
실시간 데이터 파이프라인 — Kafka + PostgreSQL + Spark Structured Streaming + 배치 ML 추론
2. PostgreSQL 16 설치 및 초기화
- Ubuntu 24.04 기본 저장소에서 PostgreSQL 16을 apt로 설치하고 systemd로 관리한다.
- 운영용 사용자(
handson)와 데이터베이스(onestore)를 생성하고,.pgpass로 비밀번호 입력을 자동화한다.- 보안 기본값을 적용한다 (외부 네트워크 차단, scram-sha-256 인증).
- B2ms 8GB 환경에 맞는 메모리 튜닝을 적용한다.
| 용어 | 정의 |
|---|---|
| PostgreSQL Cluster | 한 서버 인스턴스 안의 모든 DB·role을 묶는 단위. 보통 1 서버 = 1 cluster. |
| Role | 사용자 + 그룹 통합 개념. CREATE USER는 사실 role 생성. |
| peer 인증 | Unix 소켓 접속 시 Linux 사용자명과 PG role이 일치하면 비번 없이 통과. |
| scram-sha-256 | PG14+ 기본 비번 인증 방식. TCP 접속(127.0.0.1 포함)에 적용. |
| pg_hba.conf | "누가, 어디서, 어떻게 접속 가능한가"를 정의하는 인증 규칙 파일. |
| postgresql.conf | 서버 동작 설정 (메모리·로그·복제 등). |
| shared_buffers | PG가 페이지 캐시처럼 쓰는 공유 메모리. B2ms에선 PG 할당분(1.2GB)의 절반 수준으로. |
| work_mem | 정렬·해시 조인 한 단위가 쓸 메모리. 너무 크면 OOM. |
| .pgpass | 홈 디렉터리의 권한 600 파일에 비번을 저장해 매번 입력 안 하게 함. |
개념 설명: cluster / database / role
┌──────────────────────────────────────────────────────────┐
│ Linux user "azureuser" (나) │
│ │
│ ① Unix 소켓 접속: sudo -u postgres psql │
│ → peer 인증 (Linux user == PG role 매칭) │
│ → 슈퍼유저 postgres로 진입, 관리용 │
│ │
│ ② TCP 접속 127.0.0.1:5432: │
│ psql -h 127.0.0.1 -U handson -d onestore │
│ → scram-sha-256 (비밀번호) │
│ → 운영 DB 작업용 │
└──────────────────────────────────────────────────────────┘
개념 설명: 메모리 튜닝 룰 오브 썸
| 파라미터 | 의미 | B2ms 설정값 | 근거 |
|---|---|---|---|
shared_buffers | PG 공유 메모리 캐시 | 768MB | PG 할당 1.2GB의 약 60% |
work_mem | 쿼리당 정렬·해시 메모리 | 16MB | 동시 쿼리 5개 × 16MB = 80MB로 안전 |
maintenance_work_mem | VACUUM·CREATE INDEX용 | 128MB | 학습 환경 충분 |
effective_cache_size | OS 페이지 캐시 추정치 (플래너 힌트) | 2GB | 실제 메모리 점유 X |
max_connections | 동시 연결 한도 | 20 | 학습 환경. 한 연결당 ~10MB 점유 |
PostgreSQL 16 설치
sudo apt update
sudo apt install -y postgresql-16 postgresql-client-16 postgresql-contrib-16
psql --version
sudo systemctl status postgresql --no-pager슈퍼유저 진입 및 운영 사용자/DB 생성
-- 운영 사용자 생성 (비밀번호는 학습용. 운영 시엔 강력한 값으로)
CREATE ROLE handson WITH LOGIN PASSWORD '비밀번호';
-- 운영 DB 생성 (소유자 handson)
CREATE DATABASE onestore OWNER handson ENCODING 'UTF8';
-- 추가 권한 (DB 안 모든 객체에 대한 풀권한)
GRANT ALL PRIVILEGES ON DATABASE onestore TO handson;
\l onestore
\du handson
\qTCP 접속 테스트
psql -h 127.0.0.1 -U handson -d onestore -c "SELECT current_user, current_database(), version();"
# 비밀번호 프롬프트 → handson_pw_2026.pgpass로 비밀번호 자동화
cat > ~/.pgpass << 'EOF'
127.0.0.1:5432:onestore:handson:비밀번호
127.0.0.1:5432:*:handson:비밀번호
EOF
chmod 600 ~/.pgpass
ls -l ~/.pgpass# 비번 입력 없이 접속되는지 확인
psql -h 127.0.0.1 -U handson -d onestore -c "SELECT 'pgpass works' AS status;"환경변수로 접속 정보 설정
grep -q "PGUSER=handson" ~/.bashrc || cat >> ~/.bashrc << 'EOF'
# === PostgreSQL 접속 (Part 3) ===
export PGHOST=127.0.0.1
export PGPORT=5432
export PGDATABASE=onestore
export PGUSER=handson
# 비밀번호는 .pgpass가 처리 (PGPASSWORD 환경변수 사용 X — ps에 노출됨)
EOF
source ~/.bashrc
# 환경변수 만으로 psql 접속되는지 확인
psql -c "SELECT current_user, current_database();"메모리 튜닝(postgresql.conf)
# 백업 (필수)
sudo cp /etc/postgresql/16/main/postgresql.conf \
/etc/postgresql/16/main/postgresql.conf.original
# 사용자 정의 설정을 별도 파일로
sudo tee /etc/postgresql/16/main/conf.d/99-handson.conf > /dev/null << 'EOF'
# === Handson Part 3 메모리 튜닝 (B2ms 8GB) ===
# PG 할당 예산 ~1.2GB
shared_buffers = 768MB
work_mem = 16MB
maintenance_work_mem = 128MB
effective_cache_size = 2GB
max_connections = 20
# WAL / 체크포인트 (학습 환경 안정성)
wal_buffers = 16MB
checkpoint_completion_target = 0.9
min_wal_size = 80MB
max_wal_size = 1GB
# SSD 가정 (Azure VM은 SSD)
random_page_cost = 1.1
# 로그 (트러블슈팅 편의)
log_min_duration_statement = 1000 # 1초 이상 쿼리 로깅
log_line_prefix = '%t [%p]: user=%u,db=%d,app=%a '
EOF
# include_dir 확인
grep -A1 "^include_dir" /etc/postgresql/16/main/postgresql.conf
# 서비스 재시작
sudo systemctl restart postgresql@16-main
# 적용 확인
psql -c "SHOW shared_buffers; SHOW work_mem; SHOW max_connections;"psql 기본 사용법
\? -- psql 명령어 도움말 전체
\h SELECT -- SELECT SQL 도움말
\l -- 데이터베이스 목록
\dt -- 현재 DB의 테이블 목록 (Section 3 후 채워짐)
\d 테이블명 -- 테이블 스키마 상세
\du -- role 목록
\timing -- 쿼리 실행 시간 표시 토글
\x -- 결과 가로/세로 출력 토글
\! -- 셸 명령 실행 (예: \! ls)
\i 파일.sql -- SQL 파일 실행
\q -- 종료3. 스키마 설계 및 테이블 생성
- 데이터 모델링 결과를 SQL 스크립트로 작성하고
psql -f로 일괄 실행한다.- PRIMARY KEY / FOREIGN KEY / CHECK / INDEX의 의미와 선택 근거를 이해한다.
\d 테이블명으로 스키마를 검증한다.
| 용어 | 정의 |
|---|---|
| dim / fact | 데이터 웨어하우스의 별 모양 스키마 명명. dim = 차원, fact = 사실. |
| PRIMARY KEY | 행을 유일하게 식별. NOT NULL + UNIQUE 자동 부여. |
| FOREIGN KEY | 다른 테이블의 PK를 참조. 무결성 보장. |
| CHECK 제약 | 행 단위 조건식. 위반 시 INSERT/UPDATE 거부. |
| NUMERIC(p, s) | 정확한 십진수. 금액 표현엔 FLOAT 대신 NUMERIC. |
| INDEX | 검색 가속용 보조 자료구조. INSERT 비용 ↑ / SELECT 비용 ↓. |
Float이 아닌 Numeric을 쓰는 이유
-- FLOAT 함정
SELECT 0.1::float8 + 0.2::float8;
-- 결과: 0.30000000000000004 (반올림 오차)
-- NUMERIC은 정확
SELECT 0.1::numeric + 0.2::numeric;
-- 결과: 0.3개념 설명: 인덱스 선택 근거
쿼리 패턴:
-- 1) 특정 고객의 거래 조회
SELECT * FROM transactions_fact WHERE customer_id = 'C001234';
-- 2) 최근 N분간 전체 거래
SELECT * FROM transactions_fact WHERE ts > NOW() - INTERVAL '5 min';
-- 3) 고객별 거래 수 집계
SELECT customer_id, COUNT(*) FROM transactions_fact GROUP BY customer_id;customer_id에 인덱스: 1번·3번 가속ts에 인덱스: 2번 가속 (시계열 슬라이싱)transaction_id는 PK라 자동 인덱스
DDL
cat > ~/spark-handson/sql/init.sql << 'EOF'
-- =====================================================================
-- OneStore Hands-on Part 3 — 초기 스키마
-- 실행: psql -f ~/spark-handson/sql/init.sql
-- 멱등: IF NOT EXISTS 절 사용. 재실행해도 안전.
-- =====================================================================
\set ON_ERROR_STOP on
BEGIN;
-- ----------------------------
-- 1) customers_dim — Part 2 정제본 적재 대상
-- ----------------------------
CREATE TABLE IF NOT EXISTS customers_dim (
customer_id VARCHAR(20) PRIMARY KEY,
age INT,
gender VARCHAR(10),
country VARCHAR(10),
plan_type VARCHAR(20),
signup_date DATE,
loaded_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
COMMENT ON TABLE customers_dim IS 'Part 2 customers_clean 정제본 적재 (배치 1회)';
-- ----------------------------
-- 2) transactions_fact — 스트리밍 적재 대상
-- ----------------------------
CREATE TABLE IF NOT EXISTS transactions_fact (
transaction_id VARCHAR(30) PRIMARY KEY,
customer_id VARCHAR(20) NOT NULL
REFERENCES customers_dim(customer_id),
ts TIMESTAMP NOT NULL,
amount NUMERIC(10, 2) CHECK (amount >= 0),
category VARCHAR(20),
status VARCHAR(20)
CHECK (status IN ('COMPLETED','PENDING','FAILED','REFUNDED')),
ingested_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX IF NOT EXISTS idx_tx_customer ON transactions_fact(customer_id);
CREATE INDEX IF NOT EXISTS idx_tx_ts ON transactions_fact(ts);
COMMENT ON TABLE transactions_fact IS 'Spark Structured Streaming이 Kafka에서 적재';
-- ----------------------------
-- 3) ml_predictions — 배치 추론 결과
-- ----------------------------
CREATE TABLE IF NOT EXISTS ml_predictions (
customer_id VARCHAR(20) PRIMARY KEY
REFERENCES customers_dim(customer_id),
predicted_at TIMESTAMP NOT NULL,
churn_proba NUMERIC(5, 4) CHECK (churn_proba BETWEEN 0 AND 1),
churn_label INT CHECK (churn_label IN (0, 1)),
model_version VARCHAR(50)
);
CREATE INDEX IF NOT EXISTS idx_pred_at ON ml_predictions(predicted_at);
COMMENT ON TABLE ml_predictions IS 'cron 배치 추론 결과 (UPSERT, 고객당 1행)';
COMMIT;
-- 확인용
\echo ''
\echo '=== 생성된 테이블 ==='
\dt
EOF
ls -l ~/spark-handson/sql/init.sql#실행
psql -f ~/spark-handson/sql/init.sqlPySpark에서 PostgreSQL 연결 (JDBC)
- PostgreSQL JDBC 드라이버를 PySpark에 통합 (
--packages자동 다운로드 / 수동 jar).- 안전한 비밀번호 처리 패턴(
.pgpass파싱)을 적용.- Part 2의
customers_cleanParquet을customers_dim테이블에 적재.- PySpark에서 PostgreSQL 데이터를 다시 읽어 검증하는 양방향 패턴.
| 용어 | 정의 |
|---|---|
| JDBC | Java Database Connectivity. JVM이 RDBMS와 통신하는 표준 API. PySpark는 내부 JVM이 사용. |
| JDBC URL | DB 위치 + 옵션. 예: jdbc:postgresql://127.0.0.1:5432/onestore |
| Maven Coordinates | groupId:artifactId:version. PostgreSQL JDBC는 org.postgresql:postgresql:42.7.4. |
--packages | Maven Central에서 자동 다운로드 + ~/.ivy2/cache 저장. |
--jars | 받아둔 jar 파일 경로 직접 지정. 오프라인용. |
| Write Mode | append / overwrite / error(기본) / ignore. RDBMS 적재엔 append + 멱등성 코드. |
batchsize | JDBC INSERT 한 번에 묶는 행 수 (기본 1000). |
--packages vs --jars
┌─────────────────────────────────────────────────────────────┐
│ ① --packages org.postgresql:postgresql:42.7.4 │
│ → Maven Central → ~/.ivy2/cache → 자동 클래스패스 │
│ (장점: 의존성 transitively 해결, 첫 실행 후 캐시됨) │
│ (단점: 외부 네트워크 필요, 첫 실행 1~3분) │
│ │
│ ② --jars /path/to/postgresql-42.7.4.jar │
│ (장점: 오프라인 가능, 즉시 시작) │
│ (단점: 의존성 수동 관리) │
└─────────────────────────────────────────────────────────────┘개념 설명: Spark JDBC 적재 동작
PySpark DataFrame (10,000 rows)
│
│ .write.format("jdbc").mode("append")
│ .option("batchsize", 1000)
▼
JDBC Driver (postgresql-42.7.4.jar)
│ INSERT INTO customers_dim VALUES (...) -- 1000행 묶음 × 10
▼
PostgreSQL왜
mode("overwrite")가 위험한가?
Spark JDBCoverwrite는 기본DROP TABLE + CREATE TABLE. 우리 customers_dim엔 PK·CHECK·FK 메타데이터가 붙어 DROP하면 다 사라진다. 그래서append+ 멱등성 패턴.
JDBC 드라이버 사전 캐싱
cat > /tmp/cache_jdbc.py << 'PYEOF'
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("cache_jdbc").getOrCreate()
print("PostgreSQL JDBC 드라이버 다운로드 완료")
spark.stop()
PYEOF
spark-submit \
--packages org.postgresql:postgresql:42.7.4 \
--conf spark.driver.memory=1g \
/tmp/cache_jdbc.py 2>&1 | grep -E "(SUCCESSFUL|downloaded|완료|ERROR)"
# 캐시 확인
ls -la ~/.ivy2/jars/ | grep postgresql적재
cat > ~/spark-handson/jobs/load_customers_dim.py << 'PYEOF'
#!/usr/bin/env python3
"""
load_customers_dim.py
Part 2의 customers_clean Parquet을 PostgreSQL customers_dim 테이블에 적재.
"""
import os
import sys
from pathlib import Path
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
def get_pgpass(host: str, port: str, db: str, user: str) -> str:
pgpass = Path.home() / ".pgpass"
if not pgpass.exists():
sys.exit("ERROR: ~/.pgpass not found. See Section 2 Step 2-4.")
if oct(pgpass.stat().st_mode)[-3:] != "600":
sys.exit("ERROR: ~/.pgpass permission must be 600.")
for line in pgpass.read_text().splitlines():
if not line or line.startswith("#"):
continue
parts = line.split(":")
if len(parts) != 5:
continue
h, p, d, u, pw = parts
if h in (host, "*") and p in (port, "*") \
and d in (db, "*") and u in (user, "*"):
return pw
sys.exit(f"ERROR: no matching .pgpass entry for {user}@{host}:{port}/{db}")
PG_HOST = os.environ.get("PGHOST", "127.0.0.1")
PG_PORT = os.environ.get("PGPORT", "5432")
PG_DB = os.environ.get("PGDATABASE", "onestore")
PG_USER = os.environ.get("PGUSER", "handson")
PG_PW = get_pgpass(PG_HOST, PG_PORT, PG_DB, PG_USER)
JDBC_URL = f"jdbc:postgresql://{PG_HOST}:{PG_PORT}/{PG_DB}"
JDBC_PROPS = {
"user": PG_USER,
"password": PG_PW,
"driver": "org.postgresql.Driver",
}
CUSTOMERS_PARQUET = os.path.expanduser("~/spark-handson/data/customers_clean")
def main():
spark = (
SparkSession.builder
.appName("load_customers_dim")
.getOrCreate()
)
spark.sparkContext.setLogLevel("ERROR")
print(f"[INFO] reading parquet: {CUSTOMERS_PARQUET}")
df = spark.read.parquet(CUSTOMERS_PARQUET)
df_to_load = df.select(
col("customer_id"),
col("age").cast("int"),
col("gender"),
col("country"),
col("plan_type"),
col("signup_date").cast("date"),
)
src_count = df_to_load.count()
print(f"[INFO] source rows: {src_count}")
existing = (
spark.read.jdbc(url=JDBC_URL, table="customers_dim",
properties=JDBC_PROPS).count()
)
print(f"[INFO] customers_dim existing rows: {existing}")
if existing > 0:
print("[WARN] customers_dim is not empty. Skipping load.")
print(" To reload, run reset SQL first:")
print(" psql -c 'TRUNCATE customers_dim, transactions_fact, ml_predictions CASCADE;'")
spark.stop()
return
print("[INFO] loading into customers_dim ...")
(
df_to_load.write
.format("jdbc")
.option("url", JDBC_URL)
.option("dbtable", "customers_dim")
.option("user", PG_USER)
.option("password", PG_PW)
.option("driver", "org.postgresql.Driver")
.option("batchsize", 1000)
.mode("append")
.save()
)
loaded = (
spark.read.jdbc(url=JDBC_URL, table="customers_dim",
properties=JDBC_PROPS).count()
)
print(f"[OK] loaded rows: {loaded} (expected: {src_count})")
spark.stop()
if __name__ == "__main__":
main()
PYEOF
chmod +x ~/spark-handson/jobs/load_customers_dim.py
ls -l ~/spark-handson/jobs/load_customers_dim.py실행
spark-submit \
--packages org.postgresql:postgresql:42.7.4 \
--conf spark.driver.memory=2g \
~/spark-handson/jobs/load_customers_dim.py \
2>&1 | tee ~/spark-handson/logs/load_customers_dim.log | grep -E "INFO|WARN|OK|ERROR"(선택) 재적재
# 1) 자식 테이블 + customers_dim 모두 비우기 (CASCADE)
psql -c "TRUNCATE customers_dim, transactions_fact, ml_predictions CASCADE;"
# 2) 다시 적재
spark-submit \
--packages org.postgresql:postgresql:42.7.4 \
~/spark-handson/jobs/load_customers_dim.pyKafka 3.7 단일 노드 설치(KRaft 모드)
- Apache Kafka 3.7을 tarball로 설치하고
/opt/kafka에 배치.- KRaft(Kafka Raft) 모드로 클러스터 초기화 (ZooKeeper 미사용).
- B2ms 8GB 환경에 맞게 JVM 힙을 1GB로 제한.
- systemd unit으로 등록.
transactions-raw토픽 생성 + 콘솔 producer/consumer 검증.
| 용어 | 정의 |
|---|---|
| Broker | 메시지를 저장·전송하는 Kafka 서버 노드. |
| Controller | 클러스터 메타데이터(토픽·파티션·리더 선출) 관리. KRaft에선 broker와 통합 가능. |
| Topic | 메시지가 발행되는 논리적 스트림 이름. |
| Partition | 토픽을 물리적으로 쪼갠 단위. 파티션 수 = 병렬 consume 가능 수. |
| Offset | 한 파티션 안에서 메시지의 순차 ID. |
| Consumer Group | 같은 그룹 consumer들이 토픽 파티션을 분담. Spark Streaming은 자체 그룹. |
| KRaft | "Kafka Raft" 메타데이터 합의 프로토콜. ZooKeeper 대체. Kafka 3.3+ production-ready. |
process.roles | 한 프로세스가 어떤 역할인지. 단일 노드는 broker,controller 둘 다. |
log.dirs | Kafka가 메시지를 디스크에 저장하는 디렉터리. |
retention.ms | 메시지 디스크 유지 시간. 우리는 1시간(3,600,000ms). |
KRaft vs ZooKeeper
┌─── 기존 (ZooKeeper 모드) ───┐ ┌─── KRaft 모드 ───────────┐
│ ┌─────────────┐ │ │ ┌────────────────────┐ │
│ │ ZooKeeper │ 메타데이터 │ │ │ Kafka 프로세스 │ │
│ │ (별도 클러스터) │ │ │ │ ├─ broker │ │
│ └──────┬──────┘ │ │ │ └─ controller │ │
│ │ │ │ │ (메타데이터 = Raft) │ │
│ ┌──────▼──────┐ │ │ └────────────────────┘ │
│ │ Kafka brokers│ │ │ │
│ └─────────────┘ │ │ 프로세스 1개로 끝 │
│ 프로세스 2종류 운영 부담 │ │ 메모리 절약 + 단순성 │
└──────────────────────────────┘ └───────────────────────────┘B2ms 8GB에 KRaft가 적합한 이유: ZooKeeper 모드는 별도 JVM(~512MB) 추가. KRaft는 통합 → 메모리·복잡도 절약.
Topic/Partition/Offset
Topic: transactions-raw (partitions=3)
┌───────────────────────────────────────────────────────────┐
│ Partition 0: [m0][m1][m2][m3][m4][m5]... │
│ Partition 1: [m0][m1][m2]... │
│ Partition 2: [m0][m1][m2][m3]... │
└───────────────────────────────────────────────────────────┘
Producer가 메시지 발행:
- key 없음 → 라운드로빈/스티키
- key 있음 → hash(key) % partitions로 같은 key는 같은 파티션 (순서 보장)
Consumer가 메시지 소비:
- 같은 Consumer Group 안의 consumer들이 파티션 분담
- Spark Streaming도 내부적으로 Consumer Group 사용KRaft 단일 노드의 listeners
| listener | 포트 | 용도 |
|---|---|---|
PLAINTEXT | 9092 | 클라이언트(Producer·Consumer) ↔ broker |
CONTROLLER | 9093 | controller ↔ controller (메타데이터 합의용 Raft) |
단일 노드라도 controller listener 필수.
메모리 예산
| 컴포넌트 | 설정값 |
|---|---|
JVM Heap (-Xmx1g) | 1GB 고정 |
| Page Cache | 동적 (남은 메모리) |
| Direct Memory | ~256MB 추가 |
Kafka는 JVM 힙을 작게 유지하고 OS page cache에 의존. -Xmx1g로도 충분.
tarball 다운로드
mkdir -p ~/dl && cd ~/dl
KAFKA_VER=3.7.0
KAFKA_FILE=kafka_2.13-${KAFKA_VER}.tgz
KAFKA_URL_PRIMARY="https://archive.apache.org/dist/kafka/${KAFKA_VER}/${KAFKA_FILE}"
KAFKA_URL_FALLBACK="https://dlcdn.apache.org/kafka/${KAFKA_VER}/${KAFKA_FILE}"
curl -fLO "$KAFKA_URL_PRIMARY" || curl -fLO "$KAFKA_URL_FALLBACK"
ls -lh ${KAFKA_FILE}
file ${KAFKA_FILE}압축 해제 + /opt/kafka 배치
cd ~/dl
sudo tar -xzf kafka_2.13-3.7.0.tgz -C /opt/
sudo mv /opt/kafka_2.13-3.7.0 /opt/kafka-3.7.0
sudo ln -sfn /opt/kafka-3.7.0 /opt/kafka
ls -la /opt/ | grep -E "kafka|->"환경변수 등록
grep -q "KAFKA_HOME" ~/.bashrc || cat >> ~/.bashrc << 'EOF'
# === Kafka (Part 3) ===
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/bin
EOF
source ~/.bashrc
echo "KAFKA_HOME=$KAFKA_HOME"
which kafka-topics.sh데이터, 로그 디렉터리 준비
mkdir -p ~/spark-handson/kafka-data
mkdir -p ~/spark-handson/logs/kafka
ls -ld ~/spark-handson/kafka-data ~/spark-handson/logs/kafkaserver.properties 작성
sudo cp /opt/kafka/config/kraft/server.properties \
/opt/kafka/config/kraft/server.properties.original
sudo tee /opt/kafka/config/kraft/server.properties > /dev/null << 'EOF'
# ===========================================================================
# Kafka 3.7 KRaft Single-Node — Hands-on Part 3
# ===========================================================================
# ---- KRaft Roles ---------------------------------------------------------
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:9093
# ---- Listeners -----------------------------------------------------------
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:9092
# ---- Storage -------------------------------------------------------------
log.dirs=/home/azureuser/spark-handson/kafka-data
# ---- Topic Defaults (단일 노드용 축소) -----------------------------------
num.partitions=3
default.replication.factor=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
min.insync.replicas=1
# ---- Retention (학습용 기본 1h, 토픽별 재정의 가능) ----------------------
log.retention.hours=1
log.segment.bytes=104857600
log.retention.check.interval.ms=300000
# ---- Performance (단일 노드 학습 환경) ------------------------------------
num.network.threads=3
num.io.threads=4
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
# ---- Auto Topic Creation (학습 편의, 운영에선 false 권장) ----------------
auto.create.topics.enable=false
EOF
grep -E "^(process.roles|node.id|listeners|log.dirs|num.partitions|log.retention)" \
/opt/kafka/config/kraft/server.propertiesKAFKA_HEAP_OPTS 정착
sudo tee /etc/default/kafka > /dev/null << 'EOF'
KAFKA_HEAP_OPTS="-Xmx1g -Xms1g"
LOG_DIR=/home/azureuser/spark-handson/logs/kafka
EOF
cat /etc/default/kafkaCluster ID 생성 + Storage Format
KAFKA_CLUSTER_ID=$(/opt/kafka/bin/kafka-storage.sh random-uuid)
echo "Cluster ID: $KAFKA_CLUSTER_ID"
echo "$KAFKA_CLUSTER_ID" > ~/spark-handson/kafka-data/CLUSTER_ID.txt
/opt/kafka/bin/kafka-storage.sh format \
-t "$KAFKA_CLUSTER_ID" \
-c /opt/kafka/config/kraft/server.properties
ls ~/spark-handson/kafka-data/
cat ~/spark-handson/kafka-data/meta.propertiessystemd unit 작성
sudo tee /etc/systemd/system/kafka.service > /dev/null << 'EOF'
[Unit]
Description=Apache Kafka (KRaft single-node)
Documentation=https://kafka.apache.org/documentation/
After=network.target
[Service]
Type=simple
User=azureuser
Group=azureuser
EnvironmentFile=/etc/default/kafka
Environment=JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-failure
RestartSec=5s
LimitNOFILE=100000
TimeoutStopSec=60s
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable kafka
sudo systemd-analyze verify /etc/systemd/system/kafka.serviceKafka 기동
sudo systemctl start kafka
sleep 5
sudo systemctl status kafka --no-pager | head -15# 포트 LISTEN 확인 (9092 + 9093)
ss -tlnp 2>/dev/null | grep -E ':9092 |:9093 '# Kafka 자체 로그
tail -20 ~/spark-handson/logs/kafka/server.log 2>/dev/null \
|| tail -20 /opt/kafka/logs/server.log로그 마지막에
Kafka Server started확인.
실패시 다음과 같이 fix.1) 환경 파일을 올바른 변수명으로 다시 작성
sudo tee /etc/default/kafka > /dev/null << 'EOF'
KAFKA_HEAP_OPTS="-Xmx1g -Xms1g"
LOG_DIR=/home/azureuser/spark-handson/logs/kafka
EOF
# 2) 재시작 카운터 초기화 (41번 실패한 거 리셋)
sudo systemctl reset-failed kafka
# 3) 시작
sudo systemctl restart kafka
sleep 8
sudo systemctl status kafka --no-pager | head -8다시 확인
# Kafka 자체 로그
tail -20 ~/spark-handson/logs/kafka/server.log 2>/dev/null \
|| tail -20 /opt/kafka/logs/server.log토픽 생성
kafka-topics.sh --bootstrap-server localhost:9092 \
--create --topic transactions-raw \
--partitions 3 \
--replication-factor 1 \
--config retention.ms=3600000 \
--config segment.ms=600000
kafka-topics.sh --bootstrap-server localhost:9092 --list
kafka-topics.sh --bootstrap-server localhost:9092 \
--describe --topic transactions-raw콘솔 Producer/Consumer 검증
터미널:
printf 'msg-1\nmsg-2\nmsg-3\n' | \
kafka-console-producer.sh --bootstrap-server localhost:9092 \
--topic transactions-raw
kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic transactions-raw \
--from-beginning \
--max-messages 3 \
--timeout-ms 10000Python Producer
kafka-python클라이언트로 Producer 구현.customers_dim에서 추출한 실제customer_id로 외래키 정합성 유지.- 발행률(rate), 실행 시간(duration), 이상치 비율(dirty rate) 인자로 제어.
- 의도적으로 1% 비율로 깨진 데이터를 섞어 Section 7 정제 로직 검증 재료를 만든다.
| 용어 | 정의 |
|---|---|
KafkaProducer | kafka-python의 Producer 클라이언트. send() 비동기, flush()로 강제 전송. |
send(topic, key, value) | 메시지 발행. 백그라운드 스레드가 배치로 broker에 전송. |
key | 같은 key는 같은 파티션. 고객별 순서 보장에 사용. |
value_serializer | dict → bytes 변환 함수. json.dumps().encode(). |
acks | broker ack 요구 수준. all / 1 / 0. 학습은 all. |
linger_ms | 배치 전송 대기 시간. 10ms가 throughput/latency 균형점. |
| Dirty Data | 일부러 위반시킨 데이터. 다운스트림 정제 검증용. |
Application 스레드 kafka-python 내부 Kafka Broker
───────────────── ───────────────── ─────────────
producer.send(...) ──→ [accumulator 큐]
producer.send(...) ──→ [accumulator 큐]
│
│ linger_ms 또는 batch.size 도달
▼
[Sender 스레드] ──→ TCP ─→ [9092]
│
│ broker ack 대기 (acks=all)
▼
[retry 또는 done]
producer.flush() ──→ 큐 비울 때까지 블록
producer.close() ──→ flush + 연결 종료flush()를 안 부르면? 스크립트 종료 시 큐에 남은 메시지 손실 가능. 본 가이드는 try/finally에서 호출.
key 사용 전략
key=None 또는 매번 다른 key:
Partition 0: [t1][t4][t7]... ← 라운드로빈
Partition 1: [t2][t5]...
Partition 2: [t3][t6]...
key=customer_id ("C001234"):
hash("C001234") % 3 = 1
→ 이 고객의 모든 거래는 항상 Partition 1
→ 순서 보장key=customer_id. 이유:
1. 같은 고객의 거래 순서 보장 (이상 거래 탐지 시 유용)
2. 파티션 분포가 customer_id 분포에 따름 → 자연스러운 부하 분산
4종 dirty 패턴
| 패턴 | 위반 종류 | Section 7 정제에서 어떻게 걸러지나 |
|---|---|---|
negative_amount | 도메인 (amount ≥ 0) | WHERE amount >= 0 또는 PG CHECK |
invalid_status | 열거형 | WHERE status IN (...) 또는 PG CHECK |
unknown_customer | 외래키 | PG FK 거부 → 7-2의 화이트리스트로 사전 차단 |
missing_field | 스키마 | Spark from_json 시 NULL → 필터 |
kafka-python 설치
echo $VIRTUAL_ENV
# /home/azureuser/sparkenv 가 나와야 함
pip install --quiet "kafka-python>=2.0.0,<3.0.0"
python -c "import kafka; print('kafka-python', kafka.__version__)"customer_id 샘플 파일 생성
Producer가 매번 PG에 쿼리하면 비싸다. 시작 시 한 번 추출.
psql -tAc "SELECT customer_id FROM customers_dim ORDER BY customer_id" \
> ~/spark-handson/streaming/customer_ids.txt
wc -l ~/spark-handson/streaming/customer_ids.txt
head -3 ~/spark-handson/streaming/customer_ids.txt
tail -3 ~/spark-handson/streaming/customer_ids.txt# 기대 출력:
10000 ~/spark-handson/streaming/customer_ids.txt
C000001
C000002
...
C009998
C009999gen_events.py 작성
cat > ~/spark-handson/streaming/gen_events.py << 'PYEOF'
#!/usr/bin/env python3
"""
gen_events.py — OneStore 가짜 거래 이벤트 생성기 (Kafka Producer)
실행 예시:
# 기본: 초당 5건, 무한, dirty 1%
python ~/spark-handson/streaming/gen_events.py
# 60초간 초당 10건
python ~/spark-handson/streaming/gen_events.py --rate 10 --duration 60
# systemd가 호출할 때 (로그 파일 분리)
python ~/spark-handson/streaming/gen_events.py \
--rate 5 --log-file ~/spark-handson/logs/gen_events.log
"""
import argparse
import json
import logging
import os
import random
import signal
import sys
import time
from datetime import datetime, timezone
from pathlib import Path
from typing import List
from kafka import KafkaProducer
from kafka.errors import KafkaError
# ── 도메인 정의 ────────────────────────────────────────────────────────
CATEGORIES = [
("GROCERY", 35),
("FASHION", 20),
("ELECTRONICS", 15),
("BOOKS", 10),
("SPORTS", 10),
("BEAUTY", 5),
("FOOD_DELIVERY", 5),
]
STATUS = [
("COMPLETED", 85),
("PENDING", 10),
("FAILED", 3),
("REFUNDED", 2),
]
DIRTY_PATTERNS = [
"negative_amount",
"invalid_status",
"unknown_customer",
"missing_field",
]
logger = logging.getLogger("gen_events")
# ── 유틸 ────────────────────────────────────────────────────────────────
def load_customer_ids(path: str) -> List[str]:
p = Path(os.path.expanduser(path))
if not p.exists():
sys.exit(f"ERROR: customer sample file not found: {p}")
ids = [ln.strip() for ln in p.read_text().splitlines() if ln.strip()]
if len(ids) < 100:
sys.exit(f"ERROR: too few customer ids ({len(ids)}). Expected 100+.")
logger.info(f"loaded {len(ids)} customer ids")
return ids
def make_tx_id(seq: int) -> str:
"""T + YYYYMMDDHHMMSS + 3-digit sequence (max 30 chars)."""
now = datetime.now(timezone.utc)
return f"T{now.strftime('%Y%m%d%H%M%S')}{seq:03d}"
def amount_for_category(cat: str) -> float:
if cat == "ELECTRONICS":
return round(random.uniform(50_000, 2_000_000), 2)
if cat == "GROCERY":
return round(random.uniform(3_000, 80_000), 2)
if cat == "FASHION":
return round(random.uniform(15_000, 300_000), 2)
return round(random.uniform(5_000, 150_000), 2)
def gen_clean(customer_ids: List[str], seq: int) -> dict:
cat = random.choices(
[c for c, _ in CATEGORIES],
weights=[w for _, w in CATEGORIES], k=1
)[0]
st = random.choices(
[s for s, _ in STATUS],
weights=[w for _, w in STATUS], k=1
)[0]
return {
"transaction_id": make_tx_id(seq),
"customer_id": random.choice(customer_ids),
"timestamp": datetime.now(timezone.utc).isoformat(),
"amount": amount_for_category(cat),
"category": cat,
"status": st,
}
def gen_dirty(customer_ids: List[str], seq: int) -> dict:
ev = gen_clean(customer_ids, seq)
pat = random.choice(DIRTY_PATTERNS)
if pat == "negative_amount":
ev["amount"] = -abs(ev["amount"])
elif pat == "invalid_status":
ev["status"] = "ZZZ_INVALID"
elif pat == "unknown_customer":
ev["customer_id"] = "C999999" # customers_dim에 없는 ID
elif pat == "missing_field":
ev.pop("category", None)
ev["_dirty"] = pat # _ 시작 필드는 다운스트림 무시
return ev
# ── Producer ────────────────────────────────────────────────────────────
def make_producer(bootstrap: str) -> KafkaProducer:
return KafkaProducer(
bootstrap_servers=bootstrap,
value_serializer=lambda v: json.dumps(v, default=str).encode("utf-8"),
key_serializer=lambda k: (k or "").encode("utf-8"),
acks="all",
linger_ms=10,
retries=3,
max_in_flight_requests_per_connection=1, # 순서 보장
)
# ── 메인 루프 ───────────────────────────────────────────────────────────
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--bootstrap", default="localhost:9092")
ap.add_argument("--topic", default="transactions-raw")
ap.add_argument("--sample-file", default="~/spark-handson/streaming/customer_ids.txt")
ap.add_argument("--rate", type=float, default=5.0,
help="events per second")
ap.add_argument("--duration", type=int, default=0,
help="seconds; 0 = infinite")
ap.add_argument("--dirty-rate", type=float, default=0.01)
ap.add_argument("--log-file", default=None)
args = ap.parse_args()
# 로깅
handlers = [logging.StreamHandler()]
if args.log_file:
Path(args.log_file).parent.mkdir(parents=True, exist_ok=True)
handlers.append(logging.FileHandler(args.log_file))
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
handlers=handlers,
)
customer_ids = load_customer_ids(args.sample_file)
producer = make_producer(args.bootstrap)
logger.info(f"connected to {args.bootstrap}, topic={args.topic}, "
f"rate={args.rate}/s, dirty={args.dirty_rate*100:.1f}%")
# 그레이스풀 종료
stop = {"flag": False}
def handle(sig, _frame):
logger.info(f"signal {sig} received, stopping...")
stop["flag"] = True
signal.signal(signal.SIGINT, handle)
signal.signal(signal.SIGTERM, handle)
interval = 1.0 / args.rate if args.rate > 0 else 0.0
seq = 0
sent_clean = sent_dirty = sent_err = 0
start = time.time()
try:
while not stop["flag"]:
if args.duration and (time.time() - start) >= args.duration:
break
seq = (seq + 1) % 1000
is_dirty = random.random() < args.dirty_rate
ev = (gen_dirty if is_dirty else gen_clean)(customer_ids, seq)
try:
producer.send(args.topic,
key=ev.get("customer_id"),
value=ev)
if is_dirty:
sent_dirty += 1
else:
sent_clean += 1
except KafkaError as e:
sent_err += 1
logger.warning(f"send error: {e}")
total = sent_clean + sent_dirty
if total and total % 100 == 0:
el = time.time() - start
logger.info(
f"sent={total} clean={sent_clean} dirty={sent_dirty} "
f"err={sent_err} elapsed={el:.1f}s rate={total/el:.1f}/s"
)
if interval > 0:
time.sleep(interval)
finally:
logger.info("flushing remaining messages...")
producer.flush(timeout=10)
producer.close(timeout=10)
el = time.time() - start
total = sent_clean + sent_dirty
logger.info(
f"DONE total={total} clean={sent_clean} dirty={sent_dirty} "
f"err={sent_err} elapsed={el:.1f}s avg_rate={total/max(el,0.01):.1f}/s"
)
if __name__ == "__main__":
main()
PYEOF
chmod +x ~/spark-handson/streaming/gen_events.py
ls -l ~/spark-handson/streaming/gen_events.py
wc -l ~/spark-handson/streaming/gen_events.py짧은 실행 (10초간 초당 5건)
터미널 1 (Producer):
python ~/spark-handson/streaming/gen_events.py \
--rate 5 --duration 10 --dirty-rate 0.10
# (학습용으로 dirty-rate 10%로 올려 dirty 패턴 가시성 ↑)메시지 수신 확인 (Consumer)
kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic transactions-raw \
--from-beginning \
--max-messages 50 \
--timeout-ms 5000 \
| head -5dirty 데이터 패턴 분포 확인
kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic transactions-raw --from-beginning \
--max-messages 50 --timeout-ms 5000 2>/dev/null \
| grep '^{' \
| jq -r '._dirty // "clean"' \
| sort | uniq -cSpark Structured Streaming — Kafka Consume + 정제
- Spark Structured Streaming의 micro-batch 모델 이해.
- Kafka source(
format="kafka")에서 binary value를 JSON으로 파싱.- 명시적 스키마(StructType)로 타입 안전성 확보.
- 4종 dirty 패턴을 정제 로직으로 걸러낸다.
- 콘솔 sink로 적재 전 결과를 시각적으로 검증.
| 용어 | 정의 |
|---|---|
| Structured Streaming | DataFrame/Dataset API로 스트리밍 처리. 내부는 micro-batch. |
| Micro-batch | 일정 간격(trigger)으로 누적된 데이터를 한 번에 배치 처리. |
| Trigger | "언제 다음 배치를 실행할지". processingTime='5 seconds' / available now 등. |
| Source / Sink | 입력/출력. 우리는 Kafka → 최종 PG (7-2) / 검증용 console (7-1). |
| Schema-on-read | Kafka는 binary만 저장. consumer가 읽을 때 명시. |
from_json | JSON 문자열을 StructType 스키마에 따라 컬럼으로 펼침. |
foreachBatch | 각 micro-batch DataFrame에 임의 로직 적용 (7-2에서 사용). |
checkpointLocation | offset·메타데이터 저장 디렉터리. 재시작 시 정확히 끊긴 지점부터 재개. |
Micro-batch 모델
시간축 →
Trigger 1 (t=5s) Trigger 2 (t=10s) Trigger 3 (t=15s)
│ │ │
▼ ▼ ▼
┌────────┐ ┌────────┐ ┌────────┐
│ batch │ │ batch │ │ batch │
│ ID=0 │ │ ID=1 │ │ ID=2 │
│ 25 msg │ │ 27 msg │ │ 24 msg │
└────┬───┘ └────┬───┘ └────┬───┘
│ DataFrame │ DataFrame │ DataFrame
▼ ▼ ▼
[정제 로직] [정제 로직] [정제 로직]
│ │ │
▼ ▼ ▼
[Sink] [Sink] [Sink]
│ │ │
▼ ▼ ▼
checkpoint 갱신 checkpoint 갱신 checkpoint 갱신핵심: 매 trigger마다 받은 메시지가 정적 DataFrame. 이후 처리는 일반 Spark 연산과 동일.
Kafka source의 raw 스키마
spark.readStream.format("kafka")가 반환하는 DataFrame은 항상 다음 7개 컬럼.
| 컬럼 | 타입 | 의미 |
|---|---|---|
key | binary | Producer가 보낸 key (우리는 customer_id) |
value | binary | Producer가 보낸 value (우리는 JSON bytes) |
topic | string | 토픽 이름 |
partition | int | 파티션 번호 |
offset | long | 메시지의 offset |
timestamp | timestamp | broker가 메시지를 받은 시각 |
timestampType | int | timestamp의 의미 |
4종 dirty 패턴 정제 매핑
원본 메시지 (JSON)
│ CAST(value AS STRING) → from_json(payload, SCHEMA)
▼
struct<transaction_id, customer_id, timestamp, amount, category, status>
│ ① missing_field (category null) → IS NOT NULL 필터
│ ② negative_amount → amount >= 0 필터
│ ③ invalid_status → status IN (...) 필터
│ ④ unknown_customer → 7-2에서 화이트리스트로 차단
▼
정제된 DataFrame
│
▼
sink (7-1: 콘솔, 7-2: PostgreSQL)Kafka 패키지 사전 캐싱
cat > /tmp/cache_kafka_pg.py << 'PYEOF'
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("cache_kafka_pg").getOrCreate()
print("Kafka + PostgreSQL packages loaded")
spark.stop()
PYEOF
spark-submit \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.8,org.postgresql:postgresql:42.7.4 \
--conf spark.driver.memory=1g \
/tmp/cache_kafka_pg.py 2>&1 | grep -E "(SUCCESSFUL|downloaded|loaded|ERROR)"
# 캐시 확인 — Step 4-1과 같은 경로 패턴 (~/.ivy2/jars/, 평탄 구조)
ls -la ~/.ivy2/jars/ | grep -E "spark-sql-kafka|spark-token|kafka-clients|postgresql"정제 검증용 스크립트 (콘솔 sink)
cat > ~/spark-handson/streaming/streaming_console.py << 'PYEOF'
#!/usr/bin/env python3
"""
streaming_console.py — Section 7-1 검증용
Kafka transactions-raw 구독 → 정제 → 콘솔 출력.
"""
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json, to_timestamp
from pyspark.sql.types import StructType, StringType, DoubleType
KAFKA_BOOTSTRAP = "localhost:9092"
KAFKA_TOPIC = "transactions-raw"
VALID_STATUS = ["COMPLETED", "PENDING", "FAILED", "REFUNDED"]
PAYLOAD_SCHEMA = (
StructType()
.add("transaction_id", StringType())
.add("customer_id", StringType())
.add("timestamp", StringType())
.add("amount", DoubleType())
.add("category", StringType())
.add("status", StringType())
)
def main():
spark = (
SparkSession.builder
.appName("streaming_console")
.getOrCreate()
)
spark.sparkContext.setLogLevel("ERROR")
# 1) Kafka 소스 구독
raw = (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", KAFKA_BOOTSTRAP)
.option("subscribe", KAFKA_TOPIC)
.option("startingOffsets", "earliest") # 운영은 latest
.option("failOnDataLoss", "false")
.load()
)
# 2) JSON 파싱
parsed = (
raw
.select(
col("partition").alias("kafka_partition"),
col("offset").alias("kafka_offset"),
col("timestamp").alias("kafka_ts"),
from_json(col("value").cast("string"), PAYLOAD_SCHEMA).alias("p"),
)
.select("kafka_partition", "kafka_offset", "kafka_ts", "p.*")
)
# 3) 타입 변환 + 정제
cleaned = (
parsed
.withColumn("ts", to_timestamp(col("timestamp")))
.where(col("transaction_id").isNotNull())
.where(col("customer_id").isNotNull())
.where(col("ts").isNotNull())
.where(col("amount").isNotNull() & (col("amount") >= 0))
.where(col("category").isNotNull())
.where(col("status").isin(VALID_STATUS))
.select(
"transaction_id", "customer_id", "ts",
"amount", "category", "status",
"kafka_partition", "kafka_offset",
)
)
# 4) 콘솔 sink
query = (
cleaned.writeStream
.format("console")
.outputMode("append")
.option("truncate", "false")
.option("numRows", 10)
.trigger(processingTime="5 seconds")
.queryName("console_q")
.start()
)
print(f"[INFO] streaming started. trigger=5s, topic={KAFKA_TOPIC}")
print(f"[INFO] press Ctrl-C to stop")
query.awaitTermination()
if __name__ == "__main__":
main()
PYEOF
chmod +x ~/spark-handson/streaming/streaming_console.py두 터미널 실행 패턴
터미널 A: Producer
python ~/spark-handson/streaming/gen_events.py \
--rate 5 --duration 120 --dirty-rate 0.20터미널 B: Streaming consumer
spark-submit \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.8 \
--conf spark.driver.memory=2g \
~/spark-handson/streaming/streaming_console.pydirty 메시지가 사라진 게 보이는가? Producer는 dirty 20%를 보냈지만 콘솔엔 정상만. 즉 dirty는 정제 단계에서 모두 제거.
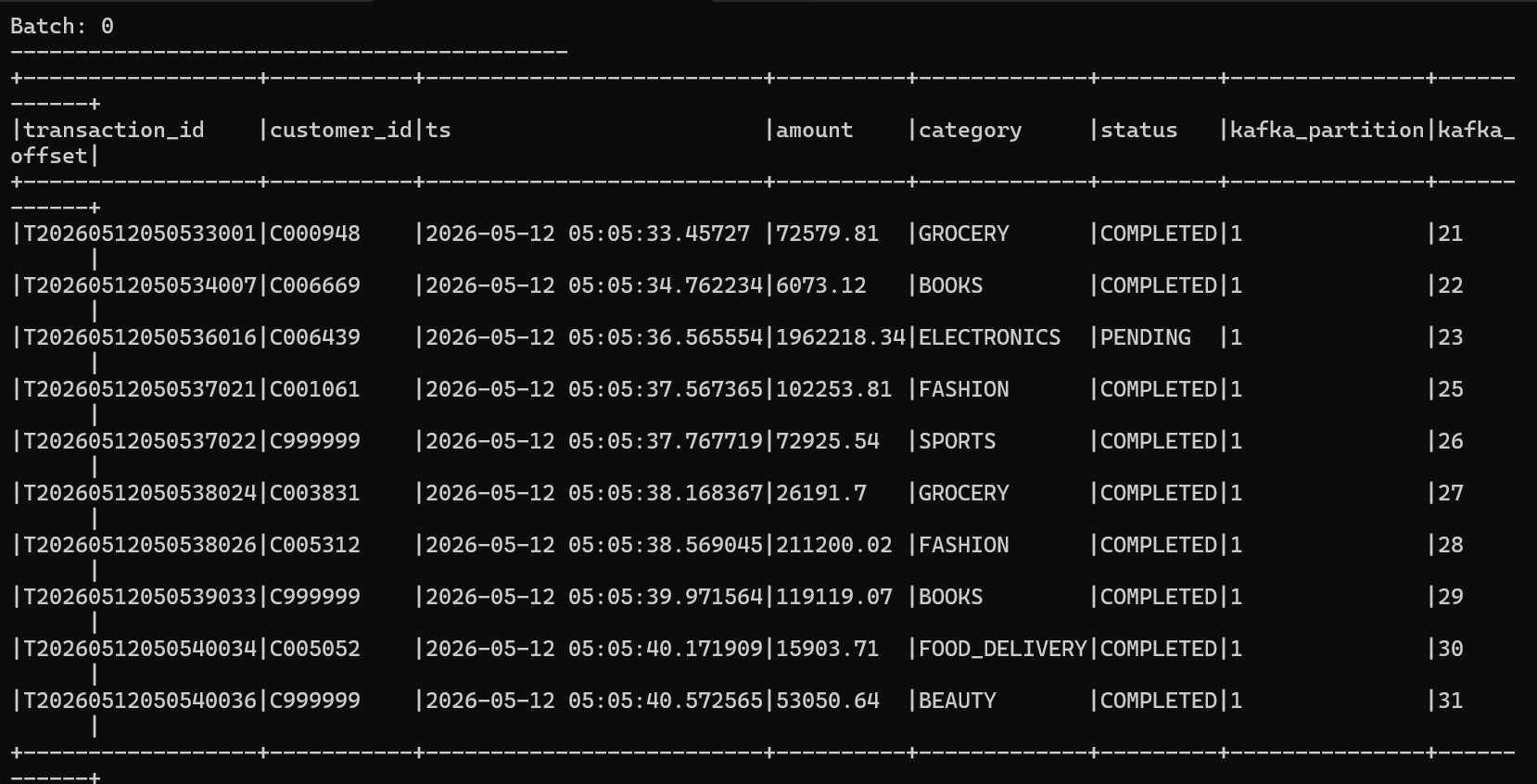
종료
터미널 B에서 Ctrl-C. graceful shutdown.
Spark Structured Streaming — foreachBatch + PostgreSQL 적재 + 체크포인트
foreachBatch로 micro-batch DataFrame을 JDBC로 적재.customers_dim화이트리스트로unknown_customer사전 차단.ON CONFLICT DO NOTHING패턴으로 멱등성 확보 (재처리 시 중복 PK 무시).checkpointLocation으로 정확히 끊긴 지점부터 재개 (exactly-once 효과).- 운영 환경 권장 옵션(
maxOffsetsPerTrigger, retry 정책) 적용.
| 용어 | 정의 |
|---|---|
foreachBatch(func) | 각 micro-batch의 DataFrame과 batchId를 인자로 사용자 함수 실행. |
| psycopg2 | Python의 PostgreSQL 클라이언트. UPSERT 쓸 때 사용. |
| UPSERT | INSERT ... ON CONFLICT (...) DO ... PostgreSQL 9.5+ 문법. |
| Checkpoint | offset, state, batch metadata 저장. 재시작 시 복구. |
| Exactly-once | 메시지가 sink에 정확히 1번 반영. (멱등 sink + checkpoint 조합) |
| Whitelist | 허용 대상만 통과. customers_dim에 있는 customer_id만. |
개념 설명: 화이트리스트 사전 차단 vs FK 거부
방어선 1: Spark에서 화이트리스트 (선제 차단)
df.join(customers_broadcast, "customer_id", "inner")
→ unknown_customer 메시지 사전 제거
방어선 2: PostgreSQL FK (최종 차단)
FOREIGN KEY (customer_id) REFERENCES customers_dim(customer_id)
→ 만에 하나 통과해도 INSERT 거부방어선 1만으로 거의 끝. 2는 안전망.
왜 broadcast? customers_dim 10,000건 (~1MB)은 작아서 모든 executor에 broadcast 가능. shuffle 없이 빠른 join.
개념 설명: ON CONFLICT DO NOTHING의 멱등성
INSERT INTO transactions_fact (transaction_id, customer_id, ts, amount, category, status)
VALUES (...)
ON CONFLICT (transaction_id) DO NOTHING;- 같은
transaction_id다시 들어오면 무시. - Streaming 재시작 후 일부 메시지가 재처리되어도 중복 안 됨.
- 이것이 Streaming의 "exactly-once 효과"의 핵심.
개념 설명: Checkpoint 동작
첫 실행:
Kafka offset 0 → batch 0 → PG 적재 → checkpoint 갱신 (offset=25)
Kafka offset 25 → batch 1 → PG 적재 → checkpoint 갱신 (offset=52)
...
재시작 (마지막 checkpoint=52):
Kafka offset 52 부터 재개
→ batch 마지막에 미완료 적재가 있어도 ON CONFLICT가 멱등성 보장Checkpoint 구조:
~/spark-handson/checkpoints/streaming_to_pg/
├── offsets/ ← 매 batch의 시작 offset
├── commits/ ← batch 완료 표시
├── sources/ ← Kafka source 메타
└── state/ ← (stateful 연산 시 사용; 본 가이드는 stateless)체크포인트 디렉터리는 절대 수동 삭제 X (의도적 reset 외엔). 삭제 시 처음부터 다시 처리 → 중복 가능.
psycopg2-binary 설치
pip install --quiet "psycopg2-binary>=2.9.0,<3.0.0"
python -c "import psycopg2; print('psycopg2', psycopg2.__version__)"streaming_to_pg.py 작성
cat > ~/spark-handson/streaming/streaming_to_pg.py << 'PYEOF'
#!/usr/bin/env python3
"""
streaming_to_pg.py — Section 7-2 본 적재 스크립트
Kafka → 정제 → customers_dim 화이트리스트 → PostgreSQL UPSERT.
checkpoint로 정확한 재시작 보장.
"""
import os
import sys
from pathlib import Path
import psycopg2
from psycopg2.extras import execute_values
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json, to_timestamp, broadcast
from pyspark.sql.types import StructType, StringType, DoubleType
# ── 설정 ────────────────────────────────────────────────────────────────
KAFKA_BOOTSTRAP = "localhost:9092"
KAFKA_TOPIC = "transactions-raw"
VALID_STATUS = ["COMPLETED", "PENDING", "FAILED", "REFUNDED"]
CHECKPOINT_DIR = os.path.expanduser("~/spark-handson/checkpoints/streaming_to_pg")
PAYLOAD_SCHEMA = (
StructType()
.add("transaction_id", StringType())
.add("customer_id", StringType())
.add("timestamp", StringType())
.add("amount", DoubleType())
.add("category", StringType())
.add("status", StringType())
)
# ── PG 접속 정보 (.pgpass 파싱) ─────────────────────────────────────────
def get_pg_password() -> str:
pgpass = Path.home() / ".pgpass"
if oct(pgpass.stat().st_mode)[-3:] != "600":
sys.exit("ERROR: ~/.pgpass permission must be 600")
for ln in pgpass.read_text().splitlines():
parts = ln.split(":")
if len(parts) == 5 and parts[3] == "handson":
return parts[4]
sys.exit("ERROR: handson entry missing in ~/.pgpass")
PG_HOST, PG_PORT = "127.0.0.1", 5432
PG_DB, PG_USER = "onestore", "handson"
PG_PASS = get_pg_password()
# ── customers_dim 화이트리스트 로드 ─────────────────────────────────────
def load_customer_whitelist(spark: SparkSession):
jdbc_url = f"jdbc:postgresql://{PG_HOST}:{PG_PORT}/{PG_DB}"
props = {"user": PG_USER, "password": PG_PASS,
"driver": "org.postgresql.Driver"}
df = (
spark.read.jdbc(jdbc_url,
"(SELECT customer_id FROM customers_dim) AS sub",
properties=props)
)
cnt = df.count()
print(f"[INFO] customers_dim whitelist loaded: {cnt} rows")
if cnt == 0:
sys.exit("ERROR: customers_dim is empty. Run Section 4 first.")
return df
# ── foreachBatch 함수 ───────────────────────────────────────────────────
def write_batch_to_pg(batch_df, batch_id):
"""매 micro-batch마다 호출."""
if batch_df.rdd.isEmpty():
print(f"[batch {batch_id}] empty, skip")
return
# Spark Driver로 행 수집 (batch당 보통 수십~수백건)
rows = batch_df.collect()
print(f"[batch {batch_id}] received {len(rows)} valid rows")
if not rows:
return
# psycopg2로 UPSERT
conn = None
try:
conn = psycopg2.connect(
host=PG_HOST, port=PG_PORT,
dbname=PG_DB, user=PG_USER, password=PG_PASS,
connect_timeout=5,
)
conn.autocommit = False
with conn.cursor() as cur:
data = [
(r.transaction_id, r.customer_id, r.ts,
float(r.amount), r.category, r.status)
for r in rows
]
sql = """
INSERT INTO transactions_fact
(transaction_id, customer_id, ts, amount, category, status)
VALUES %s
ON CONFLICT (transaction_id) DO NOTHING
"""
execute_values(cur, sql, data, page_size=500)
inserted = cur.rowcount
conn.commit()
print(f"[batch {batch_id}] inserted={inserted} (skip on conflict)")
except Exception as e:
if conn:
conn.rollback()
# 에러 raise → Spark가 batch를 retry. 너무 자주면 max retry 후 query 실패.
print(f"[batch {batch_id}] ERROR: {e}")
raise
finally:
if conn:
conn.close()
def main():
spark = (
SparkSession.builder
.appName("streaming_to_pg")
.getOrCreate()
)
spark.sparkContext.setLogLevel("ERROR")
# 1) 화이트리스트 (broadcast로 변환)
whitelist = broadcast(load_customer_whitelist(spark))
# 2) Kafka 소스
raw = (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", KAFKA_BOOTSTRAP)
.option("subscribe", KAFKA_TOPIC)
.option("startingOffsets", "latest") # 운영: latest
.option("failOnDataLoss", "false")
.option("maxOffsetsPerTrigger", 1000) # 백프레셔 보호
.load()
)
# 3) JSON 파싱 + 정제
parsed = (
raw.select(
from_json(col("value").cast("string"), PAYLOAD_SCHEMA).alias("p")
)
.select("p.*")
.withColumn("ts", to_timestamp(col("timestamp")))
.where(col("transaction_id").isNotNull())
.where(col("customer_id").isNotNull())
.where(col("ts").isNotNull())
.where(col("amount").isNotNull() & (col("amount") >= 0))
.where(col("category").isNotNull())
.where(col("status").isin(VALID_STATUS))
)
# 4) 화이트리스트 join (unknown_customer 차단)
cleaned = parsed.join(whitelist, "customer_id", "inner") \
.select("transaction_id", "customer_id", "ts",
"amount", "category", "status")
# 5) foreachBatch sink
query = (
cleaned.writeStream
.foreachBatch(write_batch_to_pg)
.option("checkpointLocation", CHECKPOINT_DIR)
.trigger(processingTime="10 seconds")
.queryName("kafka_to_pg")
.start()
)
print(f"[INFO] streaming started")
print(f"[INFO] checkpoint: {CHECKPOINT_DIR}")
print(f"[INFO] press Ctrl-C to stop gracefully")
query.awaitTermination()
if __name__ == "__main__":
main()
PYEOF
chmod +x ~/spark-handson/streaming/streaming_to_pg.py
ls -l ~/spark-handson/streaming/streaming_to_pg.pyProducer
Streaming → PG
PG에서 실시간 적재 확인

checkpoint 디렉터리 확인

재시작 검증 (exactly-once 효과)
터미널 B에서 Ctrl-C → 30초 대기 → 같은 명령으로 재실행.
# 재실행 전 PG의 전체 행 수
COUNT_BEFORE=$(psql -tAc "SELECT COUNT(*) FROM transactions_fact")
echo "before restart: $COUNT_BEFORE"
# 30초간 더 실행 후 종료, 다시 행 수 확인
# (재시작 시 [INFO] starting from checkpoint ... 로그 보임)예상: checkpoint 덕분에 끊긴 지점에서 재개. 약간의 중복은 ON CONFLICT가 흡수.


적재 데이터 검증 SQL
psql << 'SQL'
\echo '== 전체 행 수 =='
SELECT COUNT(*) FROM transactions_fact;
\echo '== status별 분포 =='
SELECT status, COUNT(*) FROM transactions_fact GROUP BY status ORDER BY 2 DESC;
\echo '== 가장 활발한 고객 5명 =='
SELECT customer_id, COUNT(*) AS tx_count, SUM(amount) AS total_spent
FROM transactions_fact
GROUP BY customer_id
ORDER BY tx_count DESC
LIMIT 5;
\echo '== category별 평균 금액 =='
SELECT category, COUNT(*) AS n, ROUND(AVG(amount)::numeric, 0) AS avg_amount
FROM transactions_fact
GROUP BY category
ORDER BY avg_amount DESC;
\echo '== 최근 1분간 처리량 =='
SELECT COUNT(*) AS recent_count
FROM transactions_fact
WHERE ingested_at >= NOW() - INTERVAL '1 minute';
SQL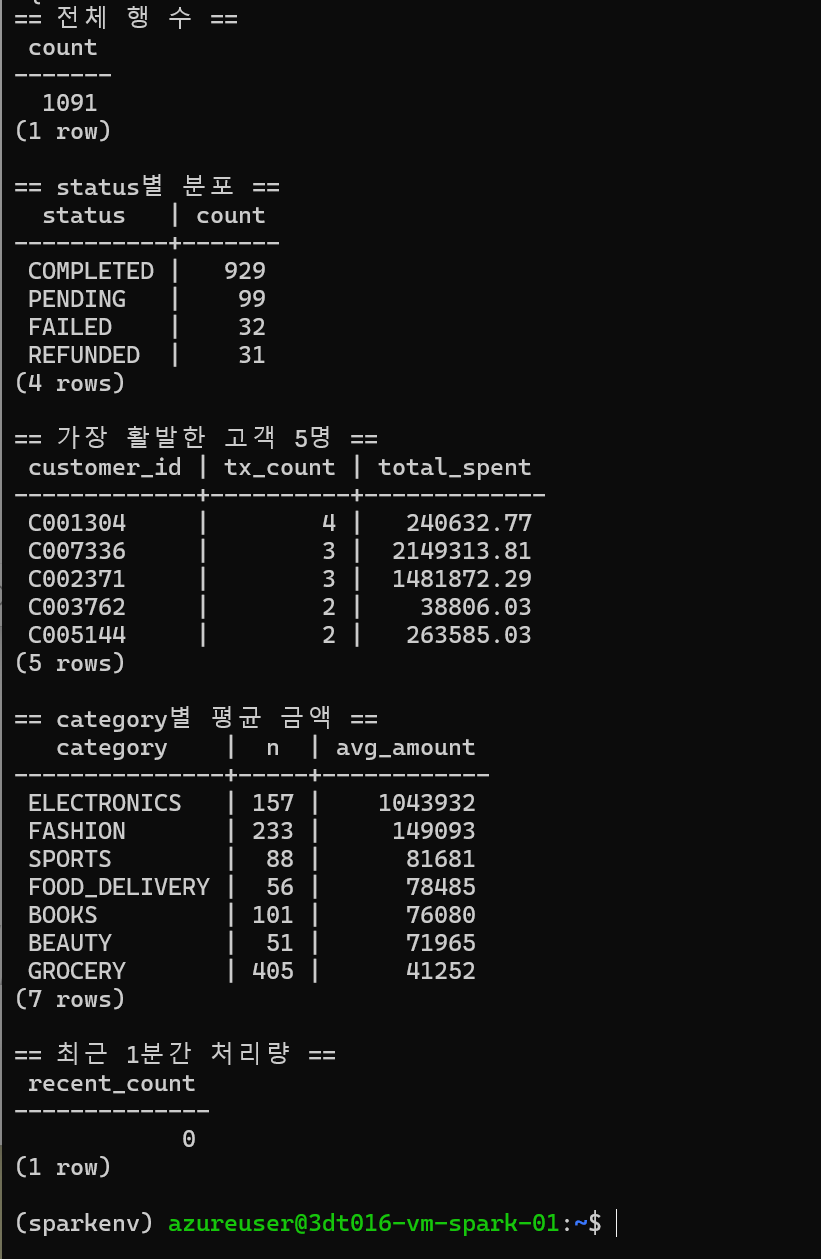
cron
| 항목 | cron | Airflow |
|---|---|---|
| 설치 | OS에 기본 내장 | 별도 설치 (DB·webserver·scheduler·worker) |
| 메모리 | < 10MB | 1.5~3GB 이상 |
| 잡 정의 | 1줄 (m h dom mon dow command) | Python DAG 파일 (수십~수백 줄) |
| 재시도 | 직접 구현 (wrapper에 retry 로직) | 빌트인 (retries, retry_delay, exponential backoff) |
| 잡 의존성 | 없음 (시간으로 순서 강제) | DAG 그래프로 명시 (A → B → C) |
| 백필 (backfill) | 없음 | airflow dags backfill 한 줄 |
| 부분 실패 복구 | 잡 전체 재실행 | 실패한 task만 재실행 |
| 모니터링 UI | 없음 (로그 파일 직접) | 웹 UI, 시각화, SLA 알림 |
| 알림 | 직접 구현 (mail, webhook) | EmailOperator, SlackOperator 등 빌트인 |
| 분산 실행 | 없음 (단일 호스트) | CeleryExecutor·KubernetesExecutor |
| 시각화 | 없음 | Gantt, Graph, Calendar 뷰 |
| 학습 곡선 | 30분 | 며칠~몇 주 |
| 운영 비용 | 거의 0 | 별도 클러스터 운영 |
cron으로 충분한 경우
다음 모두 해당하면 cron 유지.
- 잡 수 < 10개
- 잡 의존성 없음 (또는 시간 순서로 강제 가능)
- 모든 잡의 실행 시간 < 다음 호출 간격 (락으로 보강)
- 실패 시 다음 회차 재실행으로 충분 (즉시 복구 불요)
- 단일 호스트에서 처리 가능
- 한국 시간 기준 일정한 시각으로 충분 (윈도우·캘린더 복잡도 없음)
Airflow가 필요한 시점
다음 신호가 하나라도 등장하면 Airflow(또는 Dagster, Prefect) 도입 고려.
| 신호 | 예시 | Airflow 해결책 |
|---|---|---|
| DAG 의존성 | "추출 끝나면 변환, 변환 끝나면 적재, 적재 끝나면 알림" | Operator chaining (A >> B >> C) |
| 잡 수 증가 | 매일 50개 이상의 잡, 일부는 매시간·일부는 매일 | DAG 단위 관리, 폴더 구조 |
| 부분 실패 | 5단계 ETL 중 3단계 실패 시 1·2를 재실행하기 싫음 | task 단위 재실행 |
| 백필 | "지난 30일치 다시 돌려야 함" | backfill --start-date ... |
| 동적 분기 | 입력 크기에 따라 다른 처리 경로 | Branch Operator |
| 다른 시스템 트리거 | "Kafka 메시지 수가 임계 초과 시 잡 실행" | Sensor (Kafka·HTTP·File) |
| 알림 통합 | 실패 시 Slack·PagerDuty | EmailOperator·SlackWebhook |
| SLA 추적 | "이 잡은 30분 안에 완료해야 함" | sla 파라미터 + 알림 |
| 분산 실행 | 한 호스트로 부족 | Celery·Kubernetes Executor |
Phase 1 :
cron + bash wrapper (락·메모리 가드·로그)
→ Part 3 수준에 적합
Phase 2:
cron + Python orchestrator
- 더 복잡한 wrapper (DB로 잡 상태 추적)
- Slack 알림
→ 잡 수 5~15개
Phase 3:
Airflow (LocalExecutor, single host)
- DAG, retry, UI
→ 잡 수 15~50개, 의존성 등장
Phase 4:
Airflow (CeleryExecutor 또는 KubernetesExecutor)
- 분산 워커
→ 50개 이상, 멀티 팀kafka 다중 브로커
현재 (단일):
┌─────────┐
│ broker1 │ partitions: P0, P1, P2 (모두 leader)
└─────────┘ replication: 1
확장 (3 broker, RF=3):
┌─────────┐ ┌─────────┐ ┌─────────┐
│ broker1 │ │ broker2 │ │ broker3 │
│ P0 (L) │ │ P1 (L) │ │ P2 (L) │
│ P2 (F) │ │ P0 (F) │ │ P0 (F) │
│ P1 (F) │ │ P2 (F) │ │ P1 (F) │
└─────────┘ └─────────┘ └─────────┘
L=Leader, F=Follower (replica)도입 시 필요한 작업:
- 추가 VM 2대 또는 컨테이너
- 모든 broker가 같은 controller quorum 공유 (
controller.quorum.voters=1@host1:9093,2@host2:9093,3@host3:9093) - 토픽 재생성 또는
kafka-reassign-partitions.sh로 replication 추가 min.insync.replicas=2(3 broker, RF=3 권장)- Producer
acks=all(이미 본 가이드 적용)
Spark 분산 모드
현재 (local):
spark-submit --master local[*]
→ driver = executor = 한 JVM
→ 메모리 = VM RAM
확장 옵션:
① Spark Standalone Cluster
spark-submit --master spark://master:7077 \
--deploy-mode cluster \
--executor-memory 4g --executor-cores 2 \
--num-executors 5
→ 별도 master + worker 노드 (Spark 자체 클러스터 매니저)
② Kubernetes
spark-submit --master k8s://https://... \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=...
→ Pod로 동적 executor 생성·소멸
③ YARN (Hadoop 환경)
spark-submit --master yarn --deploy-mode cluster
→ 기존 Hadoop 클러스터 자원 활용Delta Lake 도입
Parquet의 한계 → Delta Lake로 ACID·time travel.
| 기능 | Parquet (현재) | Delta Lake |
|---|---|---|
| ACID 트랜잭션 | 없음 (실패 시 부분 파일) | 있음 (_delta_log로 commit) |
| Time Travel | 없음 | VERSION AS OF / TIMESTAMP AS OF |
| Schema Evolution | 수동 (파일 재생성) | MERGE SCHEMA 자동 |
| Upsert (MERGE) | 없음 | MERGE INTO ... WHEN MATCHED ... |
| Optimize·Z-order | 없음 | 빌트인 |
| Streaming + Batch 통합 | 어려움 | "Lambda 통합" |
전환 예시
# Streaming sink를 Delta로 변경
parsed.writeStream \
.format("delta") \
.option("checkpointLocation", "/.../checkpoints/delta") \
.start("/.../delta/transactions_fact")
# UPSERT (배치 추론에서 사용 가능)
from delta.tables import DeltaTable
delta_pred = DeltaTable.forPath(spark, "/.../delta/ml_predictions")
delta_pred.alias("p").merge(
new_pred.alias("n"),
"p.customer_id = n.customer_id"
).whenMatchedUpdate(set={...}).whenNotMatchedInsert(values={...}).execute()도입 비용: --packages io.delta:delta-spark_2.12:3.0.0. PostgreSQL은 그대로 두고, 분석·아카이브 레이어를 Delta로 분리하는 패턴이 일반적.
Schema Registry
현재 Producer가 임의 JSON. → 스키마 레지스트리로 contract 강제.
Producer Schema Registry Consumer
│ ▲ │
│ schema_id 조회 │ ┌─schemas:─┐ │
├────────────────▶│ │ v1: ... │ │
│ │ │ v2: ... │ │
│ │ └─────────┘ │
│ msg = schema_id + binary payload │
├──────────────────────────────────────▶│
│
schema_id로 deserialize대표 옵션:
- Confluent Schema Registry: Avro 표준
- Apicurio: Avro/Protobuf/JSON Schema 다 지원, Apache 2.0
- Karapace: Apache 2.0, Confluent 호환
장점:
- 호환성 검증 (BACKWARD/FORWARD/FULL)
- Producer/Consumer 독립 진화
- 메시지 크기 절감 (스키마 미포함, ID만)
Dead-Letter Topic
현재 정제 실패 메시지는 where(...) 필터로 폐기. → 별도 토픽에 보관해 분석.
┌───── valid → transactions_fact
│
[정제 분기] ┤
│
└───── invalid → transactions-dlq (dead-letter)구현 패턴:
# foreachBatch 내부
valid = batch_df.filter(...).cache()
invalid = batch_df.exceptAll(valid).cache()
# valid → PG
write_to_pg(valid)
# invalid → Kafka dead-letter 토픽 (또는 PG 별도 테이블)
invalid.selectExpr("CAST(transaction_id AS STRING) AS key",
"to_json(struct(*)) AS value") \
.write.format("kafka") \
.option("topic", "transactions-dlq") \
.save()dead-letter 분석으로 Producer 버그·외부 시스템 변경 조기 탐지.
모니터링 스택 (Prometheus + Grafana)
현재 사람이 SQL·CLI로 조회 → 자동 메트릭 수집·시각화·알림.
┌────────────────────────────────────────────────────────┐
│ ① 메트릭 노출 (각 컴포넌트 → /metrics endpoint) │
│ - PG : postgres_exporter │
│ - Kafka : JMX exporter │
│ - Spark : spark.metrics.conf │
│ - Node : node_exporter (메모리·디스크·CPU) │
│ - 사용자정의 : pushgateway │
└────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────┐
│ ② Prometheus (시계열 DB) - 주기적 scrape, 저장 │
└────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────┐
│ ③ Grafana (시각화) - 대시보드, 알림 룰 │
└────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────┐
│ ④ Alertmanager - Slack·PagerDuty·Email │
└────────────────────────────────────────────────────────┘확장 우선순위 (현재 → 운영으로 가려면)
다음 순서를 권장:
- Schema Registry — 데이터 contract 강제
- Dead-Letter — 실패 분석·신뢰도 향상
- Prometheus + Grafana — 정량 모니터링
- PG replica + 백업 자동화 — 데이터 안전성
- Kafka 3-broker — Kafka 장애 내성
- Spark 분산 — 처리량이 한계 도달 시
- Delta Lake — 분석 레이어 분리 시
쇼핑몰 인프라 핵심 기술 정리
Elasticsearch
왜 사용하는가?
RDBMS는 일반적인 CRUD에는 강하지만 검색 엔진 역할에는 한계가 있다.
예를 들어:
LIKE '%맥북%'같은 쿼리는 인덱스를 제대로 활용하지 못해 대규모 데이터에서 매우 느려진다.
특히 쇼핑몰에서는:
- 상품 10억 건 규모
- 한국어 형태소 분석
- 오타 보정
- 카테고리 + 가격 + 태그 조합 검색
- 검색어 적합도 순 정렬
등이 필요하기 때문에 Elasticsearch를 별도로 둔다.
Elasticsearch의 핵심 특징
1. 역색인(Inverted Index)
일반 DB:
문서 → 단어Elasticsearch:
단어 → 문서형태로 저장한다.
즉:
"맥북"이라는 단어가 들어간 문서 목록을 미리 만들어두기 때문에 검색이 매우 빠르다.
2. 형태소 분석
한국어는 띄어쓰기·조사·어미 변화가 많다.
예:
노트북을
노트북이
노트북용Elasticsearch는:
- Nori
- Mecab-ko
같은 분석기를 통해 단어를 분리하고 정규화할 수 있다.
3. Relevance Score
단순 포함 여부가 아니라:
검색어와 얼마나 관련 있는가를 계산해 정렬한다.
예:
- 제목에 포함 → 점수 높음
- 설명에만 포함 → 점수 낮음
CDC (Change Data Capture)
문제:
상품 DB와 Elasticsearch 데이터를 어떻게 동기화할 것인가?직접 애플리케이션 코드에서:
- DB 저장
- ES 저장
둘 다 처리하면 결합도가 커진다.
Debezium + Kafka 구조
MySQL binlog
↓
Debezium
↓
Kafka
↓
ElasticsearchDebezium 역할
DB binlog를 읽어:
- INSERT
- UPDATE
- DELETE
변경 이벤트를 추출한다.
즉:
DB 변경사항을 이벤트로 변환하는 역할이다.
Kafka 역할
변경 이벤트를 버퍼링·전달한다.
장점:
- 대량 이벤트 처리 가능
- Consumer 분리 가능
- 재처리 가능
Redis
Redis를 사용하는 이유
Redis는 메모리 기반 저장소이다.
특징:
- 매우 빠름
- 읽기 TPS 높음
- 단순 조회에 강함
쇼핑몰처럼:
- 조회량은 많고
- 데이터 변경은 상대적으로 적은
환경에 매우 적합하다.
Redis 캐시 전략
이 자료에서는:
모든 데이터를 동일하게 캐싱하지 않는다는 점이 중요하다.
데이터 성격에 따라 전략을 다르게 가져간다.
1. 메인 페이지 상품
특징:
- 모든 사용자 동일 데이터
- 1시간마다 갱신
전략:
Write-Through
TTL 1시간Write-Through
DB 업데이트 시:
- Redis도 같이 갱신
즉:
데이터 생성 시 캐시도 함께 생성하는 방식.
TTL(Time To Live)
캐시에 만료 시간을 둔다.
1시간 후 자동 삭제이 자료에서는:
- 매시간 배치 실행
- Redis 갱신
- TTL 1시간
전략을 사용한다.
2. 카테고리 트리
특징:
- 거의 안 바뀜
- 변경 시 즉시 반영 필요
전략:
Read-Through
+ Explicit InvalidateRead-Through
조회 시:
- Redis 확인
- 없으면 DB 조회
- Redis 저장
Explicit Invalidate
관리자가 카테고리를 수정하면:
캐시를 직접 삭제한다.
즉 TTL만 믿지 않고:
- 변경 이벤트 기반으로 캐시 제거
전략을 사용한다.
3. 평점·리뷰 수
문제:
리뷰 작성마다 평균 계산을 하면:
- 락 경합
- DB 부하
문제가 생긴다.
해결 전략
30분 배치 집계
→ Redis 저장즉:
- 실시간 정확성보다
- 안정성과 성능
을 우선한다.
메시지 큐(Message Queue)
왜 필요한가?
주문 API는 빠르게 응답해야 한다.
하지만:
- 이메일 발송
- 판매자 알림
은 느릴 수 있다.
이걸 동기로 처리하면:
- 응답 지연
- 타임아웃
이 발생한다.
비동기 처리 구조
주문 API
↓
Message Queue
↓
Worker핵심 아이디어:
"일단 큐에 넣고 응답 먼저"이다.
Queue의 장점
1. 트래픽 평탄화(Traffic Smoothing)
순간 TPS 급증을 큐가 흡수한다.
2. 시스템 분리
주문 시스템과 알림 시스템이 독립된다.
3. 재시도 가능
실패 메시지는:
- 재시도
- DLQ(Dead Letter Queue)
로 관리 가능하다.
SQS vs RabbitMQ vs Kafka
SQS
특징:
- AWS 관리형
- 운영 부담 적음
- DLQ 기본 제공
이 자료에서는:
- 이메일
- 판매자 알림
같은 단순 비동기에 적합하다고 평가했다.
RabbitMQ
특징:
- 복잡한 라우팅 가능
- 낮은 지연시간
단점:
- 직접 운영 필요
Kafka
특징:
- 초고성능 이벤트 스트리밍
- 이벤트 재처리 가능
- CDC와 매우 잘 맞음
하지만:
- 운영 복잡도 높음
- 단순 큐 용도로는 과함
이라는 특징이 있다.
Hot / Warm / Cold 아카이빙
핵심 아이디어
모든 데이터를 비싼 DB에 둘 필요는 없다.
대부분 오래된 데이터는 거의 조회되지 않는다.
계층 분리
HOT
최근 30일- RDS
- 빠른 조회
- 고비용
WARM
30일 ~ 2년- 샤딩 DB
- 일부 인덱스 유지
COLD
2년 ~ 5년- S3 Parquet
- Athena 조회
특징:
- 저비용
- 느린 조회 허용
