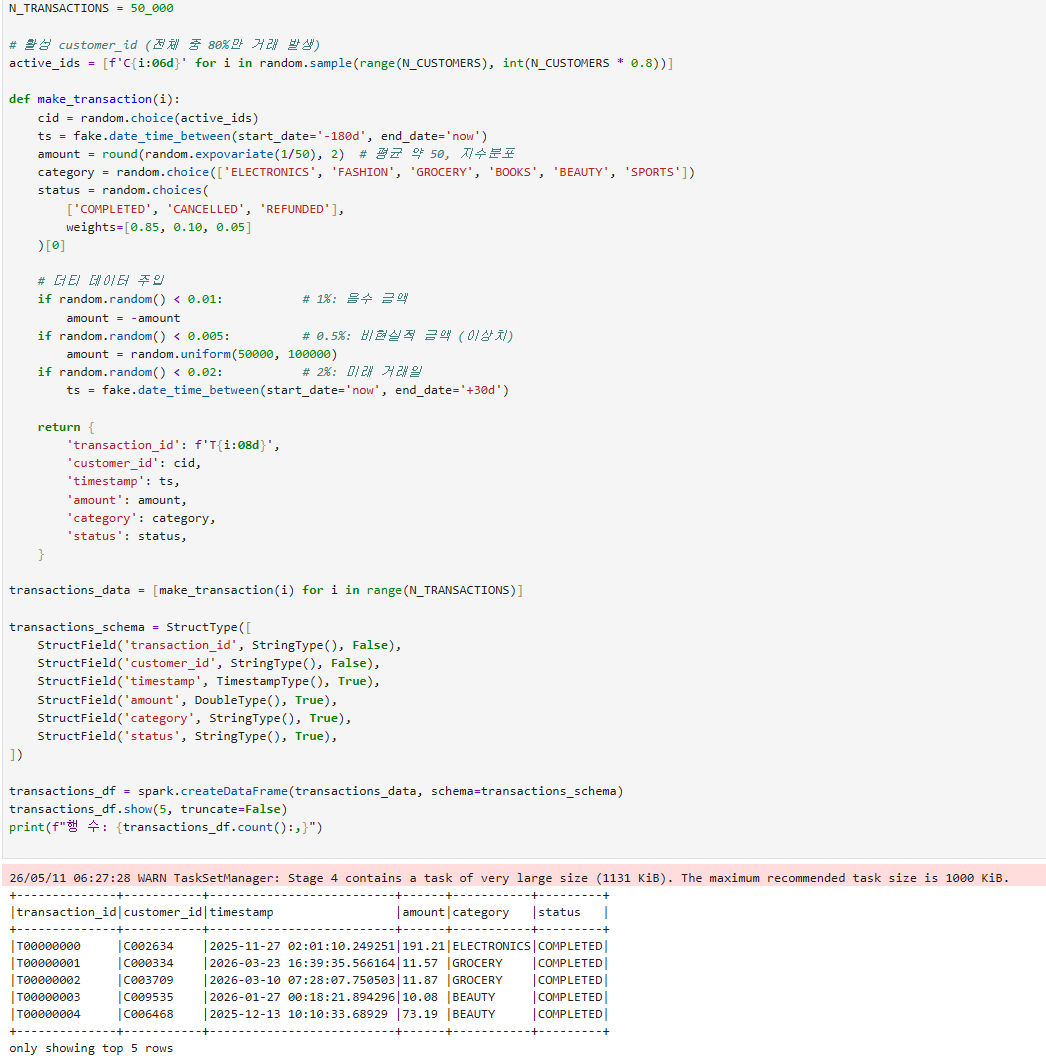
경고가 뜬다면, 이유:
- Spark는 driver의 데이터를 task로 보낼 때 직렬화해서 워커에 전송
- 50,000개 transaction을 Python 리스트로 만들어 createDataFrame에 넘기면 driver가 통째로 직렬화
- 그 직렬화 페이로드가 1131 KiB > Spark 권장값 1000 KiB
큰 문제 아니나 해결하려면, partition을 명시적으로 나눠서 만들면 됩니다:
# 기존 방식 (driver가 한 덩어리로 전송)
transactions_df = spark.createDataFrame(transactions_data, schema=transactions_schema)# 개선 방식 (4개 partition으로 분할 전송)
transactions_rdd = spark.sparkContext.parallelize(transactions_data, numSlices=4)
transactions_df = spark.createDataFrame(transactions_rdd, schema=transactions_schema)numSlices=4로 데이터를 4등분해서 보내므로 각 task ~283 KiB로 줄어듭니다.
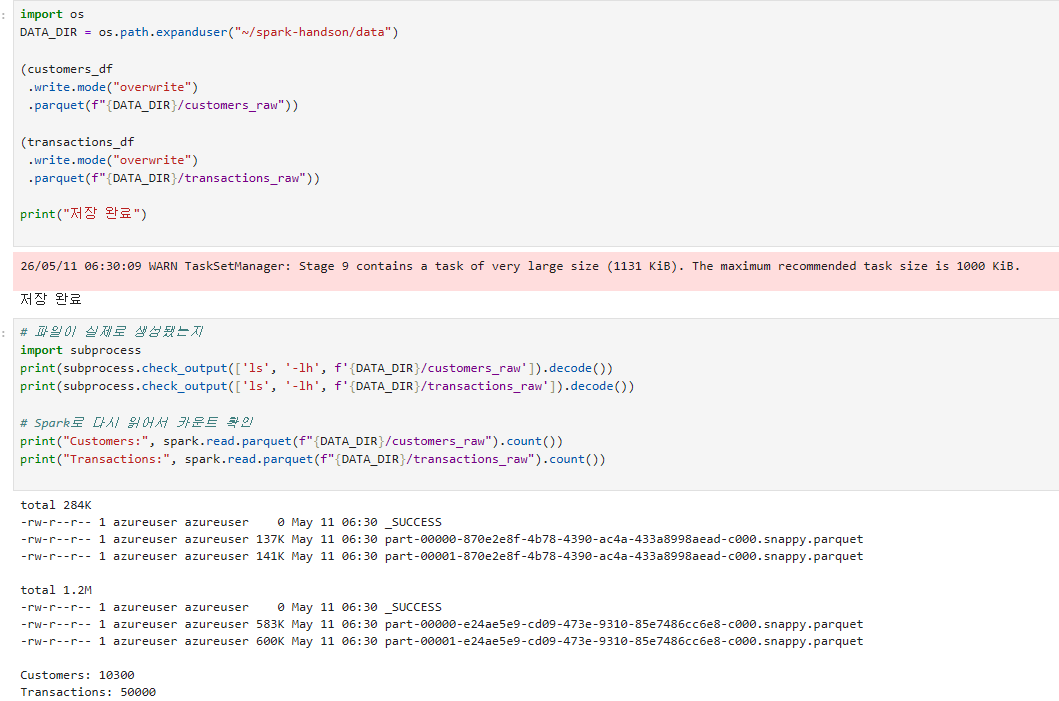
parquet로 저장
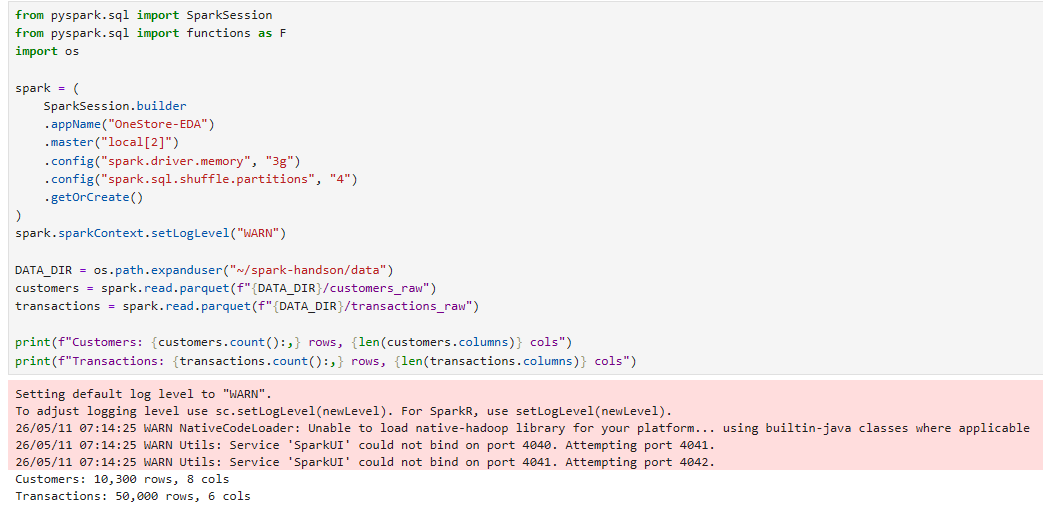
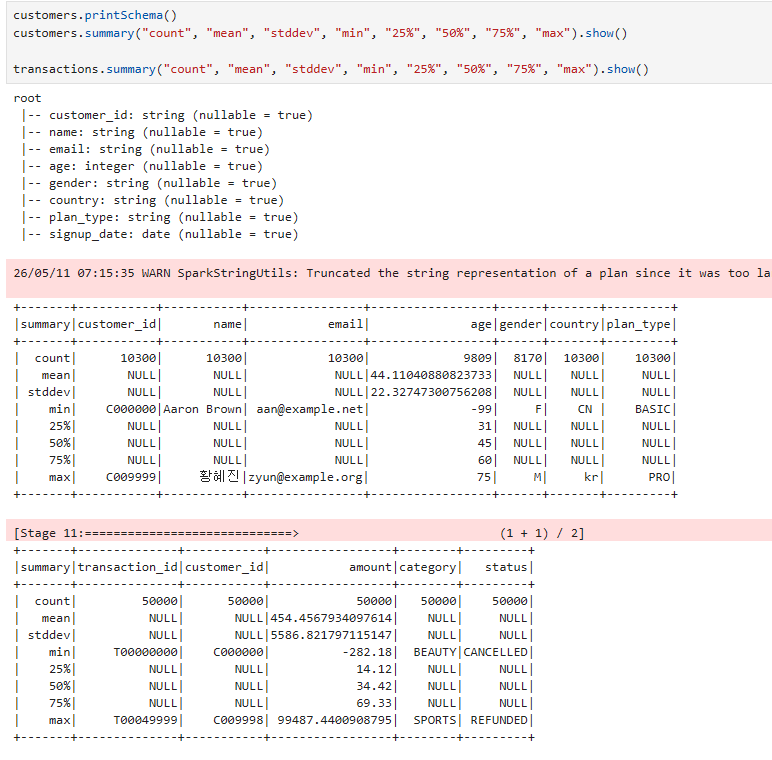
데이터 탐색 (EDA)
EDA (Exploratory Data Analysis): 모델링 전 데이터의 특성/품질을 파악하는 단계. 통계 요약, 분포, 결측 패턴, 상관관계 등.describe() vs summary(): 둘 다 통계 요약. summary()가 더 풍부 (count, mean, stddev, min, percentiles, max).dtypes / printSchema(): 컬럼 타입 확인. 정제 전 반드시 검토.PySpark → Pandas 변환 주의: .toPandas()는 driver 메모리에 전체를 수집(collect). 큰 데이터에선 OOM 위험. 시각화 직전 작은 집계 후 변환할 것.


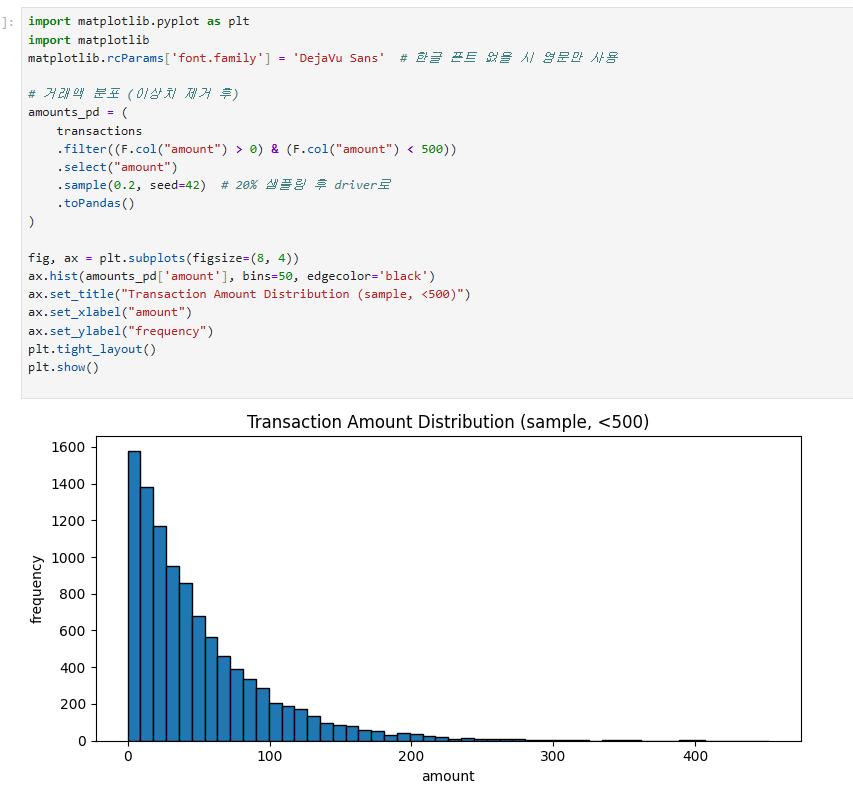
데이터 정제
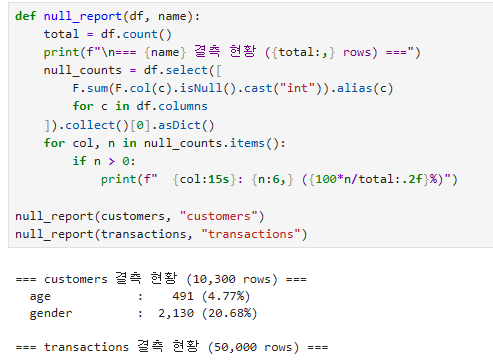
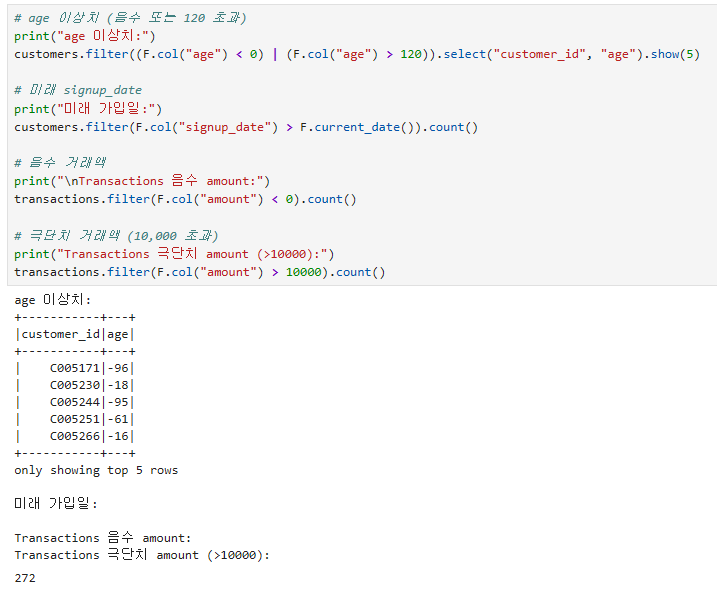
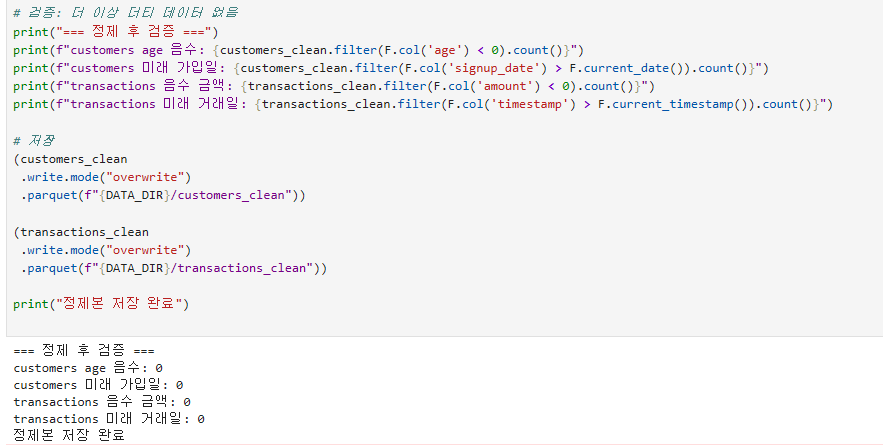
결측치 처리 전략: 1) 행 제거(dropna), 2) 평균/중앙값 대체(fillna), 3) 그룹별 대체, 4) 별도 카테고리("UNKNOWN") 부여. 어느 것이 좋은지는 도메인과 결측 비율에 따름.when().otherwise(): SQL의 CASE WHEN. 조건부 값 변환에 사용.F.trim(), F.upper(), F.lower(): 문자열 정규화 함수.이상치 처리: 1) 제거(필터), 2) winsorize(상하한 자르기), 3) 변환(log). 도메인 지식이 핵심.dropDuplicates(): 모든 컬럼 또는 지정 컬럼 기준 중복 제거. 첫 번째 row를 유지.


피처 엔지니어링
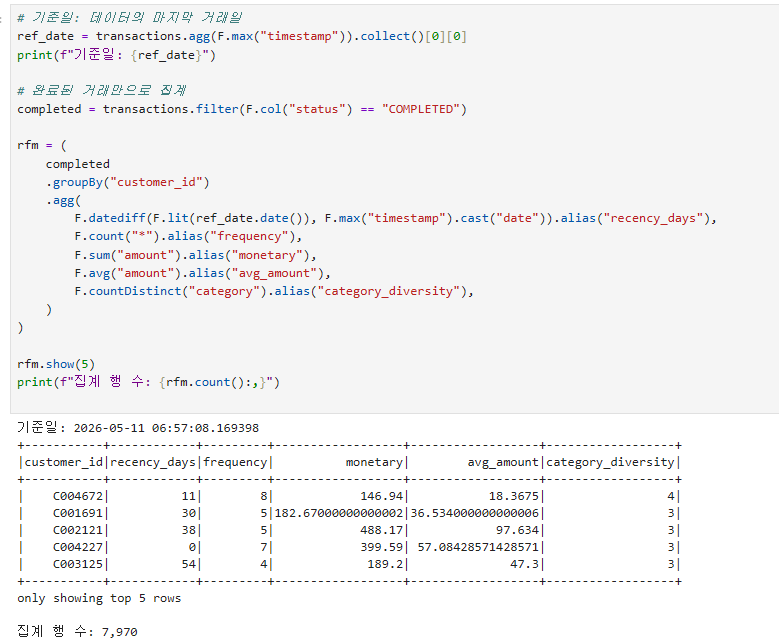
피처 엔지니어링 (Feature Engineering): 원시 데이터에서 모델 학습에 유용한 변수를 만드는 과정. ML 성능의 70~80%는 피처에서 결정된다는 격언도 있음.RFM 분석:Recency: 마지막 거래 후 경과일 → 작을수록 활성Frequency: 거래 횟수 → 클수록 충성Monetary: 총 거래액 → 클수록 가치 높음. 고객 세분화·이탈 예측의 고전적 피처
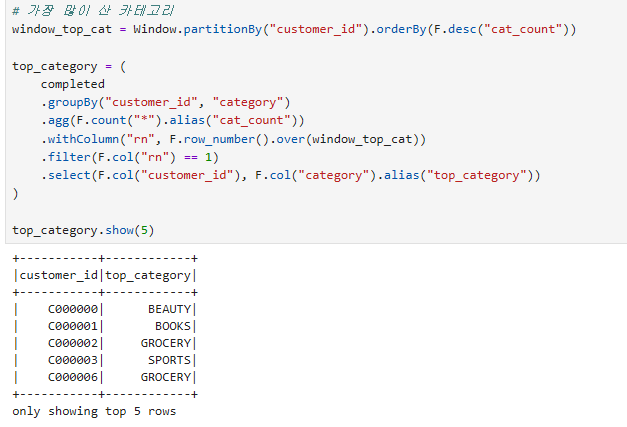
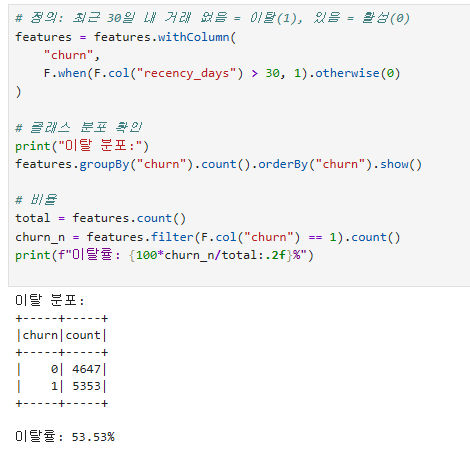
Window Function: 행 간 관계 연산. 누적합, 순위, 이전 값 참조 등.groupBy().agg(): SQL의 GROUP BY + 집계함수. F.sum, F.avg, F.count, F.countDistinct, F.max, F.min 등.타겟 변수 (Label): 지도학습에서 예측할 값. 본 시나리오에서는 "최근 30일 비활동 = 이탈"로 정의.
정제 데이터 로드
거래 데이터 집계
추가 피처: 카테고리 선호
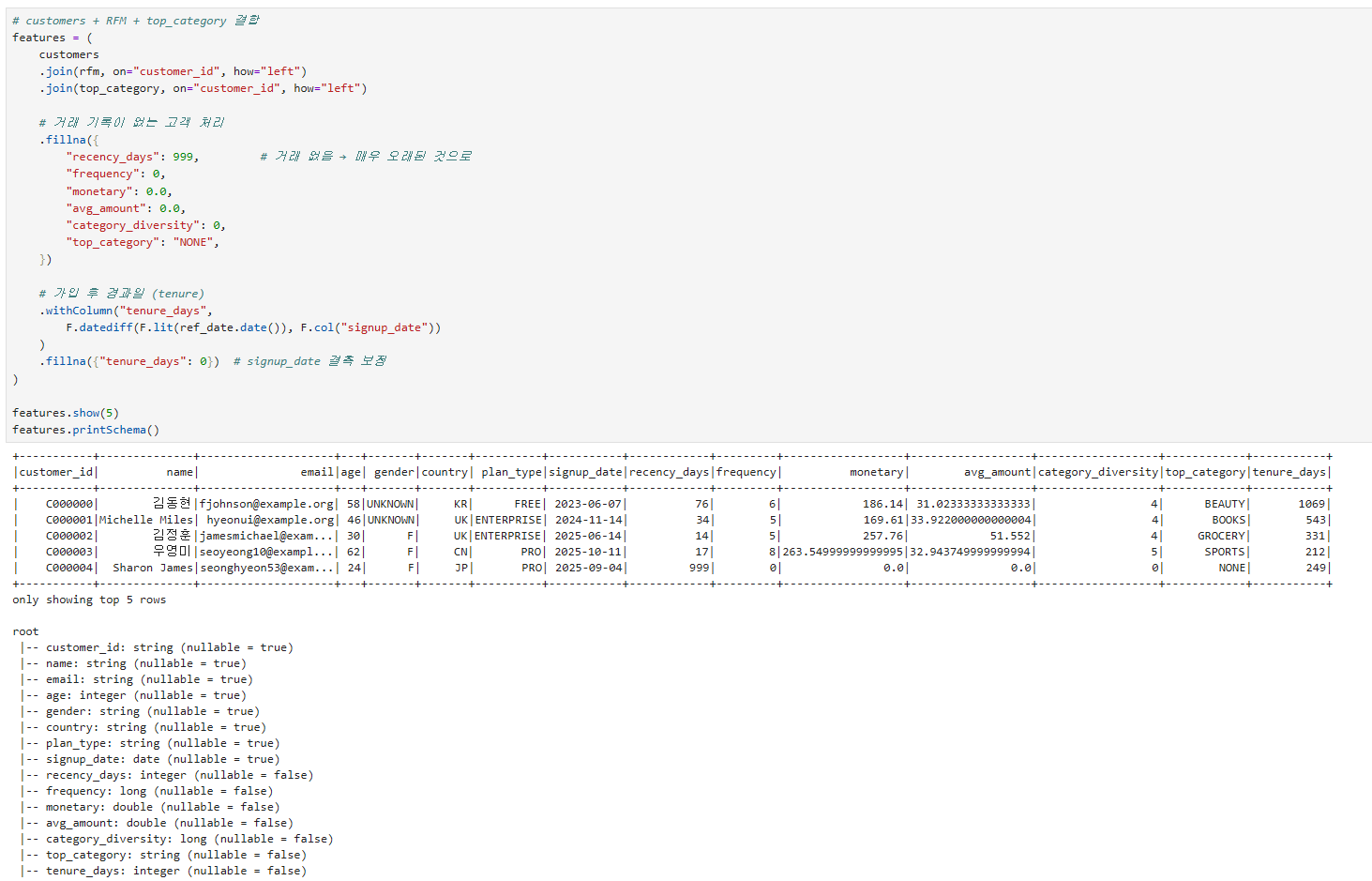
고객 정보와 join
타겟 변수: 이탈 정의
최종 피처셋 저장
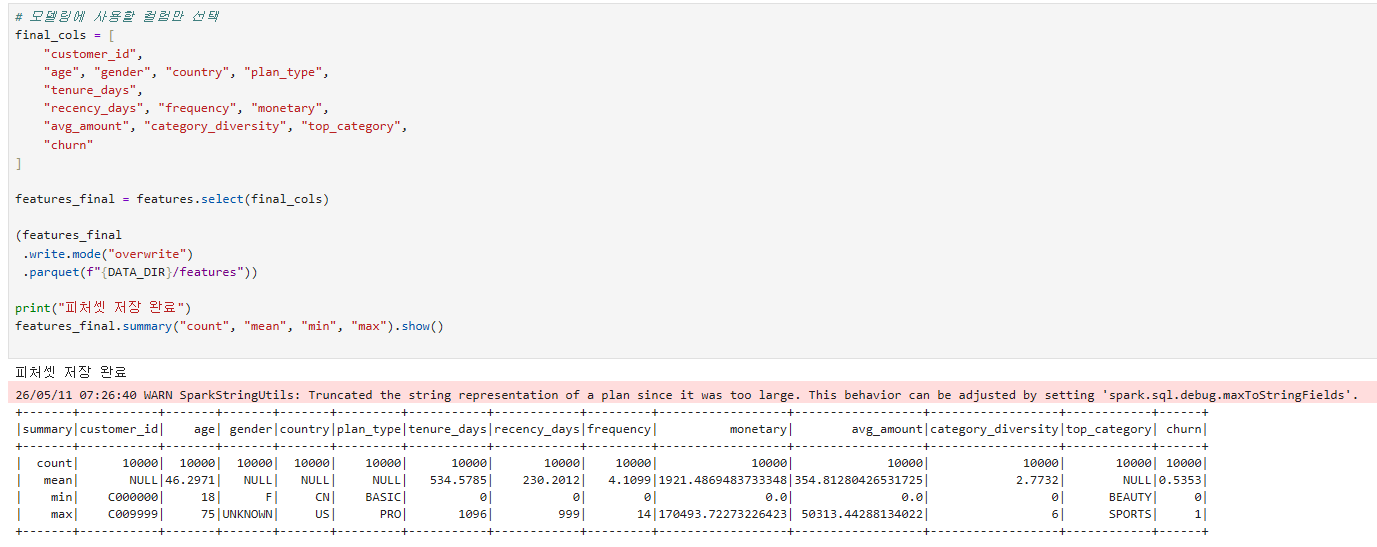
머신러닝: 이탈 예측 (분류)
Spark MLlib: Spark의 분산 ML 라이브러리. 두 API 존재:
pyspark.ml (DataFrame 기반, 현재 권장)
pyspark.mllib (RDD 기반, 유지보수만 됨)Pipeline: 전처리 + 모델을 단일 객체로 묶음. 학습/예측 시 동일 변환 보장 → 데이터 누수 방지.StringIndexer: 범주형 문자열을 정수 인덱스로 변환. [“KR”,”US”,”KR”] → [0.0, 1.0, 0.0].OneHotEncoder: 인덱스를 희소 벡터로. 0 → [1,0,0], 1 → [0,1,0]. 트리 모델은 불필요하나 선형 모델엔 필수.VectorAssembler: 여러 피처 컬럼을 하나의 vector 컬럼으로 결합. ML 알고리즘 입력 표준 형식.LogisticRegression: 이진 분류의 베이스라인 모델. 확률 출력, 해석 용이.train/test split: randomSplit([0.8, 0.2])로 학습 80% / 평가 20% 분리.평가 지표:- `Accuracy : 전체 정답률. 클래스 불균형 시 오해 소지.
AUC (ROC): 임계값 무관 분류 성능. 0.5=무작위, 1.0=완벽, 0.7+=쓸만함.Confusion Matrix: TP/FP/TN/FN 행렬.Precision/Recall/F1: 클래스별 세부 성능.
피처 로드 및 분할
Pipeline 구성

학습

평가
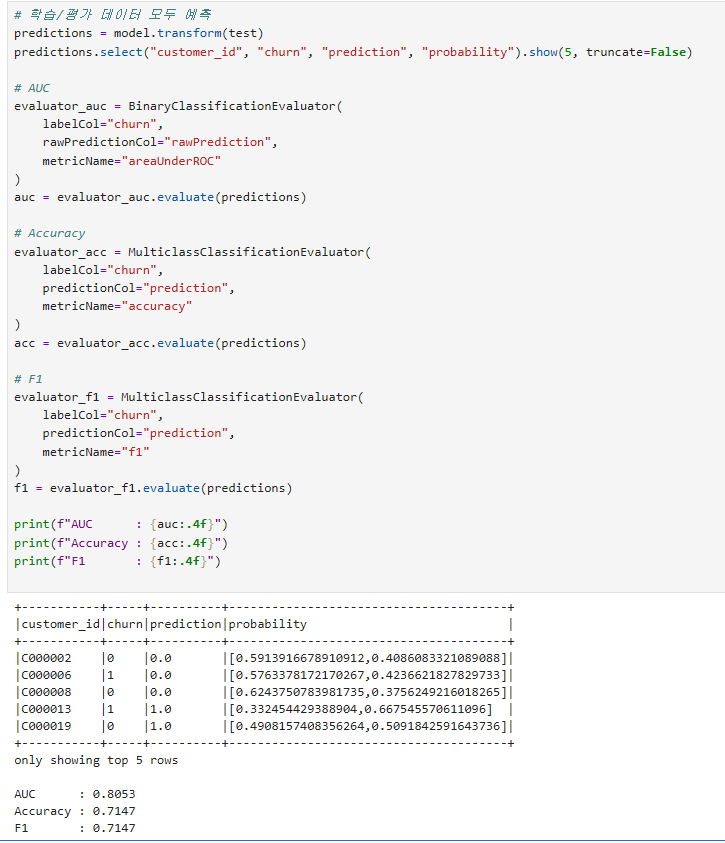
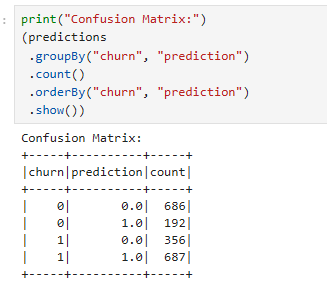
Confusion Matrix
피처 중요도 (계수)
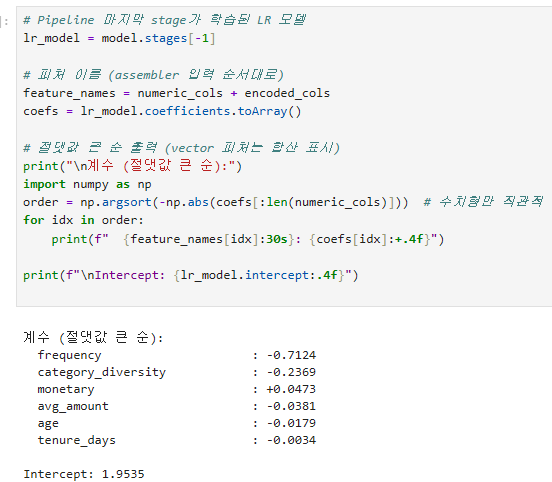
모델 저장 및 로드

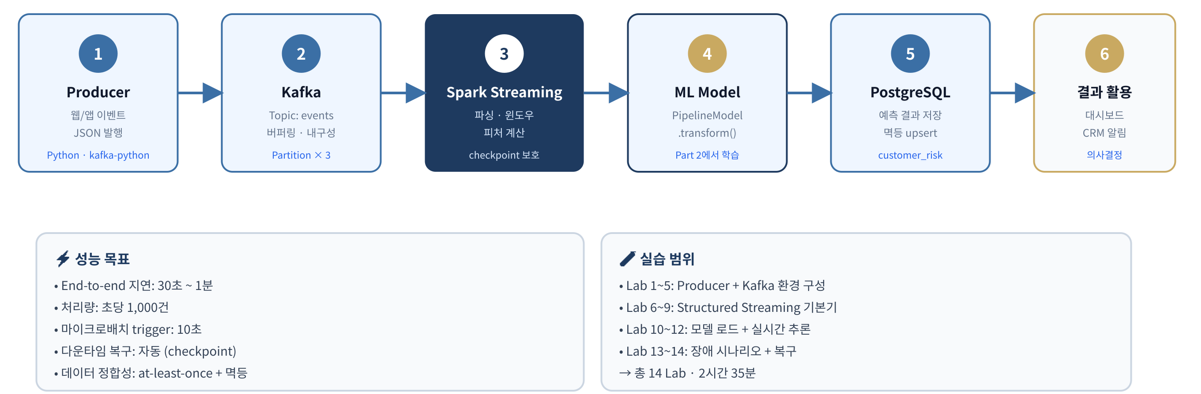
실시간 데이터 파이프라인 — Kafka + PostgreSQL + Spark Structured Streaming + 배치 ML 추론
- PostgreSQL 16을 같은 VM에 설치·운영 (Spark·Kafka와 8GB 안에서 공존)
- Kafka 3.x 단일 노드를 KRaft 모드로 설치 (ZooKeeper 없이)
- Python 프로듀서로 가짜 거래 이벤트를 Kafka 토픽에 발행
- Spark Structured Streaming으로 Kafka 토픽 구독·정제·PostgreSQL 적재
- PostgreSQL 데이터를 PySpark로 다시 읽어 분석·조회
- Part 2의 학습된 ML 모델을 운영 DB의 신규 데이터에 적용 (배치 추론)
- systemd + cron으로 파이프라인 자동화·운영
- SQL·Kafka CLI·Spark UI로 파이프라인 모니터링
