[Paper review] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Paper review
목록 보기
1/14
- 목적
-
GPT(Generative Pre-trained Transformer) 모델은 뛰어난 성능을 보이지만 계산, 저장 비용이 높음
- 추론 시에도 여러 개의 고성능 GPU 필요 (ex) GPT-3 175B → 326GB 필요(FP16))
-
오버헤드를 줄이기 위해 모델 압축 수행 (Low-bitwidth Quantization/ Pruning)
- retraining 필요 → 재훈련 비용 발생
-
PTQ와 같은 Post-training 방법이 매력적
-
PTQ의 정확도 높은 방법들은 수십억개의 파라미터를 가지는 모델에 적용하기는 어렵다는 한계점
- 높은 계산 비용/ 8bit 이하로는 정확도 손실
-
핵심 기여: GPTQ 방법 제시
- one-shot weight quantization
- retraining / fine-tuning 없이 한번의 처리 과정으로 양자화 한다는 의미
- 3~4 bit의 low-bitwidth 양자화 시에도 낮은 정확도 손실/ 빠른 속도 / retraining 불필요
- one-shot weight quantization
- 사전 지식
- Layer-Wise Quantization
- GPTQ가 사용하는 기본적인 접근 방법
- 말 그대로 양자화를 layer-by-layer로 수행 → 여러 레이어를 한번에 하나씩 독립적으로 양자화 함
- 원본 출력과 양자화된 출력 사이의 오차(양자화 오차) 최소화
- Optimal Brain Quantization (OBQ)
- GPTQ의 직접적인 기반이지만 한계점 존재
- 핵심 방법
- Greedy 방법 + 오차 보상
- 하나의 가중치를 양자화할때 생긴 오차 → 나머지의 가중치들을 조정하여 오차 보상
- 최적의 보상을 계산하기 위해 헤시안 행렬 사용 ()
- 목적 함수를 2차 미분한 결과 행렬
- 헤시안 행렬: 입력 X에 대해 목적함수의 기울기가 어떻게 변하는 가를 나타낸 것
- 양자화하지 않은 가중치들(F) 중 양자화를 수행할 가중치 선택
- 양자화시 발생하는 오차를 다른 가중차들이 가장 쉽게 보상해주는 가중치 선택 (최적의 희생양 선택)
- 앞서 선택한 양자화, 양자화되지 않은 나머지 가중치(F)들을 조정해 오차 보상
- 맨 앞 - 부호 → 오차를 상쇄하는 방향으로 업데이트 (gradient descent처럼)
- : 헤시안 역행렬의 q번째 열 벡터
- ⇒ 를 양자화하면서 생긴 오차를 다른 가중치들을 조정해 전체 오차 최소화
- 공통적으로 등장하는
- 헤시안 역행렬에서 q 번째 행, q 번째 열에 위치한 대각 성분
- 가중치의 중요도를 판단하는 지표
- 의 중요도 :
- 가 크면 중요도가 낮다 ( 값 작아짐)
- 가 작으면 중요도가 높다 ( 값 커짐)
- : 를 양자화 했을 때 발생하는 오차를 다른 가중치들이 얼마나 쉽게 보상해 줄 수 있는 가
- 중요도 낮은 가중치→ 값이 큼→ 오차가 조금 크더라도 값이 작음
- 중요도 높은 가중치→ 값이 작음→ 오차가 0에 가깝지 않으면 값이 큼
- ⇒ 중요도가 낮은 가중치부터 우선적으로 양자화
- 매번 헤시안 역행렬을 구하는 비효율을 피하기 위해 아래의 수식 사용
- 가 양자화되었을때 새로 구하는 것이 아닌 바뀐 행 / 열의 값만을 계산해 전체 헤시안 역행렬 계산
- -q의 의미: q에 해당하는 행과 열이 제거된 행렬
- 한계점
- 위와 같은 공식을 사용함에도 불구하고, 위의 모든 과정을 모든 가중치 w에 대해 반복해야함
- 계산 복잡도가 로 큰 모델에는 적용 불가능
- 방법
목표: 정확하지만 느린 OBQ를 거대 모델에 적용할 수 있도록 빠르게 만드는 것
- Step 1: Arbitrary Order Insight (임의 순서 통찰)
- OBQ의 방법 (계산 순서)
- 를 모든 미양자화 가중치에 대해서 계산하여 다음 양자화할 가중치 구함
- 양자화 오차가 작은 순서대로 양자화를 함 (Greedy order)
- 새로운 발견
- 파라미터가 매우 많은 거대 모델에서 양자화 순서에 의한 최종 성능 차이가 거의 없었음
- 이유: 거대 모델은 heavily-parametrized 되어있어 하나의 가중치를 양자화 했을 때 생기는 오차를 보상해줄 다른 가중치가 매우 많음 → 최적의 순서를 찾지 않아도 충분히 오차가 보상됨
- GPTQ의 방법 (계산 순서)
- 첫번째 열부터 마지막 열까지 순서대로 처리
- 효과
- OBQ의 헤시안 역행렬 계산 복잡도:
- GPTQ의 헤시안 역행렬 계산 복잡도:
- OBQ의 시간 복잡도:
- GPTQ의 시간 복잡도: → 배 만큼 빨라짐
- OBQ의 방법 (계산 순서)
- Step 2: Lazy Batch-Updates (지연 배치 업데이트)
- Step 1의 방법만으로는 실제 환경에서 빠르지 않음. (메모리 접근 문제 때문)
- 문제점: 양자화 후 헤시안 역행렬/ 가중치 업데이트 시 메모리 읽고 쓰는 과정에서 병목 현상 발생
- 발견
- i번째 열을 양자화하고 업데이트할 때는 i번째 이전의 열들에게만 영향을 받음
- → i번째 이후의 열은 신경 쓸 필요 없음
- → 업데이트를 즉시 하는 것이 아닌 모아두었다가 한번에 업데이트하여 병목 현상 해결
- GPTQ의 방법(해결책)
- Lazy Batch 방법
- 전체 열을 B(=128)개의 블록으로 나눔
- 한 블록을 양자화할 때, 업데이트를 블록 내부와 헤시안 역행렬의 해당 블록 부분에서만 수행
- 한 블록의 양자화가 모두 끝나면, 나머지 전체 행렬에 대해 업데이트
- 효과
- 이론적인 계산량을 줄이지는 않음
- 매번 업데이트 하는 것이 아닌 한번에 업데이트를 수행하여 GPU의 병렬 처리 능력 극대화
- 식
- OBQ에서 사용한 식과 똑같음. (식은 달라지지 않지만, 업데이트 하는 시점이 다름)
- Lazy Batch 방법
- Step 3: Cholesky Reformulation (숄레스키 분해 재구성)
- Step 1, Step 2를 사용해도 수치적 불안정성(numerical inaccuracies) 문제 발생
- 부동소수점 연산에서 발생하는 작은 오차들이 누적되는 문제
- 헤시안 역행렬이 양의 정부호성을 잃는 등의 문제 발생 → 양자화에 큰 영향을 줌
- 헤시안 행렬
H는 수학적으로 항상 '양의 준정부호(positive semi-definite)'여야 하고, 그 역행렬H⁻¹도 마찬가지입니다. 이 성질은 오차 함수의 모양이 아래로 볼록한 그릇 형태임을 보장하여, 알고리즘이 항상 올바른 '최저점' 방향으로 찾아가게 만듭니다. 하지만 수치 오류가 누적되어 이 성질이 깨지면(indefinite), 오차 지형도가 울퉁불퉁하고 예측 불가능하게 변합니다. 그 결과, 알고리즘이 엉뚱한 방향으로 폭주하여 가중치를 비정상적으로 크게 만들고 양자화를 완전히 망쳐버립니다.
- 헤시안 행렬
- 모델 크기가 커질 수록 이 문제가 발생할 확률이 높아짐 → 거대 모델에서는 몇개의 레이어에서 확정적으로 문제 발생
- 문제점
- 을 업데이트 하는 것이 수치적으로 불안정함
- 발견
- OBQ 알고리즘에서 전체가 필요한 것이 아닌, 특정 행과 열의 정보만 필요함
- 헤시안 역행렬을 업데이트 하는 방식이 숄레스키 분해와 비슷한 구조
- GPTQ의 방법
- 수치적 불안정성을 가지는 헤시안 역행렬 업데이트 공식이 아닌 숄레스키 분해 수행
- 숄레스키 형태: 하삼각행렬*전치행렬 → 역행렬 공식보다 수치적으로 안정적
- 이기에 숄레스키 분해 수행 가능 (
- 수치적 불안정성을 가지는 헤시안 역행렬 업데이트 공식이 아닌 숄레스키 분해 수행
- Step 1, Step 2를 사용해도 수치적 불안정성(numerical inaccuracies) 문제 발생
- GPTQ의 양자화 과정
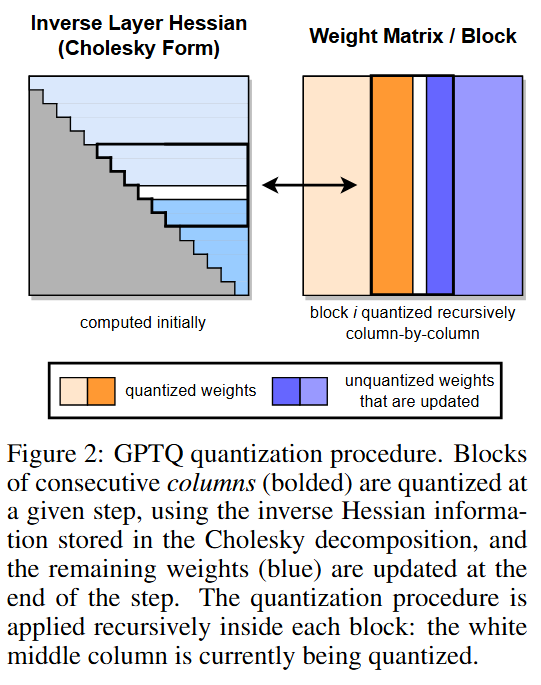
- 숄레스키 형태로 저장된 헤시안 역행렬과 가중치를 순서대로 양자화하는 과정
- 전체 알고리즘

- 실험
-
비전 모델에도 높은 양자화 성능, 매우 빠른 시간에 양자화 수행
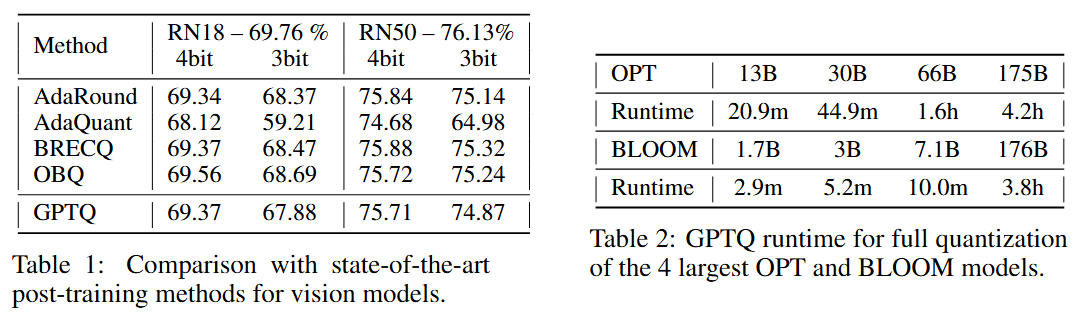
-
3bit와 같은 low-bitwidth 양자화시에도 높은 성능 (Round-To-Nearest은 성능 유지 안됨)
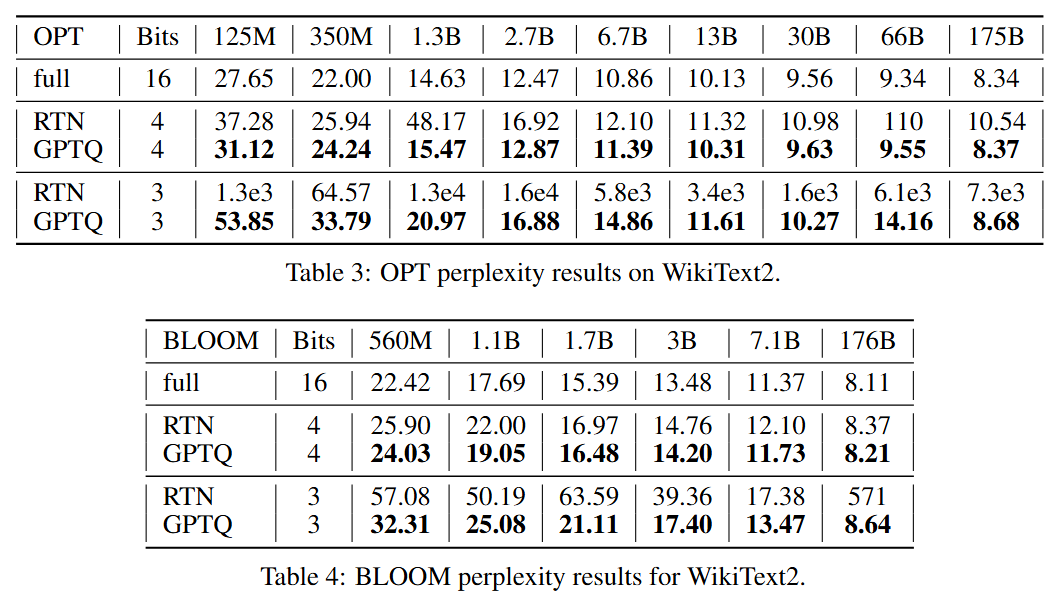
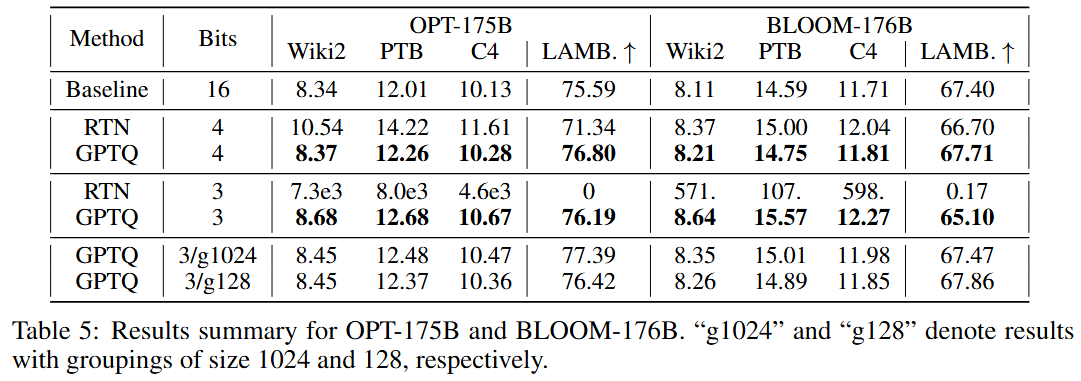
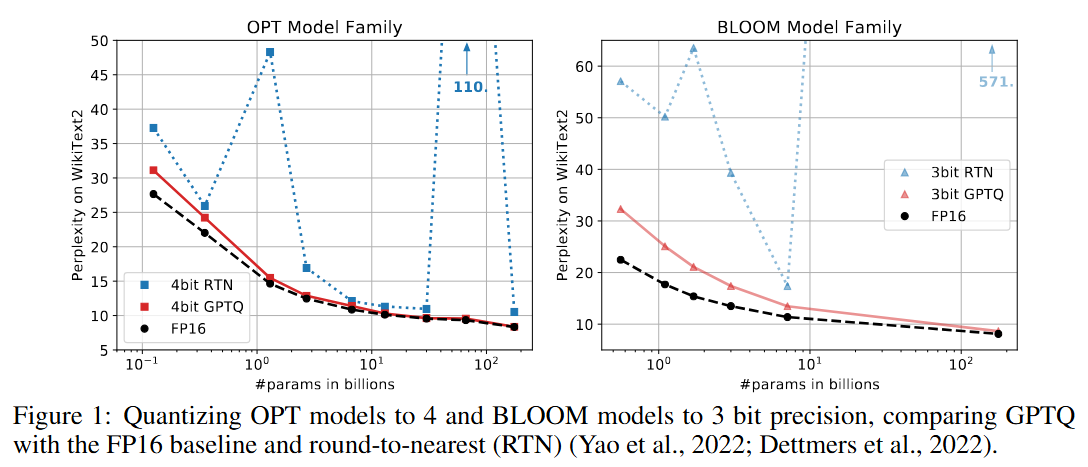
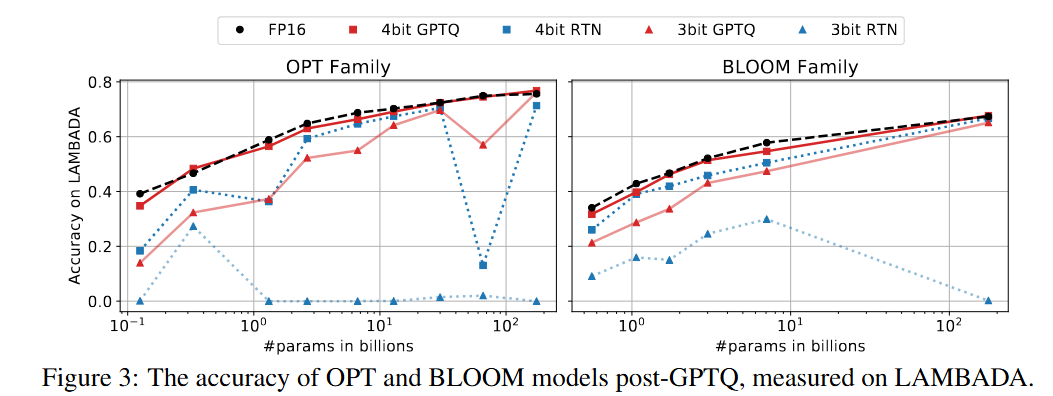
-
추론시 GPU 요구량을 줄일 수 있었음

- 결론
-
핵심 기여
- GPTQ 라는 거대 모델(GPT)에 적용할 수 있는 양자화 방식 제시
- 3~4bit와 같은 낮은 비트에서도 높은 정확도 가짐
- GPU 요구량 및 시간의 획기적인 감소
-
한계점
- weight quantization만 다룸, activation quantization은 다루지 않음
-
개인적인 느낀점
- OBQ ver2 처럼 OBQ에서 단점을 보완한 방법으로 생각되었음
- 정확도도 중요하지만 GPU 사용량이나 속도와 같은 부분이 오히려 더 중요할 수 있다고 생각함

브라우니맛있디