
머리말
이번 글에서는 SingleStoreDB 에서 지원되는 Time Series 함수 3개, FIRST, LAST, TIME_BUCKET 의 사용 사례를 살펴 보겠습니다.
Python Pandas Grouper
먼저 Python 의 Pandas DataFrame 으로 가상의 주가 데이터를 만들도록 합니다.
import pandas as pd
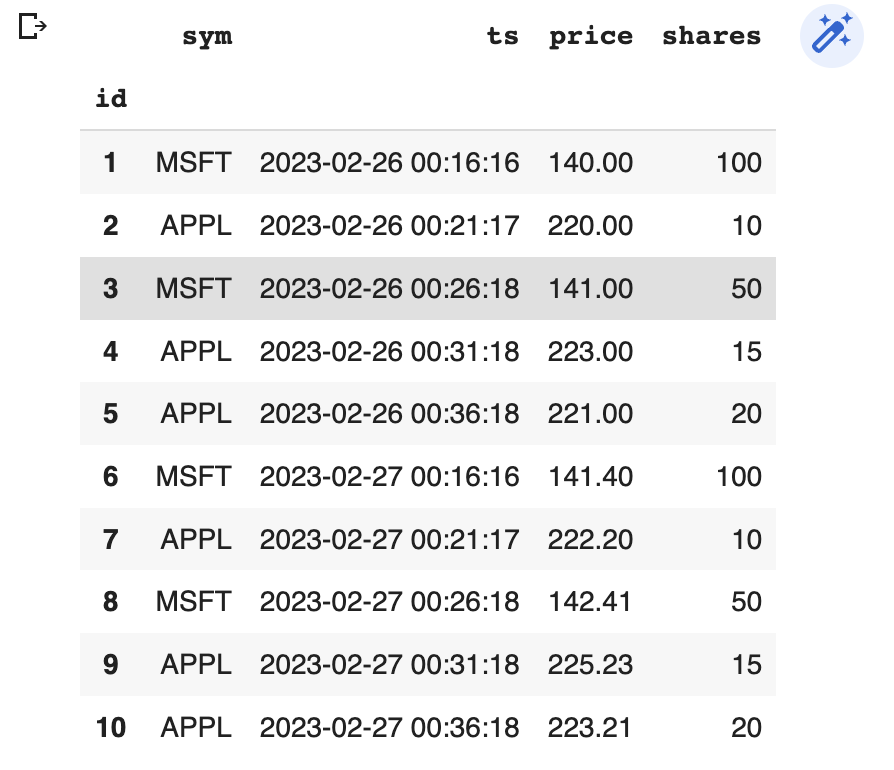
df = pd.DataFrame([[1,'MSFT',pd.Timestamp('2023-02-26 00:16:16'),140.00,100],
[2,'APPL',pd.Timestamp('2023-02-26 00:21:17'),220.00,10],
[3,'MSFT',pd.Timestamp('2023-02-26 00:26:18'),141.00,50],
[4,'APPL',pd.Timestamp('2023-02-26 00:31:18'),223.00,15],
[5,'APPL',pd.Timestamp('2023-02-26 00:36:18'),221.00,20],
[6,'MSFT',pd.Timestamp('2023-02-27 00:16:16'),141.40,100],
[7,'APPL',pd.Timestamp('2023-02-27 00:21:17'),222.20,10],
[8,'MSFT',pd.Timestamp('2023-02-27 00:26:18'),142.41,50],
[9,'APPL',pd.Timestamp('2023-02-27 00:31:18'),225.23,15],
[10,'APPL',pd.Timestamp('2023-02-27 00:36:18'),223.21,20]],
columns=['id', 'sym', 'ts', 'price', 'shares'])
df.set_index('id', inplace=True)
dfDataFrame 의 모습은 다음과 같습니다.
Pandas 의 Grouper 함수를 이용해 일단위, 시간단위, 분단위 등 Frequency 를 바꿔가며 분석을 할 수 있습니다.
df.groupby(['sym', pd.Grouper(key='ts', freq='D')]).agg(
high=('price','max'),
low=('price','min'),
open=('price','first'),
last=('price','last'))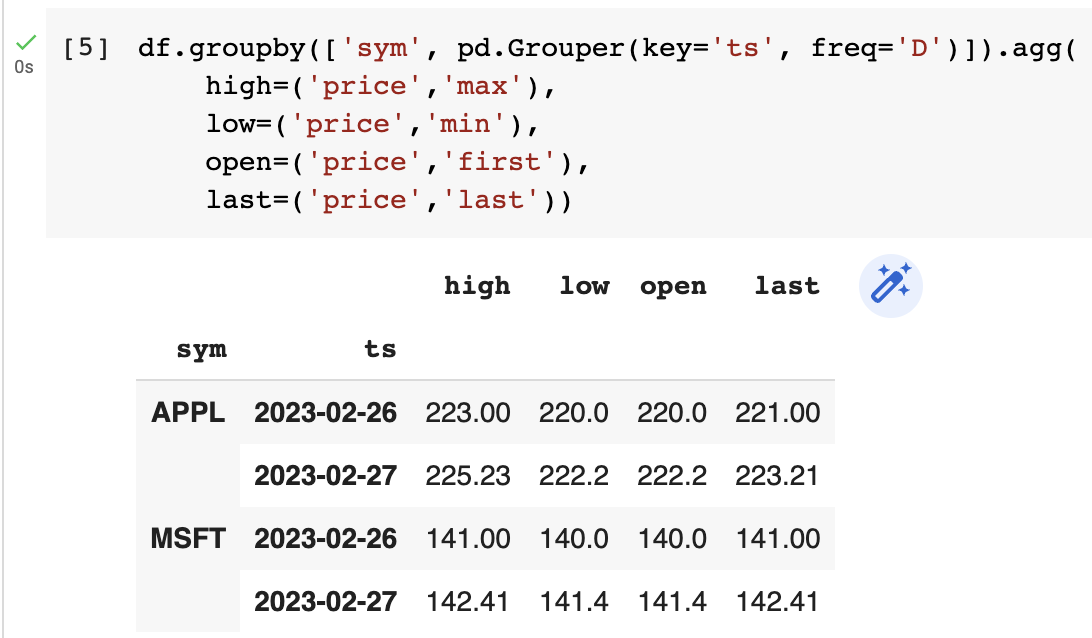
df.groupby(['sym', pd.Grouper(key='ts', freq='5min')]).agg(
high=('price','max'),
low=('price','min'),
open=('price','first'),
last=('price','last'))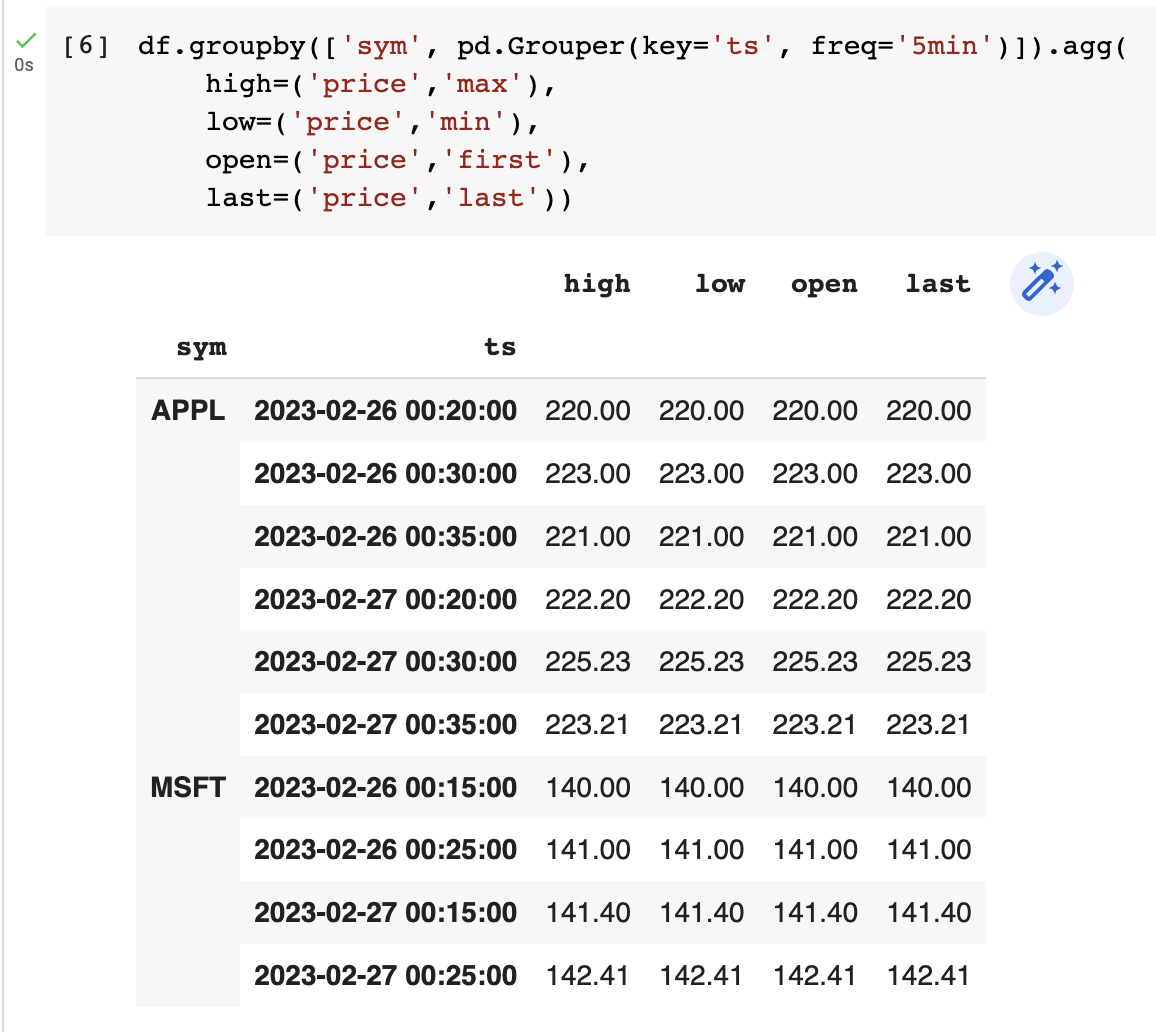
SingleStoreDB Time Series
이제 SingleStore 에서 동일한 분석을 Time Series 함수를 이용해 만들어 보겠습니다.
테이블을 만들고 Python Pandas 와 동일한 데이터를 생성합니다.
실제로는 SingleStoreDB 로 먼저 데이터를 만들고 이를 이용해 Pandas 에서 이용했습니다.
CREATE TABLE trade (
id INT, sym CHAR(4), ts DATETIME SERIES TIMESTAMP, price DECIMAL(8,2), shares FLOAT
);
INSERT trade VALUES(1, "MSFT", now(), 140.00, 100.00);
INSERT trade VALUES(2, "APPL", now() + interval 5 minute, 220.00, 10.00);
INSERT trade VALUES(3, "MSFT", now() + interval 10 minute, 141.00, 50.00);
INSERT trade VALUES(4, "APPL", now() + interval 15 minute, 223.00, 15.00);
INSERT trade VALUES(5, "APPL", now() +interval 20 minute, 221.00, 20.00);
INSERT into trade
SELECT id + (SELECT MAX(id) FROM trade), sym, ts + interval 1 day, price * 1.01, shares
FROM trade;
SELECT * FROM trade ORDER BY id;
+------+------+---------------------+--------+--------+
| id | sym | ts | price | shares |
+------+------+---------------------+--------+--------+
| 1 | MSFT | 2023-02-26 00:16:16 | 140.00 | 100 |
| 2 | APPL | 2023-02-26 00:21:17 | 220.00 | 10 |
| 3 | MSFT | 2023-02-26 00:26:18 | 141.00 | 50 |
| 4 | APPL | 2023-02-26 00:31:18 | 223.00 | 15 |
| 5 | APPL | 2023-02-26 00:36:18 | 221.00 | 20 |
| 6 | MSFT | 2023-02-27 00:16:16 | 141.40 | 100 |
| 7 | APPL | 2023-02-27 00:21:17 | 222.20 | 10 |
| 8 | MSFT | 2023-02-27 00:26:18 | 142.41 | 50 |
| 9 | APPL | 2023-02-27 00:31:18 | 225.23 | 15 |
| 10 | APPL | 2023-02-27 00:36:18 | 223.21 | 20 |
+------+------+---------------------+--------+--------+
10 rows in set (0.81 sec)Pandas 에서와 같이 일단위, 5분단위로 시간을 나눠 max, min, first, last 값을 조회합니다.
singlestore> SELECT sym, TIME_BUCKET('1d'), MAX(price) as high, MIN(price) as low,
-> FIRST(price) as open, LAST(price) as close
-> FROM trade
-> GROUP BY 1, 2
-> ORDER BY 1, 2;
+------+----------------------------+--------+--------+--------+--------+
| sym | TIME_BUCKET('1d') | high | low | open | close |
+------+----------------------------+--------+--------+--------+--------+
| APPL | 2023-02-26 00:00:00.000000 | 223.00 | 220.00 | 220.00 | 221.00 |
| APPL | 2023-02-27 00:00:00.000000 | 225.23 | 222.20 | 222.20 | 223.21 |
| MSFT | 2023-02-26 00:00:00.000000 | 141.00 | 140.00 | 140.00 | 141.00 |
| MSFT | 2023-02-27 00:00:00.000000 | 142.41 | 141.40 | 141.40 | 142.41 |
+------+----------------------------+--------+--------+--------+--------+
4 rows in set (0.42 sec)
singlestore> SELECT sym, TIME_BUCKET('5m'), MAX(price) as high, MIN(price) as low,
-> FIRST(price) as open, LAST(price) as close
-> FROM trade
-> GROUP BY 1, 2
-> ORDER BY 1, 2;
+------+----------------------------+--------+--------+--------+--------+
| sym | TIME_BUCKET('5m') | high | low | open | close |
+------+----------------------------+--------+--------+--------+--------+
| APPL | 2023-02-26 00:20:00.000000 | 220.00 | 220.00 | 220.00 | 220.00 |
| APPL | 2023-02-26 00:30:00.000000 | 223.00 | 223.00 | 223.00 | 223.00 |
| APPL | 2023-02-26 00:35:00.000000 | 221.00 | 221.00 | 221.00 | 221.00 |
| APPL | 2023-02-27 00:20:00.000000 | 222.20 | 222.20 | 222.20 | 222.20 |
| APPL | 2023-02-27 00:30:00.000000 | 225.23 | 225.23 | 225.23 | 225.23 |
| APPL | 2023-02-27 00:35:00.000000 | 223.21 | 223.21 | 223.21 | 223.21 |
| MSFT | 2023-02-26 00:15:00.000000 | 140.00 | 140.00 | 140.00 | 140.00 |
| MSFT | 2023-02-26 00:25:00.000000 | 141.00 | 141.00 | 141.00 | 141.00 |
| MSFT | 2023-02-27 00:15:00.000000 | 141.40 | 141.40 | 141.40 | 141.40 |
| MSFT | 2023-02-27 00:25:00.000000 | 142.41 | 142.41 | 142.41 | 142.41 |
+------+----------------------------+--------+--------+--------+--------+
10 rows in set (0.42 sec)Time Bucket 의 크기는 Time Interval 형식을 따릅니다. 예를 들어 "INTERVAL 1 DAY" 또는 "1h4m" 등과 같이 사용할 수 있습니다.
마무리
SingleStoreDB 의 Time Series 함수는 시간을 원하는 Bucket 으로 나누고 그 범위 안에서 여러 집계함수를 사용할 수 있게 합니다.
또한 해당 시간 범위에서 첫번째 Row 및 마지막 Row 를 쉽게 찾을 수 있어 Oracle 이나 MySQL 등과 같은 다른 Database 에서 복잡하게 구현하는 SQL 을 간편하게 사용할 수 있습니다.
