
개요
RDBMS 를 사용하는 고전적인 프로그래밍 방식은 프로그램 실행 초기에 커넥션(connection) 을 열고 특정 SQL 을 처리하기 위한 커서(cursor) 를 생성한 다음 커서의 실행 결과를 페치(fetch) 하여 처리하고 커넥션을 닫는 순서로 작성되곤 했습니다.
문제는 커넥션을 맺거나 끊는 작업이 DBMS 입장에서는 상당히 무겁고 큰 비용이 발생하는 작업이라는 것입니다. 그래서 보통 일정 갯수이상의 커넥션을 미들웨어나 WAS 등에 커넥션 풀(Connection Pool) 형태로 만들어 두고 필요할 때마다 커넥션을 열고 닫는 것이 아니라 커넥션 풀에서 커넥션을 획득/반납하게 합니다.
RDBMS 와 WAS 등의 미들웨어간에는 항상 커넥션이 유지되기 때문에 커넥션 생성 및 제거에 시스템 자원을 소모할 필요가 없어 성능이 향상되는 효과가 있었습니다.
서버리스(Serverless) 아키텍처와 같이 경량의 코드(Code)로 구성된 프로그램에서 WAS 의 커넥션 풀을 사용하거나 직접 DBMS 커넥션을 열고 닫는 방식은 매우 비효율적입니다.
SingleStore 에는 이런 경량화된 DB 접근 방식을 지원하기 위한 Data API가 있어 http 또는 https 프로토콜 위에 SQL 을 실어 전송하고 결과를 JSON 으로 반환받아 빠르고 간편하게 처리할 수 있도록 지원합니다.
https://docs.singlestore.com/db/v7.8/en/reference/data-api.html
Data API 구조
SingleStore Data API 를 활성화하면 websocket_proxy 라는 프로세스가 실행되며 이 프로세스가 SingleStore Aggregator Node 에서 소켓 커넥션(Socket Connection) 을 풀(Pool) 형태로 맺고 있습니다.
Client 에서 http request 로 Data API 를 호출하면 websocket_proxy 가 http server 및 로드밸런서 역할을 수행하면서 SQL 을 SingleStore Server 에게 전달하고 추후 결과를 Client 에게 리턴하는 역할을 수행합니다.
Data API 활성화
Data API 를 활성화하기 위해 http_api 및 http_proxy_port 의 두가지 engine variable 을 추가합니다.
먼저 sdb-admin list-nodes 를 수행하여 Aggregator Node 의 MemSQL ID 를 확인합니다.
sdb-admin list-nodes
Master Aggregator 의 MemSQL ID 를 확인 후 변수를 추가합니다.
http_proxy_port : 3305
http_api : on
sdb-admin update-config --memsql-id 4769FA3E41 --set-global --key http_proxy_port --value 3305
sdb-admin update-config --memsql-id 4769FA3E41 --set-global --key http_api --value on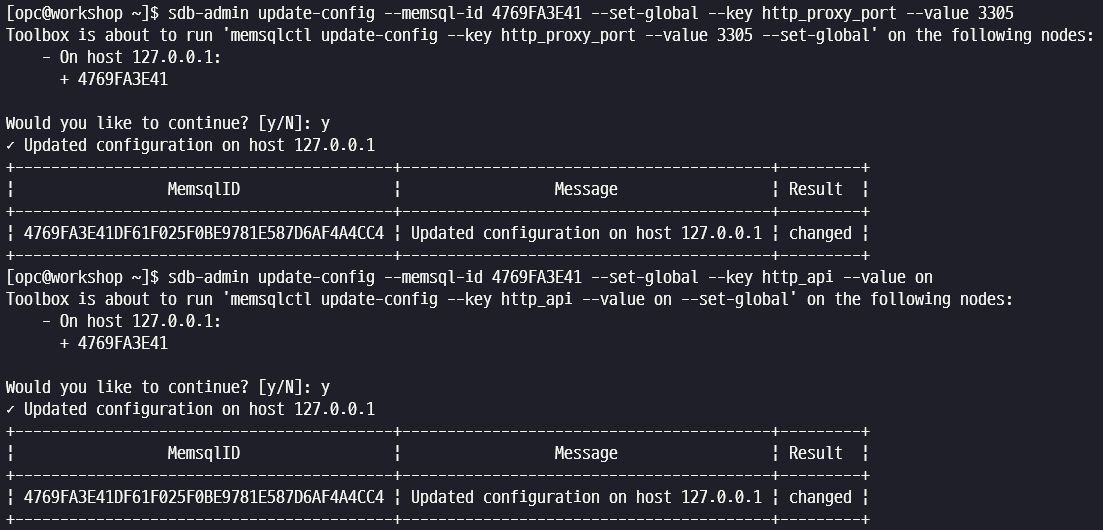
singlestore client 에 접속한 후 restart proxy 명령어를 수행하여 websocket_proxy 프로세스를 기동합니다.
$ singlestore -p
restart proxy;
\! ps -ef | grep websocket_proxy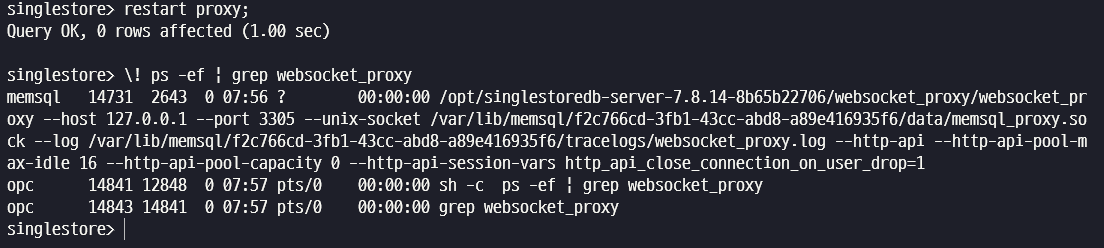
Data API 가 제대로 동작하는지 curl 명령어로 간단하게 테스트합니다.
$ curl -s -u "root:1234" -H "Content-Type: application/json" \
--data '{"sql": "SELECT * FROM airline where airline_id = (?)", "args": [1], "database": "airportdb"}' \
http://localhost:3305/api/v2/query/rows | jq .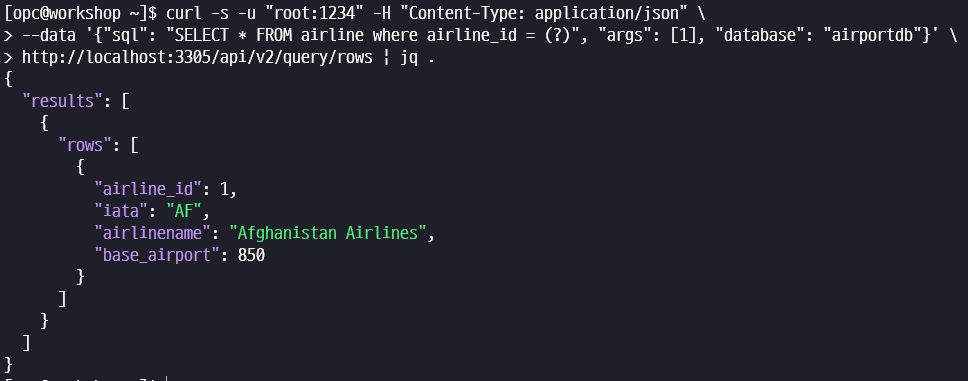
Data API 간단 성능 테스트
Data API 의 간단한 성능을 테스트하기 위해 Grafana k6 를 이용하도록 하겠습니다.
Grafana k6 설치
sudo yum install -y https://dl.k6.io/rpm/repo.rpm
sudo yum install -y --nogpgcheck k6성능테스트용 테이블 생성
다음 SQL 을 실행하여 테스트 테이블을 생성합니다.
- colemp 테이블은 100만건의 row를 생성하여 저장합니다.
- colemp_logging 테이블은 colemp 에서 조회한 데이터를 로깅(logging)하는 용도로 사용합니다.
$ singlestore -p
use airportdb
CREATE TABLE colemp (
empno BIGINT,
ename VARCHAR(255),
PRIMARY KEY(empno) USING HASH,
SORT KEY(empno),
SHARD KEY(empno)
);
WITH t as (
SELECT ROW_NUMBER() OVER () as n
FROM TABLE(CREATE_ARRAY(1000000):>ARRAY(bigint))
)
INSERT INTO colemp SELECT n as empno, CONCAT('emp',LPAD(n,6,'0')) as ename FROM t;
CREATE TABLE colemp_logging (
empno BIGINT,
ename VARCHAR(255),
ts TIMESTAMP(6),
PRIMARY KEY(empno, ts) USING HASH,
SORT KEY(empno),
SHARD KEY(empno)
);k6 테스트용 스크립트 작성
- data-api.js
colemp 에서 empno 를 random 으로 조회하여 반환받은 json 데이터를 파싱하여 empno, ename 을 추출한 뒤 empno_insert 테이블에 현재 시간과 함께 로깅하는 구조입니다.
import encoding from 'k6/encoding';
import http from 'k6/http';
import { check } from 'k6';
const username = 'root';
const password = '1234';
// username, password 를 base64 로 encoding
const hostname = '127.0.0.1'
const data_api_port = '3305'
const db = "airportdb"
const credentials = `${username}:${password}`;
const encodedCredentials = encoding.b64encode(credentials);
// Aggregator node 로의 data api 호출 url
const url1 = `http://${hostname}:${data_api_port}/api/v2/query/rows`;
const url2 = `http://${hostname}:${data_api_port}/api/v2/exec`;
// HTTP Post 방식으로 전달할 Header 설정 : Authentication / Content-type
const params = {
auth: "basic",
headers: {
"Authorization": `Basic ${encodedCredentials}`,
'Content-Type': 'application/json',
},
};
export default function () {
// HTTP Post 방식으로 전달할 SELECT SQL Payload 설정
const empno = Math.floor(Math.random() * 1000000 + 1)
const payload1 = JSON.stringify({
sql: "SELECT * FROM colemp WHERE empno = (?)",
args: [empno],
database: db,
});
// http post 방식으로 SELECT 호출
let res1 = http.post(url1, payload1, params);
// ********************************************
// 조회 성능만 체크하고 싶으면 이하 라인 주석처리 필요
// ********************************************
// 응답받은 JSON Data Parsing 및 변수 저장
let emp = JSON.parse(res1.body);
const new_empno = emp.results[0].rows[0].empno;
const new_ename = emp.results[0].rows[0].ename;
// HTTP Post 방식으로 전달할 INSERT SQL Payload 설정
const payload2 = JSON.stringify({
sql: "INSERT INTO colemp_logging values (?, ?, now())",
args: [new_empno, new_ename],
database: db,
});
// http post 방식으로 INSERT 호출
let res2 = http.post(url2, payload2, params);
// 필요시 Data 확인
//console.log(res2.body);
}k6 간단 성능 테스트
k6 를 실행하여 간단한 Data API 성능을 테스트합니다.
-u : 동시접속 세션 수
-d : 테스트 지속 시간
k6 run -u 20 -d 60s data-api.js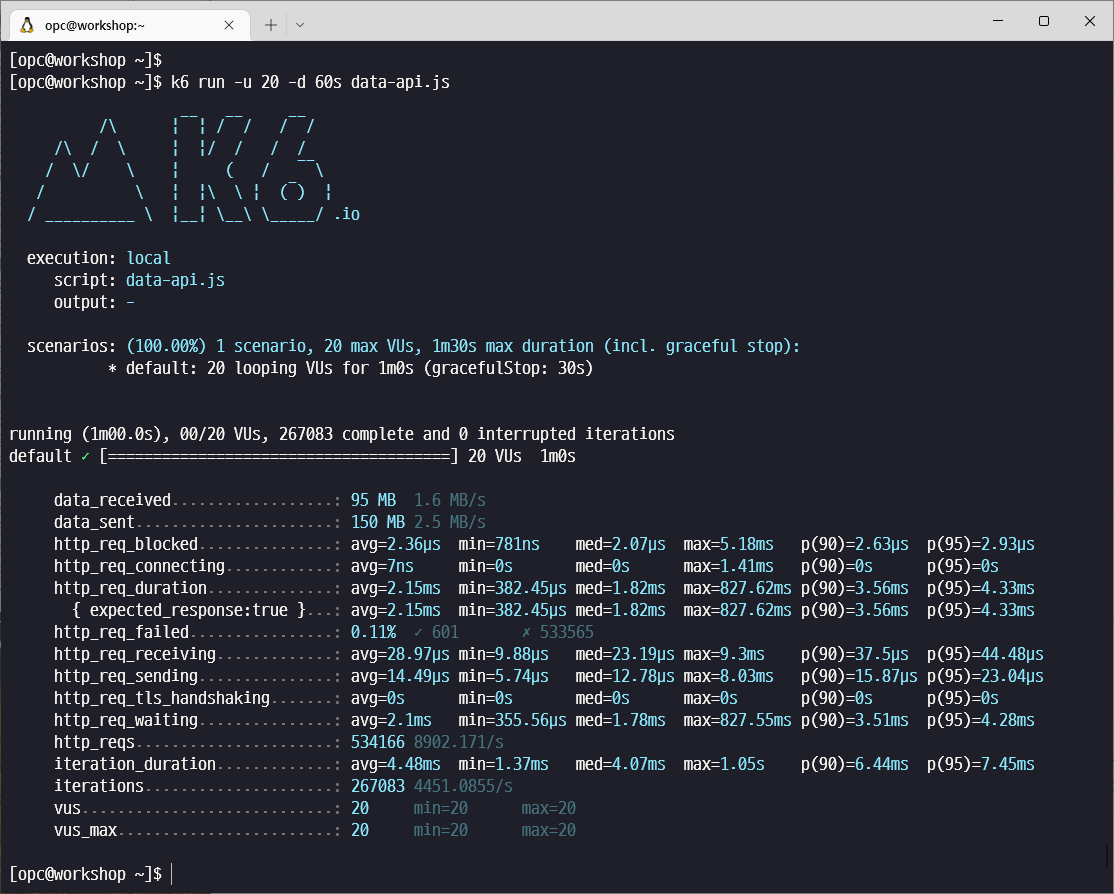
한번의 iteration 에 2개의 http request 가 전달되도록 스크립트를 작성했으므로 http_reqs 는 iterations 의 2배로 기록됩니다.
20개의 동시 세션에서 수행했을 때 초당 4451 회의 스크립트 수행이 가능했습니다.
동시 세션수와 스크립트를 변경해서 여러번 테스트한 결과는 다음과 같습니다.
상당히 작은 크기의 동일 장비에서 k6 테스트와 SingleStore 의 모든 Node 운영이 동시에 실행되기 때문에 10여개 이상의 동시 세션으로 테스트 수행시 CPU 사용률이 상당히 높습니다. 따라서 이번 간단 테스트에서는 동시 세션수를 높여도 성능 개선 효과를 뚜렷하게 확인할 수는 없었습니다.
| Iterations/sec 동시 세션수 | Select/Insert | Select Only |
|---|---|---|
| 10 | 3934 | 6901 |
| 20 | 4451 | 7676 |
| 30 | 4449 | 7698 |
마무리
SingleStore Data API 를 활성화하고 K6 및 Data API를 이용하여 간단하게 데이터 조회 및 Insert 작업을 수행하는 스크립트를 수행해 보았습니다.
Data API 는 MSA(Micro Service Architecture) 및 서버리스 아키텍쳐에서 Stateless http request 를 이용하여 SingleStore 접속 및 DML 처리를 용이하게 수행시킬 수 있도록 하여 활용도가 매우 높은 기능이라고 판단됩니다.
