from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()스파크 완벽 가이드 를 요약한 내용입니다.
Aggregation
- 구매 이력 데이터를 사용해 파티션을 휠씬 적은 수로 분할할 수 있도록 리파티셔닝
- 빠르게 접근할 수 있도록 캐싱
""" 구매 이력 데이터 """
df = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load("./data/retail-data/all/*.csv")\
.coalesce(5)
df.cache()
df.createOrReplaceTempView("dfTable")df.show(1)+---------+---------+--------------------+--------+--------------+---------+----------+--------------+
|InvoiceNo|StockCode| Description|Quantity| InvoiceDate|UnitPrice|CustomerID| Country|
+---------+---------+--------------------+--------+--------------+---------+----------+--------------+
| 536365| 85123A|WHITE HANGING HEA...| 6|12/1/2010 8:26| 2.55| 17850|United Kingdom|
+---------+---------+--------------------+--------+--------------+---------+----------+--------------+
only showing top 1 rowdf.count()541909집계 함수
- org.apache.spark.sql.functions 패키지 참조
count
from pyspark.sql.functions import col, count
df.select(count("StockCode")).show() # null 로우는 제외
df.select(count("*")).show() # null 로우를 포함+----------------+
|count(StockCode)|
+----------------+
| 541909|
+----------------+
+--------+
|count(1)|
+--------+
| 541909|
+--------+countDistinct
- 고유레코드 수
from pyspark.sql.functions import countDistinct
df.select(countDistinct("StockCode")).show()+-------------------------+
|count(DISTINCT StockCode)|
+-------------------------+
| 4070|
+-------------------------+approx_count_distinct
- 근사치로 구하지만 연산 속도가 빠름
from pyspark.sql.functions import approx_count_distinct
df.select(approx_count_distinct("StockCode", 0.1)).show() # 0.1은 최대 추정 오류율
df.select(approx_count_distinct("StockCode", 0.01)).show() +--------------------------------+
|approx_count_distinct(StockCode)|
+--------------------------------+
| 3364|
+--------------------------------+
+--------------------------------+
|approx_count_distinct(StockCode)|
+--------------------------------+
| 4079|
+--------------------------------+first와 last
from pyspark.sql.functions import first, last
df.select(first("StockCode"), last("StockCode")).show(1) # null도 감안하려면 True+-----------------------+----------------------+
|first(StockCode, false)|last(StockCode, false)|
+-----------------------+----------------------+
| 85123A| 22138|
+-----------------------+----------------------+min과 max
- 문자열도 동작이 됨
from pyspark.sql.functions import min, max
df.select(min("Quantity"), max("Quantity")).show(1)
df.select(min("Description"), max("Description")).show(1) # 문자열+-------------+-------------+
|min(Quantity)|max(Quantity)|
+-------------+-------------+
| -80995| 80995|
+-------------+-------------+
+--------------------+-----------------+
| min(Description)| max(Description)|
+--------------------+-----------------+
| 4 PURPLE FLOCK D...|wrongly sold sets|
+--------------------+-----------------+sum
from pyspark.sql.functions import sum
df.select(sum("Quantity")).show(1)+-------------+
|sum(Quantity)|
+-------------+
| 5176450|
+-------------+sumDistinct
from pyspark.sql.functions import sumDistinct
df.select(sumDistinct("Quantity")).show(1) # 고유값을 합산+----------------------+
|sum(DISTINCT Quantity)|
+----------------------+
| 29310|
+----------------------+avg
- avg, mean 함수로 평균을 구함
from pyspark.sql.functions import sum, count, avg, expr
df.select(
count("Quantity").alias("total_transcations"),
sum("Quantity").alias("total_purchases"),
avg("Quantity").alias("avg_purchases"),
expr("mean(Quantity)").alias("mean_transcations"),
).selectExpr(
"total_purchases / total_transcations",
"avg_purchases",
"mean_transcations").show(3)+--------------------------------------+----------------+-----------------+
|(total_purchases / total_transcations)| avg_purchases|mean_transcations|
+--------------------------------------+----------------+-----------------+
| 9.55224954743324|9.55224954743324| 9.55224954743324|
+--------------------------------------+----------------+-----------------+분산과 표준편차
- 표본표준분산 및 편차: variance, stddev
- 모표준분산 및 편차 : var_pop, stddev_pop
from pyspark.sql.functions import variance, stddev
from pyspark.sql.functions import var_samp, stddev_samp
from pyspark.sql.functions import var_pop, stddev_pop
df.select(variance("Quantity"), stddev("Quantity"),
var_samp("Quantity"), stddev_samp("Quantity"), # 위와 동일
var_pop("Quantity"), stddev_pop("Quantity")).show()+------------------+---------------------+------------------+---------------------+------------------+--------------------+
|var_samp(Quantity)|stddev_samp(Quantity)|var_samp(Quantity)|stddev_samp(Quantity)| var_pop(Quantity)|stddev_pop(Quantity)|
+------------------+---------------------+------------------+---------------------+------------------+--------------------+
|47559.391409298754| 218.08115785023418|47559.391409298754| 218.08115785023418|47559.303646609056| 218.08095663447796|
+------------------+---------------------+------------------+---------------------+------------------+--------------------+spark.createDataFrame(df.select("*").take(1))\
.select(variance("Quantity"), stddev("Quantity"),
var_samp("Quantity"), stddev_samp("Quantity"), # 위와 동일
var_pop("Quantity"), stddev_pop("Quantity")).show() # 1일 때는 NaN이 나옵니다.+------------------+---------------------+------------------+---------------------+-----------------+--------------------+
|var_samp(Quantity)|stddev_samp(Quantity)|var_samp(Quantity)|stddev_samp(Quantity)|var_pop(Quantity)|stddev_pop(Quantity)|
+------------------+---------------------+------------------+---------------------+-----------------+--------------------+
| NaN| NaN| NaN| NaN| 0.0| 0.0|
+------------------+---------------------+------------------+---------------------+-----------------+--------------------+비대칭도와 첨도
from pyspark.sql.functions import skewness, kurtosis
df.select(skewness("Quantity"), kurtosis("Quantity")).show()+-------------------+------------------+
| skewness(Quantity)|kurtosis(Quantity)|
+-------------------+------------------+
|-0.2640755761052562|119768.05495536952|
+-------------------+------------------+공분산과 상관관계
- 표본공분산(cover_samp), 모공분산(cover_pop)
from pyspark.sql.functions import corr, covar_pop, covar_samp
df.select(corr("InvoiceNo", "Quantity"), covar_pop("InvoiceNo", "Quantity"),
covar_samp("InvoiceNo", "Quantity")).show()+-------------------------+------------------------------+-------------------------------+
|corr(InvoiceNo, Quantity)|covar_pop(InvoiceNo, Quantity)|covar_samp(InvoiceNo, Quantity)|
+-------------------------+------------------------------+-------------------------------+
| 4.912186085635685E-4| 1052.7260778741693| 1052.7280543902734|
+-------------------------+------------------------------+-------------------------------+복합 데이터 타입의 집계
from pyspark.sql.functions import collect_list, collect_set, size
df.select(collect_list("Country"), collect_set("Country")).show()+---------------------+--------------------+
|collect_list(Country)|collect_set(Country)|
+---------------------+--------------------+
| [United Kingdom, ...|[Portugal, Italy,...|
+---------------------+--------------------+df.select(size(collect_list("Country")), size(collect_set("Country"))).show()
# 각 컬럼의 복합데이터 사이즈+---------------------------+--------------------------+
|size(collect_list(Country))|size(collect_set(Country))|
+---------------------------+--------------------------+
| 541909| 38|
+---------------------------+--------------------------+df.select(countDistinct("Country")).show() # 중복없이 카운트+-----------------------+
|count(DISTINCT Country)|
+-----------------------+
| 38|
+-----------------------+그룹화
- 하나 이상의 컬럼을 그룹화하여 RelationalGroupedDataset 반환
- 집계 연산을 수행하는 두 번째 단계에서는 DataFrame이 반환됨
df.groupBy("InvoiceNo", "CustomerId").count().show()+---------+----------+-----+
|InvoiceNo|CustomerId|count|
+---------+----------+-----+
| 536846| 14573| 76|
| 537026| 12395| 12|
| 537883| 14437| 5|
| 538068| 17978| 12|
| 538279| 14952| 7|
| 538800| 16458| 10|
| 538942| 17346| 12|
| C539947| 13854| 1|
| 540096| 13253| 16|
| 540530| 14755| 27|
| 541225| 14099| 19|
| 541978| 13551| 4|
| 542093| 17677| 16|
| 536596| null| 6|
| 537252| null| 1|
| 538041| null| 1|
| 543188| 12567| 63|
| 543590| 17377| 19|
| C543757| 13115| 1|
| C544318| 12989| 1|
+---------+----------+-----+
only showing top 20 rows표현식을 이용한 그룹화
from pyspark.sql.functions import count
df.groupBy("InvoiceNo", "CustomerId").agg(
count("Quantity").alias("guan"),
expr("count(Quantity)")).show()+---------+----------+----+---------------+
|InvoiceNo|CustomerId|guan|count(Quantity)|
+---------+----------+----+---------------+
| 536846| 14573| 76| 76|
| 537026| 12395| 12| 12|
| 537883| 14437| 5| 5|
| 538068| 17978| 12| 12|
| 538279| 14952| 7| 7|
| 538800| 16458| 10| 10|
| 538942| 17346| 12| 12|
| C539947| 13854| 1| 1|
| 540096| 13253| 16| 16|
| 540530| 14755| 27| 27|
| 541225| 14099| 19| 19|
| 541978| 13551| 4| 4|
| 542093| 17677| 16| 16|
| 536596| null| 6| 6|
| 537252| null| 1| 1|
| 538041| null| 1| 1|
| 543188| 12567| 63| 63|
| 543590| 17377| 19| 19|
| C543757| 13115| 1| 1|
| C544318| 12989| 1| 1|
+---------+----------+----+---------------+
only showing top 20 rows맵을 이용한 그룹화
- 파이선의 딕셔너리 데이터 타입을 활용하여 집계함수의 표현이 가능
df.groupBy("InvoiceNo").agg(
{"Quantity":"avg", "Quantity":"stddev_pop"}).show() # 키 값이 충돌됨+---------+--------------------+
|InvoiceNo|stddev_pop(Quantity)|
+---------+--------------------+
| 536596| 1.1180339887498947|
| 536938| 20.698023172885524|
| 537252| 0.0|
| 537691| 5.597097462078001|
| 538041| 0.0|
| 538184| 8.142590198943392|
| 538517| 2.3946659604837897|
| 538879| 11.811070444356483|
| 539275| 12.806248474865697|
| 539630| 10.225241100118645|
| 540499| 2.6653642652865788|
| 540540| 1.0572457590557278|
| C540850| 0.0|
| 540976| 6.496760677872902|
| 541432| 10.825317547305483|
| 541518| 20.550782784878713|
| 541783| 8.467657556242811|
| 542026| 4.853406592853679|
| 542375| 3.4641016151377544|
| C542604| 15.173990905493518|
+---------+--------------------+
only showing top 20 rows윈도우 함수
-
group-by 함수를 사용하면 모든 로우 레코드가 단일 그룹으로만 이동하지만, 윈도우 함수는 하나 이상의 프레임에 할당될 수 있음
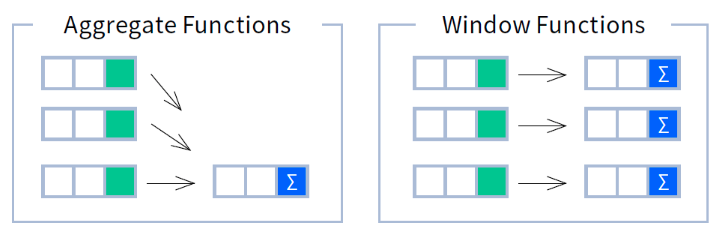
이미지 출처 -
가장 흔한 예시로는 하루는 나타내는 값의 롤링 평균을 구하는 예시
-
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
""" 예시 DataFrame : 날짜 정보를 가진 date 컬럼 추가 """
from pyspark.sql.functions import col, to_date
dfWithDate = df.withColumn("date", to_date(col("InvoiceDate"), "MM/d/yyyy H:mm"))
dfWithDate.createOrReplaceTempView("dfWithDate")dfWithDate.show(5)+---------+---------+--------------------+--------+--------------+---------+----------+--------------+----------+
|InvoiceNo|StockCode| Description|Quantity| InvoiceDate|UnitPrice|CustomerID| Country| date|
+---------+---------+--------------------+--------+--------------+---------+----------+--------------+----------+
| 536365| 85123A|WHITE HANGING HEA...| 6|12/1/2010 8:26| 2.55| 17850|United Kingdom|2010-12-01|
| 536365| 71053| WHITE METAL LANTERN| 6|12/1/2010 8:26| 3.39| 17850|United Kingdom|2010-12-01|
| 536365| 84406B|CREAM CUPID HEART...| 8|12/1/2010 8:26| 2.75| 17850|United Kingdom|2010-12-01|
| 536365| 84029G|KNITTED UNION FLA...| 6|12/1/2010 8:26| 3.39| 17850|United Kingdom|2010-12-01|
| 536365| 84029E|RED WOOLLY HOTTIE...| 6|12/1/2010 8:26| 3.39| 17850|United Kingdom|2010-12-01|
+---------+---------+--------------------+--------+--------------+---------+----------+--------------+----------+
only showing top 5 rowsfrom pyspark.sql.window import Window
from pyspark.sql.functions import desc
windowSpec = Window\
.partitionBy("CustomerId", "date")\
.orderBy(desc("Quantity"))\
.rowsBetween(Window.unboundedPreceding, Window.currentRow) # 파티션의 처음부터 현재 로우까지from pyspark.sql.functions import max
maxPurchaseQuantity = max(col("Quantity")).over(windowSpec)from pyspark.sql.functions import dense_rank, rank
purchaseDenseRank = dense_rank().over(windowSpec)
purchaseRank = rank().over(windowSpec)from pyspark.sql.functions import col
dfWithDate.where("CustomerId IS NOT NULL").orderBy("CustomerId")\
.select(col("CustomerId"), col("date"), col("Quantity"),
purchaseRank.alias("quantityRank"), # 중복 순위를 감안
purchaseDenseRank.alias("quantityDenseRank"), # 중복 순위를 감안하지 않음
maxPurchaseQuantity.alias("maxDenseRank")
).show()+----------+----------+--------+------------+-----------------+------------+
|CustomerId| date|Quantity|quantityRank|quantityDenseRank|maxDenseRank|
+----------+----------+--------+------------+-----------------+------------+
| 12346|2011-01-18| 74215| 1| 1| 74215|
| 12346|2011-01-18| -74215| 2| 2| 74215|
| 12347|2010-12-07| 36| 1| 1| 36|
| 12347|2010-12-07| 30| 2| 2| 36|
| 12347|2010-12-07| 24| 3| 3| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 12| 4| 4| 36|
| 12347|2010-12-07| 6| 17| 5| 36|
| 12347|2010-12-07| 6| 17| 5| 36|
+----------+----------+--------+------------+-----------------+------------+
only showing top 20 rows
그룹화 셋
- 여러 그룹에 걸쳐 집계를 결합하는 저수준 기능
""" 재고 코드(stockCode)와 고객(CustomerId)별 총 수량 얻기 """
dfNoNull = dfWithDate.na.drop()
dfNoNull.createOrReplaceTempView('dfNoNull')
# drop 후에도 CustomerId에 null이 포함되는 이유는 ? na를 추가해야 함
dfNoNull\
.groupBy(col("stockCode"), col("CustomerId")).agg(
sum("Quantity").alias("sumOfQuantity")
).orderBy(desc("sumOfQuantity"))\
.show()+---------+----------+-------------+
|stockCode|CustomerId|sumOfQuantity|
+---------+----------+-------------+
| 84826| 13256| 12540|
| 22197| 17949| 11692|
| 84077| 16333| 10080|
| 17003| 16422| 10077|
| 21915| 16333| 8120|
| 16014| 16308| 8000|
| 22616| 17306| 6624|
| 22189| 18102| 5946|
| 84077| 12901| 5712|
| 18007| 14609| 5586|
| 22197| 12931| 5340|
| 22469| 17450| 5286|
| 84879| 12931| 5048|
| 23084| 14646| 4801|
| 22693| 16029| 4800|
| 21137| 16210| 4728|
| 22616| 17381| 4704|
| 85099B| 15769| 4700|
| 21787| 12901| 4632|
| 22629| 14646| 4492|
+---------+----------+-------------+
only showing top 20 rows롤업
- 다양한 컬럼을 그룹화 키로 설정하면 데이터셋에서 볼 수 있는 실제 조합을 살펴볼 수 있음
- 컬럼을 계층적으로 다룸
- null 값을 가진 로우에서 전체 날짜의 합계를 확인할 수 있음
- 모두 null인 로우는 두 컬럼에 속한 레코드의 전체 합계를 나타냄
rolledUpDF = dfNoNull.rollup("Date", "Country").agg(sum("Quantity"))\
.selectExpr("Date", "Country", "`sum(Quantity)` as total_quantity")\
.orderBy("Date")
# null 값을 가진 로우는 전체 날짜의 합계 확인
rolledUpDF.where(expr("Date IS NULL")).show()
# 모두 null인 로우는 두 컬럼에 속한 레코드의 전체 합계
rolledUpDF.where(expr("Country IS NULL")).show()+----+-------+--------------+
|Date|Country|total_quantity|
+----+-------+--------------+
|null| null| 4906888|
+----+-------+--------------+
+----------+-------+--------------+
| Date|Country|total_quantity|
+----------+-------+--------------+
| null| null| 4906888|
|2010-12-01| null| 24032|
|2010-12-02| null| 20855|
|2010-12-03| null| 11548|
|2010-12-05| null| 16394|
|2010-12-06| null| 16095|
|2010-12-07| null| 19351|
|2010-12-08| null| 21275|
|2010-12-09| null| 16904|
|2010-12-10| null| 15388|
|2010-12-12| null| 10561|
|2010-12-13| null| 15234|
|2010-12-14| null| 17108|
|2010-12-15| null| 18169|
|2010-12-16| null| 29482|
|2010-12-17| null| 10517|
|2010-12-19| null| 3735|
|2010-12-20| null| 12617|
|2010-12-21| null| 10888|
|2010-12-22| null| 3053|
+----------+-------+--------------+
only showing top 20 rows큐브
- 계층적이 아닌 모든 차원에 대해 동일한 작업을 수행
rolledUpDF = dfNoNull.cube("Date", "Country").agg(sum("Quantity"))\
.selectExpr("Date", "Country", "`sum(Quantity)` as total_quantity")\
.orderBy("Date")
# null 값을 가진 로우는 전체 날짜의 합계 확인
rolledUpDF.where(expr("Date IS NULL")).show()
# 모두 null인 로우는 두 컬럼에 속한 레코드의 전체 합계
rolledUpDF.where(expr("Country IS NULL")).show()
# 모두 null인 로우는 두 컬럼에 속한 레코드의 전체 합계+----+--------------------+--------------+
|Date| Country|total_quantity|
+----+--------------------+--------------+
|null| European Community| 497|
|null| Norway| 19247|
|null| Channel Islands| 9479|
|null| Lebanon| 386|
|null| Singapore| 5234|
|null|United Arab Emirates| 982|
|null| USA| 1034|
|null| Denmark| 8188|
|null| Cyprus| 6317|
|null| Spain| 26824|
|null| Czech Republic| 592|
|null| Germany| 117448|
|null| RSA| 352|
|null| Australia| 83653|
|null| Portugal| 16044|
|null| Unspecified| 1789|
|null| Japan| 25218|
|null| Finland| 10666|
|null| Italy| 7999|
|null| Greece| 1556|
+----+--------------------+--------------+
only showing top 20 rows
+----------+-------+--------------+
| Date|Country|total_quantity|
+----------+-------+--------------+
| null| null| 4906888|
|2010-12-01| null| 24032|
|2010-12-02| null| 20855|
|2010-12-03| null| 11548|
|2010-12-05| null| 16394|
|2010-12-06| null| 16095|
|2010-12-07| null| 19351|
|2010-12-08| null| 21275|
|2010-12-09| null| 16904|
|2010-12-10| null| 15388|
|2010-12-12| null| 10561|
|2010-12-13| null| 15234|
|2010-12-14| null| 17108|
|2010-12-15| null| 18169|
|2010-12-16| null| 29482|
|2010-12-17| null| 10517|
|2010-12-19| null| 3735|
|2010-12-20| null| 12617|
|2010-12-21| null| 10888|
|2010-12-22| null| 3053|
+----------+-------+--------------+
only showing top 20 rows그룹화 메타 데이터
- 결과 데이터셋의 집계 수준을 명시하는 컬럼을 제공
3: 가장 높은 계층의 집계 결과에서 나타남
2: 개별 재고 코드의 모든 집계 결과에서 나타남
1: 구매한 물품에 관계없이 customerId를 기반으로 총 수량을 제공
0: customerId와 stockCode별 조합에 따라 총 수량을 제공from pyspark.sql.functions import grouping_id, sum, expr
dfNoNull.cube("customerId", "stockCode").agg(grouping_id(), sum("Quantity"))\
.orderBy(col("grouping_id()").desc())\
.where("grouping_id() = 3").show(3)
dfNoNull.cube("customerId", "stockCode").agg(grouping_id(), sum("Quantity"))\
.orderBy(col("grouping_id()").desc())\
.where("grouping_id() = 2").show(3)
dfNoNull.cube("customerId", "stockCode").agg(grouping_id(), sum("Quantity"))\
.orderBy(col("grouping_id()").desc())\
.where("grouping_id() = 1").show(3)
dfNoNull.cube("customerId", "stockCode").agg(grouping_id(), sum("Quantity"))\
.orderBy(col("grouping_id()").desc())\
.where("grouping_id() = 0").show(3)+----------+---------+-------------+-------------+
|customerId|stockCode|grouping_id()|sum(Quantity)|
+----------+---------+-------------+-------------+
| null| null| 3| 4906888|
+----------+---------+-------------+-------------+
+----------+---------+-------------+-------------+
|customerId|stockCode|grouping_id()|sum(Quantity)|
+----------+---------+-------------+-------------+
| null| 21755| 2| 1942|
| null| 82482| 2| 8043|
| null| 21034| 2| 1872|
+----------+---------+-------------+-------------+
only showing top 3 rows
+----------+---------+-------------+-------------+
|customerId|stockCode|grouping_id()|sum(Quantity)|
+----------+---------+-------------+-------------+
| 14506| null| 1| 730|
| 14850| null| 1| 285|
| 14896| null| 1| 279|
+----------+---------+-------------+-------------+
only showing top 3 rows
+----------+---------+-------------+-------------+
|customerId|stockCode|grouping_id()|sum(Quantity)|
+----------+---------+-------------+-------------+
| 14688| 84997B| 0| 12|
| 14688| 21929| 0| 10|
| 13767| 22730| 0| 108|
+----------+---------+-------------+-------------+
only showing top 3 rows피벗
- 로우를 컬럼으로 변환할 수 있음
pivoted = dfWithDate.groupBy("date").pivot("Country").sum()pivoted.columnspivoted.where("date > '2011-12-05'")\
.select("date", "USA_sum(CAST(Quantity AS BIGINT))").show()+----------+---------------------------------+
| date|USA_sum(CAST(Quantity AS BIGINT))|
+----------+---------------------------------+
|2011-12-06| null|
|2011-12-09| null|
|2011-12-08| -196|
|2011-12-07| null|
+----------+---------------------------------+사용자 정의 집계 함수
- User Defined Aggregation Function, UDAF
- UDAF를 생성하려면 기본 클래스인 UserDefinedAggregateFunction을 상속
- UDAF는 현재 스칼라와 자바로만 사용할 수 있음(ver 2.3)
inputSchema: UDAF 입력 파라미터의 스키마를 StructType으로 정의
bufferSchema: UDAF 중간 결과의 스키마를 StructType으로 정의
dataType: 반환될 값의 DataType을 정의
deterministic: UDAF가 동일한 입력값에 대해 항상 동일한 결과를 반환하는지 불리언값으로 정의
initialize: 집계용 버퍼의 값을 초기화하는 로직을 정의
update: 입력받은 로우를 기바느로 내부 버퍼를 업데이트하는 로직을 정의
merge: 두 개의 집계용 버퍼를 병합하는 로직을 정의
evaluate: 집계의 최종 결과를 생성하는 로직을 정의
# data engineering