
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
What’s going on inside ConvNets?
ConvNet 안에서 어떤 일이 일어나고 있을까? 이를 알기 위해서 주로 visualizing 기법을 활용한다. 즉 딥러닝 내부를 시각화 해서 살펴보는 것이다.
Visualize Filters

Input image와 weight의 내적이 first layer에 입력되는데 이를 시각화해서 살펴보면 edge나 보색 성분이 주로 검출된다는 것을 알 수 있다.

하지만 layer가 깊어질수록 시각화를 통해 정보를 얻어내기가 쉽지 않다.

Last layer에서도 시각화를 통해 정보를 얻을 수가 있는데 nearest neighbors 기법을 활용해서 시각화할 수 있다. 픽셀 단위에서 nearest neighbors를 사용했을 땐 비슷한 픽셀들로 구성되어 있는 것을 같은 그룹으로 분류했기 때문에 정확성이 그리 높진 않았다.
하지만 CNN 모델에서 마지막 layer의 특징 벡터들에 nearest neighbor을 적용하게 되면 객체의 방향이나 위치가 서로 다르더라도 올바르게 분류하고 있음을 볼 수 있다. 가령 2번째 열의 코끼리를 살펴보면 코끼리가 서있는 방향이나 위치가 가운데에 있는 지, 왼쪽으로 치우쳐 있는 지 등이 서로 달라 비슷한 픽셀이라 말하기 어려운데 CNN에선 같은 그룹으로 분류하고 있음을 알 수 있다.
따라서 이러한 시각화 기법을 통해 ConvNet이 얼마나 잘 작동하고 있는 지를 살펴볼 수 있다.
Dimensionality Reduction
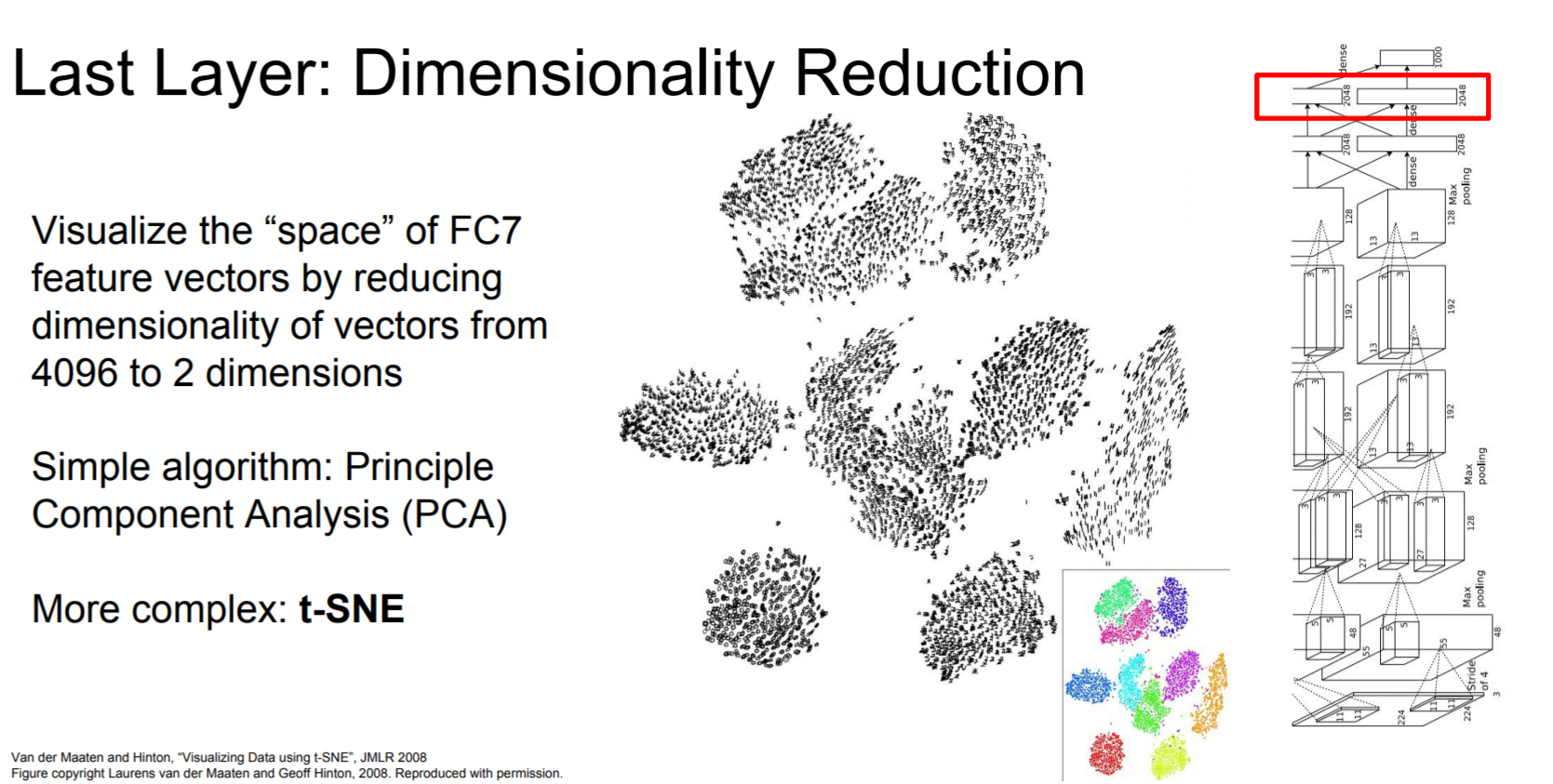
Last layer를 PCA나 t-sne 기법을 이용해 차원 축소를 하게 되면 위의 그림처럼 군집화된 모습을 볼 수 있다.
그 밖의 시각화 기법
Maximally Activating Patches

Occlusion Experiments

Saliency Maps

추후 다시 정리하겠습니다...
참고자료
