
Query 성능 비교
이제 설치한 각 데이터베이스 별로 동일한 Query 를 수행하여 성능을 비교해 보겠습니다. 각 Query 는 Parsing 및 Buffer Cache miss 등의 성능상 오버헤드를 제거하고자 두 번씩 연속으로 수행하고 두번째 수행 결과를 확인합니다.
Query #1, Query #3, Query #4 는 MySQL Heatwave Quickstart Page 에서 예제로 사용하는 Query 이고 Query #2 는 Query #1 에서 필터 조건을 추가했습니다.
https://dev.mysql.com/doc/heatwave/en/airportdb-quickstart.html
현재 장비의 사양은 8vCPU, 16GB Memory 입니다.
32GB Memory 사양에서의 동일한 테스트 결과는 아래 링크에서 확인할 수 있습니다.
https://velog.io/@runway053/SingleStoreDB-PostgreSQL-MySQL-간단-조회-성능-비교
Query #1
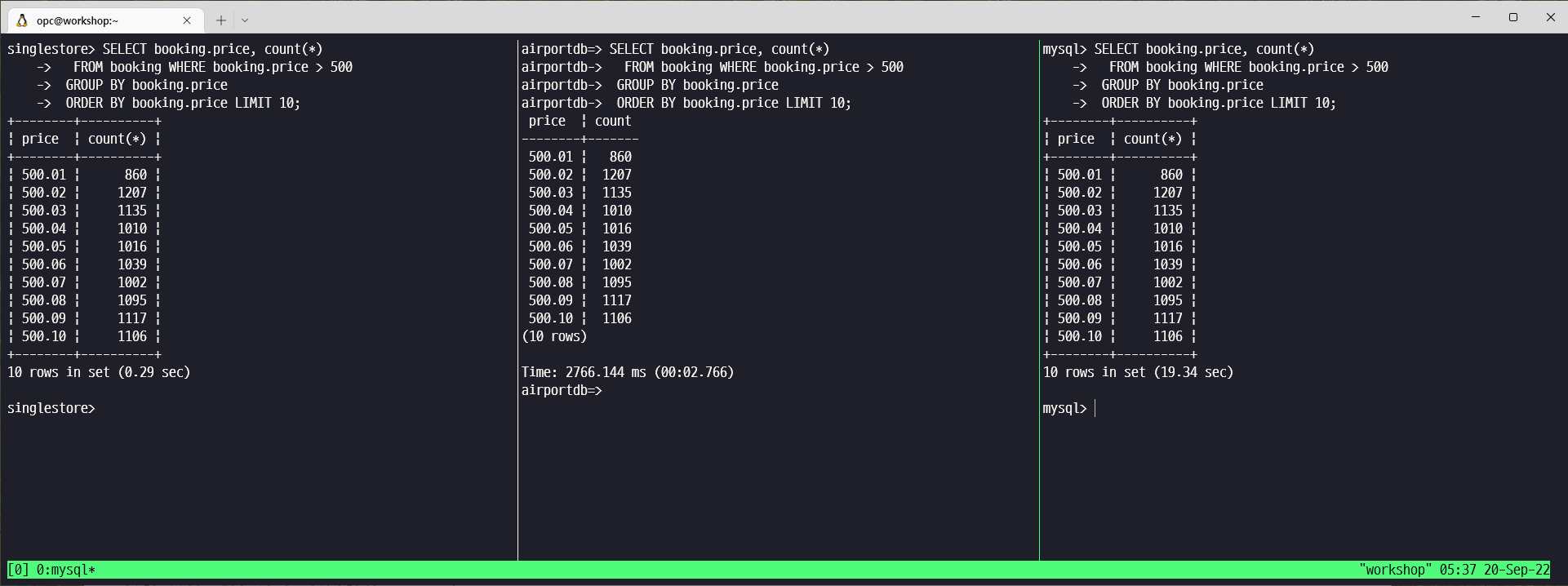
SELECT booking.price, count(*)
FROM booking WHERE booking.price > 500
GROUP BY booking.price
ORDER BY booking.price LIMIT 10;| 단위(s) | SingleStore | PostgreSQL | MySQL |
|---|---|---|---|
| Query #1 | 0.29 | 2.766 | 19.34 |
Query #2
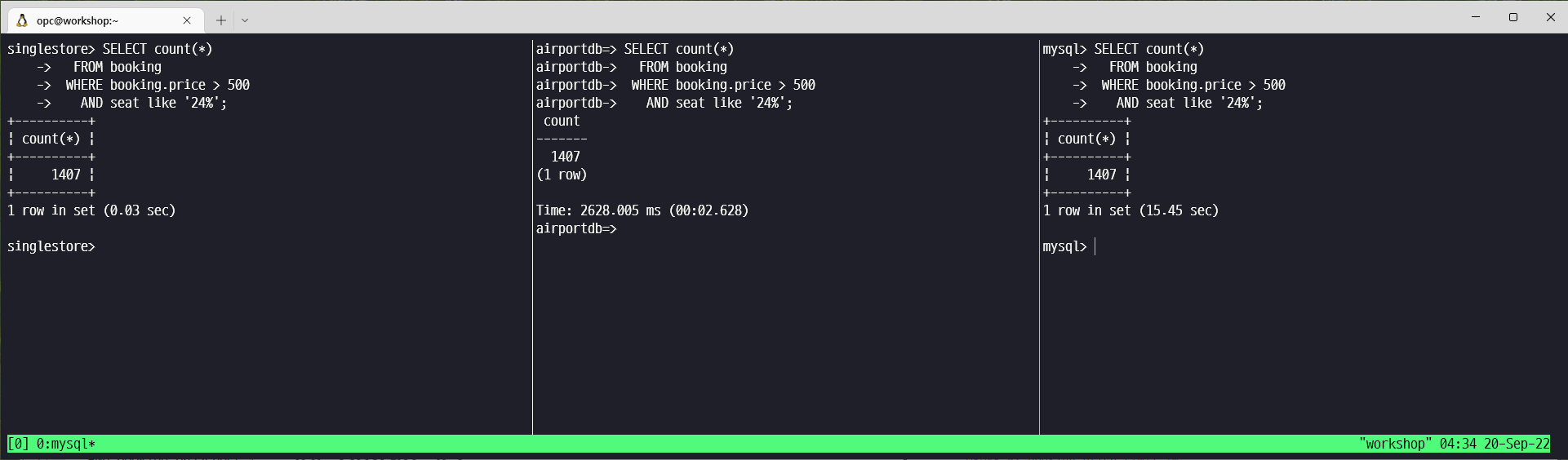
SELECT count(*)
FROM booking
WHERE booking.price > 500
AND seat like '24%';| 단위(s) | SingleStore | PostgreSQL | MySQL |
|---|---|---|---|
| Query #2 | 0.03 | 2.628 | 15.45 |
Query #3
SingleStore, MySQL 용 SQL
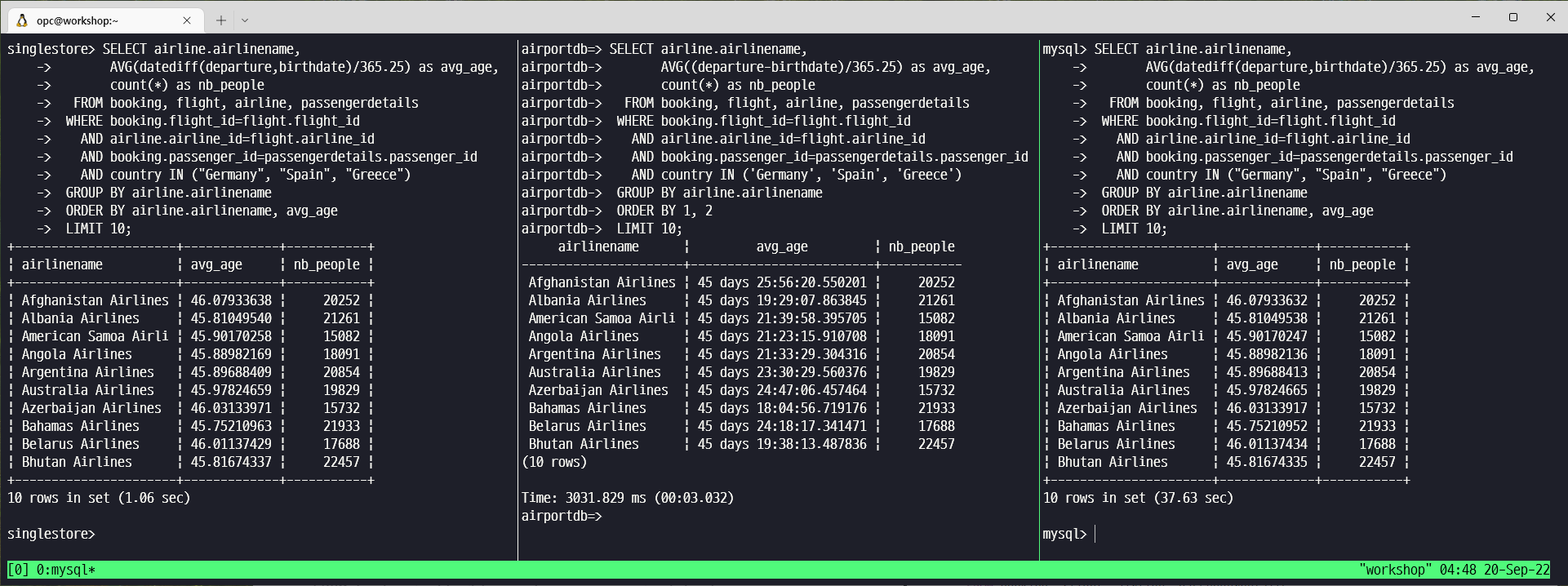
SELECT airline.airlinename,
AVG(datediff(departure,birthdate)/365.25) as avg_age,
count(*) as nb_people
FROM booking, flight, airline, passengerdetails
WHERE booking.flight_id=flight.flight_id
AND airline.airline_id=flight.airline_id
AND booking.passenger_id=passengerdetails.passenger_id
AND country IN ("Germany", "Spain", "Greece")
GROUP BY airline.airlinename
ORDER BY airline.airlinename, avg_age
LIMIT 10;PostgreSQL 용 SQL
SELECT airline.airlinename,
AVG((departure-birthdate)/365.25) as avg_age,
count(*) as nb_people
FROM booking, flight, airline, passengerdetails
WHERE booking.flight_id=flight.flight_id
AND airline.airline_id=flight.airline_id
AND booking.passenger_id=passengerdetails.passenger_id
AND country IN ('Germany', 'Spain', 'Greece')
GROUP BY airline.airlinename
ORDER BY 1, 2
LIMIT 10;| 단위(s) | SingleStore | PostgreSQL | MySQL |
|---|---|---|---|
| Query #3 | 1.06 | 3.032 | 37.63 |
Query #4
SingleStore, MySQL 용 SQL
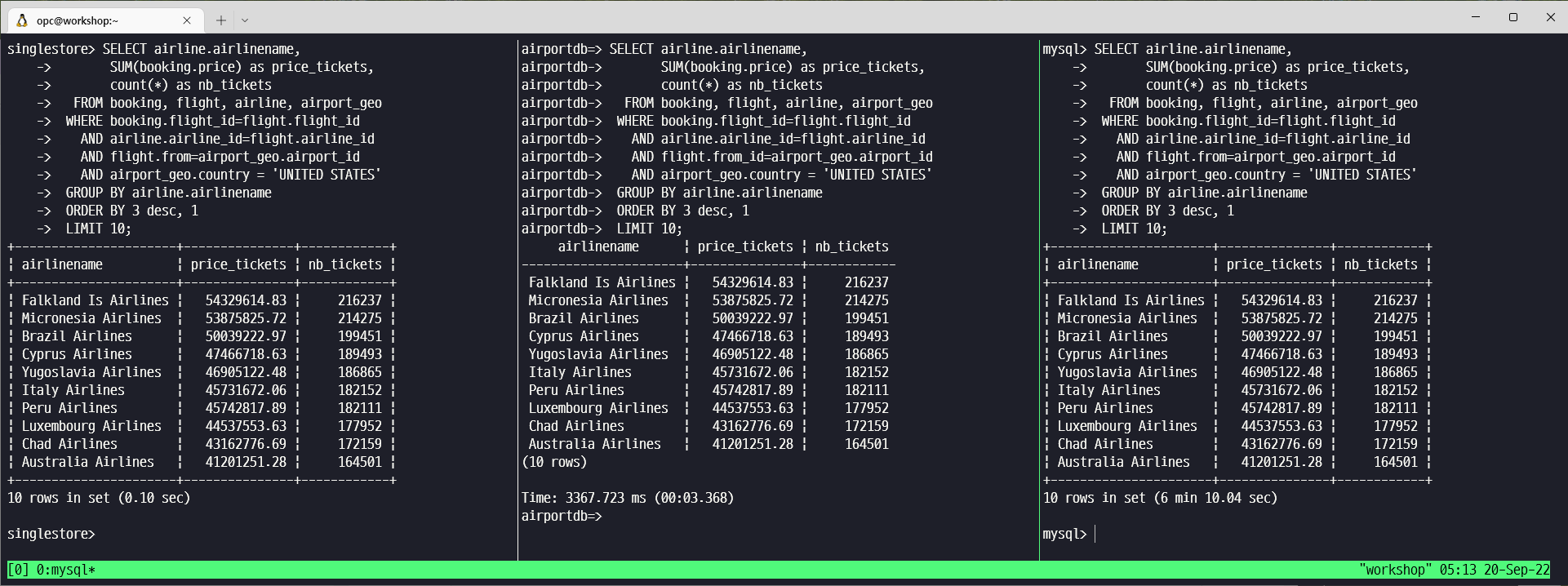
SELECT airline.airlinename,
SUM(booking.price) as price_tickets,
count(*) as nb_tickets
FROM booking, flight, airline, airport_geo
WHERE booking.flight_id=flight.flight_id
AND airline.airline_id=flight.airline_id
AND flight.from=airport_geo.airport_id
AND airport_geo.country = 'UNITED STATES'
GROUP BY airline.airlinename
ORDER BY 3 desc, 1
LIMIT 10;PostgreSQL 용 SQL
SELECT airline.airlinename,
SUM(booking.price) as price_tickets,
count(*) as nb_tickets
FROM booking, flight, airline, airport_geo
WHERE booking.flight_id=flight.flight_id
AND airline.airline_id=flight.airline_id
AND flight.from_id=airport_geo.airport_id
AND airport_geo.country = 'UNITED STATES'
GROUP BY airline.airlinename
ORDER BY 3 desc, 1
LIMIT 10;| 단위(s) | SingleStore | PostgreSQL | MySQL |
|---|---|---|---|
| Query #4 | 0.10 | 3.368 | 370.04 |
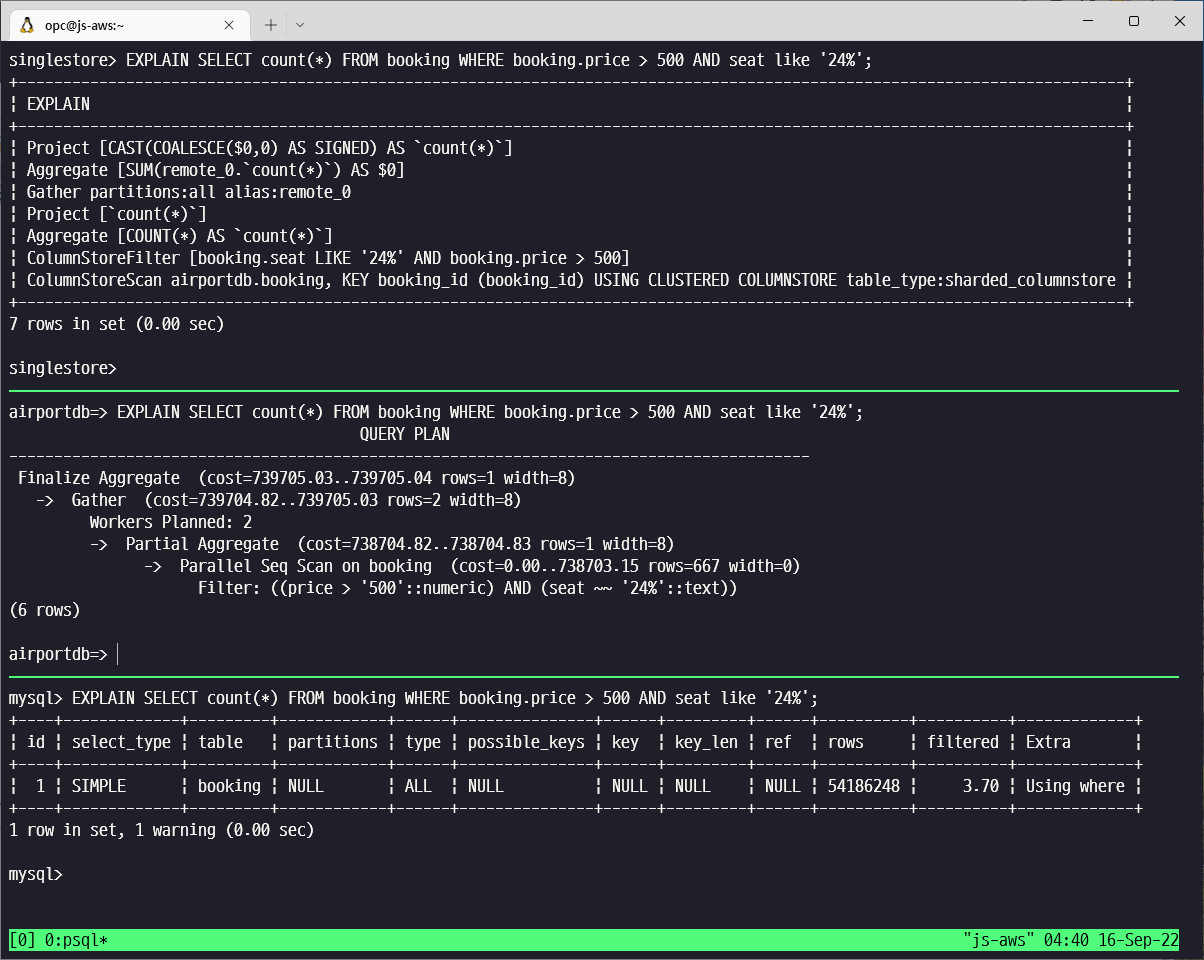
MySQL 조회 성능이 낮은 이유
각 Database 별 Query 실행 계획을 보면 MySQL 의 조회 성능이 낮게 나온 이유를 알 수 있습니다.
- SingleStore 는 분산(Distributed) DB 이므로 원래 아키텍처상 병렬(Parallel) Query 가 기본적으로 수행됩니다.
- PostgreSQL 은 옵티마이저(Optimizer)가 병렬 쿼리 수행을 자동으로 결정하고 수행했습니다.
- MySQL 은 대량 데이터에 대해 Serial Scan 을 하기 때문에 Query 수행 속도가 늦을 수 밖에 없습니다.
Query #2 의 각 데이터베이스별 실행 계획은 아래 그림과 같습니다.
마무리
16GB / 32GB Memory 장비에서의 동일한 테스트 결과입니다.
| 단위(s) | SingleStore | PostgreSQL | MySQL |
|---|---|---|---|
| Query #1 (16GB) | 0.03 | 2.628 | 15.45 |
| Query #1 (32GB) | 0.32 | 2.696 | 16.03 |
| -- | -- | -- | -- |
| Query #2 (16GB) | 0.03 | 2.628 | 15.45 |
| Query #2 (32GB) | 0.06 | 2.756 | 18.36 |
| -- | -- | -- | -- |
| Query #3 (16GB) | 1.06 | 3.032 | 37.63 |
| Query #3 (32GB) | 1.16 | 3.110 | 31.38 |
| -- | -- | -- | -- |
| Query #4 (16GB) | 0.10 | 3.368 | 370.04 |
| Query #4 (32GB) | 0.08 | 3.181 | 104.17 |
SingleStore 의 기본 Unit 크기는 Leaf Node 1개가 8 vCPU / 32GB Memory 입니다. 운영 환경의 최소 권장 크기는 4 Unit 으로 총 32 vCPU / 128GB Memory 입니다.
이번 테스트는 16GB Memory 에 Master Aggregator 1개, Leaf Node 1개가 함께 설치된 Cluster-in-a-Box 형태에서 진행되었습니다. 권장 크기에 비해 현저하게 작은 크기의 클러스트 구성임에도 불구하고 대량 데이터 조회 성능이 다른 데이터베이스에 비해 크게 뛰어남을 알 수 있습니다.
