
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
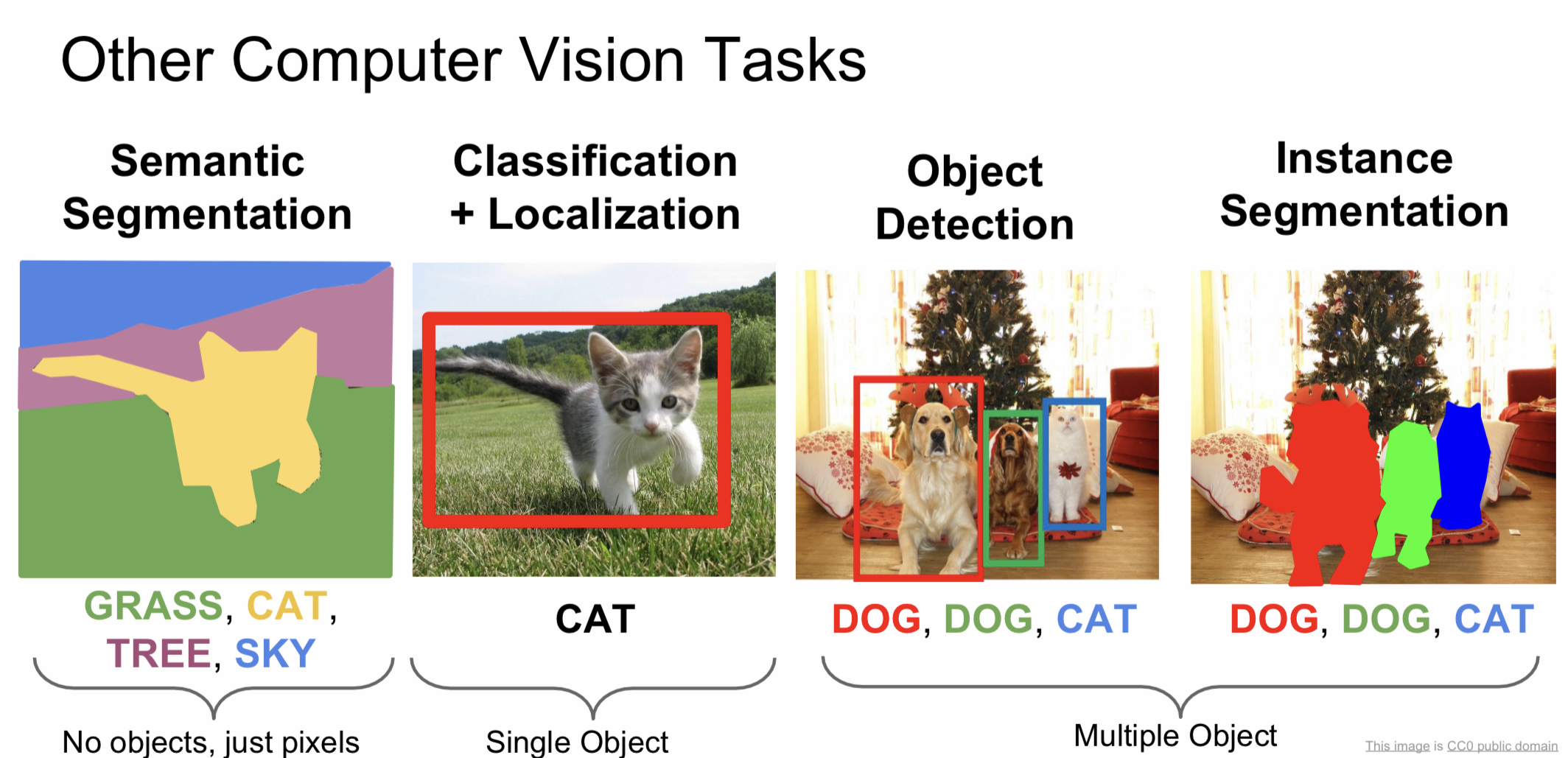
1. Semantic Segmentation
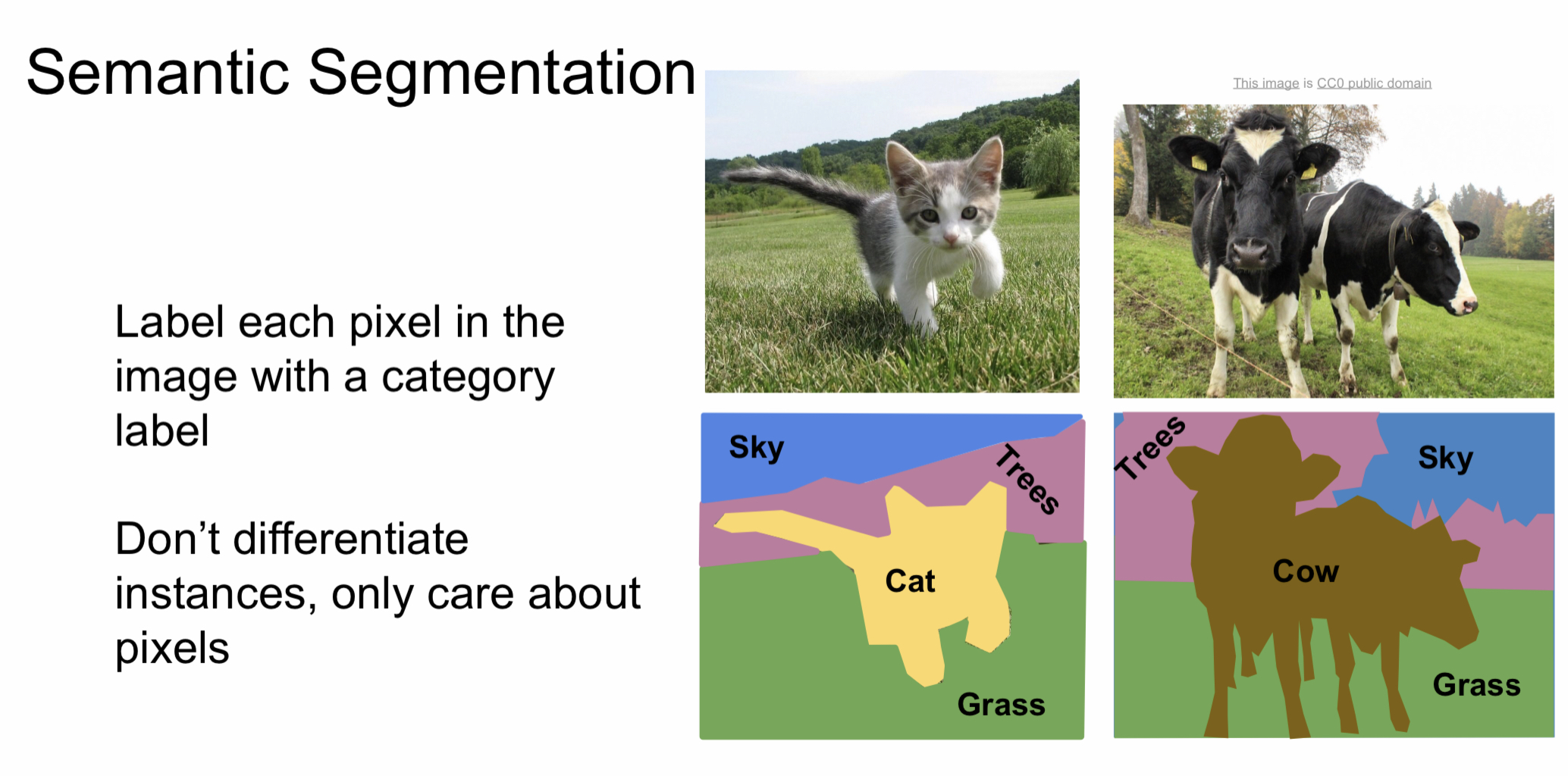
Semantic Segmentation이란 각각의 픽셀 별로 카테고리를 할당하는 방식으로 위의 고양이 사진처럼 고양이 픽셀은 고양이로, 나무 픽셀들은 모두 나무로 구분하는 방식이다. 따라서 소 사진처럼 여러 객체들이 있는 경우에도 한 가지의 카테고리로 분류하기 때문에 객체들의 개수는 파악할 수 없다는 것이 단점이다.
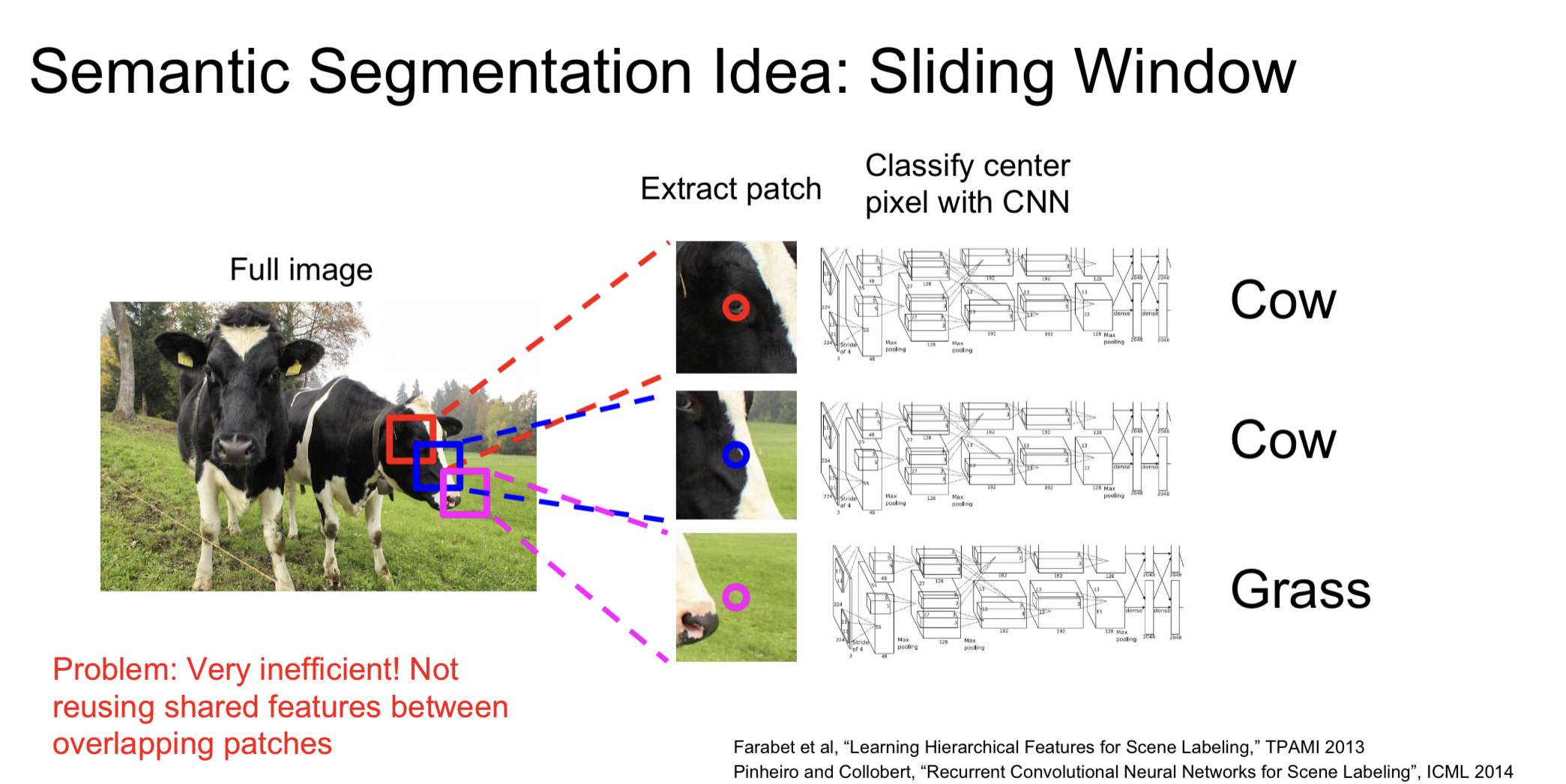
Semantic Segmentation을 하기 위해선 이미지를 잘게 쪼개어 나온 patch 별로 학습을 시켜야 한다. 그러나 이러한 방식은 계산양이 너무 많아 비효율적이라는 단점이 있다.
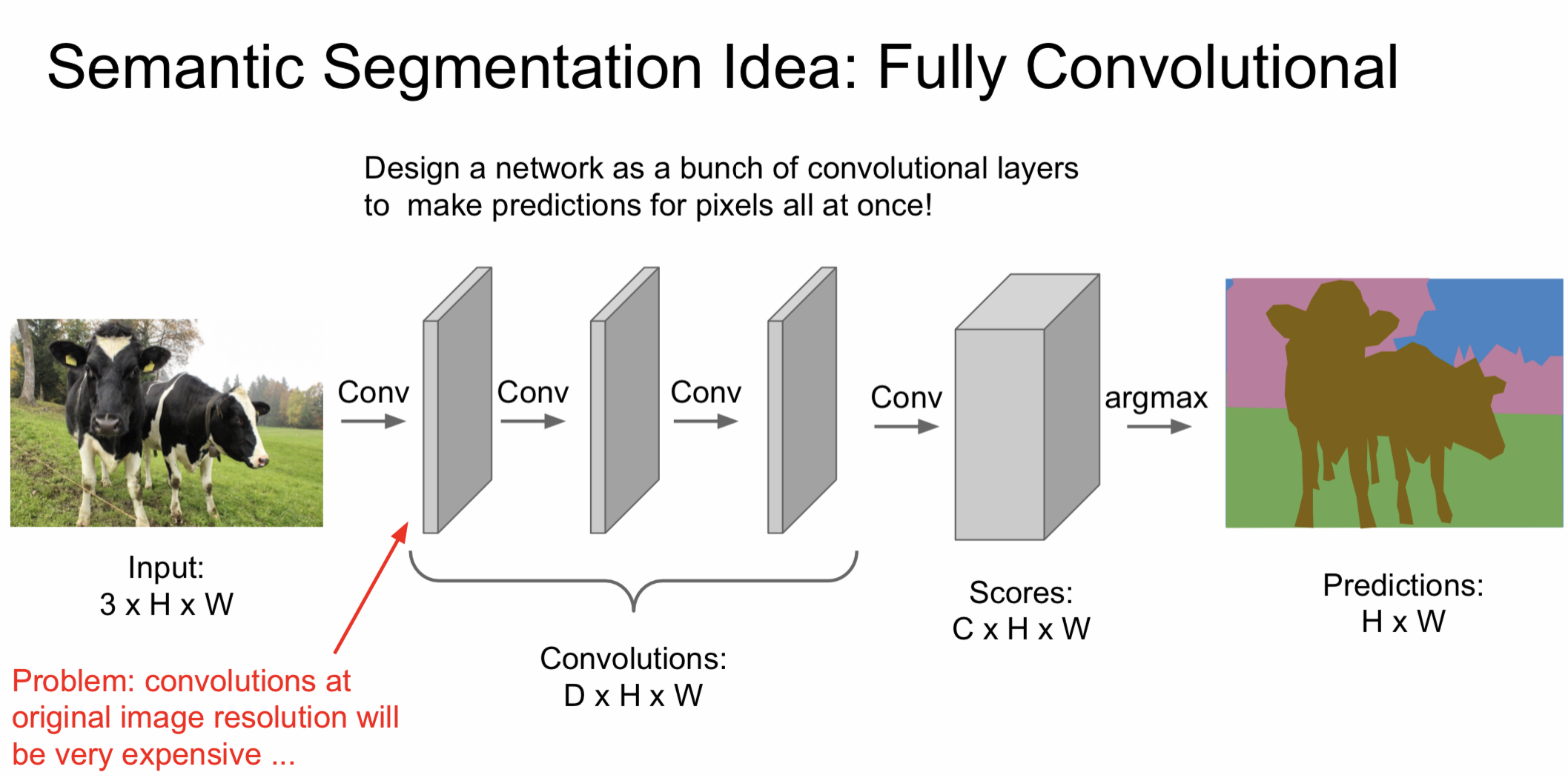
따라서 이미지를 잘게 나누는 방식이 아닌 전체 이미지를 conv layer에 넣어 최종적으로 출력되는 모든 픽셀에 score를 적용하는 방식이 나왔다. 하지만 fully convolution을 하기 위해선 spatial size를 계속 유지시켜야 하기 때문에 계산양이 많아 비용이 너무 크다.
Downsampling & Upsampling
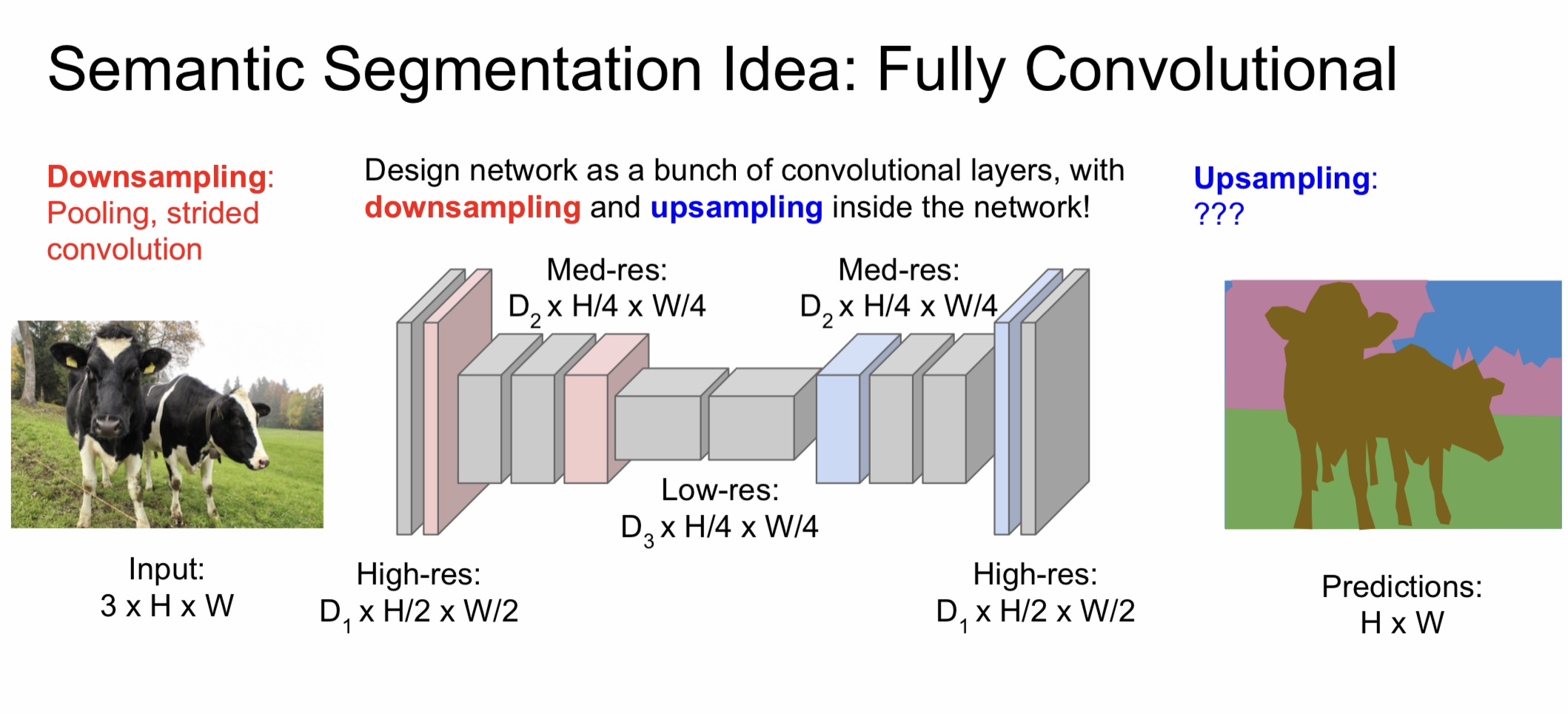
따라서 나온 방식이 downsampling을 진행한 후 upsampling을 하는 방식이다. Downsampling은 기존의 max pooling, stride convolution을 사용하면 되고 여기서는 upsampling에 대해서 좀 더 살펴보려 한다.
Unpooling
Upsampling의 한 방법으로 unpooling이 있다. unpooling에는 여러가지 방식이 존재한다.
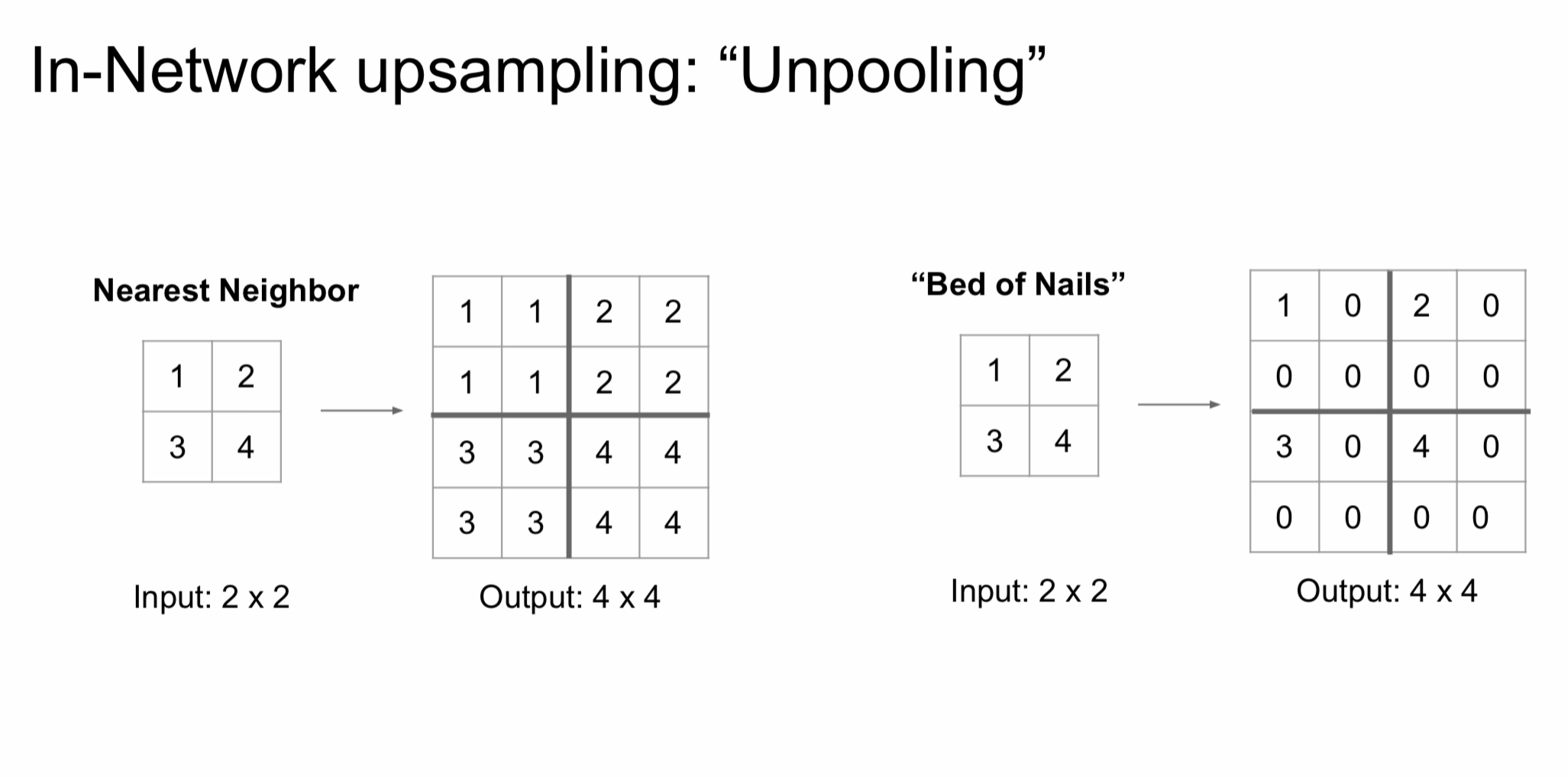
-
Nearest Neighbor : 사이즈를 늘릴 때 주변을 같은 값으로 채움
-
Bed of Nails : 사이즈를 늘릴 때 주변을 0으로 채우기에 해당 값만 돋보임
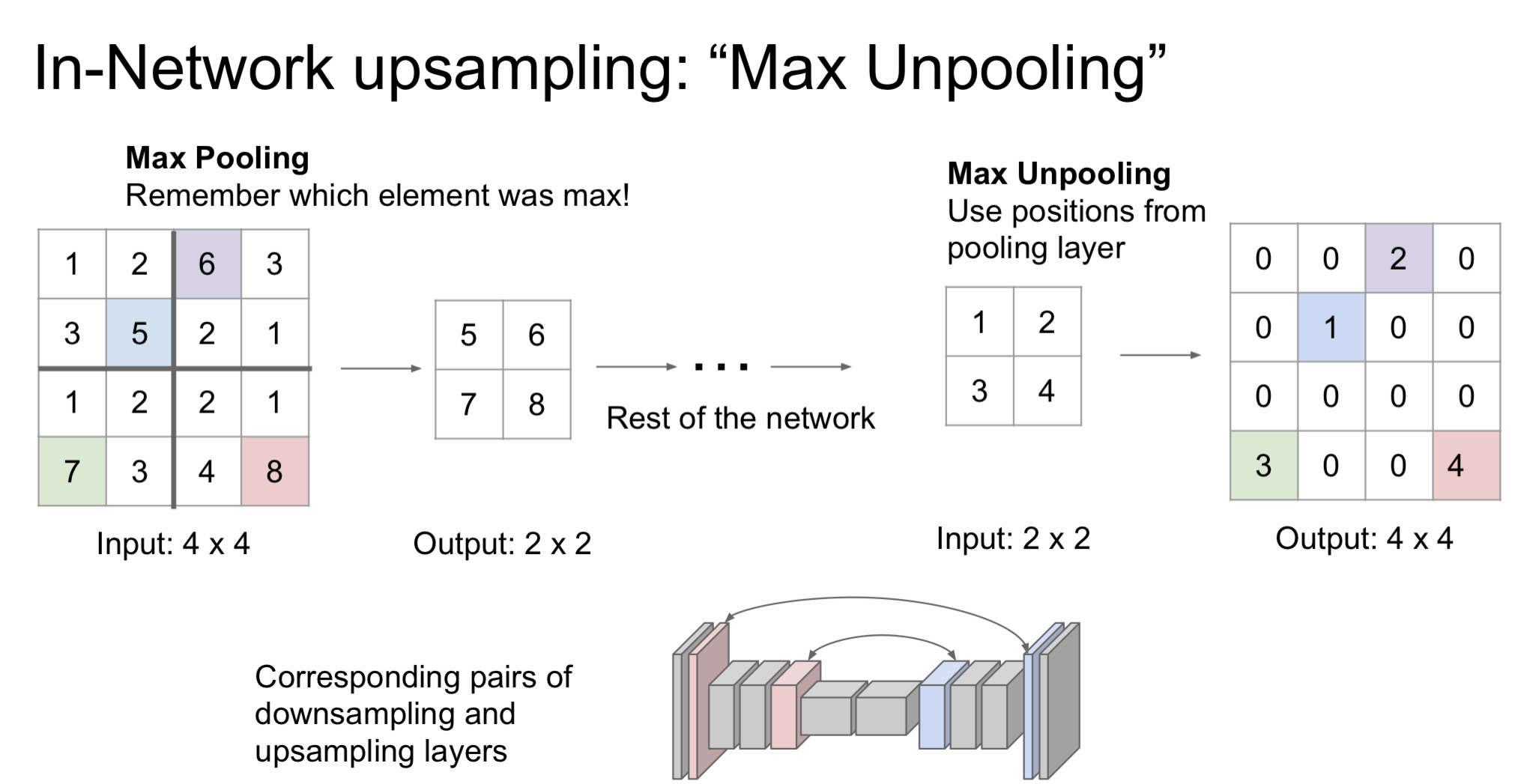
- Max Unpooling : max pooling을 할 때 위치 정보를 기억해서 max unpooling을 할 때 해당되는 위치에 값을 집어넣고 주위는 0으로 채우는 방식
Learnable Upsampling : Transpose Convolution
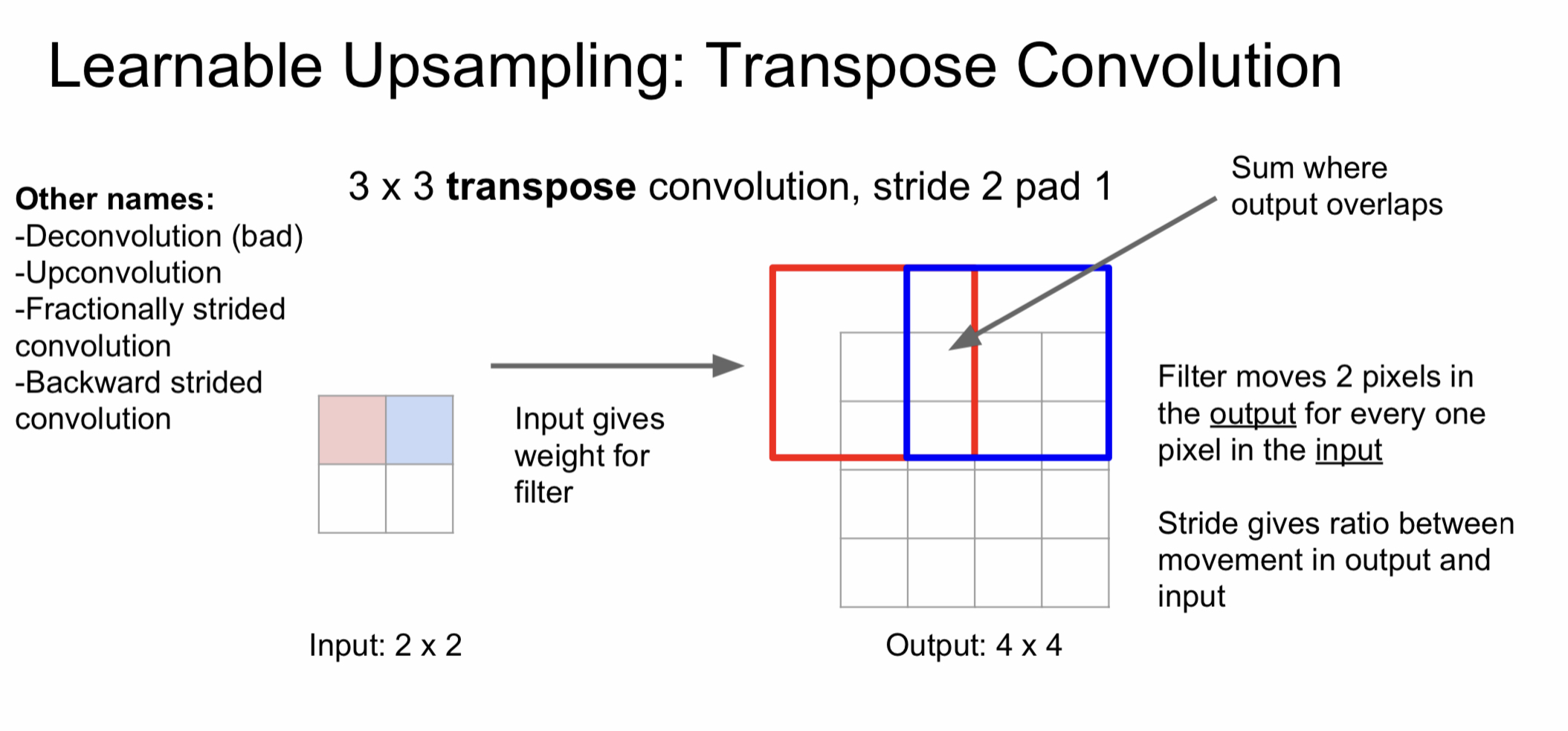
또 다른 방식으로는 학습이 가능한 transpose convolution이 있다. Transpose convolution에선 입력에서 한 스칼라 값을 선택해 filter와 곱하고 그 값을 출력에 넣는다. 입력은 가중치라고 생각하면 된다. 이런식으로 진행하면 겹치는 부분이 생기는데 이 부분은 각 결과값을 더해서 채워준다. 이런 식으로 upsampling을 진행하는데 이게 왜 transpose convolution인지는 matrix 관점으로 생각해보면 된다.

Stride = 2라고 가정했을 때 그냥 와 를 비교해보면 에서 결과가 크게 확장되었음을 볼 수 있다. 이러한 이유로 transpose라는 이름이 붙은 것이다.
2. Classification + Localization
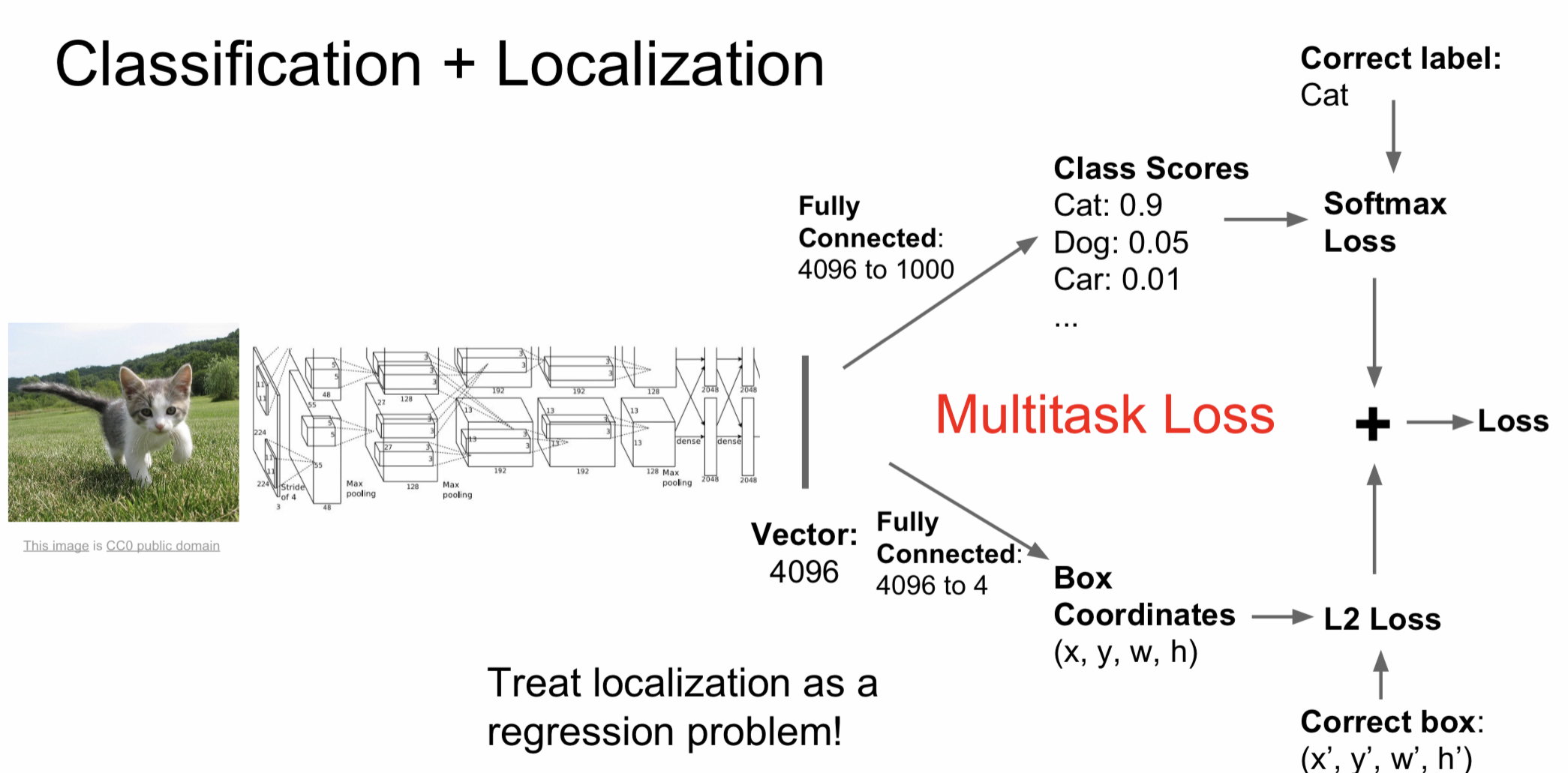
Classification + localization이란 물체를 구별하는 것 뿐만 아니라 물체의 위치까지 알고 싶을 때 사용하는 방법이다. 다만 여기서 구별하는 객체의 수는 1개뿐이다. 이를 구현하기 위해서는 classification과 관련된 loss 뿐만 아니라 위치와 관련된 box coordinates loss도 계산해야 한다. 각각 따로 구한 뒤 나중에 합친다.
3. Object Detection
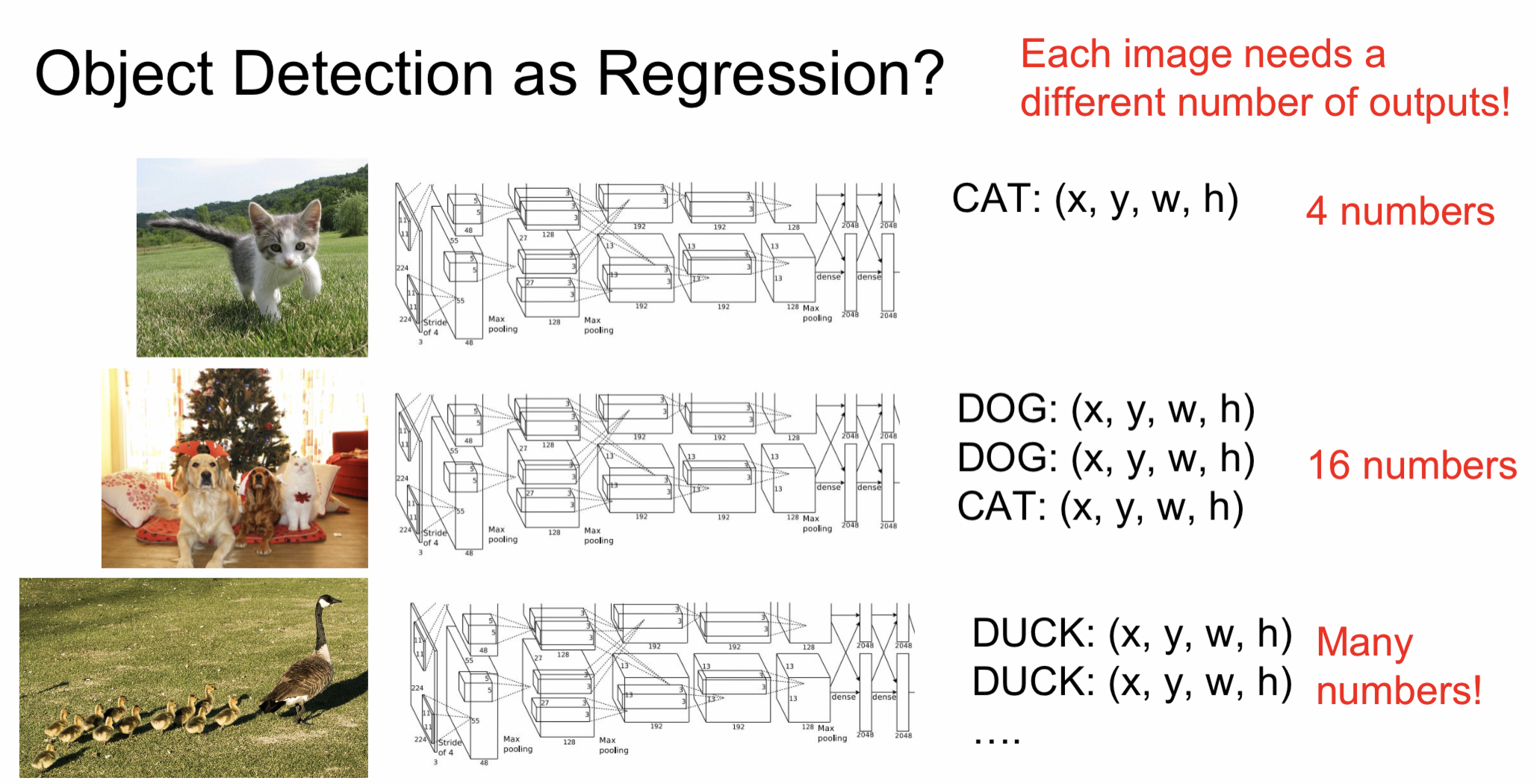
Object detection이란 classification + localization과 다르게 이미지가 주어졌을 때 주어진 이미지에 알맞게 bounding box의 수가 달라진다. 이 bounding box를 이용해서 각 객체들을 위치와 함께 탐지한다. Image마다 객체의 수가 다르기 때문에 앞서 살펴본 classification + localization보다 더 어려운 기술이다.
R-CNN
따라서 이를 구현하기 위해서 새로운 방식이 도입됐는데 우선 region proposals의 개념부터 살펴보자.
Region Proposals

Region proposals이란 객체가 있을만한 후보를 나타내는 것으로 rule-base 기반 알고리즘인 selective search를 이용해서 빠르게 찾아낸다.
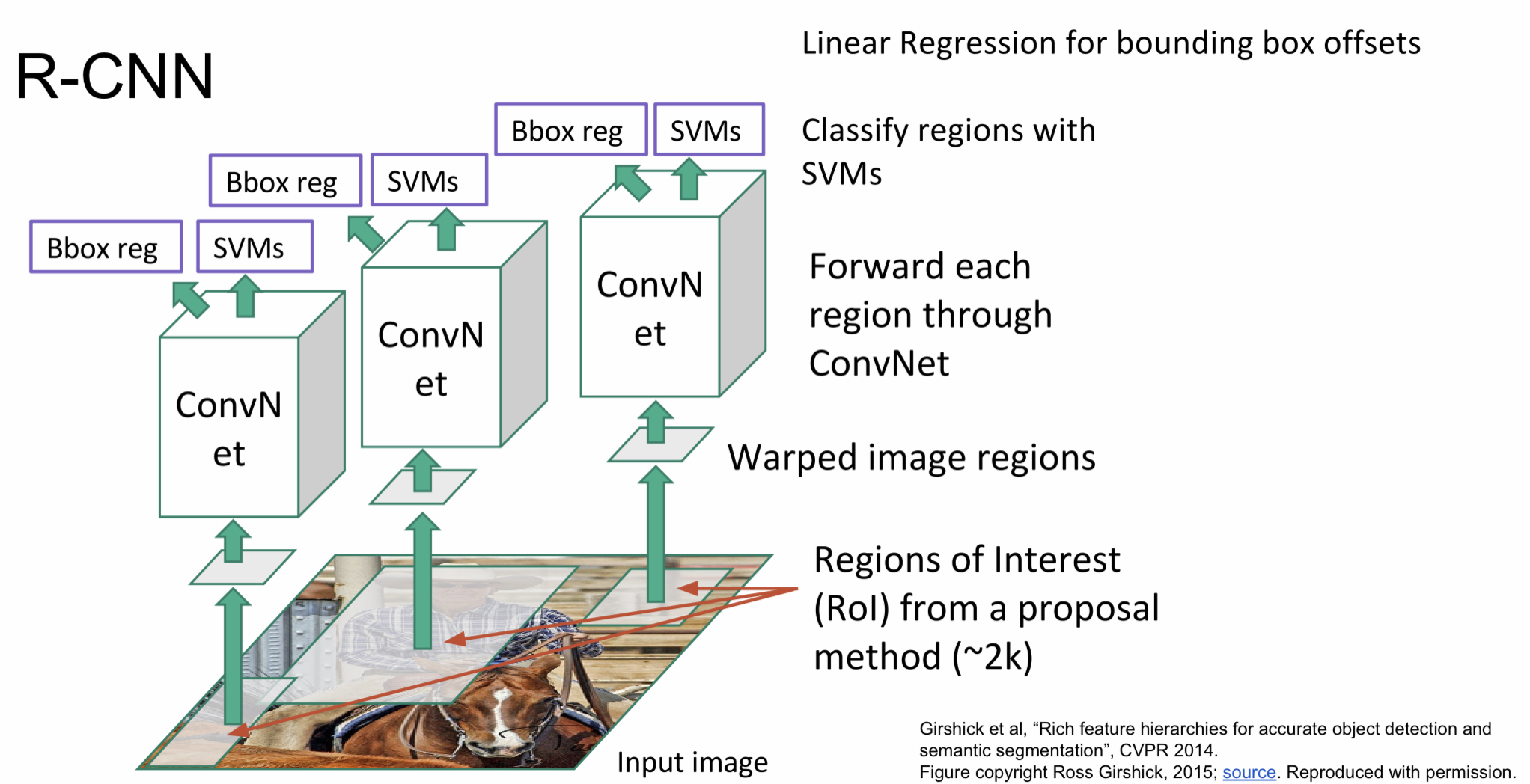
이렇게 구한 region proposals를 이용한 방법이 바로 R-CNN이다. 우선 앞서 구한 region proposals을 CNN에 적용하기 위해 같은 사이즈로 맞춰준 후 CNN에 넣는다. 후에 SVMs를 이용해서 분류하고 region proposals을 보정하기 위해 Bbox reg도 따로 구한다.
하지만 이 방식은 계산양이 너무 많기 때문에 이를 개선한 fast R-CNN이 나왔다.
Fast R-CNN
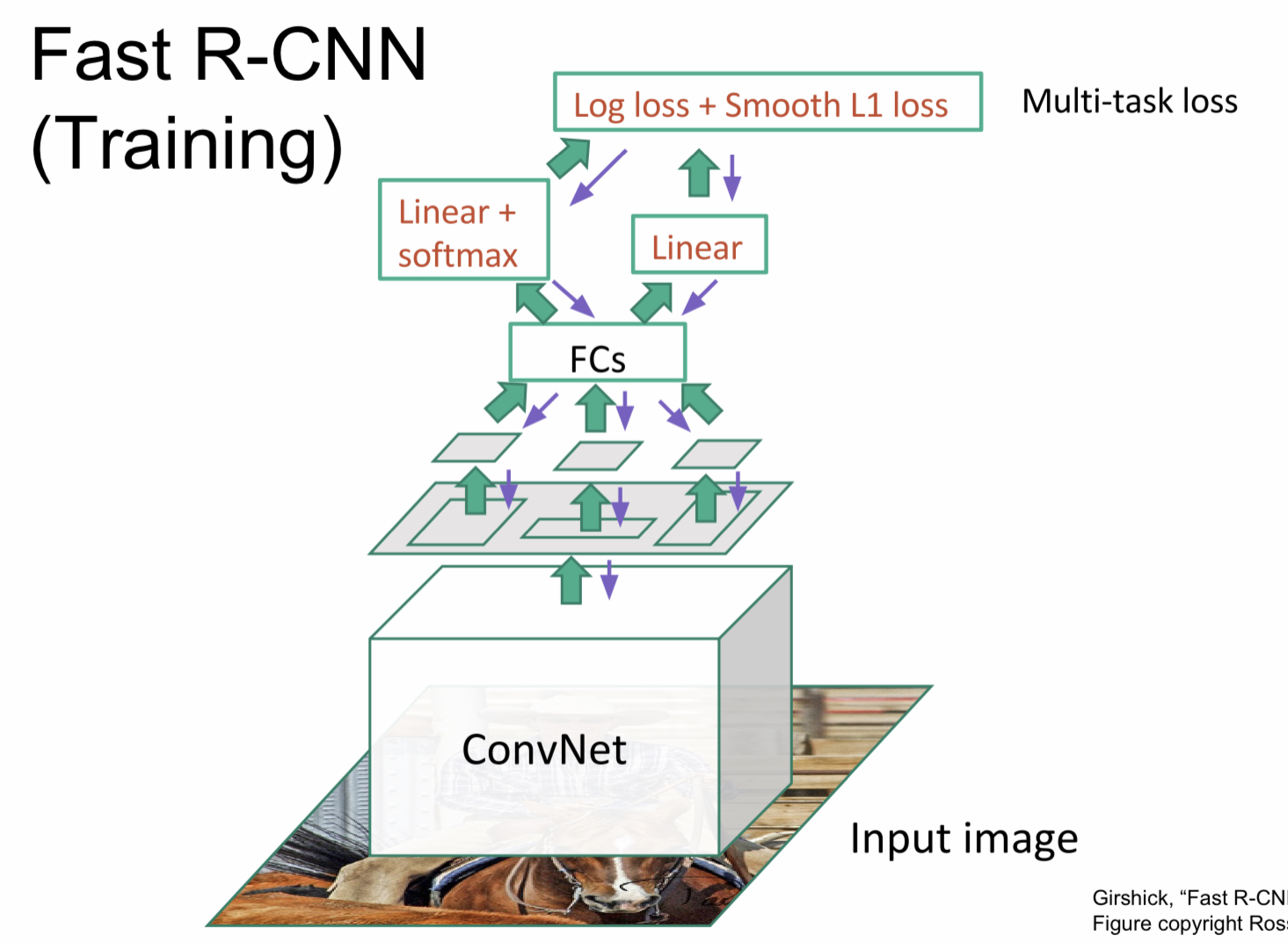
Fast R-CNN은 처음에 전체 이미지를 ConvNet을 이용해 고해상도 이미지를 얻은 다음 Regions of Interest를 구하는 방식이다. 이러한 방식으로 더 빠르게 처리할 수 있게 되었다.
Faster R-CNN
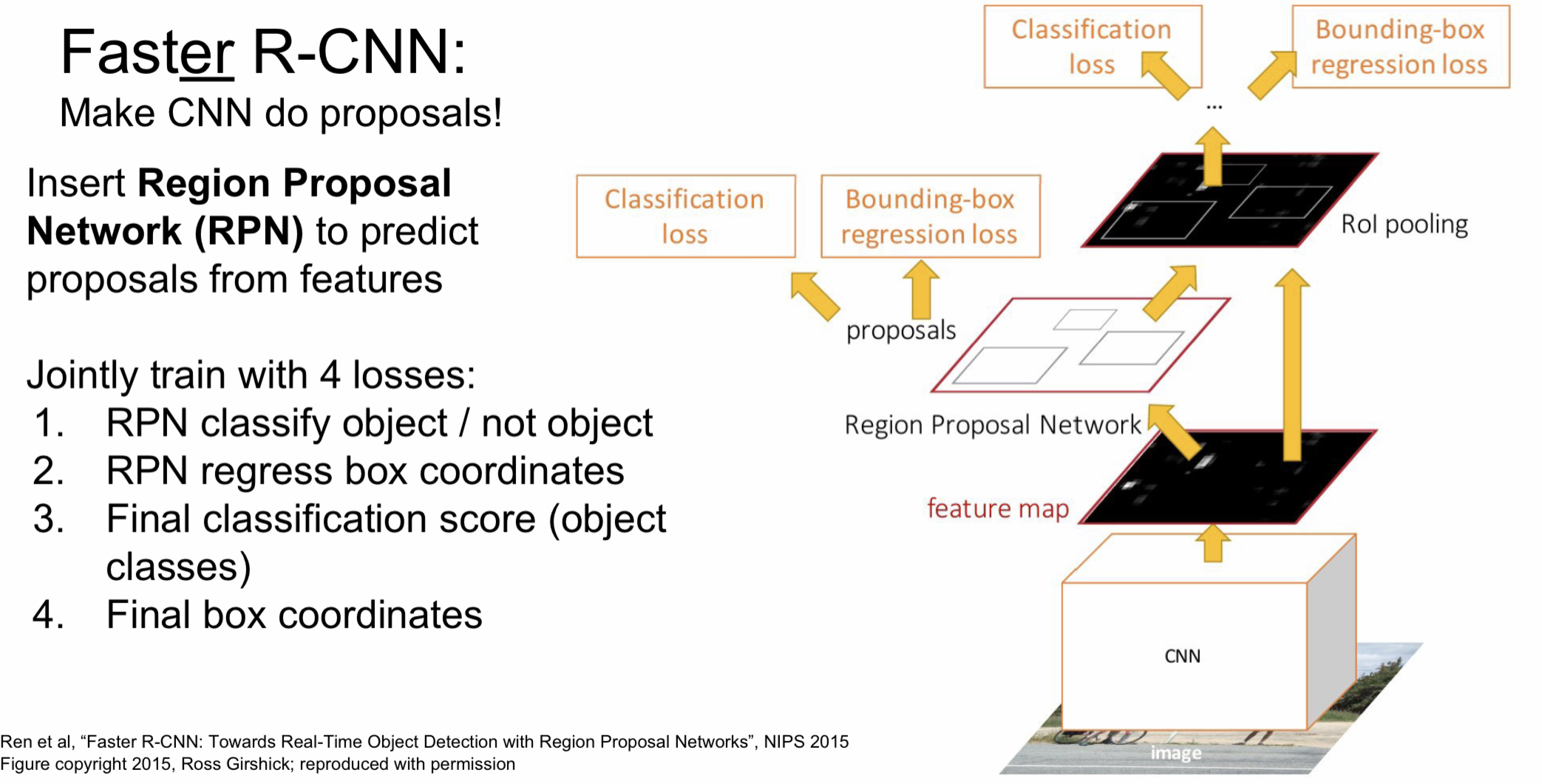
Fast R-CNN보다 더 빠르게 처리되도록 개선한 방법이 바로 faster R-CNN인데 이는 region proposal도 Region Proposal Network(RPN)을 이용해 예측하는 방식이다.
각 방식 별 속도 차이는 다음과 같다.
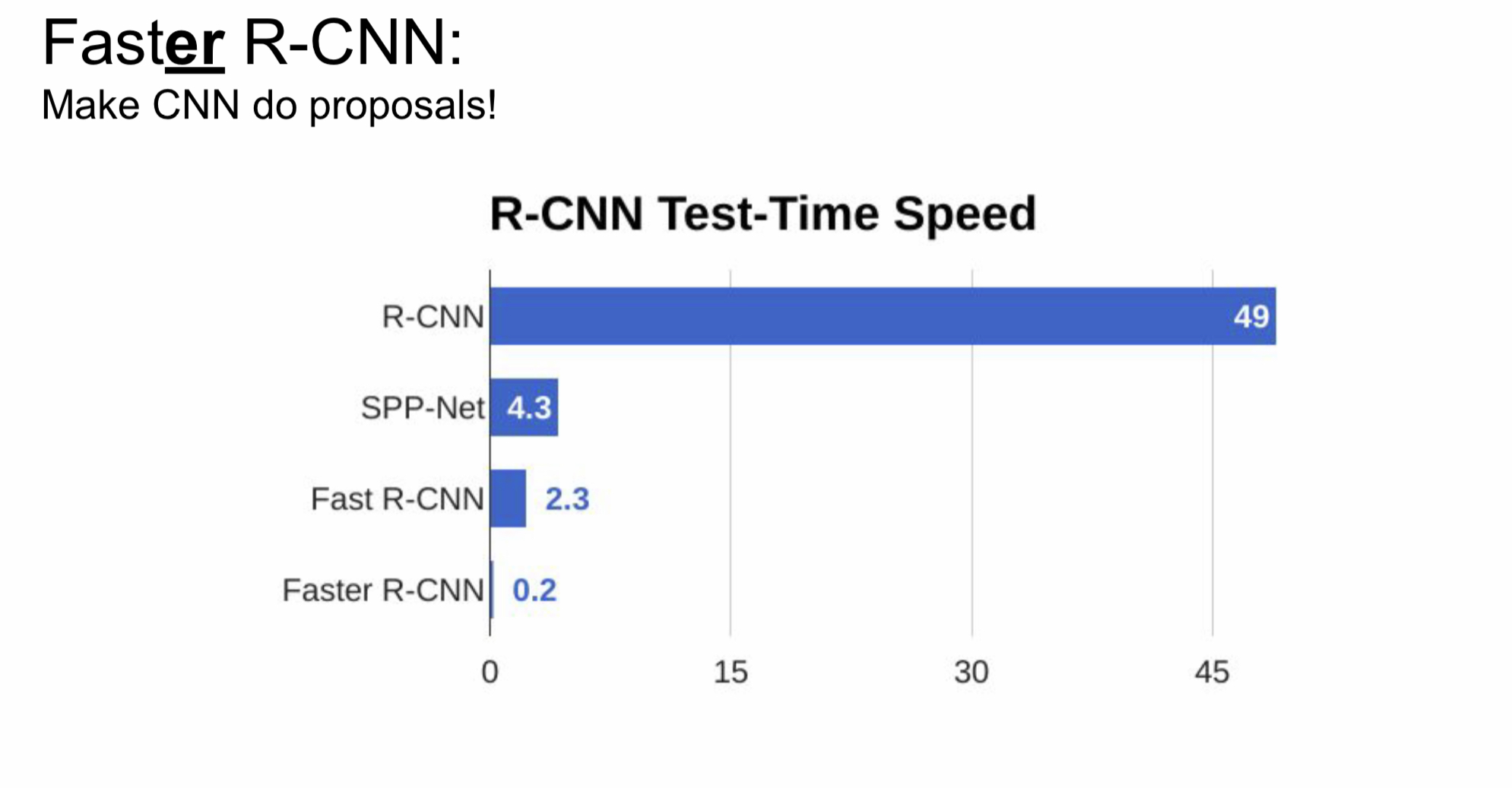
참고자료
